面向互联网舆情事件的企业风险识别
2022-03-13张志剑刘政昊马费成
张志剑 刘政昊 马费成



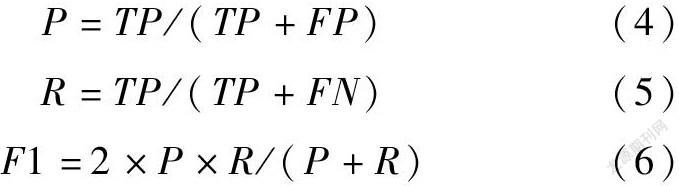


摘 要:信息智能时代背景下,互联网舆情信息对企业的影响愈加显著。有效准确地从舆情事件中识别风险有助于企业进行风险管理,实现良性运营。本文提出一种有效识别企业风险的模型KGANN,该模型使用知识图谱的结构和内容构造神经网络,实现知识图谱和神经网络的融合,从而提升模型风险识别能力。实验结果表明,在企业风险识别任务上所提方法相较于传统方法具有显著优势。同时根据知识的权重值对模型进行分析,得到股权结构复杂、司法案件较多、知识产权较少的企业风险等级较高。研究结果为企业和监管机构进行风险管理提供了重要的研究视角,对防范企业风险具有一定的参考价值。
关键词:互联网舆情;风险识别;风险事件;知识图谱;神经网络
中图分类号:F272.35 文献标识码:A 文章编号:2097-0145(2022)01-0065-09 doi:10.11847/fj.41.1.65
Abstract:Under the background of the information intelligence era, the impact of Internet public opinion information on enterprises is becoming more and more significant. Effectively and accurately identifying risks from public opinion events is helpful for enterprises to carry out risk management and realize benign operations. This paper proposes a model KGANN for effectively identifying enterprise risk. The model uses the structure and content of knowledge graph to construct a neural network to realize the integration of knowledge graph and neural network to improve the ability of model risk identification. The experimental results show that the proposed method has significant advantages over the traditional methods in enterprise risk identification. At the same time, the model is analyzed according to the weight value of knowledge. It is concluded that the enterprise with a complex ownership structure, more judicial cases, and less intellectual property rights has a higher risk level. The research results provide an essential research perspective for enterprises and regulators to carry out risk management and have a specific reference value for preventing enterprise risks.
Key words:internet public opinion; risk identification; risk events; knowledge graph; neural network
1 引言
近年來,随着经济全球化进程的不断加速,市场主体各要素间的关联性不断增强,金融系统的风险敞口也日益增大。在全球经济贸易互通互联、国内经济加速转型的特殊阶段,企业正处于创新发展与经济转型升级的关键时期,然而由于企业内外环境的不确定性、生产经营活动的高度复杂性和部分企业能力的有限性,导致各类风险因子高度集中,企业风险事件频发[1]。与此同时,互联网媒体的发展大大加快了各行业信息产生和传播速度,一些负面的互联网舆情事件的爆发与传播更是加剧了企业风险,给企业带来了巨大的财产损失和声誉损失。
习近平总书记在深圳经济特区建立40周年庆祝大会发表的重要讲话中强调,世界经济面临诸多复杂挑战,要统筹好发展和安全两件大事,增强自身竞争能力、开放监管能力、风险防控能力。企业全面风险管理是一项十分重要的工作,关系到资产的增值保值和企业持续、健康、稳定发展[2]。相关企业如果对互联网舆情事件处理不及时或不到位,将会面临资产负债和信用破产的风险,甚至直接影响到行业和社会经济的正常运行[3]。可见,识别重大风险因素对于企业及时发现风险根源、调整战略规划、实现良性运营和长足发展具有重要意义。企业应广泛且持续地收集与自身风险和风险管理相关的舆情信息[4],提高风险防范意识,并制定有效的风险识别和预警方案。
传统的企业风险识别研究主要采用案例分析方法[5~7],重点在于将人工定义的风险类型应用于个体风险的管理,但具有一定的主观因素,普适性较差。随着大数据、人工智能、云计算等新一代信息技术的发展和企业数字化转型加速的冲击,企业的经营决策与风险管理更加依赖对互联网新闻舆情等企业外部信息的智能化分析与处理。在面向企业风险的识别任务中,卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Network,RNN)和长短期记忆神经网络(Long Short-Term Memory,LSTM)等传统深度学习模型因推出时间较早,已在业界得到了广泛应用[8~10]。但由于传统深度学习模型融入知识的能力较差,导致模型可扩展性较差。为此,本文提出了一种知识图谱神经网络(Knowledge Graph Artificial Neural Network,KGANN),该模型能够更为有效识别互联网舆情事件下企业风险,KGANN模型结合了知识图谱模式层构建的基本原理,将知识图谱中的“知识”作为神经网络的一部分,实现了神经元与知识的有效融合,在风险识别任务中有着更好的表现,同时一定程度上增强了深度学习模型的可解释性。
2 文献综述
企业风险通常指未来的不确定性对企业实现其经营目标的影响,一般可分为战略风险、财务风险、市场风险、运营风险、法律风险等[11]。从企业管理的角度来看,风险源只是潜在的损失信号,而风险事件的发生则将其转化为了现实的损失[12]。企业风险管理是对企业内可能产生的各种风险进行识别、衡量、分析、评价,并适时采取及时有效的方法进行防范和控制,用经济合理的方法来综合处理风险,以实现最大安全保障的一种科学管理方法[13]。其中风险的识别是风险管理的前提与核心环节,主要指通过企业面临的尚未发生的潜在的各种风险进行系统的归类分析,从而加以认识与辨别的过程。
由于风险具有动态性、可变性和潜伏性,导致识别难度较高。如何采用有效的方法对企业风险进行准确识别一直是学者们关注的重点。除了传统的依赖人工感知、判断或归类的方式对现实的和潜在的风险性质进行鉴别的定性识别方法外[5~7],较为常见的企业风险识别方法还包括资产财务状况分析法[14]、分解分析法等量化分析方法[15]。近年来,随着大数据、人工智能等信息技术的发展,许多研究尝试借助机器学习和深度学习技术,从海量的相关数据中识别风险因素。Leng等[16]提出一种改进的加权下降的反向传播(Back Propagation,BP)算法,建立起反欺诈风险识别模型。Bose和Pal[17]使用支持向量机研究了风险预测问题。柳向东和李凤[18]利用随机森林模型建立了企业信用风险评估模型,并通过采样算法SMOTE改进模型。曹如中等[19]对企业竞争情报工作中出现的市场风险、生产风险、环境风险等进行了细致的总结和自动识别。黄世忠等[20]则在近期提出了碳中和背景下企业财务风险的识别框架。
近年来,网络科技发展迅猛,网络分析也逐渐成为风险识别研究的重要方法。Allen和Gale[21]首先将网络分析方法应用于系统性风险研究。Didimo等[22]通过建立决策支持系统,对企业关联交易的逃税行为进行检测。Yerashenia和Bolotov[23]基于语义数据分析原理,提出了一种企业智能破产风险预测计算模型,并构建了破产预测本体和语义分析图数据库系统。在此基础上,大规模语义网络——知识图谱也在风险识别与管理领域得到了初步应用。杨波和廖怡茗[24]针对风险的演化特性构建了面向风险事件的动态企业风险图谱。在图谱应用方面,Franco-Salvador等[25]对风险事件的关键特征进行了标注,并构建了企业风险知识库,而后借助Jena推理机完成了对风险信息的识别和推理。姜增明等[26]利用知识图谱和社交网络分析等手段,提高防范欺诈风险的效率。金磐石等[27]基于企业的关联图谱预测小微企业欺诈的可能性。王成和舒鹏飞[28]通过知识图谱的网络嵌入方法预测网络借贷中的欺诈行为。陶士贵和相瑞[29]建立了股权关系图谱,通过复杂股权关系路径算法,对企业相关风险进行预警。
结合国内外文献可以发现,定量化与智能化已成为企业风险识别与分析的趋势,但部分技术手段存在只能处理单一数据源、数据类型受限、数据组织方式存在割裂性等问题。知识图谱作为一种新生技术形态,能够将大量的金融数据进行关联融合,精准描述风险主体之间的关系,并根据分析结果及时做出风险识别和判断。当前利用知识图谱进行企业风险识别的研究依然较为有限,大多数研究仅仅关注企业风险知识图谱的构建和基于图谱的查询及预测,将其作为外部知识引入深度学习模型的思路尚不多见。另一方面,由于舆情数据具有体量大、多样性、碎片化、价值稀疏性等特点,目前的面向舆情事件的风险识别工作尚处于起步阶段,相关分析大多仍以事后风险监测为主要目的,利用计算机辅助舆情分析与信息抽取并结合人工校验,分析方式较为被动,导致风险识别和预警能力弱,具有较大的局限性。如何借助知识图谱和深度学习的方法,从风险事件的角度去识别与挖掘企业风险,让计算机能完全理解新闻舆情、赋能智能风控,仍然是一个挑战性课题。
3 企业风险识别框架
3.1 模型设计
为了帮助企业快速准确地从海量舆情信息中自动识别和获取风险预警信号,进而快速做出响应,降低企业损失。本文提出一种KGANN模型,该模型通过融合知识图谱的结构和内容,提高了从舆情信息中识别风险的效果。
基于KGANN的企业舆情事件风险识别框架共包含8个步骤。(1)构建企业风险本体库。该本体库由领域专家构建,包含企业基本信息、企业股权信息、企业财务信息和企业风险信息。(2)构建企业风险知识图谱。基于企业风险本体库,使用自顶向下的方式构建企业风险知识图谱。(3)知识图谱向量化。使用TransE方法[30]对知识图谱所包含知识进行训练,生成知识向量。(4)识别知识图谱结构。依据本体库的层次结构对知识图谱进行结构识别。(5)数据集预处理。去除“互联网舆情企业风险事件的识别和预警”比赛数据集无用字段并进行分词及去除停用词处理。(6)训练Word2vec模型。使用第五步生成的数据集训练Word2vec模型,利用该模型对语料进行向量化表示。(7)构建并训练神经网络模型。输入层负责接收向量化的语料,隐藏层的结构为第四步所提取出知识图谱的结构,隐藏层的“知识”即第三步生成的知识向量。全连接层将隐藏层的特征进行融合,得到融合特征向量,并将其缩放至适当的维度。最终识别层使用softmax函數将融合特征向量进行归一化表示,得到输入语料的风险类别概率。(8)风险识别及分析。保存训练过程中识别效果最好的模型,该模型可用于后续的风险识别。然后对模型的识别效果进行评估,并通过“知识”的权重对模型进行分析。
3.2 企业风险本体库与知识图谱构建
与传统神经网络模型不同,所提框架的隐藏层结构和内容由知识图谱决定。构建知识图谱有自底向上和自顶向下两种模式,自底向上的知识图谱构建方式通常为数据驱动,从公开的海量数据集中进行知识抽取,并选择其中置信度较高的知识存入知识图谱[31]。自顶向下的知识图谱构建方式通常需要构建本体库,使用本体库从高质量的结构化和半结构化数据进行知识抽取并存入知识图谱[32]。本体是知识图谱的模式层和逻辑基础,知识图谱是本体的实例化,本体研究的成果可以促进该领域知识图谱得到更快的发展和应用[33]。在使用KGANN模型时,需要考虑计算开销,小而精的知识图谱更加适合本框架。因此,使用自顶向下的方式来构建知识图谱。
企业风险本体库由领域专家构建。本体库共分为三层,第一层为企业基本信息、企业股权信息、企业财务信息和企业风险信息本体;第二层包含法人、登记状态、成立日期、所属地、所属行业、曾用名、参保人数、变更记录等;第三层包含控股股东、持有股份、投资比例、投资金额、案件金额、裁判结果等。
通过自顶向下的方式构建知识图谱,需要借助高质量的半结构化和结构化的数据,从中抽取符合本体结构的知识加入到知识图谱中。考虑到知识图谱应具有更高的可复用性和普适性,将沪深300指数和语料集包含的3527家企业纳入知识抽取范围。最后按照本体库在互联网上获取相关企业的具体数据,获取到2822394个三元组。
3.3 隐藏层神经元
隐藏层神经元由“神经网络”部分和“知识”部分组成,每部分都包含独立的权重系数,用来调节两个部分之间的重要程度。通过“知识”部分的权重系数,可以了解不同知识在训练过程中的重要程度。在训练过程中,与任务密切相关的知识权重系数绝对值会提高,此时神经元中“知识”部分起到更重要的作用。相反地,与任务相关程度低的知识权重系数绝对值会降低,此时神经元中“神经网络”部分更为重要。训练过程使用BP算法,降低了人工选择知识的难度,隐藏层神经元由两部分构成,如(1)式所示。
其中由“神经网络”部分生成的向量称为特征向量,使用nn表示。由“知识”部分生成的向量称为知识向量,使用kg表示。然后,将特征向量和知识向量进行拼接,得到高维的语义特征向量。该语义特征向量融合了语料的特征和领域先验知识,任务语料的语义信息得以更充分地表示。最后,神经元使用激活函数引入非线性因素,提高模型的学习能力和鲁棒性。具体的计算过程如图1所示。
其中xi表示第i个输入向量,WN表示特征向量的权重,bi表示特征向量的偏置,KGM表示知识矩阵,wk表示知识矩阵中每条知识的权重,WR表示转换矩阵,可以将输入向量和知识矩阵进行融合,并以适当维度输出。nn的计算方式如(2)式所示,kg的计算方式如(3)式所示
其中“神经网络”部分的计算过程参考了感知器的计算过程,Word2vec模型将输入语句转换为包含一定语义信息的向量xi,接着使用WN对输入向量进行加权处理,最后添加偏置因子bi,使模型表达能力更强。
其中KGM的每一行都代表一个知识,为了区分不同知识的重要程度,需要给每条知识赋予权重。此时的知识是按行存放,然而输入神经元时需要按列读取,因此需要将(wkKGM)转置。然后,需要计算输入向量和知识间的语义关联性,但是输入向量xi和知识矩阵KGM维度往往不匹配,无法直接进行计算。因此,需要引入转换矩阵WR做连接,将输入向量和知识矩阵进行融合后得到融合知识向量。
3.4 舆情文本向量化
常用的词向量模型为Word2vec模型和双向注意力机制编码器(Bidirectional Encoder Representations From Transformers,BERT)模型。2013年Mikolov等[34]提出Word2vec模型,由于其简单有效得到了广泛的应用。2018年Google的研究人员提出了BERT模型,该模型使用self-Attention机制进行特征提取,在多种自然语言处理任务中取得SOTA结果[35]。
BERT模型具有较强的特征提取能力,然而该模型的最大输入长度为512,去除[CLS]和[SEP]两个标签后,有效输入仅为510个字,因此难以处理长文本任务。为此,有研究人员提出截断法,将输入文本的起始部分和结尾部分作为模型输入,但是依旧难以覆盖完整语料;另一些研究人员提出将输入文本进行切分,分别输入BERT模型,最后使用注意力机制将多个输出进行融合。但是该方法生成向量的语义并不连续,效果难以达到预期;还有一部分研究人员提出扩大BERT模型的输入长度,虽然该方法可以更好地支持长文本的输入,但其计算成本也大幅提升,难以得到广泛的应用。
经统计,数据集中的每条正文平均包含1042个字,上述三种方法难以较好地应用于当前任务。因此,使用Word2vec模型作为框架的词向量模型。通过将训练集分词和去除停用词之后,使用Skip-gram方式训练Word2vec模型。
4 实验设置及分析
4.1 数据集与知识图谱
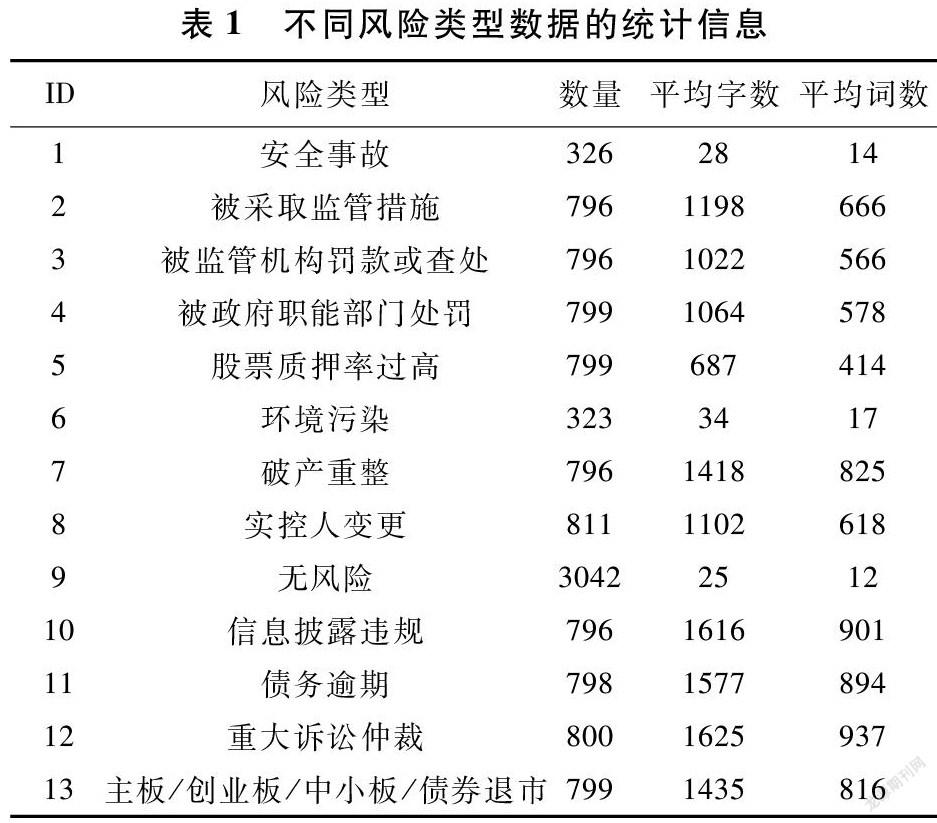
实验使用“互联网舆情企业风险事件的识别和预警”比赛数据集,该数据集包含13个字段:新闻ID、新闻标题、摘要、正文、作者、下载源地址、文章类型、来源、首发网站名称、网站频道、发布时间、企业名称、风险标签。共计13类标签,其中包含12类企业风险事件和无风险事件,剔除无用字符后风险类型和字词数量统计信息如表1所示。
由表1可知,无风险类别的数量远高于其他风险类别,为降低数据类别不平衡所产生的影响,使用欠采样(under sampling)方法隨机从无风险类别数据中取800个样本。同时,平均词数最多的风险为重大诉讼仲裁,达到937个词。为了覆盖大部分语料,将Word2vec模型的最大输入长度设置为1000词,当输入长度超过1000词时,采用截断法,取开头500词和结尾500词作为输入。
本文构建的企业风险知识图谱包含280余万条知识,如果将其全部纳入KGANN模型会导致参数过多且难以训练。因此,根据企业所属行业和规模,选取具有代表性的86家企业及其相关知识节点,生成知识图谱子图。接着对子图进行剪枝,去除无意义的节点。为保证每层知识向量的长度一致,使用企业类型为属性的三元组作为第一层知识(例如:[中国石油化工股份有限公司,企业类型,其他股份有限公司(上市)])。最终得到知识图谱的第一层包含86个节点,第二层共计914个节点,第三层共计6650个。以此为基础构成了KGANN模型的隐藏层结构。
4.2 实验设置
使用Word2vec模型和TransE模型分别对输入语料和知识图谱进行向量化表示,然后构建KGANN模型,模型均采用early_stopping策略进行训练,模型的相关参数设置如表2所示。
实验采用精确率P(Precision)、召回率R(Recall)和F1值进行评估,在多分类任务中,需要单独计算每一类的P、R和F1值。当计算某一类样本的指标时,该类样本为正样本,其余类样本为负样本。其定义如(4)~(6)式所示。
其中TP表示正样本识别正确的数量,FP表示正样本识别错误的数量,FN表示负样本识别错误的数量。P表示在识别样本总数中,识别正确的样本占比,R表示在所有正样本数中,识别正确的样本占比,F1值是P和R的等权调和平均值,可以对P和R进行整体评价。
4.3 对比实验
为了验证模型的有效性,选取了RNN模型和Bi-LSTM模型作为KGANN模型的对比模型。上述模型均使用Word2vec作为词向量工具,RNN模型和Bi-LSTM模型的神经元个数设置为1024,使用包含1200个样本的验证集对模型进行验证,得到结果如表3所示。
由表3可知,Bi-LSTM模型的相关评价指标略优于RNN模型,其原因是Bi-LSTM模型引入门结构可以将对识别结果有益的特征进行保留,无益的特征选择遗忘。同时双层结构可以同时提取输入语料的正向特征和逆向特征,进而提高了模型的特征提取能力。KGANN模型在相关评价指标中均显著优于RNN模型和Bi-LSTM模型,其原因是KGANN模型将知识图谱转化为模型,不仅模型结构更加符合逻辑,而且在模型识别风险过程中考虑到企业相关的领域知识。领域知识可以对特征向量进行补充或约束,从而使模型在识别风险时更具有针对性。
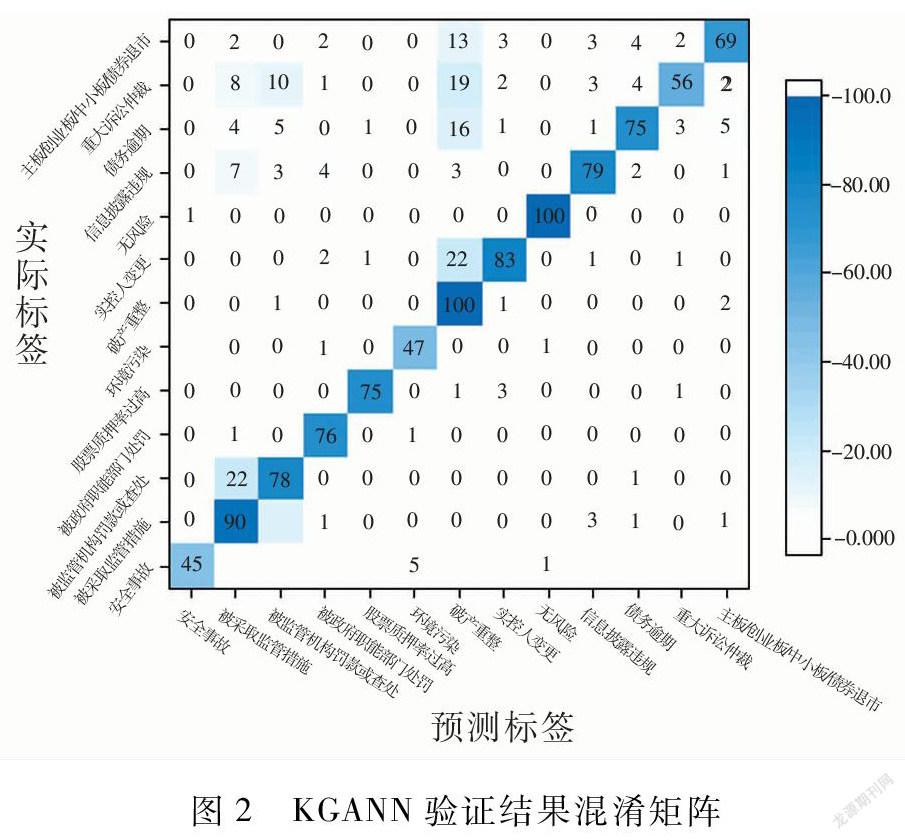
为了进一步研究KGANN模型在识别不同类别风险时的差异,将模型在验证集上所得结果绘制成如图2所示混淆矩阵。
由图2可知,有5个安全事故的样本被识别为环境污染,是因为安全事故有时会导致环境污染,例如有毒有害化学品大量泄露会在一定范围内造成环境污染。有15个被采取监管措施的样本被识别为被监管机构罚款或查处,有22个被监管机构罚款或查处的样本被识别为被采取监管措施。其原因是监管措施是非行政处罚性监管措施,通常以监管谈话、出具警示函和计入诚信档案等形式出现,而被监管机构罚款或查处则是通过减损权益或增加义务的形式,达到一定的惩戒效果,通常以罚款、限制生产经营活动和责令关闭等形式出现。两种风险事件存在部分重叠,因此模型在识别时存在误判的情况。有7个信息披露违规样本被识别为被采取监管措施,其原因是信息违规披露通常为企业信息披露不完整、风险揭示不充分,造成企业和广大投资者之间的信息不对称,损害了金融市场的健康发展。因此监管机构会对企业信息违规披露行为处以相应监管措施。有22個实控人变更的样本、16个债务逾期样本、19个重大诉讼仲裁样本和13个退市样本被识别为破产重整。其原因是当企业一旦出现上述情形时,如果处理不当往往会演变为企业债务危机,甚至陷入资不抵债和破产重整的境地。因此企业出现上述四种重大风险时,往往伴随着破产重整。
4.4 分析及讨论
在自然语言处理领域,神经元的含义不明确是传统深度学习模型可解释性较差的根本原因,KGANN模型通过将知识图谱转换为可训练的深度学习模型,模型可以通过追踪隐藏层中每个神经元的知识部分,从而对深度学习模型进行分析。同时,知识图谱的构建依赖于本体库,通过本体库可以对模型进行逻辑上的解释。
保存训练过程中F1值最高的模型,其中每一条知识都包含对应的权重值。通常,权重值有正负之分,当神经元处于激活状态时权重值为正,此时神经元内的知识有利于风险识别;当神经元处于静息状态时权重值接近于零,此时神经元内的知识作用较低;当神经元处于抑制状态时权重为负,此时神经元内的知识不利于风险识别。通过分析权重值可以了解深度学习模型的侧重点,并分析不同类型的风险对应的重要因素和指标。
4.4.1 隐藏层权重分布描述性统计
第一层隐藏层包含86个节点,节点所包含的知识结构为[企业名称,企业类型,企业类型的值]。选取企业时需要尽量包含不同行业和规模的企业,以此为基础链接到企业具体的知识节点。第一层隐藏层节点包含企业名称和企业类型,模型无法通过企业名称来判断企业是否包含风险。尽管企业类型和风险类别存在一定关联,但样本过少不具备统计学上的解释意义。因此后续分析的数据为第二层隐藏层和第三层隐藏层的知识权重值,简称为第二层和第三层。
描述性统计结果显示,第二层和第三层权重值在零附近聚集,说明模型中的大部分知识对模型的修正较为谨慎。第二层相较于第三层的权重值具有更高的离散度和区分度,其原因是第三层所包含的知识更为具体,例如第三层的“变更项目”、“变更前”和“变更后”相较于第二层的“变更记录”更为具体,更上层的概念所能表达的特征更丰富,对模型产生的影响更大,因此第二层权重相较于第三层权重更加分散,方差也更大。
第二层和第三层的均值接近零,分别为0.00056和-0.00127,说明模型中的知识激活或抑制较为均衡。第二层和第三层的标准差分别为0.70607和0.16717,说明第二层知识的权重更离散,相较于第三层的知识有着更高的区分度。第二层的最大值和最小值分别为3.29179和-3.72968,第三层的最大值和最小值分别为1.89145和-2.05702,可以看到第二层知识的权重区间更大,说明数据分布较为分散。
离群点中具有极高和极低的权重值,对模型产生的影响较大,具有分析意义。使用四分数方法计算离群点,首先将数据从小到大排列分成四等份,三个分割点从小到大分别为下四分位Q1、中位数Q2、上四分位Q3。第二层的Q3和Q1分别为0.05243和-0.04162,第三层的Q3和Q1分别为0.02734和-0.02715。接着使用(7)式和(8)式计算权重值的最大观测值和最小观测值。
经计算第二层的最大观测值和最小观测值分别为0.19108和-0.18121,第三层的最大观测值和最小观测值分别为0.10872和-0.10876。最后,大于最大观测值或小于最小观测值的权重值为离群点,第二层和第三层的离群点个数分别为372和831。
4.4.2 离群点特征分析
基于本体库构建知识图谱时,知识的关系及属性含义较为清晰,因此使用知识的关系及属性来表示知识的所属类别。为了分析模型在学习过程中调整了哪些类别的知识,使用负离群点表示小于最小观测值的点,使用正离群点表示大于最大观测值的点。通过观测负离群点和正离群点中不同关系及属性占比的变化,进而分析出哪些类别的知识具有更高的区分度。最后对第二层和第三层隐藏层中占比变化最大的八类关系及属性进行统计,如图3所示。其中横轴为初始状态下各关系及属性的占比,在横轴以下代表占比减少,在横轴以上代表占比增加。正离群点在横轴以上时,代表该类别的关系及属性有利于风险识别,有更高的区分度。而负离群点在横轴以上时,代表该类别的关系及属性不利于风险识别,容易混淆风险识别特征。
图3 隐藏层关系及属性占比变化 图3(a)和图3(b)中“案件名称”为司法案件的名称,正离群点的增幅较大,说明司法案件相关知识在风险识别过程中起到了积极的作用。除去一些特殊行业的企业,如保险公司虽有较多的司法案件,但不影响其风险水平。但常规企业涉及司法案件较多时,通常伴随着企业的信用缺失和风险水平的提高。
图3(a)和图3(b)中“被控制企业名称”的正离群点的增幅较大,说明被控制企业相关知识有利于风险的识别。与之相对应的是图3(a)和图3(b)中“投资企业名称”的正负离群点的占比同时增加,说明投资企业分为两种情况,一种对风险识别有益,一种对风险识别无益。投资人以股东身份投资企业时分为控股股东和非控股股东,控股股东对应“被控制企业名称”,表现出正离群点占比增加趋势,有利于风险的识别。非控股股东则表现负离群点占比增加趋势,无益于风险的识别。这是因为许多投资人为了规避风险,通过多层嵌套的方式,利用有限责任公司间接持有上市公司股份。由于自身风险得到控制,股东有动力实施自身收益更高而风险更大的决策,这样的决策无形中提高了企业的风险水平,不利于金融市场的稳定性。
同时,企业为了扩展自身业务还会开设分支机构,如图3(a)中的“分支结构名称”表现出负离群点占比增加的趋势,说明分支结构的相关知识和风险识别关联度较低。其原因是分支结构与总公司存在密切联系,当分支结构出现风险事件时,总公司难以置身事外,需要承担相应的责任。因此分支机构不会增加企业的风险水平。图3(b)中的“状态”为企业分支结构的状态,呈现正负离群点的占比同时增加,但负离群点占比增幅大于正离群点,说明分支机构的状态和企业风险的关联度较低,这是因为分支机构在业、存续或注销都不会显著影响企业的风险水平。
图3(a)中的“主要人员”为担任董事长、总经理、董事和监事等重要职务的人员,表现为负离群点占比增加,说明企业的主要人员与风险关联度较低。其原因是高风险水平企业的主要人员通常不是企业的实际控制人,即便是实际控制人对待自己不同企业也有不同的策略,因此企业的主要人员缺少能够表征企业风险的相关特征,无法判断企业的风险水平。
图3(a)中的“经营范围”表现为正离群点占比少量增加,说明部分经营范围相关的知识有利于风险的识别。其原因是少数风险和企业的经营范围密切相关,例如金融领域的企业发生安全事故的概率极低,教育领域的企业发生环境污染的概率极低。因此通过企业的经营范围可以对识别结果进行一定程度的约束,从而达到全局最优解。
图3(a)中的“变更记录日期”和“曾用名”均表现为负离群点占比增加,说明两者与企业风险关联程度较低。这两类关系缺少风险识别的相关特征,模型无法通过“变更记录日期”和“曾用名”来辨别企业的风险水平。
图3(b)中的“投資比例”为图3(a)中的“投资企业名称”的下位关系,两者具有相似的变化趋势,其中投资比例较高的情况对应被控制企业。与之相关的关系为图3(b)中的“投资数额”,表现为负离群点占比增加,说明投资数额与企业风险水平相关性较低。同一投资数额对不同规模的企业影响不同,投资比例相较于投资数额具有更高的区分度。
图3(b)中“知识产权名称”表现为正离群点占比增加,说明知识产权有利于风险识别。其原因是重视知识产权的企业,通常具有更强的法律意识,有助于企业在签订合同、履行合同、融资等过程中规避风险。因此,以知识产权为着眼点可以体现企业全局的法律意识,知识产权具有较高的风险区分度。
图3(b)中“关联产品或机构”表现为正负离群点占比同时增加,负离群点增幅大于正离群点。说明该关系所包含的大部分知识不具有区分度,小部分有较高的区分度。其原因与图3(a)中“经营范围”相似,小部分企业产品和机构与特定类型的风险相关,例如主营产品为矿产的行业发生安全事故的风险明显高于其他行业。
5 结论与建议
风险对企业的生存发展有着重要的作用,随着互联网的快速发展,网络舆情信息对企业影响越来越大,如何快速准确地识别舆情事件中的风险成为了企业、投资人、监管机构和学术界共同关注的热点之一。为了对企业风险进行更为准确的识别,本文研究提出了KGANN模型。与传统深度学习模型不同,KGANN模型保留了知识图谱的层级结构和具体的知识。得益于特殊的结构,每个神经元都包含独立的知识特征,模型可以根据当前任务对知识的权重进行主动学习,具有较高的自主性。实验结果表明,所提方法在相关评价指标中优于RNN和Bi-LSTM模型,在风险识别任务上具有显著优势。
本文的贡献主要体现在以下三方面:(1)在领域专家的指导下构建了企业风险本体库,并以该本体库为基础构建了企业风险知识图谱。(2)提出了一种全新的知识注入模型,该模型在企业风险识别任务上的效果较好,可以帮助企业识别风险并及时响应。(3)与传统的深度学习模型相比,本文所提模型具有一定的可解释性。知识是以三元组形式出现,因此可以根据权重值对模型的侧重点进行分析,进而得到风险水平较高企业的特征,实现风险预警的功能。
本研究的相关结论对企业及监管部门开展风险预警、分析和监管等管理活动也具有一定的指导意义。(1)对于企业而言,企业自身应加大科研创新的投入,只有拥有自主知识产权的核心技术,企业才具有核心竞争力。此外,企业经营者还应提升自身的法律意识,并加强权力制约和内部规章制度的设立,做好各级员工法律意识的建设,以保证公司依法经营、依法管理和依法决策。(2)对于监管机构而言,相关监管部门应当加强对企业实控人的识别和对一些司法案件较多、知识产权较少、股权结构复杂企业的监管。研究在识别风险的过程中发现,投资人经常会使用间接持股的方式控制企业,这种行为扰乱了监管机构的视野,导致在监管过程中存在盲区。2021年初,中国证券监督管理委员会发布了《监管规则适用指引——关于申请首发上市企业股东信息披露》,文件强调要加强对违规代持、影子股东、突击入股和多层嵌套等IPO乱象的监管。因此,相关部门需要加强对股权穿透的识别分析,确保可以准确地核查到企业的实际控制人,并将风险水平较高的企业放在聚光灯下,以充分保障金融市场稳定有序的发展。
参 考 文 献:
[1] 黄文锋.企业家精神[M].北京:中国人民大学出版社,2018.
[2] 人民日报评论员.在更高起点上推进改革开放——论学习贯彻习近平总书记在深圳经济特区建立40周年庆祝大会上重要讲话[J].人民政坛,2020,(10):1.
[3] 杨波,杨美芳.风险事件驱动的企业知识服务模型及应用研究[J].情报理论与实践,2021,44(10):100-109,71.
[4] 白喜平.关于企业风险管理模式及管理原则的研究[J].山西财税,2021,(1):36-37.
[5] Deng M R. Study on risk conduction of commercial banks based on business process chain[J]. Contemporary Economic Management, 2006, 28(6): 76-79.
[6] 李柏洲,徐广玉,苏屹.基于扎根理论的企业知识转移风险识别研究[J].科学学与科学技术管理,2014,35(4):57-65.
[7] 叶伟政.中国白酒企业财务风险识别及应对措施分析——以五粮液股份有限公司为例[J].中国总会计师,2021,(8):59-61.
[8] 杨子昭.基于卷积神经网络的上市企业财务风险预测模型研究[D].上海:上海师范大学,2021.
[9] 李旻旸,戴月娥.基于模式识别技术的财务风险识别研究[J].电子设计工程,2021,29(4):122-125,130.
[10] Ahn B S, Cho S S, Kim C Y. The integrated methodology of rough set theory and artificial neural network for business failure prediction[J]. Expert Systems with Applications, 2000, 18(2): 65-74.
[11] 周春生.企业风险与危机管理[M].北京:北京大学出版社,2007.
[12] Francisco J, Poblacion G. Financial risk management[M]. Berlin: Springer International Publishing, 2017.
[13] Coleman thomas S. A Practical guide to risk management[M]. Virginia: CFA Institute Research Foundation, 2011.
[14] 武彥伏.企业财务风险识别及应对策略[J].消费导刊,2014,(11):106-107.
[15] 张祥来,金雪梅,周俊红.如何做好危害识别与风险评价工作[J].安全,2013,(9):37-38.
[16] Leng B, Du H, Wang J, et al.. Analysis of taxi drivers’ behaviors within a battle between two taxi apps[J]. IEEE Trans Intell Transp Syst 2016, 17(1): 296-300.
[17] Bose I, Pal R. Predicting the survival or failure of click-and-mortar corporations: a knowledge discovery approach[J]. European Journal of Operational Research, 2006, 174(2): 959-982.
[18] 柳向东,李凤.大数据背景下网络借贷的信用风险评估——以人人贷为例[J].统计与信息论坛,2016,(5):41-48.
[19] 曹如中,刘长奎,曹桂红.企业竞争情报工作风险识别及控制研究[J].图书与情报,2010,(4):38-42.
[20] 黄世忠,叶丰滢,李诗.碳中和背景下财务风险的识别与评估[J].财会月刊,2021,(22):7-11.
[21] Allen F, Gale D. Financial contagion[J]. Journal of Political Economy, 2000, 108(1): 1-33.
[22] Didimo W, Giamminonni L, Liotta G, et al.. A visual analytics system to support tax evasion discovery[J]. Decision Support Systems, 2018, 110: 71-83.
[23] Yerashenia N, Bolotov A. Computational modelling for bankruptcy prediction: semantic data analysis integrating graph database and financial ontology[A]. 2019 IEEE 21st Conference on Business Informatics(CBI)[C]. IEEE, 2019. 84-93.
[24] 杨波,廖怡茗.面向企业动态风险的知识图谱构建与应用研究[J].现代情报,2021,41(3):110-120.
[25] Franco-Salvador M, Rosso P, Montes-y-Gomez M. A systematic study of knowledge graph analysis for cross-language plagiarism detection[J]. Information Processing & Management, 2016, 52(4): 550-570.
[26] 姜增明,陳剑锋,张超.金融科技赋能商业银行风险管理转型[J].当代经济管理,2019,41(1):85-90.
[27] 金磐石,万光明,沈丽忠.基于知识图谱的小微企业贷款申请反欺诈方案[J].大数据,2019,5(4):100-112.
[28] 王成,舒鹏飞.WEB:一种基于网络嵌入的互联网借贷欺诈预测方法[J].大数据,2019,5(6):85-100.
[29] 陶士贵,相瑞.基于大数据技术的商业银行反洗钱风险识别“穿透”研究[J].金融发展研究,2020,(7):73-78.
[30] Bordes A, Usunier N, Garcia-Duran A, et al.. Translating embeddings for modeling multi-relational data[J]. Advances in Neural Information Processing Systems, 2013, 26: 1-9.
[31] 刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
[32] 李涛,王次臣,李华康.知识图谱的发展与构建[J].南京理工大学学报,2017,41(1):22-34.
[33] 黄恒琪,于娟,廖晓,等.知识图谱研究综述[J].计算机系统应用,2019,28(6):1-12.
[34] Mikolov T, Sutskever I, Chen K, et al.. Distributed representations of words and phrases and their compositionality[A]. Advances in Neural Information Processing Systems 26(NIPS 2013)[C]. NIPS, Nevada, 2013. 3111-3119.
[35] Devlin J, Chang M W, Lee K, et al.. Bert: pre-training of deep bidirectional transformers for language understanding[A]. The 2019 Conference of the North American Chapter of the Association for Computational Linguistics-Human Language Technologies(NAACL-HLT2019)[C]. NAACL, Minneapolis, 2018. 4171-4186.
3390500338226
