多尺度特征DCA融合的海上船舶检测算法研究
2022-03-02段先华罗斌强
潘 慧,段先华,罗斌强
江苏科技大学 计算机学院,江苏 镇江212003
近几年,我国的海域频频受到邻国的侵犯和非法捕捞,四大海域的监管任务日趋严峻,因此海上船舶识别成为海上交通安全领域的热门研究方向。针对海洋背景下的船舶检测问题,目前常见的解决方法有两类:一类为成像系列,以基于合成孔径雷达(synthetic aperture radar,SAR)的图像[1]、红外图像[2]的检测方法为主,它的应用比较成熟,但其成像未能包含目标丰富的光谱信息,且与人类视觉习惯相偏差,不利于网络提取更丰富的特征信息,从而降低了检测的精度。另一类为非成像系列,利用声呐[3]等技术获取船舶目标的相关信号,但是海上环境复杂,且通信传输通道复杂,对小目标的船舶检测效果极差。
随着卷积神经网络(convolutional neural network,CNN)[4]和候选区域算法[5]的问世,基于深度学习的目标检测取得了巨大突破。传统的检测算法结合了Region Proposal和CNN,代表性的two-stage算法有Fast-RCNN[6](fast region-based convolutional neural network)和Faster-RCNN[7](faster region-based convolutional neural network),虽然这类算法检测精度很高,但是该系列算法需要在每个映射区域进行分类和回归,模型参数的计算量非常大,导致其在实时应用上遭到限制。针对此类问题,出现了以YOLO(you only look once)和SSD(single shot multibox detector)[8]为主的one-stage 系列算法,其利用端到端的网络一步完成候选框回归和目标分类的任务,运行检测速度较two-stage系列算法有近100倍的提升,为实时检测打下了理论基础。目前流行的检测算法YOLOV3,在YOLOV1[9]和YOLO9000[10]的基础上进行各项优化,包括多尺度特征融合,加入类FPN(feature pyramid network)[11]的金字塔结构。该算法平衡了精度和速度之间的差距,在保持检测速度快的特点前提下,性能得到了很大的提升,较同期的SSD 算法,检测速度快了3倍。YOLOV3的尺度特征图来自不同层的融合,其特征检测图包含的目标信息更加丰富,进而检测精度的优势更明显。
YOLOV3在各个领域应用时具有更好的泛化性,因此本文将采用该模型对海上船舶进行检测[12],但是拍摄的海上船舶图像[13]分辨率较低,其包含的船体信息不丰富,不同类别的船舶在形状上拥有高度相似性,导致YOLOV3 模型在检测过程中出现误检和小目标漏检的现象。针对上述问题,本文的工作分为两部分:首先,根据图像信息不丰富的特点,在YOLOV3 的网络基础上增加检测的尺度,并在高低层特征融合的过程中使用双线性插值上采样算法和判别相关分析(discriminant correlation analysis,DCA)融合策略,增强输出特征信息表达能力,使得目标的细节信息更加突出。其次,优化损失函数,在MS-YOLOV3模型的基础上,采用GIOU(generalized intersection over union)损失代替损失函数中边框优化参数。前者主要是改进模型来适应真实环境拍摄的低分辨率图像检测任务,后者进一步优化模型参数,提升目标位置信息的精确度。在自建的船舶数据集上,对YOLOV3 和MS-YOLOV3 的各项性能进行对比,结果验证了改进后的网络在船舶图像上取得的结果优于原始算法。同时以公开数据集Pascal VOC2007为训练目标,将改进后的模型与原始模型、YOLO9000、SSD300 和Faster-RCNN 进行平均精度对比,改进后的网络更胜一筹。
1 MS-YOLOV3网络构建
YOLOV3 模型[14]以Darknet-53[15]作为特征提取网络,其由52 个卷积层和1 个全连接层组成,提取网络为全卷积,取消池化层,解除了对输入图像尺寸的限制,图像尺度变化通过卷积步长完成;此外,该网络借鉴了ResNet[16]的残差结构思想,以1×1 和3×3 的卷积方式组成Residual 类残差结构,并在其内部加入快捷链路层Shortcut,保证了网络结构在很深的情况下,网络关键点仍然能够正常收敛。虽然YOLOV3网络检测精度和速度比较优秀,但是对Shipdataset数据集的低分辨率图像来说,该模型的预测网络获取的尺度特征信息还是不丰富,导致模型无法检测部分小目标,且对于相似的其他类型船体或者图中凸起的物体,容易出现误检的情况。基于此,本文对YOLOV3网络进行了两处修改。
1.1 增加网络检测尺度
在YOLOV3模型上增加一个检测尺度[17],提高对小目标的识别能力。用于预测的尺度特征图来源于网络高层与低层的特征图融合,高层的特征图为上一个尺度特征图上采样的结果,而低层的特征图为原图经过多层卷积下采样得到,因此新增检测尺度特征图的大小为104。改进的模型结构如图1 所示,特征提取网络仍然使用Darknet-53,输入图像的大小为416×416×3,原模型的3个尺度预测模块,分别记为LF(52×52)、MF(26×26)和SF(13×13),新增尺度的预测模块记为Add_LF(104×104),原图经过Darknet-53下采样8倍后,得到的特征输出会在形状颜色等细节方面突出优势,将其作为尺度融合的低阶特征,大小为104×104×128,然后将LF2 信息交互模块的输出进行上采样。虽然最近邻插值算法简单,但是其操作不考虑采样点附近的像素值,使得缩放后的图像灰度值不连续,图像质量损失较大,会有明显的马赛克和锯齿,最终影响网络训练性能。因此利用双线性差值算法将其尺寸放大至104,并与低阶特征进行特征融合。之后利用一组信息交互模块完成低层细节信息和高层语义信息的充分交流,得到的结果经过1×1的卷积更改通道数之后,输出作为第四个尺度检测的输入。新增模块的尺度感受野[18]大,更容易检测到小目标的存在,能够有效地改善小目标漏检的现象。

图1 MS-YOLOV3网络结构图Fig.1 Network structure of MS-YOLOV3
1.2 DCA特征融合策略
YOLOV3对于融合高低层特征图,采用concat通道拼接算法,即将高低层特征图的通道数直接相加,尺度不变,结果作为局部特征交互模块的输入,这种做法简单,但是两种特征集因相关性不强而产生冗余信息,这些信息影响后续其他策略的执行,从而造成目标漏检的问题。为此,引入DCA[19-21]特征融合策略,此策略在CCA[22](canonical correlation analysis)的基础做了改进,使得两个特征集之间的差异更为突出,同时最大化两者之间的相关性,更好地融合不同模式下提取的信息,进而使得经过交互模块的待检测输入的特征信息更加丰富。
首先假设样本数矩阵有C个单独的类,因此n列数据可以分为C个单独的类。假设ni列属于第i类,对于i类的第j个样本,即特征向量,记为Xi,j。和分别表示所有特征集合的平均值和第i类特征的平均值。由此得到的类间散布矩阵如下:

其中有:


r的最显著特征可以通过Φ→Φbxφ映射得到,Wbx=ΦbxφΛ-1/2为转移矩阵,归一化Sbx并对数据矩阵进行降维(p→r)。记输入的其中一个特征集为X,则X在空间上的投影X′的求解如式(4)和(5)所示:

同理可得另一输入特征集Y在空间上的投影Y′,如式(6)和(7)所示:

为了让X与Y的特征保持非零相关,利用SVD(singular value decomposition)[23]对两者的协方差矩阵进行对角化,先定义S′xy=X′Y′T,那么对角化推算如下:

紧接着定义Wcx=UΣ-1/2,Wcy=UΣ-1/2,这样就能得到。最后进行转换,得到新的特征集X*、Y*,如式(9)和(10)所示:
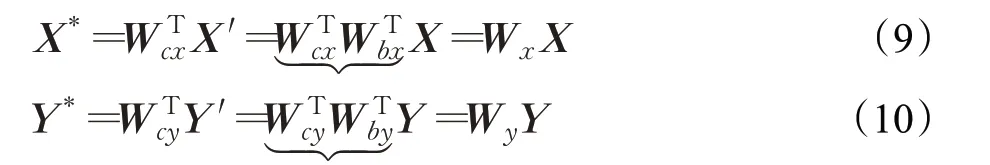
该策略在本文实验中的具体加入流程如图2所示。

图2 基于DCA的深度特征融合示意图Fig.2 Schematic diagram of deep features fusion based on DCA
2 损失函数优化
2.1 原始算法中损失的缺陷
损失函数由三部分组成:边框损失、类别损失和置信度损失。本节主要说明边框损失带来的问题。在YOLOV3检测算法中,利用交并比(intersection over union,IOU)[24]衡量预测框和真实框的距离,利用损失函数迭代优化模型的网络结构参数,边框参数优化将预测的4个点看成一个整体进行回归,采用的是范数L1或者L2距离[25]。但是在相同Loss的情况下,每组的预测框和真实框的IOU值参差不齐,这也就说明了根据损失局部优化得出的权重参数,并不能表示其预测的边框最接近真实框,即IOU值最大。进一步讲,模型的MSE损失和IOU预测距离在评判模型性能上形成不了等价关系。这种情况下通常的做法是,将IOU 作为边框损失计算参数,解决上述的不等价问题。但是基于IOU 的损失面临着一个问题:当预测框和真实框不相交,即IOU为零值时,不仅不能反映两个边框的距离,而且损失不可导,无法参与优化任务。此外,利用YOLOV3训练Shipdataset时,出现了预测框远偏离真实框的情况,导致预测位置信息不准确,极大地降低了整个模型的性能。
2.2 损失优化
针对上述问题,在不能采用IOU_Loss的情况下,对模型损失进行了优化,引入广义交并比(GIOU)[26-27]。
对于预测框A和真实框B,先求出A和B的最小凸包(包含AB框的最小包围圈)C,再根据IOU的值得到GIOU,具体的计算公式如式(11)和(12)所示:

式中,C表示预测框和真实框的最小包围框的面积,A⋃B表示真实框和预测框的面积之和减去两者的重叠面积。
由上述公式,GIOU总是小于等于IOU,根据公式得其值位于区间[0 ,1],因此GIOU 的值位于区间[-1,1]。当预测框和真实框完全重合的时候,GIOU 的值为1。当预测框和真实框不重合,即IOU为0时,GIOU越接近-1,两者的距离越远。
GIOU作为边框评价指标时,边框代价函数如式(13)所示:

最后,整个模型的损失函数如式(14)所示。其中,第一部分为边框损失。第二部分为类别损失,的取值是由网络单元代表的边界框是否负责预测某个对象决定,为参与预测的边界框含有目标的置信度。若边界框不参与目标预测,但是其与真实框的IOU值大于设定的阈值,那么Gij值为0,其他情况下,其值为1。第三部分为置信度损失,同样也表示边界框是否预测对象。

3 实验
3.1 船舶数据集的构建
为了验证改进的模型在海上船舶检测中的有效性,本次实验建立一个海上船舶数据集Shipdataset,该数据集包含两类船舶品种,海上民用船(civilship)和海上军用船(warship)。此次数据集的图片来自网上搜索的海上拍摄视频和图片,因为视频中存在大量相同内容,所以通过跳帧手段,即每20帧截取一张视频片段,最后将得到的视频片段进行人工筛选,剔除低质量不清晰的图像,保留含有目标的图像和海上背景图像。
因为收集到的样本数量不够支撑网络的训练,所以通过数据增强的手段来增加样本的数量。先对图片进行裁剪和缩放,将图片的大小固定为640×720,接着对预处理过的图片随机抽取1/3进行90°、180°和270°的旋转和镜像翻转,再随机抽取1/3 进行对比度和亮度的调整,以此提高模型的泛化能力,同时也能缓冲网络过拟合的现象。最后利用labelImage 工具对已处理好的图片进行目标框标注。将数据集按照比例划分为训练集、测试集和验证集,具体如表1所示。
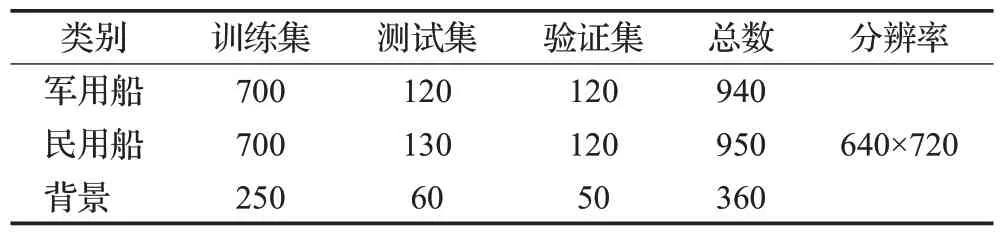
表1 海上船舶数据集Table 1 Shipdataset
3.2 模型训练
实验的条件以及训练中的参数调整如下:为了节省训练时间和加快损失的收敛,本次实验的网络结构各节点参数在backbone 上进行微调。使用随机梯度下降法[28]进行损失优化,学习动量设为0.9,初始学习率设为0.001,权重衰减为5.0×10-4,Batch Size为64。前4.0×104迭代次数中学习率不变化,到4.5×104迭代次数中学习率为前者的10%,之后至最大迭代次数,学习率为当前值的10%,适当降低学习率,可以使模型更有效地学习,也能降低训练损失。实验所需要的环境和软硬件设备如下:Win10,Darknet,CPU 为Intel Core i9-6700,GPU为NVIDIA GeForce GTX 2080,显存12 GB等。
利用Kmeans 聚类算法[29],对数据集的边框信息进行训练,得到K值和平均IOU 的关系,如图3 所示。当K大于15 时IOU 变化趋于平缓,因此实验将选取12 个Anchor Box。根据网络的输出尺度个数,每个尺度按照感受野的大小分配3个相应大小的Anchor Box,即预测特征图中每个单元格可预测3个Bounding Box。

图3 平均IOU变化曲线Fig.3 Curve of average IOU
3.3 对比实验
本实验针对数据集中两类船舶进行检测,具体的评价标准为单类精确率(precision,P)、平均精度(mean average precision,mAP)和召回率(recall,R),如式(15)、(16)、(17)所示。

式中,TP表示被模型预测的真正类,FP表示模型将负例错误分类为正例,FN表示模型将正例错误分类为负类,Pcivil和Pwar分别代表民用船和军用船的识别精确度。
3.3.1 上采样算法对比
为了验证插值算法对模型的影响,上采样模块分别以最近邻插值和双线性插值为基础来训练模型,然后采集模型中三个上采样模块输出特征图。图4(a)为以最近邻插值为主的上采样模块输出,对比图4(b),表现出较为明显的马赛克和锯齿缺陷,细节信息的精度缺失严重,对比最大尺寸的采样结果图来看,前期的上采样模块采用双线性插值算法,经过卷积操作之后,一定程度上保留了目标的形状信息。因此模型的上采样模块将采用双线性插值保证后期每个卷积模块输出的特征信息精度不会缺失,以此间接提升模型的识别准确度。

图4 上采样模块的可视化对比Fig.4 Visual comparison of upsampling module
3.3.2 特征融合算法对比
为了验证DCA融合策略的优势,在模型的LF模块所表示的尺度基础上,对相关卷积层的输出特征图做灰度化处理。以Darknet-53 网络提取到尺寸为52 的特征图为输入X,以MF2 模块的输出再上采样得到的特征图为输入Y,对原始模型中直接通道拼接融合方法和改进模型中DCA融合方法进行比较。如图5所示,经过相关性变换得到输出X′和Y′,对比输入的两张图,在最大化两者相关性后,输出图中船体的信息更加丰富,再经过通道拼接,得到的尺度特征图在目标形状、背景和目标分割界线方面,与直接通道拼接融合的输出图对比,细节信息有着明显的精度提升,且后者的视觉效果不如前者。由此可以看出,使用DCA 策略的融合模块能够加强细节信息的表达,丰富船体的特征信息,使得船体凸出部分的特征得到显示。对于检测层来说,细粒度特征丰富的输出更容易检测出目标的类别和位置信息,这也有助于提升整个模型的性能。

图5 融合算法的特征可视化结果图对比Fig.5 Comparison of feature visualization maps in strategy of scale fusion
如图6所示,将DCA融合算法与卷积神经网络常见的Addition 融合算法和Concatenation 融合算法进行类别准确度对比。从图中可以看出,相比另外两个融合算法,加入DCA融合策略的模型在每个类别上的AP值都有提升,虽然上升的幅度较小,但是对于改善模型性能也能起到推波助澜的作用。
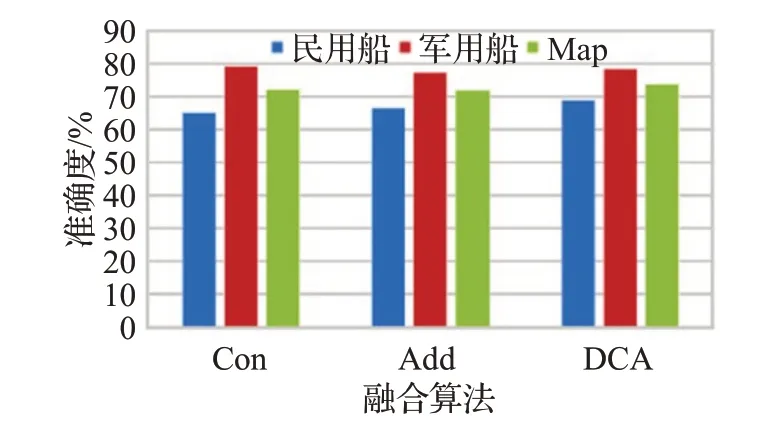
图6 融合算法对模型准确度的影响Fig.6 Influence of different fusion methods on accuracy
3.3.3 损失对比
以MS-YOLOV3为实验训练模型,对损失函数收敛性进行验证。两种Loss 函数随着迭代次数的变化曲线如图7 所示。图中的两条曲线分别表示边框损失使用MSE 的初始损失函数,和使用GIOU 的更改损失函数。虽然两者在迭代一定次数之后都趋于零值,达到收敛状态,但是边框损失函数使用GIOU 之后,模型平均损失收敛更快,曲线整体值低于MSE,而且batch之间的纵坐标数值波动大幅度减小,稳定性增强。由此看出,使用GIOU边框损失之后,模型的性能更加稳定,同时具有较高的鲁棒性。
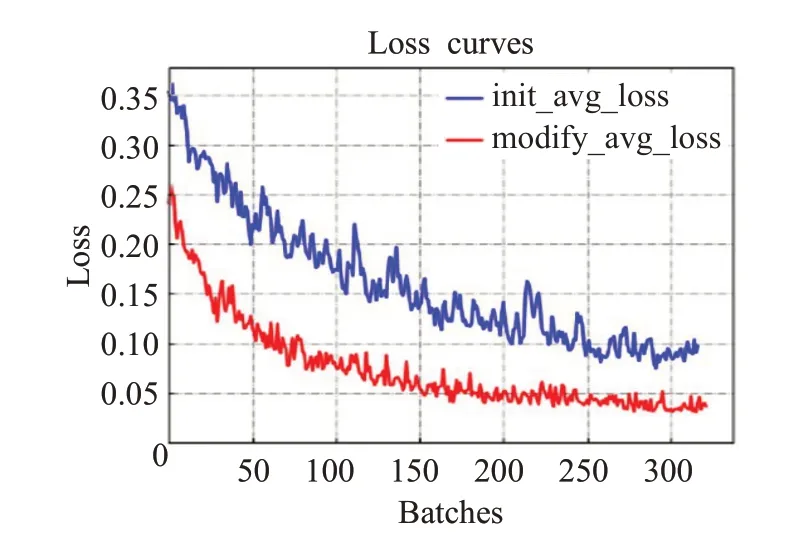
图7 平均损失收敛曲线对比Fig.7 Comparison of average loss
如图8所示,对船舶图片进行目标预测和真实框的距离测试对比,图8(a)(b)表示边框损失使用MSE,图8(c)(d)表示边框损失使用GIOU,粉色框表示预测边框,蓝色框表示真实边框。比较两组结果,GIOU 边框损失下的真实框与预测框的距离,明显小于MSE 边框损失的反馈结果,以此也表明GIOU在对边框位置信息的预测精确度上还是起到了推进作用。

图8 预测框和真实框的距离对比Fig.8 Distance comparison between prediction box and real box
3.3.4 原始模型与改进模型对比
以Darknet-53为基础提取网络,将原始YOLOV3与基于GIOU损失的MS-YOLOV3进行性能对比,实验结果如表2所示。从结果可以看出,YOLOV3的尺度特征表达的信息不充分,两个类别的精度只达到了65.32%和79.34%,平均精度达到72.34%。而MS-YOLOV3 充分融合更低层的特征信息,单类别精度提升了5.9~9.9个百分点,检测平均精度提升了7.9个百分点,同时召回率也提升至82.45%。因此从精确度可以看出MS-YOLOV3在Shipdataset数据集上的优势。

表2 两种模型的精度和召回率对比Table 2 Comparison of precision and recall of two models
通过训练好的模型,对验证集图片预测后,得到每个类别的置信度得分,分别对两个类别的样本进行排序,计算Precision 和Recall,并绘制每个类别的P-R 曲线,如图9 所示。图9(a)(b)表示民用船在两个模型测试下精度和召回率的关系,图9(a)表示YOLOV3 验证结果,图9(b)表示MS-YOLOV3测试结果。由于民用船的船体结构复杂,其类别精确度整体还是偏低,但是根据P-R 曲线来看,经过MS-YOLOV3 测试得到的Recall还是提升了10 个百分点左右。图9(c)(d)表示军用船的测试结果,图9(d)对比图9(c)原始模型的测试结果,Recall 有小幅度提升,每个召回率对应的精度提升很大,说明MS-YOLOV3 预测错误类别的概率减小,两个指标都得到改善。

图9 YOLOV3和MS-YOLOV3对两类船舶验证的P-R曲线Fig.9 P-R curve of two types of ships of YOLOV3 and MS-YOLOV3
为了进一步验证改进模型的有效性,对比不同的改进措施下YOLOV3 的运行时间,如表3 所示。很明显,四种改进方案下的模型在运行时间上整体处于上升趋势,特别是多加一个检测尺度之后,网络层数增加,计算参数量变大,运行速度涨幅较大。最终改进模型的检测精度提升了7.9 个百分点,但是模型的运行速度相较于原始模型上升了3.34 ms。综合考虑,牺牲较小的速度换取预测准确度的大提升,这种方案在本场景中还是可取的。

表3 不同改进方法对模型运行时间的影响Table 3 Influence of different improvement methods on running time of model
根据训练出来的权重文件对海上船舶图片进行预测。如图10 所示,对部分船舶进行目标检测,MS-YOLOV3可以精确地预测出船舶类别和位置信息。

图10 船舶类别识别Fig.10 Identification of ship classes
为了更加直观地观察神经网络的运作情况,如图11所示,对MS-YOLOV3预测网络中四个尺度模块的卷积层输出进行可视化。

图11 四个尺度预测模块的卷积层可视化Fig.11 Convolutional layer visualization of four scale prediction modules
在船舶数据集上对MS-YOLOV3 和原始YOLOV3进行效果测试,实验结果如图12所示。图12(a)(b)(c)(d)为原算法的样本测试效果。可以看出,在图12(a)中,由于船体相似,小船的预测边框出现严重的类别偏差。在图12(b)中,原算法将凸起的人和文字误检为船舶。在图12(c)中,选取分辨率较低的图片进行测试,发现对于小一点的目标,原算法无法检测。在图12(d)中,除了出现上述问题之外,目标虽然在预测之中,但是并没有完全覆盖到,位置信息预测不精确。图12(e)(f)(g)(h)表示MS-YOLOV3 的样本测试效果,对比来看,对网络结构进行改进,增加的尺度使得图12(g)(h)中不清晰的小目标得到发现。同时尺度特征融合阶段采用DCA策略,增强两个特征集的相关性,使检测图的语义和细节信息得到充分的交互,增加了细粒度特征信息,如图12(e)(f)所示,船舶的误检情况得到改善。此外优化先验框和加入GIOU边框损失,也着实提高了边框位置信息的精确度。

图12 YOLOV3和MS-YOLOV3对船舶预测效果对比Fig.12 Visual comparison of ship prediction between YOLOV3 and MS-YOLOV3
3.4 与其他方法对比
为了验证采用GIOU损失的MS-YOLOV3在目标检测任务中的可靠性,将其与其他流行检测算法在Pascal VOC20007 数据集上做性能对比。实验以threshold 为0.5进行平均精度性能评估。实验结果如表4所示,相比较SSD300、Faster-RCNN以及YOLO系列的模型训练平均精度,MS-YOLOV3的优势还是很明显的。

表4 不同模型在Pascal VOC2007数据集上的实验结果Table 4 Experimental results of different models on Pascal VOC2007 dataset
4 结束语
针对YOLOV3模型对船舶识别中出现的误检和漏检问题,本文提出了基于YOLOV3 模型改进的船舶检测算法。以民用船和军用船作为研究对象,海上环境为研究背景。首先通过剪裁、缩放、旋转等手段,增加正样本的数量,为缓冲过拟合现象打下铺垫。其次利用维度聚类的算法对采集的船舶数据集进行anchor box 的常见尺寸的聚类,以提高模型对目标位置的检测准确度。接着在网络模型增加检测尺度,并在高低层尺度融合过程中加入DCA融合策略,丰富了待检测输入的细粒度,减小模型对目标的误检率和漏检率。虽然多尺度模块拉低了运行速度,但是准确度提升7.9个百分点,速度小幅度降低对于场景目标检测还是可取的。最后优化损失函数,采用GIOU 作为边框损失函数的参数,以此提高模型对目标的检测定位能力。实验结果表明,相对于YOLOV3 模型,改进后的MS-YOLOV3 模型对船舶的检测精度有很大的提高,同时将改进模型与其他流行检测算法在Pascal VOC2007 数据集上做精度对比,实验结果验证了本文提出的改进方法的有效性。下一步工作主要对本文提出的船舶数据集Shipdataset进行优化,同时针对民用船的船体复杂特征的情况,继续改进模型,使得其对民用船的检测精度得到提升。此外,针对模型计算量较大的情况,需要学习研究模型剪枝方面的策略。
