基于Spark的设备状态数据实时处理系统设计
2022-02-20李程文
李程文
(佛山职业技术学院,广东 佛山 528137)
0 引言
工业生产设备数据采集、处理和分析系统利用泛在感知技术对各种工业生产设备进行实时高效采集和云端汇聚,并通过对数据的实时处理分析和预测设备运行状态。传统制造企业判断生产设备是否会发生故障,主要凭借设备维护人员长时间的经验积累和对生产设备的逐一排查,人力成本高且滞后。伴随着现代工业突飞猛进的发展,工业设备也向着高智能、大体型、分布式等方向快速发展,功能越来越强,设备结构也愈加复杂,设备发生故障的概率较之前大幅提高,设备故障的信息数据呈指数型增长。人工已经无法负荷设备产生的海量数据,无法完成正确、有效的故障分析[1-3]。
此外,工业生产设备结构越复杂,各部分之间的耦合性就越强,故障与故障相互影响的概率就越大,故障机理变得越复杂。因此,对工业生产设备所产生的海量信息进行实时分析就显得尤为重要,这有助于确定故障发生的频率、位置和原因,对故障的实时感知、实时预测和实时处理,从而提高设备日常维护效率,减少维护成本[4-6]。
本系统基于Spark实时处理生态圈框架,实现了对工业生产设备数据的实时采集、分析和挖掘,实现了设备状态在线监测与故障预警。通过本系统,设备管理维护人员能够实时掌握设备运行状态数据和整体变化趋势,做到事前预防、事中管控、事后检验,在每台设备的工作周期内,极大地延长设备的安全运行时间和缩短设备的维护时间,从而减少生产设备的突发性停机与事故,减少生产设备运行和维护成本,帮助企业实现生产设备的高效、实时、智能管理,提高企业的生产效益[7-9]。
1 设备状态数据实时处理系统设计
设备状态检测和故障预警系统的一般业务流程为:获取和记录数据,对数据进行抽取、清洗和注释,然后集成、聚集或表达相关数据,再对数据进行分析建模,最后对数据进行解释和应用。根据这个过程,设计通用性设备状态数据实时处理过程如图1所示,包括设备状态数据采集、设备状态数据预处理、设备状态数据分析和设备状态数据可视化4个步骤。

图1 设备状态数据处理流程
1.1 设备状态数据采集
设备状态数据一般来源于各种传感器和各种自动化系统数据,主要为结构化数据和半结构化数据。本系统通过Flume框架对设备运行状态数据进行实时采集。
1.2 设备状态数据预处理
在原始数据中,通常存在脏数据,主要包括数据缺失、数据噪声、数据冗余、数据集不均衡等。因此,相关人员需要对数据进行预处理。预处理的方式主要包括数据清洗、数据转换、数据描述、特征选择(组合)、特征抽取等。
1.3 设备状态数据分析
通过大数据分析、机器学习、深度学习等算法建立设备健康指数模型并及时进行设备预警,可实现整条生产线设备的故障诊断分析与预测。
1.4 设备状态数据可视化
管理人员可通过可视化系统实时监控设备、观察设备运行状态,可视化系统能够显示报警信息,同时支持设备状态在线检测、实时分析等功能。
2 设备状态数据实时处理系统实现
基于Spark的工业数据实时处理平台从实际业务出发,基于Spark实时处理生态圈框架,解决数据采集、数据预处理、数据分析、数据存储和数据可视化问题,可应用于工业大数据、工业互联网及工业数据实时处理等领域。其系统结构如图2所示。
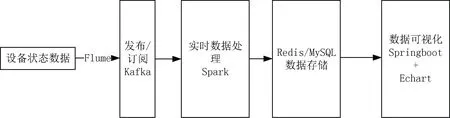
图2 工业数据实时处理平台结构
平台采用2台搭载Centos系统的服务器作为主节点,3台搭载Centos系统的服务器作为计算节点。部署的组件为JDK11、Scala2.12、Redis5.0.8、Hadoop3.2.2、Spark3.1.3、Flume1.9.0和Kafka2.12。
2.1 设备状态数据采集
在数据采集环节使用Flume框架采集日志数据,Flume是由Sink,Source和Channel三部分组成。首先,通过设置Source类型为“file”并使用Linux的“tail -F”命令来监控设备状态日志文件,从而监控采集设备状态数据的变化,如图3所示。然后,通过设置Sink的类型为“Kafka”,并设置Kafka的topic实现将变化的结果实时写入Kafka。最后,配置Channel将Source端收集到的数据传输到Sink中。

图3 开启设备状态数据实时采集
2.2 设备状态数据预处理
本系统采用SparkStreaming实时读取Kafka中的数据然后进行处理,创建DStream的方式为Direct直接连接方式,该方式具有高并行能力和速度可以自行控制等特点。第一步创建SparkSession并设置相关参数;第二步配置Zookeeper保证系统的一致性与稳定性;第三步配置Kafka,此处Topic需要和Flume job文件中的Topic一致,并绑定Kafka的Brokers。配置完成后,每当Flume采集到数据,同时Kafka成功发布订阅,Spark既可通过SparkStreaming实时读取设备状态数据。同时,Spark提供了丰富的算子可以对获取的实时数据进行处理,比如当实时传入的数据中值为“null”的数据需要替换为“0”,则可以采用filter算子进行处理。
2.3 设备状态数据分析
Spark的机器学习库MLlib,旨在简化机器学习的工程实践工作,并易于扩展到更大规模的运算。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。本系统使用Spark MLlib对上一步预处理后的数据进行分析,并将处理的结果存储入Redis数据库。
2.4 设备状态数据可视化
数据可视化系统采用B/S架构,前端采用HTML,CSS和Vue等技术,后台采用Sprintboot框架,数据可视化话组件采用ECharts。当数据处理完成后,本研究使用Sprintboot读取Redis数据,使用ECharts,HTML和Vue等前端工具实现可视化。
3 结语
本研究采用Spark实时处理生态圈框架中的Flume,Kafka,Spark和相关数据库及前后端软件实现了基于Spark的设备状态数据实时处理系统,从而实现对工业设备的状态实时监测,设备运行数据实时采集、分析和预测。本系统的成功运行,帮助企业对生产设备运行状态进行监测,从而减少生产设备的突发性停机与事故,减少生产设备运行和维护成本,提高了企业的生产效益。
