基于深度强化学习的主动配电网高恢复力决策方法
2022-03-08罗欣儿杜进桥田杰刘安迪王标李妍王少荣
罗欣儿,杜进桥,田杰,刘安迪,王标,李妍,王少荣
(1. 深圳供电局有限公司,广东 深圳518001;2. 华中科技大学强电磁工程与新技术国家重点实验室,武汉430074)
0 引言
随着全球灾害威胁的增加,电力系统在极端自然灾害下恢复力的研究得到越来越多的关注[1 - 2]。美国、欧盟、日本等国家和地区已将电网恢复力建设作为未来电网发展的重要方向。主动配电网(active distribution network, AND)是智能配电网技术发展到高级阶段的产物,可以通过拓扑结构、分布式发电(distributed generation, DG)和可中断负荷(interruptible load, IL)等进行主动优化控制,在故障恢复过程中减少用户停电损失[3 - 5]。文献[6]针对含微网的配电系统,在极端灾害下的网架重构阶段,根据故障位置的不同提出差异化供电恢复方案;文献[7]提出通过动态拓扑分析、孤岛配置、含DG主网络连通性恢复和网络优化解决故障快速恢复问题;文献[8]将多源协同的配电网故障恢复问题建模为混合整数二阶锥规划模型,并利用商业优化软件MOSEK进行求解。针对配电网在极端灾害下的故障恢复过程,建立适应具有复杂动态约束的混合整数非线性规划模型,运行状态随机性会导致场景组合激增[9],求解的复杂度随求解时段数成指数增长,在极端灾害条件下或者在实际故障恢复过程中,以上优化模型会消耗大量的计算资源也可能找不到最优解[10]。
数据驱动的机器学习算法已成为求解随机优化决策领域的研究热点[11 - 12],其中AlphaGo是成功的应用案例[13],其核心技术是自学习方法[14 - 16]。随着智能电网技术发展,高级量测体系、各种监控系统的大规模部署将产生和积累大量数据,基于数据驱动的自学习方法在能源与电力系统优化调度和控制决策等方面已引起广泛关注[17 - 20]。配电网的故障恢复决策是随机优化决策的问题,强化学习是一种无模型的方法,不需要先验知识,采用历史状态数据训练神经网络进而得出复杂决策,本文将其引入到问题求解中去,为解决极端灾害下故障恢复决策提供一条新的思路。本文首先构建基于深度强化学习的高恢复力决策模型,考虑减少负荷停电的经济损失,同时兼顾故障恢复时电网运行经济成本,采用观测状态数据,基于深度强化学习算法对竞争深度Q网络(dueling deep Q network, DDQN)进行训练,迭代更新参数,完成历史观测状态的深度强化学习(deep reinforcement learning, DRL),实现观测状态到主动配电网故障恢复策略的非线性映射。本文最后基于蒙特卡罗法随机生成易损线路的故障状态,得到易损线路故障集合,仿真研究IEEE33节点配电网算例的随机故障场景,将DG孤岛、网络重构和可中断负荷等作为故障恢复的动作手段,对DDQN结构的神经网络进行训练,分析了3种决策策略下的负荷损失功率,说明本文所提方法可有效提高主动配电网极端灾害下供电恢复力。
1 基于深度强化学习的高恢复力决策模型
本文基于数据驱动的深度强化学习方法开展极端灾害条件下的故障恢复决策,将极端灾害下配电网运行状态和线路故障状态作为观测状态集合,自学习智能体Agent在当前环境观测状态下寻求可行的决策策略进行动作,通过回报函数进行动作评价以开展自学习,如图1所示。

图1 基于深度强化学习的故障恢复决策机制
t时刻观测状态St包括极端灾害下的线路故障状态和主动配电网运行状态,其中,运行状态包括DG以及负荷的功率,线路故障状态定义为极端灾害期间主动配电网易损线路的受损状态。
在主动配电网极端灾害后故障恢复阶段,本文提出可行的3种决策策略at并给出对应约束条件,通过决策策略的约束建模可体现故障恢复能力。
策略一:“DG”控制,以实现故障后孤岛内负荷的供电恢复;DG出力的功率存在上下限表明其恢复能力的大小,如式(1)所示。
(1)
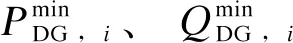
策略二:“DG +网络重构”,灵活使用联络开关转供电,形成孤岛联络,充分利用DG的容量;网络重构需要考虑配电网的潮流运行方式约束,主要为功率平衡约束、相邻节点电压关系约束、线路容量约束以及电压大小上下限约束等。以线路容量约束为例说明,如(2)所示。
(2)

策略三:“源-网-荷”控制,通过可中断负荷控制进一步提高供电恢复能力;可中断负荷的功率变化大小与自身属性有关,如(3)所示。
(3)
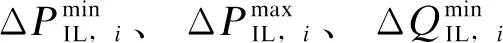

(4)

故障恢复阶段DG提供备用功率支撑,需要考虑其出力成本;此外,对可中断负荷进行控制时,需要考虑可中断负荷的中断补偿成本。因此,本文考虑的故障恢复时电网运行经济成本包括DG出力成本以及可中断负荷的中断补偿成本,电网运行的经济损失回报rc如式(5)所示。
(5)

综合以上建立基于深度强化学习的故障恢复决策自学习Agent的即时回报函数rt+1, 见式(6)。
(6)
智能体Agent通过试错学习方式选择动作进行即时回报评价,基于评价激励可实现经验积累与决策动作优化。
2 基于DDQN结构的DRL自学习训练
本节基于DDQN网络开展DRL训练,自学习智能体Agent的试错经验在估值函数Q矩阵中存储,以实现状态到主动配电网实时故障恢复策略的非线性映射。基于DDQN结构构造Q函数,对状态和动作进行分层学习,DDQN用两个不同的神经网络分别拟合观测状态的状态估值函数V(st)和当前状态每个动作的优势估值函数[23],并得到实现状态和动作解耦的Q(st,at)值。DDQN的Q函数如式(7)所示。
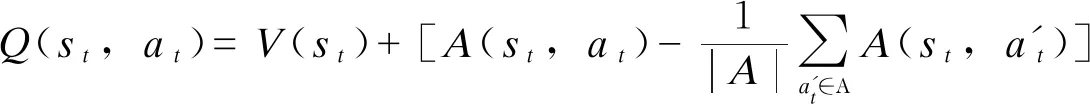
(7)
式中:A为所有可执行动作集合,执行动作包括DG出力ADG、 联络开关动作AS以及IL控制AIL; |A|表示可执行动作的总数。由于每个观测状态只对应一个控制动作,因此获取的一个Q函数值无法拆解成唯一状态估值函数V值和动作优势函数A值,故为了去除多余的自由度,提高算法稳定性,将动作优势函数设置为单独动作优势函数减去当前状态下所有动作优势函数的平均值。
引入ε-greedy策略进行动作选取体现自学习对环境的探索机制见式(8)。
(8)
式中:ε为ε-greedy策略中的固定常数;T为总训练次数;k为当前训练次数;γ(0<γ≤ε)为计算机生成的随机数;Q′(st,at)为状态st下动作at的预测估值。
DDQN执行正向计算可得到所有控制动作的Q值,将目标Q值和神经网络输出的预测Q值之间的均方差定义为损失函数,见式(9)。
(9)
式中:Qπ*(st,at)为目标Q值;Qπ′(st,at,w)为神经网络输出的预测Q值;ω为神经网络的结构参数;n为小批量训练的样本数。
为了消除短期内样本间的时序相关性,采用记忆回放来存储状态动作传输对样本(st,at,rt+1,st+1)。建立容量为N的经验池,在每个训练周期内,将主动配电网观测样本存入其中,当样本数超过回放开始容量M, 则从经验池中随机抽取小批量的观测样本,开展神经网络训练,通过随机抽取观测样本训练神经网络,避免过拟合等现象的出现。若样本数超过经验池的最大容量,则剔除掉最早的观测样本再存入新样本,保证神经网络学习最新的观测状态。
基于DDQN结构的DRL自学习训练过程:首先设置合适的超参数λ、α、ε、n、N、M, 初始化神经网络与经验池,设定训练终止时刻T并令当前训练时刻t=0; 其次观察当前状态st, 结合ε-greedy策略选取下步动作at, 记录下一状态st+1并计算即时回报rt+1, 不断积累样本数据;然后判断经验池是否存满,若存满则剔除掉早期样本,并存入当前时刻观测样本;当样本数超过回放开始容量,从经验池中随机抽取n个小批量历史样本作为DDQN网络的训练数据开展DRL自学习训练。具体来说,首先通过DDQN的正向计算得到所有控制动作的预测Q值,根据式(8)结合目标Q值计算损失函数,使用小批量梯度下降法完成DDQN网络的参数更新;令t=t+1, 进行循环迭代,在经过足够多的训练周期后,DDQN神经网络的结构参数会收敛于稳定值,完成估值函数的近似,最后判断t是否达到终止时刻T, 若达到终止时刻则结束自学习的训练过程。
采用观测状态数据完成基于DDQN的DRL训练后,可实现观测状态到主动配电网故障恢复策略的非线性映射。后面基于算例仿真进行有效性分析。
3 算例分析
3.1 典型配电网随机故障场景
选取IEEE 33节点典型配电系统作为算例,如图1红色虚线框内所示,详细的算例模型参数见文献[22];考虑台风极端天气下算例系统的故障恢复过程。在节点6,13,23,29设置可控型DG1、DG2、DG3、DG4,容量限额分别为300 kVA、300 kVA、400 kVA、600 kVA,可控型DG的单位电量出力成本为0.4元/kWh,节点6,13,23,29负荷在停电时单位电量的停电损失为5.6元/kWh;在节点21、32设置风电WT21、WT32,节点17、24设置光伏PV17、PV24;5条联络开关支路33、34、35、36、37作为改变拓扑结构的动作手段;在节点4、8、15、30设置可中断负荷IL4、IL8、IL15、IL30,其单位电量的中断补偿成本分别为1.2、0.84、0.96、1.4元/kWh,在停电时其单位电量的停电损失成本为0.4元/kWh;其余节点负荷停电时单位电量停电损失成本为2元/kWh。
台风灾害下电力系统设备的故障率主要与台风风速有关,根据现有的文献,线路故障概率与台风风速vtyp满足威布尔累积分布[9],如式(10)所示。算例中台风风速模拟按照下述假设:台风风速vtyp服从正态分布,本算例中vtyp~N(22,62)。
(10)
式中α>0,β>0, 分别为尺度参数和形状参数,结合配电网历史故障数据。算例系统中支路5、9、15、20、22、28共6条线路为台风登陆时的易受损线路。线性拟合获取α和β参数的估计值,本算例中α=32,β=6。
3.2 DDQN训练的样本数据
基于DDQN结构的深度强化学习算法开展易受损线路故障下随机决策过程的优化,DDQN训练的样本数据(st、at、rt+1、st+1)对应的变量设置如表1所示。

表1 DDQN训练样本数据

(11)
3.3 基于DDQN的DRL自学习算法的超参数
将仿真中的DDQN网络结构设置为:状态估值网络V(st)和动作优势网络A(st,at)的输入层均含44个神经元(和状态变量个数相同),隐含层分别含20个和25个神经元,均以线性整流单元(Relu)作为激活函数,V(st)和A(st,at)的输出层分别有1个和32个神经元(代表联络开关的动作组合数),所有层之间采用全连接方式。DRL算法中超参数的设置见表2。

表2 DRL算法中超参数的设置
在迭代训练期间,DDQN的损失函数下降情况如图2所示。由图2可知,DDQN的损失函数迅速下降并趋于稳定,说明该算法收敛性较好。

图2 训练期间DDQN的损失函数
3.4 基于DRL的决策结果
本文采用每隔15 min的运行状态数据,基于蒙特卡罗仿真方法随机生成线路故障集合,仿真配电网故障运行方式。把配电网观测状态(如表1所示)输入到训练后的DDQN神经网络中,按照第1节3种不同的决策策略进行动作决策分析。
1)可控DG出力决策
可控DG出力在不同随机运行方式下的决策结果如表3所示。
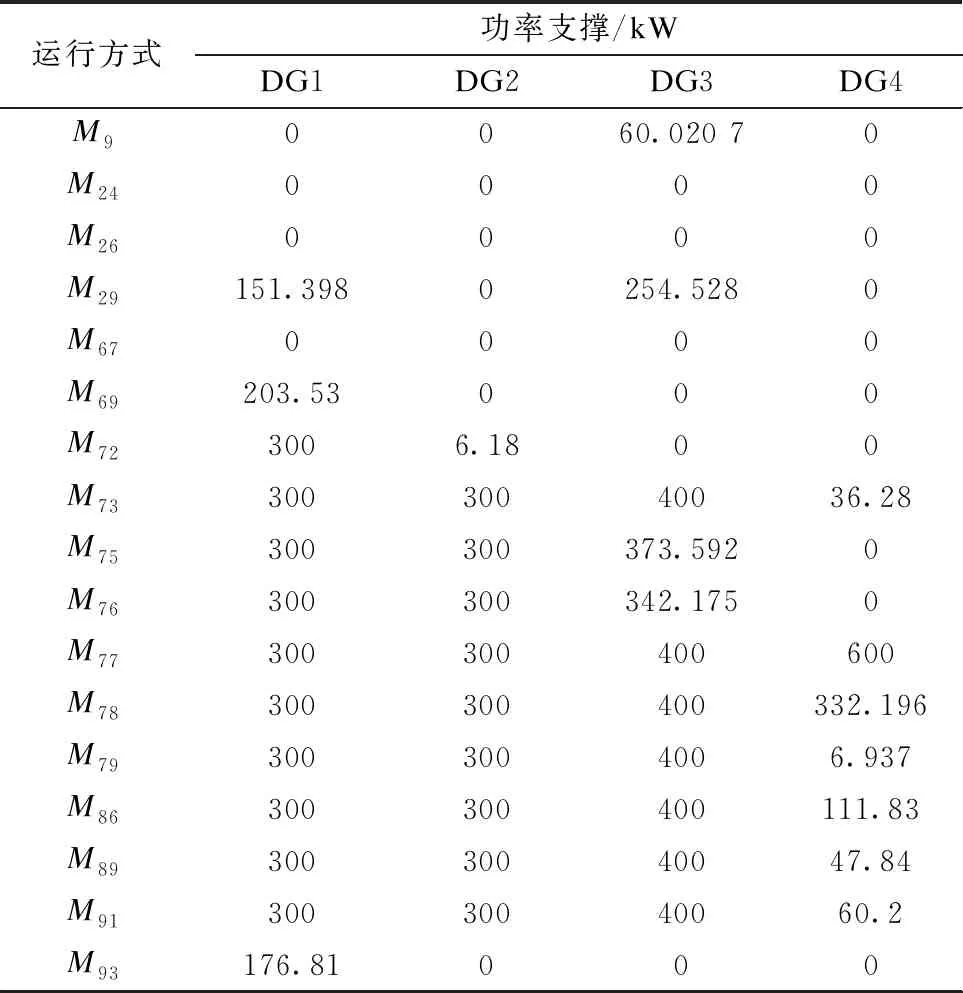
表3 可控DG出力的决策结果
2)联络开关动作
联络开关在随机运行方式下的决策结果动作情况如表4所示,其中1表示动作,0表示未动作。

表4 联络开关决策结果
3)IL的中断控制
针对随机运行方式M29、M73、M75、M76、M77、M78和M79的IL决策结果中断负荷量数据见表5。

表5 可中断负荷决策结果
IL的需求响应曲线见图3,其中蓝色虚线代表IL的原始负荷需求,红色实线代表优化控制后的实际负荷曲线。
基于3种不同决策策略,随机故障运行方式下基于DRL的动作决策结果说明:本文基于DRL的高恢复力决策方法适应多种随机运行方式。
3.5 不同决策策略的有效性
选取仅在DG支撑下无法完全恢复所有负荷供电的随机运行方式,其余运行方式下由DG进行孤岛供电,均可完全恢复。不同随机运行方式下负荷
损失功率数据见表6。负荷损失功率是指该配电网算例中正常运行条件下所有负荷的总功率P1与极端灾害导致的故障情况下所有负荷的总功率P2的差值,即负荷损失功率等于(P1-P2)。在随机运行方式M9、M24、M26、M67、M69、M72、M86、M89、M91和M93下,采用策略二能够将负荷损失功率减小到零,进一步发挥了DG的恢复能力;最后策略三采用“源-网-荷”控制,随机运行方式M73、M75、M76和M79的负荷损失功率可减小到零。

表6 不同决策策略的负荷损失功率数据
综上,针对配电网极端灾害条件下故障过程的随机性,将DG、联络开关以及IL作为减少停电损失的动作手段,通过基于DDQN的深度强化学习算法形成随机优化动作决策,可有效提升配电网在极端灾害条件下的恢复力。
5 结论
为提高极端灾害下主动配电网供电恢复力,本文提出了一种基于深度强化学习的主动配电网高恢复力决策方法,通过典型算例研究了深度强化学习算法的随机优化决策能力。
1)在极端灾害导致的随机故障场景下,本文构建基于深度强化学习的高恢复力决策模型,定义自学习Agent恢复力回报函数,采用观测状态数据训练DDQN神经网络,实现了观测状态到主动配电网故障恢复策略的非线性映射。
2)本文基于DDQN结构构造Q函数,对状态和动作进行分层学习,开展基于DDQN的DRL自学习训练过程,损失函数迅速下降并趋于稳定,说明该算法收敛性较好。
3)算例仿真研究表明,基于DDQN的深度强化学习算法适应多种随机运行方式,不同动作决策均可实现有效提升故障恢复力。
