最小相关系数的多元校正波长选择算法
2022-03-11程介虹陈争光衣淑娟
程介虹,陈争光,*,衣淑娟
1.黑龙江八一农垦大学信息与电气工程学院,黑龙江 大庆 163319 2.黑龙江省水稻生态育秧装置及全程机械化工程技术中心,黑龙江 大庆 163319
引 言
近红外光谱区(800~2 500 nm)的含氢基团的倍频和合频吸收带较宽且严重重叠,全谱建模定量分析会存在多重共线性或无信息变量过多导致模型性能不佳。因此,对全谱进行特征波长选择在一定程度上可以减少数据冗余和多重共线性,提高模型的预测精度和预测效率。特征波长选择一直是近红外光谱分析中的热点。
常用的近红外光谱特征波长选择方法包括:无信息变量消除法[1]、竞争性自适应重加权采样法[2]、间隔偏最小二乘法[3]、遗传算法[4]、连续投影算法[5]、随机蛙跳[6]、迭代保留信息变量法[7]等等。所有这些研究表明,使用特征波长代替全谱建模可以获得更好的预测精度,这说明波长选择的重要性。
众所周知,在近红外光谱的定量分析中,变量间的多重共线性问题是导致模型效果较差的一个关键问题。这是因为如果两个向量之间存在共线性,意味着两个向量具有相似的趋势并且有可能携带相似信息,这类变量的存在会降低模型的性能。变量间共线性可以通过相关性分析判断,相关系数高于0.8,表明存在多重共线性。所以,以变量间相关系数为选择标准,提出一种以所选变量之间共线性最小化,并且输入变量对响应变量影响最大化为主要目的的波长选择方法,称之为最小相关系数法(minimal correlation coefficient,MCC)。
我们将该算法应用于两组公开的近红外光谱数据集,并与其他常用波长选择方法,如:连续投影算法(successive projections algorithm,SPA)、竞争性自适应重加权采样法(competitive adaptive reweighted sampling,CARS)、随机蛙跳算法(random frog,RF)、迭代保留信息变量法(iteratively retains informative variables,IRIV)进行对比,以说明本方法的有效性。
1 算法原理
1.1 符号说明
矩阵用粗斜体大写字母表示,向量由粗体小写字母表示,变量(标量)用斜体字母表示。光谱数据矩阵表示为XN×K,响应(浓度)向量表示为yN×1,其中,N为样本数,K为波长数。下标变量i,j表示光谱矩阵的第i列、第j列,“^”符号代表预测值。
1.2 相关概念
1.2.1 向量间最小相关系数
在近红外光谱的定量分析中,多重共线性问题是导致模型效果较差的一个关键问题。对于多元线性回归模型来说,当变量之间不存在线性相关性,即参与建模的变量中的任一变量与其他变量间均不存在线性相关性时,模型的预测性能较优。反之,如果参与建模的变量中的任一变量与其他变量间存在线性相关性,则模型存在多重共线性。
皮尔森相关系数(Pearson correlation)是一种衡量向量之间线性相关性的指标,计算方法如式(1)所示。
(1)
式中,cov(x,y)为向量x和y的协方差,σx,σy为向量x和y的标准差,E(x),E(y)为向量x和y的期望。
皮尔森相关系数ρ取值区间为[-1,1],其绝对值是表征两个向量相关性的一个度量(表1)。如果两个向量之间的皮尔森相关系数ρ绝对值高于0.8,即可判定存在一定程度的多重共线性;而两个向量之间的皮尔森相关系数ρ绝对值小于0.4,那么两个向量弱相关。因此,向量之间皮尔森相关系数ρ的大小可以作为判断向量间共线性程度的一个度量。

表1 变量间相关系数所对应的相关强度Table 1 The strength of correlation corresponding to the correlation coefficient between variables
光谱数据矩阵XN×K可以看作是一个包含K个N维向量的向量组,每个向量代表了在特定波长下近红外光谱的吸光度特性。为了后面算法描述方便,在此用运算符r(·)表示两个向量之间的相关系数绝对值,r(xi,xj)与皮尔森相关系数ρ的关系如式(2)所示。r(·)具有特性:r(xi,xj)=r(xj,xi),r(xi,xi)=1,如果光谱矩阵进行了标准化处理,那么,r(xi,xj)=|cov(xi,xj)|。
r(xi,xj)=|ρ(xi,xj)| (i,j=1,2,3,…,K)
(2)
由上述理论可知,如果某一个波长与其余波长之间的相关系数r(·)均较小,则意味着该波长不能由其他波长线性表示,需要作为建模变量保留下来,这个波长即为关键波长。反之,如果一个波长与其余波长间的相关系数均较大,则意味着该波长与其余波长间存在多重共线性,不能作为建模变量,需要剔除。
那么,如何判断某一波长与其余所有波长之间的相关性均较小呢?首先计算矩阵XN×K中各列向量之间相关系数的绝对值,得到相关系数矩阵RK×K,其中第i列向量为XN×K中第i个波长xi与其他波长之间的相关系数(图1)。然后计算矩阵RK×K中各列向量的平均值r和标准差σ,选取平均值ri和标准差σi均较小的列对应的波长作为候选波长。这是因为,对于RK×K的第i列向量,其对应的ri较小不一定说明该列向量中的所有元素均较小,只有同时满足标准差σi较小时,才能说明RK×K中第i列相关系数向量各元素值均较小,且分布较为集中。此时XN×K中第i个波长应该保留下来作为建模候选波长。
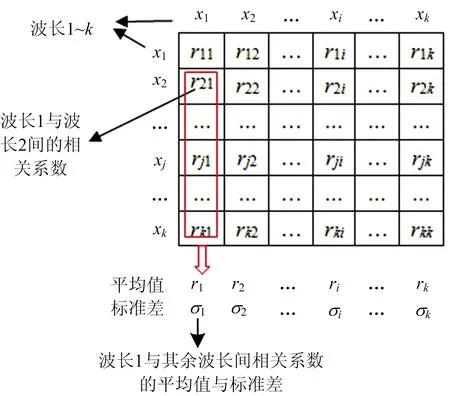
图1 相关系数平均值与标准差Fig.1 Average value and standard deviation of correlation coefficient
1.2.2 最大标准回归系数
由于通过MCC方法消除了变量之间的相关性,因此,可以建立基于MCC方法的波长选择结果的线性回归方程。假设线性回归方程的形式如式(3)
(3)
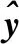
为了使不同变量的效应大小具有可比性,通常对回归系数βi进行无量纲化处理,将其按式(4)转化为一个无量纲的标准回归系数。
(4)
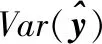
向前选择法是一种回归模型的自变量选择方法,其特点是把候选的自变量逐个引入回归方程,故称向前法。首先对符合最小相关系数准则的波长按如前所述计算得到标准回归系数bi,并按标准回归系数绝对值|bi|大小进行降序排列,然后按排列顺序每次将一个标准回归系数所对应的波长引入模型,建立线性回归模型,计算每个模型的均方根误差,以获得最小均方根误差所引入的变量为准得到一个最优模型。
1.3 算法步骤
根据上述理论基础,MCC具体算法步骤如下:
步骤1:利用通过式(2)计算光谱矩阵XN×K中各列向量之间相关系数的绝对值,得到相关系数矩阵RK×K;
步骤2:计算矩阵RK×K中各列数据除对角线元素之外的其他元素的平均值ri和标准差σi(图1);
步骤3:通过网格寻优法(后面详细说明),选择满足某一阈值条件的波长组成候选波长集S;
步骤4:以集合S中波长建立的MLR方程[式(3)],然后通过式(4)计算标准回归系数bi。对集合S中的波长按bi的绝对值降序排序,得到集合S′;
步骤5:对集合S′中的波长通过向前选择法建模获得该阈值条件下最小均方根误差模型;
步骤6:选择网格中的下一对阈值,重复步骤3—步骤5,直至完成网格寻优。
END:所有阈值条件下最小均方根误差对应的变量集合即为最终所选波长。
1.4 网格寻优
算法步骤3中的网格寻优法,具体操作表述如下:
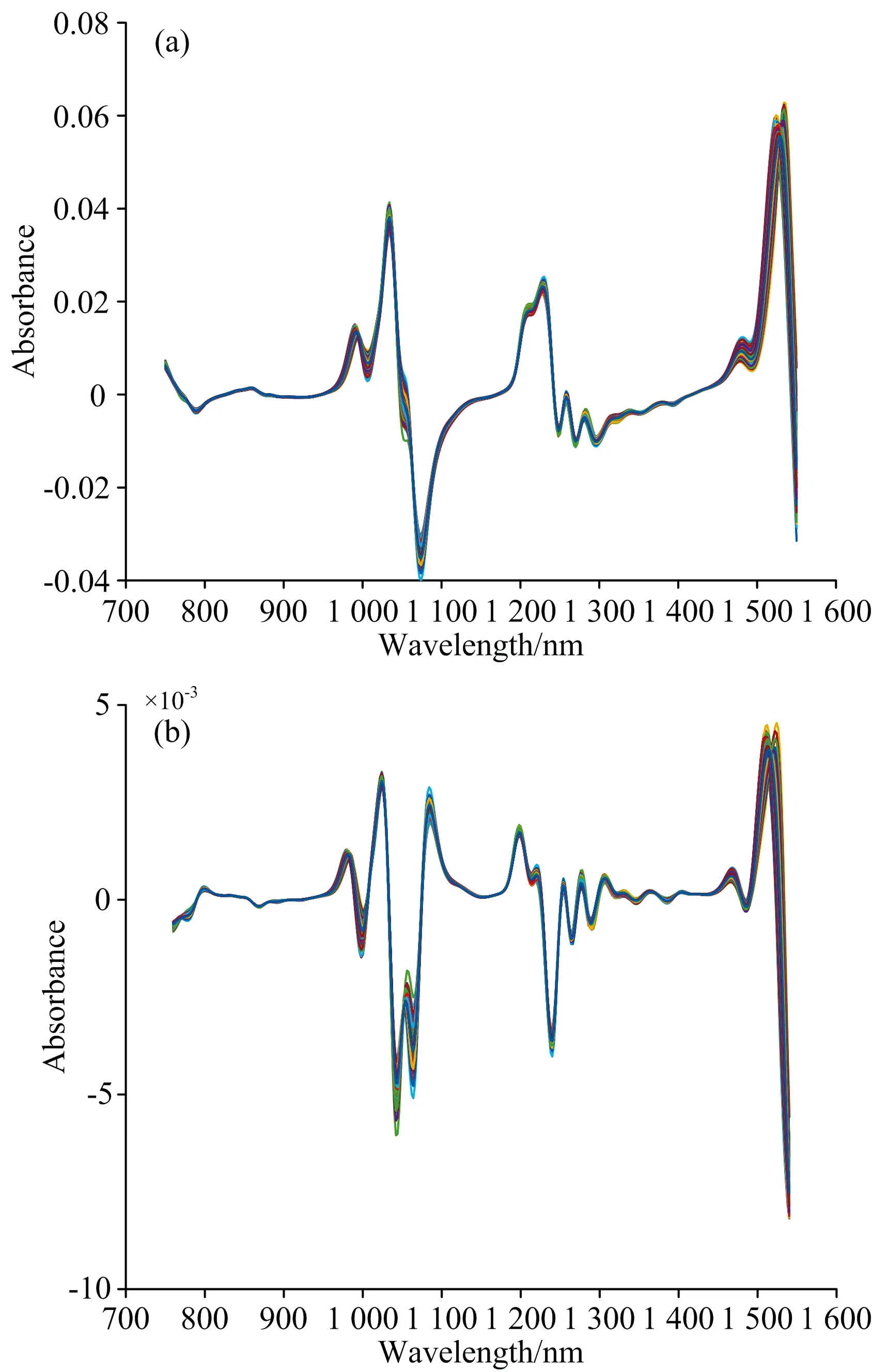
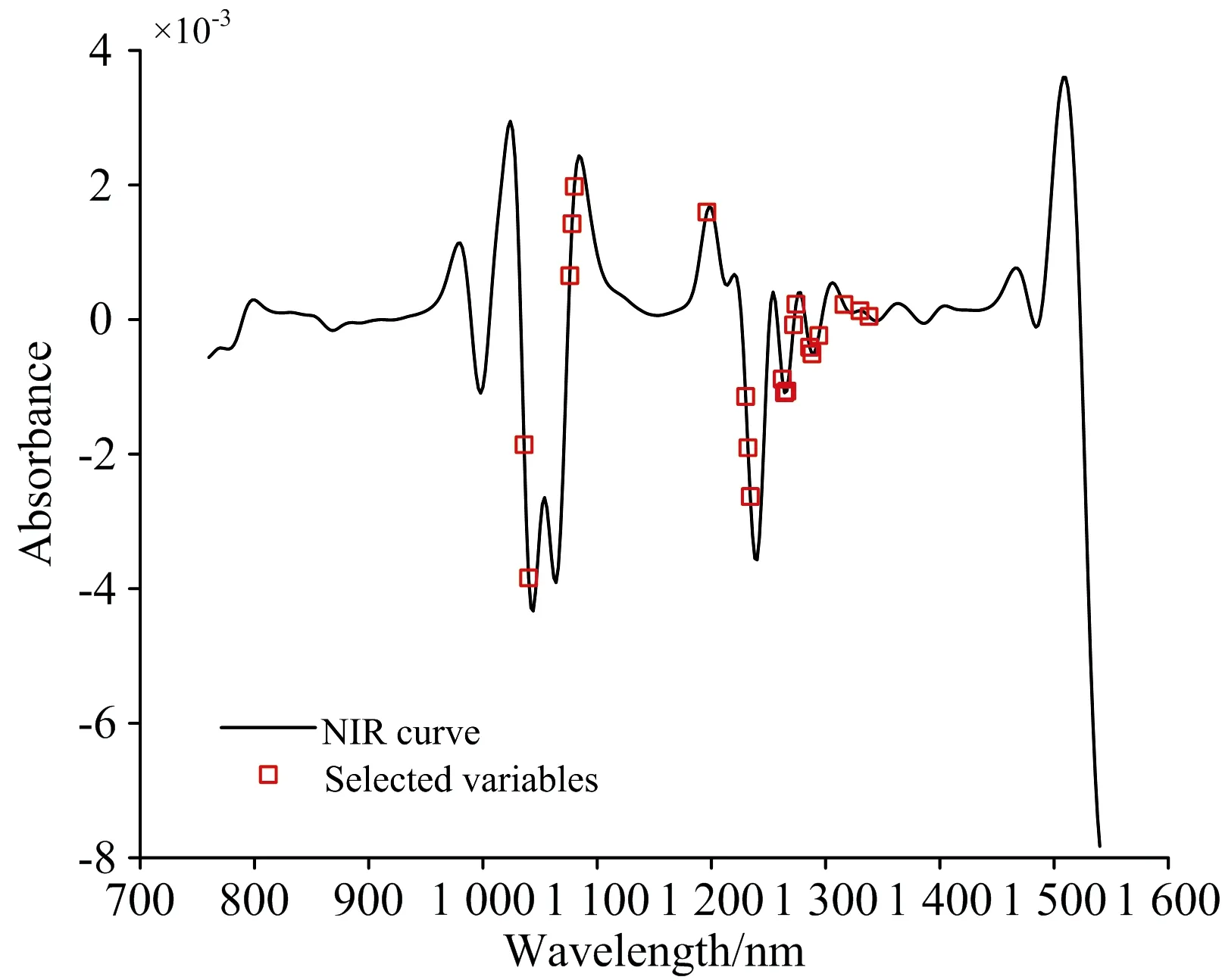
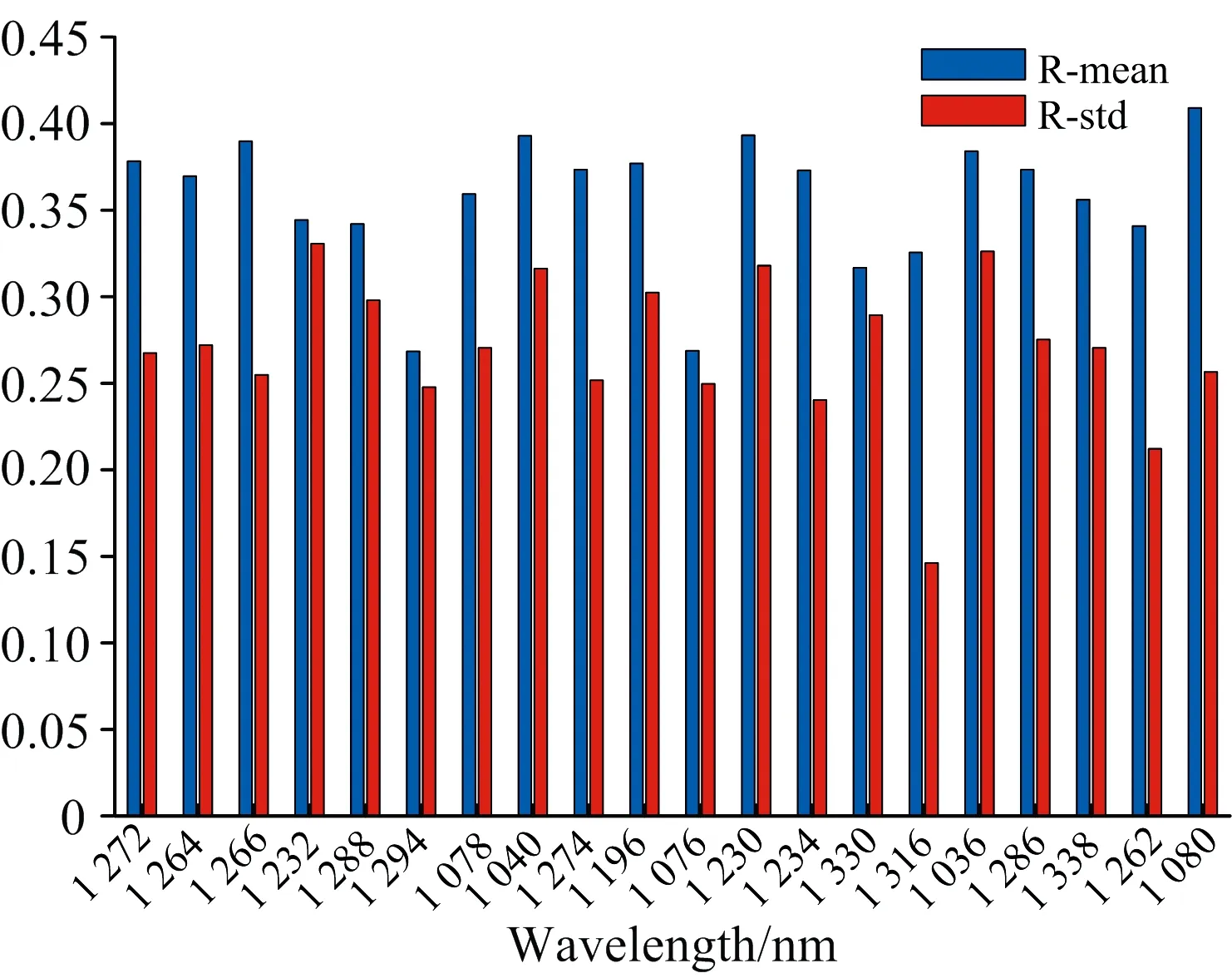
设阈值范围(rmin,rmax)=(min(ri),max(ri)),(σmin,σmax)=(min(σi),max(σi)),i=1,2,…,K,将阈值范围(rmin,rmax)和(σmin,σmax)划分为q×q均匀网格T,如图2所示。以网格T中每一个点(trm,tσn)(m,n=1,2,…,q)作为阈值对,从矩阵R中选择满足条件(r 图2 网格T阈值对图解Fig.2 Graphic analysis of threshold in grid T 注意,当m=1或n=1时,tr1=rmin,tσ1=σmin,因为rmin和σmin分别是相关系数的平均值的最小值和标准差的最小值,此时满足条件(r 同样,当m=q或n=q时,trq=rmax,tσq=σmax时,则所有的波长都满足条件(r 因此,取两个阈值系数thr1>1和thr2<1,令(rmin,rmax)=(thr1*min(ri),thr2*max(ri)),(σmin,σmax)=(thr1*min(σi),thr2*max(σi)),在此基础上生成网格矩阵T。这样,当满足条件(r 根据经验,阈值系数thr1和thr2的取值范围分别为1.3~1.6和0.7~0.9,这主要是根据数据的相关性确定的,并通过实验得到,阈值系数对波长选择的影响将在后面讨论部分进行详细阐述。 选取两个公共数据集进行试验:数据集1为一组柴油样本的近红外光谱数据,来自于Eigenvector网站,包含246个柴油样本,每条光谱有401个波长变量,光谱范围为750~1 550 nm。响应变量为柴油50%回收率下的沸点(BP50)值。 数据集2为一组土壤样本近红外光谱数据,来自于Quality &Technology网站,包含108个土壤样本,每条光谱有1 050个波长变量,光谱范围为400~2 500 nm。响应变量为土壤有机质(soil organic matter,SOM)的含量。 近红外光谱数据集被分为一个校正集和一个独立预测集。校正集用于建立校正模型,将校正集进一步划分为训练集(calibration set)和验证集(validation set),利用验证集对训练集的标定模型的误差进行评估,即验证集是用来指导选择候选波长子集变量个数的集合。独立的预测集(prediction set)用来评估所生成模型的性能,它不用于校正和验证程序的任何步骤。通过SPXY(sample set portioning based on joint x-y distance)算法将数据集划分为一个校正集(60%的样本)、一个验证集(20%的样本)和一个独立的预测集(20%的样本)。各数据集的样本集划分数及样本化学性质统计结果如表2所示。 表2 样本化学性质含量统计结果Table 2 Results of sample chemical property 偏最小二乘回归(partial least squares regression,PLSR)是光谱分析中常用的多元统计数据分析方法。PLSR适用于预测变量高度共线性,特别是当预测变量大于样本数时,该方法特别有效。然而PLSR通常存在潜在变量与原始变量相比难以解释的问题。 多元线性回归(multiple linear regression,MLR)是一种简单、常用的校正方法。MLR采用最小二乘法进行回归计算,其优点是方便解释波长变量对因变量的影响,利用该方法所得到的模型比PLSR模型更易于解释。但其缺点是存在多重共线性,当变量数大于样本数时无法实现,因此MLR一般在提取特征波长之后再建模。因为本文提出的MCC算法消除了变量之间的多重共线性,MCC波长选择结果适合通过MLR方法建模。 波长选择的一个最主要的目的就是提高模型的预测能力,而模型的预测能力主要通过模型的决定系数(R2)和均方根误差(root mean squared error,RMSE)指标来评价。其中,决定系数又称为拟合优度,取值范围为[0-1],R2越接近1,自变量对因变量的解释程度越高。RMSE用来衡量实测值与模型预测值之间的偏差,RMSE的值越小,说明模型预测精确度越高。 柴油数据的原始近红外光谱图如图3(a)所示,通过窗口宽度为11的Savitzky-Golay(S-G)一阶求导法进行预处理,预处理后的近红外光谱如图3(b)所示,后续的波长选择和建模均在图3(b)数据基础上进行。对原始光谱进行S-G导数预处理能够提高光谱分辨率,减少变量间的线性相关性,为后续的波长选择奠定基础。 图3 柴油样本原始近红外光谱图(a)和预处理后的近红外光谱图(b)Fig.3 Original (a)and Preprocessed (b)NIR spectra of diesel fuels sample 对于柴油数据,设置thr1=1.45,thr2=0.85,通过MCC方法选择20个变量,选择出的变量分布如图4所示。分别为1 272,1 264,1 266,1 232,1 288,1 294,1 078,1 040,1 274,1 196,1 076,1 230,1 234,1 330,1 316,1 036,1 286,1 338,1 262和1 080 nm。20个波长中,任一波长与其他19个侯选波长间的相关系数的平均值和标准差如图5所示,各波长与其余所选波长间的相关系数平均值在0.3~0.4之间,处于弱相关水平。标准差在0.2~0.3之间,相关系数相对集中。由此可见,所选变量之间弱相关,变量间的共线性较小。并且MCC选择的波长集中在1 100和1 200~1 300 nm附近,柴油是轻质石油产品,复杂烃类混合物,而烃类化合物是由碳与氢原子所构成的化合物。MCC方法选取的特征波长都处于C—H键的三倍频和二倍频吸收区域。 图4 MCC波长选择结果Fig.4 Wavelength selection results by MCC 图5 所选波长间的相关系数平均值与标准差Fig.5 Mean and standard deviation of correlation coefficient between selected wavelengths 为证明MCC波长选择算法的有效性,我们对数据集通过SPA,CARS,IRIV及RF算法进行波长选择,建立相应回归模型,比较预测精度。通过文献[8]可知,各方法的变量初始化、建模方法各不相同,如MCC是通过计算所有变量间的最小相关系数,建立MLR模型,选择最优变量;SPA是计算全部变量正交子空间上的最大投影值,建立MLR模型,选择最优变量;CARS是通过蒙特卡洛采样随机抽取80%的样本建立PLS模型;IRIV是通过二进制矩阵取样,建立PLS模型;RF是通过蒙特卡洛采样,建立PLS模型。根据各波长选择算法特点,对SPA和MCC建立MLR模型,对CARS,IRIV和RF建立PLSR模型,会获得较优的预测能力。 表3为MCC、全谱及四种常用的波长选择算法(SPA,CARS,IRIV和RF)所建模型验证集和测试集的模型结果。由表3可知,基于波长选择的回归模型的参数均不同程度地优于基于全谱的PLSR模型(FULL-PLSR),说明对全谱进行特征波长选择的重要性。对比可以发现,MCC相比于SPA,CARS和RF三种算法具有明显的优势,IRIV较MCC的预测集均方根误差略优,但在选择的变量个数上,MCC算法略有优势。这个结果进一步表明,MCC变量选择方法具有一定的有效性。 表3 基于柴油数据集不同波长选择方法下模型的参数Table 3 Model results based on different wavelength selection methods for diesel fuels datasets 将土壤数据的原始近红外光谱数据通过窗口宽度为11的S-G一阶求导法预处理后,分别通过MCC,SPA,CARS,IRIV及RF进行特征波长提取并建立回归模型,验证集和测试集模型结果如表4所示。由表4可知,MCC的预测集均方根误差相比于SPA,CARS和RF三种算法具有较优的预测精度,IRIV与MCC的预测效果不相上下。与数据集1所得结果一致,可以证明MCC方法的有效性。 表4 基于土壤数据不同波长选择方法下模型参数Table 4 Model results based on different wavelength selection methods for soil datasets Zhang等[9]在土壤数据集的基础上,利用SiPLS,SiPLS-GA和SiPLS-GA-SPA三种方法进行波长选择后的数据建立PLSR模型,其中基于SiPLS-GA-SPA波长选择结果建立的PLSR模型具有最佳预测精度,RMSEP=1.42。用MCC波长选择法建立的模型的RMSEP为1.032 3。相较而言,基于MCC的波长选择算法更具有优势。根据以往的研究结果可知,基于SPA方法的波长选择模型优于GA[10],CARS[11]和IPLS[12]等其他波长选择方法。由此可见,MCC算法在波长选择方面具有一定的优势。 从MCC算法可以看出,MCC和SPA的基本原理都是选择最少冗余信息和最小共线性的变量组合,不同的是,SPA是利用向量的投影分析,通过将多个向量投影到某个超平面(前一个投影向量的法平面)上,比较投影向量的模,选择模最小的向量作为待选向量,以此达到该向量与前一个向量的共线性最小。但是,SPA波长选择只考虑相邻两次选择波长之间的相关性,而不考虑所选择的波长和其他所选波长之间的相关性,即,SPA波长选择算法并没有考虑所有特征波长之间的共线性。 MCC算法以某一波长和其他所有波长间相关系数最小为准则选择特征波长,使得所选特征波长和其他所有波长之间相关性最小,从而达到降低共线性的目的。由于减少了所有特征波长之间的共线性,因此MCC波长选择的结果适合使用线性回归方法建模,所以MCC-MLR模型的预测精度较优。从前面两个数据集建模所得的结果来看,相较于其他波长选择算法所建模型的预测精度,MCC-MLR模型的预测精度较优,是一种有效的模型。MCC算法在应用于近红外光谱数据的波长选择具有一定的优势,本方法的设计思想可以为其他高维数据的特征选择和降维提供一定的参考。 根据算法步骤3,为了保证候选波长集S在某一阈值下不为空集,阈值系数thr1应大于1。另外,为了保证所选择的波长更有效,阈值系数thr2应小于1。为了获得更好的thr1和thr2,通过选择thr1和thr2的不同组合,得到MCC-MLR模型的RMSEV。图6为以土壤数据集为例得到的不同的thr1和thr2阈值系数取值情况下的模型RMSE分布情况。 图6 不同阈值系数下MCC-MLR模型的RMSEV值变化Fig.6 Changes in RMSEV value of MCC-MLR model under different threshold coefficients 从图6可以看出,随着thr2变大,RMSEV逐渐变小,当thr2大于0.8时,RMSEV趋于平缓,MCC算法的thr2取值为0.85。随着thr1的降低,RMSEV有下降趋势,在thr1=1.45附近取得最小值,以此,MCC算法的thr1的取值为1.45。对于柴油数据集来说,当thr1取值1.45,thr2取值为0.85时,MCC-MLR方法也能得到最小RMSE模型。因此,MCC设置thr1和thr2的默认值分别为1.45和0.85。对于其他数据集,两个阈值系数的取值可能有细微波动,可以通过实验确定。 针对变量间的多重共线性问题,提出一种基于最小相关系数的近红外光谱波长选择方法,该方法以所选变量之间共线性最小化,并且输入变量对响应变量的影响最大化为主要目的,消除模型间的共线性,提高模型预测精度。为了验证所提出算法的有效性,利用两组公开的近红外光谱数据集对该方法进行了测试。结果表明,MCC算法获得了良好的预测性能,是一种有效的波长选择算法。MCC方法可以为其他类型高维数据降维提供参考。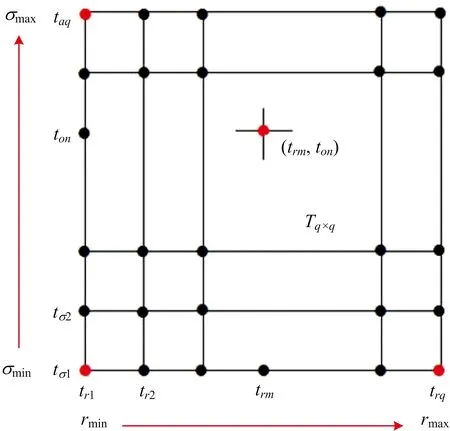
2 实验部分
2.1 样本数据集
2.2 样本集划分
2.3 模型建立与评价
3 结果与讨论
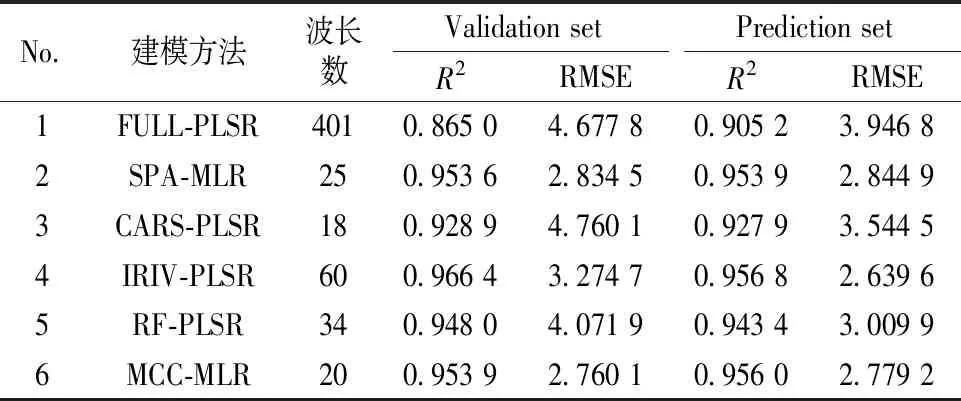
3.1 柴油数据结果
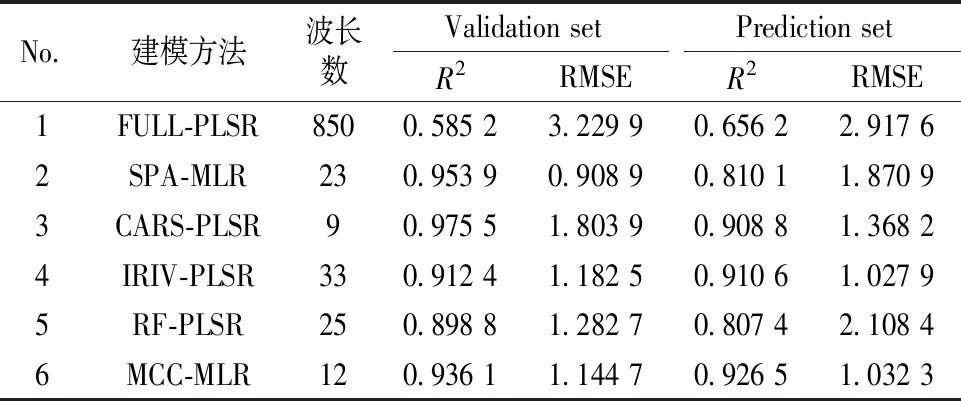
3.2 土壤数据
3.3 MCC方法优势分析
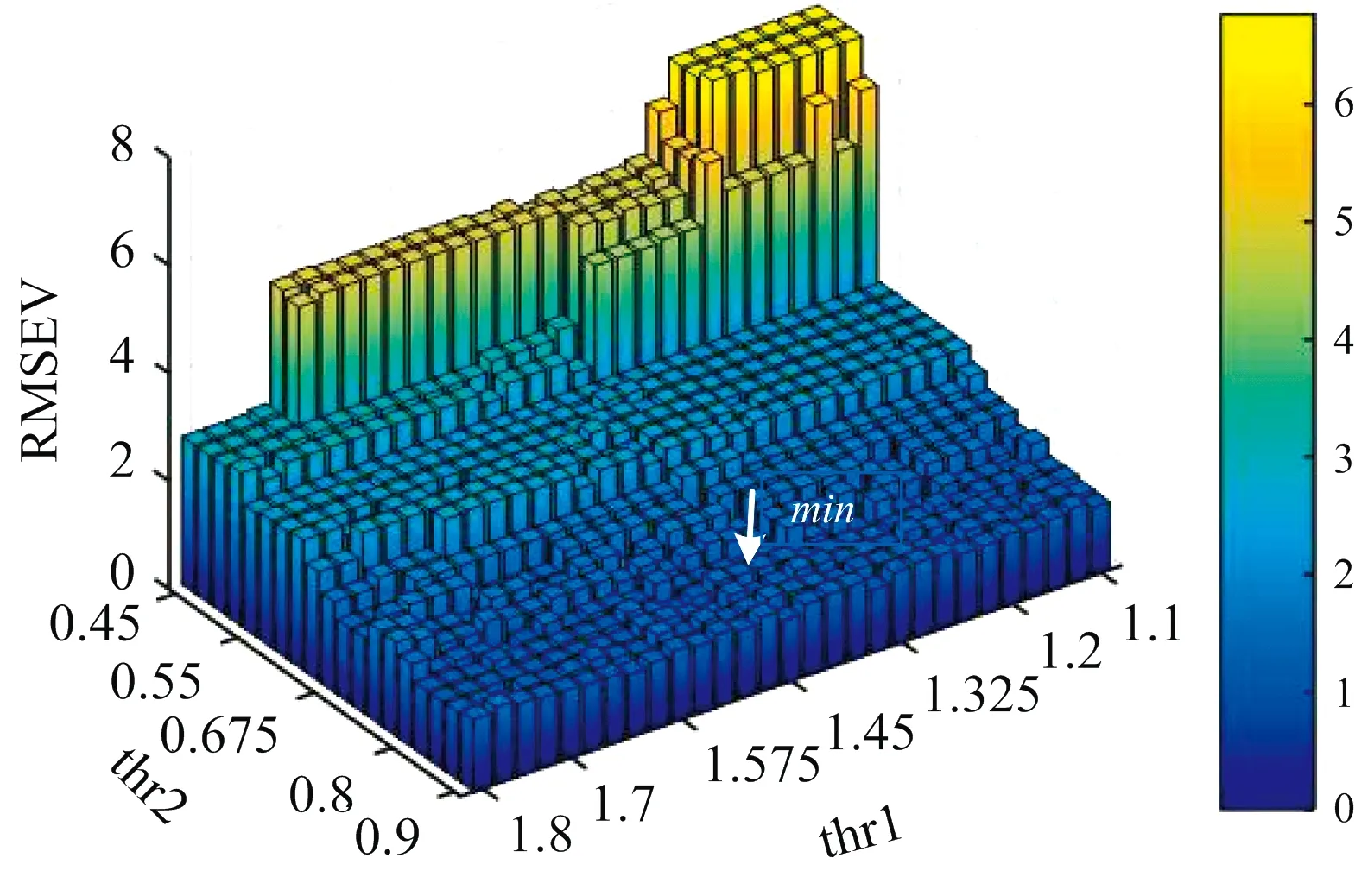
3.4 阈值系数的选取对MCC方法的影响
4 结 论
