基于Paxos的分布式一致性算法应用研究
2022-03-19刘克礼张文盛
刘克礼,张文盛
(安徽开放大学,合肥 230022)
一、引言
Paxos是解决分布式一致性的核心算法[1]。Tushar Chandra在Paxosmadelive[2]中提出Paxos从理论到实现之间有较大的鸿沟,实现一个Paxos往往需要对Paxos的经典理论做一些扩展[3]。目前针对Paxos的研究,除了降低理解难度,使用形式化的方法证明外[4],更多的研究是进行优化,以提高性能和便于实践中应用。这方面已经有很多应用的实例,如Google的Chubby[5],Tencent的PhxPaxos[6],Alibaba的X-Paxos等。作为应用研究成果的MultiPaxos,引入了实例和选主[7]。Raft也是一个分布一致性算法,其优点是易实现,对Paxos的应用有借鉴意义[8]。Lampson[9]分析了Paxos算法在工程领域实践中遇到的问题和经验教训。Tecent[10]详细地研究了实现PhxPaxos中存在的问题,并给出解决方法。现有的Paxos应用研究中存在选主和成员变更较复杂,难以实现的问题,本文对此进行梳理,并提出两条优化措施。
二、Paxos的实现要点及优化
(一)选主和配置变更
1.Paxos中节点间的通信
Paxos应用的一个重要设计是将Proposer、Acceptor、Learner、SM(State Machine,状态机)融合在一个节点中,通常是同一个进程,其中Proposer、Acceptor和Learner使用线程实现。这样做的好处是所有节点都是对等和对称的,可以降低复杂度。此外Proposer、Acceptor和Learner之间可以共享数据,能够执行一些优化措施,提高系统性能。为了保证提案编号唯一,所有节点都要按顺序进行编号,确保编号唯一。
Paxos是针对异步通信环境而设计的,在算法实现过程中存在通信协议的选择。UDP协议属于典型的异步通信,支持多播和广播,可以减少发送的消息数量,适合Paxos应用。TCP协议能够消除异步消息的各种问题,如通过超时重传解决丢失和延迟,通过序号解决乱序和重复的问题。使用TCP协议降低了编程难度,例如ZooKeeper[11]就是使用了TCP协议。
2.Paxos中的实例
Paxos算法只能确定一个值,但在实际应用中,需要确定多个值,并且这些值是有序的,形成值序列。各个节点都维持一个状态机,状态机的初始状态一致。各个节点将相同值序列输入本地状态机,最终得到的状态机仍然一致,从而实现一致性和高可用性。多次执行Paxos算法,就可以确定多个值。
相同节点的集合,可以先执行一次Paxos算法,直到值V1确定,保存该值和相关状态,然后再初始化Paxos算法,重新执行,直到值V2确定,依次进行下去。每个Paxos算法的执行被称为一个实例(Instance),并被编号,这种方法称为MultiPaxos。由于后面的选主和配置变更也要用到Paxos,为了方便区分,记确定应用相关值的Paxos为MP(V),实例i确定的值记为MP(V,i),执行MP(V)时产生的消息称为应用消息。实例和值按实例号顺序组织,一般称为日志。
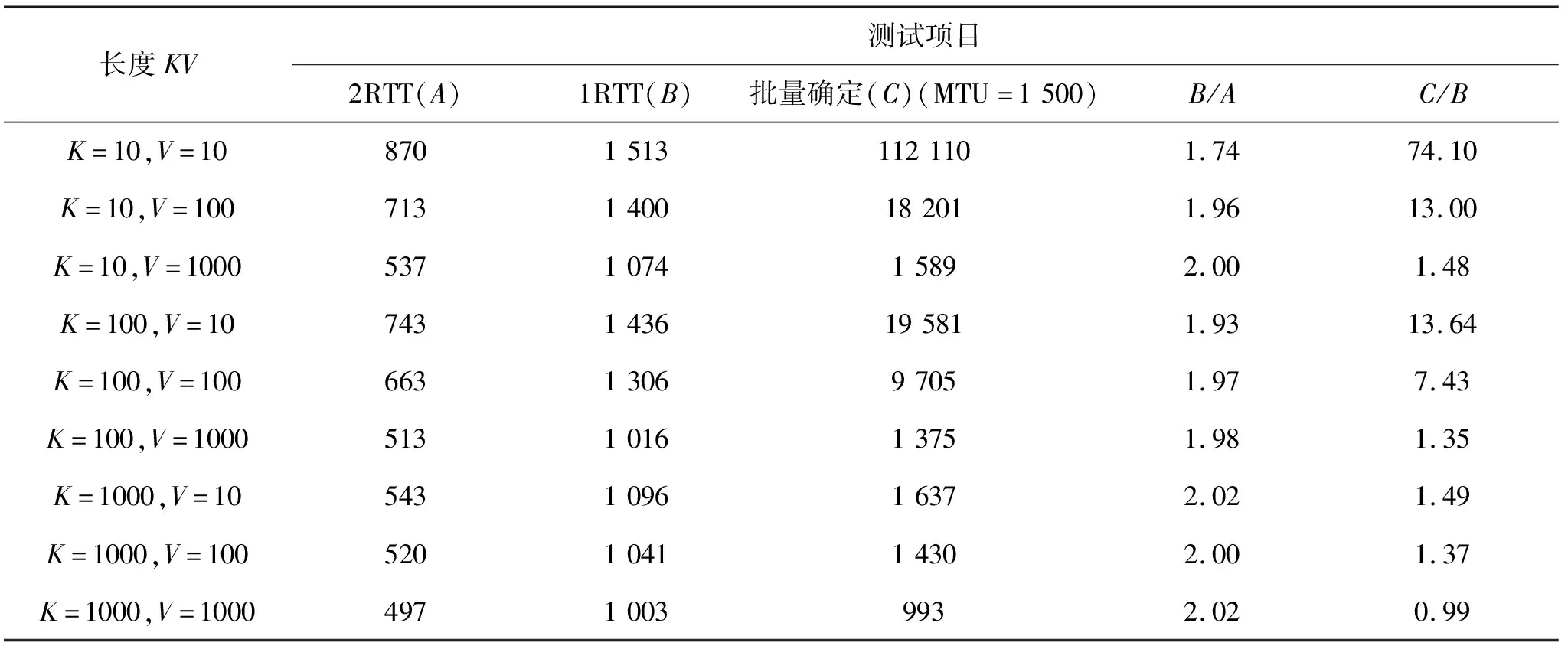
各个实例之间的执行关系有两种:顺序和乱序。现有实例号i和j,顺序是指当i 3.Paxos中的选主过程 Paxos算法因为Proposer竞争导致确定值可能要很长时间,甚至存在活锁问题,一般通过选主(Leader)来解决。在所有Proposer中选出一个Leader,其他Proposer的请求都发给Leader,由Leader发起提案。Leader消除了锁竞争,可以迅速确定值,其缺点就是可能存在单点故障。 Leader也是一种共识,为了达成共识,选主也使用Paxos算法。当Leader因为某种原因失效后,需要重新选主。记用于选主的MultiPaxos为MP(L),执行MP(L)产生的消息称为选主消息。选主状态机很简单,只有一个变量,就是当前主(curLeader)。MP(L)在第二阶段选择提案值的时候,如果没有值可选,可将自己作为提案中的值。一开始所有的节点都无主,所有的节点都开始执行选主过程(假设实例号为1),若最终节点a胜出,那么实例1的值就是a,记为MP(L,1)=a,并设置到各个节点curLeader,此后其他节点将请求转发给节点a。产生主的实例号一般称为代或任期(term),当主失效后,任期增加。MP(L)形成的日志称为选主日志。假设当前任期是l,有主的MP(V,i)扩展记为MP(V,i,l)。在应用消息中携带任期,节点可检测主是否切换,如果切换,那么先要执行选主日志同步操作。 选主过程如图1所示。 图1 选主过程 为了维持a不失效,a需要定期向其他节点发送存活消息,其他节点也可以向节点a定期发送探测消息,此外其他节点向a转发请求时也可以看成附带的探测。当超过一定时间没有收到存活消息,或发送几次探测消息没有响应,或转发几次相同的请求都没有响应时,在这三种情况下都可以认定a失效,并设置变量validCurLeader为NULL。 认定a失效的节点b开始执行定时探测,向其他节点发送消息,询问其当前的validCurLeader,其他节点返回当前实例号和validCurLeader。如果当前实例号相同,且过半节点(包括b)的validCurLeader为NULL,则b开始执行MP(L,2)。等待过半节点的validCurLeader为NULL实质是一个同步的过程,是触发选主的必要条件。 如果a真的宕机了,那么其他节点将几乎同时认定a失效,并几乎同时启动MP(L,2)的执行。发现选主成功的节点(例如c)会通知其他节点当前主是谁(例如d),d在确认自己当选主之后,开始发送存活消息,而其他节点在同步选主日志后将curLeader和validCurLeader都设置为d。 认定a失效并不等于a真的失效,例如分区导致节点b在一个少数分区C中,而该分区不包括a。当C重新加入主分区,b经过几轮探测发现,当前任期相同,且过半节点的validCurLeader仍然是a,则重新设置本地validCurLeader=a。如果任期不同,那么要先执行同步操作。 当节点b认定主a失效后(validCurLeader=NULL),将不再转发应用消息给a,也不再处理a的任何应用消息,直到新的主产生。 4.成员和配置变更 运行Paxos算法需要知道系统的配置,至少包括各个节点的信息(IP和端口),记为集合CC。各个节点上的配置必须一致,且默认情况下配置固定不变。但在实际应用中,为了应对多变的环境和需求,要求系统是可配置的和可伸缩的。 配置的变更需要所有节点参与。如果只有部分节点参与,将会导致配置不一致,从而各个节点看到的节点数n是不一致的,这样会影响Quorum的计算,从而使得Paxos算法执行产生混乱。配置也是一种共识,因此配置的变更也适用Paxos算法,记为MP(C,i),配置的状态机就是集合CC。为了解决执行MP(C,i)后可能有部分节点不知配置已变更的问题,在节点向Leader发送消息时,携带本地当前配置的实例号(也称为版本)。如果Leader的当前配置版本大于收到消息中的配置版本,立即返回错误,指示节点先同步配置。配置变更一般都是管理员手动进行,管理员在确认所有节点都正常运行后,才会执行变更,因此MP(C,i)都能执行成功。 配置的变更有很多种组合:增加一个节点,删除一个节点,增加多个节点,删除多个节点,同时增加和删除多个节点。只考虑删除一个节点(DeleteNode)和增加一个节点(Add Node)两种基本操作,其他组合都可以分解成这两种基本操作。 MP(C,i)执行完成并应用到状态机CC后,如果是DeleteNode,则判断节点值是否是自己,如果是的话,则退出;如果节点值是主节点,则各个节点将validCurLeader设置为NULL,并立即启动选主过程,不必等待超时;如果是AddNode,Leader会主动通知新节点成功加入,此后新节点可以参与后续的各种消息处理。 5.三个MultiPaxos的关系 上述三个一致性协议的执行对比如表1所示。 表1 三个MultiPaxos比较 选主和配置变更,都会影响业务处理。配置变更可能会触发选主,而选主不会影响配置。只有选主是通过竞争确定值,执行过程不确定;而配置变更和业务处理都是在有主的情况下进行的,可以迅速确定值。当无主时,配置和业务处理暂停执行,直到新主选出,因此三个MultiPaxos只能交替运行。 1.Paxos中的日志和快照 在执行Paxos协议过程中,Acceptor在accept阶段要持久化[mp,ap,av],记为plog,其中mp是收到的最大提案号,ap是接受提案的编号,av是接受提案的值。在MultiPaxos中的Leader在值确定后,要将实例号和值写入本地日志,记为mlog。然后Leader将值输入状态机,并把日志确定标志发给其他节点,其他节点也执行同样的动作,即写日志和输入状态机。由于每个节点都具有相同的结构,因此可以将plog和mlog合并,组成(i,s,mp,ap,av),记为mplog,其中i是实例号,s是值的状态。 节点重启后,从头执行mplog可恢复状态机。在日志量很少的情况下,该方法有效。但在日志量很大的情况下,一方面日志要占用大量磁盘空间,另一方面恢复状态机也需要更长的时间,在恢复期间节点不可用,这降低了系统可用性。为了减少日志量和加速状态机的重建,引入快照技术,定期导出状态机的当前状态,并删除之前的日志。节点重启后,直接从最新快照恢复状态机,然后执行增量日志,可以快速恢复服务。 导出快照时状态机不能执行任何改动,在数据量很大的情况下,可能需要较长时间。节点对外服务是基于状态机的,状态机的冻结降低了节点的可用性。一种称为COW(Copy On Write,写时复制)的技术解决了该问题。在准备生成快照时,父进程节点先克隆一个子进程,该子进程共享父进程的内存,父进程可以读写状态机,而子进程对状态机只读不写。父进程写状态机时操作系统会自动COW新的内存页,保证了父进程正常运行。子进程的状态机始终是克隆时的状态,可以从容导出快照,并在完成后退出。 2.节点间数据同步 新节点加入集群时,状态机为空,需要从其他节点同步状态,这与节点重启时遇到的问题类似。一种同步方法是从其他节点学习所有日志,从头执行,在日志很少的情况下这种方法是有效的。在日志数据多的情况下,一方面传输日志要占用大量带宽和时间,另一方面执行日志也会需要较长的时间,此时若业务请求频繁,就可能会出现故障。另一种同步方法是从其他节点导入最新快照,再同步增量日志。 在极端情况下,同步耗时较长且新日志增长迅速,此时采用并行操作能够让新节点迅速加入集群并提供服务。新节点加入集群的操作如下:一方面参与一致性协议的执行并记录新日志(开始日志编号记为y),但不输入状态机,另一方面通过旧日志或快照同步状态(截止日志编号记为x)。当状态机还原到x时,由于x≤y,新节点需要学习其他节点(x,y)间的日志,然后将x之后的日志输入状态机,直至最新日志执行完毕,此时新节点才算成功加入集群。为了降低Leader的压力,选择同步日志节点时将Leader排在最后。 3.读数据和读写保序 集群中的写操作需要通过一致性协议完成,读操作只要读取状态机中的数据。读有两种方式,一种是通过本地节点的状态机提供,称为本地读,另一种是读取Leader的状态机,称为全局读。本地读的优点是速度快,其缺点是不能保证读到最新数据。全局读的优点是可以读到最新的数据,其缺点是比较费时,增加了Leader的压力,且在集群发生分区时无法完成。 如果两个操作之间有因果关系,为了保证结果的正确性,需要对操作进行串化,或者是保序。如果两个操作之间没有因果关系,则可以乱序执行。操作通常只有两种方式:读和写。其中写操作是纯粹写,不包含自增类的写。两个操作共有三种组合:读读,读写,写写。两个操作的目标之间有三种关系:不相交,部分相交,相同。如果两个操作不相交,则可以乱序执行。通常很难判断操作是否相交,这种情况下,读写和写写都要保序,读读不需要保序。 当某个节点收到读操作后,为了保证因果关系,确保能读到最新的数据,需要将该节点之前的写操作全部提交到日志中,写操作写入状态机后,才允许执行读操作。 同一个节点上的写操作按接收的顺序保序提交,普通节点再保序提交到Leader,Leader保序执行一致性协议,日志按顺序执行。 Leader可以让提案迅速通过,最少需要2RTT(Round Trip Time)。通过分析Paxos的两阶段(Prepare和Accept),可以发现Prepare的目的是抢占锁和选择值,Accept的目的是验证锁并提交值。因为Leader的存在,锁竞争已经成为小概率事件,所以Prepare可以省略,直接跳转至Accept阶段。省略Prepare后,MP(V)只需要1RTT就可完成,系统性能可以提高1倍。 省略Prepare需要满足条件,即不能违反Paxos值不变性约束。分析如下:在Leader发出promise消息时,此时值还未确定,假设该promise的提案编号P是1,而每个实例的初始P是0,在(0,1)之间没有其他提案,则promise安全。在新旧Leader交替时,存在如下情况,即旧Leader发送提案[1,V1]被某个节点接收后,因某种原因旧Leader宕机,假设此时新Leader生成[2,V2]提案,如果V1不等于V2,那么在新Leader完成Accept后,不变性约束就被破坏。为了限制上一个Leader造成的影响,将任期信息附加到P上,新的提案编号为(term,P)。如果promise消息中的任期小于当前任期,提案将被拒绝。 通常情况下MP(V)一次可确定一个值,也可以同时确定多个值,即同时确定编号分别是i,i+1,i+2,...,i+n的实例,这样的批量确定可以使系统性能得到提升。当然也不能无限增加同时确定的实例个数,受网络传输数据包大小限制,当数据包超过最大传输单元时就会发生分片和重组,由此导致的开销和不确定性会抵消性能的优化。批量确定只能串行操作,在前一个批量确定完成后,才能执行下一个批量的确定,这样就不会产生大量日志空洞。 在所有的一致性实现当中,一致性KV(Key Value,键值对)数据库是最简单的。根据上述分析,使用Python实现一致性KV数据库,并进行测试。实验环境采用3个节点的虚拟机,配置为4CPU AMD Opteron(tm)Processor 6376,4G内存,50G硬盘,1G网卡。测试项目包括2RTT吞吐量,1RTT吞吐量,批量确定吞吐量。结果如表2所示,单位为RPS(Request Per Second)。 表2 一致性KV数据库吞吐量测试 Request Per Second 表2中K=10指Key的长度是10字节,V=10指值的长度是10字节,余类推。A指代2RTT列数据,B指代1RTT列数据,C指代批量确定列数据。B/A指B列除以A列的值,显示将2RTT优化为1RTT后系统吞吐量提升效果。C/B指C列除以B列的值,显示将1RTT优化为批量确定后系统吞吐量提升效果。根据表2可知,2RRT比1RTT吞吐量大将近1倍,而批量确定的吞吐量比1RTT又大若干倍,优化效果明显。 详细分析Paxos应用过程中可能遇到的问题,讨论了常规的通信、实例、日志、同步等,就选主和成员变更提出了轻量级的算法,将选主、配置和应用三个一致性协议进行有机组合,互相配合,确保系统稳定、可靠和易用。为了保证结果的正确性,研究分析了读写保序问题,并给出一般准则。最后讨论了性能优化措施,将2RTT缩减到1RTT,再到批量确定。结果表明,该设计能够满足进一步研究和应用的需求。

(二)日志和数据同步
(三)性能优化措施
三、实验结果与分析
四、小结
