基于生成对抗网络的多智能体对抗仿真建模方法*
2022-03-23孙旭朋黄文铮
白 桦,孙旭朋,黄文铮
(北京圣涛平试验工程技术研究院有限责任公司,北京 100089)
0 引言
无人化与智能化是当今武器装备体系发展的一个重大技术趋势,各种无人装备如无人飞机、无人车辆、无人舰船等陆续投入战场,以更好地建立未来的海底、海洋、陆地、空间优势[1-4]。无人化与智能化武器装备通常以集群的方式参与军事行动,通过装备间的协同合作,发挥“倍增”的作战效能。在武器装备无人化与智能化发展过程中,人工智能相关的研究成果也不断地应用于体系仿真建模中。国内外研究表明,传统的建模方法(诸如还原论方法、归纳推理方法等)已经不能很好地刻画复杂系统,而基于多智能体的建模则是最具活力、最有影响的方法之一。其基本思想是通过模拟现实世界,将复杂系统划分为与之相应的智能体,从研究个体微观行为着手,进而获得系统宏观行为[5]。
在人工智能领域,强化学习为一类特定的机器学习框架,已在电动游戏、棋盘游戏、自动驾驶等领域进行应用[6-7],与深度神经网络结合的DQN 是其中经常采用的建模方法。在一个强化学习系统中,决策者通过与环境的交互来学习如何得到最大化回报。强化学习的特点是在学习过程中没有正确答案,而是通过回报信号来激励学习。因此,在特定领域内,一个设计良好的强化学习模型经过训练可以超过人类的水平,在Deepmind 的AI AlphaGo和星际争霸II 的人机对抗中得到体现。这一特性也意味着强化学习具有极大的军事应用价值,引起美国国防部高级研究计划局(简称DARPA)的高度关注,设置了多个项目进行技术攻关,近期“Alpha dog fight”竞赛中,深度强化学习模型击败了人类战斗机驾驶员。
GAN[8]由Ian Goodfellow 等人在2014 年提出。GAN 的核心思想是对抗性学习,即同时训练两个互相对抗的模型,其中,生成器G 从一个指定的随机分布中生成样本,而判别器D 用来分辨样本的真实性。对抗指的是生成网络和判别网络的互相对抗。生成网络尽可能生成逼真样本,判别网络则尽可能去判别该样本是真实样本,还是生成的假样本。基于这种学习框架,GAN 不需要马尔可夫链或其他复杂的概率近似推理,这对提高训练学习效率具有显著作用。它使得在多智能体对抗仿真建模技术领域,GAN 可以在不依赖于任何关于分布假设的情况下,以一种简单的方式学习高维、复杂的真实数据分布。
现代军事对抗仿真需要模拟越来越复杂的对抗场景,通常需要经过极为复杂的对抗动作序列之后才能得出一个对抗结果。而以DQN 为代表的强化学习技术依赖回报信号作为反馈进行模型训练。这意味着一个极高维度的神经网络模型只能依赖于极度稀疏的反馈进行训练。这一特点与现代军事对抗仿真本身具有的极高维度的状态空间和动作,以及动作参数空间的叠加使得模型的训练效率和收敛速度成为一个极大的挑战。
在GAN 框架下,针对强化学习取得了进一步发展[9-10],考虑从专家行为数据中学习策略,提出了一种新的生成对抗模仿学习通用框架,用于直接从数据中提取策略,并证明了该框架的某些实例化将模仿学习与GAN 进行了类比,由此导出了一种无模型的模仿学习算法,该算法在模拟大型、高维环境中的复杂行为方面比现有的无模型方法获得了显著的性能提升。
借鉴这一思路,可以采用GAN 作为通用框架,结合DQN 强化学习模型,对多智能体军事对抗仿真模型进行初始模仿训练,从专家行为回放数据中直接学习智能体行动策略。其中,GAN 作为通用框架,其判别器网络对多智能体仿真模型以及专家回放产生的行动策略相似性进行判别,这一判别结果作为多智能体强化学习模型的反馈信号对其进行训练。由于GAN 的对抗训练技术,且解决了强化学习的稀疏回报问题,仿真模型的训练效率可以得到显著提升。此外,采用这种方法得到的多智能体模型可以进一步使用强化学习技术,利用更高水平的人机对抗或自对弈等方式得到的数据进行优化训练,达到更高的智能水平。
本文探讨采用GAN 通用框架,构建红军事对抗的多智能体模型,并进行了仿真计算,验证了GAN 方法在多智能体军事对抗仿真建模的可行性。
1 多智能体GAN 建模方法
1.1 总体技术框架
为了快速建立具有高度智能的神经网络对抗策略,首先采用生成对抗网络技术,利用已有的高水平对抗回放数据,对策略神经网络进行快速优化,使其能够模仿这些回放中采用的对抗策略,达到同等智能水平。所需回放数据可以由高水平人类玩家手动操作产生,或由专业技术人员编写的已经经过高度优化的自动化对抗规则程序产生,只需要通过仿真引擎保存对抗回放记录即可,无需额外的人工标记处理。所产生的表演者神经网络可以直接用于智能对抗仿真,也可以通过强化学习技术进行进一步优化改进达到更高的智能水平,多智能体GAN 建模总体技术框架如下页图1 所示。

图1 多智能体GAN 建模总体框架
1.2 GAN 鉴别网络和表演者网络构成
生成对抗网络由判别网络D和表演者网络A组成。其中,判别网络D对输入对抗数据进行分类,输出0~1 之间的标量值判定输入数据是否符合演示对抗策略,0 为完全符合,1 为完全不符合,因此,判别网络D的优化目标是尽可能对所有数据进行准确判别。表演者网络A读取对抗态势(环境)数据,产生在这种态势下应采取的对抗命令,表演者网络A的目标是尽可能准确地模仿演示对抗策略,也意味着尽可能欺骗判别网络D使其无法区分对抗数据是来由演示玩家产生还是由表演者网络产生。因此,判别网络D和表演者网络A形成对抗关系,对这两个网络的交替训练,当这两个网络达到平衡时,判别网络D以接近同等概率对演示对抗数据和表演者网络产生的对抗数据进行判别(即无法有效分辨二者的差别,理想情况下期望该值为0.5,意味着判别网络完全无法分辨),此时表演者网络A学到了接近于演示玩家的对抗策略。
首先需要从仿真引擎获取多轮演示对抗回放数据保存在回放缓存中。回放缓存中的每个样本点为一个对抗步骤数据,包括联合对抗态势S和演示者对抗命令列表a,演示对抗回放采集及数据结构如图2 所示。
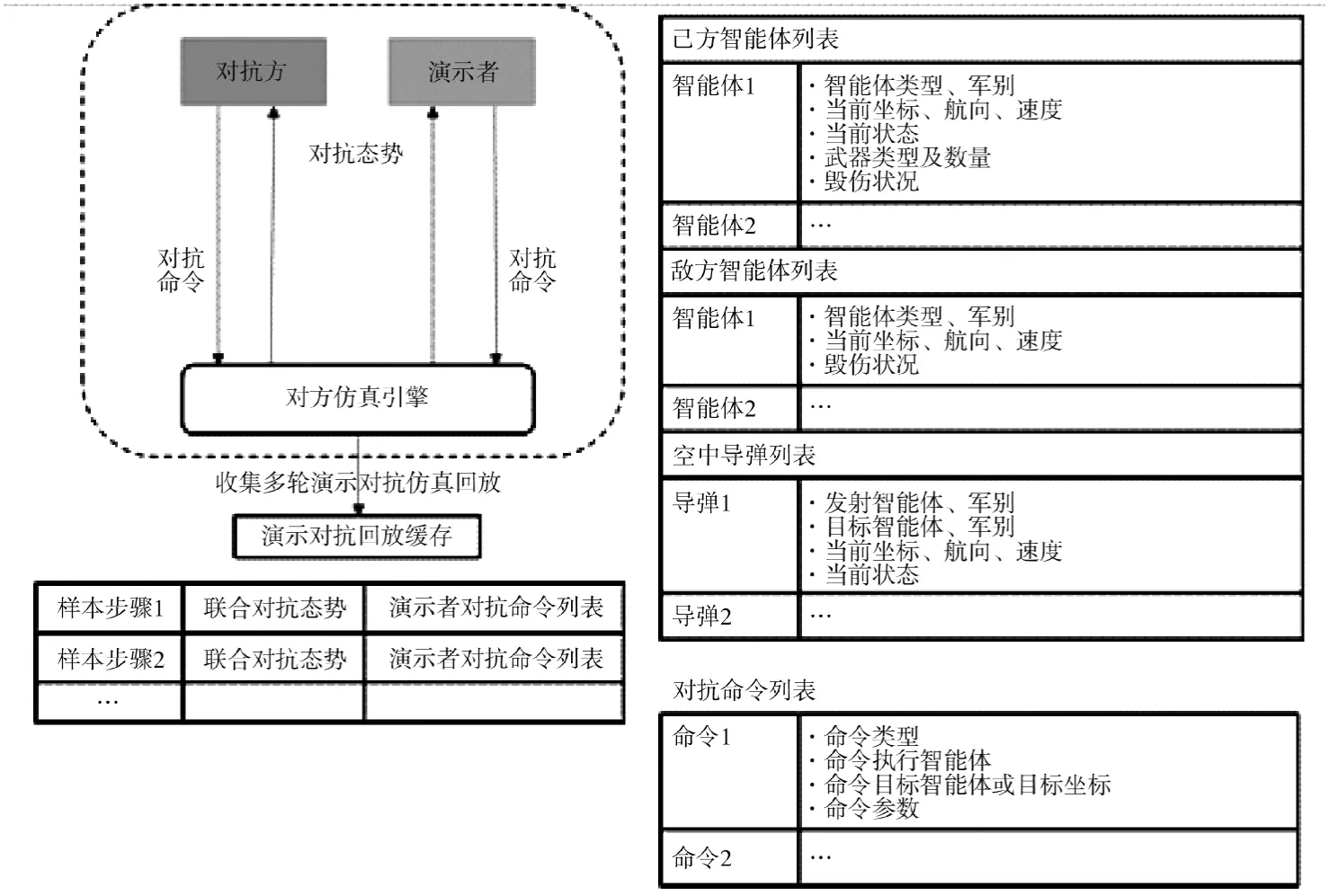
图2 演示对抗回放采集及数据结构
1.3 损失函数的构造
采集到回放数据以后即可采用生成对抗网络技术对判别网络D和表演者网络A进行对轮交替训练,使表演者网络A学习到演示者采用的对抗策略。训练过程如下页图3 所示。
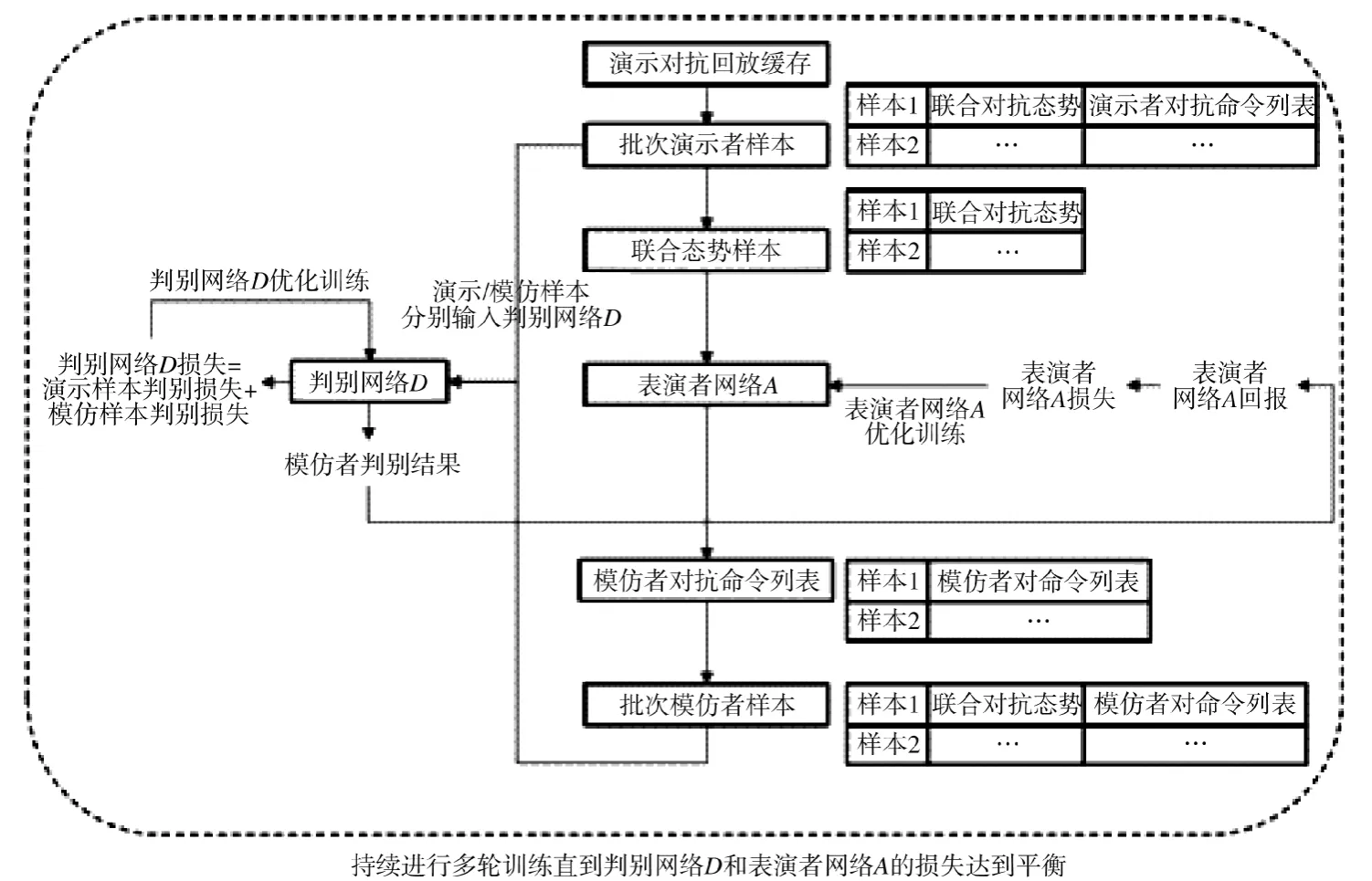
图3 GAN 对抗训练算法流程
其中,判别网络D的损失为演示样本与模仿样本的判别损失总和:

演示样本判别损失Dloss-expert和Dloss-learner分别为判别网络D对演示样本和模仿样本的实际输出与预期输出的交叉熵。演示样本应被判别为完全符合演示对抗策略,因此,预期输出应为0;模仿样本应被判别为完全不符合演示对抗策略,因此,预期输出应为1。
交叉熵BCELoss[10]计算公式如下:
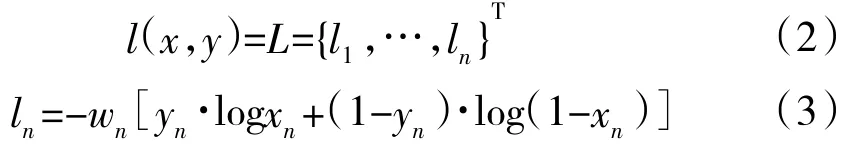
因此,判别网络D损失计算函数为:
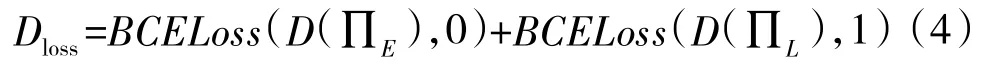
其中,∏E为演示样本,∏L为模仿样本。
判别网络D的优化目标是最小化总体判别损失。判别网络D是典型的二元分类神经网络,输入为联合对抗态势+对抗命令列表的张量编码,输出为0~1 二元分类标量,其网络结构和网络规模可以考虑输入数据特点进行选择,通常可以采用例如卷积网络CNN 或多层感知机MLP 等,参数维度和网络深度可以根据输入数据属性的数目和关联关系复杂性进行调整选择。
表演者网络A的结构设计与强化学习中表演者网络设计类似,可以根据输入输出特点选择卷积网络CNN 或多层感知机MLP 等进行构造,输入输出维度以及网络深度等参数需要考虑仿真数据特点进行选择调整。不同种类的Agent,以下标i表示,同一种类的Agent 有不同的数量,以下标j表示。
表演者网络A的回报计算公式:
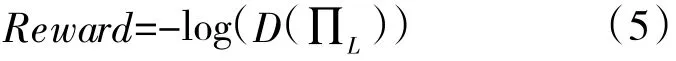
表演者网络A的优化目标是最大化回报。
表演者网络A的损失计算函数:
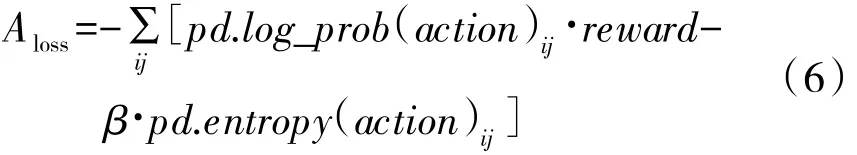
其中,pd为由表演者网络A输出的参数构造的对抗命令参数概率分布,pd采用的概率分布类型可以根据参数特点进行选择,对离散参数例如命令类型可以采用Categorical[11]分布等,对连续参数例如坐标点x,y可以采用Normal 分布等。action 为从构造的概率分布取样获得的命令参数取值。log_prob 为概率分布在action 取值的样本点的log 概率密度,entropy[11]为概率分布的熵。β为超参数,控制最大熵目标在表演者网络损失中的占比,在训练时根据训练状况进行调整。
表演者网络A类似强化学习中的表演者网络,其输入为联合对抗态势的张量编码,输出为可用于构造对抗命令列表的概率分布参数。自动化对抗程序将根据表演者网络A的输出构造对抗命令参数概率分布pd,从pd取样获取对抗命令参数,最后按照对抗仿真引擎所需的接口格式,转换为对抗命令列表输入到对抗仿真引擎。
2 仿真平台设置
本文以中央军委装备发展部主办的2020 全国“谋略方寸,联合智胜”联合作战智能博弈挑战赛[12]提供的仿真环境为应用场景,在此基础上,基于生成对抗网络建立多智能体对抗仿真模型,并对模型进行训练和测试。
2.1 对抗场景
蓝方目标(防守方):依托地面、海面和空中立体防空火力,守卫己方岛屿2 个指挥所重点目标。红方目标(进攻方):综合运用海空突击和支援保障力量,突破蓝方防空体系,摧毁蓝方2 个指挥所重点目标。双方对抗单局仿真时间为2.5 h,实现目标的一方得分。如果红方在仿真时长内仅摧毁蓝方的1 个指挥所,则有相应的计分方法计算各自的剩余兵力,多者胜。
2.2 仿真环境
仿真引擎以容器的形式运行,通过容器的虚拟端口进行调用。各装备底层控制律由仿真引擎操作,仿真环境接口仅提供高级命令语法包括命令种类和命令参数。例如战斗机的攻击指令,包括攻击战斗机的ID和被攻击空中目标的ID;轰炸机的定点攻击指令包括攻击轰炸机的ID、被攻击地面目标的ID、攻击角度的攻击距离。各Agent 的控制律、攻击毁伤概率等为黑盒。
仿真环境的对战调度程序[11]如下页图4 所示,仿真环境提供Python 语言开发的对战流程控制,参与者负责开发的程序为图中“决策并下发指令”,而作为制定决策的输入为“获取态势”。获取的态势主要包括3 个方面的信息,一为己方信息,包括各agent 的种类、空间位置和速度信息、载弹量和燃油量信息、毁伤状态信息等;二为对方信息,仅提供战争迷雾可视范围内的敌方Agent 种类、空间位置和速度等信息;三为导弹信息,包括双方发射导弹的种类、发射装备、攻击目标、速度等信息。
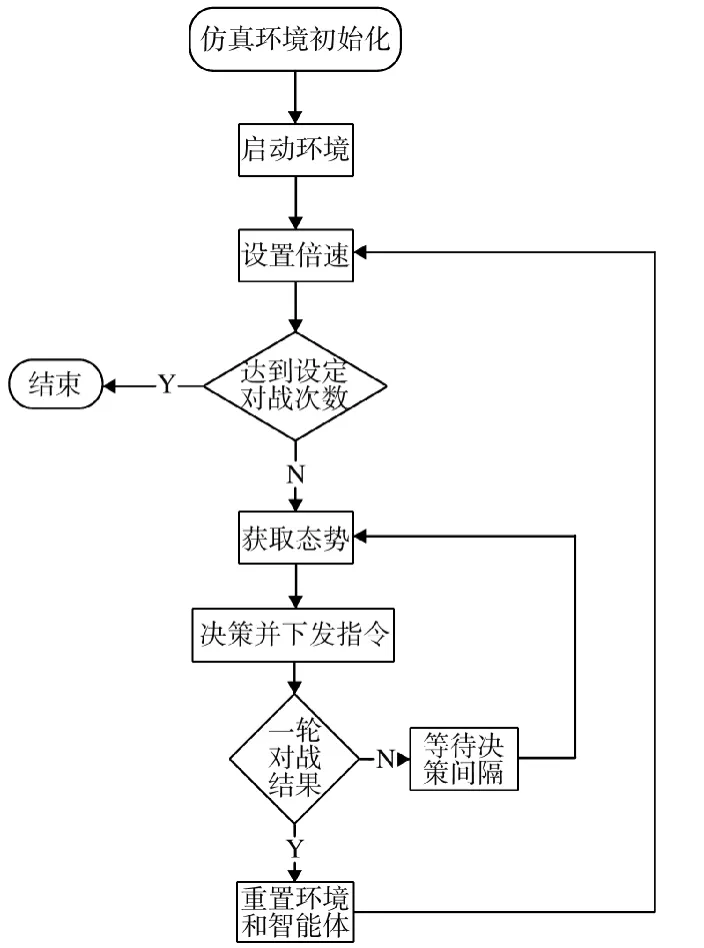
图4 仿真环境对战调度程序
2.3 仿真模型
本文以仿真平台提供的Python 语言开发框架为基础开发仿真模型。仿真模型中战场环境模型,对战参与方数量,每个参与方的Agent 组成,每个Agent 的行为能力,Agent 的探测、通信、攻击和毁伤效果计算均由仿真引擎控制,并通过Python 语言仿真调度框架进行调度,调度框架在每个时间步骤向参与者提供的智能体决策程序提供态势数据并获取决策程序返回的对战指令列表作为输入。
仿真模型的战场环境为350 km×350 km 的对抗空间。战场中心为坐标原点,向右为x轴正轴,向上为y轴正轴,红方岛屿机场坐标为(146 700 m,-3 000 m),蓝方北部岛屿指挥所坐标为(-129 532m,87 667m),蓝方南部岛屿指挥所坐标为(-131 154m,-87 888m),对抗地图[12]如图5 所示。
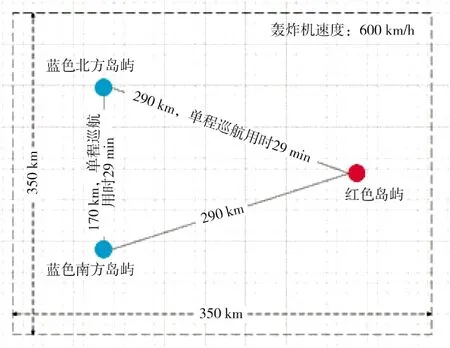
图5 红蓝双方对抗地图
仿真模型中对抗双方的Agent 组成即双方对抗兵力组成如表1 所示。
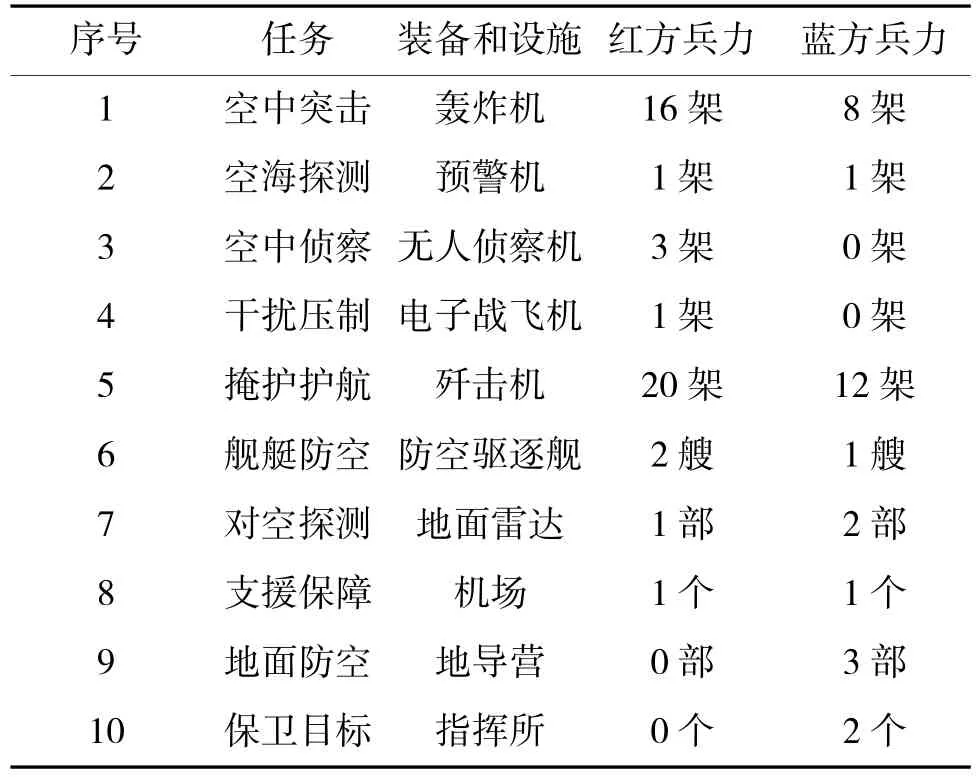
表1 红蓝双方对抗兵力
对抗双方相同类型的Agent 具有完全相同的行为模型。每种类型的Agent 能够接受的指令及每个指令的参数可以参考仿真平台提供的开发白皮书。
探测模型采用战争迷雾设置,即每种类型的Agent 具有一定的发现和识别范围,只有进入Agent发现范围的敌方Agent 才会出现在己方情报信息列表中,标记为“未知”状态;只有进入Agent 识别范围的敌方Agent 才会在己方情报列表中具有明确识别的军别和详细状态信息。其中,电子战飞机对探测模型具有特殊影响,仿真模型中的电子战飞机设定为阻塞模式,即当电子战飞机开启干扰时其干扰范围内的Agent 对对抗双方均处于不可见状态。探测状态由仿真引擎根据Agent 状态进行自动计算,决策程序不需要显示发送探测或识别指令。
仿真模型中Agent 之间的通信为己方完全通信模式,即己方所有Agent 之间的信息完全自动共享。
双方的攻击手段为发射导弹,其中的战斗机发射空空导弹、轰炸机发射空地导弹、驱逐舰发射舰空导弹、地导营发射地空导弹。仿真模型中每个Agent 的攻击指令发出后攻击成功的概率由仿真引擎控制,对参与者不可见,参与者无法干预。每种类型的Agent 携带的攻击武器类型,武器数量和攻击能力各不相同,其模型由仿真引擎控制。每种类型的Agent 受到攻击后的毁伤程度,对Agent 作战能力的影响各不相同,由仿真引擎控制。
3 实例仿真建模与分析
3.1 GAN 模型构建
为简单起见,主要介绍红方模型的构建,编程语言框架为Pytorch。首先构建判别器D神经网络模型,采用全连接线性模型,输入量为联合态势与联合动作拼接成的向量,输出为0~1 之间的标量,表示Agent 行为符合演示对战策略的概率,0 表示完全符合,1 表示完全不符合,中间层由全连接线性网络和双线性网络组合后构成。联合态势由己方态势、敌方态势以及导弹态势构成,判别器网络的输入数据结构如表2 所示,表中的Nb为批样本数量、Ns为己方Agent 数量、Nt为敌方Agent 数量、Nm为发射的导弹数量、Nc为己方Agent 动作命令数量。为了确保神经网络在训练时不发生崩溃,对于所有的网络输入数据均进行归一化处理,并且对于取值为0 的数据填充为ε小量。

表2 判别器网络输入数据结构
判别器网络主要有两路通道,其中一路是将多Agent 的己方态势和导弹态势数据拼接后输入一个双线性网络,敌方态势数据输入另一个双线性网络,两者的输出经过拼接后再经过一个双线性网络;另一路是动作命令信息经过全连接线性网络输出后与第1 路输出拼接,在经过一个全连接线性网络最后输出为1 维。判别器网络结构如图6 所示。网络损失函数的设置参照式(4),优化方法为Adam。

图6 判别器网络结构
在表演者网络的构造中,同一类型的Agent 共享相同的神经网络参数,采用全连接线性网络结构,网络输入为联合态势,网络输出为动作命令,表演者网络结构如图7 所示。网络输出根据动作命令类型进行随机采样,其中,分类指令参数如攻击ID号等的采样器为Categorical,连续指令参数如攻击距离等的采样器为Normal。表演者网络的损失函数如式(6)所示,优化方法为Adam。
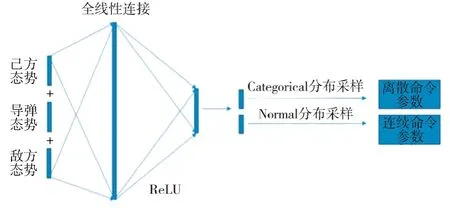
图7 表演者网络结构
3.2 演示者数据的产生
为进行GAN 训练,需要输入演示者数据。在仿真平台未提供相关对抗的历史数据的情况下,通过编写红蓝双方的规则对抗模型,并进行多局对抗的方式来记录数据,记录的数据即包括红方联合态势数据也包括红方动作命令数据。共选取红蓝对抗的50 轮次对战样本,平均轮次约300 个采样点数据。统计规则模型红方胜率为0.84。规则对抗模型的主要设计规则为:
红方Agent 规则:
1)两艘防空驱逐舰分别初始化在红方岛屿与蓝方两个岛连线与中轴线交点处,对进入舰载防空导弹射程(100 km)内的蓝方目标进行无差别攻击;
2)战斗机以密集队形在初始3 min 内起飞,在蓝方岛屿附近对空中目标进行跟踪,并派遣距离最近的战斗机进行一对一拦截;
3)预警机以自我保全为优先任务,在敌方射程之外前提下并尽可能靠近敌方岛屿侦查;
4)轰炸机编队以南岛指挥所至北岛指挥所的顺序进行攻击,攻击距离80 km,根据与目标相对位置计算攻击角度;
5)电子战飞机跟随轰炸机编队进行干扰;
6)一旦探测到攻击的导弹后,被攻击飞机暂时中断任务进行规避操作直到威胁解除,规避方向为距离最近的攻击导弹的反方向。
蓝方Agent 规则:
1)防空驱逐舰随机初始化在己方两个岛附近,对进入舰载防空导弹射程(100 km)内的蓝方目标进行无差别攻击;
2)战斗机以密集队形在初始3 min 内起飞,在南岛和北岛之间的预设空域进行巡航,对发现的空中目标派遣距离最近的战斗机进行一对一拦截;
3)预警机以自我保全为优先任务,在敌方射程之外前提下扩大侦查范围;
4)轰炸机编队以最近的红方驱逐舰为目标进行攻击,攻击距离80 km,根据与目标相对位置计算攻击角度;
5)飞机的导弹规避算法与红方相同。
3.3 模型的训练
按上节的规则模型,产生演示者数据。考虑到规则模型中通常一个动作命令会控制Agent 多步骤的行为直到Agent 接受另一个动作命令,对命令转换前的空白动作命令进行了填充。将处理好的演示者数据存入回放数据文件供GAN 模型训练。
表演者网络模型训练的时候,按照批样本数量为500 从回放数据文件中进行随机取样。根据采样得到的联合态势数据,运行表演者网络,根据网络输出进行随机采样后,生成表演者动作列表,将该动作列表与输入的联合态势进行组合,生成模仿样本数据,同时记录抽样概率log_prob和entropy。
判别器网络模型训练时,回放数据文件中的联合态势和相应的动作命令,组合成为演示样本数据输入到判别器网络,计算演示样本的损失函数;模仿样本数据输入到判别器网络,计算模仿样本的损失函数,总损失函数如式(4)所示。训练进行了256 轮次,得到的网络性能统计曲线如图8 所示。从图中可以看出,在80 轮次左右,回报值达到极值,此时表演者网络的损失函数达到极小值,而演示样本和模仿样本的鉴别率达到稳定值。训练过了80 轮次之后,回报值开始下降而表演者网络的损失函数进入震荡区间,显示网络进入了过拟合阶段,分析原因主要是用于训练的回放数据只选用固定的一组规则模型进行对抗的原因,在对抗模式上缺少多样性。
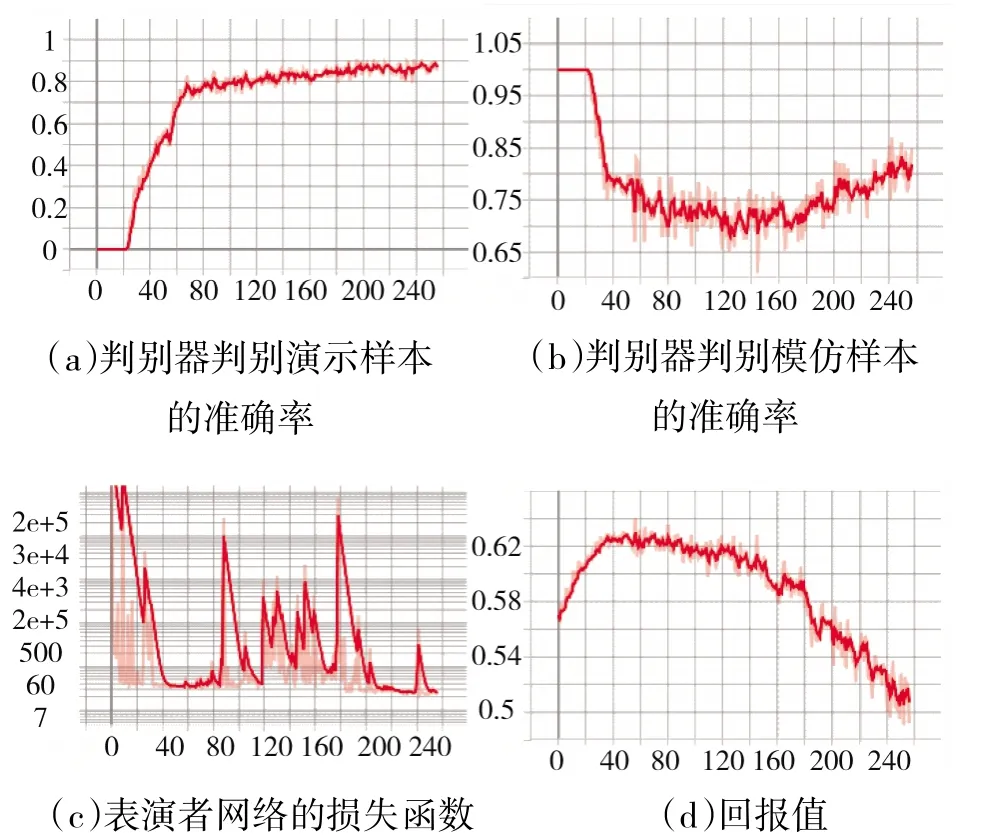
图8 网络训练性能统计曲线
3.4 模型的测试
选取80 轮次训练量得到的表演者网络模型与产生回放数据的蓝方规则模型进行对局,得到红方胜率为0.86,表演者网络的作战效能达到了所模仿的红方规则模型。
另外,为了测试GAN 建模学习效率,红方建立图7 所示的神经模型,并随机初始化网络参数,按照DQN 的框架与蓝方的规则模型进行训练。由于状态空间和动作空间数量巨大,模型难以快速收敛,在5 000 轮次学习后,红方DQN 模型的胜率约为0.5,学习速率已变得平缓。主要表现在红方轰炸机的攻击距离和攻击角度等参数未得到好的优化,攻击效率较差。
4 结论
本文借鉴GAN 建模方法,在2020 全国“谋略方寸,联合智胜”联合作战仿真环境上进行了多智能体强对抗神经网络建模。利用规则模型产生的回放数据进行网络模型的训练,对网络模型的学习特性进行了分析。通过模型的测试,显示出基于生成对抗网络的多智能体对抗仿真建模方法具有较高的学习效率,未来在体系对抗快速建模和建立假想敌仿真模型方面具有实用价值。
