基于机器学习的运营商客户行为分析
2022-02-18周艳聪郝园媛
周艳聪, 郝园媛
(天津商业大学信息工程学院, 天津 300134)
随着5G时代的来临,各大运营商竞争日趋激烈,客户的选择更加主观,因此运营商往往面临着一些客户离网的挑战。通过大数据工具与人工智能技术对客户数据进行分析,建立有效的预测与分析模型,对不同的客户实施精准的营销策略,降低客户的离网意愿,减少客户流失,将是十分有意义的工作。同时,在模型优化过程中,可以进一步挖掘客户价值和企业管理的潜在规律,从而为企业的进一步发展提供依据。
国外在运营商客户分析方面研究相对较早。很大一部分学者利用各种数据分析和建模技术,对客户分类、维系流失客户等方面进行研究。例如,文献[1]提出了一种基于客户生命周期的新型客户细分方法,采用决策树方法提取与客户长期价值和忠诚度有关的重要参数。但研究者们发现单一模型的准确度往往不足,于是开始结合多种模型进行研究,Adwan等[2]使用了两种基于多层感知机(multilayer perception,MLP)的方法,对客户流失率的最大影响因素排名,构建客户流失分类模型。Ahmed等[3]着重总结和分析了客户流失预测技术,识别客户流失行为并验证其原因,提出最准确的客户流失预测是由混合模型而不是单一算法给出的。Abdi等[4]结合K均值算法和聚类技术,提出了一种基于数据挖掘技术的客户行为挖掘框架,有效帮助电信管理人员分析其客户的行为。
国内学者的研究大多集中在对多方法的结合应用,实现对运营商客户多角度的综合分析。王观玉等[5]针对通信公司客户数据多维度的特点,首先利用主成分分析法对数据进行降维处理,找到影响客户流失的关键指标,再通过支持向量机进行学习建模,有效提高了预测客户流失的准确性。林勤等[6]通过对大均值子矩阵(larg average submatrices, LAS)双聚类算法和K均值算法的对比分析,进一步挖掘客户群体,为识别高价值客户市场带来实际的帮助。
人工智能技术的流行使得机器学习算法在客户分析的应用中更为广泛。机器学习利用计算机模拟人类的学习活动,是研究计算机识别现有知识、获取新知识、不断改善性能和实现自身完善的方法[7]。近年来,越来越多的研究者利用机器学习的相关算法对运营商客户行为进行分析。陈思含[8]在进行移动公司的客户分析过程中,建立了距离判别模型、支持向量机、神经网络三种模型,并采用K均值聚类、逻辑回归分析等方法,寻找运营商流失客户的行为特征。夏国恩等[9]针对传统数据预处理中one-hot编码导致的数据维度增加及数据过于稀疏的问题,构建了基于多层感知机的客户流失预测模型并验证了模型的有效性。
回顾相关领域的研究发现,对于客户行为的分析,现存的研究方法十分多样,从单模型的建立到多模型的综合运用,从传统的统计方法到结合机器学习的智能方法,为运营商客户行为分析及客户管理提供了基础和借鉴,但当前研究仍存在两方面的问题:①传统模型多采用MATLAB等语言进行建模,算法较为复杂,但泛化能力不强,在数据规模较大时方法的应用很受限,而运营商具有广泛的用户数量,每个用户对应的基本信息、套餐消费、通信等数据量大且维度广,由此产生了海量、多维的客户行为数据,这就增加了实现高效运营商客户分析的难度;②以往研究集中于对模型准确度的提升,对数据特征的分析较少,但运营商客户数据涉及特征广泛,需要结合数据特点对特征进行筛选和比较,从而为运营商的客户管理提出新的方案。
基于此,现尽可能降低对先验知识的依赖程度,基于运营商客户数据海量、多维的特点,通过机器学习技术,采用Python语言对数据进行预处理,建立反向传播(back propagation,BP)神经网络和随机森林模型,对客户流失行为进行预测与分析,提高客户分析的智能性、敏捷性和科学性,从而为实际运营商企业的运营决策提供借鉴;同时,为了避免出现盲目追求预测准确度而忽略数据特征,利用Lasso回归模型对数据特征进行分析与比较,将深入分析和探索运营商客户数据,并根据所构建的模型挖掘隐藏在历史客户数据中的有效信息和规则,以期为运营商的客户管理和相关决策提供理论支持。
1 数据处理
1.1 数据说明
某电信运营商提供了不同用户在三个月内的使用信息,一共900 000条数据,包括用户的身份标识号码(IDentity,ID)、在网时长、通话时长、上网流量等34个特征,因变量为客户是否流失,其中1月和2月的流失标记值为空。
1.2 数据预处理
由于原始数据的不完美,如包含数据异常或冗余内容,将不利于数据建模,因此需要对数据进行预处理。根据本文研究的数据情况,对原始数据中存在的缺失值、异常值等数据进行处理,从而避免因数据污染导致分析结果的偏差。
1.2.1 特征选择与分析
观察数据,发现部分数据存在一些计算值重复的现象,例如,通话时长等于本地通话时长、国内长途通话时长、国内漫游通话时长的和,可以保留通话时长的总和数据,将其他特征删去,便于后期模型的建立。同理,通话次数、上网流量、通话天数、语音呼叫圈等特征做类似的处理。此外,数据特征中,用户星座及手机型号名称与客户流失关联较小,故删除这两个特征以简化数据。
1.2.2 检测与处理重复值
根据数据实际情况采用drop_duplicates函数去重。初始状态的数据形状为900 000列、35行,经过去除重复数据和删除冗余特征后的数据形状为899 904行、20列。
1.2.3 检测与处理缺失值
在实际的数据分析过程中很难避免缺失值,缺失值的存在往往会使数据分析不够准确。由于本次样本数据量较大,样本特征较多,所以首先对缺失值进行识别和分析。由数据分析结果可知,合约计划到期时间(AGREE_EXP_DATE)以及VIP等级(VIP_LVL)数据缺失情况相对比较严重,缺失值比例分别约为0.49以及0.35,如果将缺失值全部删去对数据分析影响较大,所以采取均值补齐缺失数据。此外,从数据缺失情况可以看出,用户性别(CUST_SEX)、用户年龄(CERT_AGE)以及操作系统描述(OS_DESC)也存在少量的数据缺失,由于缺失程度较小,采取删除法删除缺失的样本,以保证信息完整度。最后,经过缺失值处理,数据形状为819 059行、20列。
1.2.4 检测与异常值处理
异常值可能是一些外在因素产生的,如工作人员的错误输入、统计工具的不兼容、命名规则的差异等。如果在数据分析过程中存在异常值,会导致分析结果产生较大的偏差,干扰数据模型的建立。由于本次数据分析的数据量级比较大,所以先利用describe函数查看数据分布及极值情况,可以得知许多特征的波动性都很大,例如,本月费用(ACCT_FEE)特征,用户平均月费用为114.4元,标准差为106.9元,波动性很大,中位数费用为86.1元,75分位数费用为141.4元,说明绝大部分订单的本月费用都不多,月费用最大值为1 1059.4元,受极值影响,需要排除异常值。同理,在网时长(INNET_MONTH)、通话时长(CALL_DURA)、短信发送数(P2P_SMS_CNT_UP)、上网流量(TOTAL_FLUX)、年龄(CERT_AGE)等特征数据波动过大,也需要进行异常值排除,因为数据样本比较多,再加上数据受极值影响较大,所以使用盖帽法自定义函数处理异常值。
1.2.5 筛选和转换数据
在初始数据中,每个用户对应着3个月的数据记录,存在一个用户有3条记录的情况,所以需要对数据进行筛选。通过用户ID(USER_ID)特征对数据进行分组,将数据处理为一个用户一条记录,保留用户每月的费用、通话时长等信息,从而便于数据模型的建立。此外数据中还存在手机品牌、操作系统等类别型数据,如手机品牌有633种,操作系统描述有47种。神经网络模型的建立要求输入的特征为数值型,所以需要对手机品牌和操作系统特征进行处理。首先合并用户的手机品牌(MANU_NAME)与操作系统(OS_DESC)特征为“手机操作系统(MOBILE_OS)”,再对手机操作系统特征做哑变量处理。
1.3 数据不平衡问题
数据不平衡是指响应变量值的不平衡分配,这种不平衡问题是影响数据分析的常见问题之一。在本文的客户流失分析当中,经过数据处理后的数据有流失客户8 301名,非流失客户266 762名,比例为1∶32,模型在训练过程中会产生偏差。因此在建模之前需要解决数据不平衡问题,保证模型的建立更准确。一般来说,当流失客户数据与非流失客户数据比例为1∶2或1∶3时模型的效果较好[10]。
由于本次数据量较大,所以采用过采样的方法。通过合成少数类过采样(synthetic minority over-sampling technique,SMOTE)技术进行过采样之后,利用Counter函数查看数据情况,流失客户样本数量为106 704,非流失客户的样本数量为266 762,比例约为1∶2.5,可以进行后期模型的构建。
2 建模
经过前期的对比分析,最终选择神经网络和随机森林作为数据分析模型。神经网络模型对于输入的各项特征可以自行学习,人工干预较少,有利于得到比较客观的模型。选择随机森林模型主要考虑到:①该模型可以产生高准确度的分类器;②它可以在内部对于一般化后的误差产生不偏差的估计;③如果有部分数据缺失,模型仍可以维持准确度;④对于不平衡的数据,它可以平衡误差;⑤学习过程快速。尤其在出现数据缺失和不平衡的情况下,随机森林是一个很好的选择。
以Anaconda为环境,采用Jupyter Notebook为代码编辑工具,用Python语言对运营商客户数据进行建模与分析。
2.1 神经网络模型构建
BP神经网络是一种按误差反向传播训练的多层前馈网络,其由输入层、隐藏层和输出层组成。BP神经网络不要求建模者有丰富的先验知识,便于建模,其在解决非线性问题方面有强大的数据识别和仿真能力。
2.1.1 模型构建
经过数据预处理后,用于模型训练的数据共有373 466条,其中非流失用户数据有266 762条,流失用户数据有106 704条。首先通过Python的sklearn库中的train_test_split函数进行数据集划分,得到训练集和测试集。其中,训练集数据样本为280 099个,测试集数据样本为93 367个。
在训练神经网络时,选取运营商客户的14个特征作为网络的输入,分别为是否合约有效用户、VIP等级、用户性别、用户年龄、合约到期时间、终端硬件类型、本月费用、通话时长、短信发送数、上网流量、通话次数、通话天数、语音呼叫圈、手机和操作系统描述。训练BP神经网络时给定的输出为一个节点,该节点输出结果为1或0,其中1代表流失客户,0代表非流失客户。构建的神经网络结构如图1所示。
利用sklearn库中的MLPClassifier方法建立模型。根据几何金字塔公式设置初始的BP神经网络为单个隐藏层,隐藏层节点数为3,权重优化求解器采用lbfgs模式,其余参数均取默认值。模型构建成功后,用joblib.dump函数保存模型,以便后续模型的应用。构建的模型如图2所示。

图1 神经网络结构Fig.1 The structure of neural network

图2 通过MLPClassifier构建的神经网络模型Fig.2 The neural network model by MLPClassifier
2.1.2 神经网络模型评价及结果分析
分类器准确度评价采用混淆矩阵的相关指标。为了能更好地评估模型的准确度,同时采用了混淆矩阵的一些延伸指标:精确率(precision)、召回率(recall)和F1。同时,为了使模型评价更加直观,结合受试者工作特征曲线( receiver operating characteristic curve,ROC)来评价模型的效果。运行多次后的模型结果如表1所示。

表1 BP神经网络模型运行结果Table 1 The result of neural network model
根据表1可知,当神经网络模型有单个隐藏层,隐藏层节点数为3时,对客户流失预测的精确率仅达到了80%,平均预测精确率仅为83%,效果不是很理想,需要对模型进一步优化。
2.1.3 神经网络模型优化
BP神经网络模型的优化有很多种方法,包括对算法结构的优化以及对模型的参数进行优化。在本文中,主要根据模型参数的自身特性,对隐藏层结构、权重优化求解器、学习率模式三方面进行优化,提升模型的准确度。经过实验测试,输入层14个节点,输出层1个节点,中间设置两个隐藏层,各18个节点的神经网络模型精确度较高,判断客户为非流失时的精确率为92%,判断客户为流失的精确率为95%,并且隐藏层节点数不会过大。相比初始的神经网络模型,准确度得到了较大的提升,在此基础上对其他参数进行调节,可进一步优化模型。
对于权重优化求解器,经过实验数据(表2)可得,基于随机梯度下降(stochastic gradient descent,sgd)和其的一阶优化算法(adaptive moment estimation,adam)的权重优化算法精确率较高,准牛顿方法族优化器(large BFGS,lbfgs)算法精确率相对较低,可以在此基础上进一步调节对权重优化十分重要的学习率参数。
本文的模型除去输入、输出层,采用隐藏层为两层,每层节点数为18个的隐藏层结构,即在隐藏层结构为(18,18)的情况下,权重算法采用随机梯度下降(sgd)算法,对三种不同学习率模式的精确率进行了比较,比较结果如表3所示。
从表3中可以看出,当采用常数模式(constant)和自适应模式(adaptive)的学习率时,神经网络模型精确率较高,而采用升级模式(invscaling)精确率相对较低。综合参数优化过程,最终确定隐藏层结构为两层,每层节点为18个,权重下降算法采用随机梯度下降法,学习率模式采用自适应模式所得的模型预测结果精确率最高,平均精确率达到了96%,最后得到的ROC曲线如图3所示。从图3可以直观地看出,优化后的BP神经网络ROC曲线更加接近左上角,准确度较高。

表2 权重优化算法与模型精确度的关系Table 2 The relationship between weight optimization algorithm and model accuracy

表3 学习率模式与模型精确率的关系Table 3 The relationship between learning rate mode and model accuracy

TPR为真正率;FPR为假正率 图3 神经网络模型优化前后的ROC曲线对比Fig.3 Comparison of ROC curves before and after neural network model optimization
2.2 随机森林模型构建
随机森林是一种基于决策树的集成学习算法[11]。与许多其他的分类器相比,其往往表现出较好的性能,能够较好地解决过拟合问题[12],且准确性相对较高。除此之外,它还能够处理具有高维特征的输入样本,且不需要删除特征。由于随机森林在每次划分时考虑的属性较少,其在大型数据库的应用中效果较好[13]。
在Python中,通过随机森林分类器(random forest classifier)构建随机森林模型。模型的参数设定为:随机森林允许单个决策树使用特征的最大数量(max_features)设为每棵子树可以利用总特征数的平方根;子树的数量(n_estimators)设为10;最小叶子节点数目(min_sample_leaf)设为50,其他参数采用默认形式,最终构建的随机森林模型结构如图4所示。
构建好随机森林模型后,采用和神经网络模型相同的评价指标对随机森林模型运行结果进行评价,运行多次后取平均值得到运行结果如表4所示。由表4可以看出,随机森林模型的非流失客户预测精确率达到了93%,召回率达到了99%,F1为96%;流失客户预测精确率达到了98%,召回率达到了82%,F1为89%;整个模型的预测精确率达到了96%。

图4 构建的随机森林模型结构Fig.4 The structure of random forest model

表4 随机森林模型运行结果Table 4 The running results of random forest model
3 模型对比与分析
3.1 模型对比
在模型的选择问题上,也曾尝试过其他模型,如支持向量机(support vector machine,SVM),贝叶斯网络等,但效果不佳;也尝试了模型组合,但各项运行指标均低于单一的神经网络模型和随机森林。两个模型对流失客户的预测准确率分别达到了96%和98%,已经高于大部分文献的预测准确率。本文的主要贡献在于对模型参数的选择和调整。尤其神经网络模型,从网络层数到每层网络的节点数,都是若干次实验选择后的结果。模型的泛化性能也较好,在若干测试集上进行测试,准确率均较高。此外,对于大量数据的分析,本文研究的随机森林模型运行速度也较快。因此,仅对神经网络模型和随机森林模型进行对比分析。
BP神经网络是由多个非线性单元组合而成的模型,需要在每个神经元进行运算。随机森林是以决策树为基本单元,通过集成学习后所得的组合分类器。二者都是近年来比较流行的预测算法,本文研究结合对运营商客户分析的结果,从以下几个角度对两个模型进行对比分析。
(1)二者的决策边界不同,因此模型的表现效果也不同。BP神经网络的层与层之间具有高度的连接性,它的决策边界是由一组非线性的计算单元组成,计算比较复杂,所提供的决策边界是非线性的曲线或曲面。随机森林是通过多个决策树以投票的形式输出分类结果,具有较好的容差性,其决策边界更像是多个分段函数[14]。
(2)二者的预测准确度略有差异。总体来说,随机森林算法的准确度要高于BP神经网络模型。如表5所示,经过参数优化的BP神经网络模型,对非流失用户的预测精确度为93%,对流失用户的预测精确度为96%。相比而言,随机森林模型对流失用户的预测精确度略高,为98%。召回率和F1方面,随机森林模型也略优于神经网络模型。总体来看,随机森林模型的预测准确程度以及运算速度略优于BP神经网络模型。此外,将模型的ROC曲线进行对比,如图5所示,绿色曲线代表随机森林模型,蓝色曲线代表优化后的神经网络模型,随机森林模型的曲线整体比BP神经网络的曲线更靠近左上方,也更加的平滑。综合来看,在对运营商客户的分析中,随机森林模型的性能要优于BP神经网络模型。
(3)二者对于不平衡分类情况的处理效果不同。BP神经网络模型对不平衡分类的数据较为敏感,得出的模型很容易出现异常。在运营商客户分析中,流失用户占较少的比例,出现了不平衡分类问题,表6为神经网络模型数据不平衡情况下的模型评价,可以看出它的准确度在数据不平衡时出现了异常。而随机森林算法对不平衡数据的问题比较不敏感,它不会过度抽样,面对不平衡的分类,其受到的影响较小。
(4)模型训练速度方面,随机森林模型面对大量的数据也能够有效的处理,并且学习速度很快。BP神经网络处理速度较慢,尤其是在数据量比较大的情况。
(5)参数设定方面,BP神经网络有较多的超参数,可调节性较强,但在对参数设定和优化方面往往要花费较多的时间,所以神经网络一般存在较大的冗余性,也给模型的训练带来负担。而随机森林模型的超参数较少,且它的参数设定比较稳定,在参数设置方面不会花费太大的时间就能取到较好的效果。

表5 神经网络模型和随机森林模型精确度对比Table 5 Comparison of accuracy between neural network model and random forest model

图5 神经网络模型和随机森林模型ROC曲线对比Fig.5 Comparison of ROC curve between neural network model and random forest model

表6 神经网络模型在数据不平衡情况下的模型评价Table 6 Model evaluation of neural network model in case of data imbalance
(6)过拟合程度方面,BP神经网络较易发生过拟合[15]。与其他分类方法相比,随机森林算法的一大特点就是它不易发生过拟合,分类准确率也较高。
(7)参数选择方面,神经网络参数较多,并且神经网络的分类需要利用所学到的变量特征。同样的样本,随机森林模型可以选择部分参数进行测试,并赋予参数不同的权重,它的模型建立是边建树边分类。
综合上述对二者的对比情况,可以得到表7。
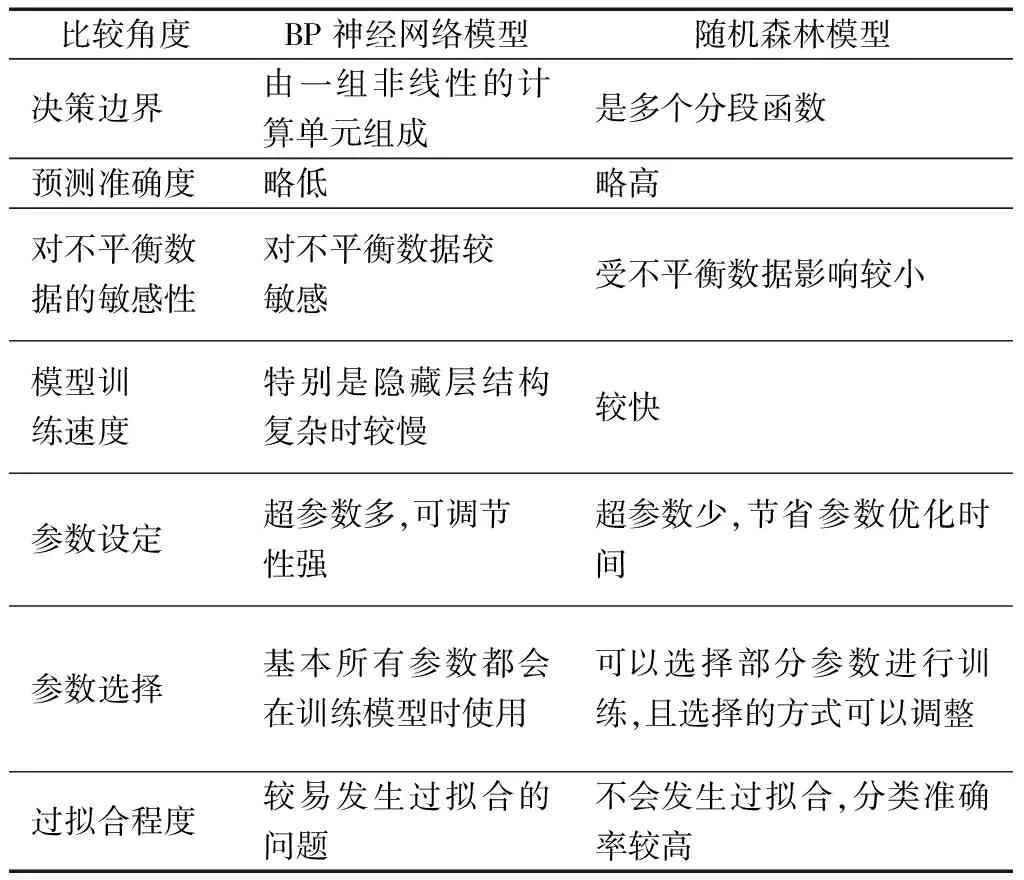
表7 神经网络模型和随机森林模型的对比Table 7 Comparison of neural network model and random forest model
3.2 影响因素分析
总体来看,随机森林模型的预测准确程度以及运算速度优于BP神经网络模型,也优于文献[16]中92%的准确率,说明本文研究创建的模型是有效的,可以将其应用于实际的客户流失预测中,从而针对流失客户的特点采取一定的策略挽留客户,为运营商减少损失。
在实际应用中,还需要对用户的行为和属性等特征进行分析,判断哪些属性与客户的流失行为具有较大的关联性,也就是对影响客户流失的因素进行分析,从而使运营商能够根据相应的属性特点采取针对性的措施。
通过Lasso回归模型对用户属性进行相关度的比较。通过利用sklearn库中的LassoCV方法,结合自定义函数和绘图工具,通过图像表示特征变量的重要程度,从图6可以看出,是否合约有效用户(IS_AGREE)、有通话天数(CALL_DAYS)、用户性别(CUST_SEX)、用户年龄(CERT_AGE)特征与流失相关性较强,并且主要是负相关,如用户每月有通话的天数越多,流失的概率就越低。同时也可以看出各特征与用户流失的相关性不是特别大,可以再结合散点图进一步对特征进行分析。
通过Matplotlib绘图工具,本文对部分特征进行了两两对比分析,利用散点图分析特征对客户流失的影响。本月费用和通话时长的散点图如图7所示。由图7可知大部分流失客户的通话时长和本月费用较小,说明经常通话、每月消费较高的用户不易流失。
图8为通话天数与用户年龄的散点图。从图8可以看出,非流失用户的年龄大部分集中在20~50岁,流失用户的年龄主要集中在10~30岁及50~60岁,说明年龄过大或过小的用户流失概率相对较高。同时可以观察到非流失用户的通话天数总体比流失用户的通话天数略长,但通话天数的差异没有用户年龄带来的差异大,因此用户年龄与用户流失的相关性更强。

图6 通过Lasso比较特征向量的重要程度Fig.6 Compare the importance of feature vectors through Lasso
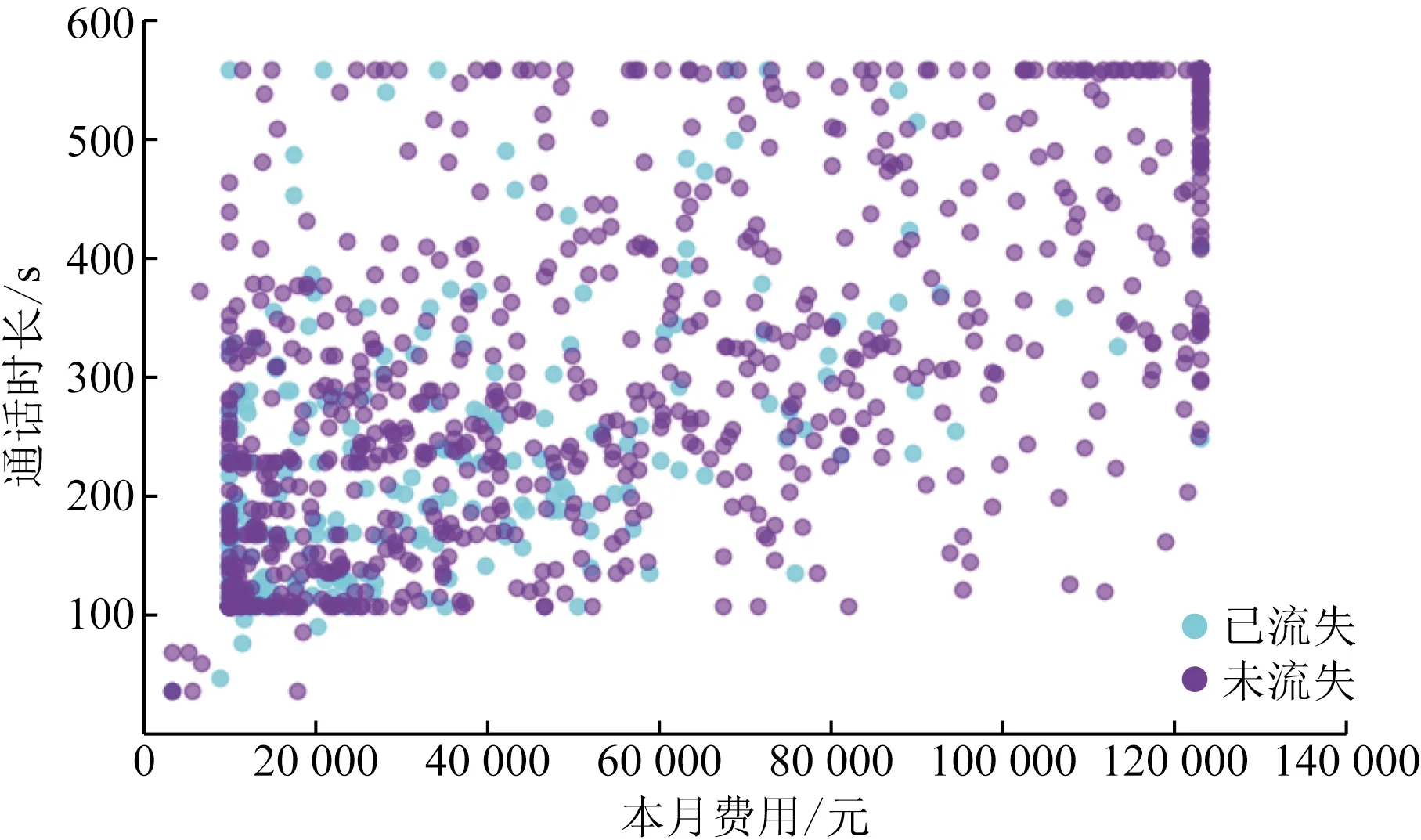
图7 本月费用和通话时长的散点图Fig.7 Scatter chart of this month’s cost and call duration

图8 通话天数与用户年龄的散点图Fig.8 Scatter plot of call days and user age
3.3 应用方案建议
基于模型分析以及企业运营环境,提出以下几点方案。
(1)针对经常通话、每月消费较高的用户不易流失的情况,可以通过营销套餐的组合、升级套餐优惠、套餐免费体验等方式,提升用户的消费兴趣。特别是对于一些经过模型预测可能流失的用户,可以进一步提供专属服务、个性化套餐等,增强用户的满意度,从而减少客户流失。
(2)针对用户年龄对用户流失概率的影响,对于不同的年龄层,可设计不同的方案。如年龄较小的青少年电话使用频率不高,较易流失,运营商可以与儿童手表、儿童学习机等厂家合作,采取一定的套餐优惠、绑定条件等,提升用户的使用频率;同时,也可以将青少年的账号与家长、学校进行绑定等,从而能够提供更全面的服务。
(3)针对运营商激烈的竞争环境,运营商企业必须抓住发展机遇,拓展思路,加强合作,可以参与到金融服务、信息技术(information technology,IT)服务、媒体或公用事业等领域当中,利用自身海量的数据资源和电信资源,寻找新的合作机会和收入来源。同时,通过与第三方的合作,也能够为运营商带来更专业的知识,进一步补充运营商强大的客户关系和广泛的覆盖范围。
(4)运营商应加强数字化转型,广泛地学习和应用新技术,培养相关的人才,增强其敏捷性,通过强大的数据分析,及早瞄准目标客户,以测试其喜好和价格敏感性。同时,加强技术基础设施的建设,紧跟5G的发展潮流,推动组织和业务的技术革新。
(5)最后,企业需要进一步追求更好的用户体验,以用户为始并回归用户。大多数运营商将客户体验看作是一系列的接触点,也就是客户与业务节点之间的交互,如产品客户服务、销售人员等。但是忽略了客户对公司的整体体验、对服务流程的整体体验。而大数据、云计算、人工智能等技术又能够帮助运营商从用户的角度思考,全方位地优化用户体验,从而为企业带来更大的效益。
4 结论
基于简单、有效的BP神经网络和随机森林模型,分析了运营商客户特别是其中流失客户的行为,并对两个模型的分析结果进行了对比分析,最终两种模型的预测准确度都超过了96%;此外,数据处理和模型建立均基于Python语言实现,也使得整个行为分析过程更加简洁高效。在此基础上,利用Lasso回归模型和散点图对用户特征进行了深入比较和分析,给出了一些有利于客户挽留的合理化建议。
虽然取得了一些成果,但还存在一些待改进的地方:①模型算法优化,向技术方向继续延伸,结合数据特征尝试采用更先进、更多样的机器学习算法来建立客户行为分析模型;②多种算法结合,后续研究可以进一步将BP神经网络和随机森林进行结合,吸取二者的优点,并根据所分析的数据特征来进行分析和建模,如深度神经决策树(deep neural decision forest,DNDF)结构,在神经网络中引入了树的结构,又适应于集成;③数据结果可视化,可以结合更多可视化工具将数据效果更清晰地呈现出来,使其能够在实际的运营商客户维系中得到更广泛的应用;④数据挖掘,可以将数据挖掘的结果与企业的客户关系管理系统结合起来,使预测模型得到充分运用,同时也能够根据客户的具体情况,提供更加个性化的维系策略。
