基于嵌入式特征选择算法下的抗乳腺癌药物分子活性预测
2022-02-20叶丹胡二琴
叶丹 胡二琴


摘要:文章提出在嵌入式特征选择算法背景下,通过对比正则化模型和树模型两种筛选方法下的重要性权重选取出对生物活性最具有显著影响的20个分子描述符,并分别建立预测模型。结果表明树模型下的随机森林方法真实值与预测值相对平均误为0.0167,相较于正则化方法和树模型方法下的梯度提升决策树更优,证实基于该方法下筛选的模型具有预测误差小、预测精度更高的优点。
关键词:抗乳腺癌;嵌入式特征选择;重要性权重选择特征;生物活性预测
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2022)34-0008-03
1 引言
乳腺癌是目前世界上最常见,致死率较高的癌症之一。世界卫生组织国际癌症研究机构(IARC) 发布的2020年全球最新癌症负担数据显示,2020年全球新增癌症病人约1930万人,其中女性乳腺癌占11.7%,在数量上已经超越了肺癌(11.4%) ,成为全球新诊断人数最多的癌症。乳腺癌确诊病人超过226万[1],其中仅中国就超过41万人,占比9.1%。其发病率和死亡率分别位列我国女性恶性肿瘤的第1位和第4位[2]。虽然乳腺癌发病率高,但致死率相较于肺癌、肠癌这些常见癌症要稍低。提高早期乳腺癌及其癌前病变的检出率并进行及时有效的治疗是提高乳腺癌预后、降低乳腺癌死亡率的重要措施[3]。
近年来,国内外研究发现雌激素受体α亚型(Estrogen receptors alpha, ERα) 在乳腺发育过程中扮演了十分重要的角色[4-5]。在恶性乳腺癌组织中的雌激素受体的浓度一般较高,而大部分良性肿瘤和正常组织都不含雌激素受体[6],因此ERα被认为是治疗乳腺癌的重要靶标。能够拮抗ERα活性的化合物可能是治疗乳腺癌的候选药物。
不断地寻找新的手段来改进药物以最大化药物的治疗效果是科学制药发展的趋势。因此,寻找新的抗乳腺癌候选药物尤为关键,对于乳腺癌患者精确治疗具有积极而重大意义,可以降低乳腺癌患者死亡率。本文提出在嵌入式特征筛选背景下,通过对比正则化模型和树模型下不同方法的特征选择,对1974个化合物所对应的ERα生物活性数据进行特征筛选,并利用不同筛选办法选取的前20个对生物活性具有显著性影响的化合物分子式分别构建预测模型并对模型进行评估。
2 数据处理及变量筛选
本文数据来源于2021年中国研究生数学建模竞赛数据,数据包含1974个化合物的729个分子描述符信息(自变量)和化合物对应ERα的生物活性值PIC50。PIC50值越大表明生物活性越高,对抑制ERα活性越有效。本文设定PIC50为因变量。利用Python、R编程完成对集中数据的预处理。
2.1 数据预处理
1) 删除原始数据中化合物分子式中缺失值。原始数据中有225个分子描述符取值全部为零,删除全部为零的分子描述符后剩余504个分子描述符(自变量)。
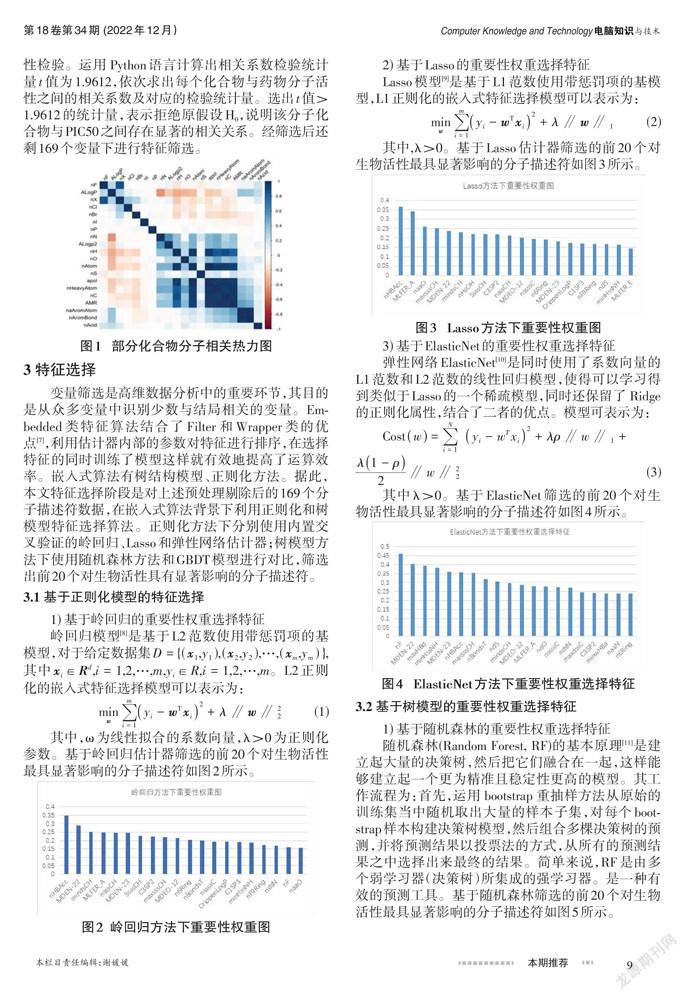
2) 进行化合物分子的相关性分析。去除冗余的化合物分子式,防止过度拟合。结合热力图1可发现部分变量相关系数绝对值接近1,此类变量的信息高度重叠(本文选取绝对值大于0.9) 。为解决模型建立复杂问题,本文将信息高度重叠的部分变量进行剔除。
经过剔除后还剩222个有化合物分子,显然直接应用这些化合物分子式不仅浪费时间还可能会导致模型的过度拟合,因此还需要筛选出与因变量PIC50具有一定相关性的自变量。
3) 相关性显著性检验。计算化合物分子式与药物分子活性PIC50之间的Pearson相关系数并进行假设检验得到对应的t值,发现部分化合物分子式与PIC50之间的相关性较弱。为使数据降维,减少原始数据对预测模型准确性的干扰,对相关系数进行显著性检验。运用 Python语言计算出相关系数检验统计量t值为1.9612,依次求出每个化合物与药物分子活性之间的相关系数及对应的检验统计量。选出t值>1.9612的统计量,表示拒绝原假设H0,说明该分子化合物与PIC50之间存在显著的相关关系。经筛选后还剩169个变量下进行特征筛选。
3 特征选择
变量筛选是高维数据分析中的重要环节,其目的是从众多变量中识别少数与结局相关的变量。Embedded类特征算法结合了Filter和Wrapper类的优点[7],利用估计器内部的参数对特征进行排序,在选择特征的同时训练了模型这样就有效地提高了运算效率。嵌入式算法有树结构模型、正则化方法。据此,本文特征选择阶段是对上述预处理剔除后的169个分子描述符数据,在嵌入式算法背景下利用正則化和树模型特征选择算法。正则化方法下分别使用内置交叉验证的岭回归、Lasso和弹性网络估计器;树模型方法下使用随机森林方法和GBDT模型进行对比,筛选出前20个对生物活性具有显著影响的分子描述符。
3.1 基于正则化模型的特征选择
1) 基于岭回归的重要性权重选择特征
2) 基于Lasso的重要性权重选择特征
3) 基于ElasticNet的重要性权重选择特征
3.2 基于树模型的重要性权重选择特征
1) 基于随机森林的重要性权重选择特征
随机森林(Random Forest, RF)的基本原理[11]是建立起大量的决策树,然后把它们融合在一起,这样能够建立起一个更为精准且稳定性更高的模型。其工作流程为:首先,运用 bootstrap 重抽样方法从原始的训练集当中随机取出大量的样本子集,对每个bootstrap样本构建决策树模型,然后组合多棵决策树的预测,并将预测结果以投票法的方式,从所有的预测结果之中选择出来最终的结果。简单来说,RF是由多个弱学习器(决策树)所集成的强学习器。是一种有效的预测工具。基于随机森林筛选的前20个对生物活性最具显著影响的分子描述符如图5所示。
2) 基于GBDT模型的重要性权重选择特征
梯度提升决策树[12](GBDT)是以分类回归树为基学习器Boosting集成学习算法。在GBDT的每次迭代中都在残差减少的梯度方向新建一棵CART决策树,经多次迭代最后的残差趋近0,最后将所有决策树的结果累加获得最终的预测结果。基于随机森林筛选的前20个对生物活性最具显著影响的分子描述符如图6所示。
通过查阅药物分子研究文献发现:1) 高效率结合靶标的小分子配体具有更强的疏水性,药物分子可以通过其疏水基团与机体内的靶标相结合,发挥药理活性[13];2) 化合物的亲脂性对化合物的药理学活性有重大影响[14];3) 氢键作用是药物与生物靶标之间非共价相互作用中作用力较强的形式之一,往往对药效的强弱产生重要影响[15]。本文中筛选的部分变量与药物分子研究理論吻合,如:XLogp、LipoaffinityIndex、nHBAcc。体现出上述使用正则化方法和树模型方法筛选出的分子描述符较为合理,具有可信度。
4 生物活性预测模型构建与评价
构建预测模型的整体思想:结合三种特征筛选方法下分子描述符的数据作为模型样本集。正则化筛选变量分别建立岭回归、Lasso和ElasticNet弹性网络预测模型;树模型筛选变量分别建立随机森林回归和梯度提升决策树回归模型。模型评估时选用相对平均误差(MSRE) 作为评价模型的指标。相对平均误差(MSRE) 的定义如下:
从上述分析可以看出基于嵌入式算法下建立的预测模型都保持了较高的预测精度,而其中所有的树模型预测结果较正则化方法下的结果更优。在树模型下方法下,随机森林方法预测结果优于GBDT模型。
5 结束语
本文从嵌入式特征选择方法出发,通过化合物对ERα的生物活性数据进行分析,采用特征重要性排序方法进行特征选择建立不同预测模型,结果表明随机森林方法在生物活性预测方面具有精度更高的优点。此外,通过特征选择方法筛选出的部分化合物分子式与药物分子研究吻合,有望成为抗乳腺癌药物研究的可选标志物。嵌入式方法下的特征筛选方法具有可拓展性,未来可以将该算法推广到其他类型癌症的药物筛选上,推动未来不同癌症的靶细胞筛选不同的化合物分子事业发展。
参考文献:
[1] Sung H,Ferlay J,Siegel R L,et al.Global cancer statistics 2020:GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J].CA:a Cancer Journal for Clinicians,2021,71(3):209-249.
[2] 赫捷,陈万青,李霓,等.中国女性乳腺癌筛查与早诊早治指南(2021,北京)[J].中国肿瘤,2021,30(3):357-382.
[3] 中华预防医学会,赫捷.中国女性乳腺癌筛查标准(T/CPMA 014-2020)[J].中华肿瘤杂志,2021,43(1):8-15.
[4] Fuqua S A,Wiltschke C,Zhang Q X,et al.A hypersensitive estrogen receptor-alpha mutation in premalignant breast lesions[J].Cancer Research,2000,60(15):4026-9.
[5] 张桂香,赵学东.雌激素受体亚型的研究现状[J].国外医学 妇产科学分册,2002,29(6):352-355.
[6] 赵晓民,徐小明.雌激素受体及其作用机制[J].西北农林科技大学学报(自然科学版),2004,32(12):154-158.
[7] 周志华.机器学习[M].北京:清华大学出版社,2016.
[8] Liu J,Ji S W,Ye J P.Multi-task feature learning via efficient l2,1-norm minimization[J].Uncertainty in Artificial Intelligence,2009:339-348.
[9] Keerthi S S,Shevade S.A fast tracking algorithm for generalized LARS/LASSO[J].IEEE Transactions on Neural Networks,2007,18(6):1826-1830.
[10] Zou H,Hastie T.Regularization and variable selection via the elastic net[J].Journal of the Royal Statistical Society:Series B (Statistical Methodology),2005,67(2):301-320.
[11] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[12] Friedman J H.Greedy function approximation:a gradient boosting machine[J].The Annals of Statistics,2001,29(5): 1189-1232.
[13] Ferreira de Freitas R,Schapira M.A systematic analysis of atomic protein-ligand interactions in the PDB[J].MedChemComm,2017,8(10):1970-1981.
[14] 王佩利.新型抗肿瘤活性小分子化合物的类药性质研究[D].上海:华东师范大学,2018.
[15] 盛春泉.药物结构优化——设计策略和经验规则[M].北京:化学工业出版社,2018.
【通联编辑:王力】
