应用YOLOv4-tiny算法实现保护压板智能校核
2022-02-18杨宗源侯进周浩然郝彦超文志龙李天宇
杨宗源, 侯进, 周浩然, 郝彦超, 文志龙, 李天宇
(1.西南交通大学信息科学与技术学院, 成都 611756; 2.西南交通大学综合交通大数据应用技术国家工程实验室, 成都 611756; 3.西南交通大学唐山研究生院, 唐山 063000)
随着智能电网的发展,电网结构越来越复杂,继电保护压板的数量日益增多,人工巡检的工作负担与误操作风险随之加大。如何提高巡检效率,保障电力系统的稳定,成为目前亟需解决的问题。
目前,压板的智能校核主要基于图像识别方法与人工智能技术。图像识别方法一般分为压板有效区域分割与状态判别两部分。文献[1]需要人工添加4个校正基准点,以此完成透视变换。然后使用红、绿、蓝(red-green-blue,RGB)三分量差值法,提取红、黄两色的压板;文献[2]通过设定RGB阈值采集有效色块区域;文献[3]采取RGB阈值筛选法分割压板区域;文献[4]针对RGB模型中的三种颜色,以不同的权值进行了加权处理。然后通过颜色匹配定位压板区域;文献[5]采用了基于RGB值的聚类算法来分割压板图像。但是目前不同变电站的调色标准并不统一,并且仍存在未按标准分色的压板,所以基于RGB值进行定位的方法,不适合推广使用,后期维护的难度较大。文献[6]需要根据压板区域的红色框线,进行区域定位,但是在江苏南京某220 kV变电站中并没有类似的外框线。更重要的是,图像识别方法与图像质量休戚相关,而光照,角度等会直接影响图像质量,进而影响图像识别的准确率。
随着智能变电站的投入使用,人工智能技术备受关注。为实现智能校核,文献[7]使用了OpenCV与AdaBoost算法,文献[8]使用了卷积神经网络+特征变换方法,文献[9-10]使用了SSD(single shot multiBox detector)目标检测算法,文献[11]使用了YOLOv3目标检测算法,但是其模型预测准确率均不高,性能有待提升。
除了以上的常用方法,文献[12]提出了基于泛在物联网的运维技术。但其采用的射频识别技术,会在一定程度上增加设备的复杂性,并且对网络的畅通性也有一定要求。而本文的方法是可以离线完成的,用户可在离开现场后再将工作数据上传到服务器。
YOLOv4-tiny是一种轻量级目标检测模型,因为保护压板结构较简单,所以适合使用轻量模型,并且目标检测已在电力系统有了一定的应用[9-11]。现使用数据增强与迁移学习提高模型的泛化性,使其达到99.13%的均值平均精度(mean average precision,mAP)。
ncnn是一个专为卷积神经网络模型,进行移动端优化的前向推理框架,可以提高模型在移动端的预测速度。经过实测,优化后的模型在移动端的平均预测速度为30张图每秒( frames per second,FPS),达到实时检测的标准。同时,为解决由环境因素导致的漏检与误检问题,提高方法可靠性,研究并实现漏检压板的自动补全功能,以及误检压板的状态更正功能。以期为保护压板的智能巡检与智能电网的进一步发展提供理论基础。
1 YOLO目标检测与优化设计
1.1 YOLO的目标检测过程
YOLO算法的目标检测过程如图1所示,首先将输入图片划分为S×S个网格,如果网格中存在物体,那该网格会预测出B个边界框以及每个框的置信度。因此,往往会出现多个边界框定位到同一个物体,而为了得到最佳的边界框,YOLO算法会根据每个框的类别置信度和交并比(intersection over union,IOU),使用非极大值抑制[13]对冗余的边界框进行过滤。

图1 预测过程示例图Fig.1 Example diagram of prediction process
置信度Conf为模型认为该框包含物体的可能性以及该框的准确性,计算公式为
(1)
式(1)中:Object为物体;Pr为框中包含物体的可能性,包含为“1”,不包含为“0”;IOU为预测框(pred)与真实框(人工标注的框,truth)的交并比。计算公式为
(2)
式(2)中:AOI为预测框与真实框的交集的面积(area of intersection,AOI);AOU为两个框并集的面积(area of union,AOU)。
因为目标检测一般需要预测多类物体,这里假设模型需要预测C类(Class)物体,那么包含物体的网格,又会预测出每个类的条件概率Pr(Classi|Object),Classi表示第i类。将条件概率与置信度相乘,就可以得到每个框的每个类的置信度——类别置信度ConfClass。
ConfClass=Pr(Classi|Object)Conf
(3)
1.2 YOLOv4-tiny的网络结构
YOLOv4-tiny的网络结构由CSPDarknet53-tiny、FPNet[14]和两个YOLO Head[15]三部分组成。CSPDarknet53-tiny作为主干网络,进行特征提取; FPNet作为特征融合模块,用来构建特征金字塔;YOLO Head用来进行特征整合和预测。
CSPDarknet53-tiny主要由CSPNet[16]模块(简称CSPBlock,如图2右上角所示)与Darknet53[17]构成的。YOLOv4使用CSPBlock取代了以往常用的ResBlock[18]。因为CSPBlock会分开梯度流,使其在不同的网络路径上传播,而这种形式传播的梯度流会有较大的相关性差异[16],使其比ResBlock具有更强的学习能力。
假设以416×416×3的图片作为网络输入,YOLOv4-tiny的网络结构如图2所示。
1.3 数据增强算法设计
图3为一次数据增强的效果展示,图3(b)为打破原图纵横比并进行随机扭曲;图3(c)为进行随机程度的缩小,并且为保证缩小后所有图片的尺寸均为416×416,不足的部分用黑色填充;图3(d)为按50%的概率翻转图像;图3(e)为按50%的概率进行高斯模糊处理;图3(f)在HSV(Hue,色调;Saturation,饱和度;Value,明度)颜色空间中进行随机程度的色域扭曲。

Input为模型输入;DarknetConv2D_BN_Leaky为Darknet53[17]卷积+批正则化+Leaky激活函数;CSPBlock_MaxPool为CSPNet[16]结构块+最大池化;Concat为特征融合;Conv为普通卷积;UpSampling为上采样;Conv2D为普通二维卷积;Base layer为基础层;Part 1为分支1;Part 2为分支2; Res(X)Block为残差结构;wo为without的简写,表示没有Bottleneck的Res(X) Block;Bottleneck为瓶颈层;Partial Transition为部分梯度融合图2 YOLOv4-tiny网络结构图Fig.2 YOLOv4-tiny network structure diagram

图3 数据增强示例图Fig.3 Example data enhancement diagram
由于设计的数据增强策略具有较高的随机性,所以对样本进行了大量扩充。
1.4 迁移学习的设计实现
迁移学习就是使用已训练好的模型(简称预训练模型)与新数据集来训练新模型。经过论证,大部分数据或任务是存在相关性的,通过迁移学习可以加快并优化新模型的学习效率[19]。
预训练模型使用MS COCO公共数据集[20]训练,在训练保护压板数据时,冻结预训练模型的前29层卷积层,只训练剩余的卷积层和全连接层,以此达到微调(fine-tune)的目的。
2 ncnn框架的部署与可靠性提升
2.1 ncnn前向推理框架
ncnn 是一个为移动端极致优化的高性能神经网络前向计算框架,其具有非常完备的使用文档,按照步骤就能完成ncnn库的构建。
ncnn针对移动端部署做了大量的优化,如没有使用batch批处理,因为移动端的推理场景并不需要;在通道channel上实现了数据对齐,有助于提高性能;自定义ncnn::Mat取代OpenCV的cv::Mat,剔除了移动端不需要的冗余代码。
因为ncnn框架是纯C++实现的,而移动端的手机软件(application,APP)使用Java开发,所以需要使用JNI(Java native interface,Java本地接口)技术,以Native的方式,将ncnn模型移植到APP中,并编写CMakeLists.txt文件,编译生成.so动态库,建立Java与C++的联系。
2.2 漏检补全模块设计
漏检补全功能的整个实现流程如图4所示,其核心思想是:将模型返回的一维无序边界框数组Box转换成二维有序数组Platens,使Platens与屏柜中的压板阵列在位置上一一对应。再通过比较边界

(xa, ya)、(xs, ys)分别为每行行首的平均起始坐标、每行行首坐标的和;r为当前的行数;c为当前的列数;Platens.length为总行数;Platens[r].length为第r行的总列数;为第r行的第一个框的左上角x坐标;为第r行的第c个框的左上角x坐标;分别为发生漏检位置的前一个边界框的左上角和右下角坐标;x为当前补全位置的,前一个位置边界框的右下角x轴坐标;j 为当前补全的位置图4 漏检功能流程图Fig.4 Leak detection function flow chart
框之间的间隔距离与边界框的平均宽度,判断漏检的压板个数,最后根据平均宽度和高度构建补全框并插入到二维数组中。
ncnn模型返回的预测结果是一个无序的边界框数组Box,数组中的每个矩形边界框由4个元素组成:左上角坐标(xu,yu)、右下角坐标(xb,yb)、预测类别和置信度。
在初始化时,根据yu进行冒泡排序使同一行的边界框挨在一起,并在排序时统计边界框的总数sumB、总高度sumH、总宽度sumW、总间隔sumG,排序完成后,就可以得到边界框的平均高度avgH,平均宽度avgW,平均间隔avgG。经过排序,虽然同一行的数据挨在了一起,但是仍无法确定每行的边界位置,简称“换行的位置”。于是,使用front记录每一行的行首位置,i为当前位置,row为当前行数,(xs,ys)记录每行行首坐标的和。
要构建二维数组,关键是判断换行的位置。判断标准是相邻边界框的坐标差,如图4所示。找到每行的边界点之后,更新相应的变量值,然后对行内数据进行排序,再插入到二维数组中。
二维数组构建完成后,要判断每行的补全个数。如图4所示,从每行的行首startRow、行内inRow和行尾endRow三个位置分别判断补全个数。
补全时,无论是行首、行内还是行尾,边界框的生成逻辑都是相同的,所以统一假定为需要补全t个边界框。
使用Photoshop对压板图片进行处理,复现了模型的漏检现象,如图5所示。

蓝色框是漏检补全后的效果;红色框是误检框图5 漏检与误检示例图Fig.5 Example diagram of missed detection and false detection
2.3 误检更正模块设计
因为模型自己并不能判断自己是否误检,所以需要将预测结果与压板基准进行对比,当两者不一致时,判定为误检。
因为目前模型精度较高,误检复现难度较大,所以只能对基准文件做出“错误”的更改,以达到相同的误检效果,如图5所示。
更正时,只要用户在屏幕上点击边界框内的位置,APP就会弹出提示对话框,以供用户变更压板状态。而实现这样的功能需要进行坐标转换,判断屏幕点击位置在图片中的位置。
在Android中坐标转换是通过矩阵运算实现的。

(4)
式(4)中:左侧的3×3矩阵为Android中的图片变换矩阵;MSCALE用于图片缩放;MTRANS用于控制图片平移;MSKEW用于控制图片进行错切变换;MPERSP用于控制图片进行透视变换,该矩阵可以通过调用getImageMatrix()方法获取;(xp,yp)为图片的实际坐标;(xs,ys)为屏幕的显示坐标,而“1”代表图片在z轴上不发生变换,即代表这是一次二维坐标转换。
当所有边界框更正完毕后,红色和蓝色就都被“消灭”了,使用这种颜色区分的方式,可以很大程度上缓解视觉疲劳。
3 实验结果与分析
3.1 数据集制作
首先,以尽可能复现工作环境为原则,在不同角度、光照条件下采集压板图片。然后,对采集的图片使用1.3节的方法进行数据增强。最终,共获得4 860张图片作为数据集,并按9∶1的比例划分为训练集和验证集。
3.2 模型训练
使用搭载NVIDIA RTX 2080 SUPER显卡的工作站作为训练设备;使用基于MS COCO数据集的预训练模型;使用表1所示的超参数配置。
如表1所示,输入网络的图片尺寸为416×416,初始学习率为0.002 61,总迭代次数为150 000,分别在第120 000次与135 000次迭代时,将学习率降低1/10。训练过程中模型的平均损失(avg Loss)与mAP曲线如图6所示。

表1 超参数配置表Table 1 Super parameter configuration table

mAP为 均值平均精度;Loss 为损失;Iteration number 为迭代次数图6 avg Loss与mAP曲线图Fig.6 avg Loss and mAP graph
表2是模型的训练结果,其展示了目标检测中常用的4个评价指标。
3.3 模型测试与对比
表3将本文模型与文献[9]使用的SSD目标检测模型以及文献[10]使用的改进的SSD算法模型进行了详细对比。而文献[11]使用的YOLOv3目标检测模型,其只给出模型识别率为98.95%,并没有给出识别率的定义与计算方法,也没有给出其他指标,因此,表3对比了本文训练过的YOLOv3模型。
分别使用华为Mate40 Pro、三星Note9与小米10进行了实测,其中Mate40 Pro的表现最好,图7为其测试结果。测试图片是从验证集中随机抽取的50张图片,并对比了OpenCV和ncnn两种深度学习模型在移动端的移植方式,使用OpenCV的Dnn模块进行移植是以往常用的方法。从图7中可以清晰地看出,在保持较高准确率的同时,ncnn的速度远快于OpenCV。ncnn对每张图的平均预测时间约33.28 ms,等价于30 FPS;而OpenCV约289.06 ms,等价于3 FPS。并且ncnn的数据分布更集中,表示其预测速度更稳定。

表2 训练结果展示表Table 2 Training results display table
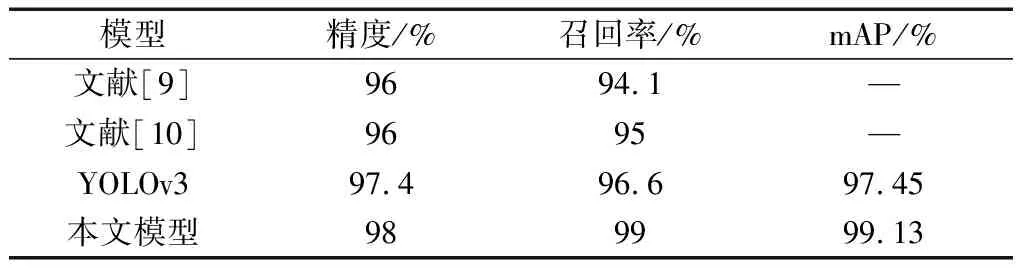
表3 模型性能对比表Table 3 Model performance comparison table

图7 模型实测表现图Fig.7 Model performance diagram
3.4 校核模块设计
模拟方法与2.2节和2.3节同理:在第1行第4列的压板处发生漏检现象;第1行第5列的压板处发生误检现象。
初始状态,即用户第一次看到的状态,如图8(a)所示。当用户点击蓝色框或红色框的位置时,APP将弹出提示对话框,如图8(b)所示。提示对话框将显示当前点击位置以及该位置压板的投退状态,并提供更改选项。当用户选择的变更状态与当前状态不一致时,边界框将重绘,如图8(c)所示,更正后两处边界框的形状与颜色均发生改变。
当所有边界框的颜色都是绿色时,代表当前屏柜的校核工作就完成了,用户保存操作结果后,就可以前往下一个屏柜了。

图8 校核功能示例图Fig.8 Example diagram of calibration function
4 结语
以提高继电保护巡检工作的效率为出发点,提出了一种新的智能实时校核方法。设计使用数据增强与迁移学习方法,提高YOLOv4-tiny目标检测模型的泛化性;借助ncnn前向推理框架,对模型的移动端部署做出针对性优化;发现并解决模型在移动端的漏检与误检问题;最终实现移动端的保护压板实时校核。
在之后的工作中,会使用APP采集的图片不断扩充数据集,并且会根据用户对APP的使用反馈,不断优化APP的性能,以提升用户体验。
