基于情感对象识别和情感规则的微博倾向性分析
2022-03-08王泽辰王树鹏孙立远张磊王勇郝冰川
王泽辰,王树鹏,*,孙立远,张磊,王勇,郝冰川
(1.中国科学院信息工程研究所,北京 100193; 2.国家计算机网络应急技术处理协调中心,北京 100085)
微博作为中文社交平台,具有强大的影响力和渗透力。微博用户不断增加,2020年第1季度财报显示,微博日活跃用户达2.41亿,月活跃用户达5.5亿。这些用户在平台上建立关系、获取信息及生产大量内容。在微博文本信息中,大量博文包含带有明显情感色彩的内容。挖掘这些文本背后用户的观点与倾向,可以判断流行趋势和热点,有助于企业分析消费者购买倾向,进行精准化营销,也使得政府可以对网民的舆论立场变化做出及时反应。因此,对微博文本进行倾向性分析,进而完成对博文立场的判定,是情感分析中一项重要的研究任务。
情感分析以对特定文本进行处理及挖掘其中情感色彩为目的,是自然语言处理的重要分支,近年来受到了广泛关注。提取情感词是分析微博所表达情感最直接的方法。微博文本具有长度较短、内容形式多样、观点倾向性强、表达方式口语化、普遍缺少上下文信息等特点。针对微博数据有许多情感分析的研究,结合情感词典对微博进行分析的方法较为直观。通过对微博中包含的情感词进行分类,可以简单地概括其中蕴含的情绪。但是1条微博所表达的信息不仅与其包含的情感词相关,即使2条微博包含完全相同的情感词,当情感词所指向的对象不同时,微博的观点与倾向性会存在明显差异。例如,电子产品制造商可能只希望关注用户与手机、电脑等相关的微博情感信息,而不关心对食品、日用品等的购买倾向;在舆情方面,要分析网民在讨论社会热点问题时的立场,不仅需要辨别微博表达的态度是积极还是消极,还需要确定微博支持或反对的实体是什么。另外,中文词汇的多义性使得同一词语在不同语境下指代的实体含义可能不同。随着网络语言的发展,用于实体表示的新词也层出不穷,用户常常用品牌缩写、谐音、流行语等进行指代,这些依赖人工标注的实体往往需要很大的工作量。因此,如何针对海量微博数据进行倾向性分析,从而实现立场判定,是目前亟须解决的问题。
为解决微博倾向性分析的问题,本文将深度学习的方法与情感规则相结合,基于句法规则进行博文情感分析,指定相应的情感规则,结合协同学习和主动学习的方法,可以在仅依赖少量标注数据的前提下准确判断博文对指定类型实体表达的情感。
本文主要有以下3点创新:
1)利用半监督学习的方式,通过协同训练加主动学习的方式,同时利用半监督学习结合主动学习的模式,确定指向性实体集。
2)不同于传统的情感规则,本文提出了基于主成分分析的情感规则,通过识别指定方向实体,结合情感词对博文进行倾向性判断。
3)生成指定类别实体集,结合情感规则,判断博文的立场,实现对博文更深层次的分析。
1 相关工作
网络舆情中的情感识别问题得到了学界广泛关注。网络社交平台数据是情感识别任务的重要数据来源。例如,基于Twitter平台数据,Giachanou等[1]建立了情感分析方法,训练、分析推文内容的情感倾向性。类似地,微博作为受众广、数据规模大的中文平台,吸引了许多学者对其数据开展研究。
微博情感分析方法主要有3种:
1)基于语义词典的方法。该方法需要先构建微博情感分析数据库,一般包含多个词典和句法规则库,再利用知识库进行聚合计算。例如,王志涛等[2]提出了一种基于词典和规则集的中文微博情感分词方法,将词典和语义规则结合进行情感分析。王灿伟[3]提出了结合情感词典和感情符号来计算微博情感值的方法,实现主题归类和情感分类。语义词典通过构造情感词典,筛选出微博文本中的情感词,计算文本片段的情感权值,从而判断微博的情感倾向。Ebrahimi等[4]提出了将情感极性融入到情感对象和情感立场中的方法,通过对数线性联合建模实现立场判定。
2)传统机器学习方法。该方法普遍应用于情感分类,其核心思想是构建特征向量,找到特征与分类结果之间的关联。朴素贝叶斯(naive Bayes)、最大熵(maximum entropy,ME)、支持向量机(support vector machine,SVM)等方法常用于情感分类[5]。Pang等[6]使用了电影评论作为数据,采用以上3种机器学习方法进行情感分类。奠雨洁等[7]使用SVM、随机森林和梯度提升决策树对文本特征进行立场检测,并利用特征分类器进行立场融合。这些方法具有训练时间短及特征维度高的特点,但不能充分利用上下文信息和语法信息,且需要大量手工标注。
3)基于深度学习的方法。该方法对微博博文进行分词,将其表示为词向量,通过深度神经网络提取语义信息,构建情感表征向量,并利用微博情感表征完成情感分类任务。深度学习模型在情感分析上取得了很好的效果[8],特别是基于长短期记忆网络(long and short term memory,LSTM)方法,在长语句分析上取得了很好的结果[9]。除此之外,还有基于双重注意力模型[10]、监督学习[11]、集成学习[12]的方法。
通过对上述已有工作进行总结和分析,可以将基于语义词典、传统机器学习和深度学习的微博情感分析方法的特点进行对比,结果如表1所示。由表1可知,深度学习方法能够充分利用文本信息,往往具有更好的效果。基于深度学习的情感分析又可细分为无监督学习、有监督学习和半监督学习3种方法。

表1 微博情感分析方法的特点Table 1 Features of Weibo sentiment analysis methods
在无监督学习方法中,所有数据都缺少情感标注。Turney[13]提出了情感倾向性分类的方法,通过选取指定词汇,分别计算每个词与情感词典中积极、消极情感词的交叉熵,以ME值作为情感词分类判断标准。除此之外,还有基于语法分析[14]、句法模式[15]等方法的研究。上述方法可以发掘文本数据中内在的词汇情感规律,节约人工标注的成本。
有监督学习情感分类问题主要关注特征选择和分类器设计。例如,文献[16]中采用了词性特征,Cambria等[17]引入了符号特征和词嵌入特征。基于商品评论中产品特征信息的情感分类采用有监督学习方法[18],具有较高的运行效率。但是,如果在有监督学习中出现分类错误,那么之后的学习都会受到这个错误的影响。为了解决这个问题,有学者提出了半监督学习方法避免准确率的下降。
Sindhwani[19]和Liu[20]等 分 别 提 出 了 采 用 半监督学习方法进行情感分析。半监督学习包括自训练、协同训练等方法。自训练[21]方法是较早提出的一种半监督学习方法,先训练初始分类器,再使用该分类器对未标注的数据进行标注,选取分类准确度较高的样本确认标注,直到经过多轮迭代后所有样本都完成标注为止。半监督学习方法仅需要标记少量数据,适用于数据量大的任务。
对基于深度学习的方法进行总结和分析,将基于无监督学习、有监督学习和半监督学习的深度学习情感分析方法的特点进行归纳,结果如表2所示。
由表2可知,采用半监督学习方法,在情感分析任务上可以取得较好的效果。基于情感分析研究现状,本文提出了基于情感对象识别与情感规则的倾向性分析(orientation analysis based on sentiment object recognition and sentiment rules,OASOSR)算法,不仅能够确定博文中的情感词,还可以分析情感词指向的实体是否为目标实体。

表2 基于深度学习的情感分析方法特点对比Table 2 Comparison of features of sentiment analysis methods based on deep learning
2 OASOSR算法
OASOSR算法框架如图1所示,主要分为2个部分:①基于协同训练和主动学习的实体识别模型;②基于情感词典和句法分析的微博倾向性分析。

图1 OASOSR算法总体架构Fig.1 Algorithm architecture of OASOSR
基于协同训练和主动学习的实体识别模型部分采用半监督学习方法,将少量已标注的微博文本数据集作为初始输入,协同训练2个不同的实体识别模型。为了在协同训练中比较模型训练效果,基于这2个实体识别模型构建2个分类器,分别包括实体集、情感词典和情感规则3个部分。在协同训练的过程中,首先,从未进行实体标注和立场判定的数据集中抽取一定数量的数据,并利用这2个训练过的实体识别模型对未标注语料进行实体识别。同时,2个实体识别模型通过判断微博文本中的实体类型,提取指定方向的实体,各形成1个实体集。然后,在这2个实体集的基础上,构造2个分类器,利用分类器分别结合情感词典和情感规则来判断微博立场,并对同一条博文进行倾向性分析。比较2个分类器得到的倾向性分析结果,判断样本置信度,从中选择高置信度(即2个分类器输出结果完全相同)的样本,并为此类样本添加指定类别的实体标记和倾向性标签,合并到已标记博文数据中。同时,对于低置信度的样本,采用主动学习模式,将分类器挑选出的分歧大(2个分类器标注结果不同)的样本添加到已标注的数据集中。将更新扩充后的有标注数据集重新输入到协同训练模型,再次训练上述2个实体识别深度学习模型,不断迭代直到已标记的博文数据集达到足够的规模,进而获取最大的指定方向实体集。2.1节将详细介绍微博实体识别模型及指定方向实体集的训练过程。
在基于情感词典和句法分析的微博倾向性分析部分,首先,模型基于学习得到指定方向实体集。然后,针对需要立场判断的微博数据,判断微博是否与指定方向的实体相关。如果微博文本中包含指定方向实体集内的任意实体,则对此类微博根据预先编写的情感规则和情感词典进行倾向性分析,实现对微博文本的立场判定。2.2节将重点讨论OASOSR算法中基于情感词典和情感规则的倾向性分析。
2.1 基于协同训练和主动学习的实体识别模型
本节详细介绍基于协同训练和主动学习模型的构造细节、训练过程及微博情感对象实体集的提取流程。
协同训练假设数据拥有2个充分且条件独立的视图,即每个视图所包含的信息都可以支持生成最优学习器,且在给定类别标记的条件下2个视图相互独立。利用未标记数据在每个视图上都训练生成1个分类器,每个分类器选择置信度最高的样本生成伪标记,再将这些伪标记作为标记样本训练另1个分类器。本文对层叠隐马尔可夫模型(cascaded hidden Markov model,CHMM)和条件随机场(conditional random field,CRF)实体识别学习模型进行协同训练。
隐马尔可夫模型(hidden Markov model,HMM)是一种在自然语言处理领域中被广泛应用的统计模型。中文命名实体识别中的人名识别、地名识别、译名识别及机构名识别等都可以用HMM来解决。本文利用CHMM 在统一的HMM中识别各类实体命名,自底向上分为人名识别HMM、地名识别HMM 和机构名识别HMM 3层。每一层HMM将产生的最好的若干个结果送到词图中供高层模型使用,最终实现人名、地名和机构名的实体识别。
CRF模型是一种基于统计的判别式模型,结合了ME模型和HMM 模型的特点。CRF模型根据样本的特征生成预测,对所有的特征权重进行最优化,进而得到最优解,解决了HMM模型因独立性假设而导致其不能考虑上下文特征的问题。在本文模型中,从经过分词的数据中挑选出包含在特定微博主题标签内的数据实体,形成候选词集。再利用CRF模型对候选词集中的候选实体进行实体抽取。
本文采用协同训练和主动学习的方法训练以上2个模型。主动学习方法具有在训练集较少的情况下能够获得较高分类准确率的优势,是对有监督学习方法的一种改进。有监督学习方法在学习过程中被动接受人工标注的样本集,通过将标注样本映射到目标函数空间来学习知识。而主动学习方法则试图从未标注的池中选择数量尽可能少的、机器无法正确标注的样本(低置信度的样本),并由领域专家进行标注后添加到下一次迭代过程中作为训练集,以提高分类的效率。主动学习通过选择质量高的少数样本进行学习以保证分类器的分类性能,同时,也可以减轻样本的标注复杂度。
情感对象实体集提取流程如图2所示,采用了半监督学习方法,通过协同训练和主动学习的方式对2个实体识别学习模型进行训练。在实体及情感类别已标注数据集中,有少量已标注微博文本分别标注了博文中包含的实体(实体1、实体2等)和博文情感类别(正向、负向)。将有标注的微博文本进行切词处理,分别输入到CHMM 和CRF实体识别学习模型,初步训练这2个模型。
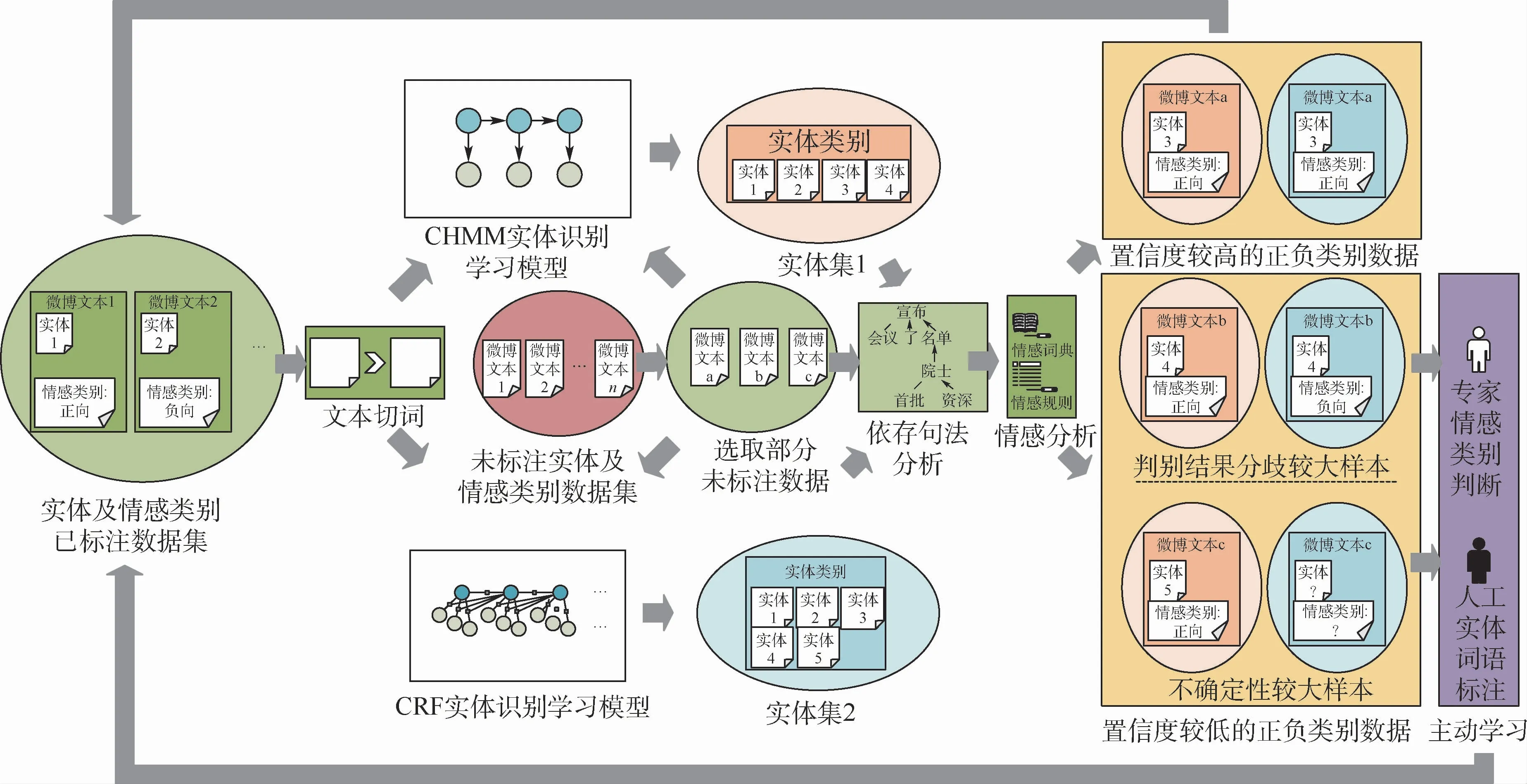
图2 情感对象实体集提取流程Fig.2 Extraction flowchart of sentimental object entity sets
在对CHMM和CRF实体识别学习模型进行协同训练的过程中,先从未标注实体及情感类别数据集中选取部分数据(微博文本a、b、c),输入到经过初步训练的CHMM 和CRF实体识别学习模型,提取博文中指定方向的实体,分别得到实体集1和实体集2。分别基于2个实体集对相同的未标注数据进行依存句法分析,再基于给定的情感词典和情感规则进行情感分析,判断微博文本的情感类别。对于每条微博,都有基于实体集1和实体集2的2个标记结果,每个标记结果都包括微博所含有的实体(实体n)和倾向(正向、负向、无法判断)。比较基于实体集1和实体集2得到的标记结果,针对同一微博文本,若2个分类器得到的结果中所标记实体和情感类别都完全相同,则判断该结果为置信度较高的正负类别数据。直接将这条微博文本和对应实体、情感类型标注添加到实体及情感类别已标注数据集;若2个结果中所标记实体或情感类别不完全相同,则判断该结果为置信度较低的正负类别数据,需要采用主动学习的方法处理。对于这类数据,针对同一微博文本,若2个分类器提取的指定方向实体完全相同,但情感类别相反,则认为该样本是分歧较大样本,需要将结果交由领域专家进行情感类别判断。若2个分类器提取的指定方向实体不同,或有1个分类器没有提取出指定方向实体,则认为该样本是不确定性较大样本,需要进行人工实体词语标注。同样地,将经由主动学习得到的微博文本和对应实体、情感类型标注添加到实体及情感类别已标注数据集,这样就完成了协同学习的第一轮循环。
对这一过程进行迭代,不断扩充实体及情感类别已标注数据集,直到已标记数据的数据量达到设定的停止阈值。获取该数据集中的所有标注实体所组成的实体集,作为2.2节中微博倾向性分析的基础。
2.2 基于情感词典和情感规则的微博倾向性分析
本节介绍基于情感词典和情感规则进行句法分析的微博立场判断算法。该算法通过情感规则识别微博中情感词所充当的句子成分,分析情感词与目标实体之间的修饰关系,从而判断微博的倾向性。然而,情感规则的制定依赖于依存句法分析。汉语语句以词语为基本单位,在词语之间拥有依存和支配关系。依存句法分析理论能够借用各级语言单位的依存关系,清晰地提炼出成分之间的修饰和搭配信息,从而达到解析语句的目的,进而总结句子成分之间的关联,制定情感规则。
基于情感词典和情感规则的微博倾向性分析算法包含文档预处理、条件判断、实体信息判断、句法分析及规则判断5个步骤,输出结果为对应输入博文的博文倾向性类别。算法流程如图3所示。
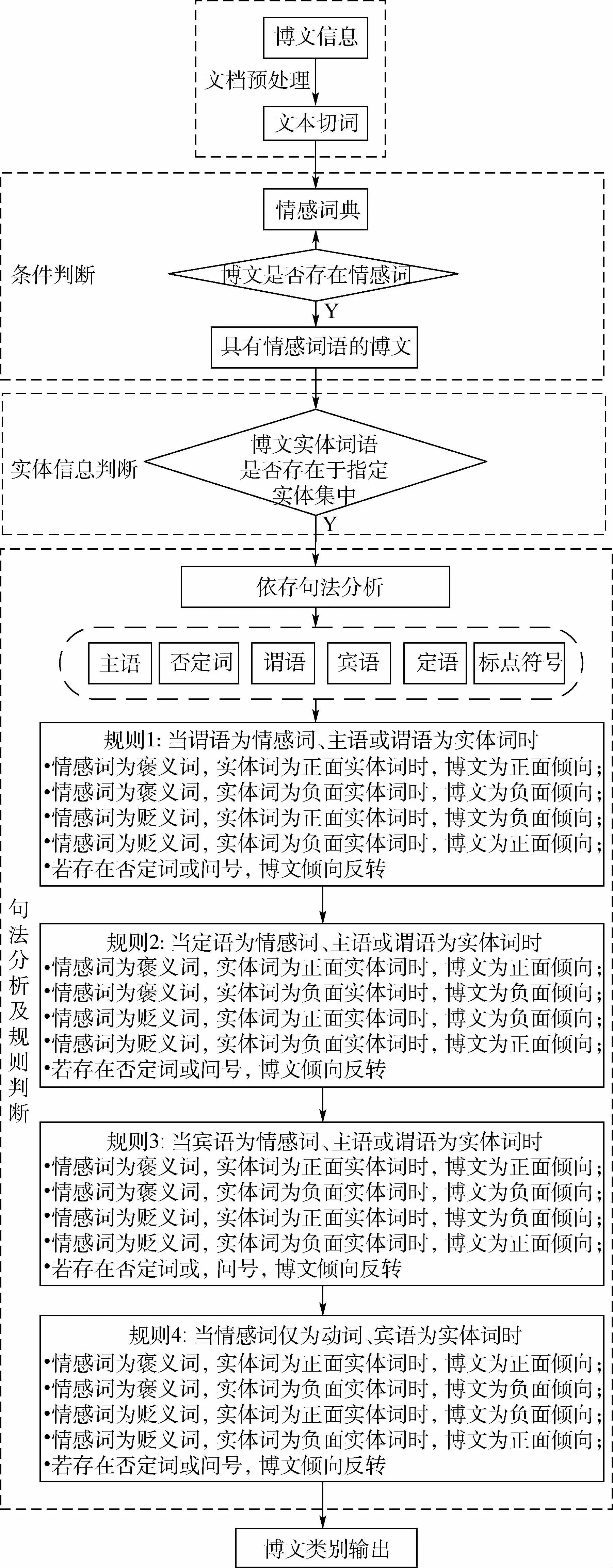
图3 OASOSR算法流程Fig.3 OASOSR algorithm flowchart
首先,对原始博文进行数据清洗,经过简化繁体字、删除无效评论等操作后,得到有效数据,再使用结巴分词(数据来源:https://github.com/fxsjy/jieba),并去除分词结果中的停用词。然后,基于情感词典,对经过处理的微博文本数据进行情感词判断。显然,只有包含情感词的微博文本才能表达倾向性,不包含情感信息的微博不具有立场分析的价值。因此,本文采用大连理工大学情感词汇本体库DUTIR情感词典(数据来源:http://ir.dlut.edu.cn)判断博文中是否存在情感词,筛选出含有情感词的微博文本,进行下一步处理。在含有情感词的微博文本基础上,进行实体信息判断,筛选出包含指定方向实体的微博。实体信息判断基于2.1节中通过协同训练和主动学习得到的实体集完成。最后,提取微博文本中实体词语,若实体存在于该指定方向的实体集之中,则筛选出这条微博,对其中的句子进行依存句法分析。通过识别句子的主语、否定词、谓语、宾语、定语、标点符号等成分,基于句法分析、情感规则将句子分为4种不同的类型:①当谓语为情感词、主语或谓语为实体词时;②当定语为情感词、主语或谓语为实体词时;③当宾语为情感词、主语或谓语为实体词时;④当情感词仅为动词、宾语为实体词时。
情感词在句子中充当不同成分时,具体分类规则如OASOSR算法所示(见图3)。经过对应的情感规则判断,最终输出该微博文本的立场。
算法1 OASOSR算法。
输入:微博文本。
输出:博文类别。
步骤1 文档预处理。文本切词。
步骤2 条件判断。依据情感词典判断博文是否存在情感词,若存在情感词,则对句子进行下一步处理。
步骤3 实体信息判断。提取博文中实体词语,若实体存在于指定实体集之中,则进行下一步处理。
步骤4 句法分析及规则判断。
步骤4.1 对句子进行依存句法分析,识别句子的主语、否定词、谓语、宾语、定语、标点符号等成分。
步骤4.2 设定情感判断规则。
1)规则1:当谓语为情感词、主语或谓语为实体词时:
①情感词为褒义词,实体词为正面实体词时,博文为正面倾向。
②情感词为褒义词,实体词为负面实体词时,博文为负面倾向。
③情感词为贬义词,实体词为正面实体词时,博文为负面倾向。
④情感词为贬义词,实体词为负面实体词时,博文为正面倾向。
⑤若存在否定词或问号,博文倾向反转。
2)规则2:当定语为情感词、主语或谓语为实体词时:
①情感词为褒义词,实体词为正面实体词时,博文为正面倾向。
②情感词为褒义词,实体词为负面实体词时,博文为负面倾向。
③情感词为贬义词,实体词为正面实体词时,博文为负面倾向。
④情感词为贬义词,实体词为负面实体词时,博文为正面倾向。
⑤若存在否定词或问号,博文倾向反转。
3)规则3:当宾语为情感词、主语或谓语为实体词时:
①情感词为褒义词,实体词为正面实体词时,博文为正面倾向。
②情感词为褒义词,实体词为负面实体词时,博文为负面倾向。
③情感词为贬义词,实体词为正面实体词时,博文为负面倾向。
④情感词为贬义词,实体词为负面实体词时,博文为正面倾向。
⑤若存在否定词或问号,博文倾向反转。
4)规则4:当情感词仅为动词、宾语为实体词时:
①情感词为褒义词,实体词为正面实体词时,博文为正面倾向。
②情感词为褒义词,实体词为负面实体词时,博文为负面倾向。
③情感词为贬义词,实体词为正面实体词时,博文为负面倾向。
④情感词为贬义词,实体词为负面实体词时,博文为正面倾向。
⑤若存在否定词或问号,博文倾向反转。
步骤4.3 输出博文的立场。
在OASOSR算法中,文本切词的时间复杂度为O(n2),条件判断、实体信息判断的时间复杂度为O(n),而句法分析的时间复杂度为O(Kn3),可以得知OASOSR算法时间复杂度为O(Kn3)。
3 实 验
3.1 实验设置
为证明OASOSR算法的实用性,本文实现了OASOSR算法的自对比实验和他比实验。本文通过网络爬虫获取了38 175条新冠肺炎疫情舆论微博数据(数据来源:https://github.com/Zu-Qin131/Weibo-public-opinion-analysis),并 对 新 冠肺炎疫情舆情言论微博数据进行人工实体标注,分为正面和负面情感博文,用于自对比实验;并选用weibo_senti_100k(数据来源:https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets)的开源微博情感数据集,从中选取部分数据进行实体标注和人工正面、负面情感标注,应用于自对比实验和他比实验。上述数据集的特点总结如表3所示。
实验中构造的微博情感词典是在大连理工大学情感词汇本体库DUTIR的基础上,添加与新冠肺炎疫情舆论相关的情感词得到的。最终构建的情感词典共有23 651个中文情感词,包括9 833个正面情感词和13 818个负面情感词。
为了测试在数据量变化情况下OASOSR算法的稳定性、鲁棒性与准确率变化趋势,本节设计了基于OASOSR算法的自对比实验。如表4所示,从新冠肺炎疫情话题数据集中随机选取485条新冠肺炎疫情舆情言论微博数据,进行人工实体标注,并将博文分为正面情感博文和负面情感博文,其中已标注正面情感博文331条,负面情感博文154条,作为小规模数据集。

表4 对比实验中选取的数据集大小Table 4 Size of datasets selected for comparative experiment
同时,也在weibo_senti_100k的开源微博情感数据集上使用该方法进行实验,这是一个开源的大规模数据集,共有119 989条微博情感数据,从中随机选取4 000条微博数据进行数据标注,并作为大规模数据集,其中标注了正面情感博文2 200条,负面情感博文1 800条。
为证明OASOSR算法在不同规模数据集上的有效性,设计了4组实验,在不同规模下对OASOSR算法的鲁棒性进行了测试。首先,在小规模数据集(新冠肺炎疫情话题数据集)上进行实验,从新冠肺炎疫情话题数据集中随机选取200条作为训练集,剩余的285条博文作为测试集。然后,在大规模数据集上进行实验,从weibo_senti_100k开源微博情感数据集中选取了2 000条作为训练集,剩余2 000条作为测试集进行实验。在2个数据集上分别进行4组实验,每组实验分别从训练集中选取25%、50%、75%和100%的数据用于训练,生成训练结果,并对比观察2个模型在测试集上情感分类的正确率,正确率对比如图4所示。
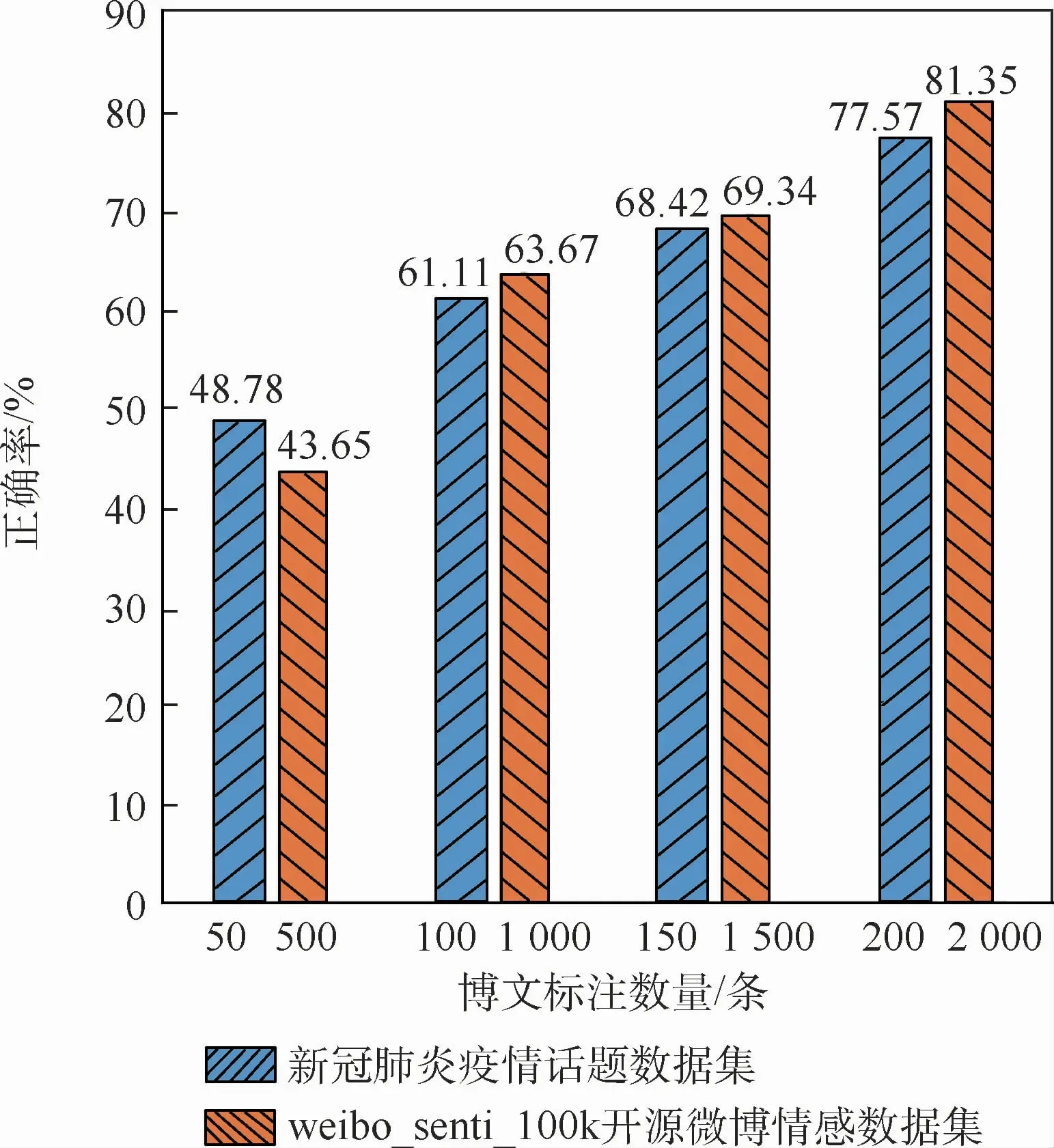
图4 不同规模数据集上OASOSR算法立场判断正确率Fig.4 Accuracy of standpoint judgement by OASOSR algorithm on different datasets
在小规模数据集上,当实体标注博文的数量为50条时,标注数据过少,识别出的情感对象实体较少,因此博文情感识别率较低。当实体标注博文的数量为100,150,200条时,正面和负面情感博文的判断正确率持续提高。相似地,在大规模数据集上,当实体标注博文的数量为500条时,正面和负面情感博文的判断正确率都比较低,而当情感标注博文的数量为1 000,1 500,2 000条时,正面和负面情感博文的判断正确率持续提高。
可以看出,随着训练数据中标注实体的博文数量增加,在不同规模的数据集上,算法对微博立场的判断正确率都在逐渐提高。OASOSR算法在数据集规模变化差别较大的情况下,仍具有很好的鲁棒性。
3.2 他比实验
他比实验选取weibo_senti_100k开源微博情感数据集作为实验语料。为了验证OASOSR算法的有效性,本文选取了基于SVM的有监督情感文本分类方法(sentiment classification of texts based on SVM,SCSVM)[22]和基于极性词典情感分析的无监督情感分类方法(sentiment analysis method based on a polarity lexicon,SAMPL)[23],分别与本文算法进行对比。在SCSVM方法中,先构建情感词典,并进行情感特征选取及情感特征加权,再使用SVM分类的方法对文本进行情感识别及分类。SAMPL方法则综合了基础词典、领域词典、网络词典及修饰词词典,将极性词和修饰词组合成极性短语,以极性短语为极性计算的基本单元,进行情感分析。
表5展示了实验中基于上述2个模型的微博立场判断正确率和基于OASOSR算法的微博立场判断正确率。对比表5中正确率可知,在同等数量的训练集和测试集中,OASOSR算法要优于SCSVM方法和SAMPL方法。这是因为:本文提出的OASOSR算法充分考虑了对情感对象的识别,微博情感识别更有针对性,在立场判断任务上的正确率相对较高。由对比实验结果可以证明,相较于有监督学习方法和无监督学习方法,半监督学习方法更适用于指定实体的博文立场判断。

表5 基于不同模型的微博立场判断正确率Table 5 Accuracy of Weibo standpoint judgement based on different models
3.3 规则分析实验
为证明OASOSR算法中不同情感规则在微博文本倾向性分析中会起到作用,本文设计了2组规则分析实验。在第1组实验中,设置变量为仅保留情感规则1~4条中的1条,去除其他3条规则;在第2组实验中,设置变量为去除情感判断规则1~4条中的1条,按原有顺序保留其余3条规则。在新冠肺炎疫情话题数据集和weibo_senti_100k开源微博情感数据集上进行这2组实验,生成实验结果,并将结果与去除判断规则前的实验结果进行对比。图5中,“单一”代表仅保留某1条规则,去除其他3条情感规则得到的实验正确率;“缺失”表示缺失某1条规则,但保留其他3条规则的得到的实验正确率。从实验结果对比可以看出,在去除某1条情感规则后,立场判定的正确率均低于原有算法模型。特别是去除规则1后,正确率下降了34.36%。因此,OASOSR算法中4条规则互相支撑且都具有必要性,缺一不可。

图5 基于不同模型筛选条件的微博立场判断正确率Fig.5 Accuracy of Weibo standpoint judgement based on filtering conditions of different models
4 结 论
微博情感的分类较为简单,无法判断微博对特定方向实体的立场问题。针对微博文本数据信息量大、情感倾向性强的特点,本文提出了使用OASOSR算法解决微博立场判定问题。该算法结合深度学习与情感规则,实现微博立场判定。首先,本文采用半监督学习的方法,分别基于CHMM和CRF模型,对微博文本进行协同训练,再通过主动学习的方法,提取微博文本中的指向性实体集,并构造了2个分类器。然后,通过分析大量微博文本中的句法特征,构建情感规则,提取句子的主成分,去除与立场判断不相关的信息,将表达方式较为随意的微博文本规范化。基于经过处理的博文数据,综合判断指向性实体的正面和负面性,结合博文句子中情感词的褒贬义、分析情感词充当的句子成分及情感词修饰的实体类型,进而分析博文的倾向性,确定微博对指定主题所表达的立场。为证明OASOSR算法的实用性,本文实现了自对比实验和他比实验。自对比实验显示,随着标注实体的博文数量增加,模型对博文立场判断的正确率持续提升,证明了该算法可以有效增强立场判断效果。将OASOSR算法与SCSVM方法、SAMPL方法进行对比实验,在不同标注数量博文上进行对比的实验结果显示,OASOSR算法判断博文立场的正确率显著高于对比方法。
