基于卷积神经网络的交通标志ROI 提取与识别
2022-02-17张博
张博
(华南理工大学机械与汽车工程学院,广东广州 510640)
交通标志识别是智能辅助驾驶的重要组成部分,对无人驾驶领域的发展有直接的推动作用。近年来,城乡公路建设迅速,复杂自然场景对交通标志识别的稳定性提出了新的挑战。目前对交通标志的识别方法主要有模板匹配、机器学习以及卷积神经网络等[1]。从现有研究来看,基于卷积神经网络的分类方法在预测准确率、泛化性以及实时性方面相比于其他方法更高,并在交通标志识别方面成功应用。Natarajan 等人[2]改进CNN的参数,利用加权组合的4 个并行CNN 网络训练模型,精度超过99.59%,但结构复杂;Shao[3]、Cao[4]等在传统CNN的基础上,利用Gabor 过滤器替代初始卷积核,并结合批量归一化方法,提高了交通标志识别率,但识别速度有待提升。这些传统方法受到的干扰因素多,虽然数据集庞大但在某些特定场合仍存在不足。为减少无关干扰因素,通过去除背景使得模型在复杂环境中聚焦于交通标志的感兴趣区域是一种较好的处理思路。而全卷积网络(Fully Convolution Network,FCN)的语义分割网络[5]为背景的快速去除提供了很好的解决方法。Noh 等人[6]提出对称语义分割模型DeconvNet,该模型在VGG16[7]的基础上将SoftMax 层移除,相应地加入对称的上池化和反卷积模块,然而该模型由于参数量太大而计算效率不高。Ronneberger 等人[8]提出UNet 对称语义分割模型,该模型在各种医学图像以及自然图像综合表现效果较好,因此有较广泛的实际应用。
当前针对交通标志感兴趣区域切割与识别的相关研究较少,文献[9]提出了一种K-means 形状匹配并使用对应形状的切割模板获取ROI的方法,该方法计算量太大并且不能有效解决不同位置和旋转角度的问题。文中通过融合UNet 语义分割的优良性能与LeNet5 较好的分类能力提出一种对交通标志进行感兴趣区域提取与分类的新方法,该方法在感兴趣区域切割上相比传统方法有两处显著改进,其一是使用了神经网络方法获取交通标志感兴趣区域,通过其强大的表征能力将交通标志与背景快速而准确分离,从而为简单CNN 网络结构LeNet5的稳定分类奠定了条件;其二是传统方法均作用于灰度图像并由纹理特征实现ROI 切割,而该文则是作用于彩色图像,同时考虑颜色与纹理特征对交通图像进行ROI 切割,为语义分割网络提供更多的特征,从而保证感兴趣区域分割的准确性。
1 基于UNet-LeNet5的识别框架
传统机器学习一般基于颜色、形状、纹理等特征对交通标志进行识别研究,这些方法计算量大并且适应性差,无法满足复杂自然场景下交通标志的识别需求。但直接对这些感兴趣特征进行学习的思想对现在的研究仍有很强的借鉴意义,利用深度学习方法能够充分挖掘复杂图像数据的多重属性[10],通过将大量无关特征进行过滤,从而降低图像中复杂信息对分类的干扰,提升交通标志识别算法的分类性能。为充分利用深度学习方法强大的特征提取能力,文中根据交通标志的颜色、形状特征设计出一种对交通标志进行感兴趣区域提取与分类一体的UNet-LeNet5 模型,总体结构包括图像预处理、基于改进语义分割网络UNet 感兴趣区域获取(简称ROI获取)、分类识别3 个部分,其识别流程如图1 所示。

图1 交通标志识别流程
1.1 图像预处理
对于自然场景的交通标志图像,其光照条件以及雾气等因素对图像明暗和清晰度影响较大,而这个问题可以通过直方图均衡化进行对比度调整得到有效解决。文献[11]使用了3 种不同直方图均衡化处理方式对交通标志的灰度图像进行预处理,实验对比分析得出,对比度有限直方图均衡方法在交通标志预处理方面表现较好。而语义分割一般针对RGB 彩色图像,使用对比度有限直方图均衡进行图像预处理时,通过将图像的RGB 空间转换为YUV 或LAB 空间进行对比度调整后,转回RGB 空间时会出现色彩暗淡的现象。因此对于RGB 彩色图像,在该方法基础上还需要进一步调整对比度,具体操作是对图像的R、G、B 3 个通道分别进行灰度拉伸及去雾气处理,灰度拉伸公式见公式(1)。

在式(1)中,F(x,y)表示单个通道上的某像素点灰度拉伸处理后对应的亮度值,f(x,y)表示该点原来的亮度值,MAXf(x,y)和MINf(x,y)值由图像的规模以及给定的暗色素和亮色素个数的最小比例确定。其中,单个通道灰度拉伸去雾气的具体实现过程为:通过直方图统计求出MAXf(x,y)和MINf(x,y),并分别用MI和MA代替,当MI小于或等于MA时通过式(1)进行灰度拉伸。
从图2 可以看出,通过对比度有限直方图均衡化对原图像进行粗调后,利用去雾气算法进一步微调效果十分明显,相比于直接使用直方图均衡方法有更好的实际表现。

图2 预处理效果对比
1.2 基于改进UNet感兴趣区域提取
UNet 是一种基于编码器与解码器的对称语义分割网络结构,编码器通过不同层次的下采样操作从而学习到深层次的特征,解码器则是不断通过上采样并与低层特征融合,从而恢复原图大小,最后输出对感兴趣区域位置预测的二值mask 图像。而UNet 主要针对尺寸较大的医疗图像二分类语义分割问题,在几何形状差异较大的交通标志的语义分割上,其网络预测精度难以保证。为将UNet 应用于尺寸较小、形状复杂的交通标志图像的语义分割并提高模型的预测精度,对其进行一些结构改进与参数调整十分必要。
1.2.1 网络具体改进
改进方法是将最后一层1×1 卷积的输出通道数由1 到多调整(文中为1 到3),从而实现多分类,将二分类向多分类扩展的本质即是对每一种形状进行聚类,通过对不同几何形状交通标志进行分类处理有利于提高算法的稳定性。实验过程中主要针对圆形、三角形标志,具体操作中将背景看作类别0,圆形标志看作类别1,三角形标志看作类别2。由于分类方法发生了改变,因此还需将原来的二分类交叉熵损失函数相应替换为多分类交叉熵损失函数,见公式(2)。
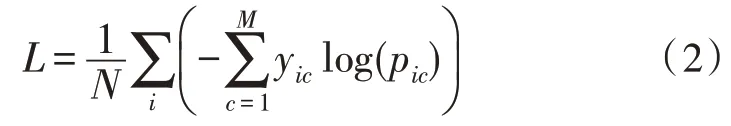
其中,N表示像素点的总个数,M表示类别的数量,yic表示指示变量,当实际类别与像素点i对应的类别相同时为1,不同时为0,pic表示像素点i属于类别c的概率。改进UNet网络结构如图3 所示。

图3 改进UNet网络结构
图3 中,不同方块是进行相应操作后生成的特征图。除最后的一个1×1 卷积外,中间的每层卷积均进行了批归一化处理并使用了relu 激活函数。对于通过1×1 卷积生成的3 张二值图像mask,序号0 对应背景的类别,其位置上mask的白色区域是对背景区域位置的预测结果;序号1 对应圆形标志的类别,其位置上mask的白色区域是对圆形区域位置的预测结果(由于图3 输入的示例图像为三角形标志,因此序号1 上对圆形区域的预测为空,图像显示为黑色);序号2 对应三角形标志的类别,其位置上mask的白色区域对应三角形区域的预测结果。
1.2.2 ROI提取与前处理
由上述对背景区域、圆形区域、三角形区域位置的预测过程,对于圆形标志与三角形标志图像,通过改进UNet 语义分割网络后与其感兴趣区域位置对应的mask 应出现在序号1 或2。为确定目标mask的序号,利用了目标序号的mask 与序号0 对应的mask的互补性质,将最后SoftMax 输出的特征图上小于阈值的点的值设置为1,而将大于阈值的点的值设置为0,然后乘以255 输出不同二值图像mask。通过该取反操作,图3 中序号0 对应的mask 就相当于与目标mask(在图3 中即是序号2 对应的mask)进行了位置交换,所以每次只需要取序号0 对应的mask 与输入图像进行按位与操作即可获取感兴趣ROI,也就不需要像Mask-RCNN[12]通过形状判定然后输出对应的mask。为减少后续处理的计算量,进一步将交通标志ROI 图像转换为单通道灰度图像,具体处理过程见公式(3)。

式(3)中,R、G、B分别代表某像素点3 个通道分别对应的像素值。由于语义分割实验中针对的是64×64 输入的交通图像,因此ROI 提取与前处理后得到的是64×64 大小的交通标志ROI 灰度图像,整个过程见图4。

图4 ROI提取与前处理
1.3 基于LeNet5分类(分类识别)
通过改进UNet 提取到交通标志的感兴趣区域后,考虑到待识别ROI 图像的特征易于提取,使用轻量级CNN 分类结构LeNet5 进行分类。
为降低图像分辨率对分类结果的影响,直接将原尺寸的ROI 图像送入分类网络,因此输入层参数设置为64×64。而对于输出层,由于后续只对15 个不同交通标志进行分类,因此最后SoftMax的输出类别值为15,具体网络参数配置见表1。

表1 具体参数设置
2 改进UNet-LeNet5实验过程
该实验基于深度学习框架pytorch 实现,计算机配置如下:操作系统为Win10;显卡为NVIDIA GeForce GTX 1050 Ti,4G 显存;系统内存为8 GB。改进语义分割网络UNet和LeNet5 分类识别网络训练借鉴了CCTSDB 数据集[13],该数据集对三大主要交通标志进行了标注,原文件记录了每幅自然场景图像的交通标志真实位置,对每个位置的交通标志进行剪裁并保存,统一图片尺寸为64×64 对数据集进行整理。实验过程中分别在警告标志、指示标志、禁令标志中各取5 种子类的交通标志,具体类别如图5所示。

图5 CCTSDB数据集
2.1 改进UNet的实验过程与改进前后对比
2.1.1 数据集选取与标签制作方法
由于语义分割是具体到对图像像素的分类方式,因此对标签的制作精度要求比较高,而传统图像标注工具LabelImg 对于尺寸较小的交通图像标注速度缓慢且难以保证精度要求。在制作的过程中,通过grabcut[14]算法手动拾取分离前景与背景初步获取感兴趣区域位置对应的mask 图像,在此基础上进行相应的直线拟合以及椭圆拟合操作以保证更好的几何形状精度。由于使用grabcut 算法的过程中每次手动拾取前景与背景的操作精度上略有差异,因此对单张图片重复制作的标签是不同的。
选取三角形和圆形两种交通标志构建数据集,制作样本总量为1 000。将对应形状的交通标志图像进行对比度有限直方图均衡和去雾气预处理后,将其作为训练图像,最后分别对每个图像绘制mask,并且在mask的基础上制作标签,其处理方式如图6所示。其中,圆形交通标志对应类别1,并将其感兴趣ROI 区域像素用1 进行填充;三角形标志对应类别2,将其感兴趣ROI 区域像素用2 进行填充;背景区域对应类别0,将背景区域使用像素0 进行填充。因此,最后数据集中用到的单通道标签图像整体看起来是黑色的而没有展示。

图6 改进UNet标签制作
2.1.2 网络训练过程与评估
设置学习率为0.000 1,batch-size 为1,冲量为0.9 以及权值衰减10-8进行训练,训练优化器选择RMSprop 进行训练,训练过程的损失曲线如图7所示。

图7 损失曲线
由图7 可以看出,改进UNet的损失曲线最后稳定收敛。为更加直观地反映出其语义分割效果,将测试集通过语义分割网络生成的mask 与实际mask计算Dice相关系数进行比较,计算过程见公式(4):

其中,gi代表像素点i的真实值,pi代表该点的预测值。相似系数取值在0 到1 之间,越接近1 表明两者越相似,表2 是改进前后UNet 在测试集上计算的平均Dice系数值。

表2 改进前后Dice系数
从表2 中可以看出,通过对UNet 原结构进行改进后,在耗时差异不大的前提下模型整体预测性能提升了7%左右,能够满足实际应用中的语义分割要求。交通标志的语义分割精度较高,一方面是因为交通标志有比较稳定的几何形状,另一方面则是因为交通标志识别数据集的前景与背景的占比相对于其他自然场景语义分割数据集分布更为均匀并且单幅图像中标志之间不发生重叠。将改进前后的UNet实际效果进行对比,如图8 所示。在图8 对交通标志ROI的预测结果中,对于改进前UNet 对感兴趣区域预测的mask,其几何形状精度无法得到保证,而改进后的UNet则有更好的表现,再次验证表2的结论。

图8 实际效果对比
2.2 LeNet5训练与整体实验方案验证
2.2.1 LeNet5分类数据集选取与预处理
图5 数据集所示的交通标志每个类别制作样本为200,对3 000 张交通标志感兴趣区域的灰度图像进行训练,为防止数据集的分布差异较大,需对数据集进行标准化处理,采用Z-score 方法进行处理,其计算过程见公式(5)。

其中,μ为数据集所有样本的均值,对于转化为单通道灰度图像的数据集,其实就是指所有样本的像素平均值,σ则为数据集样本的标准差,X和X′分别代表处理前后的数据。最后,由于交通的标志位置以及旋转角度不同,在训练的过程中使用随机剪裁和随机旋转操作。
2.2.2 分类网络训练与整体实验方案测试
设置初始学习率为0.01,batch-size 为10,冲量为0.9 以及权值衰减0.005,训练优化器为SGD。输出的准确率曲线如图9所示,分类识别网络LeNet5识别数据集的准确率达到了99%以上,因此当语义分割网络准确预测交通标志的感兴趣区域时,使用该分类网络能够保证交通标志分类的准确率。

图9 训练过程的分类准确率曲线
2.2.3 整体实验测试与对比
完成上述训练过程后,将语义分割模块与分类识别模块级联构建整体识别方案,对UNet-LeNet5模型进行测试。测试过程中选择警告标志、指示标志以及禁令标志各一种分别在弱光、强光、雾气的复杂自然场景下进行评测,如图10 所示。其中,第一列图像是输入图像,第二列图像是对交通标志ROI提取的效果展示(用不同颜色的包络线表示),并最后显示对该交通标志预测的类别。

图10 不同环境识别结果
从图10 可以看出,基于UNet-LeNet5的交通标志的识别方法针对不同光照与雾气的复杂自然条件有较好的识别效果,该模型在应对这些恶劣条件时表现出良好的抗干扰性能。为方便与其他方法进行比较并验证分类方法选择LeNet5的合理性,除与HOG-SVM[15]和ResNet50[16]分类方法对比之外,还将改进UNet和这两种方法分别级联进行验证,如表3所示。从表3 中可以得出,通过感兴趣区域的精确分割,HOG+SVM和ResNet50的识别方法在原基础上分别提升了11%和5%,表明通过对复杂背景干扰去除使识别率有较明显的提升。在分类方法的选择上,选择LeNet5 相对于HOG+SVM 在识别时间与精度上更有优势,对比ResNet50 虽精度有所不足但在时间上能够得到保证。综合上述讨论,所提出的方法综合识别率与时间上优势比较明显,可以较好地进行交通标志分类。

表3 实验结果对比
3 结论
利用深度学习方法将交通标志感兴趣区域提取与分类识别分成两个阶段,实现了对交通标志由图像边缘浅层次的特征到具体纹理深层次特征的特征学习方式,从而在不使用较深的网络下也能获得较好的识别率。
在预处理过程中通过对比度有限直方图均衡与去雾气算法处理改善图像质量,这一方面有利于应对光照、雾气对识别率产生的影响,另一方面有利于grabcut 算法人工实现前景与背景分离,不仅为改进UNet 高精度的数据集标注工作降低了难度,也为其高精度的预测性能作了良好的保证。
对UNet 最后1×1 卷积输出进行多通道分类扩展,这不仅对不同形状的交通标志起到了聚类作用,也是该语义分割网络在改进后具有优异预测性能的根本原因,该方式最大程度地减少了无关特征,使得LeNet5在复杂的自然条件下也能拥有较高的识别率。
