自适应短文本关键词生成模型
2022-03-08王永剑孙亚茹杨莹
王永剑,孙亚茹,杨莹
(公安部第三研究所,上海 201204)
关键词是文档内容的紧凑表示,由一个或多个字组成[1-2]。对短文本进行关键词匹配可以有效表达文本主题,关键词识别的准确度对文本分类、文本推荐及文本搜索存在着较大的影响,是文本挖掘和文本分析领域中一项重要的基础工作[3]。正确提取文本的关键词,有助于对文本的主题进行全面的研究和分析,亦可以对文本做出很好的决策。但因短文本在内容结构上表达灵活和主题风格各异等特点,使得从短文本中提取关键词成为了一项具有挑战性的任务。
分析社交平台发文数据最重要的任务之一是关键字提取。由于社交平台发文文本较短,字数限制140个字符,内容多样性、非正式性、语法错误、流行语、俚语及实时内容的生成速度等问题,需要一种有效的技术来提取有用的关键词[4]。传统的关键词提取方法主要是基于机器学习[5-7]或图模型[1,8-9]。机器学习方法通常采用特征值量化的方式从预处理后构建的候选集中得到关键词,如基于频率特征的TF-IDF模型、挖掘词句隐藏信息的LAD和HMM模型。词划分的准确度会对这些模型造成较大的扰动,并且存在语义缺失等问题。图模型对文本构建网络图,词为节点,边为词间的关系。在对图进行分析的过程中,通过评估节点重要性来选出关键词,这增强了节点间的语义关联,如基于拓扑结构的TextRank和在TextRank的基础上改进的NE-Rank[10]。NE-Rank是一种节点-边的加权方法,通过构造主题关键词特征来有效改进关键词提取。尽管基于机器学习和图模型的方法取得了良好的效果,但是会受特征选择和人工定义规则的影响。近年来,随着深度学习技术的出现,利用深度学习算法自动学习特征可以提高许多任务的性能。采用卷积神经网络在文本字符级上建模,学习文本和单词间的分布矢量表示,以捕获有关单词的形态信息,有效缓解了未知单词的问题[11]。然而卷积神经网络无法捕获长距离依赖,获取到的是文本局部特征。杨丹浩等[12]采用序列标注模型从字粒度和词粒度角度结合注意力机制[13-14]提取文本特征,有效改进中文文本的关键词提取。序列标注模型在文本处理领域取得了较好的进展,基于深度Bi-LSTM的ELMo[15]可以学习到词在上下文中复杂的用法,但是序列模型当前步的计算依赖前一步的计算,无法考虑另一个方向的数据。图神经网络(graph neural network,GNN)的出现缓解了深度学习模型处理文本数据结构的一系列问题。图神经网络将词、句子或词句搭配表示成图中的节点,节点的表征依赖与其相邻的节点,边表示节点间不同类型的关系,在图结构上应用神经网络可以直接获取节点依赖信息。但是基于有监督学习的模型依赖标签数据,存在模型移植性能差、不能有效发现新词等问题。综上,如何使模型可以正确划分词并能够识别出可以表达文本主题的关键词或词组是任务的关键。
针对上述所提问题,本文提出了一种以图神经网络为框架结合注意力机制的关键词生成模型—— ADGCN,有效捕获关键词与文本主题间的关联密度,摆脱数据领域的偏向,以提高无监督学习方法的性能。基于图到序列的学习模型,在文本数据结构上应用图神经网络的同时结合注意力机制捕获数据中丰富的语义信息,自适应地将局部特征与全局依赖性相结合,使模型有效学习节点间的关联强度,更有效地利用图结构中的信息。
本文的主要贡献如下:
1)构建文本内容与主题标签间的图链接,通过图构建层来表征文本的内部结构和主题间的关系。在图构建层的基础上采用注意力机制来学习节点特征空间的相关性,关注不同子空间的信息,引导节点间的关联密度。
2)提出了一种新的线性解码模型,采用图神经网络编码图信息,捕获节点间的远依赖信息,解决未登录词的问题。
3)收集并公布了一个社交平台的标签数据集。
1 相关工作
1.1 图神经网络
图神经网络模型在图形结构数据建模方面的应用越来越受到人们的关注,包括关系结构明确的社会网络预测系统[16]、推荐系统[17-18]、知识图谱[19]等,也包括关系结构不明确的非结构化场景,如图 像 分 类[20-21]、文 本 处 理[22-27]等。本 文 利用图神经网络对非结构化的文本数据进行建模。
近期研究致力于将图神经网络应用于文本分类任务中,涉及到将文本建模为图。文献[23]提出将文档转换为单词共现图,再将其用作图卷积层的输入,利用图表示的优势,有效捕获非连续和长距离语义的优势。文献[24]以概念图的形式表示文本,通过图卷积神经网络(graph convolution neural network,GCN)汇总匹配信号,比较包含相同概念顶点的句子来匹配一对文本。文献[25]构造了一个文本图张量,从文本的语义、句法和上下文信息3个角度来学习图内传播和图间传播,用于协调和集成图之间的异构信息。本文从以上工作得到启发,但是这些工作是为分类任务设计的,分类任务和生成任务是存在差别的。
一些研究是基于GCN 做生成任务的。文献[26-27]提出了一种基于图序列的Graph2Seq神经网络模型,结合注意力机制并遵循传统的编码器方法,构建了一个图形编码器和一个序列编码器,基于图神经网络学习节点间属性在SQL-totext任务中对SQL查询进行编码。文献[28]提出了基于图神经网络解决AMR-to-Text的问题。尽管这些工作将图神经网络做为编码器,但都是利用已经存在的图形式的信息,如SQL查询、抽象语义(abstract meaning representation,AMR)图和依存图,并且输入的文本相对社交平台发文较长,而笔者对短文本处理的工作更具挑战性。
1.2 关键词提取
关键词提取有利于信息检索、自动索引、自动分类、自动聚类、自动过滤等应用。文本中的主题不唯一,若只集中在文本语料库上,可能会导致知识获取的瓶颈和误解。目前的方法主要集中在怎样提取表达文本主题的关键词或词组。
文献[29]提出了一个利用主题模型从大众分类提取主题关键概念的方法。根据标签相对于某个主题的重要性进行排序,将排名靠前的标签作为提取主题关键的概念。文献[30]提出了一种以图表示文档、以节点表示文档单词、以边表示文档单词之间关系的关键字提取算法,用度和临近度中心测量主题关键词。文献[31]提出了一种利用3个主要因素不同于其他关键词提取方法,这3个主要因素是前面话题的时间、话题关联和参与者。当前发表言论的人应该被认为比其他参与者的言论更重要。本文从以上工作中得到启发,将文本主题与图表示序列模型联合生成短文本关键词。
2 ADGCN模型
2.1 模型概述
模型的目标是对句子进行信息压缩,输出短文本关键词信息。如图1所示,模型主要包括文本嵌入层、图构建层、注意力层、主题交互层和密集连接层,对应关键词生成的3个步骤:文本嵌入、特征编码和特征解码。

图1 ADGCN模型原理结构Fig.1 Schematic diagram of ADGCN model
文本嵌入部分的输入是预处理好的社交平台发文文本。对文本采用命名实体识别,并利用TextRank提取文本中的M关键词,对分好的词采用glove训练生成词嵌入向量。特征编码部分的目的是将文本嵌入层的输出进一步编码成一组隐藏向量,以获取文本节点关联信息和关键词隐藏信息。图构建层对文本节点进行编码,用于组织文本句子间的关系。图构建后由N个相同的编码模块连接,每个块包含2个层:注意力层和主题交互层。注意力层对图加强边的权重,用于引导节点间的联系密度,这里采用多头注意力机制,挖掘隐含的节点关系,生成的是全连接的边权图。主题交互层对图结构进一步编码,编码框架采用GCN,初始的输入是节点向量和节点的邻接矩阵,每一层包含上一层和初始时的输入。本文由M个主题交互层组成,对应着M 头注意力。输出的隐藏向量由特征解码部分的密集连接层处理生成关键词。密集连接层对编码信息进行解码,在解码过程中采用注意力机制计算上下文向量对主题交互层的输出,并用一种复制机制来计算关键词的复制概率。
2.2 图构建层
图构建的目的是将短文本组织成图结构,便于模型理解文本的内部结构和主题之间的联系。相比较序列标注模型对文本的处理方式,图结构可以直接获取节点依赖关系,编码较广范围的语义信息,做到减少噪声语句对关键语句的影响,降低高维度特征的复杂度,缓解非主题数据对关键节点的扰动。
如图2所示,对含有n条句子的短文本S={s1,s2,…,sn}构建图,节点分为关键节点vk、空闲节点vempty和主题节点vtitle。关键节点是由关键词K={k1,k2,…,km}和包含关键词的句子组成。空闲节点vempty是由剩余未包含关键词的句子组成。主题节点vtitle是由TextRank计算一个文本主题title,同时融合HashTag向量表征。若节点间包含相同的句子,则添加边,相同句子的个数作为边的权重。依据图构建算法生成图节点和边,并将图转化为邻接矩阵,作为下一层的输入。图构建方法如算法1所示。

图2 图构建过程Fig.2 Graph construction process

?算法1 图的构建方法。输入:关键词k={k1,k2,…,km},句子s={s1,s2,…,sn},文本主题title。输出:关键节点{v1,v2,…,vm},空闲节点v empty,主题节点v title,节点vi 和节点vj边的权重wij。1:对文本主题提取,并对文本分词。2:做命名实体识别,并提取文本中的m个关键词k={k1,k2,…,km}。3: for s={s1,s2,…,sn}do:4: if句子si包含关键词ki then:5: 将si分配给节点vi 6: else:7: 将si分配给节点v emp ty 8: end for 9: for节点vi和节点vj do:10: wij为vi和vj间包含相同句子的个数

11: end for
文本中词的初始输入是其在句子中的位置特征pi∈Rd×d及词特征xi∈Rd×d表征,如下:

2.3 注意力层
注意力层用于引导节点间的关联密度。如图3所示,对图构建层输出的邻接矩阵做多头注意力来关注不同子空间的信息,生成全连接的注意力矩阵,对应邻接矩阵的边权连通图,矩阵中每个元素对应相应节点之间边的权重,从而捕捉到领域节点间的关系密度。

图3 注意力层Fig.3 Attention layer
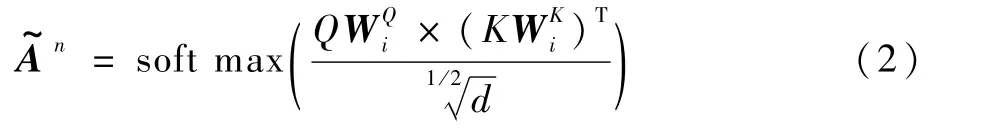
式中:Q和K为模型第l-1层的表征;WQ∈Rd×d和WK∈Rd×d为可学习参数矩阵。
2.4 主题交互层
主题交互层是对图信息进行编码,编码器采用GCN[32]。图神经网络既可以对节点内容编码,又可以利用图结构中丰富的信息。其核心思想是:通过学习一个映射函数映射图中的节点vi,vi可以聚合自己的特征与其邻居特征来生成节点vi新的表示。通过多个GCN层可以挖掘到更深层次的节点信息,节点的最终表征包含了更远的邻居节点信息。


随着GCN网络层数和迭代次数的增加,节点的隐层表征会趋向于收敛至空间中的同一个位置,即过度平滑问题。为了避免GCN过度平滑的问题,在每一层输入时考虑之前层的输出:

2.5 密集连接层
密集连接层完成对文本解码的工作,参考机器翻译模型[33]采用循环神经网络(recurrent neural network,RNN)模型作为解码器。GCN层的输出Gout作为密集连接层的初始输入,以生成一个注释标记序列y ={y1,y2,…,ym}。考虑短文本主题是一个重要的信息,将图编码器处理后的主题隐藏特征作为解码器RNN的初始输入t0,RNN每一步的解码特征ti。在解码过程中,采用注意力机制αj计算上下文向量ci来关注GCN的输出:

式中:δ为函数,计算当前解码器状态与原文各单词的相关度。
考虑初始抽取关键词本身的重要性,采用复制机制[34],将预测的词标记的概率分布与注意力分布相结合,利用解码器的隐藏状态ti和上下文信息向量ci动态计算关键词的复制概率pcopy:

式中:U、M、Wcopy和b为可学习的模型参数。
3 实验与分析
3.1 实验数据
本文从某个社交平台上收集数据,由于在不同主题下数据量差别很大,从生活、艺术、时尚、世界、科技、商业、微博、体育、健康、教育、旅行等主题中选择3个比较流行的主题:生活、教育和健康。对原文本处理成社交平台发文文本和话题标签的格式,称之为标签数据集(TH)。TH数据集详情如表1所示,可通过https://github.com/MiniiEcho/keywords-generation.git访问该数据集,可以用来做提取标签或是文本分类等任务,这些数据是可以免费获取的。在数据集中存在一个话题共用多个主题的情况,如#HappyTeachersDay属于生活也属于教育。教育和健康2个主题的样本数相对生活的少一些,健康主题的样本数不足教育主题的样本数的一半,但是总样本数为30 093条,足以支撑模型训练的。

表1 不同话题中的TH样本和标签数量Table 1 Num ber of TH sam p les and tags in different topics
在收集的小型数据集上评估时,体现为:具有较好的可移植性和在大规模数据集中同样可以取得较好的结果,选择在一个公开数据集即KP20k[35]上进行测试和评估。该数据集是Meng等[35]从ACM、SicenceDirect和Web of Science图书馆中收集的有关计算机领域的高质量数据,许多模型[35-37]在该数据集上验证其模型性能的有效性。KP20k数据集总样本数超过50万,是TH数据集的18倍,可以作为大规模数据集去验证模型性能。KP20k详情如表2所示。

表2 KP20k数据集描述Tab le 2 KP20k dataset descrip tion
3.2 实验设置
通过在验证集上的测试发现,从N={1,2,3}中选择编码部分的块数,从M ={1,2,3,4}选择多头注意力的头数,从L={2,3,4,5}中选择主题交互层的层数。通过对验证集的初步实验,发现(N=2,M =2,L=1,d=300)的组合设置在TH数据集上取得了最好的效果,在顶点数相对较小的情况下,降低L数值,会缓解模型过度平滑问题。(N=2,M=3,L=2,d=300)的组合设置在KP20k数据集上取得了最好的效果。该模型是在NVIDIA GeForce GTX 1650下采用CUDA9.0训练。训练周期为100,每10个周期用时约270 s。词典大小为60 000。句子大小为100,生成关键词的长度最大值为4。对于解码器,采用双向LSTM,128隐藏节点,2层。dropout率设置为0.1,并采用Adam优化器训练参数。初始化的学习率为0.01,epoch为10,每epoch一次学习率减少至原来的一半。
3.3 评估度量标准
本文采用3种度量方法评估收集的数据集上生成的关键词的质量,分别为相关性、信息量和连贯性。对所有的度量方法,让评分者按3种方式打分,分值范围为0~10。在KP20k数据集上采用精准率P、召回率R和F1值作为评估模型性能的评估指标。
1)相关性。用于评估结果是否与文本主题一致,即关键词是否符合社交平台发文文本内容,属于或是不属于社交平台发文文本。
2)信息量。用于评估结果包含了多少具体信息。衡量的是输出结果是否涉及到某个人物或事件的特定方面,或者是对某个人物或事件的概括描述,或者是一般关键词。
3)连贯性。用于评估输出的词是否流畅,是否是正确的、有意义的词。
本文邀请3位评分员去评估不同模型生成的关键词。由于评估过程复杂,选取3个话题的各100条发文的结果进行评估。评分员会得到原发文、发文主题和关键词,这与用户在线阅读发文的方式相同。使用Spearman等级相关分数来衡量评分者之间的相关性,p-values都低于1×10-50,这表明评分员之间的评分有较好的相关性。在这些指标中,连贯性的差异更大。这和预期的一致,因为该指标更灵活,不同的人会有不同的评估标准。
3.4 Baseline
本文从无监督和有监督模型进行对比,选取的Baseline是Tf-id f、TextTank、Maui[36]、RNN[35]、CopyRNN[35]、CovRNN[37]。Tf-id f、TextTank属 于无监督模型,Maui、RNN、CopyRNN、CovRNN是有监督模型。Tf-idf、TextTank是基于统计的方法,其针对候选关键词的次数来作为对文本的重要性,无法体现文本内容包含的语义信息,更无法生成未出现的关键短语。Maui、RNN、CopyRNN和CovRNN是生成方法,可以捕捉文本上下文信息。
3.5 实验结果
表3~表5展示了在生活、教育和健康3个不同主题下的不同Baseline模型与本文模型在不同度量下的结果。从结果中可以看出,本文提出的ADGCN模型在相关性和信息性方面都优于所有的Baseline。

表3 生活主题下Baseline模型和本文模型的3个度量评估比较Tab le 3 Com parison of three m easurem ent evaluation of Baseline m odel and p roposed m odel under life topic
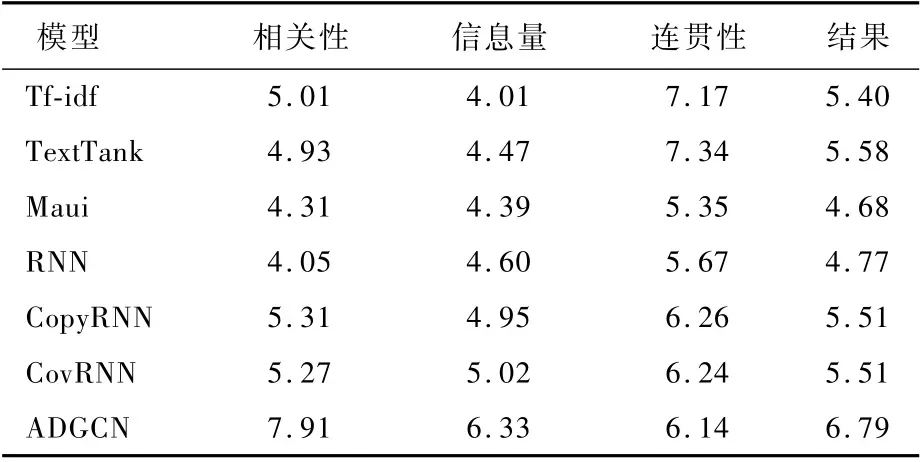
表4 教育主题下Baseline模型和本文模型的3个度量评估比较Table 4 Com parison of three m easurem ent evaluation of Baselinemodel and proposed model under education topic

表5 健康主题下Baseline模型和本文所提模型的3个度量评估比较Table 5 Com parison of three m easurem ent evaluation of Baseline m odel and p roposed m odel under health topic
1)相关性。与所有其他Baseline模型相比,本文模型在相关性方面获得了较高的分数。这说明本文所提出的基于图到序列的学习模型可以更有效地获取和生成与文本主题相关的关键词。在遇到低频率话题时,如#HappeningNow下的某个句子“The protesters in Rochester NY are‘shutting down restaurants’,tables are broken,peop le running off sc…”。句子与话题的相关性不明显,这误导关键词的生成,这种现象严重影响了关键词相关性的分值。在Baseline模型中Tf-idf取得了较高的结果,这说明对与话题相关性不明显的句子提取关键词时,在样本数量足够的情况下,基于统计的方法可以提取出与文本主题相关的词。而在样本数量较少的情况下,如表5所示,统计的方法便不如生成模型的结果了。生成模型可以输出文本中不存在的词组,来更好地表达主题。
2)信息量。从结果中可以看出,随着样本数的减少,关键词包含的信息量随之增大。与所有其他Baseline模型相比,本文模型在信息量方面获得了更高的分数。信息量和相关性是有一定关系的,相关性较高的模型,其信息量越丰富。但是当样本较少时也会出现不稳定的情况,像在健康主题下,RNN模型信息量与相关性没有呈现正比的关系。原因是:在健康主题下,样本中低频率话题较多,文本主题和话题不匹配会对模型造成一定的扰动。从结果中可以看出,基于图的模型可以利用文本结构,捕获文本情节,有稳定的健壮性。
3)连贯性。基于统计的方法是从原文中直接复制词,连贯性只受到分词的影响。因此,结果中也显示基于统计的模型的连贯性分值要远高于生成模型。在检查了部分生成的关键词后,总结了以下几条影响流畅度的原因:①机器对人名不能较准确地识别,如赵立、坚定,而赵立坚是一个人名。②存在连续生成相同词的问题,严重影响了连贯性分值,本文猜测这和复制机制有关,这也是下一步待解决的问题。③模型生成的关键词是有悖知识逻辑的,如Railway Speak Up(铁路大声的说)。这一问题也是比较难解决的问题之一。
表6展示了Baseline模型与本文模型在KP20k数据集上的P、R和F1值的对比结果。发现各模型的召回率都比较低,这表明模型将很多正样本赋值了错误的标签,这和数据集样本的质量有关。另外,数据集中主题不明确的句子会对模型造成较大的扰动。KP20k数据集中的标签大部分是文本中不存在的,因此,这对统计模型直接提取造成了重创。对生成模型来说,所生成的标签存在重复、次序混乱等现象而导致错误结果。但是本文模型ADGCN仍取得了较好的结果。

表6 KP20k数据集上Baseline模型和本文模型的精确率、召回率和F1 值评估比较Tab le 6 Com parison of p recision,recall and F1 evaluation of Baselinem odel and proposed m odel on KP20k dataset
3.6 实验分析
3.6.1 消融分析
对模型的各模块进行消融研究,评估结果如表7所示。从结果中发现,编码模块的注意力层和主题交互层对模型的贡献最大。去除注意力层,模型F1值降低至0.413,减少了0.04。这说明注意力层有效发挥了捕捉领域节点间关系密度的作用。去除主题交互层,模型F1值降低至0.406,减少了0.047。这说明编码远距离的邻居节点信息可以提升模型准确率。若两者都去除,F1值则会降低0.06,这对模型性能的影响是最大的。而图构建层和密集连接层对模型的影响相对较小。可见,注意力与图神经网络相结合有助于ADGCN学习短文本内的信息聚合,以生成更好的节点信息特征。
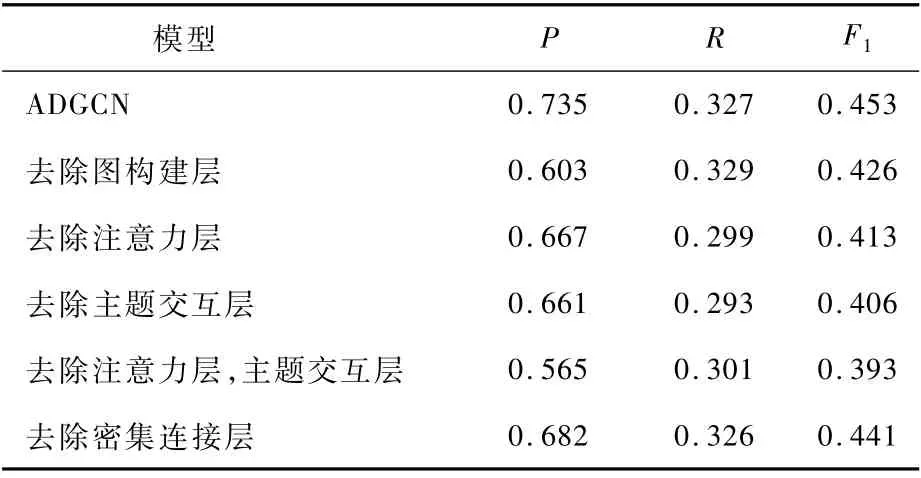
表7 ADGCN模型的消融Tab le 7 Ab lation of ADGCN m odel
3.6.2 数据集规模对模型性能的影响
对KP20k数据集进行统一划分,设置5种规模训练数据:20%、40%、60%、80%和100%的训练数据。对ADGCN和Baseline模型在不同训练设置上进行评估。如图4所示,在数据规模不大时,CovRNN取得了较好的效果,这说明CovRNN可以从样本较少的数据中捕获有利的信息,但是与其他生成模型的差距并不明显。随着数据集规模的扩增,发现生成模型与统计模型的性能差距越明显,在数据集规模达到40%时,生成模型远超于统计模型。在数据集规模达到60%时,本文所提出的ADGCN的F1值达到了其他Baseline模型的最优值。这说明ADGCN可以更有效地利用训练数据集,在数据规模一定的情况下,基于图到序列的模型可以有效学习短文本中主题信息。
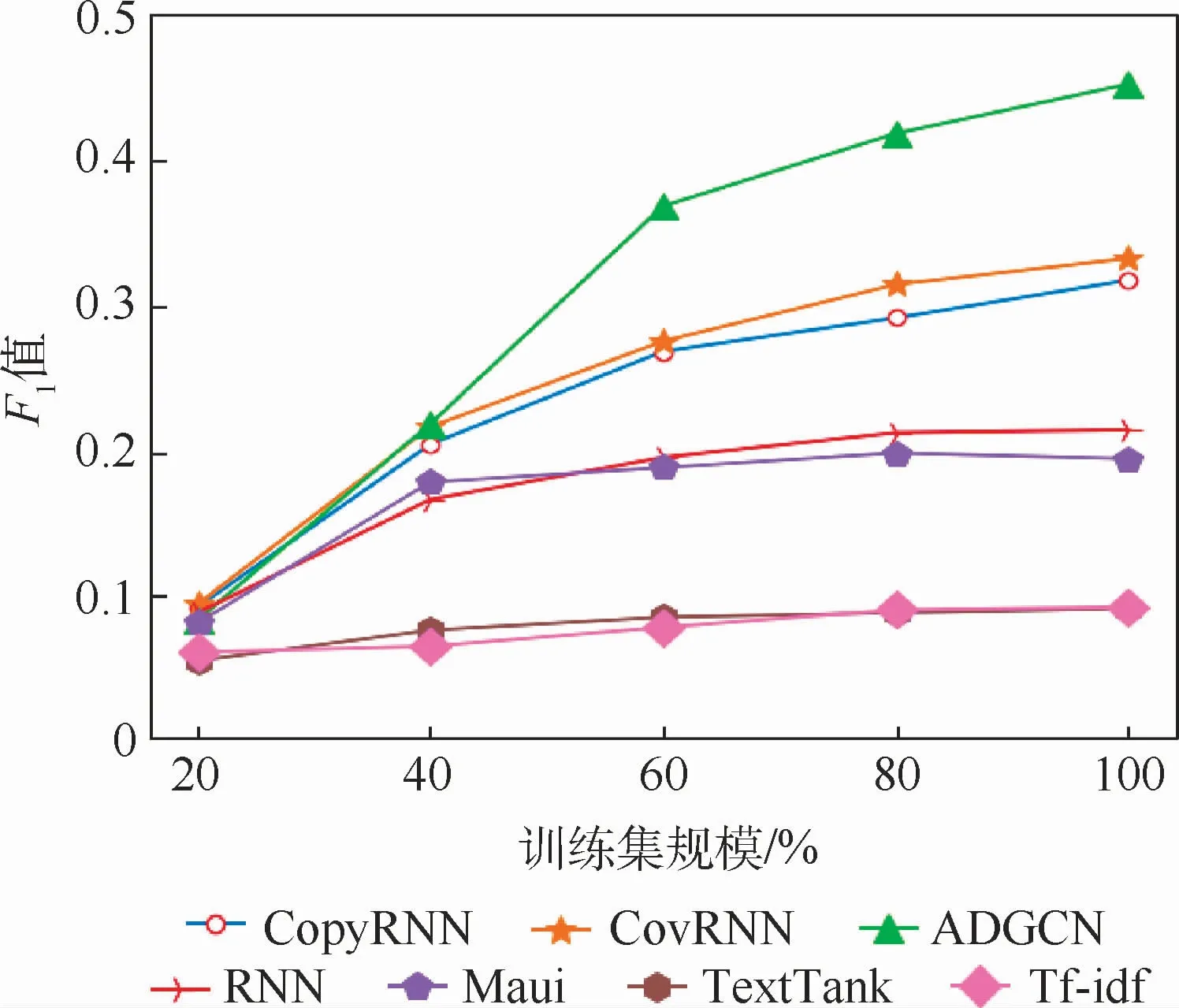
图4 不同数据规模下各模型的F1 值比较Fig.4 Comparison of F1 values of differentmodels under different data scales
3.6.3 话题种类对模型性能的影响
评估TH数据集中话题种类对模型性能的影响。设置包含不同话题种类个数1、2、3、4和≥5的句子,对ADGCN和与ADGCN较相近的Copy-RNN、CovRNN模型在不同数量的话题句子上进行关键词质量评估,分别从关键词的相关性、信息量、连贯性3个方面进行统计评估。统计包含不同个数的话题标签的发文比例,如图5所示。话题种类个数为1的只占据了60%,而话题种类个数在5之上的占据了5%,这些数据增加了文本主题的噪声,对短文本主题表征会有一定的影响。如图6所示,发现各模型在话题种类个数≤2时生成的关键词质量是最好的。而随着话题种类个数的增加都有减少的趋势,这说明话题种类的数量越多对模型的扰动性越大。
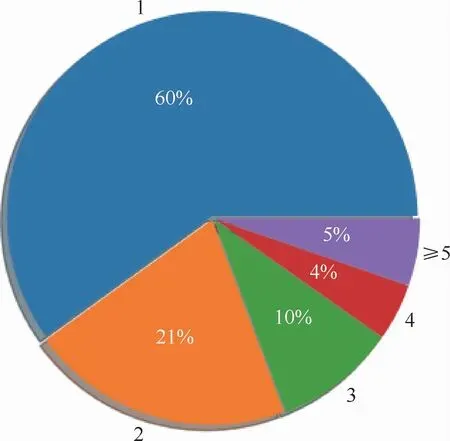
图5 话题标签个数比例Fig.5 Ratio of the number of topic tag

图6 不同话题标签个数下度量值的评估Fig.6 Evaluation ofmeasurement value under different numbers of topic tag
在对相关性评估分析时发现,ADGCN的相关性分值虽然也会收到数据扰动的影响,但是相对CovRNN和CopyRNN两个模型较缓慢。CovRNN和CopyRNN在话题标签个数大于2时急速下降,在[2~4]区间存在不明显的差距。而在对信息量评估时,2个模型的差距明显化,这说明Cov-RNN相对CopyRNN是稳定的。当话题种类个数为1或是超过5时,无论是相关性还是信息量CopyRNN的表现要比CovRNN模型弱一些,猜测可能和数据不平衡有关。而ADGCN可以有效缓解数据不平衡的影响,因此表现是最优的。
在对连贯性评估分析时发现,CovRNN 和CopyRNN在话题种类个数为1时的表现比ADGCN好,但是当话题标签个数增加时,2个模型下降明显,而ADGCN下降缓慢,并在数值较大时有缓升的趋势。这说明在文本组织结构明显的情况下,序列标注模型对文本信息的组织可能要优于图结构模型。对结构化不明显的文本,图结构模型表现出了优势。
造成数据扰动的原因可能有以下2点:①因发文有字符字数限制,话题种类数量越多,文本的组织结构会越差。这对序列标注模型RNN的影响是较大的。相比较,利用图表示模型的结果会好一点。②随着话题种类的增加,主题节点表征的信息特征越不明显,这大大降低了文本主题的表达,模型信息获取的性能会随之下降。而本文所提出的ADGCN在不同设置上的性能完全优于其他生成模型。
4 结束语
本文提出了一种新的图到序列的关键词生成,一是通过图构建层来表征文本内容与主题标签间的图链接;二是结合注意力机制来学习节点特征空间的相关性,关注不同子空间的信息,引导节点间的关联密度。该方法有效缓解了短文本主题依赖和文本组织结构差对模型造成扰动的影响。ADGCN模型不仅具有良好的相关性、信息量及连贯性,在大规模数据集KP20k上也取得了较好的性能。
接下来会对模型的不足进行改进和优化,如复制机制的影响、知识逻辑的推理等。缓解多话题标签对文本主题的影响也是未来待解决的问题之一。
