基于多信息交互与深度强化学习的电动汽车充电导航策略
2022-03-08沈国辉赵荣生董晓邢强陈中袁浩耿爱国刘纪民
沈国辉,赵荣生,董晓,邢强,陈中,袁浩,耿爱国,刘纪民
(1.南瑞集团有限公司,南京211106;2. 北京科东电力控制系统有限责任公司,北京100194;3. 国网电动汽车服务有限公司,北京 100053;4. 东南大学电气工程学院,南京210096)
0 引言
随着“碳中和和碳达峰”能源变革的逐步推进,人们越来越关注环境的健康和可持续性发展[1 - 2]。电动汽车(electric vehicle, EV)依据其绿色、低碳、环保等优点,将逐渐取代传统内燃机汽车,成为智慧电网和绿色城市的重要组成部分[3 - 4]。然而随着电动汽车用户的激增,其动态行驶行为与随机充电行为必然与城市电网和交通路网产生耦合交互[5 - 6]。因此,为了降低电动汽车车主出行成本以及提高交通电气化网络运行效率[7 - 8],融合“车-站-网”多交互信息与人工智能技术[4]制定电动汽车充电导航策略,将为充电设施规划、配网经济运行以及车网友好互动提供重要指导[9 - 10]。
目前,国内外已有许多学者提出了充电导航策略引导电动汽车进行有序充电。针对理论驱动建模策略,文献[11]考虑实时电价信息对电动汽车充电行为决策的影响,通过微观交通模型设计了充电导航系统。文献[12]则基于充电需求信息与充电站(charging station, CS)能量信息,通过动态演化分析为车主规划充电路径与推荐充电站。文献[13]则综合分析了电网与交通信息的实时动态特征,建立了“车-网-路”融合的充电站推荐模型。进一步地,一些研究则从数据驱动层面提出充电引导方法,文献[14]对网约车出行轨迹信息进行数据挖掘与融合建模,建立了电动汽车充电导航模型。文献[15 - 16]设计问卷调查采集车主出行信息,通过行为偏好分析为车主制定最优充电计划。另外,这些工作将人工智能技术引入到电动汽车充电控制领域,文献[17 - 18]从物理和电气连接构建了电气交通网耦合架构,利用深度强化学习(deep reinforcement learning, DRL)方法为车辆进行充电导航。文献[19]运用DRL方法分析了不确定条件下电动汽车的充放电控制问题,采用能量边界模型表征充放电行为。文献[20]基于竞争深度Q网络结构,提出了电动汽车充电控制方法,协同优化充电资源和新能源发电资源。
虽然上述方法剖析了电动汽车充电导航和控制的本质,但依旧存在如下几个问题:1)传统建模思路缺乏采用真实交互信息刻画电动汽车动态特征。2)基于数据驱动建模方法无法实现实时优化调度且面临海量数据的计算压力。3)现有DRL引导策略在城市级运营数据的挖掘和算法综合性能的评估方面仍有待完善。综上,为了解决上述方法的不足,本文考虑电动汽车行驶与充电过程的信息交互特征与人工智能方法求解复杂问题的适应性[21 - 22],提出一种基于多信息交互与深度强化学习的电动汽车充电导航策略。首先,采用数据驱动方法对“电动汽车集群优化储能云平台”的数据进行建模挖掘,得到电动汽车出行所需的行驶与充电信息、城市充电站信息以及动态交通路网信息。其次,运用DRL方法求解多目标优化的电动汽车充电导航问题,将挖掘得到“车-站-网”实时信息作为深度Q网络(deep Q-network, DQN)的状态输入,并通过DQN的动作执行为车主推荐合适充电站与规划充电路径。最后,设计不同仿真实验场景,验证所提方法的实施效果。
1 “电动汽车-充电站-交通网”交互信息
1.1 电动汽车行驶与充电信息
本文依托“电动汽车集群优化储能云平台”[23],该平台可以实时监控接入的电动汽车动态行驶信息与充电信息,并获取管辖范围内充电站的实时运行情况,数据平台界面如图1所示。

图1 电动汽车集群优化储能云平台
首先,本文选择电动汽车相关的数据进行数理统计与建模挖掘,接入平台电动汽车数据格式如表1所示。

表1 电动汽车数据格式
为了消除数据采集和通信产生的误差以及提高后续数据建模的准确性,采取作者原有研究工作相同的数据预处理方法对数据进行数据清洗、坐标转换、地图匹配以及数据可视化显示。限于篇幅,具体步骤可参考文献[14]。
经去噪的数据被映射到采用WGS- 84坐标系编码的地图上,则每条电动汽车行驶与充电信息表示如式(1)所示。
Ωi={pi,1,pi,2,…,pi,m,…,pi,n}
(1)
式中:Ωi为第i辆电动汽车的行程轨迹数据集,i=1,2,…,Ne,Ne为电动汽车的数量。其中,pi,m=(xi,yi,tg,et,vt),xi,yi,tg,et,vt分别第i辆电动汽车在第m条行程轨迹的经度坐标、纬度坐标、即时时间戳、时刻t的即时荷电状态(state of charge, SOC)以及时刻t的即时速度。
由于数据体量较为庞大,为了降低数据处理的维度,本文选择南京市城市范围为经度(东经):118.741 2 °—118.824 9 °,纬度(北纬):32.023 4 °—32.063 3 °范围内接入的367辆电动汽车在3个月内产生的24 647条数据进行分析,图2给出了采用Datamap软件绘制的所选城区范围内车辆起止位置分布图。
图2 电动汽车起止位置分布
1.2 城市充电站信息
其次,筛选出该区域范围内接入平台的运营充电站,充电站的数据格式如表2所示。该区域范围内的充电站信息表示如式(2)所示。

表2 充电站数据格式
Ψk={Rk,1,Rk,2,…,Rk,r,…,Rk,s}
(2)
式中:Ψk为第k个城市充电站的数据集,k=1,2,…,Nc,Nc为充电站的数量。其中,Rk,r=(ta,ts,td,sc,ωt),ta,ts,td,sc,ωt分别为第r个订单到站时间、开始时间、结束时间、充电电量以及充电费用,r=1,2,…,Ns,Ns为订单的数量。
进一步,采用Datamap软件对所选区域范围内分布的14个充电站在某一时段的订单数量进行统计,充电站的地理位置和订单数量如图3所示。其中颜色越深表示充电站的充电订单数量越多。
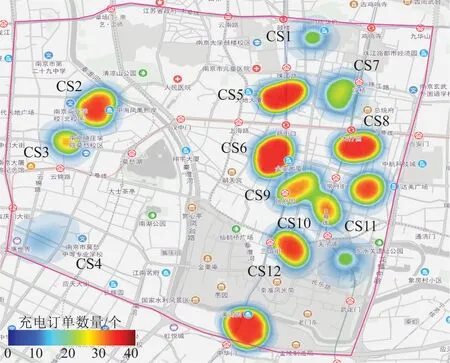
图3 各充电站某一时段订单分布
1.3 动态交通路网信息
最后,在电动汽车与充电站信息获取基础上,为了准确描述电动汽车路径规划与充电行驶行为,采用图论分析[13]法对该区域范围内的交通路网(traffic network, TN)进行建模。
(3)
式中:G为交通路网拓扑;V为交通路网节点集合;E为交通路网路段集合;T为时间序列集合;W为动态路段路阻集合,即表示城市路网动态交通信息;vi为第i个交通节点;vij为交通节点vi和vj之间的路段;s为时间序列的数量;wt,ij为t时刻路段vij的路阻。
进一步地,采取作者原有的研究方法[24],综合考虑城市道路路阻可由路段阻抗Rvij(t)和节点阻抗Cvi(t)构成,因此,动态交通路网信息如式(4)所示。限于篇幅,具体推导过程和路网基本参数可参见文献[19]。
(4)
式中:wij(t)为道路实时路阻;S为城市交通路况饱和度;R1vij(t)、R2vij(t)分别为0
2 电动汽车充电导航的DRL方法
2.1 电动汽车充电导航问题构建
针对电动汽车充电导航问题的多主体互动性质,本节分别考虑电动汽车车主、充电站以及交通路网多方利益作为综合目标进行优化分析。
(5)
约束条件:
(6)
(7)
(8)
(9)
(10)
(11)
式中:Ce为路程能耗花费;Cs为充电站充电费用;Tw为充电站等待时间;Tt为路程通行时间;π为单位时间成本费用;δij为路段决策变量,δij=1表示车辆选择交通节点vi行驶到节点vj,δij=0表示该路段未被选择;φk为充电站决策变量,φk=1表示充电站k分配给车主,否则为0;εm为单位里程耗电量[10];ωe为车辆平均充电电价;dij为车辆从节点vi到节点vj行驶里程;Ep为车辆电池容量;ee为车辆充电结束时的SOC值;ωt为充电站充电电价;tr,a、tr,s为第r个订单到站时间和开始充电时间;tr,s-tr,a为第r个订单充电等待的时间;Nk,s为充电等待的订单数量;to,g为车辆起点的时间戳。
由上式可知,多目标的电动汽车充电导航是一个混合整数非线性问题。该问题的求解可以采用大M方法转换成混合整数线性规划问题,运用Gurobi、Cplex以及Lingo等求解器求解。但上述所提传统方法均为离线运算且面对实际动态拓扑网络运算耗时较长。
2.2 基于DRL方法的电动汽车充电导航模型
针对上述不足,本文引入DRL方法对电动汽车充电导航问题进行建模求解。强化学习是智能体对真实环境的探索与利用,通过反复的试错得到高奖励值,从而选择执行高回报值的动作。强化学习中每一个状态的改变,都只与前一个状态和智能体选择的动作有关,而与前面的动作无关(即满足马尔科夫性),这种满足马尔科夫性的强化学习定义为马尔科夫决策过程(Markov decision process, MDP)。
而电动汽车充电导航问题中电动汽车作为智能体通过感知动态交通路网环境,通过对充电状态以及行驶状态的奖励值进行评价,依次选择执行动作直至结束。因此,上述过程符合马尔科夫链的相关定义。进一步,为了解决智能体对整个动态交通路网的状态感知与学习中存在的维数灾难问题,采用深度神经网络与强化学习方法相结合的深度Q网络(DQN)方法[15]进行求解。因此,具体基于MDP过程的电动汽车充电导航建模过程如下。
2.2.1 状态
考虑到电动汽车智能体的多信息交互特征,将电动汽车的行驶特性与充电特性作为状态空间集合:
st={xi,yi,et,Ce,Cs,πTw,πTt}
(12)
2.2.2 动作
智能体根据系统状态选择所要执行的动作,因此,将充电站分配作为智能体的动作空间,智能体根据所分配的充电站进行路径规划导航:
at=k,k∈Nc
(13)
2.2.3 奖励值
根据电动汽车是否抵达充电站进行电能补给,将奖励值分为行驶途中奖励与到站后奖励:
(14)
2.2.4 动作-值函数
电动汽车车主根据不同策略选择执行相应动作,因此动作-值函数Qψ(s,a)用来计算累积奖励:
(15)
式中:γ为折扣因子,表示智能体对长期回报和短期回报的折衷权衡;Εψ为策略ψ的期望计算函数。
进一步,电动汽车充电导航的目的是在所有可行性策略中找到最优策略ψ*求得最优动作-值函数Q*(s,a), 使得奖励值最大化:
(16)
2.3 DQN方法训练过程
针对最优动作-值函数Q*(s,a)的求解,引入基于查表方式的Q-Learning方法[16],通过Bellman方程迭代更新动作值函数逼近最优动作值函数,迭代过程和最优动作表示如式(17)—(18)所示。
Q(s,a)=Q(s,a)+β(r+γ(s′,a′)-Q(s,a))
(17)
(18)
式中:β为学习率;s′、a′分别为下一个状态的状态和动作。
为了消除Q-Learning方法求解高维状态空间和动作空间连续性的不足,DQN方法通过构建两个网络结构与输出维度相同的深度神经网络(deep neural networks, DNN),即估值网络与目标网络,利用神经网络对动作-价值函数进行拟合,输出每个动作的近似价值。图4给出了DQN方法训练过程示意图,由图4可知DQN具体训练步骤如下。

图4 DQN方法架构
1)采用DNN作为估值网络进行Q值的估计:
Q(s,a)≈Q(s,a|θ)
(19)
式中θ为估值网络参数。
2)构建相同DNN架构的目标网络作为估值网络的“标签”指导估值网络进行参数更新,且每训练N步,将估值网络的参数完全复制给目标网络:

(20)

3)在Q值中使用均方差(mean square error, MSE)定义DQN的损失函数:
(21)
4)计算损失函数中关于参数θ的梯度:
(22)
5)最后,对式(22)使用随机梯度下降方法[16]更新参数,完成整个算法的训练任务。
3 电动汽车充电导航架构
本文所提的电动汽车充电导航框架如图5所示。

图5 电动汽车充电导航框架
首先,对“电动汽车集群优化储能云平台”采集的数据进行数据预处理得到建模所需的电动汽车行驶、充电信息以及城市充电站信息;
其次,对上述所得的电动汽车、充电站以及动态城市路网信息进行数据挖掘与数据建模,采用起止矩阵(origin destination, OD)方法为电动汽车抽样分配行驶特性与充电特性参数模拟车辆全天候出行轨迹[19],并将“车-站-网”多信息交互作为深度神经网络的状态输入;
最后,运用DQN方法对电动汽车充电导航问题进行求解,将电动汽车的能耗与时间耗时指标作为奖励值,通过动作-值函数的评估将最优充电作为动作空间推荐给智能体执行,并以分配的充电站为目标进行路径规划[10],完成整个充电导航任务。
4 算例分析
本节设计不同的实验场景验证所提方法的实施效果,实验参数设置如下:引入100辆电动私家车进行充电模拟,电池容量Ep设置为36 kWh,初始SOC服从正态N(0.8,0.1),充电结束时的SOC值ee服从N(0.85,0.3),单位时间成本费用π为6.15元[25],充电站充电电价ωt为2.5 元;DQN网参数络θ包括6个输入层、512个隐藏层以及3个输出层,学习率β为0.99,训练步数N为20,训练回合为200次。在服务器配置CPU R93950X、GPU RTX2080TI、RAM 32GB以及仿真软件MATLAB 2020b环境中进行实验验证。
4.1 算法训练过程
首先,图6给出了本文基于DQN方法充电导航策略训练过程的每回合的奖励值,训练时长为3.58 h。由图6可知,算法在整个200回合的训练中,在初始阶段智能体不断从环境中进行试错学习,该阶段奖励值求解过程存在较为明显的振荡现象,随后在中期到最终后期阶段求解过程逐渐趋于稳定收敛。其中,在初始的前50回合中由于DQN采用ε-greedy策略在训练初期ε设定值为0.90,以较大地概率鼓励智能体对环境进行探索,因此奖励值波动较为明显,该阶段平均奖励均值为-125.38 元。在50—160回合阶段,ε值下降到0.5,智能通过对环境的前期探索积累了一定的“经验”,因此更好的利用环境状态累计更多的奖励值,该阶段平均奖励值为-50.23元。而在160—200回合,智能体对环境的探索可以学习到最优策略,此时ε值下降到0.02,智能体能够取得最高的奖励值,平均为-31.55 元。

图6 DQN算法训练过程
4.2 泛化能力评估
其次,为了评估所提方法的泛化能力,将所选区域交通路况的饱和度S分别设定为畅通、缓行和严重拥堵状态,通过改变动态交通信息获得不同的实验样本数据,验证算法对不同信息环境下的适应能力,不同道路通行状态下奖励值如图7所示。
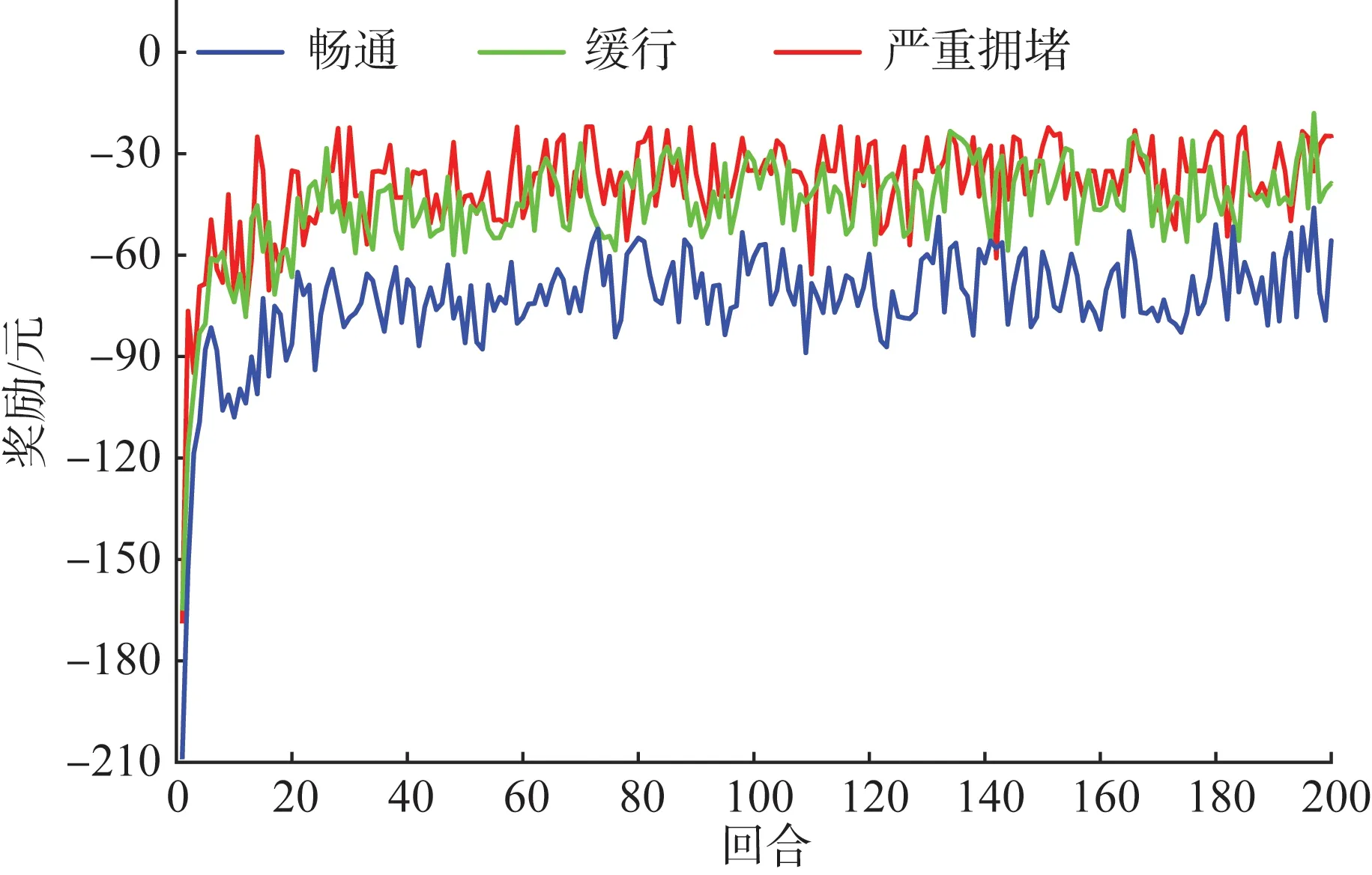
图7 不同道路通行状态下的奖励值
由图7可知,整体上,在不同道路通行状况下,DQN方法通过200次训练均可以获得稳定收敛的奖励值。而道路交通状况为畅通条件下,城市道路通行路阻较小,路径搜索与策略学习难度较低,因此算法训练时长最少,为3.08 h。随着道路交通状况变得趋于饱和,增加了算法的搜索与学习负担,因此,道路缓行状况下耗时为3.88 h,严重拥堵条件下耗时为4.45 h。另外,道路为畅通条件时,车主路程耗时较小,最终收敛奖励值约为-42.56 元,比缓行和严重拥堵条件下分别低15.56%和46.56%。
4.3 鲁棒性分析
然后,在算法泛化能力验证基础上,本节设计算法鲁棒性能的验证实验。具体实验场景设置为:仿真回合设计为180次,每隔60次回合改变各充电站电价。其中充电站电价1为CS1~CS5的电价,充电站电价2为CS6~CS10的电价,充电站电价3为CS11~CS14的电价。不同充电站电价条件下的奖励值如图8所示。
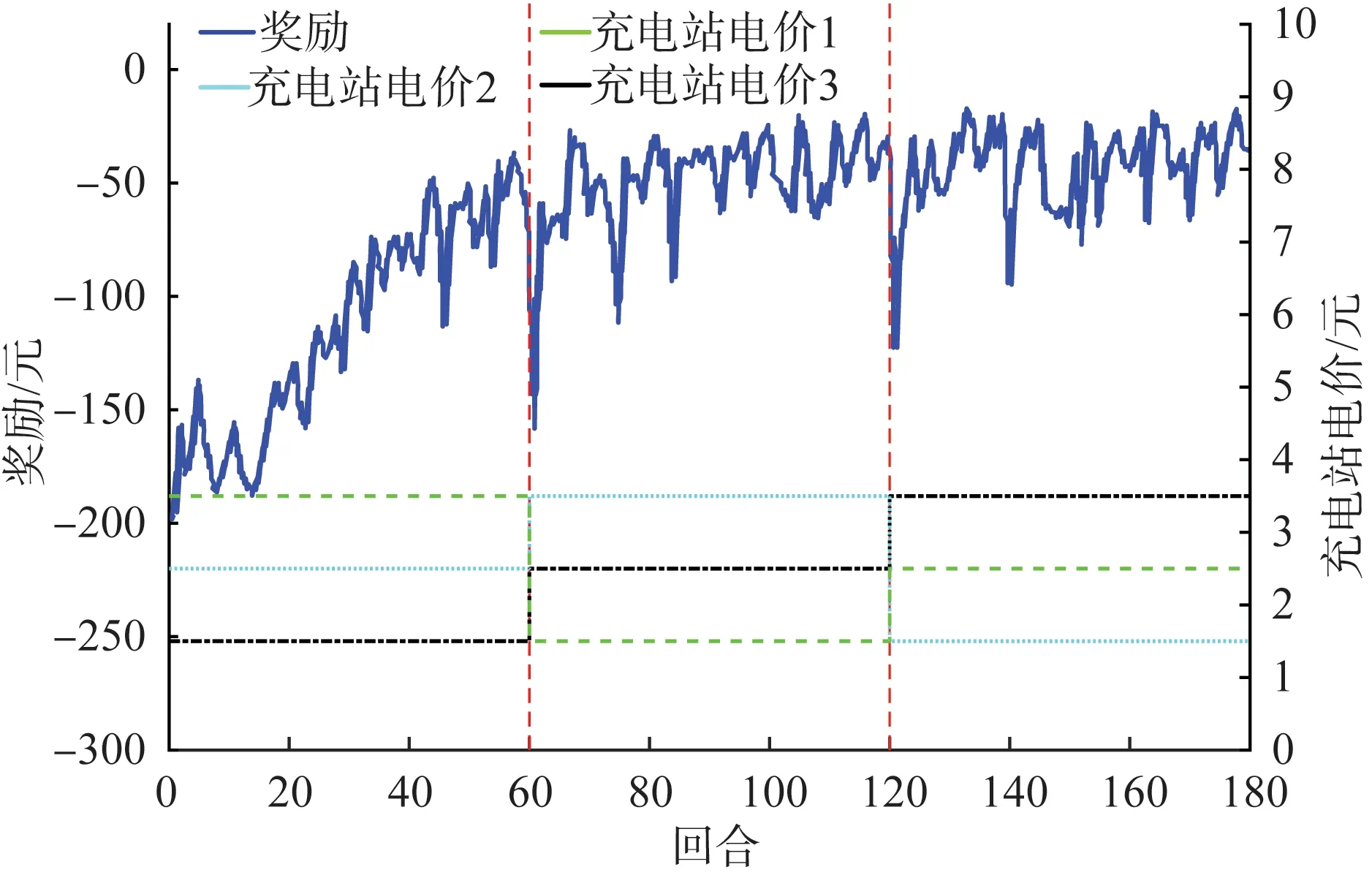
图8 不同充电站电价条件下的奖励值
由图8可知,整体上随着仿真回合的增加,算法得到的奖励值逐渐趋于稳定,收敛在-47.56元附近。而仿真回合在第60次和120次时充电站电价发生骤变,相对应的奖励值在第61次和第121次回合均发生骤降跌落,说明算法具有很好的实时跟踪性能。另外,在第61次回合时,奖励值跌落幅度为-103.32元,而第121次回合,跌落幅度为-78.55元。表明随着训练次数的增加,算法的实时跟踪性能逐步提高。
4.4 导航策略对比
最后,为了与本文所提电动汽车充电导航策略进行对比,引入距离最短(shortest length path, SLP)与时间最短(shortest time path, STP)两种基本策略[13]为车主进行充电引导。其中,SLP和STP方法分别为车主以路程距离最短和路程耗时最少为目标进行导航,即基于DRL建模方法中仅将奖励值更改为路程距离和路程耗时,其余条件不变。图9给出了某一车辆在同一起讫点采用不同导航策略全天的行驶路径。

图9 不同导航策略的行驶路径
由图9可知,车主采用上述3种导航策略一共得到8条行驶路径,其中3种方法共同搜索到第6条路径,说明路径6为距离最短路程。而本文方法和STP方法为动态导航策略,在规划目标中均考虑了行程耗时的动态目标,可以根据不同时段行程时间动态调整搜索结果,因此搜索到多条行驶路径,而SLP方法仅以行程距离最短为目标,为静态导航策略,因此仅得到一条行驶路径。
进一步,图10给出了全部车辆分别采用3种策略在200次训练的总时间成本(行程时间与等待时间总和)的平均累积值。

图10 不同导航策略的总时间成本
此外,表3给出了不同导航策略的行驶与充电评价指标的具体值。结合图10和表3可知,前40次回合训练中,各方法处在探索初期,算法所利用的环境信息来制定寻优策略有限。因此各方法的总的时间成本相近,随着训练回合的增加,算法探索-利用环境信息的能力逐渐成熟,因此,根据奖励机制制定的差异,各导航方法所花费的总时间成本逐渐显现,SLP策略方法所花费的时间成本最多,平均比STP多32.45%,比本文策略多27.89%,其中在第142 回合时各策略的总时间成本差值最大。

表3 不同导航策略评价指标对比
针对具体评价指标,STP方法和SLP方法各自优化目标为最少时间和最短路程,行程时间花费最少的为STP方法,行程距离最少的为SLP方法。另外,由于STP方法为了追求行程耗时较少,存在一定的绕路现象,车辆所行驶的路程最多,比本文方法超出29.33%,比SLP方法超出74.39%。充电费用与行程距离成正比,因此采取STP方法同样让车主花费更多的充电费用。虽然,本文方法在各单项指标(行程时间、行程距离以及充电费用)中并非最优解,但本文方法综合考虑了行程能耗与时间耗时为奖励值让智能体训练学习执行动作,因此在等待时间以及综合评价指标上获得了最优值。
5 结语
本文针对电动汽车行驶与充电过程中的多信息交互特性以及实际交通路网中充电调度的复杂性。对实际电动汽车监控平台数据进行建模挖掘,并综合考虑电动汽车-充电站-交通路网的融合信息,建立了基于深度强化学习方法的电动汽车充电导航模型,通过多场景仿真实验得到如下结论。
所提策略充分利用了现有电动汽车实际运营数据,通过建模挖掘得到电动汽车行驶与充电所需的全部参数信息。且采用实测数据驱动建模得到的“车-站-网”信息更能生动刻画电网系统和交通系统的运行特征。
通过分析电动汽车充电导航过程的马尔可夫链相关性,将交互信息作为深度网络的状态输入空间,运用DQN算法求解该多目标规划问题。通过算法的探索学习,训练回合次数的合理设置可以提高算法的收敛程度。改变环境的数据与信息对算法的泛化能力与鲁棒性影响较小。相较于单目标导航策略,本文的多信息交互的多目标导航策略可以使车主的综合利益最优。
尽管如此,限于篇幅本文没有对电动汽车监控平台采集的全部数据进行挖掘。在下一步工作中,电动汽车全数据链的建模分析可以继续研究完善。由于采用实际城市路网作为交通拓扑,可以通过改进DRL算法来提高对复杂网络的计算效率。此外,基于所提的充电导航策略,可以进一步评估聚集充电对电网和交通网的影响。
