基于LIME的恶意代码对抗样本生成技术
2022-03-08黄天波李成扬刘永志李燈辉文伟平
黄天波,李成扬,刘永志,李燈辉,文伟平
(北京大学 软件与微电子学院,北京 102600)
近年来,恶意代码检测技术的研究表明机器学习在代码检测问题上被越来越多的研究人员应用,众多学者提出将机器学习技术作为下一代恶意代码分类器的关键组成部分[1-5]。分类器从恶意代码中提取特征,使用机器学习算法对良性程序与恶意程序进行分类。根据使用的特征性质,可以将恶意代码检测技术分为静态检测[6-7]和动态检测[8]。然而机器学习分类器在多个领域都被证明是不安全的。随着机器学习越来越广泛的应用,对抗样本攻击和防御的研究也在变得越来越有意义,这一领域通常被归为对抗机器学习(adversarial learning)。在恶意代码检测问题上,基于机器学习的分类器在面对对抗样本攻击时也可能是非常脆弱的。因此,研究在恶意代码检测问题上的对抗样本生成技术可以增加对这种攻击方法的了解,避免将分类器暴露在这种攻击之下,从而针对该攻击提出针对性或者普适性的防御方法。同时,研究人员可以通过攻击方法攻击其所研究的分类器,对分类器的鲁棒性进行评估。
本文提出了一种基于模型无关的局部可解释(local interpretable model-agnostic explanations,LIME)[9]的对抗样本生成方法。该方法可针对未知算法和参数细节的分类器生成有效的对抗样本,并且通过引入扰动常量,使该方法具有了适用范围广泛、灵活控制扰动大小的优点。同时,在实验中验证了该方法的健全性。
1 相关研究
为使提出的对抗样本生成方法不仅可攻击分类器,同时有助于评估防御[10]、提供具体级别的安全产品[11],针对对抗样本相关技术、攻击者对抗能力的描述和样本修改进行了相关的研究。
1.1 恶意代码对抗样本相关技术
对抗样本攻击意为通过微小地修改机器学习分类器的输入样本,诱导分类器对修改后的输入产生错误的输出结果。2014年,Szegedy等[12]在神经网络模型背景下给出了严谨的问题描述,之后出现了基于梯度的白盒解决方案[13]。但是因为现实中的大部分分类器都是闭源的,相较于白盒方法,黑盒更具有广泛的使用价值。
2017年,Hu和Tan[14]提出了MalGAN,其是一种针对恶意代码分类器的黑盒对抗样本生成方法。使用该方法可以对一些使用One-Hot型(只有0和1两种取值)特征的黑盒分类器生成对抗样本。
2017年,Chen等[15]提出零阶优化(zeroth-order optimization,ZOO)方法,其是一种基于零阶优化估计目标分类器梯度进而生成对抗样本的方法。由于不需要梯度,ZOO也是一种黑盒方法,使用ZOO无需额外训练模型。
2016年,Ribeiro等[9]提出LIME方法,其是一种与模型无关的方法(model-agnostic)。原理是:使用可解释的简单模型在局部逼近目标模型,无论目标模型有多复杂,其在局部(可理解为切点)的趋势(可理解为切线)都可以用一个简单模型来刻画,从而通过简单模型解释局部的特征权重。对于给定的目标模型f和输入向量x,LIME方法可以在f的局部使用简单模型模拟目标模型的局部性质,从而判断x各分量对分类结果的影响权重。局部模拟需要一组与x相近的特征,使用z代表临近特征。LIME对特征的解释ξ(x)通过下式表达:

式中:g∈G,G为用于模拟目标模型的简单模型集合,通常包括线性模型和决策树;Πx(z)用于度量局部特征z和x的接近程度;Ω(g)用来衡量g的复杂性(不利于解释的程度),通常取决于选用的简单模型,如选用决策树,决策树的深度就是影响Ω(g)的主要因素;L为损失函数,用来描述g在x附近模拟f的效果,模拟效果越好,则L的值越小,L的一种实现如下:
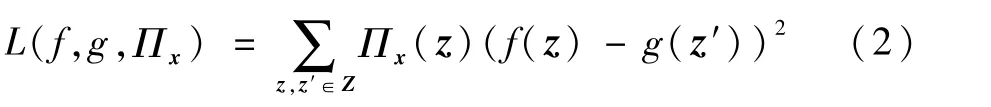
在L中,z和x的距离越小,则Πx(z)越大,也就是说,离x越近,误差权重越大,通过最小化,这样的损失函数使g在x局部获得较好的模拟效果,而L(f,g,Πx)+Ω(g)最小,意味着使局部模拟和可解释的综合效果最好。Ribeiro等[9]用KLasso算法选择k个特征(通过正则化路径),基于对x的随机扰动生成一组数据,通过最小化L(f,g,Πx)+Ω(g)学习到最优的简单模型g,通过对g的参数w分析即可得到特征权重,如当g是线性模型时,g的参数w就对应了每个特征的权重。如果k被设置为特征的总数,那么将得到所有特征的权重。由于LIME方法在设计时没有对目标模型做任何假设约束,使用时无需知道目标模型的算法和参数,理论上可用于解释任意黑盒模型。因为只在局部用简单模型模拟,效果好速度快,所以这也是本文所设计的对抗样本方法选用LIME的原因。
1.2 对攻击者能力的描述
精确的描述攻防场景,需要对攻击者的攻击能力做出合理的预估[16]。本文采用Stokes等[11]的方法,将特征分为正特征(positive feature)和负特征(negative feature),正特征表示样本中有利于使分类器判断为恶意代码的特征,这些特征往往代表恶意行为,负特征表示样本中有利于使分类器判断为良性代码的特征。Crandall等[17]指出,攻击者通常采取变构策略,使用替代代码的方式来达到所需的恶意目标,攻击者有能力删除正特征或添加负特征。在MalGAN方法中,假设攻击者只能添加特征,不能删除特征,从而保证不影响原样本的程序特征,但该方法不对添加特征的数量进行限制,本身的假设存在低估攻击者对抗能力的可能。Incer等[18]使用了特定的对抗能力来描述其所提供的安全机制的安全边界,通过分析一系列特征的修改,并评估每种类型的修改是否简单廉价,从而确定攻击者的对抗能力。但是在对这些类别的修改进行评估时,评估的标准缺少灵活性。事实上,对于攻击能力较强的专业黑客,即使是被认为困难的修改,也是可以完成一定数量的,而对于被认为是简单廉价的修改,在现实场景中,攻击者也不一定会不计数量的大量修改,大量未使用的特征可能增大被检测为对抗样本的概率,如Xu等[19]提出一种检测对抗样本的方法,筛选被添加到原样本中却未使用到的修改作为检测标准之一。
基于上述分析,可以明显看到这些假设容易低估或者高估一些攻击者,导致只能用于特定研究背景,具有一定的局限性。为了寻找适合衡量对抗能力的方法,需要进一步分析攻击者修改样本的过程。
1.3 样本修改过程
攻击者在其能力和成本范围内对原样本进行修改,在保证新样本可执行的前提下,要确保新样本与原样本主要程序功能相同,即保证对抗样本的有效性。一般修改的过程分为2个部分:逆提取和逆预处理。逆提取中,针对新旧样本的差异特征r和中间层表示的对应关系,通过直接修改中间层文件或者样本的源代码以满足在不影响其他特征的基础上添加新特征。逆预处理实现修改后的中间层文件到可执行文件的转变,可以通过逆向工程的方式从中间文件转换为可执行文件,甚至若在逆提取阶段中直接修改源码,则可编译得到可执行文件。
通过对攻击过程进行分析可知,修改样本的难度和成本主要体现在逆提取过程中。因此引入扰动常量的概念,用于描述攻击者的对抗能力,并提出基于LIME的扰动方式的实现。
2 对抗样本生成方法设计
2.1 基于LIME的恶意代码对抗样本生成过程
对抗样本的生成过程主要包含4个部分:探测(A部分)、扰动算法(B部分)、逆向过程(C部分)和验证部分(最下方虚线部分),如图1所示。

图1 基于LIME的恶意代码分类器对抗样本生成过程Fig.1 Adversarial sample generation process of malicious code classifier based on LIME
本文对抗样本生成方法所解决的问题可描述为

式中:mal(malicious)为恶意代码分类标签;ben(benign)为良性代码分类标签;x为目标分类器f的输入,表示恶意代码中提取的特征;r为对x的扰动(perturbation);函数g为获取样本的主要程序功能,g(x)为x原本的主要程序功能,g(x+r)为修改后的主要程序功能。在保证代码语义的前提下,诱使目标分类器将恶意代码标识为良性代码。对图1的4个模块做出具体阐述如下:
1)探测。通过特征工程获取样本特征,探测目标分类器f的分类结果,当结果为ben时结束方法,否则进行下一步。
2)扰动。使用基于LIME的扰动方法生成一个扰动r,满足f(x+r)=ben,生成成功则进入下一步,失败则方法以失败结束。
3)逆向过程。根据扰动r修改相应样本程序,生成最终可逃逸检测的对抗样本,使用该对抗样本再次进行步骤1的探测,应能够正常结束方法,否则可能是在逆向过程出错,检查错误后重试方法。
4)验证过程。如果修改后的样本满足式(4),且能够按照探测模块的方法再次探测,并能得到探测结果ben,则验证通过,结束方法。
2.2 扰动算法设计
扰动模块的实现包括2个方面:扰动常量和扰动方式。扰动常量形式化地描述了攻击者在有限成本内修改样本,且保持样本主要功能不变的能力。扰动常量越大,攻击者能力越强;扰动方式指定了对于具体特征的修改,不同于使用雅可比算法[20]等白盒方法,使用LIME模拟黑盒分类器在恶意样本处的局部表现,从而确定影响样本分类的关键特征,然后使用一个扰动算法,在保证不影响输入样本主要程序功能的同时,修改部分关键特征。
2.2.1 扰动常量
扰动常量R,用于描述在特定攻击场景下攻击者的成本和能力边界,也就是对抗能力——攻击者在有限成本内修改样本,且使修改后的样本保持原样本主要程序性质不变的能力。以下是R的一般形式:

式中:k为正整数;di、si1和si2均为实数。R为一个k×3的向量,包含k个扰动规则;i-th表示第i个扰动规则,通常用1个或2个扰动规则描述一种特征,对应添加和删除规则。不妨假设i规则描述一种A特征,则攻击者使用i规则对A特征所能修改的维数比例的最大值用di表示,di取值在[0,1]之间,如果A特征在特征向量中一共m维,攻击者真实修改的A特征维数应不大于m×di;用s描述对具体某维特征的修改能力,允许对某个特征在初始值的基础上加s,这里的si1和si2用来描述s的取值范围。当si1与si2确定时,区间[si1,si2]表示对所有A特征,s取值应在[si1,si2]范围内。这个区间往往由特征的性质、攻击者的攻击成本和能力所决定。这样k个扰动规则综合起来,就描述了R表示的范围。攻击者能力越强或越不计成本,R表示的范围就越大;特征越容易修改,R表示的范围也越大。
2.2.2 基于LIME的扰动方式实现
扰动方式指定了对于具体特征的修改。首先使用LIME方法求解出逼近真实情况的ω。在LIME方法中,需要选择简单模型g来模拟目标分类器,这里以线性模型为例,那么g(x)可以表示为

式中:ω={ω1,ω2,ω3,…,ωm}为g的参数。使用K-Lasso算法选择k个特征(通过正则化路径),然后基于对x的随机扰动生成一组临近x的数据,在这组数据基础上最小化损失函数L(f,g,Πx),可以得到此时g的参数ω,用ω近似表示特征x的权重,即令w=ω,从而求解出w,如果k被设置为特征的总数,那么将得到所有特征的权重。
当攻击者获取权重w之后,需要根据w和扰动算法生成一个符合式(3)、式(4)的扰动r,且攻击者可以在对抗能力范围内对恶意样本做出r对应的修改。不妨设分类器给出的置信度在[0,1]区间内,以0.5为分界,0表示百分之百确定是ben样本,1表示百分之百确定是mal样本。创建扰动r的过程如算法1所示。
算法1 创建扰动r的算法。
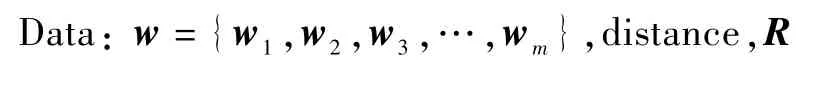
Data:w={w1,w2,w3,…,w m},distance,R

1 r←{Δx1,Δx 2,Δx3,…,Δx m},Δx i=0 2 U←{(1,w1),(2,w2),(3,w3),…,(m,w m)}3 sum←0 4 list←sortw(U)//根据w i的绝对值进行递增排序5 if not list then 6 return fail//list为空7 end 8 while list do 9 i,w←list.remove(0)//移除第1个元素10 Δx i←arg minΔx,Δx∈RΔx·w 11 sum←sum+Δx i·w 12 if sum<distance then 13 break 14 end 15 end 16 f(x+r)←ben?return r:distance←distance×2,go 5
攻击者首先探测到分类器f检测恶意样本x的置信度confidence=f(x),对于恶意样本,confidence在(0.5,1]之间。由于w是已经求得的,攻击者需要在x中选择一些维度,在使confidence减少的方向上,做一些能力和成本范围之内的改变。考虑g取线性模型的情况,此时有g(x)=w·x,且g(x+r)=g(x)+g(r),因为g(x)是对f(x)的局部模拟,攻击者可以通过g近似计算confidence,所以一般满足g(r)=w·r<-0.2即可。在具体选择r的维度时,由于w已经用LIME方法求得,可以使用贪心法,按权重由大到小,依次判断能否对相应特征做出符合R要求的修改,从而挑选合适的维度,用Δx∈R表示对某个特征进行Δx的变动是符合R要求的修改,如果符合,就加入候选维度。
3 实验评估
为了验证本文所提出的基于LIME的对抗样本生成方法的效果,分别进行攻击实验和对比实验。攻击实验用于测试本文方法在目标分类器上的攻击效果;对比实验用于和同类方法做比较,增强结论的说服力。本节将介绍实验环境、数据集、评估指标、目标分类器设置以及实验设计。
3.1 实验环境
实验的软硬件环境信息如表1所示,实验代码主要使用Python3.6.3实现,在数据集准备环节借助了IDA pro 7.0提供的Python 2.7.17脚本执行接口,在IBM 提供的adversarial-robustness-toolbox 1.1.1包中,封装了许多应用于机器学习分类器的攻击与防御方法,这包括本文要使用的ZOO方法,此外本文所要使用的LIME方法被封装在lime 0.1.1.37包中。
表1 实验的硬件、软件环境Table 1 Hardware and software environment of experiment
3.2 数 据 集
本文收集了2组不相交的Win32 PE文件,这2组文件的收集方式借鉴于文献[21],对于每个PE文件,都使用其IDA pro反汇编生成的ASM文件来代表PE文件。良性样本源于系统镜像中使用ninite[22]安装的50多个供应商的应用软件,进而有效避免学习和识别与特定供应商相关联的文件[23]。恶意样本包含来自Ramnit、Lollipop等9个恶意代码家族的10 868个Win32 PE恶意程序对应的ASM 文件,这些文件来自2015年微软举办Kaggle比赛[24]时公开的数据。
3.3 评估指标
因为攻击者希望原本被识别的恶意样本,经改变为对抗样本后,被标识成良性样本,攻击前后的真阳性率TPR之差就是有效对抗样本的比例。为了直观考虑,将攻击前后的TPR之差与攻击前的TPR之比称为攻击成功率,表示为ASR,则有ASR=1-TPRafter/TPRbefore;除上述2个指标外,为了保证说服力,本文采用准确率ACC来评估自建的目标分离器,仅保留那些准确率90%以上的分类器纳入实验。采用的评估指标如表2所示。表中:TP为真阳性样本数量,FP为假阳性样本数量,FN为假阴性样本数量,TN为真阴性样本数量。

表2 评估指标Table 2 Evaluation indicators
为充分测试方法的效果,目标分类器根据使用的算法或特征差异,可分为18个,如表3所示。算法涵盖线性、树形和深层神经网络类算法,包括LR、RF、SVM、MLP算法,特征包括API、opc-2gram、opc-3gram。
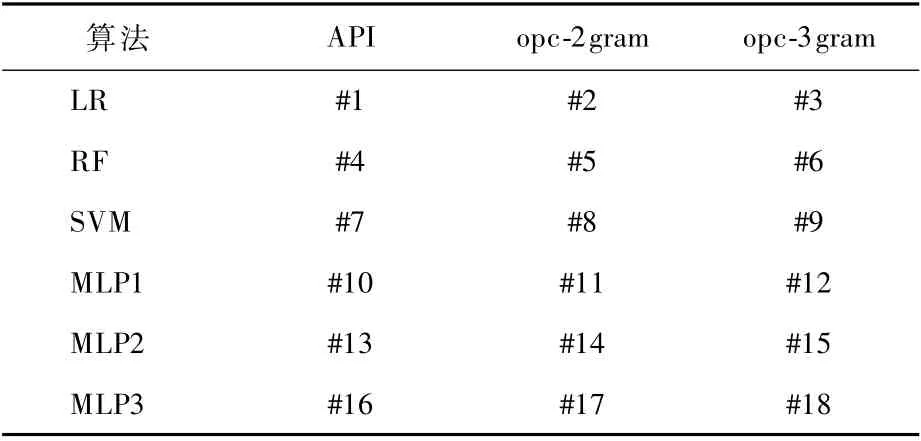
表3 目标分类器设置Table 3 Target classifier setting
将算法用集合alg表示,特征用集合fea表示,alg与fea做笛卡儿积,则有12个有序对组合(表3的#1~#12),用一个数字编号表示一种组合,例如,#1表示(API,LR),代表使用API特征和LR算法训练的一个分类器。考虑到基于MLP的模型根据隐层数不同可能存在较大的性质差异,对#10~#12分类器额外设置了2组不同层数的分类器,因此共有18个目标分类器。
3.4 实验设计
攻击实验中,恶意样本数据集有60%用于目标分类器的训练,在剩余的40%中,在9个恶意代码家族各随机选取了20个样本,将这180个样本称为攻击样本,用于生成对应的对抗样本。
使用本文的对抗样本生成方法,生成上述180个攻击样本的对抗样本来攻击每一个目标分类器。用扰动常量控制扰动大小[25],绘制扰动大小-TPR图、扰动大小-ASR图,以获得不同扰动强度下的攻击效果。为进一步增强说服力,本文设计了对比实验:复现MalGAN和ZOO这2个先进的黑盒对抗样本生成方法,生成攻击样本的对抗样本,攻击#1、#4、#7、#10、#13、#16分类器,记录TPR攻击前后的变化,并与本文方法进行对比分析。
3.5 实验与结果
图2为基于不同扰动维度(Dr)生成对抗样本,攻击各目标分类器产生的TPR和ASR的变化图。查看TPR图可以发现,18个分类器的TPR均降到了接近0的水平,即在较高扰动代价情况下,本文方法几乎100%成功地攻击任意恶意代码分类器。
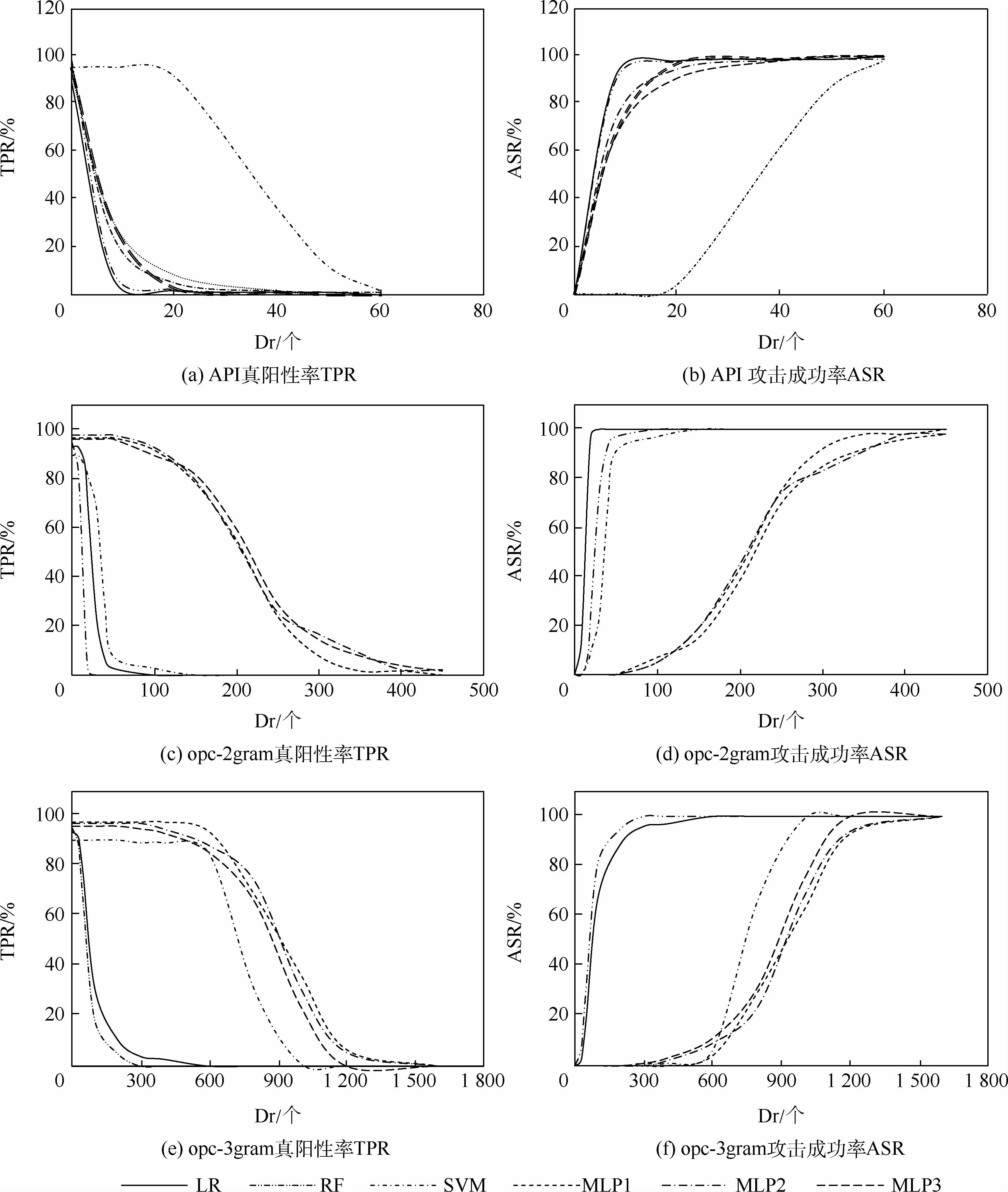
图2 三种特征的Dr-TPR图和Dr-ASR图Fig.2 Dr-TPR and Dr-ASR of three characteristics
对比实验中,使用MalGAN和ZOO生成攻击样本的对抗样本,攻击#1、#4、#7、#10、#13、#16分类器。每个分类器性质不同,选用参数也有差异,本文倾向于选择使对抗样本更有效的参数,经过多次实验,结合本文方法汇总如表4所示。
从表4可以看出,MalGAN和本文方法都具有较好的效果,且攻击效果相似(将TPR降到更低,且降幅相似)。ZOO在实验中表现不佳,攻击后的TPR 都 在50%以 上;MalGAN 将#1、#10、#13、#16分类器的TPR降到0,#4、#7分类器的TPR降到1.67%和0.56%;本文方法将#1、#4、#10、#16分类器的TPR降到0,而#7、#13分类器的TPR分别降到1.67%和1.11%。为了进一步对比这3种方法,比较了3种方法生成的对抗样本本身的差异。

表4 API特征分类器的真阳性率对比Table 4 API feature classifier and TPR compar ison
实验中的API特征是One-Hot型的,对应取值应该是0或者1,而ZOO在特征中可能出现-3、-1、2等值,只能通过筛选来获取符合要求的对抗样本,这将导致有效对抗样本进一步减少;MalGAN适用于One-Hot类型的特征,主要对比其生成的对抗样本的扰动维度。表5为MalGAN和本文方法在对各分类器取得较好攻击效果时的平均扰动维度Dr。其中,攻击效果相似的情况下,本文方法比MalGAN生成的样本平均扰动维度小,这可能因为本文方法有针对扰动大小的设计。

表5 两种方法生成的对抗样本平均扰动维度Table 5 Average perturbation dimension of adversarial samples generated by two methods
4 结 论
1)本文方法是一种有效的黑盒对抗样本生成方法。使用该方法生成的对抗样本测试黑盒的恶意代码分类器,能显著降低分类器的真阳性率。
2)本文方法适用范围广泛。使用该方法攻击18个不同算法或特征的目标分类器,均有不错的攻击成功率。目标分类器的算法涵盖了线性算法、树形算法和深度神经网络算法,而特征既有One-Hot型也有数值型。
3)本文方法能有效控制扰动的大小。可以通过设置不同的扰动常量来控制对抗样本的扰动维数和扰动范围。
4)本文方法具有健全性。随着扰动的增大,攻击成功率是严格递增的;随着扰动持续增大,攻击成功率接近或达到100%。虽然过大的扰动可能会使对抗样本失去意义,但可以说明该方法是健全的。
