联合GEE与多源遥感数据的黑龙江流域沼泽湿地信息提取
2022-03-09宁晓刚常文涛王浩张翰超朱乾德
宁晓刚,常文涛,王浩,张翰超,朱乾德
1.中国测绘科学研究院摄影测量与遥感研究所,北京100036;
2.山东科技大学测绘科学与工程学院,青岛266590;
3.南京水利科学研究院水文水资源与水利科学国家重点实验室,南京210029
1 引言
湿地仅覆盖地球陆地表面积的3%—8%,但它却是减少全球温室气体和减轻气候变化的最重要的因素之一,并且极大地影响了生物多样性和水文联系(Mitsch 等,2013)。湿地的生态系统服务功能包括调蓄洪水,改善水质,维持海岸线稳定,保持水生植物生产力,维持野生动植物种群续存等(Mitsch 和Gosselink,2000)。但是由于人类活动和自然过程的影响,湿地面积正加速萎缩(Ozesmi 和Bauer,2002)。因此,对湿地进行快速准确的监测是当前湿地研究的热点(Shalaby 和Tateishi,2007)。
相对于传统的野外调查,遥感技术具有观测范围广,更新周期短,信息量大等优点,在湿地信息提取及变化监测方面发挥了重要作用。但是在大尺度范围利用遥感数据进行准确的湿地信息提取仍具有挑战性。光学影像作为最主要的遥感数据源,受到云雨等天气影响很大,经常形成无效观测。云污染对重访周期较长的中高分辨率卫星数据影响更为显著,对于大尺度区域和阴雨天气较多的南方地区更易造成数据缺失。基于微波的合成孔径雷达(SAR)弥补了光学影像的不足,其对云层具有很强的穿透能力,可以不受天气影响对地表进行全天时全天候观测。雷达后向散射系数对地物的介电特性敏感,对植被含水量和土壤含水量以及地表的几何特性如粗糙度具有不同的响应,可以提供不同于光学影像的独特信息(王安琪等,2012)。此外,利用地形地貌特征对提取某些湿地类型,如灌丛湿地和森林湿地具有重要作用(严婷婷等,2014)。研究表明,光学、雷达以及地形数据的结合使用可以发挥多源遥感数据优势互补的作用,光谱信息和散射机制的结合对湿地信息提取有着巨大的潜力。刘蕾等(2013)结合Landsat TM 影像、C 波段的ENVISAT ASAR 以及地形辅助数据对扎龙湿地进行分类,发现雷达后向散射系数和地形辅助数据对湿地分类精度的提高起到重要作用。Dubeau 等(2017)使用了Landsat、L 波段ALOS PALSAR 以及地形数据对埃塞俄比亚的达布斯湿地进行分类,光学、雷达和地形数据的结合取得了最佳的总体分类精度。Limpitlaw 和Gens(2006)研究发现,单独使用光学或SAR 数据识别开阔水体、淹水植被和非淹水植被时,精度并不理想,而将两者结合时可以显著提高这3种地物的识别精度。然而在这些研究中鲜有将光学、SAR、地形特征进行横向对比,以评价它们对沼泽湿地信息提取的重要性差异。
近年来,随着欧洲空间局“哥白尼”计划(Copernicus Programme)的启动,先后发射了12 d重访周期(双星协同可达6 d)的Sentinel-1 合成孔径雷达(SAR)卫星和10 d重访周期(双星协同可达5 d)的Sentinel-2 多光谱卫星。这为全球湿地制图提供了前所未有的机会,高重访周期有效地减轻了云污染的影响。并且,Sentinel-2 是目前唯一一个在红边范围内含有3个波段的多光谱传感器,这对监测植被健康信息非常有效(Shoko 和Mutanga,2017)。Chatziantoniou 等(2017)使用Sentinel-1 和Sentinel-2 数据与支持向量机(SVM)对希腊的科洛尼亚国家公园和沃尔维湖进行土地覆盖制图,重点关注湿地类,取得了93.85%的总体精度。Whyte 等(2018)协同使用Sentinel-1 和Sentinel-2 数据和面向对象(OBIA)方法采用支持向量机和随机森林算法对iSimangaliso 湿地公园进行土地覆盖制图,Sentinel-1 和Sentinel-2 的联合使用显著提高了湿地制图的精度。其他研究也表明了Sentinel-1 和Sentinel-2 在湿地研究方面的巨大潜力(Yesou 等,201)。此外,由于数据量和机器性能的限制,融合多源数据实现省级乃至更大范围的高频次观测仍然面临很大困难。使用基于工作站的常规遥感影像处理软件在收集、存储和处理覆盖大尺度区域长时间序列的遥感数据方面效率低下(Teluguntla等,2018)。随着高级机器学习工具的开发以及强大的云计算资源的集成,有效的解决了现有方法和产品的局限性,为地理空间科学在新的时空尺度上开展更广泛的应用提供了新的机遇(Hird 等,2017)。Google Earth Engine(GEE)是一个开放式的云计算平台,拥有海量历史遥感影像数据存档,借助谷歌公司强大的计算资源实现PB 级遥感数据的高性能并行运算(Gorelick 等,2017)。用户通过调用GEE 提供的Python和JavaScript 应用编程接口API(Application Programming Interface)实现对云端海量数据的访问,结合其提供的算法实现在线计算和结果可视化等操作。凭借此优势,GEE 可以大大减少数据获取和处理的工作量,已经成为地理空间科学研究的重要工具(Gorelick 等,2017)。孟梦等(2019)使用GEE 平台生产了白洋淀湿地1987年—2017年的NDVI 和NDWI 数据集并对其湿地生态系统景观进行分类。Mahdianpari 等(2019)利用GEE 平台和Sentinel-1 和Sentinel-2 数据对纽芬兰岛进行湿地分类,他们发现光学和SAR 的结合可以显著提高湿地分类的准确性,运用基于对象的随机森林(RF)分类可以实现88.37%的总体精度和0.85 的Kappa 系数。Amani 等(2019)使用GEE 和机器学习算法利用Landsat 8 和Sentinel-1 数据基于有限的实测样本绘制了加拿大3个省的湿地地图,总体准确度分别为84%,78%和82%。常文涛等(2020)研究了Sentinel-2 红边特征和Sentinel-1 雷达特征对小范围湿地提取的作用,但在更大的范围上特征适用性问题需要进一步研究。
综上,尽管光学、SAR 和地形等多源数据结合已被用于湿地信息提取,但鲜有将光学、SAR等众多特征进行横向对比,定量评价各个特征对于沼泽湿地信息提取的作用,以寻找有利于沼泽湿地提取的最优特征组合。为此,本文借助GEE云平台,将Sentinel-1SAR、Sentinel-2 光学和地形数据以及机器学习算法相结合,对中国境内黑龙江流域沼泽湿地进行提取。设计了多种分类方案,探讨了红边、雷达以及地形特征对大范围区域沼泽湿地提取的重要性,验证了利用JM 距离寻找最优特征的可行性。鉴于全国湿地类别的特征相似性,希望未来能够将本文的方法用于更大的尺度以在全国范围内进行沼泽湿地信息提取。
2 研究区概况
本文的研究区为黑龙江流域(中国境内)(41°42′N—53°33′N,115°25′E—135°2′E),文中所有黑龙江流域均特指位于中国境内的部分。黑龙江跨蒙古国、中国、俄罗斯3国,中国境内流域面积约为89万km2,占流域总面积的48%。黑龙江流域有着中国最大的沼泽湿地,河流、湖泊等水资源丰富。黑龙江流域水系以黑龙江为干流,主要支流有松花江、乌苏里江、嫩江等(崔茂欢,2006)。流域跨温带和寒温带两个气候带,年均气温在-8—6 ℃。年均降水量为250—800 mm,主要发生在6—9月,约占全年降水量的70%(鄢波等,2019)。
3 材料与方法
3.1 数据来源及预处理
研究中使用的所有遥感数据均由GEE 平台在线调用和处理,具体包括Sentinel-2 卫星的多光谱数据,Sentinel-1 卫星的后向散射系数,SRTM 数字高程数据以及训练样本数据。
根据已有研究(Lin 等,2015;Song 等,2011),使用训练样本做监督分类时,若训练样本与研究区域的范围和时相相对应时,大气校正并不是必须的。考虑到2018年GEE 上Sentinel-2 的地表反射率数据覆盖不全,因此Sentinel-2 数据使用的是L1C级的大气表观反射率(TOA)产品。由于研究区范围巨大(89 万km2)以及云污染的影响,在短时间内(例如一个月)难以获取覆盖研究区范围的数据。因此,使用2018-08—2018-10创建了光学合成影像,选择此时间段是因为它提供了最多的无云数据并且处于植被生长期,可以保留更多的湿地植被信息。在此期间内共获得了Sentinel-2 影像2942 景。为了减轻云污染的影响,在合成无云影像时对云量百分比进行了限制(<20%)。然后使用Sentinel-2 云掩膜算法对指定时间和空间范围内影像进行计算,以中值合成方法重构最小云量合成影像。受益于GEE 平台的数据运算和管理机制,研究中使用的所有遥感数据均采样至10 m,并且GEE 通过内嵌算法统一坐标系确保不同数据源之间的几何配准精度。
Sentinel-1 数据使用的是干涉宽幅模式(IW)的地距多视产品(GRD),分辨率为10 m。通常,Sentinel-1在极地地区收集全极化即HH、HV、VH和VV 数据,而在其他地区只收集VH 和VV 数据。因此本研究共获取2018-08—2018-10 VH 极化数据433 景,VV 极化数据407 景。然后通过调用GEE 预处理模块完成轨道参数定标、热噪声去除、辐射定标和地形校正等操作。通过上述步骤将无单位的后向散射强度图像转换为后向散射系数值(以dB 为单位)。虽然SAR 影像不受云雨等天气条件的影响但是其受观测角度影响较大,即距离成像中心越远的像元噪声越强。因此预处理后的SAR 数据逐像元计算其在时间范围内的中位数,以减小噪声的影响。
分类结果的精度与训练样本的数量、分布和代表性显著相关。根据黑龙江流域土地覆盖情况结合相关文献(方利等,2017)将研究区土地覆盖类型分为沼泽、水田、人工地表、旱地、盐碱地、林地、明水面7类,其中沼泽、水田和明水面是湿地的主要类型。采用随机采样的方法在研究区生成样本点,利用2018-08—2018-10 Google Earth 等高分辨率影像对样本点进行目视解译,得到的样本总数为6649 个,其中用于训练和验证的比例为7∶3,分别为4673 个和1976 个。最终各类型样本数量如表1所示。

表1 样本采集情况Table 1 Situation of sample collection/个
3.2 研究方法
3.2.1 技术路线
本文的技术路线如图1所示。首先对2018-08—2018-10 Sentinel-2 影像进行最小云量合成,结合SRTM DEM 数据提取的坡度和高程特征以及Sentinel-1 雷达数据提取的VV 和VH 后向散射系数特征进行波段合成、研究区裁剪。为了说明红边、雷达和地形特征的作用以及有利于沼泽湿地提取的最佳特征设计6 种实验方案:光谱特征+植被指数+水体指数(方案1),光谱特征+红边特征(方案2),光谱特征+地形特征(方案3),光谱特征+雷达特征(方案4),光谱特征+植被指数+水体指数+红边特征+地形特征+雷达特征(方案5),特征优选(方案6)。利用样本点进行随机森林分类和精度评价,对精度最高的实验方案进行分类器参数调优,最后得到分类结果。

图1 技术路线Fig.1 Technical scheme
3.2.2 特征集构建
选取光谱特征、植被指数、水体指数、红边指数、地形特征以及雷达后向散射系数构建特征集,各个特征的详细说明见表2。需要说明的是,Sentinel-2 包括3 个红边波段,为了说明红边波段的作用将红边波段与红边指数一起作为红边特征。
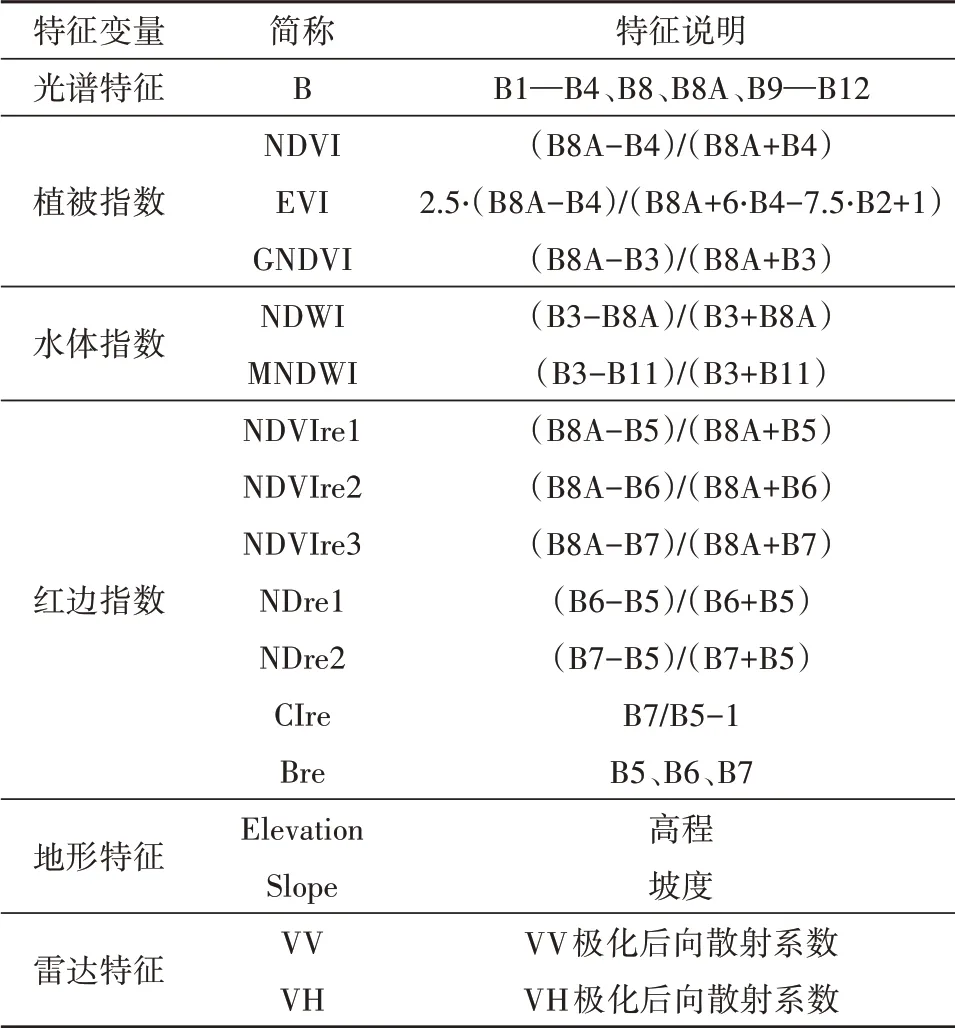
表2 特征说明Table 2 Description of the features
3.2.3 特征优选
采用JM 距离(Jeffries-Matusita distance)对沼泽与其他地类的可分性进行定量分析,并据此确定最佳特征组合。JM 距离是衡量类别间分离度的有效工具(张猛和曾永年,2015),表达式为
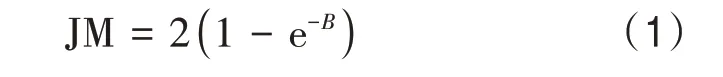
式中,B表示某一特征的巴氏距离。在样本满足正态分布的前提下,不同类别样本的巴氏距离B(Bhattacharyya distance)为

式中,ek表示某类特征的均值,表示某类特征的方差(张猛等,2017)。JM距离表示样本间的可分离程度,其值在0—2,值越大表示分离性越好。
3.2.4 随机森林分类
本研究采用随机森林(RF)算法用于黑龙江流域湿地分类。RF 是一种非参数分类器,由一组决策树组成,能够处理高维遥感数据(Belgiu 和Drăguţ,2016)。与其他的机器学习算法如决策树(DT)和支持向量机(SVM)相比,它更加稳健并且易于使用(Rodriguez-Galiano 等,2012)。随机森林的构建过程为:首先使用bootstrap非参数抽样方式从原始训练样本集中有放回的随机抽取样本生成训练样本集合进行训练得到决策树模型。假设每个样本有M个特征,之后在决策树的每个结点处从M个特征中随机抽取m(m≪M)个进行结点分裂;由于随机森林是一种集成学习方法,不容易出现过拟合现象,因此在决策树构建过程中不需要进行剪枝(何云等,2019)。重复上述步骤k次得到由k个决策树模型组成的随机森林,每个分类样本的分类结果由k个决策树通过多数表决的方式决定。
随机森林的效果通过两个参数来调整,即决策树的个数k和结点使用的特征数m。根据之前的研究(Belgiu 和Drăguţ,2016),当特征数使用以下值时(树的个数固定为500):(1)特征总数的三分之一;(2)特征总数的平方根;(3)特征总数的二分之一;(4)特征总数的三分之二;(5)所有特征,分类精度的变化很小。因此根据文献(Breiman,2001)的建议,将结点特征数设置为特征总数的平方根,研究中调用GEE 平台提供的随机森林算法并对决策树的个数进行调整。
3.2.5 精度评价
利用混淆矩阵和从Google Earth 等高分辨影像采集的样本点(表1)对黑龙江流域湿地分类进行精度验证。计算总体精度、Kappa系数、制图精度和用户精度,总体精度反映了算法的总体效果,通过正确分类的样本数占验证样本总数的比例来衡量。Kappa系数表示地面真实数据和预测值之间的一致性程度。制图精度表示该类别的地面真实参考数据(验证样本)被正确分类的概率。用户精度表示在该次分类中,在分类图上,落在该类别上的检验点,被正确分类为该类别的比率(Congalton,1991)。
4 结果与分析
4.1 特征优选分析
基于GEE 平台取得每个类别的样本均值计算JM 距离对特征集内所有特征进行可分性分析,本研究关注的是不同特征对沼泽湿地信息提取的重要性,因此只计算沼泽同其他土地覆盖类型的JM距离。利用JM 距离作为衡量不同特征沼泽同其他地类的分离程度的标准,按照分离度由高到低依次增加特征,观察沼泽的制图精度变化(图2)。当特征数为21 时沼泽的制图精度达到最大,之后随着特征继续增加沼泽精度开始趋于稳定并有所下降。因此使用前21 个特征作为方案6 使用的特征,具体为B6、B11、B4、B2、NDVIre2、MDWI、
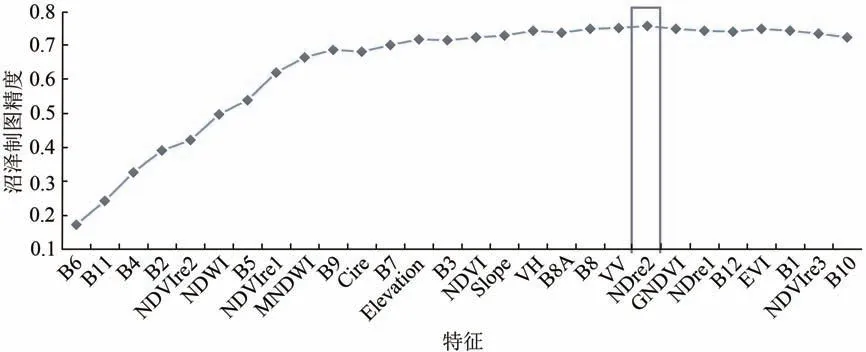
图2 沼泽制图精度随特征变化情况Fig.2 Variation of marsh producer accuracy with features
B5、NDVIre1、MNDWI、B9、CIre、B7、Elevation、B3、NDVI、Slope、VH、B8A、B8、VV、NDre2。开始随着所用特征的增加,沼泽制图精度呈快速增长趋势,当使用特征数为10 时即能达到最优精度的90.74%。
对前21 个特征的JM 距离进行分类统计分析,将光谱特征、植被指数和水体指数作为其他光学特征类别,得到表3。4 类特征中分离度最高的是红边特征,其次是其他光学特征、地形特征、雷达特征。红边特征中分离度最高的是红边波段B6,分离度最低的是红边指数NDre2。红边特征与植被的生化信息(如叶面积指数、叶绿素含量等)息息相关(Dubeau 等,2017),相比其他特征更能凸显植被种间差异,有利于植被茂密繁杂的沼泽区域的识别。雷达特征中,VH 交叉极化后向散射系数能获取更多的植被结构信息,分离度上要高于VV 极化后向散射系数。雷达特征在四类特征中的分离度最低,但仍对沼泽湿地信息提取起到积极作用。

表3 不同类型特征的Jeffries-Matusita(JM)距离Table 3 Jeffries-Matusita(JM)distance between different types of features
4.2 6种方案分类结果比较
图3 展示了6 种分类方案的分类结果,经过特征优化的方案6取得了最好的分类效果,分类结果碎片化的现象明显少于其他几种分类方案。
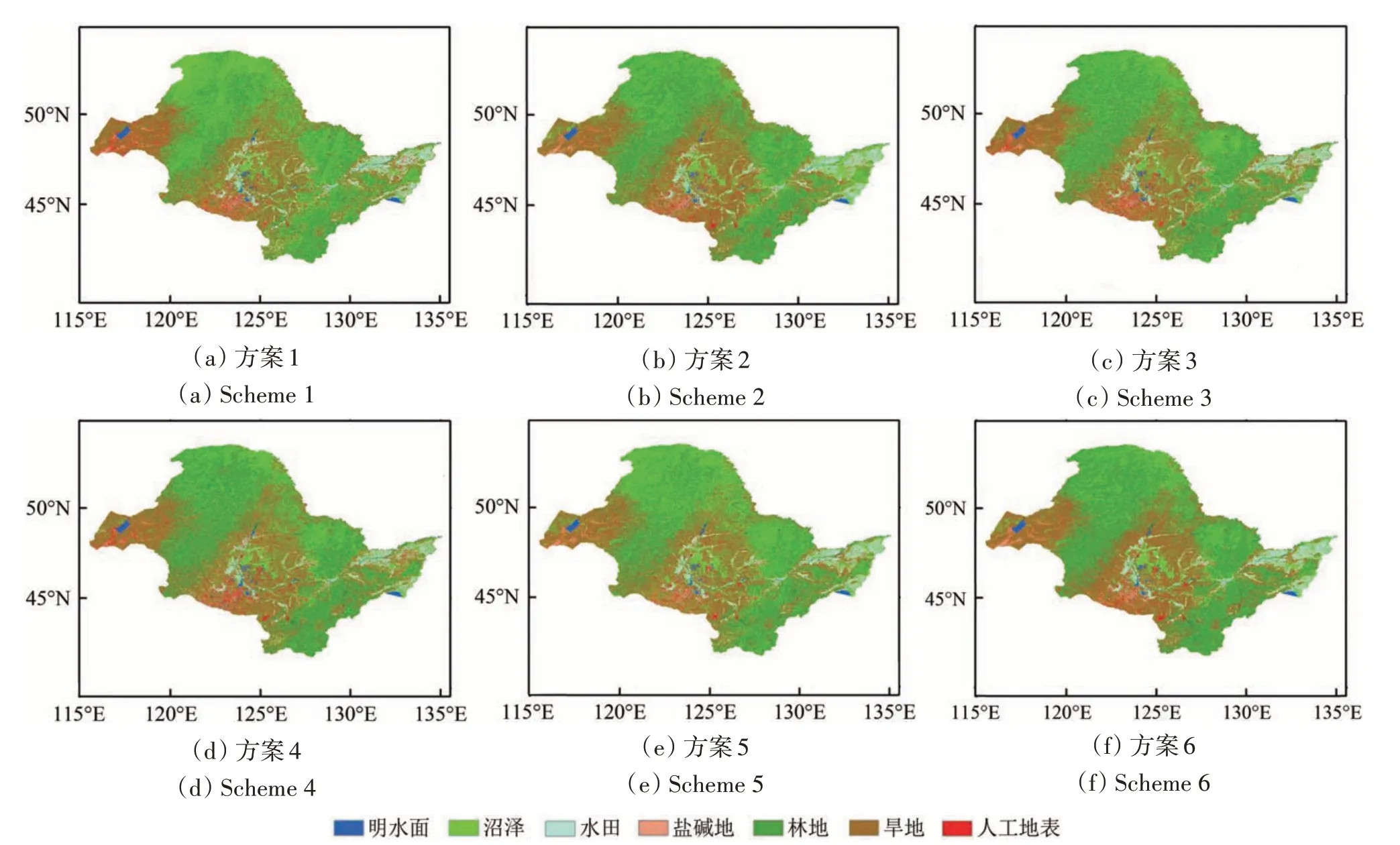
图3 6种实验方案的分类结果Fig.3 Classification results of six schemes
6 种分类方案的分类精度如表4所示,综合来看在所有类别中明水面的分类精度最高,沼泽的分类精度最低。与植被指数和水体指数相比,红边特征、雷达特征和地形特征对沼泽提取的作用更大。红边特征、雷达特征和地形特征分别使沼泽的制图精度和用户精度提高了7.56%,5.01%;5.04%,5.39%;4.48%,4.22%。虽然所有特征都参与分类的方案5取得了较好的效果,但是没有考虑到信息冗余问题。方案6 通过JM 距离对所有特征进行优选,不仅取得了比所有28 个特征参与分类的方案5 更好的精度而且有效的降低了数据量,特征数减少到21 个,减少了信息冗余提高运算效率。通过特征优化后,沼泽的制图精度和用户精度相比方案5 分别提高了1.40%和4.60%,总体精度和Kappa 系数提高了0.86%和0.02。因此采用方案6作为最终的湿地分类方案。
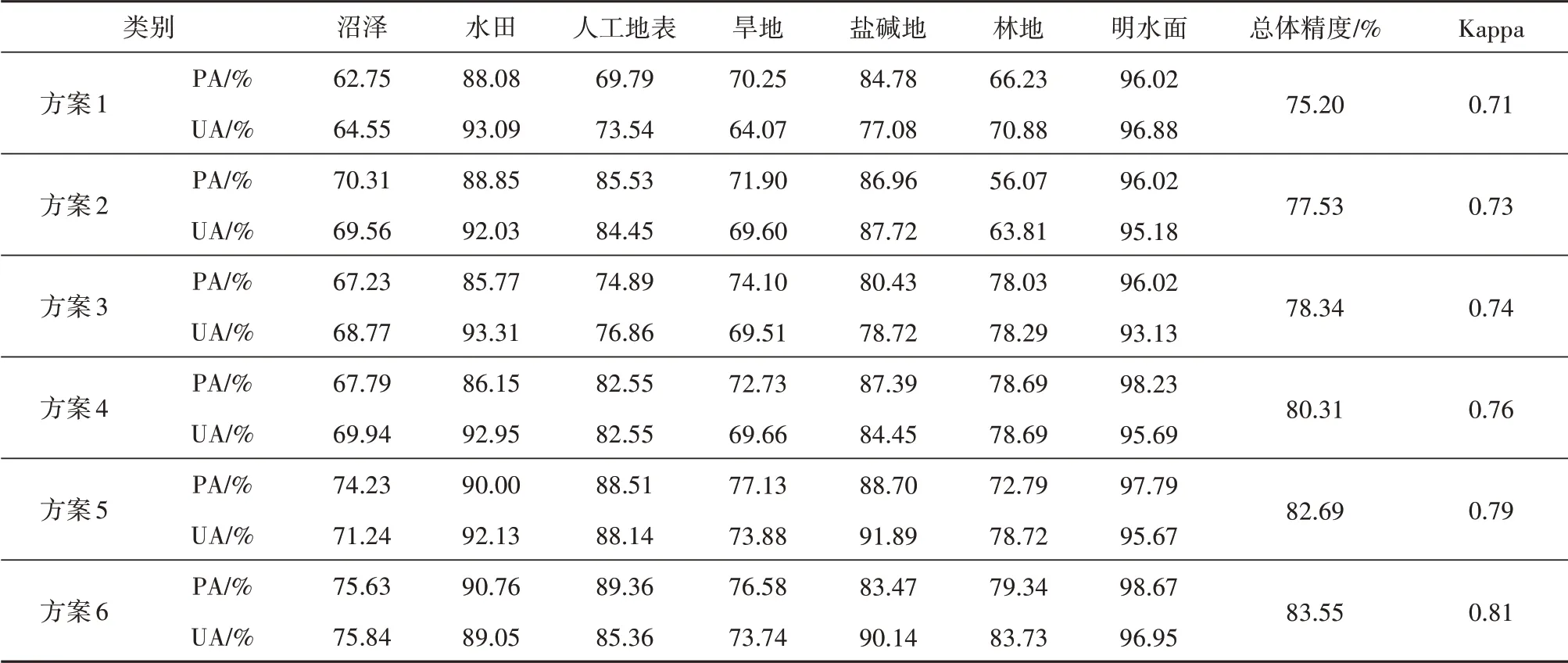
表4 分类精度统计Table 4 Classification accuracy statistics
4.3 最佳分类方案下的沼泽湿地提取精度评价
对方案6进行随机森林分类,对每个结点决策树的个数进行了调整以寻找最佳值,首先将树的个数设置为1记录其沼泽的制图精度,然后将树的个数设置为5,之后以5 为步长,观察树的个数每增加5其精度的变化(图4)。由图4看出,增加树的个数,沼泽的生产者精度快速增长,当树的个数为20 时,沼泽的生产者精度达到最大,之后随着树的个数增加,沼泽的生产者精度开始缓慢下降。因此最优参数为决策树的个数为20 棵。经过随机森林调参后沼泽的制图精度提高了13.16%,总体精度提高了7.99%。
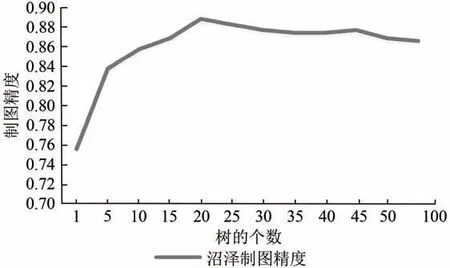
图4 随机森林树的个数与沼泽制图精度的关系Fig.4 Relationship between the number of random forest trees and the producer accuracy of marsh
表5 显示了方案6 最终的混淆矩阵,其中对角线表示制图精度。利用JM 距离进行特征优选和随机森林调参后分类精度显著提高,水田、人工地表、盐碱地和明水面的生产者精度均在90%以上。沼泽、旱地和林地的精度相对较低,这主要是由于旱地上农作物种植时间存在差异,不同地区甚至是同一地区的旱地存在有植被覆盖和无植被覆盖两种地表覆盖差异,而本文在采集样本点时没有对此加以区分,导致旱地的训练样本包含有植被覆盖的旱地和无植被覆盖的旱地2 类,由于这3种地类的光谱相似性导致相互混淆。利用最佳分类方案进行湿地分类总精度为91.54%,Kappa 系数为0.90,沼泽的制图精度和用户精度分别为88.79%和88.30%,水田的制图精度和用户精度分别为94.23%和96.45%,明水面的制图精度和用户精度分别为98.67%和98.23%。

表5 方案6混淆矩阵Table 5 Confusion matrix of scheme 6
图5展示了本文的分类结果图,以及几处细节的分类效果,图5(b)和图5(c)为扎龙湿地,图5(d)为三江平原湿地。最终的分类结果边界清晰,基本没有破碎化的现象,对比光学影像绝大大多数土地覆盖类型都得到了正确区分。图5(b)中,靠近河流的区域被正确识别为了沼泽湿地。图5(c)位于扎龙国家级自然保护区,主要土地覆盖类型为草本沼泽,本文中大部分区域识别正确,沼泽中分布的明水面、水田和盐碱地等也都清晰可见。在图5(d)中也是如此,沼泽湿地边界清晰,比较符合实际情况,提取效果较好。
5 结论
本文依托于Google Earth Engine 强大的计算能力以及哨兵卫星收集的高空间和高时间分辨率遥感数据,考虑了多种分类方案,基于GEE 平台实现了大尺度区域沼泽湿地信息提取,探讨了红边、雷达以及地形特征对沼泽湿地提取的作用,验证了利用JM 距离寻找最优特征的可行性。结果表明:(1)红边特征对沼泽湿地类别的辨别能力最好,红边特征、雷达特征和地形特征分别使沼泽的制图精度和用户精度提高了7.56%,5.01%;5.04%,5.39%;4.48%,4.22%。(2)利用JM距离横向对比了不同特征对沼泽湿地信息提取的重要性,就沼泽同其他类型的分离度而言,红边特征>其他光学特征>地形特征>雷达特征。(3)利用JM 距离探索了有利于沼泽湿地信息提取的最优特征组合,并将特征数由28减少到21。具体为B6、B11、B4、B2、NDVIre2、MDWI、B5、NDVIre1、MNDWI、B9、CIre、B7、Elevation、B3、NDVI、Slope、VH、B8a、B8、VV、NDre2,相比特征优化前沼泽湿地的制图和用户精度分别提高了1.40%和4.60%。在最优特征基础上进行随机森林调参最终得到的总体精度为91.54%,Kappa系数为0.90,沼泽湿地的提取精度达到88.55%。JM 距离为特征优选提供理论支持,相比其他特征选择方法更为直观合理,得到最优特征组合后方便后续直接使用。需要注意的是训练样本应满足与影像时相相对应且具有代表性,否则将影响基于样本特征计算的JM距离的结果。
尽管本文沼泽湿地提取取得了较好的精度,但仍存在一些不足,后续研究将从以下3个方面进行改进:(1)利用沼泽与旱地、林地在多时相上展现出的物候特征差异减少单时相中三者的混淆;(2)更深入的探讨有利于沼泽湿地提取的特征及不同特征间的相互影响,以期更好的优化所用特征;(3)探索基于GEE 平台实现面向对象的方法以改善基于像元方法产生的“椒盐现象”。
