基于MapReduce 并行计算的网站日志数据分析处理
2022-02-19刘义卿陈新房
刘义卿 陈新房
(防灾科技学院信息工程学院,河北 三河 065201)
Hadoop 是一种具有分布式特点的系统框架,Hadoop 发展到今天已经发展成一个生态系统,其组件之多,使用也是极其复杂,但是根本的目的只有一个那就是解决数据的存储与分析。本文将在Hadoop 分布式系统下的MapReduce 为处理系统的基础上进行网站日志的清洗,通过LogMapper 类进行键值对的Shuffl 操作、通过LogReducer 类进行合并统计。利用分布式、并行计算的优越性,快速得到数据分析结果。
1 Hadoop 分布式平台核心技术
Hadoop 主要由两大核心HDFS 和MapReduce 两部分组成。
1.1 HDFS。HDFS是一种分布式文件系统,作为Hadoop 核心之一,具有处理超大数据、流式处理、可在廉价的服务器上运行等特点。HDFS在访问应用程序数据时,具有很高的吞吐率,因此对于超大数据集的应用程序而言,选择HDFS 作为底层的数据存储是比较理想的选择。
1.2 MapReduce。MapReduce 是一种编程模型,通常被用于大规模的数据集的并行运算,对于各个数据分片,都会有一个map 任务对该分片进行处理,这种处理是一种并行的方式。但是对同一个分片,Mapreduce 的map 任务对该分片的<key,value>对的处理是一个串行的处理过程。分布式并行计算指的是对数据分片的并行,对分片内的记录,则按照顺序的串行处理。
Mapreduce 模型的核心是Map 函数和Reduce 函数。二者都是由应用程序开发者负责具体实现的。只需要关注如何实现Map 和Reduce 函数,不需要处理并行编程过程中的其他各种复杂问题。,例如分布式存储、工作调度、负载均衡、容错处理等。这些问题都会由Mapreduce 框架进行处理完成。如图1所示。
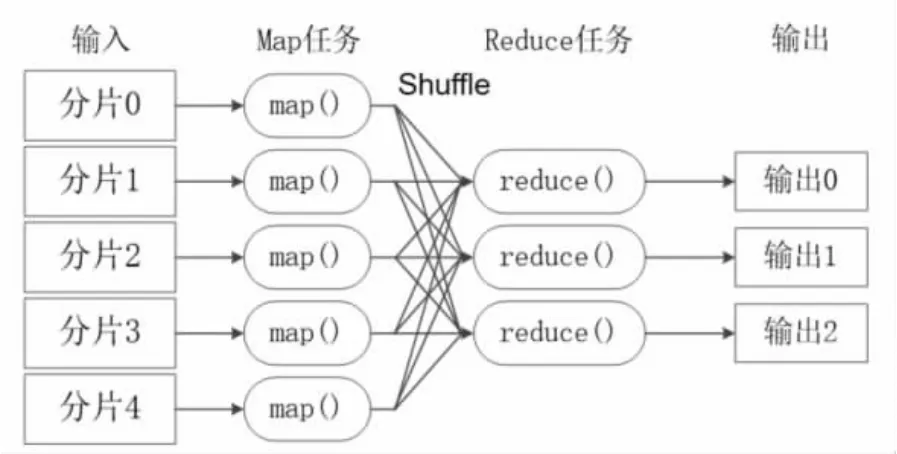
图1 MapReduce 模型
2 MapReduce 工作原理
MapReduce 将复杂的、运行于大规模集群上的并行计算过程高度的抽象到两个函数:Map 函数和Reduce 函数。
2.1 Map 函数的输入来自于分布式文件系统的文件块,这些文件块的格式是任意的。类型也是任意的。在Map 读取之前MapReduce 框架会使用InputFormat 模块做Map 的预前处理,检验其格式是否符合等。讲文件逻辑上切分多个InputSplit 在这个过程中还需要RecordReader 记录相应的处理信息。Map 函数将输入的元素转化为<key,value>键值对的形式,转化的过程是根据用户输入的映射规则进行转化的。因此键的类型和值的大小,都与用户定义的规则有关。
2.2 Shuffle 过程分为Map 端和Reduce 端。Map 端的Shuffle 的任务主要分为以下几部分:首先将输入的数据按照用户自定义的映射规则转换成一批<key,value>,写入缓存,每个任务都会分配一个缓存一般默认为100MB,溢写比为0.8 这样就能保证Map 持续的写入缓存,即要保证缓存不满。到达缓存后,在进入磁盘的过程中会先被分区、排序、合并。分区的方式是采用Hash 函数对Key 进行哈希后再对Reduce 任务进行取模,以为了更均匀的分配给Reduce。后台进程还要根据key的不同进行排序,并根据用户是否定义了合并操作而选择合并,以减少写到磁盘的数据量。合并的根本目的就是将key相同的value 相加起来目的是减少键值对的数量。写入磁盘后,缓存要被清空。输送到磁盘中要进行文件的归并,所谓“归并”就是要将相同的键值对的归并成一个新键,待Map 端结束后Reduce端会“领取”属于它的数据放到自己的磁盘中,期间Reduce 还会通过RPC向JobTracker 查看Map 的状态,保证任务的传递速率。Map 端领过来的数据会先放入Reduce 的缓存中,进行文件的归并以及合并操作,最后把任务输送到Reduce。图2 为Shuffle 过程。

图2 Shuffle 过程
2.3 在整个Shuffle 结束之后,Reduce 任务会根据Reduce函数中用户定义的各种映射规则,输出最终结果,并保存到分布式文件系统中。
3 网站日志数据分析
在此进行一个网站日志清洗的实例,将其上传到分布式系统中,并利用MapReduce 计算模型进行数据分析。
3.1 将数据上传集群中

3.2 LogTcl 类实现代码
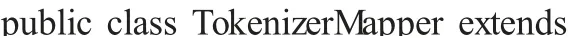


System.setProperty ("HADOOP_USER_NAME", "root"); // API 连接高可用时用到


3.3 LogMapper 类实现代码

3.4 LogReducer 类实现代码

3.5 查看处理后的结果

总结,本文首先介绍了Hadoop 在大数据技术中的重要地位,并简单介绍了Hadoop 的两大核心HDFS 和MapReduce 的概念。进而详细介绍MapReduce 的组成部分和其各部分的主要功能,尤其是Map 函数的处理过程和Shuffle 的详细过程。以及各部分组件在工作时的相互作用与协调。在MapReduce 计算模型的处理下,将网站的日志进行了分析处理将其日志进行清洗过滤得到了想要的分析结果。充分体现了Mapreduce 作为Hadoop 生态圈的重要一员,其在处理数据时具有的高效性和优越性。
