Sketch统计方法研究
2022-02-18乔冠杰吕高锋莫露莎
乔冠杰,吕高锋,王 宏,谭 靖,莫露莎
(国防科技大学 计算机学院,长沙 410073)
1 引 言
随着网络的发展,流量规模的不断增大,大规模流量统计变得越来越重要,早期的网络管理功能如流量统计,是固化在相应的网络设备中的,基于端口对交换机或路由器链接不同网络的流量进行统计.随着网络的发展,这种方式已经不能满足网络管理的需求.
网络可视化应运而生,能够实现对网络的实时监控.网络就像公路,需要实时掌握主干道信息,了解每条路是否堵塞,了解车流密度等等.车辆就相当于网络中的流量,只有实时掌握道路信息,才能更好的调度交通,保证道路畅通.网络也是一样,只有实时去监测流量,才能了解网络状态,进行流量调度、拥塞控制[1-4]、异常检测[5-8]等等.
为了应对大规模流量统计[9,10],各种统计结构应运而生,一种典型的网络统计结构是Sketch.Sketch是一种基于哈希的紧凑的数据结构,通过哈希来减少流量统计的存储空间,将在第2节Sketch背景中进行介绍.Top-k流[11,12]统计是Sketch统计中的热点问题,通过对Top-k流的研究,可以对流量特征进行分析,进而可以研究重击者[13,14]、DDOS攻击[15]等问题,将在第3节基于Sketch的Top-k流比较中进行介绍.第4节介绍了Sketch的应用,结合具体场景对Sketch的实现方法做了介绍.第5节展望了Sketch统计方法未来的研究方向.第6节对全文进行总结.
2 Sketch背景
2.1 Sketch产生背景及原理
在网络统计中,网络流主要依据五元组进行分类,每流检测为每个网络流分配一个计数器,保证了统计的准确性,与此同时带来的问题是存储的空间复杂度较高.抽样通过选取部分报文来推断网络流量总体性能参数,减少了统计的数据量,但随之而来的是统计精度的下降.
在实际的网络测量中,有的测量任务不需要精度要求不高,有的测量任务却需要精确的测量结果.基于计数器的测量方法与基于抽样的测量方法都存在明显的弊端,因此需要一种精度与存储折中的方法,并且可以通过参数设置达到理想的效果.为了权衡统计精度和存储空间,产生了基于Sketch的网络流量桶方法,通过哈希的方法将较大的数据映射到较小的存储空间中,Sketch将具有相同哈希值的流映射到相同的桶中,在提高统计精度的同时也减少了存储空间的占用.
Sketch是基于哈希的亚线性数据结构,常用于流量数据统计,通过不同的哈希函数,将有相同哈希结果的值存入相同的桶内,无需存储全部的网络流,从而减少存储开销,通过查询操作可以获得流量统计数据.
2.2 典型的Sketch结构Countmin Sketch
Cormode G等人提出了Countmin Sketch[16],Countmin Sketch是一个有r行l列的二维数组,通过r个不同的哈希函数,将同一元素哈希到r行的不同位置,对应位置的计数器计数值+1.当需要查询某元素出现的次数时,只需要返回r行r个位置最小的计数值,作为元素出现的次数.使用多个计数器来存储元素频率,大大降低了哈希冲突带来的统计元素频率偏大的问题.Countmin Sketch结构如图1所示.

图1 Countmin Sketch结构Fig.1 Countmin Sketch structure
Countmin Sketch在估计元素频率时估计值偏大,对于频率较低的元素,将会产生较大的误差.随着哈希函数数量的增加,哈希计算带来的冲突减少,统计精度提高,同时哈希计算开销增大,因此需要权衡统计精度,设置合理的哈希函数数量.
2.3 评价标准
对于不同的Sketch,主要从内存占用,计算开销,统计精度3个方面进行评价.内存占用和自身结构有关;计算开销主要是冷流热流频繁替换造成的,因此在下一节将会分析冷热流频繁替换问题;精度主要针对热流精度进行分析.
3 基于Sketch的Top-k流的比较
由于网络中流量分布不均衡,大多数流流量很小[17],称为冷流;少部分流流量很大[18,19],称为热流.然而正是数量较少的热流对网络产生较大的影响.数量最大的k条流称为Top-k流,Top-k流统计在网络统计中起着重要作用,许多网络统计问题都要基于Top-k流的统计结果.如何能提高Top-k流流量统计精度,如何在未知热流大小的情况下分配计数器大小,以及如何减少和避免热流冷流的替换的产生的开销,在接下来的研究中,将针对上述问题进行分析和讨论,讨论现有Sketch结构在统计Top-k流时的优势和不足.
根据结构将Sketch算法分为以下3类:基本Sketch,面向热流的高精度统计Sketch,冷热流自适应的精确统计Sketch.基本框架如图2所示.

图2 基于Sketch的Top-k流统计的基本框架Fig.2 Basic framework of Top-k flow statistics based on Sketch
3.1 基本Sketch
本节Sketch采用Countmin Sketch的基本思想,其最大特点就是只需要一个二维数组表可以实现热流统计,不需要额外维护数据结构.在Countmin Sketch结构基础上,每个桶多记录了最热流的流键,实现了对热流的统计,CountMax、MV-Sketch、HeavyKeeper设计思路及特点如表1所示.

表1 基本SketchTable 1 Basic Sketch
3.1.1 CountMax
Xiwen Yu等人提出了CountMax[20],一种轻量、精确、快速、低开销的并且可以记录Top-k流的Sketch.相比于Filtered Space-Saving和CountSketch,CountMax减少了计算开销同时保证了精度.
CountMax类似于Countmin Sketch,维护一个二维数组.对于每次更新,如果与桶内的流是不同的流,将桶内计数器的计数变成桶内size和当前size的差值,size-size′;如果与桶内的流是相同的流,将桶内计数器的计数变成桶内size和当前size的和,size+size′.通过k个并列的哈希函数来提高统计精度,查询时,查询每一行存储该流的计数器,找到最大值,作为估计值.
3.1.2 MV-Sketch
MV-Sketch[21]是一种高效可逆的Sketch,使用较小的存储空间即可实现热流检测,主要实现了热流的更新和查询.MV-Sketch主要利用MJTRY算法,借鉴了Countmin Sketch的思想,由r行组成,每一行有w个桶,每个桶中记录了3个不同的元素,Vi,j、Ki,j、Ci,j.分别表示哈希到这个桶中总的流量,当前桶内记录的重流,和当前桶内重流的计数值,用来判断此流是否被保留为重流.通过r个相互独立的哈希函数,将数据包映射到r行的不同位置,然后根据MJTRY算法更新桶内的三个元素.查询时,根据新流和桶内重流候选是否相同来确定估计值,返回所有行中的最小值,通过最小值和阈值比较来判断是否是重流.
3.1.3 HeavyKeeper
HeavyKeeper[22]是一种典型的识别Top-k流的结构,基本思想是只统计数目较大的流,提出了指数衰减策略,每个桶包括指纹域和计数域,指纹域保存由特定哈希函数产生的哈希值,冲突概率比较小,计数域保存这条流的数目.为了减少冲突,使用d个独立的哈希函数,映射到d个数组的不同位置.
当一条流到达时,计算d个哈希函数确定d个位置,每个位置的操作相同.如果映射位置桶为空,将流插入;如果流与指纹域相匹配,增加计数;若不同,利用指数衰减策略减少计数域计数,直到计数域计数为0发生替换.
3.2 面向热流的高精度统计Sketch
在典型的Sketch结构中,很多是用来对Top-k流问题进行研究的,如典型的Count Sketch、Augmented Sketch、Elastic Sketch、MV-Sketch基本思想都是维护一个额外的数据结构来维护Top-k流,涉及到一个问题便是替换策略.不同的数据结构和不同的替换策略会产生不同的计算开销和存储开销,也会影响到Top-k流的统计精度,因此本文对基于Sketch的Top-k流统计结构进行对比,并分析这些结构的替换策略.以便之后对基于Sketch的Top-k流统计方法进行研究,以及设计更合理的替换策略.CountSketch、Space-Saving、Elastic Sketch、Augmented Sketch、HeavyGuardian设计思路及特点如表2所示.

表2 面向热流的高精度统计SketchTable 2 High-precision statistical Sketch for hot flow
3.2.1 CountSketch
CountSketch[23]包含一个位图和一个堆结构以及两组哈希函数.其中,一组哈希函数将不同的流映射到对应行的不同位置,另一组哈希函数决定了对应位置计数器的增减.它将流哈希成1或-1,然后乘上对应的流计数,增加到对应计数器中.在查询一条流时,查询每一行,返回这条流计数的中间值.
CountSketch维护了一个堆结构来跟踪Top-k流,当一条流到达时,检查流是否在堆里.如果在堆结构中,增加堆中的计数;如果不在堆结构中,在位图中估计这条流的计数值,如果估计值大于堆中流计数的最小值,则这条流替换掉堆中的流.CountSketch估计的精度较低,并且跟踪Top-k流的堆结构造成了额外的更新开销和替换开销,计算开销主要取决于堆的结构,如果堆结构比较复杂,将会产生较大的计算开销.优势是维护了Top-k流.
CountSketch的替换策略是一旦有流的计数大于堆里最冷流的计数,便会发生替换,是否会发生频繁替换取决于堆的大小,如果堆比较大,不会发生频繁替换但是比较时间会增加.
3.2.2 Filtered Space-Saving
Filtered Space-Saving[24]是基于计数器的算法,维护了单行的位图来粗略的估计流量,并使用哈希表准确计数选中的流.其中一种哈希表的实现形式是哈希堆的方式.位图中每个槽含两个字段,一个计数器和一个指示器.计数器记录流量统计信息,指示器表示有多少哈希到该槽的流被记录到哈希堆中.
当一个包到达,Filtered Space-Saving首先将流键哈希到位图中的一个槽里,检查指示器,如果值大于0,Filtered Space-Saving在哈希堆里查找流键,如果流键存在,增加哈希堆中计数器的计数值;否则,增加位图中相应槽的计数器的计数值.如果槽中计数器计数值大于哈希堆中计数器最小值,这条流被插入到哈希堆中,并且指示器的值+1,如果哈希堆满了,哈希堆中最小的流将被移除,Filtered Space-Saving哈希流到一个槽,并且将计数器计数值复制到槽中的计数器,并且计数器的指示器值-1.
当一个流键存在于哈希堆中或者位图中的计数器没有超过哈希堆中的最小值时,Filtered Space-Saving更新操作的时间复杂度O(1),否则时间复杂度O(logk).
3.2.3 Elastic Sketch
Elastic Sketch[25]利用重部和轻部将热流和冷流分离,重部实现热流的精确统计,轻部实现冷流的粗略统计,重部存储着热流的流键,正投票,标志位和负投票,轻部采用Countmin Sketch.如果来的一条流与重部中存储的流相同,增加正投票,如果来的一条流与重部中存储的流不同,增加负投票,当负投票与正投票比值超多一个常数时,则会发生替换,将重部中的流映射到轻部Countmin Sketch中,并增加对应计数.标志位用于记录重部这个位置是否发生过替换,在查询流大小时,根据标志位返回重部的计数,轻部的计数或者重部与轻部的计数和.
3.2.4 Augmented Sketch
Augmented Sketch[26]将热流分离出来用过滤器进行聚合,提高了统计的吞吐量,提高了热流的统计精度,同时降低了冷流的统计错误率.Augmented Sketch包括过滤器和Sketch两部分组成,过滤器包括两个计数器new_count和old_count,其中new_count保存对数据项的过高估计,old_count记录流从Countmin Sketch中取出时的计数,new_count和old_count的计数差值表示在某段时间内该流的累计值.Sketch采取Countmin Sketch.
当一条流到达时,将键值与过滤器中键值比较,若流存在于过滤器中,则增加过滤器中流的new_count,若过滤器没满,将流插入到过滤器中;若过滤器满了,将流计数增加到Countmin Sketch中;若流在Countmin Sketch中的估值大于过滤器中另一条流的new_count,则发生替换,将new_count-old_count值作为这条流的增加值加入到对应Sketch中.关于Augmented Sketch的替换策略,因为过滤器较小,会发生频繁的替换,所以可以增加过滤器的大小来减少频繁替换的发生.
3.2.5 HeavyGuardian
HeavyGuardian[27]用于解决内存使用率较低和热流信息未被很好记录的问题,HeavyGuardian维护着n个桶,每个桶包含重部和轻部,重部存储国王单元和守卫单元,用于存储映射到这个桶中的热流,其中国王单元存储这个桶中最大的流,国王单元和守卫单元都存储着流ID和计数.轻部有多个计数器组成,将流通过哈希函数映射到一个计数器中.当一条流到达时,通过哈希函数将流映射到一个桶中,首先在重部中进行比较,如果流在重部中,增加相应计数;否则采用指数衰减策略减少最弱保卫的计数,如果最弱保卫计数减少到0,发生替换;否则这条流被映射到轻部.
面向热流的高精度统计Sketch由于存在替换策略,导致了冷热流的频繁替换,针对这个问题,在替换策略设计的时候,应该考虑以下原则:增大热流存储空间,减少热流碰撞发生;解决冷流被误判为热流的情况,防止冷流进入热流结构;提高发生替换的阈值,超过一定值再发生替换.采用以上设计原则可以减少频繁替换的发生.
3.3 冷热流自适应的精确统计Sketch
典型的Sketch结构不能很好的适应偏斜的流,这类流往往冷流数目比较多,但每个冷流的流量比较小,与此同时每条热流的流量比较大.典型的Sketch为每个计数器分配固定的内存大小,在一定的内存下,如果为每个计数器分配的内存较小,Sketch有更多的计数器,使得冷流的统计比较精确,但是热流会溢出;如果为每个计数器分配的内存较大,Sketch包含的计数器数目大幅度下降,由于哈希冲突冷流的统计精度下降严重.并且在一个流量统计任务中很难确定最热流的数目,因此关键问题是如何确定计数器大小以适应偏斜的流,既能保证热流在统计的时候不会溢出,又能保证冷流精度,实现较高精度和较快速度的更新和查询.Cold Filter、Pyramid Sketch设计思路及特点如表3所示.

表3 冷热流自适应的精确统计SketchTable 3 Accurate statistical Sketch for adaptive cold and hot flow
3.3.1 Cold filter
Cold filter[28]分为两层,L1层用来存储冷流,L2层用来存储热流,L1层计数器数量多,每个计数器的大小较小,使得冷流的哈希冲突减少;L2层计数器数量较少,每个计数器大小较大,使得热流不会溢出.这提高了数据流的存储效率,同时提高了热流和冷流的存储精度.
Cold filter更新时通过多个哈希函数h将流映射到L1层,只更新对应位置的最小值,如果最小值超过L1层计数范围,则通过多个哈希函数g将流映射到L2层,更新L2层对应位置的最小值.查询时首先在L1层查询,如果超过L1层计数范围,在L2层查询.
Cold filter不像大多数的结构只关注热流,Cold filter在L1层捕获冷流,在L2层捕获热流,此外,现有结构需要双向通信,在两个阶段频繁交换,Cold filter是单向的,不会出现频繁交换的问题.
3.3.2 Pyramid Sketch
Pyramid Sketch[29]主要用于解决偏斜流的统计问题,存在的Sketch结构在存储流的时候对不同大小的流采用相同大小的计数器去存储,造成冷流所在计数器存储空间的浪费,热流所在的计数器会溢出,在统计之前不能预估热流大小的情况下很难分配计数器大小,因此现有的存储结构不能很好处理偏斜流.
Pyramid Sketch提出了一种类似金字塔的结构,Pyramid Sketch一共λ层,高一层计数器数量是低一层计数器数量的一半,每个计数器包含 δ 位,高层每个计数器对应着低层两个计数器,分别为左子计数器和右子计数器.最低层计数器都是pure计数器,只用来计数频率.高层计数器为hybrid计数器,含有两个标志位(左标志和右标志,各占1bit),有效计数位数为 δ-2位.当低一层计数溢出时,便会像高一层进位,类似十位和个位的关系.高层计数1代表低层满计数.当查询时,每层计数器计数乘上与最低层的进制然后相加得到最终计数.
冷热流自适应的精确统计Sketch相比于其他Sketch提高了空间利用率,在相同的存储空间下,提高了冷流统计的精度,解决了热流冷流频繁替换的问题,同时解决了热流溢出的问题.但是会由于哈希冲突导致热流精度下降,会出现统计值比实际值高很多的问题.
4 Sketch面向场景的实现方法
本节将介绍Sketch针对特定场景设计的框架,将控制平面和数据平面解耦,根据不同的流量统计任务,可以选取合适的Sketch进行统计,实现高精度、低开销的统计,可以应用于特定网络.
4.1 开放式统计框架OpenSketch
Minlan Yu等人提出的OpenSketch[30],OpenSketch是一个通用的统计框架,将控制平面与数据平面解耦,数据平面运用3层流水线,第1层通过哈希运算大大较少统计数据数据量,第2层通过通配符匹配规则实现流量分类,第3层根据不同统计精度的需求,每个流分配一个或多个计数器,实现流量的计数.控制平面根据任务需求动态选取不同的Sketch算法,根据精度要求和可用资源进行资源分配,从而实现高精度的统计.OpenSketch控制平面和数据平面的解耦与SDN架构相契合,可以实现高精度、低开销、细粒度的流量统计,被广泛用于数据中心网络的标准化制定.
OpenSketch需要网络交换机的硬件支持,硬件上实现难度较高,为了减少硬件部署的复杂度,只能减少哈希函数的数量.OpenSketch结构图如图3所示.

图3 OpenSketch结构Fig.3 OpenSketch structure
4.2 高吞量统计框架SketchVisor
Qun Huang等人提出SketchVisor[31],SketchVisor是一种基于纯软件包转发的网络统计框架,这种统计框架具有较高的精度和性能,自动实现负载均衡,同时这种统计框架适用于多种Sketch算法.SketchVisor将数据平面与控制平面解耦,数据平面包含正常路径和快速路径,正常情况下,流量通过正常路径;当流量过载时,过载流量被分配到快速路径,以保持较高的精度和性能.在控制平面,设计了压缩感知算法,对分布的交换机的数据进行汇总,恢复了整个网络的流量数据.SketchVisor控制平面和数据平面结构图如图4、图5所示.

图4 SketchVisor控制平面Fig.4 SketchVisor control plane

图5 SketchVisor数据平面Fig.5 SketchVisor data plane
4.3 通用统计框架UnivMon
Zaoxing Liu等人提出UnivMon[32],利用通用数据结构Universal Sketch构成测量框架.UnivMon将控制平面与数据平面分离,数据平面完成数据和信息的收集,控制平面完成资源配置与测量任务.
UnivMon将全部交换机抽象为一个大型交换机,可以对全网络进行监视.将数据流方法和抽样方法相结合,通过并行流水线的方式处理流数据.将多个Sketch的数据进行叠加,来完成不同的测量任务.每级采样的Sketch的统计值被发送到控制平面,控制平面的算法根据收集的数据完成测量任务的计算.UnivMon的结构图如图6所示.
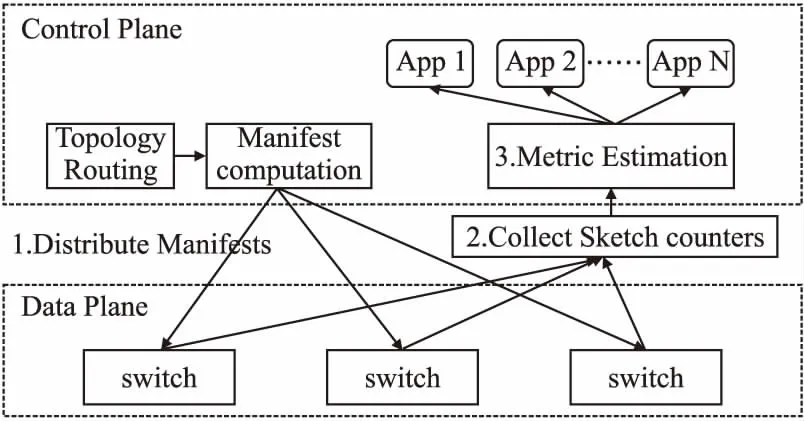
图6 UnivMon结构Fig.6 UnivMon structure
5 Sketch算法未来研究方向
随着网络技术进步,网络越来越复杂,流量规模也随之增大,给流量统计带来了新的挑战,研究人员致力于提出更高效更精确的流量统计算法.Sketch下一步的研究方向主要有以下几个方面.
1)能够根据流量特征,自适应调整计数器大小.现有结构通常采用固定大小的计数器,不同的网络通常流量特征不同,如果对所有网络应用同样的测量结构,冷流将会浪费计数器的存储空间,同时热流将会溢出,影响统计的精度.并且随着网络的发展,网络处理器部署的应用和任务越来越多,由于网络处理器资源有限,需要设计内存占用少的Sketch结构,才能在网络处理器上部署更多的应用.因此研究可以根据流量特征,实时改变计数器大小的算法可以在保证统计精度的前提下减少存储空间的使用,这样更加利于Sketch算法的部署.
2)内存与精度之间的权衡,众所周知,Sketch使用大的内存可以提升统计的精度,但是随着内存空间的增大,精度提升的效果越来越小.在之后的设计中,应当权衡内存和精度,在保证较高的统计精度的同时减少内存空间的使用,达到最高的收益.
3)采用软硬件结合的思想优化原有算法.在软件设计中,有很多重复的指令,如果将这些高频率使用的指令用硬件实现,将会大大节省处理时间,提高效率.设计节省内存空间的Sketch算法,再将算法映射到FPGA硬件平台上,可以实现高性能并且空间利用率高的流量统计算法.由于Sketch算法中都存在着大量的哈希运算,可以考虑将哈希计算交给硬件处理.当网卡接收到数据包时,提取五元组并进行哈希计算,同时将哈希计算结果送给CPU进行处理,预哈希的方式可以进一步提升Sketch算法的吞吐量.
4)优化冷热流替换策略.在冷热流分离的精确流量统计结构中,由于在流量统计时统计结构中两条流流量大小接近,一条流被精确统计,另一条流被粗略统计.由于两条流的报文交替到达,如果不设置合理的替换策略,这两条流的存储位置会发生频繁的交换.冷热流替换问题造成了很大的开销,因此,必须提出合理的替换策略避免冷热流频繁替换现象的发生.
5)研究通用的统计框架.单纯的Sketch算法通常针对特定场景,是根据某个特定的问题提出的相应结构和算法.虽然对特定问题效果较好,但是通用性较差,导致无法实际应用.框架应当综合上面提到的研究目标,能够适应流量的变化,自动调节计数器大小;能够在保证精度的同时,尽可能减少内存开销;能够软硬件结合,充分发挥各自的优势.随着网络的发展以及复杂化,提出更加通用的流量测量框架才能更好适应网络的发展.
6 结束语
本文针对基于Sketch的流量统计问题进行研究,着重对比分析了基于Sketch的Top-k流的研究方法,在面向热流的高精度统计Sketch中讨论的冷热流的频繁替换问题;在冷热流自适应的精确统计Sketch中讨论了偏斜流的统计方法.本文还介绍了Sketch面向场景的实现方法,最后提出了Sketch算法未来的研究方向.
随着网络的发展和互联网带宽的快速增长,Sketch算法发展趋势是拥有更高的吞吐量、更低的内存消耗和更高的统计精度,以及朝着更通用的方向发展.
