融合实体类别信息的实体关系联合抽取
2022-03-12陈仁杰郑小盈祝永新
陈仁杰,郑小盈,祝永新
(1.中国科学院上海高等研究院,上海 201210;2.中国科学院大学,北京 100049)
0 概述
互联网上每时每刻都涌现出大量新闻、博客、社交媒体的文本数据,如何从海量的非结构化数据中提取出有用的结构化信息成为亟待解决的问题,因此,信息抽取(Information Extraction,IE)技术被提出。实体关系抽取是信息抽取中的核心子任务,包含实体抽取和关系分类,旨在从非结构化文本中提取出潜在的命名实体对,并对每个实体对间存在的关系类型进行分类,最终以实体-关系三元组的形式呈现。例如,在句子“周星驰导演了电影《喜剧之王》”中,可以提取出的三元组是“周星驰-导演-喜剧之王”,其中,“周星驰”是头实体,“喜剧之王”是尾实体,“导演”是实体对之间存在的关系类型。实体关系抽取可以为自动问答、推荐系统、信息检索、知识库填充等下游任务提供有力支持,近年来受到学术界和工业界的广泛关注。
传统的关系抽取方法将任务划分为2 个流水线式的子任务:命名实体识别(Named Entity Recognition,NER)和关系分类[1-2]。针对每个句子,首先识别出句子中所有的实体,然后对每个实体对进行关系分类。这类方法容易导致误差传播问题,前一个子任务产生的错误可能会累积到下一个子任务[3]。此外,流水线方法还忽视了2 个子任务间的内在交互和依赖关系。
不同于流水线方法,联合抽取方法采用一个联合模型同时识别出实体和关系类型,现有的联合抽取方法主要包括基于表格填充的方法、基于标注策略的方法和基于编码器-解码器的方法。基于表格填充的方法需要枚举所有可能的实体对,会导致繁重的计算负担[4]。基于标注策略的方法[5]将实体关系抽取任务统一成一个序列标注问题,但由于对句子中的每一个token 都只能赋予一个标签,因此无法处理三元组重叠问题。
为应对三元组重叠问题,DAI 等[6]在ZHENG等[5]研究的基础上,采取对一个句子进行多轮标注的策略,这虽然可以应对三元组重叠问题,但是却带来了较大的计算量。另一种可行的思路是采用基于编码器-解码器结构的方法[7-9],将非结构化文本输入到模型中,按照特定的顺序依次解码实体关系三元组,这类方法可以应对三元组重叠问题,同时也不会带来较高的复杂度。
此外,PENG 等[10]的研究表明,句子的上下文以及实体信息(主要是实体类型信息)对于关系抽取模型效果的提升起到了重要作用,ZHONG 等[11]验证了学习实体和关系的不同上下文表示并将实体类别信息用作关系模型输入特征的重要性。
在联合抽取方法中,目前关于如何有效融合实体类别信息的研究相对较少,但相关研究[10-11]表明,实体类别信息对于构建更丰富的语义特征并进一步提升关系模型的效果具有重要意义。文献[12]利用卷积神经网络从Freebase 知识库和Wikipedia 中提取出实体描述信息特征向量,但该方法基于远程监督,会引入大量噪声,并且不能直接处理三元组重叠问题。
本文提出一种融合头尾实体类别信息的实体关系联合抽取模型FETI。将实体类别信息融合到模型中,在解码阶段增加头尾实体类别的预测,同时优化损失函数,增加对实体类别信息的约束。此外,在百度开源的中文数据集DuIE[13]上进行实验并与基线模型对比,验证融合实体类别信息对于提升实体关系抽取模型性能的有效性。
1 相关工作
1.1 实体关系抽取
早期的研究工作主要采用流水线方法[1-2],先从文本中提取出所有的实体,再对每个实体对进行关系分类,从而得到实体-关系三元组,但是这类方法存在错误累计传播问题,并且忽视了2 个子任务之间的内在交互[14]。MIWA 等[15]通过设计复杂的特征来进行关系抽取,特征的提取依赖NLP 句法分析工具,不同工具提取特征的准确率存在差异,且句法分析工具产生的误差可能传播到关系抽取任务中。TAKANOBU 等[16]采用基于强化学习的方法,先识别出关系类型,再识别出相应的实体对。孙紫阳等[17]则采用基于最短路径表示文本的方法来进行中文实体关系抽取。
ZHENG 等[5]提出一种新的标注策略,将关系类型和实体用一个标签来表示,并根据该标注策略对句子中的每一个单词进行标注,由此将联合抽取问题转化为经典的序列标注问题。但重叠的三元组问题对于传统的序列标注策略是一个极大的挑战,因为序列标注问题假定每一个单词只包含一个标签,由于该方法对句子中的每个单词只能分配一个标签,因此无法处理三元组重叠问题。DAI 等[6]尝试采用多轮序列标注的方法,但是却又引入了较大的计算负担。FU 等[18]采用基于图卷积网络(Graph Convolutional Network,GCN)的方法,将句子中的单词作为图中的节点,将单词间的关系作为图中的边,通过加权的GCN 考虑实体间的相互作用以及可能存在的重叠关系。LI 等[19]将联合抽取问题转化为多轮问答问题,利用针对特定关系类型的模板生成相应的问题。
此外,还有一些研究采用基于编码器-解码器结构,将关系抽取问题转化为序列生成问题,在解决三元组重叠问题的同时避免带来过多的计算量,这类方法与人工提取三元组的过程类似,即首先阅读整个句子,理解其含义,然后按照特定顺序抽取出实体-关系三元组。ZENG 等[7]将编码器-解码器结构应用到实体关系抽取任务中,尝试解决三元组重叠问题。
三元组重叠问题指的是一个句子中的不同三元组之间存在某个元素(头实体、尾实体或关系类型)重合的现象,这会导致无论是基于深度学习的方法还是传统的基于特征工程的方法都难以准确提取出句子中的三元组。如图1 所示,根据是否重叠可以将三元组划分为3 个类型:正常(Normal),单个实体重叠(Single Entity Overlap,SEO),实体对重叠(Entity Pair Overlap,EPO)。

图1 三元组类型划分示例Fig.1 Example of triplet type division
文献[7]模型中主要包含编码器(Encoder)和解码器(Decoder)两个部分,编码器接收非结构化的文本作为输入并转化为固定长度的上下文向量,解码器读取该向量并生成三元组。但是该方法每次只能预测实体的最后一个单词,对于含有多个单词的实体不能完整预测。ZENG 等[8]在文献[7]模型的基础上进行改进,采用多任务学习的策略使模型可以预测出多单词实体。NAYAK 等[20]提出带掩码机制的编码器-解码器结构来应对实体关系抽取中的三元组重叠问题。然而,这些基于编码器-解码器的方法将重叠三元组的抽取分解为几个有先后顺序、相互依赖的步骤,会导致曝光偏差的问题[21]。曝光偏差指的是基于编码器-解码器的模型在训练和测试阶段存在不一致的现象。在训练阶段,当前步三元组的预测依赖于前一步三元组的真实标签,但是在测试阶段,当前步模型预测的三元组却依赖于模型上一步预测出的三元组。例如,当一个句子中存在3 个三元组,在训练阶段,模型按照“三元组1-三元组2-三元组3”的顺序进行学习,在测试阶段,如果模型首先预测出“三元组2”,则最后的结果只能是“三元组2-三元组3”,而缺失了“三元组1”的预测,但“三元组2-三元组3-三元组1”仍然是正确的结果。这种在训练阶段对于多个三元组先后顺序的预定义,限制了模型的学习能力和泛化性能[9]。因此,ZHANG等[9]提出了一种树状解码方法,将一维三元组序列转化为一个无序树状结构,通过三层解码依次识别出所有可能的头实体、关系、尾实体。由于同一层预测出的结果间是无序的,并且摒弃了不同三元组间预定义的顺序,因此一个三元组的预测偏差并不会累积到下一个三元组的预测,该方法能够有效缓解曝光偏差的问题。
尽管目前的实体关系联合抽取方法研究取得了显著的进展,但仍然存在一些不足,例如实体描述信息(包括实体类别等信息)没有得到充分利用,导致实体和关系之间缺乏内在的交互。本文在联合抽取模型中集成对实体类别信息的预测,为联合抽取任务补充了背景知识,以期提升模型性能。
1.2 多任务学习
多任务学习[22]通过利用多个相关任务的训练中包含的特定信息来提高模型的泛化性能,主要研究方向包括网络设计和损失函数的优化,本文主要关注多任务损失函数的优化。VANDENHENDE 等[23]指出,在多任务学习中,当一个任务的梯度幅度比其他任务高得多时,也即不同任务的梯度若不在一个数量级上时,网络权重的更新可能由梯度较高的任务主导,并通过对现有的多种任务平衡策略进行分析,总结出对平衡多任务学习有效的方法,如降低噪声任务的权重、平衡不同子任务的梯度等。CIPOLLA等[24]利用同方差不确定性来调整各个子任务损失函数的权重,使得训练过程中每个子任务的损失函数值在数量级上较为接近。CHEN 等[25]定义了一些变量分别用来衡量不同任务损失的数量级以及任务的学习速度,使得训练过程中各个子任务的损失数量级以及训练速度尽可能比较接近。
尽管多任务学习损失函数优化研究近年来受到广泛关注,但不同方法针对不同的任务场景、数据集、优化器以及网络结构,其有效性并不一定能够得到保证,且仍缺少对于损失函数权重可解释性问题的研究与讨论,因此,损失函数权重的可解释性问题是目前多任务学习领域乃至整个深度学习领域的一大难题,学术界尚未形成系统有效的理论予以支撑。
2 融合实体类别信息的联合抽取
本文提出一种融合实体类别信息的实体关系联合抽取模型FETI。该模型整体采用基于编码器-解码器的结构[26],其中编码器采用经典的Bi-LSTM 结构[27],解码器采用一种树状解码方案替代传统的一维线性解码。具体而言,假设模型的解码顺序为h1-h2-r-t1-t2,h1代表头实体,h2代表头实体类别,r 代表关系类型,t1代表尾实体,t2代表尾实体类别。首先,第1 层解码预测出所有潜在的h1,然后将预测出的每一个头实体依次作为下一层解码的输入,在下一层解码阶段预测所有的h2,再将第2 层解码预测结果依次作为下一层解码输入,在第3 层解码阶段预测出所有的关系类型r。依次类推,通过5 层解码预测出头实体-头实体类别-关系-尾实体-尾实体类别。本文提出的FETI 模型整体框架如图2 所示,其中,左侧为从输入句子提取出一个实体关系三元组的示意图,右侧为利用树状解码提取出句子中所有三元组的示意图。
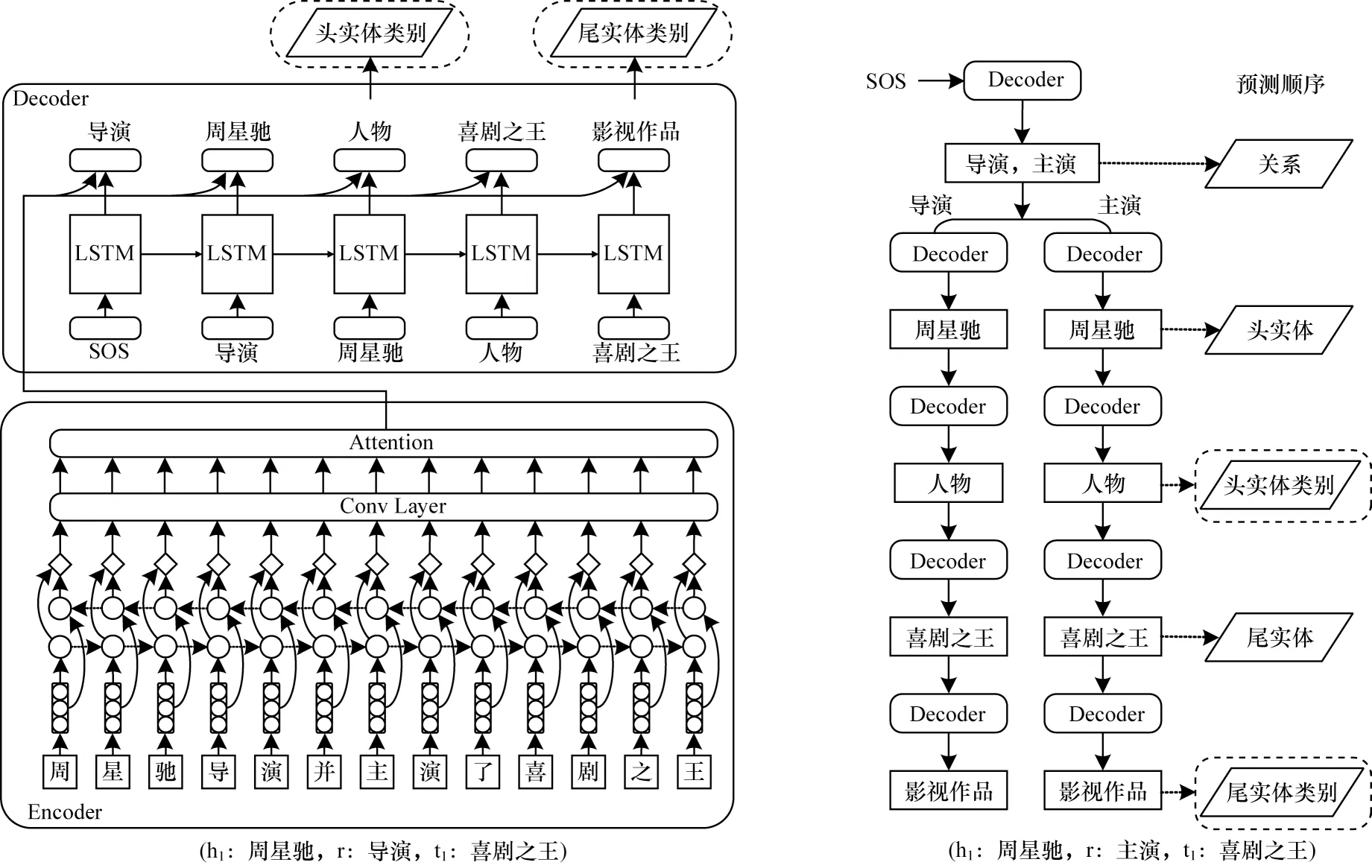
图2 FETI 模型总体框架Fig.2 Overall framework of FETI model
2.1 编码器
2.1.1 嵌入层
假设单个输入句子表示为s=[w1,w2,…,wn],经过嵌入层后得到句子的向量表示:

其中:wi表示句子中的每一个字;xi表示每一个字对应的向量表示;n表示句子的长度。字的嵌入表示通过维护一个查找表实现,在训练过程中,查找表随不断迭代而更新,根据每个字的索引可以查询到对应的向量表示。
2.1.2 Bi-LSTM 编码层
LSTM 网络[28]由不同的记忆单元组成,通过输入门、遗忘门和输出门对输入内容以及记忆单元里存储的内容进行控制,形成对之前输入信息的记忆。由于双向LSTM(Bi-LSTM)考虑了当前时间步的输出既与之前的状态有关,又可能与未来的状态有关,因此通常可以获得更好的编码。LSTM 的计算过程如下:
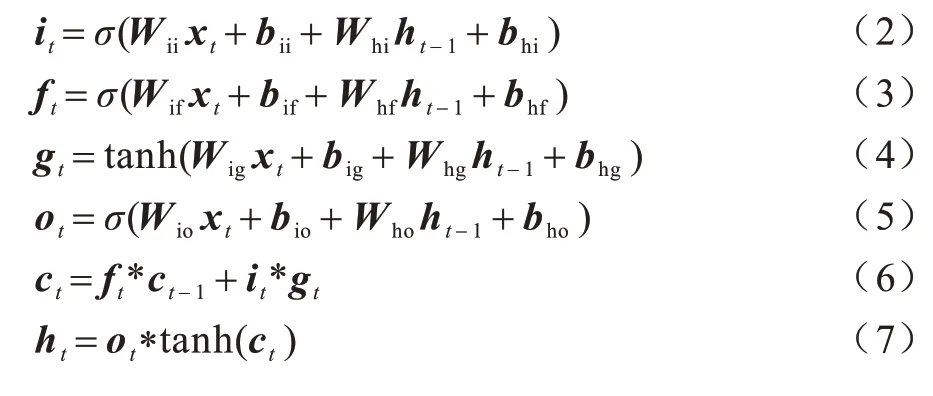
其中:ht代表时刻t的隐藏层状态;ct代表时刻t的元胞状态;xt代表时刻t的输入;it、ft、ot分别代表输入门、遗忘门和输出门。同时考虑前向LSTM 的编码和反向LSTM 的编码,则时刻t单词编码后的向量表示为:
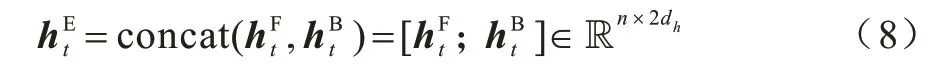
其中:dh代表LSTM 隐藏层的维度。
编码器对整个输入句子进行编码后,特征可以表示为:

2.2 融合实体类别预测的解码器
考虑时刻t解码器隐藏层状态为,前一时刻输入句子编码后的特征为ot-1,根据文献[29]提出的注意力机制(Attention)生成上下文向量:

将ct与ot-1拼接,经过卷积层(Conv Layer)得到t时刻输出:


由于一个句子中可能存在多个三元组,且三元组之间可能存在重叠,在文献[9]解码方法基础上,本文提出的FETI 模型添加了头尾实体类型的预测层。如图2 右侧所示,假设解码顺序为“关系-头实体-头实体类型-尾实体-尾实体类型”,第1 步解码出所有可能的关系,得到“导演”“主演”,第2 步分别将“导演”“主演”作为输入送入下一层进行解码,得到头实体,依次类推,继续解码得到头实体类型、尾实体、尾实体类型,最终解码得到两个实体-关系三元组:“周星驰-导 演-喜剧之王”“周星驰-主 演-喜剧之王”,从而有效应对多三元组问题以及三元组重叠问题。
2.3 损失函数
本文提出的FETI 模型融合了头尾实体类别信息的预测,假设解码时的预测顺序为h1-h2-r-t1-t2,即依次预测头实体-头实体类型-关系类型-尾实体-尾实体类型,则总的损失函数等于5 步解码的损失函数之和:
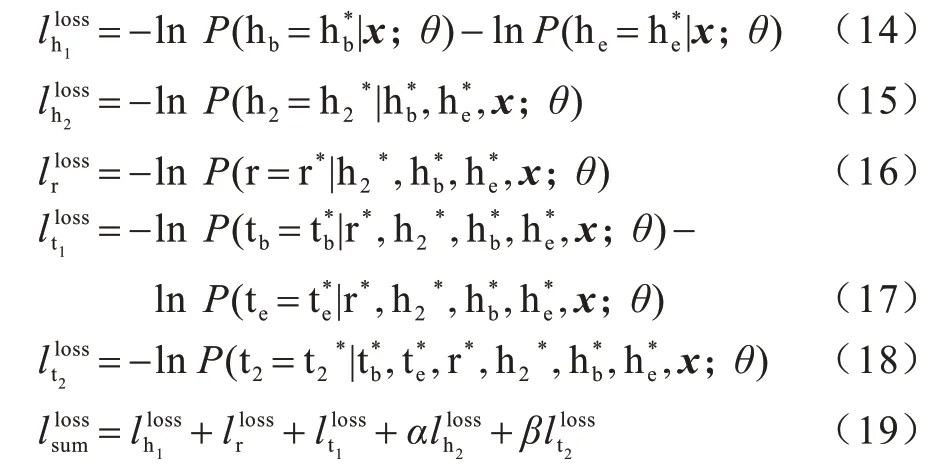
其中:α、β是超参数;和分别表示头实体的开始位置和结束位置的真实标签;表示头实体类型的真实标签;r*表示关系的真实标签;tb和表示尾实体的开始位置和结束位置的真实标签;表示尾实体类型的真实标签。FETI 模型在损失函数层对头尾实体类型进行了约束,使得模型可以充分利用实体类别信息,为联合抽取任务提供有效的背景知识。
3 实验
3.1 数据集介绍
本文实验数据集采用2019 年百度信息抽取竞赛中开源的数据集DuIE[13],该数据集是目前最大的中文关系抽取数据集,基于百度新闻和百度百科的语料,通过远程监督并结合人工校验的方式生成,其中包含训练集数据173 108 条、验证集数据21 639 条、测试集数据19 992 条。头实体包含16 种类别,如“景点”“企业”“歌曲”等,尾实体包含16 种类别,如“人物”“国家”“学校”等。
医院一名负责同志与本刊记者分享了这样一个具体分析案例:2016年,胸椎压缩性骨折CMI值为1.44,该病种在骨科所有病种中排名第85位(共313位)。2016年出院患者96人次,占骨科总出院患者比例为3.29%。出院患者与上年相比增加9人次。2016年例均费用45994.65元,例均费用与上年相比增加6739.58元。其中例均材料费用40668.47元,与上年相比增加44.87%,2016年直接可控成本/总收入为64.27%,与上年相比增加14.82%。
由于测试集原始数据并未公开,因此将原来的验证集作为测试集,将原来的训练集按照9∶1 划分为新的训练集和验证集,并且删去不包含三元组的句子。新的数据集统计信息如表1 所示。
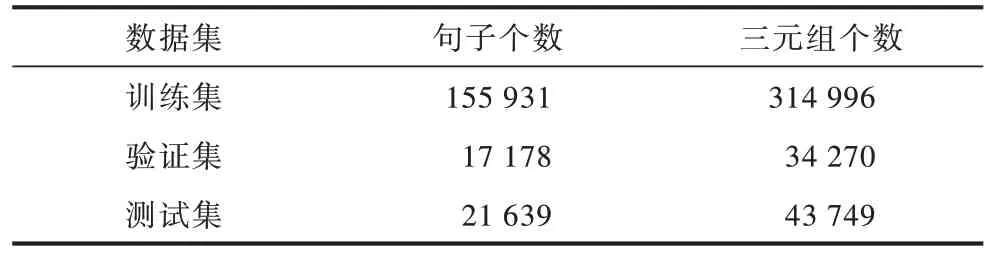
表1 数据集信息Table 1 Dataset information
数据集中的一个标注样例为{“subject”:“喜剧之 王”,“predicate”:“主 演”,“object”:“周星驰”,“subject_type”:“影视作品”,“object_type”:“人物”}。其中:“subject_type”表示头实体的类型;“object_type”表示尾实体的类型。在之前的公开数据集中,较少有关于实体类别信息的标注,因此,基于该数据集可以展开考虑实体类别信息的关系抽取实验。
3.2 实验设置
实验中的词向量通过维护一个查找表实现,词向量的维度dw为200,LSTM 隐藏层的维度dh为200,关系嵌入维度dr为200,头实体类型嵌入维度dh2为200,尾实体类型嵌入维度dt2为200,以上提到的嵌入均进行随机初始化。本文使用Dropout 来防止模型产生过拟合[30],Dropout 的大小设置为0.5,采用梯度截断防止训练过程中产生梯度爆炸。损失函数权重α设置为0.1,β设置为0.1。模型使 用Adam[31]优化器训练50 个epoch,在验证集上获取F1分数最高的模型,然后在测试集上进行测试,所有实验均在NVIDIA V100 32 GB GPU 上完成。
3.3 对比模型与评价指标
将本文提出的FETI 模型与以下模型进行对比:
1)Seq2UMTree[9]。此模型基于编码器-解码器结构,解码器部分采用了一个简单的树形结构生成三元组,本文选取其中效果最好的模型作为对比模型。
2)CopyMTL[8]。此模型是一个基于编码器-解码器结构并结合了复制机制的模型,实体的预测通过多任务学习的方式实现,解决了CopyRE[7]方法无法抽取含多个单词的实体的问题。
3)WDec[20]。此模型基于带掩码机制的编码器-解码器结构实现。
4)MHS[32]。此模型基于条件随机场进行实体识别,将关系抽取转化为一个多头选择问题,是本文基线模型中唯一一个没有采用编码器-解码器结构的模型。
使用精确率P、召回率R和F1 分数F1作为实体关系抽取的评价指标,计算方式如下:

其中:TP表示正类判定为正类的个数;FP表示负类判定为正类的个数;FN表示正类判定为负类的个数。在本文实验中,预测正确与错误是针对三元组而言的,即当三元组中的头实体h1、关系r、尾实体t1全部预测正确时,才认定该三元组的结果是正确的。
3.4 实验结果与分析
3.4.1 基本实验
对比模型CopyMTL、WDec、MHS、Seq2UMTree的实验结果均来自文献[9],本文提出的FETI 模型与所有对比模型的实验结果如表2 所示,其中加粗数据表示最优。由于解码阶段对于三元组的预测存在不同的顺序,因此表2 中的结果选自使得F1 值最高的解码顺序,Seq2UMTree 模型中F1 值最高的解码顺序是r-h-t,FETI 模型中F1 值最高的解码顺序是h1-h2-r-t1-t2。
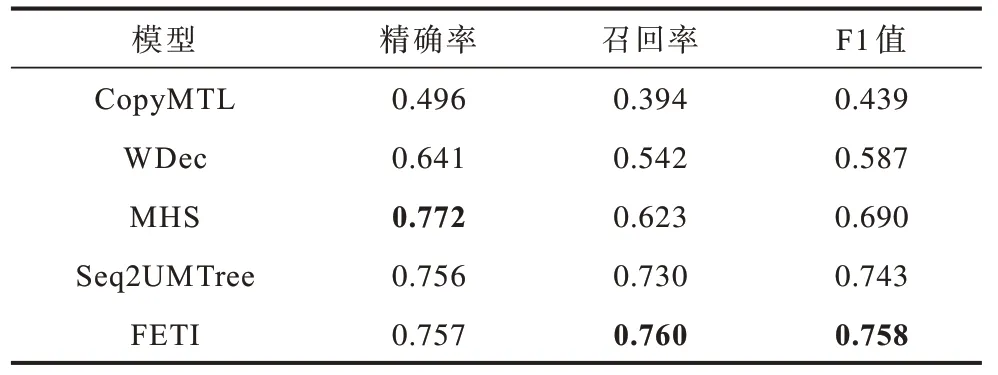
表2 基本实验结果Table 2 Basic experimental results
在DuIE 数据集上,FETI 模型取得了最高的F1 值和召回率:相对于Seq2UMTree,F1 值提升 了2.02%,召回率提升了4.11%;相对于未采用编码器-解码器结构的MHS,召回率提升了21.99%,F1 值提升了9.86%。然而,FETI 模型精确率相对于MHS 的0.772 下降了1.94%,原因在于MHS 模型在提取三元组时需要对所有的实体对进行枚举,这需要耗费大量的显存资源,且由于中文数据集中长句较多,因此在实现时删去了测试集中长度超过150 的句子,在整个测试集中占比1.6%,而Seq2UMTree 模型和FETI 模型均使用全部的测试集进行实验。
3.4.2 基于不同解码顺序的实验
在解码阶段,三元组的抽取存在一个预定义的顺序,例如:如果只预测h1、r、t1,则存在h1-r-t1、r-h1-t1等6 种不同的解码顺序。由于FETI 模型添加了头尾实体类型的预测,因此需要通过5 步解码预测出h1、r、t1、h2、t2,其中:h2表示头实体类型;t2表示尾实体类型。由于实体和实体类型密切相关,因此两者的预测应当连续进行,不应被其他元素的预测所中断,所以,存在“先实体后实体类型”和“先实体类型后实体”两种顺序,则FETI 模型存在12 种解码顺序,例如h1-h2-r-t1-t2,从中选取较好的效果进行报告。基于不同解码顺序的实验结果如表3 所示。
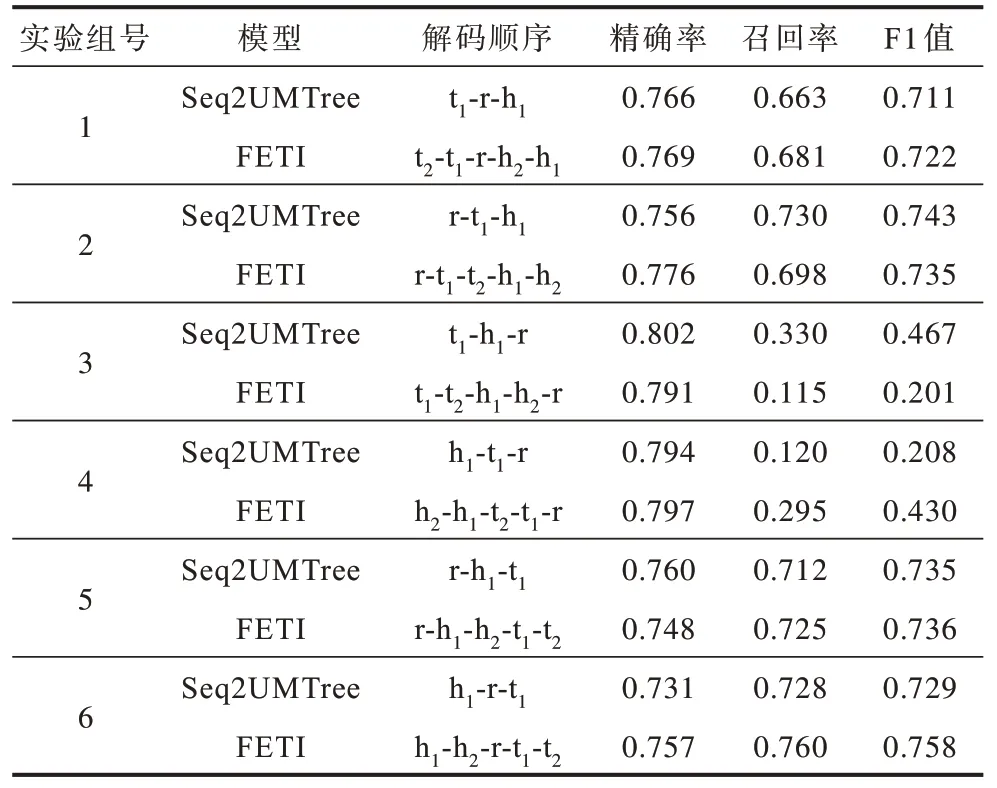
表3 不同解码顺序实验结果Table 3 Experimental results with different decoding orders
在第1 组实验中,FETI 模型采用“t2-t1-r-h2-h1”解码顺序时相对于对比模型在精确率、召回率、F1 值上分别提升了0.39%、2.71%、1.55%。
第3 组和第4 组实验FETI 模型召回率较低,导致最终的F1 值较低,检查实验结果发现大量样例在第一步解码时就出现预测错误(预测h1或t1),而关系的预测在解码的最后一步,说明关系类型信息的缺乏可能导致实体预测效果变差。在第3 组实验中,FETI 模型相对于对比模型在召回率上下降较多,尽管实体类别信息给联合抽取任务提供了一定的背景知识,但同时也可能引入一定的噪声。解码器采用自回归解码的方式,前一步的预测错误将会累积到下一步,从而导致整个三元组的预测出现错误。在第4 组实验中,虽然将关系预测放在最后一步可能导致实体预测的效果变差,但是FETI 模型融合了头尾实体预测之后,为整个任务提供了一定的背景知识,可以缓解由于缺乏关系类型而导致的实体预测错误,从而提升联合抽取模型的性能,FETI 模型相对于对比模型在召回率上提升了近1.46 倍,F1 值提升了近1.07 倍。
在第6 组实验中,FETI 模型采用解码顺序“h1-h2-r-t1-t2”时能够获得最高的F1 值,FETI 模型融合了头尾实体类别预测后,相对于采用“h1-r-t1”解码顺序的对比模型提升了3.98%,相对于“r-t1-h1”顺序的基线模型提升了2.02%。
整体上看,第3 组与第4 组实验相对其他组实验F1 值下降较多,Seq2UMTree 模型F1 值分别为0.467和0.208,FETI 模型F1 值分别为0.201 和0.430。说明不同解码顺序对于模型的最终效果影响较大,尤其是当关系类型r 放在最后一步解码时,没有为前面的头实体h1和尾实体t1的预测提供足够的背景知识,导致前面几步解码时头尾实体的预测大量出错。
3.4.3 基于不同权重损失函数的实验
上文讨论了不同解码顺序对于模型最终效果的影响,由于本文FETI 模型采用多任务学习的策略,利用损失函数对头尾实体类型分别进行了约束,因此不同损失函数权重的平衡可能会影响到模型最终的效果。
选取FETI 模型实验效果最好的解码顺序h1-h2-r-t1-t2,进行基于不同权重的损失函数相关实验。实验需要预测头实体h1、头实体类型h2、关系类型r、尾实体t1、尾实体类型t2,其中头实体、尾实体、关系类型的预测是主要任务,模型效果的评价也是基于这3 个元素预测结果的正确性来进行的,当一个样本中头实体、尾实体、关系类型预测正确,则记为预测正确,而不管头尾实体类别是否预测正确。头实体类型、尾实体类型的预测是辅助任务,两者预测结果的正确性并不直接参与模型效果的评价,而是为头实体、尾实体、关系类型的预测提供相应的背景知识,由于解码步骤中存在头尾实体类别的预测,因此可能会有误差传播问题,从而影响主要任务的表现,所以,辅助任务可能是潜在的噪声任务。
基于VANDENHENDE 等[23]总结出的多任务学习中子任务平衡的两种策略:降低噪声任务的权重以及平衡子任务的梯度,本文对辅助子任务(头尾实体类型的预测)的损失函数赋予了较低的权重,将主要任务的损失函数权重默认为1.0,具体实验结果如表4 所示,其中加粗数据表示最优。

表4 不同权重损失函数实验结果Table 4 Experimental results with different weights of loss function
在第1 组实验中,各子任务损失函数权重相等,通过观察损失函数值发现,头尾实体类别相关的损失函数值的大小曾超过头实体、尾实体、关系类型相关损失函数值10 倍以上,表现为在损失函数值上不处于同一个数量级。
在第2 组实验中,当α=0.1 和β=0.1 时取得最高的F1 值0.758,一定程度上平衡了不同损失函数的数量级,使得F1 值相对于实验1 提升了8.91%。
在第3 组和第4 组实验中,当α=0 时,F1 值相对于实验1 分别下降了29.02%和34.48%,由于没有对头尾实体类别的学习进行约束,导致头尾实体类别预测大量出错,在h1-h2-r-t1-t2解码顺序下,严重影响了后续r、t1的预测效果。而对于第5 组实验,α=0.1,β=0.0 相当于忽略了预测t2子任务的贡献,但由于t2的预测是最后一步,后续不存在对实体和关系类型的预测,因此F1 值仍保持在0.623。
对比第2 组和第5 组实验,当α=0.1,β由0.1 变为0.0 时,F1 值由0.758 降为0.623,下降了17.81%,虽然β影响的是最后一步尾实体类别t2的预测,且后续不存在对实体和关系类型的预测,但也说明实体类别提供的背景知识对整个模型的效果有重要作用。实体类别的预测在提供背景知识的同时也可能带来噪声,对比第2 组和第6 组实验,当β=0.1,α 由0.1 变为1.0 时,F1 值由0.758 降为0.729,下降了3.83%,当头实体类别损失函数权重升高时,噪声的影响可能超过了提供有效背景知识对模型的影响。
综上,对于主要任务(包括预测头实体、尾实体和关系类型)的损失函数,赋予较高权重时(均设置为1.0)并且对辅助任务(包括预测头实体类型、尾实体类型)的损失函数赋予较低权重时(均设置为0.1)实验效果最佳,能够在辅助任务为主要任务提供有效背景知识的同时限制噪声的影响,有效平衡不同损失函数值的数量级,防止次要任务主导整个训练过程。
4 结束语
本文提出融合头尾实体类别信息的实体关系联合抽取模型FETI,在解码阶段融合头尾实体类别信息的预测,并且通过辅助损失函数进行约束,使得模型能够有效利用实体类别信息,为联合抽取任务提供所需的背景知识。实验结果表明,FETI 模型在DuIE 数据集上召回率达到0.760,F1 值达到0.758。本文对实体关系的预测采用了基于多任务学习的方法,因此,如何更好地平衡不同任务损失函数之间的权重以及损失函数权重的可解释性问题将是后续研究的重点。此外,寻求多元的实体信息融合方式,更有效地表征其他实体相关的描述信息,也将是下一步的研究方向。
