改进SMOTE方法基于XGBoost的信用评分模型
2022-03-23张杏枝
◆张杏枝
改进SMOTE方法基于XGBoost的信用评分模型
◆张杏枝
(重庆交通职业学院(江津)大数据学院 重庆 402247)
针对信用数据中的高维稀疏特征与样本不平衡问题易导致模型分类性能欠佳,提出一种新颖的框架来构建信用评分模型。首先,通过计算特征相似度解决高维稀疏特征;其次针对样本不平衡问题提出基于特征聚类改进的SMOTE方法(FC-SMOTE),以平衡数据集进而提高模型分类性能;最后,采用XGBoost作为基分类器构建信用评分模型。选择网上公开的真实信用数据及UCI数据库中的信用数据进行实验,和传统过采样方法SMOTE、Borderline SMOTE、ADASYN进行对比,实验结果表明,提出的FC-SMOTE方法使基于XGBoost构建的信用评分模型具有更高预测精度。
信用评分;特征相似度;特征聚类;不平衡数据;SMOTE;XGBoost
1 引言
信用卡支付在世界范围内越来越普遍,信用卡评分机构往往利用直观经验来评估申请人的信用状况,这导致出现许多误判情况,最终每年给信用机构带来巨大损失。因此,信用评分模型已被信用机构广泛用于确定信用申请人属于好还是坏的申请人,并给出违约概率的估计。信用评分模型可降低信用分析成本,提高信用机构信用决策能力,减少信用机构的损失。
一些统计技术已被广泛用于信用评分模型,如线性判别分析[1-2],logistic回归分析[3]。然而,基于传统统计技术的信用评分模型一般是根据申请人的申请和征信机构的数据来评估申请人的违约概率,然后通过设置违约概率的阈值,拒绝低于贷款申请水平的信贷申请人。在信贷行业快速发展的今天,传统统计技术在信用评分模型中没有得到很好的应用,因此信贷行业正在积极开发更准确的信用评分模型。
根据以往研究,人工智能(Artificial Intelligence,AI)技术在处理信用评分问题上优于传统统计技术,如人工神经网络[4]、决策树(DT)[5]、支持向量机(SVM)[6]等。与统计技术相比,AI技术无需假设一定的数据分布,它是从训练样本数据中自动选择的,所以在面对大量信用评分数据时,根据信贷行业不同的信用数据集,AI技术都是有效的。
虽然AI技术优于统计技术,但信用评分数据中具有大量高稀疏、冗余特征与数据不平衡问题,导致许多信用评分模型具有高度的复杂性及预测精度过低,容易出现更多的误判概率,即将坏的信用申请人认定为好的申请人或将好的申请人认定为坏的申请人,这一误判将会给信用机构带来巨大损失。因此,为提高预测精度,减少信贷人员的负荷计算,便于银行快速决策,信贷行业迫切需要一种有效的方法去解决高稀疏、冗余特征与数据样本不平衡之间的问题。
高稀疏、冗余特征主要通过特征选择方法解决问题,特征选择的主要目的是从问题域中确定最小和最优的特征子集,同时保持适当的高准确度表示原始特征。文献[7]提出基于卡方的特征选择并将其应用到七个不同分类器中,最后将七个分类器聚合进行研究;文献[8]中为计算特征之间的相关性,提出核矩阵即核弹性网络进行计算;文献[9]提出使用加权L1范数的特征组去解决高维信用数据,但由于该方法没有考虑特征稳定性与模型之间的关系,导致模型预测精度过低。
不平衡数据集是数据集中存在某些类样本数量远远高于其他类,反之则样本数量低于其他类,通常把样本数量较多类化为多数类,样本数量较少类化为少数类[10]。在类不平衡数据集的分类问题中,由于少数类样本具有更高的误分代价,因此对于其他类别样本而言,少数类样本显得更加重要[11]。不平衡数据样本分布不平衡,导致一些传统分类算法的分类性能不佳。针对数据不平衡问题,目前一方面主要采用欠采样、过采样两种方法进行解决,另一方面主要对现有机器学习算法进行改进以此来解决数据不平衡问题。文献[12]对多数类样本进行随机欠采样,进而提出自适应增强(Adaptive Boosting,AdaBoost)方法,但由于随机欠采样具有不稳定性,导致获取的最终样本不具有代表性;文献[13]为解决过采样方法易出现过拟合的问题,提出通过计算每个少数类样本的权重取合成新的样本,但由于该方法需要使用到大量参数,导致其实用性受到限制;文献[14]对传统SMOTE算法进行改进,提出ADASYN算法去生成新样本,新样本的生成主要通过样本的学习难易程度去合成具有不同数量的新样本;文献[15]提出Borderline-SMOTE算法对位于边界的少数类样本进行过采样。
针对上述研究发现,相关文献对于高稀疏、冗余特征与不平衡数据之间没有进行深入研究,因此基于此,提出一种利用特征聚类改进SMOTE过采样算法(FC-SMOTE)并基于XGBoost分类器构建信用评分模型。首先对真实信用数据进行预处理;其次提出聚类计算信用特征之间的相似度进而解决高稀疏、冗余特征问题;接着针对传统SMOTE容易出现过拟合问题,提出基于特征聚类的SMOTE(FC-SMOTE)对传统SMOTE进行改进,以此更好解决过采样出现过拟合问题及更好解决高稀疏特征与不平衡数据之间的问题;最后基于XGBoost分类器构建信用评分模型对信贷申请人的信用状况评估。实验结果表明,利用所提方法构建的信用评分模型具有更高效的预测精度。
2 相关知识
2.1 SMOTE算法
SMOTE算法,即合成少数过采样技术,该算法是Chawla等[16]为解决数据不平衡问题在2002年提出的,它是对传统随机过采样算法的改进,主要思想是对少数类样本进行分析,通过“插值”为少数类样本合成新的样本,并添加到数据集中,进而平衡原始数据集中的不平衡类别分布问题。具体算法如下[17]:
输入:少数类样本1,近邻数,采样倍数为

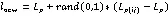
2.2 XGBoost算法
XGBoost(Extreme Gradient Boosting)是一种基于Boosting的极限梯度提升算法,即一种提升数模型[18-19],将许多树模型集成形成一个强大的分类器,所用到的基础树模型为CART回归树。
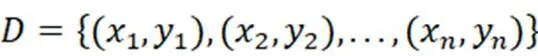
(1)模型表示为


(2)目标函数和损失函数优化
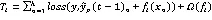
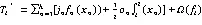
(3)最优值

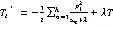
XGBoost算法在分类方面具有非常优异的表现,在分类性能上具有较高精度。因此,将采用其作为信用评分模型构建的基分类器,将XGBoost算法应用到信用评分预测中。
3 模型建立
针对相关方法对高稀疏、冗余特征与不平衡数据之间没有进行深入研究的情况,本文提出FC-SMOTE过采样方法,采用XGBoost作为基分类器构建信用评分模型,模型框架如图1所示。后续内容将对模型流程步骤进行详细描述。
3.1 数据预处理
由于信贷数据来源较广,导致征信机构获取的信用数据中常存在大量缺失、冗余数据。因此为减少信用数据中噪声数据对评分模型最终预测精度造成损失,在建立评分模型之前需对原始信用数据进行预处理,本文采样现有数据预处理方法中的Min-Max标准化方法,通过对原始信用数据进行线性变换,使其结果值处于[0,1]之间,该标准化公式为:

3.2 基于特征聚类改进的SMOTE过采样算法—FC-SMOTE
3.2.1 特征相似性计算消除噪声特征
对数据进行预处理后,需要对信贷申请人的信用特征进行重要度计算,一方面可以减少后续评分模型的输入,因为在重要度计算过程中,可根据每个特征值大小将一些无用特征剔除;另一方面可以加快模型的训练速度,进而降低模型时间复杂度。通过公式(8)、(9)计算两个变量之间的相关性,根据相关性值的大小剔除部分冗余、高稀疏特征。
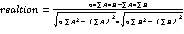

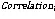
3.2.2 特征聚类改进的SMOTE方法—FC-SMOTE
通过3.2.1节消除部分冗余特征后,为了挑选出最佳特征子集及解决样本的不平衡分布,提出基于特征聚类改进的SMOTE过采样方法-FC-SMOTE,其具体过程描述如下:
(1)采样3.2.1处理后生成的新训练集对信用特征进行聚类,即特征聚类(采样传统K-means方法);
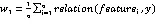
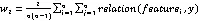

其中1表示簇元素内特征类间相关性,2表示类内相关性。
(3)产生最佳特征簇的过程中,通过簇数中的特征个数为其分配不同权重,以此对少数特征簇样本进行过采样,保持少数类样本的平衡,权重分配计算如下:
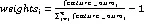
(4)根据公式(13)的权重大小对少数类样本进行采样,选择样本与所属类簇簇心之间进行线性插值,进而得到簇中合成样本集2。将L2加入新合成少数类数据集1;
(5)输出合成样本集1。
3.2.3 改进SMOTE基于XGBoost的信用评分模型
数据集经过3.2.1和3.2.2处理后,将得到一个相对“干净“且平衡的数据集,最后对处理后的数据集使用XGBoost分类器构建信用评分模型。具体的流程如表1所示。
表1 改进SMOTE基于XGBoost的信用评分模型算法流程
输入:平衡后的信用数据集输出:预测精度Accuracy,F1-Score 过程:(1)通过公式(7)对原始数据预处理,将原始数据按照7/3划分为训练集L和测试集T;(2)针对训练集L利用公式(8)、(9)消除冗余特征;(3)利用公式(10)、(11)、(12)、(13)对训练集L重新采样,得到新的训练样本L1;(4)对于L1,将其划分为训练集与验证集,多次抽取小样本,分别为,最终合成新训练样本;(5)将训练集通过XGBoost分类器进行训练;(6)将验证集代入XGBoost模型进行验证;(7)end for
4 实验及分析
4.1 实验环境及实验数据
实验环境:Intel Core i3-3110M CPU 2.40GHz,8G内存的普通PC机,基于PyCharm 2020平台,采用python语言进行实验。
实验数据:本文采用的实验数据集来自于UCI数据库中的German、Australian信用数据集及网上公开的Europe信贷客户数据集(France、German和Spain),为保证信贷客户的安全及保持数据的机密性,分别对以上三个数据集中的某些特征名称和值进行了加密,将其更改为无意义的数据符号,上述数据集基本信息归纳整理如表2。

图1 改进SMOTE基于XGBoost的信用评分模型框架
表2 实验数据集描述
国家样本大小类别特征信用良好信用不良不平衡率 German10002207003002.33 Australian6902143073830.82 Europe10000212203779633.91
4.2 实验评价指标
本实验采用的信用评分数据是一个经典二分类问题,因此选取混淆矩阵中相应指标值进行评估,包括精确率Precision、召回率Recall、F1分数(F1-Score)和准确率Accuracy。其中,对信用评分中的混淆矩阵各个指标具体描述为:设Y=1表示“好”顾客,Y=0表示“坏”顾客,则混淆矩阵如表3所示。
表3 混淆矩阵
混淆矩阵真实 Y=0,好顾客Y=0,好顾客 预测Y=0,好顾客TPFP Y=0,好顾客FNTN
其中,TP(Ture Positive)预测信用属于“好”顾客,而实际信用也属于“好”顾客;
FP(False Negative)实际信用属于“坏”顾客,而预测信用属于“好”顾客;
FN(False Positive)实际信用属于“好”顾客,而预测信用属于“坏”顾客;
TN(Ture Negative)预测信用属于“坏”顾客,而实际信用也属“坏”顾客;
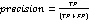
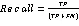

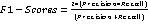
4.3 实验结果及分析
4.3.1 特征相似度消除噪声特征
图2展示了利用公式(8)、(9)计算出的特征与类标签之间的相似度值,通过相似度值的大小可将值较低的冗余特征剔除,以减少噪声特征对后续模型的训练时间。
4.3.2 FC-SMOTE方法验证
为验证FC-SMOTE过采样方法对改善数据平衡的效果,将其与采用传统SMOTE、Borderline SMOTE、ADASYN过采样方法对数据进行抽样后的少数类样本占比进行对比,实验结果如图3所示。
由图3可看出,通过采用FC-SMOTE过采样方法对少数类样本进行采样处理后,其占比明显得到提升,进而使数据样本得到平衡。
同时,表4、5展示的是基于3.2.1节对消除噪声特征进行剔除后,针对新生成的数据集,对少数类样本进行抽样过程中,挑选出的最佳子集。

图2 特征相似度

图3 数据过采样处理对比
表4 German信用数据最佳特征子集生成过程
聚类个数聚类编号特征特征合并比率合并后比率 K=214,5,7,8,10,11,14,15,17,18 5.4 21,2,3,6,12,201.5 K=314,8,10,11,15,16,17 4.0 21 32,3,5,7,12,12,14,2015.05.5 K=415,7,12,14,2 4 21 34,8,10,11,15,17,18 3 47,8,2,3,6111.5 K=512,3,6111.5 24,8,10,11,17,18 2.5 35,7,12,14,2 2.5 41 515,1 1.8
表5 Australian信用数据最佳特征子集生成过程
聚类个数聚类编号特征特征合并比率合并后比率 K=212,3,4,6,7,11,12,13 4.5 23,5,8,9,101.5 K=312,3,4,6,11,12,13 4.0 28 35,7,9,1081.52 K=412,3,4,6,12,131,1134 25,7,9,1081.52 38 411 0.5 K=512,3,461.62 25,9,10811.5 38 46,7 0.5 511,12,1370.61.1
根据表4、5可得出,对于German信用数据集来说,最优特征子集为{1,2,3,6,7,8,12,20},Australian信用数据集最优特征子集为{3,5,8,9,10,11,12,13},由于Europe数据集的特殊性,最终选定是特征子集为{3,4,5,6,7,8,9,10,11,12}。
4.3.3 模型有效性验证
为验证FC-SMOTE过采样方法基于XGBoost算法构的建信用评分模型最终性能,将提出的FC-SMOTE方法与传统过采样方法SMOTE、Borderline SMOTE、ADASYN在基分类器XGBoost上进行实验对比,分别用准确率Accuracy、F1分数(F1-Score)进行判定,实验结果如表6、7所示。
表6 四种算法在三个信用数据集上的F1-Score值
算法GermanAustralianEurope SMOTE-XGBoost72.9178.6269.41 ADASYN-XGBoost74.1183.6371.85 Borderline SMOTE-XGBoost79.3786.9076.52 FC-SMOTE-XGBoost84.2188.9378.98
表7 四种算法在三个信用数据集上的Accuracy值
算法GermanAustralianEurope SMOTE-XGBoost69.7283.1265.06 ADASYN-XGBoost72.4182.7770.66 Borderline SMOTE-XGBoost75.2880.8171.52 FC-SMOTE-XGBoost79.1289.3277.84
由表6、7可知,German、Europe信用数据集相对于Australian信用数据来说,数据不平衡分布较明显,导致在F1-Score、Accuracy得分都低于Australian信用数据集的得分;但相比而言,三个信用数据采用FC-SMOTE过采样方法基于XGBoost算法构建的信用评分模型的最终F1-Score、Accuracy比采用传统过采样方法SMOTE、Borderline SMOTE、ADASYN三种方法分值得到明显提升,其中对于German数据集,其Accuracy相比基于Borderline SMOTE-XGBoost构建的评分模型的预测精度提升了4.84%;Australian数据集,其Accuracy相比基于SMOTE-XGBoost构建的评分模型的预测精度提升了6.2%;Europe数据集,其Accuracy相比基于Borderline SMOTE-XGBoost构建的评分模型的预测精度提升了6.32%,对于信贷机构来说,信贷模型预测精度提升1%将会为其减少巨大损失,因此,根据上述结果显示,利用FC-SMOTE方法去构建信用评分模型对模型的预测精度提升有较好的效果。
5 结束语
在信用数据方面,由于存在大量噪声特征、数据严重不平衡分布问题,使得研究人员在现有信用评分模型的基础上,不断提出新型信用评分模型,并不断研究在构建评分模型时,如何更好地处理好噪声特征与不平衡数据之间的关系。因此,为构建更有效的信用评分模型,本文提出了改进SMOTE的基于XGBoost的信用评分模型,在此过程中,不仅充分考虑了消费特征之间的相似性,还对传统的过采样方法进行了改进,更好地解决了信用特征与数据不平衡分布的问题。实验表明,所提出的方法构建的信用评分模型有很好的预测性能。但由于采用的信用数据量不是很大,而且特征数也比较少,所以对于数据量庞大和特征数量多的信用数据,可能会导致所提出方法构建的模型计算时间过长,因此,在今后的工作中,将尝试采用集合分类器去构建更稳定的信用评分模型。
[1]A.K. Reichert,C.C. Cho,G.M. Wagner,An examination of the conceptual issues involved in developing credit-scoring models,Journal of Business and Economic Statistics 1(2)(1983)101-114.
[2]G. Karels,A. Prakash,Multivariate normality and forecasting of business bankruptcy,Journal of Business Finance Accounting 14(4)(1987)573-593.
[3]Bravo,C.,Maldonado,S.,Weber,R.,2013. Granting and managing loans for microentrepreneurs:new developments and practical experiences. Eur. J. Oper. Res. 227(2),358e366.
[4]Angelini E,di Tollo G,& Roli,A. A neural network approach for credit risk evaluation. Q. Rev. Econ. Financ. 48, 733-755(2008).
[5]Wen F and Yang X. Skewness of return distribution and coefficient of risk premium. J. Syst. Sci. Complex,2009;22:360-71.
[6]Kim G,Wu CH,Lim S and Kim J. Modified matrix splitting method for the support vector machine and its application to the credit classification of companies in Korea. Expert Syst. Appl,2012;39:8824-34.
[7]Shashi Dahiya,S.S Handa and N.P Singh. Credit scoring ensemble of various classifiers on reduced feature set. Industrija, vol.43,No.4,2015.
[8]B. Vinzamuri and C. K. Reddy. Cox regression with correlation based regularization for electronic health records. Proceedings of the IEEE International Conference on Data Mining (ICDM),757-767,2013.
[9]Bhanukiran Vinzamuri,Karthik K. Padthe,and Chandan K. Reddy. Feature Grouping using Weighted L1 Norm for High-Dimensional Data. 2016 IEEE 16th International Conference on Data Mining,1233-1238,2016.
[10]莫赞,盖彦蓉,樊冠龙.基于GAN-AdaBoost-DT不平衡分类算法的信用卡欺诈分类[J].计算机应用,2019,39(2)618-622.
[11]Bahnsen A C,Aouada D,Stojanovic A,et al. Feature engineering strategies for credit card fraud detection[J]. Expert Systems with Applications An International Journal,2016,51(C): 134-142.
[12]SEIFFERT C,KHOSHGOFTAAR T M,van HULSE J,et al. RUSBoost:a hybrid approach to alleviating class imbalance [J]. IEEE Transactions on Systems,Man,and Cybernetics-Part A:Systems and Humans,2010,40(1):185-197.
[13]ZHU T,LIN Y,LIU Y.Synth eticminority over sampling technique for multi class imbalance eproblems [J].Pattern Recognigtion,2017:327G340.
[4]He,H.,Bai,Y.,Garcia,E.A.,et al.(2008)ADASYN:Adaptive Synthetic Sampling Approach for Imbalanced Learning. IEEE International Joint Conference on Neural Networks,1322-1328.
[15]Han,H.,Wang,W.-Y.and Mao,B.-H.(2005) Borderline-SMOTE:A New Over-Sampling Method in Imbalanced Data Sets Learning. Advances in Intelligent Computing. Springer,Berlin,Heidelberg. https://doi.org/10. 1007/11538059_91.
[16]Chawla,N.V.,Bowyer,K.W.,Hall,L.O.,et al.SMOTE:Synthetic Minority Over-Sampling Technique.Journal ofArtificial Intelligence Research,16,321-357. https://doi.org/10.1613/jair.953.
[17]许芷慧,杨立洪. 改进SMOTE算法在Logistic回归信用评分模型中的应用[J].数据挖掘,2021,11(2),50-58.
[18]KARAMSHUK D,NOULAS A,SCELLATO S. Geo-Spotting: Mining online location-based services for optimal retail store placement[C]// Proceeding of the 19th ACMSIGKDD International Conference on Knowledge Discovery and Data Mining,2013:793-801.
[19]CHEN T Y,CHEN L C,CHEN Y M. Mining location based service data for feature construction in retail store recommendation[C]// Industrial Conference on Data Mining.Springer,2017:68-77.
[20]刘斌,陈凯. 基于SMOTE和XGBoost的贷款风险预测方法[J]. 计算机与现代化,2020.
