生成式对抗网络的高光谱遥感图像分类方法研究
2022-03-09张健保文星
张健,保文星
1.北方民族大学计算机科学与工程学院,银川750021;
2.吕梁学院计算机科学与技术系,吕梁033001
1 引言
高光谱图像(HSI)通常包含数百个连续波段,为区分地物类别提供了可靠的依据(Qureshi 等,2019)。HSI 分类是许多高光谱遥感应用的基础(杜培军等,2016),已广泛应用于植被研究(Demarez,1999),精准农业(Teke 等,2013),大气环境监测(Yuen和Richardson,2010)等多个领域。
在过去的几十年中,国内外学者提出了大量的HSI 分类方法。如基于支持向量机(SVM)的分类方法(Camps-Valls等,2006),基于结构化字典的分类方法SADL(Soltani-Farani 等,2015),基于随机森林的分类方法CK-CSRF(Liu 等,2017),基于稀疏表示的HSI 分类方法KSPCK(Chen 等,2013)等。近年来,随着GPU 在深度学习领域的广泛应用以及GPU性能的不断提升,深度学习得到飞速发展,并在语音识别,自然语言处理和计算机视觉等众多机器学习任务中取得了令人瞩目的成就(Krizhevsky等,2012)。Chen等(2014a)首次将深度学习应用于HSI分类。深度学习可以利用GPU强大的运算能力提取最有利于分类的光谱特征。目前已有诸多基于深度学习的HSI 分类方法,如Zhong等(2018)提出的基于ResNet 的SSRN,Pan 等(2017)提出的R-VCANet,Chen等(2016c)提出的3D CNN,Chen等(2017)提出的Gabor-CNN 以及Zhao 和Du(2016)提出的MCNN 等。这些方法通过设计不同的网络结构试图提取更加精准的分类特征,一般都包括多个非线性隐藏层,使得它们具有强大的表征能力,可以学习输入和输出之间非常复杂的关系。然而,对于有限的训练样本,这种复杂的关系是采样噪声的结果,它们存在于训练样本但不存在于真实的测试数据中,这就导致了过拟合。而HSI标签获取成本高,标记样本较少,研究如何在少量训练样本的情况下抑制过拟合,进而提升分类精度具有重要意义(崔宾阁等,2017)。
目前,抑制过拟合的方法有数据集扩增,提前停止,集成学习,批量归一化(Batch Normalization(BN),L2 正则化,Dropout 等。数据集扩增后可以利用更多的规则来约束模型,使模型更接近于数据的真实分布,然而在实际应用中高光谱遥感图像标签获取成本高,标记样本较少,数据集扩增方法并不可行。提前停止通过设置约束条件,使网络在测试集准确率不再提升或测试集损失不再降低时停止训练,可以防止由于训练次数过多导致模型过拟合(Zur 等,2009),该方法没有从本质上提升模型的分类性能。集成学习将多个分类器通过某种策略组合起来,然后对每个基分类器的预测结果进行投票以确定最终类别,通常可获得比单一分类器更加优越的泛化性能(Giacinto 等,2000),但是集成学习没有研究单个分类器的过拟合问题。批量正则化在神经网络的每层之间加入将激活值调整成标准正态分布的正则化层,可以通过调整和缩放激活值来标准化输入层,达到平滑目标函数以抑制过拟合的目的(Ioffe 和Szegedy,2015),但是当一个批次中样本较少时,批量正则化的有效性就会降低(Ioffe,2017),而高光谱遥感图像样本较少,批量正则化难以充分发挥作用。L2 正则化在损失函数中加入惩罚项,防止参数过大,使模型泛化能力更强(Burden 和Winkler,2008),但L2正则化对参数的约束不依赖于输入数据,对过拟合的抑制效果存在局限性(Cogswell等,2016)。Dropout在训练过程中,通过随机丢弃神经元来模拟具有大量不同网络结构的单一模型,可以有效抑制单一模型过拟合的问题,但实验过程中需要设置的参数较多,而参数的调节又与具体的数据集和网络模型有关,实际应用中Dropout 难以达到理想的效果(Srivastava 等,2014)。由此可见,上述方法虽然有效抑制了过拟合,但都存在一定的局限性,过拟合仍然是导致当前分类模型泛化能力较弱的主要原因之一。
Goodfellow 等(2014)提出一种新的深度学习模型:生成式对抗网络(GAN),并迅速成为各大领域研究的热点,随后衍生出针对不同任务的改进GAN,如Chen 等(2016b)提出的InfoGAN,Mao等(2017)提出的LSGAN,Arjovsky 等(2017)提出的WGAN 等。GAN 通常用于生成,如超分辨率任务,语义分割等。Salimans 等(2016)提出了一种基于GAN 的半监督分类方法,为GAN 在分类领域的应用提供了一种新的思路。目前,已经提出了多种基于GAN 的HSI分类方法,Zhan 等(2018)首次将GAN 应用于HSI 分类,提出了HSGAN 分类模型,随后Zhu 等(2018)提出了基于光谱特征的分类方法1D-GAN 以及基于光谱空间特征的分类方法3D-GAN,Zhong 和Li(2018)提出了基于GAN和概率图模型的分类方法SS-GAN。这些方法取得了很好的分类效果,但都是通过判别器和生成器的对抗来增强判别器表征数据分布的能力,对抗依据的是无标记样本和伪样本,并没有从标记样本的角度来解决过拟合问题,而过拟合时网络拟合的是标记样本,优化网络对标记样本的拟合效果能够更加有效地抑制过拟合,提升分类精度。
本文受对抗思想的启发,提出一种基于GAN的高维特征均值最小化(HFAM)过拟合抑制算法。利用优化函数对神经网络输出层前一层特征的均值进行最小化,以减小网络参数。较小的网络参数能够有效抑制过拟合(Cogswell 等,2016)。该算法在GAN判别器每次迭代训练样本的过程中,首先依据标签信息使判别器网络拟合标记样本的数据分布,然后利用优化器对标记样本的高维特征均值进行最小化处理,该过程会重新更新网络参数,减小参数的值和方差,防止过拟合。最终,通过合理设置拟合和对抗拟合过程的学习率,判别器会达到最优的拟合效果。
2 本文算法
2.1 算法整体框架
大量研究表明,GAN 能够很好地适用于分类任务。本文针对HSI 的特点设计了一种基于GAN的HSI 分类模型。算法框架如图1所示,首先在标准数据集的有标记像元中按比例选取训练样本和测试样本,并将训练样本拆分为标记样本和无标记样本。然后对所有样本构造空间邻域块,并将标记样本和无标记样本输入所设计的分类模型进行训练,使用测试样本进行测试。训练过程中,判别器将标记样本映射到正确的类,将无标记样本判断为真,将生成器生成的伪样本判断为假,通过判别器和生成器的不断对抗,增强判别器的判别能力。每次迭代过程中,在判别器通过标记样本的标签信息更新判别器网络参数后,利用HFAM再次更新网络参数,以抑制当前批次标记样本的拟合效果,防止过拟合。最后当测试样本的准确率不再提升时停止训练,用训练好的模型对HSI进行分类,得到分类结果。

图1 本文算法框架Fig.1 Algorithm framework
2.2 判别器网络结构
HSI通常包含数百个波段,其中某些波段可能会受噪声干扰,影响分类精度(张康等,2018)。人工剔除噪声工作量较大,且易受主观经验影响。全连接网络可以连接HSI的每一个波段,通过网络自主学习每个波段的权重,从而减少异常波段的干扰。另外,HSI中存在大量同质区域,同一区域中的像元极有可能是同一类地物(Wu 等,2016)。合理利用空间特征可以在有限训练样本的情况下提升分类准确率。基于此,本文设计了一种简单高效的判别器网络结构,有效利用HSI的光谱和空间特征。判别器网络结构如图2所示,首先将三维邻域块数据(k×k×b)按像元拆分成k2个一维向量(1×b),其中b为HSI的波段数量,k2为邻域块中像元的个数,然后将每个一维向量(1×b)分别独立输入三层全连接网络(每层神经元个数分别是1024,1024,512),提取每个像元的光谱特征,再将特征数据(1×512,k2)转换为(k×k×512),用平均池化进行特征融合,得到(1×512)的一维特征向量,最后连接到输出层得到分类结果。

图2 判别器网络结构Fig.2 Discriminator network structure
2.3 GAN分类算法
GAN 包括一个判别器D和一个生成器G。D用于判别数据是否来自真实数据分布,G用于生成尽可能真实的数据去欺骗D,在理想状态下,G可以生成判别器无法判断真假的数据。该过程可以表示为
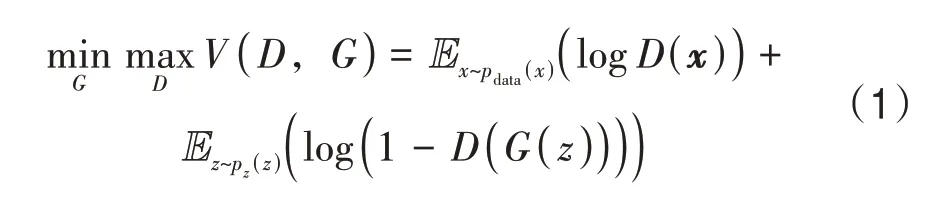
式中,x为真实数据,Pdata(x)为x的概率分布,D(x)为D将x判断为真的概率,z为噪声数据,P(z)为z的概率分布,D(G(z))为D将伪数据G(z)判断为真的概率,V(D,G)为损失函数。
将GAN 应用于分类任务中,可以使用任何标准的深度学习分类模型,只需将G生成的伪样本添加到训练样本中,并用y=K+ 1 标记,相应地增加判别器的输出维数K到K+ 1。对于未标记样本,最大化logpmodel(y<K+ 1|x)使其对应于K类真实数据之一。用于训练GAN的损失函数为

式中,L为总损失,Lsupervised为有监督分类的损失,Lunsupervised为无监督分类的损失。为将x分到正确类的概率,为将x判断为假的概率。
2.4 抑制过拟合
过拟合是导致基于深度学习的分类模型准确率难以提升的主要原因之一(Srivastava 等,2014)。存在过拟合的原因是选择模型的标准与判断模型是否合适的标准不同。例如,可以通过最大化训练数据集的分类性能来选择模型,但其适用性取决于该模型在测试数据上的表现能力,当模型开始“记忆”训练数据而不是“学习”它的分布时,就会发生过拟合。
过拟合时拟合函数需要顾及每一个样本,越复杂的模型,其参数受噪声的影响越严重,当模型复杂性增加时,通常偏差减小,方差增加(Lever等,2016)。在对神经网络模型进行拟合时,通常利用随机梯度下降和训练数据集来学习网络参数,网络训练时间越长,参数与训练数据的匹配度越高,对训练数据的拟合也越好,与此同时,为了适应训练数据中单个数据点的突然变化、不连贯或其他高维现象,网络参数将增大(Hammer,2001)。减小参数的值和方差可以缓解拟合函数在小范围的波动,达到抑制过拟合的目的(Burnham 和Anderson,2002),但参数过小又会导致拟合函数无法有效拟合数据的分布。依据奥卡姆剃刀法则,需要寻找一个最简单的模型(网络参数最小),使网络的拟合效果达到最优。
基于此,本文受对抗思想的启发,提出一种新的过拟合抑制算法HFAM,判别器网络一方面根据标记样本的标签信息拟合数据的分布;另一方面通过对标记样本的高维特征均值最小化并反向更新网络来减小网络参数的值和方差,以抑制判别器的拟合效果,抑制过拟合的过程为

式中,xi为训练样本,θ为网络参数,N为一次迭代的样本数量,f为模型的高维输出,本算法中代表的是平均池化层的输出,是一个一维特征向量。在本文提出的模型中,3 个全连接层都使用ReLU 激活函数,每一层的输出都是非负数,故f也为非负数。最小化f中特征的平均值,可以使网络参数减小,抑制拟合过程,同时可以减小网络参数的方差,使参数更加平滑。平滑的网络参数会充分考虑每个波段的特征,不太依赖某些局部特征,泛化能力更强。抑制过拟合算法流程为


3 实验及结果分析
3.1 数据集
本文使用的是两个具有不同光谱和空间分辨率的真实高光谱遥感数据集Indian Pines 和Pavia University。
(1)Indian Pines 数据集是最早用于HSI 分类的测试数据,由AVIRIS 传感器1992年在印第安纳州西北部农业区成像并截取145×145大小的图像进行标注得到的印度松树数据集。波长范围为0.4—2.5 μm,空间分辨率为20 m,共包含220 个波段,但第104—108、150—163 和第220 个波段受水汽吸收的影响信噪比较低,去除这20 个波段之后,保留了200 个波段。该数据集共有21025 个像元,其中10249个像元是有标签的,有标签像元共包括16 种地物类别,最多的一类有2455 个像元,最少的一类只有20 个像元。Indian Pines 数据集假彩色图片,真实地物类别图及各类样本数量如图3所示。

图3 Indian Pines数据集Fig.3 Indian Pines dataset
(2)Pavia University 数据集是由意大利帕维亚大学的ROSIS 传感器2003年在意大利帕维亚城市上空成像并截取610×340大小的图像进行标注得到的数据集。波长范围为0.43—0.86 μm,空间分辨率为1.3 m,共包含115 个波段,在去掉12 个受噪声影响的波段后,保留了103个波段。该数据集共有207400 个像元,但其中只有42776 个像元是有标签的,有标签像元共包含9种地物类别,最多的一类有18649 个像元,最少的一类有947 个像元。Pavia University 数据集假彩色图片,真实地物类别图及各类样本数量如图4所示。

图4 Pavia University数据集Fig.4 Pavia University dataset
3.2 实验设置
本实验在配备Intel i7 2600k CPU、8 G 内存和Nvidia GTX 1080 GPU 的PC 机上运行。使用Window 7×64 操作系统,Spyder 开发环境,Tensorflow 框架,Python 编程语言。判别器网络主要包括3 个全连接层和1个平均池化层,生成器网络主要包括两个反卷积层和3个卷积层。判别器和生成器都使用Adam 优化器,学习率为0.0002,batch size 为16。所有实验都按比例选取训练样本,并且无标记训练样本数量均为有标记训练样本的5倍,其余为测试样本。由于选取的训练样本较少,使用不同训练样本得到的实验结果差异较大,所有实验结果均为随机选取训练样本并运行10次的平均值。
3.3 与其他分类算法对比
为了测试本文算法的分类性能,两个数据集每类都选取1%标记样本(至少一个),与基于SVM 的分类方法(Camps-Valls 等,2006),基于内核的极限学习机KELM(Chen等,2014a),最近正则化联合稀疏表示NRJSR(Chen等,2016a),基于结构化字典的SADL(Soltani-Farani 等,2015),基于卷积神经网络的3D CNNs(Chen 等,2016c)、MCMs+2DCNN(He 等,2019)、MCNN(Zhao 和Du,2016)进行比较。使用总体分类精度(OA)、平均分类精度(AA)、Kappa 系数作为评价指标。Indian Pines 数据集的分类准确率如表1所示,Pavia University 数据集的分类准确率如表2所示。从表1 可以看出,16类地物中有9类地物的分类准确率高于其他几种分类方法,从表2 可以看出,9类地物中有5类地物的分类准确率高于其他几种分类方法,并且两个数据集的总体分类精度、平均分类精度及Kappa 系数都高于其他几种分类方法。与分类效果最好的MCNN 进行比较,Indian Pines数据集总体分类精度提升了5.17%, Pavia University 数据集总体分类精度提升1.38%,说明本文算法在训练样本较少的情况下能够得到理想的分类结果。
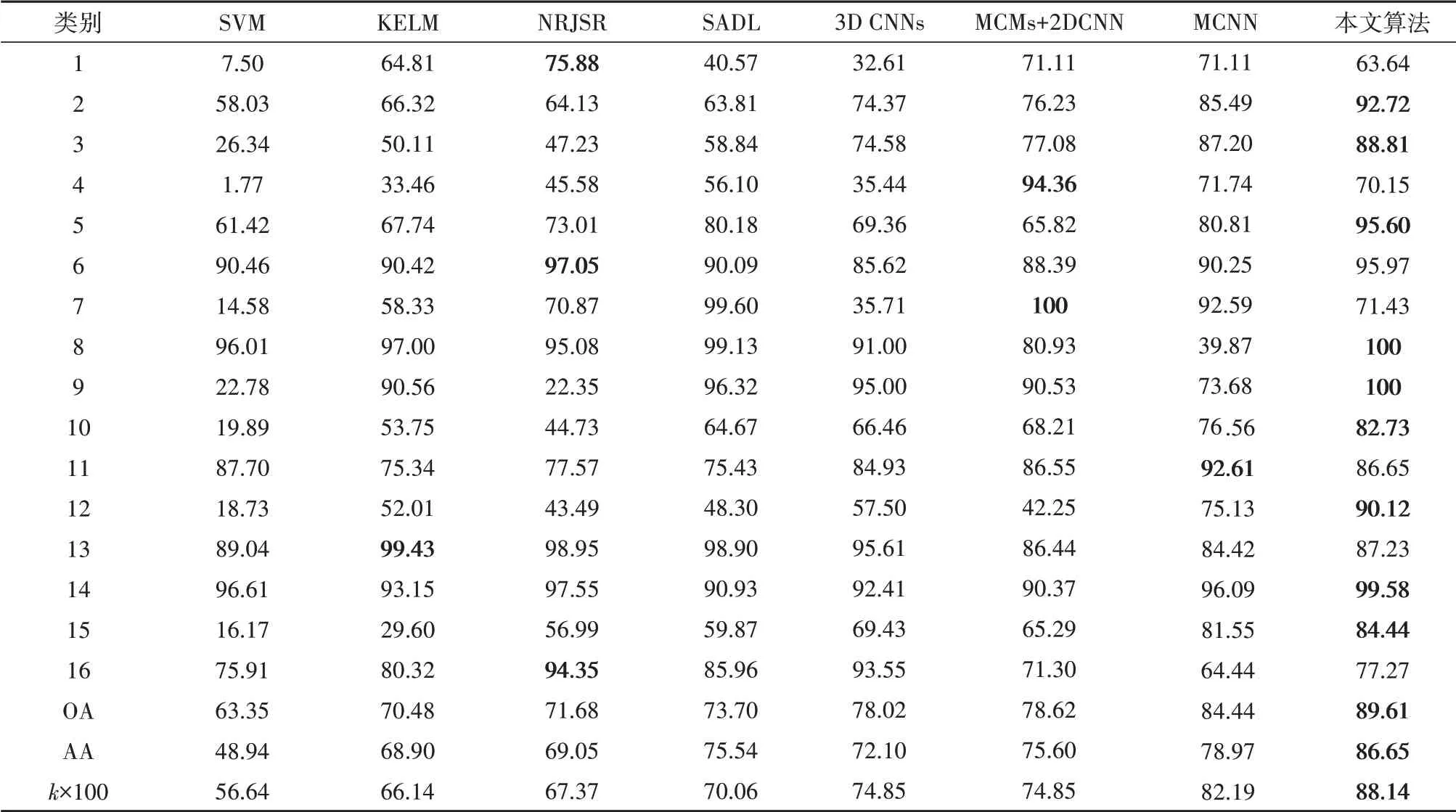
表1 Indian Pines数据集不同算法的分类准确率Table 1 Classification accuracies of different methods for Indian Pines dataset/%
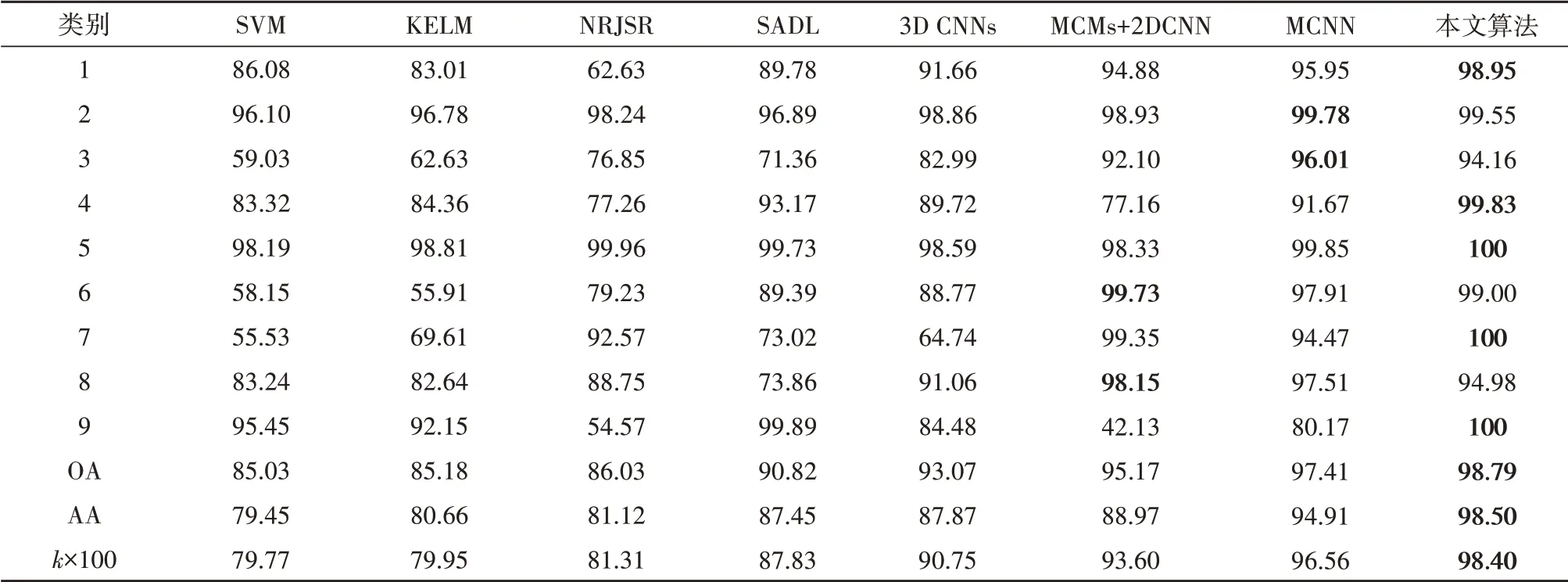
表2 Pavia University数据集不同算法的分类准确率Table 2 Classification accuracies of different methods for Pavia University dataset/%
3.4 鲁棒性验证实验
为了验证本文算法的鲁棒性,用两个具有不同波段数目,不同光谱分辨率和空间分辨率的标准数据集进行实验。Indian Pines 数据集分别随机选取0.5%、1%、2%、4%训练样本。由于Pavia University 数据集样本数量多,且光谱质量较高,Pavia University 数据集分别随机选取0.1%、0.4%、0.7%、1%训练样本。Indian Pines 数据集总体分类精度分别为81.00%、89.61%、95.42%、97.64%,Pavia University数据集总体分类精度分别为88.53%、96.75%、97.54%、98.79%,均达到了理想水平。Indian Pines 数据集取不同比例训练样本的分类准确率如图5所示,Pavia University 数据集取不同比例训练样本的分类准确率如图6所示。从图6 中可以看出,两个数据集的总体分类精度,平均分类精度以及Kappa系数随着标记样本数量的增加都不断提升,说明本文算法在不同数据集和不同数量训练样本的情况下,均能够获得稳定的分类结果。Indian Pines 分类结果如图7所示,Pavia University分类结果如图8所示。图8 中上半部分为对有标签像元的分类结果,下半部分为对整副图像的分类结果。从图中可以看出,随着训练样本数量的增加,错分像元都逐步减少。

图5 Indian Pines数据集分类准确率Fig.5 Classification accuracies for Indian Pines dataset

图6 Pavia University数据集分类准确率Fig.6 Classification accuracies for Pavia University dataset
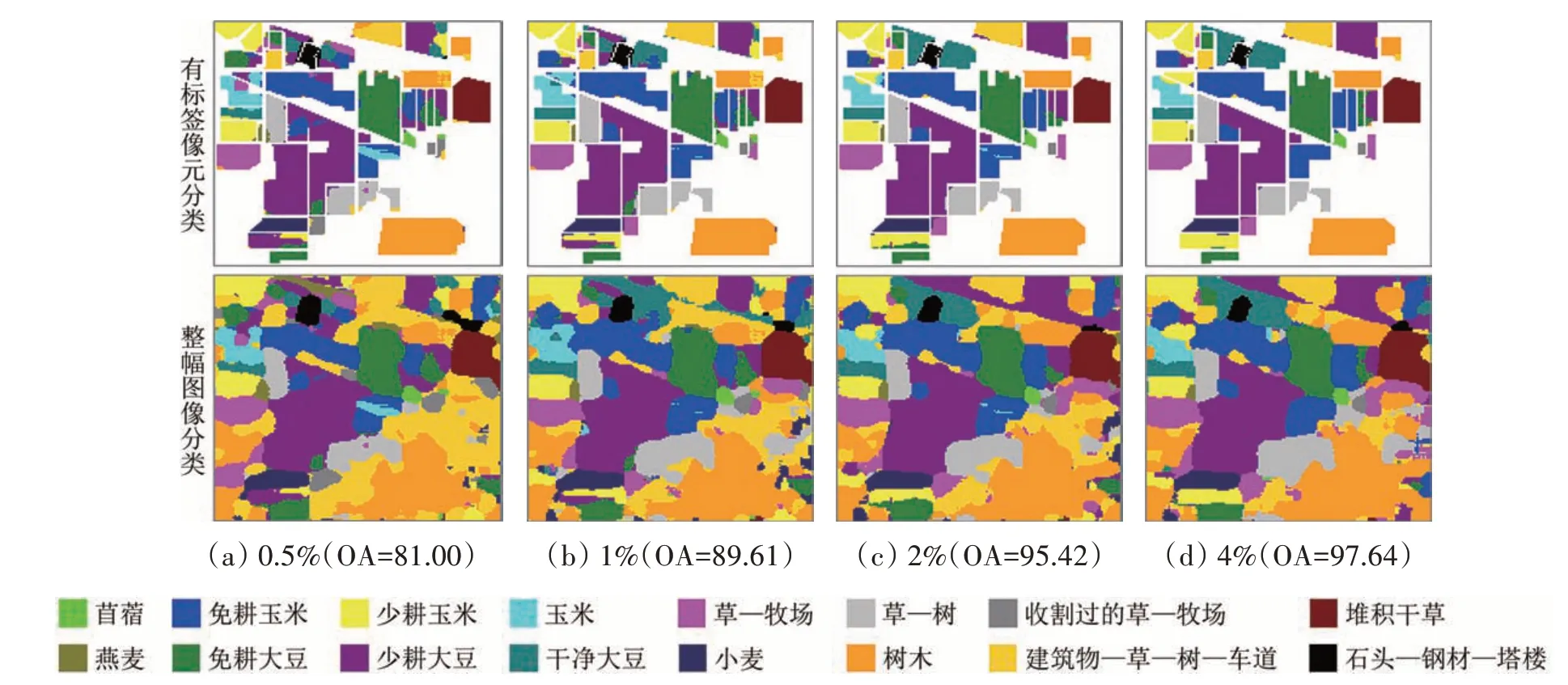
图7 Indian Pines数据集不同比例标记样本分类结果图Fig.7 Classification maps provided by different proportions of labeled samples on the Indian Pines dataset
3.5 空间特征测试实验
HSI 的空间特征表示某个像元与其周围像元很有可能是同一类地物,因此,合理利用空间特征将有助于提升分类准确率。为了验证本文所提出的模型对空间特征提取的有效性,两个数据集都取1%标记样本,采用不同大小的邻域块分别进行实验。Indian Pines 数据集分类准确率如图9所示,Pavia University 数据集分类准确率如图10所示。从图10 中可以看出在引入空间特征后,随着邻域块大小的增加,两个数据集的分类准确率都先上升后下降。Indian Pines 数据集在邻域块选择7×7 时准确率达到最高,比邻域块选择1×1,即未使用空间特征时,总体分类精度提升了32.23%,平均分类精度提升了30.91%,Kappa系数提升了36.89%。Pavia University 数据集在邻域块选择9×9 时准确率达到最高,比邻域块选择1×1,即未使用空间特征时,总体分类精度提升了11.82%,平均分类精度提升了13.84%,Kappa 系数提升了15.82%。实验结果充分验证了该模型对HSI 空间特征提取的有效性。分类准确率先上升后下降的原因是扩充邻域块后可以用更多的特征来表征地物,但邻域块越大,邻域块中异类像元的数量可能越多,异类像元会干扰邻域块表征地物的能力。

图9 Indian Pines数据集分类准确率Fig.9 Classification accuracies for Indian Pines dataset
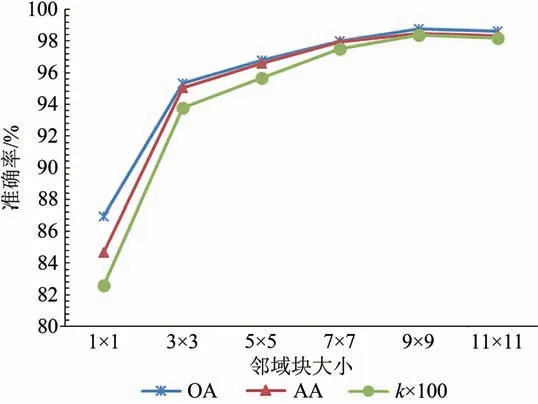
图10 Pavia University数据集分类准确率Fig.10 Classification accuracies for Pavia University dataset
3.6 过拟合抑制实验
在少量训练样本的情况下,基于深度学习的分类模型通常会遭受潜在的过拟合影响,导致模型在训练集上的分类准确率很高,而在测试集上的分类准确率不够理想。合理减小参数的值和方差可以有效缓解过拟合(Ioffe,2017)。在深度学习分类模型中通过使权重趋近于0来减小参数,达到抑制过拟合的目的(Cogswell 等,2016)。为了验证本文过拟合抑制算法HFAM 对参数约束的有效性,在GAN 分类模型中分别使用BN、L2 正则化、Dropout 与本文过拟合抑制算法HFAM 进行比较。通过TensorBoard 可视化工具对Indian Pines 数据集训练过程中模型参数的变化过程进行可视化,用直方图的形式显示每次迭代后参数的分布情况。不同方法参数的变化情况如图11所示,图中横坐标为参数的值,纵坐标为迭代次数,第1列为激活值的变化情况,第2 列为偏置的变化情况,第3 列为权重的变化情况。从图中可以看出,未使用过拟合抑制方法的权重分布在-0.02—0.14,使用BN后权重分布在-0.03—0.09,使用L2后权重分布在-0.03—0.07,使用Dropout 后权重分布在-0.025—0.045,使用HFAM 后权重分布在-0.012—0.016,权重分布的范围越来越窄,说明不同的过拟合抑制方法都使权重一定程度的向0靠近,而本文算法效果更加明显。同时,本文给出了偏置和激活值的变化情况,从图中可以看出BN、L2 正则化、Dropout 没有对偏置进行约束,HFAM 使偏置趋近于0,激活值取决于权重和偏置,在权重减小后激活值也同时减小,并且由于使用ReLU 激活函数,激活值非负。
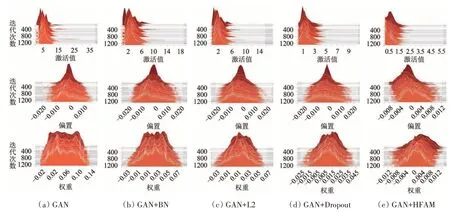
图11 不同方法参数的变化情况Fig.11 Variation of parameters in different methods
为了验证所提出过拟合抑制算法HFAM 的有效性,Indian Pines 数据集随机选取1%标记样本,Pavia University 数据集随机选取0.1%标记样本,分别使用BN、L2正则化、Dropout以及HFAM进行过拟合抑制实验。Pavia University 数据集分类准确率如表3所示,Indian Pines 数据集分类准确率如表4所示,加粗数值代表各类最高分类准确率。从表3 可以看出,Pavia University 数据集使用GAN 分类模型的总体分类精度为81.55%,在使用BN 后准确率提升了1.99%,使用L2 正则化后准确率提升了2.85%,使用Dropout后准确率提升了3.78%,使用HFAM 算法后准确率提升了6.98%。从表4 可以看出,Indian Pines 数据集使用GAN 分类模型的总体分类精度为79.92%,在使用BN 后准确率提升了2.51%,使用L2 正则化后准确率提升了3.30%,使用Dropout 后准确率提升了4.09%,使用HFAM 算法后准确率提升了9.69%。并且两个数据集中数量最少的地物分类准确率提升的最多,而数量较多的地物分类准确率提升的较少,充分说明HFAM算法在训练样本较少的情况下,能够有效抑制过拟合,提升分类准确率。Indian Pines 和Pavia University数据集使用不同方法的准确率变化情况分别如图12 和图13所示,红点代表训练结束,也就是训练结束后模型的准确率。Pavia University 和Indian Pines 数据集分类结果分别如图14 和图15所示。
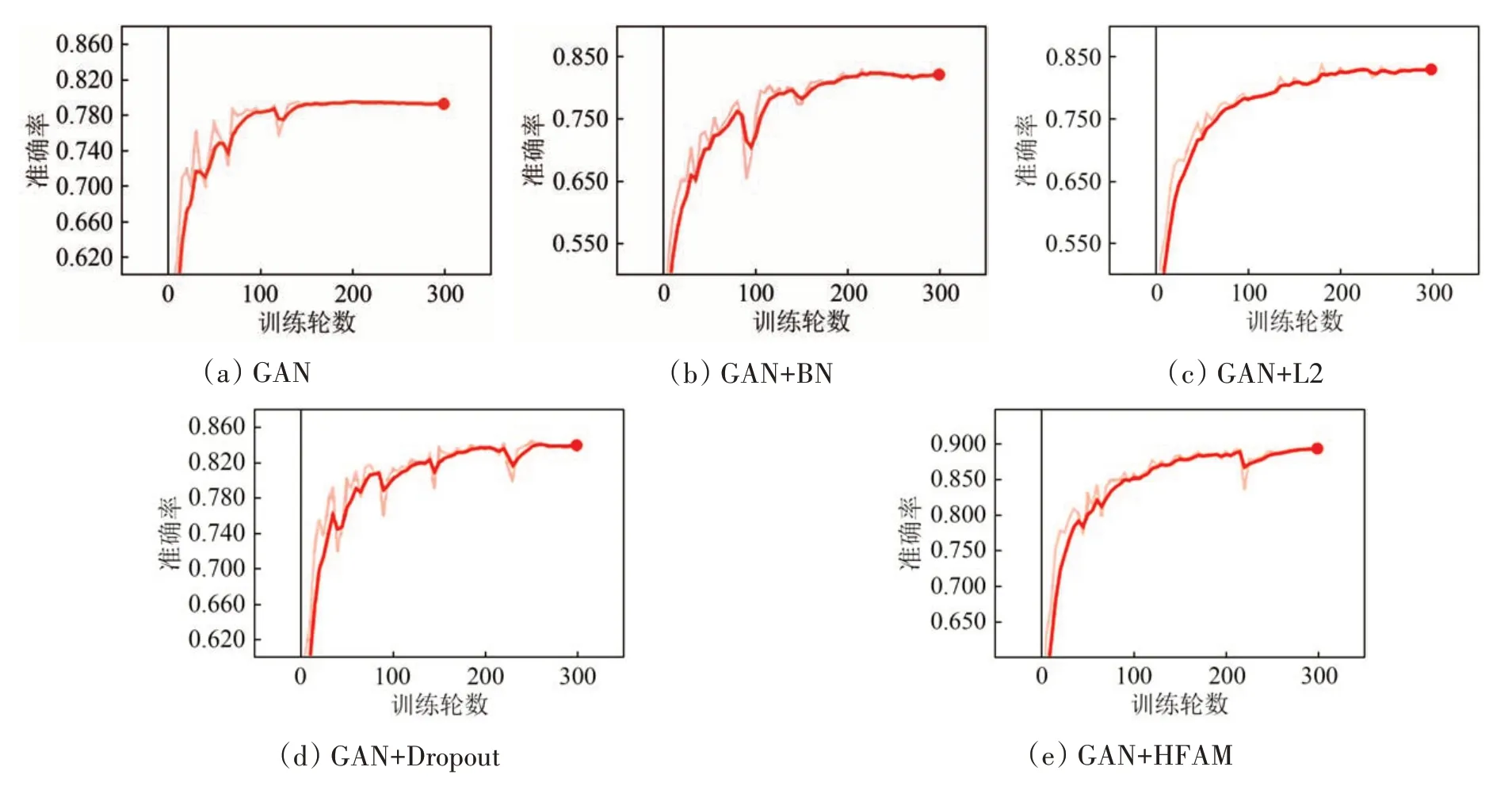
图12 Indian Pines数据集准确率变化情况Fig.12 Variation of the accuracy of Indian Pines dataset
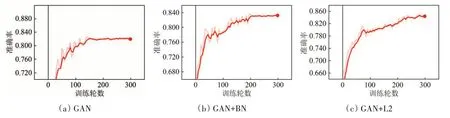
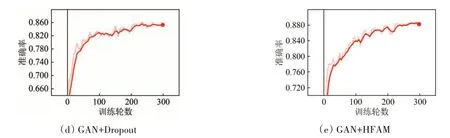
图13 Pavia University数据集准确率变化情况Fig.13 Variation of the accuracy of Pavia University dataset
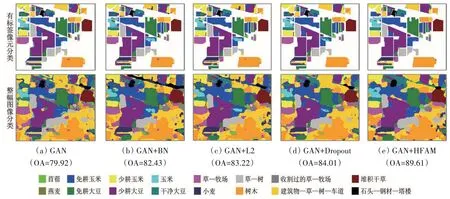
图15 Indian Pines数据集取1%标记样本不同方法的分类结果图Fig.15 Classification maps provided by different approaches with 1%labeled samples on the Indian Pines dataset

表3 Pavia University数据集分类准确率Table 3 Classification accuracies for Pavia University dataset/%
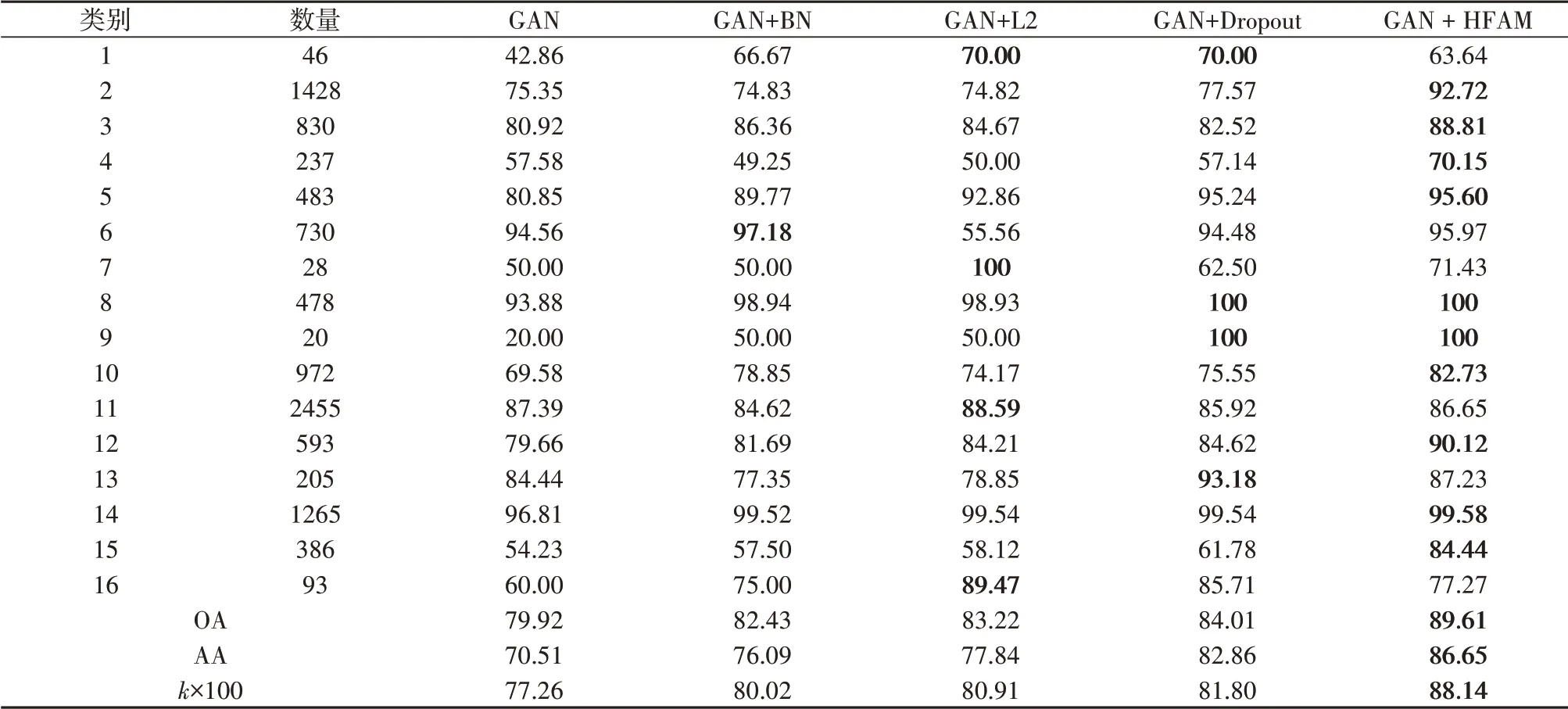
表4 Indian Pines数据集分类准确率Table 4 Classification accuracies for Indian Pines dataset/%
4 结论
本文通过分析深度学习模型产生过拟合的原因,利用对抗思想在过拟合和欠拟合之间寻找平衡点,解决了高光谱遥感图像在使用深度学习模型进行分类时,由于训练样本较少而导致分类准确率较低的问题。通过分析高光谱遥感图像的光谱特征和空间特征,设计了更加高效的网络结构。首先利用全连接网络提取邻域块中各个像元的光谱特征,然后用平均池化对空间特征进行融合,提高了特征提取的效率,减少了深度学习模型训练的时间。通过在两个不同数据集上进行的实验验证了本文所设计网络结构的高效性和鲁棒性,说明在设计深度学习网络结构时充分分析数据的特性是必要的。通过与其他过拟合抑制算法对比,验证了本文过拟合抑制算法的先进性,说明在网络模型拟合数据的过程中,利用对抗思想抑制拟合过程能够改善拟合效果,防止过度拟合。
深度学习模型通常包含大量的参数,能够拟合复杂的输入特征,但是当训练样本较少时,无约束地拟合训练样本会导致过拟合现象严重,即使训练样本较多的情况下,过拟合现象也普遍存在。通常抑制过拟合的方法是减小参数的值,认为小的参数值能够使模型更加平滑,对输入数据的拟合效果更好。然而,真实数据的分布情况复杂多变,该方法对过拟合抑制的作用存在很大的局限性。并且,产生过拟合的原因不仅是模型参数的值较大,模型参数的方差较大也是导致过拟合的原因之一,只减小参数的值难以达到理想的效果。此外,该类方法没有针对输入数据的特征来抑制过拟合,对分布较为复杂的数据难以有效发挥作用。本文通过对模型高维特征均值最小化,并与拟合过程不断对抗,不仅合理减小了模型参数的值和方差,还充分考虑了输入数据的真实分布情况。在两个标准数据集Indian Pines 和Pavia University 上进行的实验表明,本文算法比目前表现最好的过拟合抑制算法,准确率分别提高了5.60%和3.20%。
实验中发现本文算法在训练样本较多时对过拟合的抑制效果不够明显,并且在训练样本较少时,训练误差和测试误差相差还比较大。下一步工作将针对深度学习模型过拟合问题进行更加详细的理论研究,并在不同类型的数据集上进行实验,进一步提高高光谱遥感图像在少量训练样本情况下的分类准确率。
