石英Ti/Ge-P:基于机器学习的矿床类型判别新图解 *
2022-02-14王瑀邱昆峰侯照亮于皓丞
王瑀 邱昆峰, 2 侯照亮 于皓丞
1. 中国地质大学(北京)地球科学与资源学院,北京 100083 2. 中国地质大学地质过程与矿产资源国家重点实验室,北京 100083 3. 维也纳大学地质系,维也纳 1090
石英是地壳中储量最丰富、分布最广泛的矿物之一,可形成于多种物理化学环境。作为重要的热液与脉石矿物,石英在热液系统内的结晶生长能够记录区域环境演化的直接信息(Götteetal., 2011; 陈小丹等, 2011; Götte and Ramseyer, 2012; Kempeetal., 2012; Rusk, 2012)。石英晶体中微量元素含量的变化,反映了石英在富集微量元素过程中的物理化学条件及区域地质演化过程(Rusk, 2012)。因此石英微量元素含量信息不仅可以用来确定其形成环境的成矿潜力,而且可以用来确定石英的结晶条件,判断形成石英的流体、熔体的来源(Flem and Müller, 2012; Dengetal., 2018; Qiuetal., 2021)。
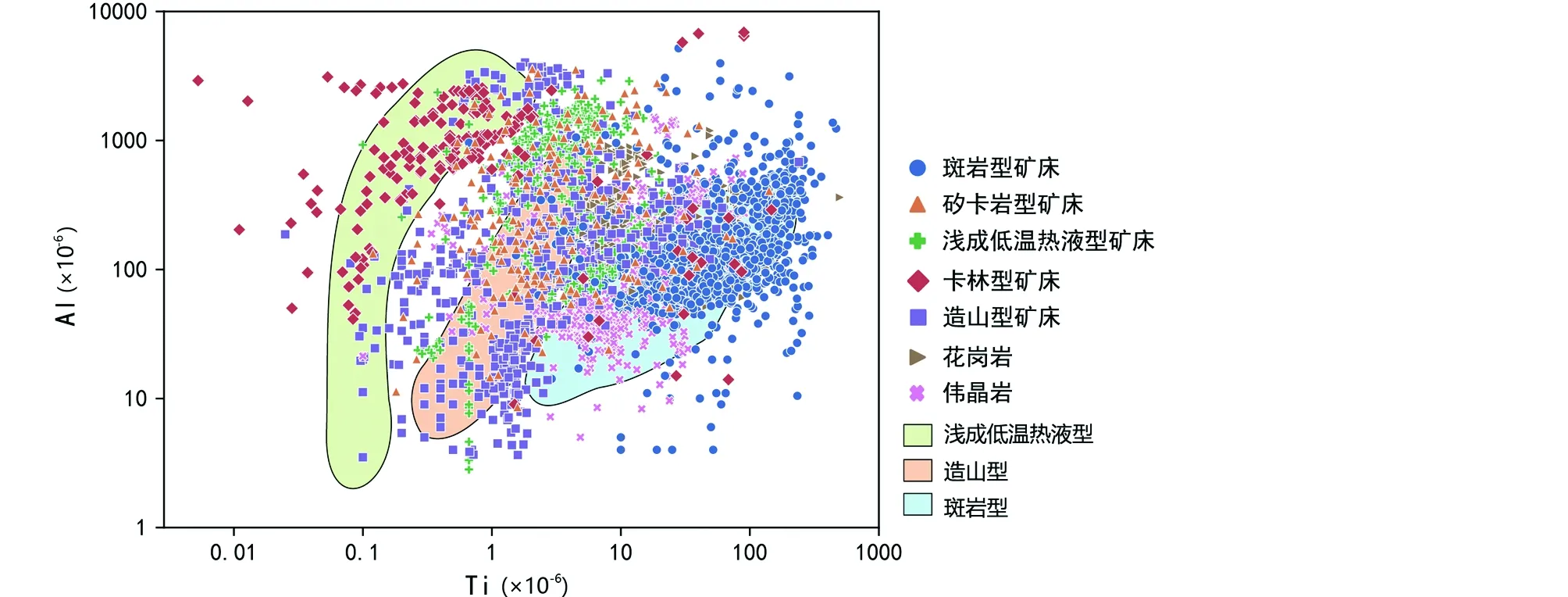
图1 不同产状石英微量元素Al-Ti图解及其与Rusk (2012)分区对比Fig.1 Some published quartz trace element data on the Al-Ti diagram (the base map after Rusk, 2012)
不同地质环境下石英晶格中微量元素的地球化学特征具有明显差异性。通过石英的微量元素对原岩进行分类的研究持续已久(Schrönetal., 1988; Götze, 2009; 陈剑锋和张辉, 2011; Rusk, 2012; Breiteretal., 2020; Dengetal., 2020b, 2021)。前人已经对石英成因判别进行了重要的研究:Schrönetal.(1988)提出适用于判别花岗岩、伟晶岩和流纹岩三种类型石英的Ti-Al-Ge三元图解;Rusk (2012)对来自大约30个热液矿床(包括斑岩型(Cu-Mo-Au)矿床、造山型金矿床和浅成低温热液型金矿床)的石英微量元素归纳研究,根据Al和Ti的含量对这些矿床的类型加以区分,提出可判别这三种类型石英的Al-Ti图解(图1)。
Schrönetal.(1988)和Rusk (2012)的图解研究均基于二维数据可视化方法。然而,越来越多的研究表明,二维图解无法展示多维度的信息特征,以石英图解为例:这些图解并不能与部分已知类型的石英微量元素数据吻合,如Peterková and Dolejš (2019)的花岗岩石英微量元素数据均落在Schrönetal.(1988)的Ti-Al-Ge三元图相应花岗岩的区域范围之外;Rusk (2012) Al-Ti二元图解,以一些已发表的石英微量元素元素数据为例(图1),其中斑岩型石英与该图解所划定的范围吻合度较高,而浅成低温热液型石英与Rusk (2012) Al-Ti二元图解划定的相应区域有较大的偏移,且与造山型矿床的相应区域有较大重叠;造山型石英相较于该图解圈定的范围更宽广,进一步增大了误差范围。虽然上述图解在随后的研究中进行了补充修订(Götze, 2009; Breiteretal., 2020),数据二维研究方法的先天性不足导致如今依旧无法准确判断石英类型,精确约束石英生成环境。
近年来,随着数据可用性和计算规模的增长,机器学习为地球科学的发展和应用提供了新的机遇。机器学习可以帮助地质学家对地震数据进行高效分类(周永章等, 2018a; Geng and Wang, 2020),利用遥感数据进行岩性分类(Yuetal., 2012; Cracknell and Reading, 2014; Dengetal., 2020a),通过矿物微量元素数据对矿物形成环境进行判别(Deng and Wang, 2016; O’sullivanetal., 2020; Wangetal., 2021; Zhangetal., 2021; Zhongetal., 2021a, b)。随着微区测试等技术的成熟,日渐丰富的地学数据可以运用机器学习寻找到最适合的,更高效,准确度更高的数据处理方法(周永章等, 2018b)。
本文收集了全球典型矿床的石英微量元素数据,包含造山型矿床、斑岩型矿床、 浅成低温热液矿床、 卡林型矿床、矽卡岩型矿床以及不含矿的花岗岩和伟晶岩七种类型,剔除成矿晚期的样品后共1220个测试点数据(表1)。在前人研究的基础上,运用监督学习机器学习方法,重新研究石英微量元素组合对岩体成矿特征的判别,提出有效的地球化学指标,建立新的石英类型判别图解。

表1 不同成因类型石英微量元素数据量
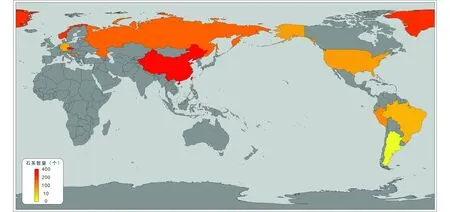
图2 石英数据集采样位置分布Fig.2 Location of quartz dataset used in this study
1 工作平台与数据来源
选取Al、Ti、Li、Ge、P等五个在石英微量元素研究中具有典型性和代表性的元素,基于Python在大数据以及人工智能方面具有的显著优势,执行最佳端元穷举。石英微量元素数据集来自以下七种类型:花岗岩:Altenberg-Teplice地区(Breiteretal., 2012)、Bohemian地块(Breiteretal., 2013)、Cínovec-Zinnwald地区(Breiteretal., 2017)、Orlovka花岗岩(Breiteretal., 2019)、Kleivan花岗岩(Jacamon and Larsen, 2009)和Krupka花岗岩(Peterková and Dolejš, 2019);伟晶岩:Borborema伟晶岩(Beurlenetal., 2011)、Orlovka伟晶岩(Breiteretal., 2019)、挪威南伟晶岩(Larsenetal., 2004)和Krupka伟晶岩(Peterková and Dolejš, 2019);斑岩型矿床:Bingham Cu-Au-Mo矿床(Landtwing and Pettke, 2005)、North Parkes Cu-Au矿床(Tanneretal., 2013);浅成低温热液型矿床:Cerro de Pasco地区(Rottier and Casanova, 2021)、Colquijirca地区(Rottier and Casanova, 2021)、Summitville Au-Ag-Cu高硫型矿床(Tanneretal., 2013)、El Indio Au-Ag-Cu高硫型矿床(Tanneretal., 2013);矽卡岩型矿床:鸡冠嘴铜金矿床(Zhangetal., 2019);卡林型矿床:丫他金矿床(Lietal., 2020)、烂泥沟金矿床(Yanetal., 2020);造山型矿床:古台山金锑矿床(Fengetal., 2020)(表1)。样品的全球分布图见图2,详见http://doi.org/10.5281/zenodo.4077298。
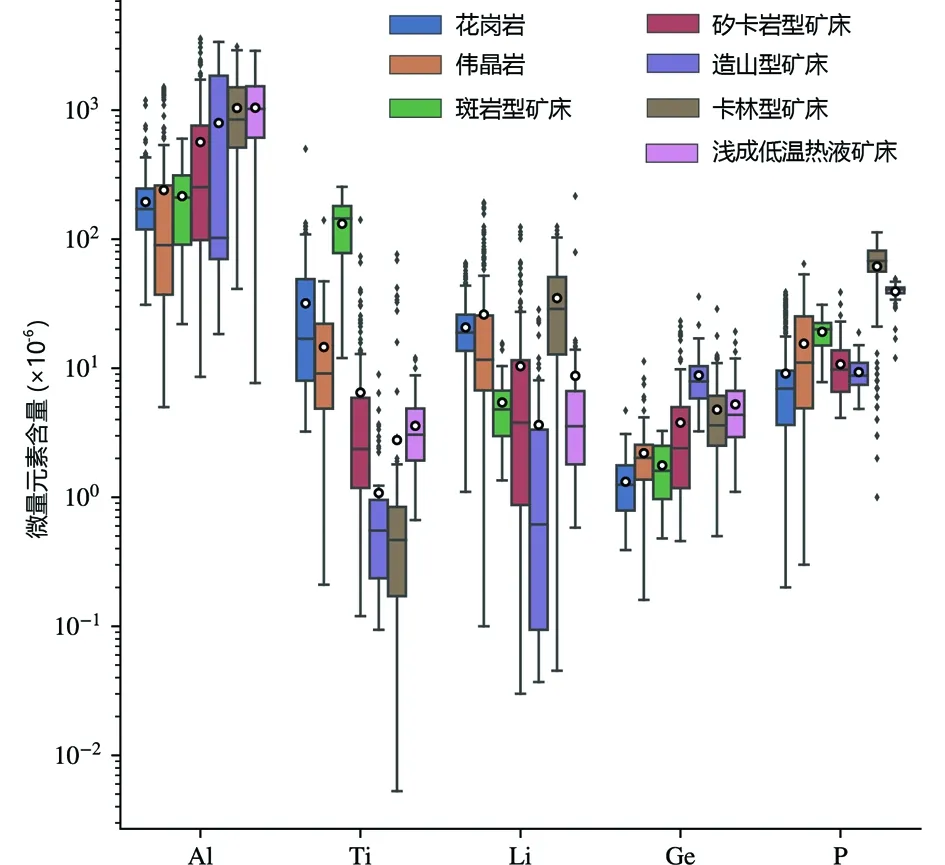
图3 不同产状和成因类型石英的微量元素含量箱式图矩形盒两端分别是数据的上、下四分位数. 矩形盒中的水平黑线代表中值,白点代表平均值. 矩形盒上、下延伸截至的横线处代表最大值和最小值. 黑点代表偏差大于±1.5σ的异常值Fig.3 Trace element concentrations of the different genetic types of quartzHeight of the color boxes show the interquartile range. The horizontal black lines within the boxes represent the median value. The white dots represent the mean value. Black lines that extended away up and down from the boxes, shows the maximum and minimum value on their horizontal cross cut. Black dots represent the outliers deviating by more than ±1.5σ
数据集Al值从5×10-6到3579×10-6,平均值为441.7×10-6;Ti值从0.005×10-6到501×10-6,平均值为22.6×10-6;Li值从0.03×10-6到215.7×10-6,平均值为19.6×10-6;Ge值从0.16×10-6到35.85×10-6,平均值为2.86×10-6;P值从0.2×10-6到113.0×10-6,平均值为19.0×10-6。不同成因类型石英的微量元素含量箱式图展示了数据集石英微量元素数据按类型的大致分布(图3)。
2 方法与流程
工作流程如下:(1)数据预处理;(2)建立穷举端元;(3)组合穷举端元;(4)选出最优组合;(5)对比不同机器学习算法在最优组合上的表现;(6)选出在此问题上最优的机器学习分类算法;(7)优化所选算法的超参数制作最终图解。
2.1 数据预处理
首先对每个分组中存在缺失值的样品进行剔除处理。通过计算Al、Ti、Li、Ge、P五个元素中任意两元素比值,得到Ti/Ge、Ti/P、Ti/Al、Ti/Li、Ge/P、Ge/Al、Ge/Li、P/Al、P/Li、Al/Li共10种组合。将初始的5种元素含量与计算后的10种元素含量比值联合,进行对数转换,得到15个构建图解的端元。利用正态化的数据,以穷举的方式生成共105个二元图解。
2.2 穷举二元图解端元
为量化且准确地筛选有效的地球化学图解,引入轮廓系数(Silhouette Coefficient)。轮廓系数是机器学习中用于无真实标签的环境下评估分簇结果的指标(Rousseeuw, 1987)。更高的轮廓系数代表模型具有更好的分簇。单个样本的轮廓系数s由内聚度和分离度两种因素决定,表达为公式(1):
(1)
其中a代表样本与同一类别中其他所有点之间的平均距离,b代表样本与下一个最近的簇中其他所有点之间的平均距离。一组样本的轮廓系数是每个样本轮廓系数的平均值。轮廓系数的范围为[-1, 1]。1指集群之间的距离清晰,区分清楚;0代表集群无关联性,亦或集群之间的距离不显著;-1代表群集分配方式错误。
通过轮廓系数量化数据簇内部紧密程度与数据簇之间的分离程度,对所有组合的图解按照轮廓系数值降序排序。轮廓系数越大,即各类别数据点簇之间分散度越大且点簇内部数据之间的关联度越高,表示各类型石英的区分度越好。基于轮廓系数,可筛选出全类型石英和仅矿床类型石英具有最佳区分度的端元,来构建端元图解。
2.3 机器学习算法计算决策边界
以穷举结果最优组合的两个端元作为坐标轴制作判别图解:本工作首先以这两个端元作为特征样本使用机器学习算法训练模型,再利用所得模型对二维平面中的所有点数据进行预测计算,推断出决策边界。所呈现的决策边界即为图解中不同石英类型的边界。为提高运算精度,测试并对比了当前机器学习领域,普遍使用的6种经典监督学习分类算法,包括线性内核的支持向量机、K近邻、随机森林、多项式内核的支持向量机、高斯内核的支持向量机和神经网络。
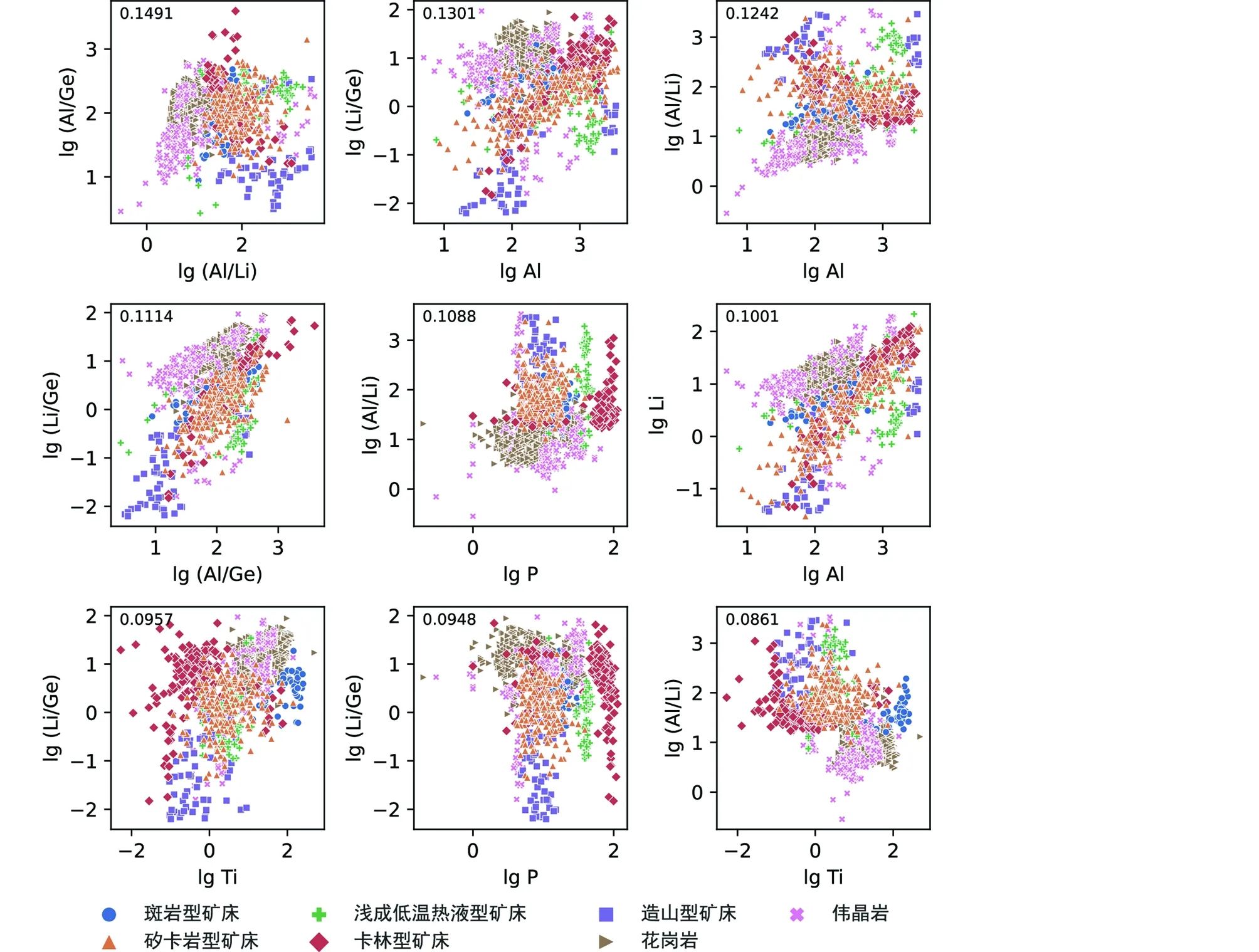
图4 穷举方法得出的区分数据集全部类别石英排名前9的图解每个坐标轴左上角数值为其轮廓系数Fig.4 Top 9 results of biplots of all types from the dataset of quartz by using exhaustive methodThe Silhouette Coefficient of each axis is at the upper left corner
支持向量机(Support Vector Machine, SVM)模型是将实际学习样本转换成空间坐标系中的点,以呈现出决策边界。这样映射可将单独类别的实例被最大限度的间隔开。新映射的样本,将基于它们相对于决策边界的分布来预测所属类别。除了典型线性分类预测,支持向量机还可以使用所谓的核技巧有效地进行非线性、多维度的分类预测(Chang and Lin, 2011; Hsuetal., 2003)。K近邻(K-Nearest Neighbors, KNN)是所有的机器学习算法中最易部署的方法之一,它是一种基于学习样本局部近似程度的惰性学习方法(Zhang and Zhou, 2007)。随机森林(Random Forest)是一种基于学习样本建立多决策树,对新的训练样本进行分类与回归预测的集成学习方法(Breiman, 1998, 2001)。人工神经网络(Artificial Neural Network,ANN)是一种通过计算模型或数学模型,模仿动物大脑内生物神经网络结构和功能,用于对学习样本进行估计预测或近似预测的学习方法(Kohonen, 1988)。
判别图解的构建基于六种算法在的学习曲线与分别预测的石英分类边界图。学习曲线使用交叉验证得分(Browne, 2000),具体采用10折交叉验证方法,即将训练集分割成10个子样本,一个单独的子样本被保留作为验证模型的数据,其他9个样本用来训练。交叉验证重复10次,每个子样本验证一次,平均10次的结果最终得到一个单一估测。学习曲线确定不同训练集大小的交叉验证训练和测试分数。结合学习曲线,审查边界过度拟合现象,综合选取最优机器学习算法;超参数进一步优化,计算与确定判别图上的决策边界(石英类型边界)。
3 结果
全类型石英图解中轮廓系数最高的组合为Al/Ge-Al/Li,其轮廓系数为0.1491(图4)。矿床类型石英图解中轮廓系数最高的组合为Ti/Ge-P,其轮廓系数为0.1698(图5)。为了更详细地展示Ti/Ge-P图解中数据的分布,绘制了Ti/Ge-P图解的核密度估计图(图6)。
最终用于机器学习的数据量为卡林型矿床76个、浅成低温热液型矿床116个、造山型矿床64个,斑岩型矿床52个、矽卡岩型矿床203个,六种机器学习分类方法分别计算出的5种矿床类型石英的学习曲线(图7)及其决策边界(图8)。线性内核的支持向量机交叉验证分数为0.716(图7a);K近邻交叉验证分数为0.794(图7b);随机森林交叉验证分数为0.796(图7c);多项式(三项)内核的支持向量机交叉验证分数为0.794(图7d);高斯内核的支持向量机交叉验证分数为0.820(图7e);人工神经网络交叉验证分数为0.789(图7f)。交叉验证分数越高,即所得结果的准确度越高。
经过交叉验证的分数和视觉审查(图8)的综合评判,选定人工神经网络作为图解构建的算法,其经优化超参数后预测出最终的判别图解决策边界(图9),其隐藏层数为2层:其中第一层100个神经元、第二层30个神经元,其交叉验证分数为0.869。
4 讨论
4.1 端元穷举
由于各端元的数值范围差别巨大(如,Al,5×10-6~3579×10-6;Ge,0.16×10-6~35.85×10-6),且中值通常远低于其平均值,不符合正态分布。对数据集做对数变换,获得符合正态分布且变化范围较小的数据集,以保证图解中的数据点分布范围相对均匀,易于判断区分效果。由于各类别不存在明显的数据不平衡问题(Chawlaetal., 2004),未进行过采样等处理。
七种类型石英的端元穷举结果显示(图4),整体上,由于二维空间的局限性,区分七种类型石英的数据点时产生叠盖是难以避免的。相较于单一元素值,元素比值能携带更多信息,因此在判别图解上普遍比单一元素作为端元具有更好的表现。在区分不同矿床类型石英的穷举结果上(图5),P和Ti是单元素作为区分单元效果较优。Al端元对各类矿床的区分效果较差,即便Rusk (2012)图解本身的Al所在的维度亦有较大重叠。Li+常以电价补偿的形式进入石英晶格而存在于其晶格间隙中(陈剑锋和张辉, 2011),常与Al3+共同替代Si4+,Al3+与Li+通常具有较高的正相关关系(Rusk, 2012)。Al/Li是出现频数最高的元素比值端元,具有较好的判别表现。在七种不同类别的石英中,尤其在岩浆岩-斑岩型矿床-浅成低温热液型矿床系列中存在明显变化性与差异性,反映了Al与Li的相关关系可能受温度影响较大。在五种类型矿床区分的结果上(图5),Ti/Ge与P为最优组合。其中Ti与Ge的比值被认为是岩浆分馏指标(Breiteretal., 2017)。P是较少被讨论的石英微量元素元素之一,但其在不同类型矿床的石英中具有明显的差异,能有效地区分石英的类型。虽然石英中的P能够对岩体赋矿类型进行有效区分,但这种现象尚未得到充分理解,其背后的地球化学意义尚待分析和发掘。
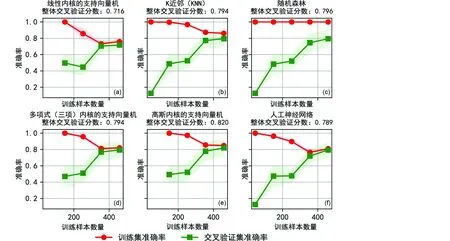
图7 六种机器学习分类算法在不同矿床类型石英分类的学习曲线比较Fig.7 Comparison of six machine learning classification algorithms on the learning curve of different mineral deposit types of quartz
矿床类型石英微量元素最优判别端元的核密度估计图(图6)显示,除了卡林型矿床类型的石英微量元素数据略呈现两极化,其它类型的石英微量元素数据在此二端元的图解上分布致密,不同类别之间亦具有较好的分离。卡林型矿床的石英微量元素数据来自烂泥沟矿床(Yanetal., 2020)和丫他矿床(Lietal., 2020),尽管二者都被认为是卡林型矿床,但其石英微量元素存在着较明显的分歧,且二者的数据均来自粉砂岩中的石英脉,未见围岩对此差异造成影响。卡林型矿床是否具有成因意义,以及卡林型是否属于成因类型,仍需进一步研究与探讨(欧阳玉飞等, 2011)。
4.2 机器学习算法比较
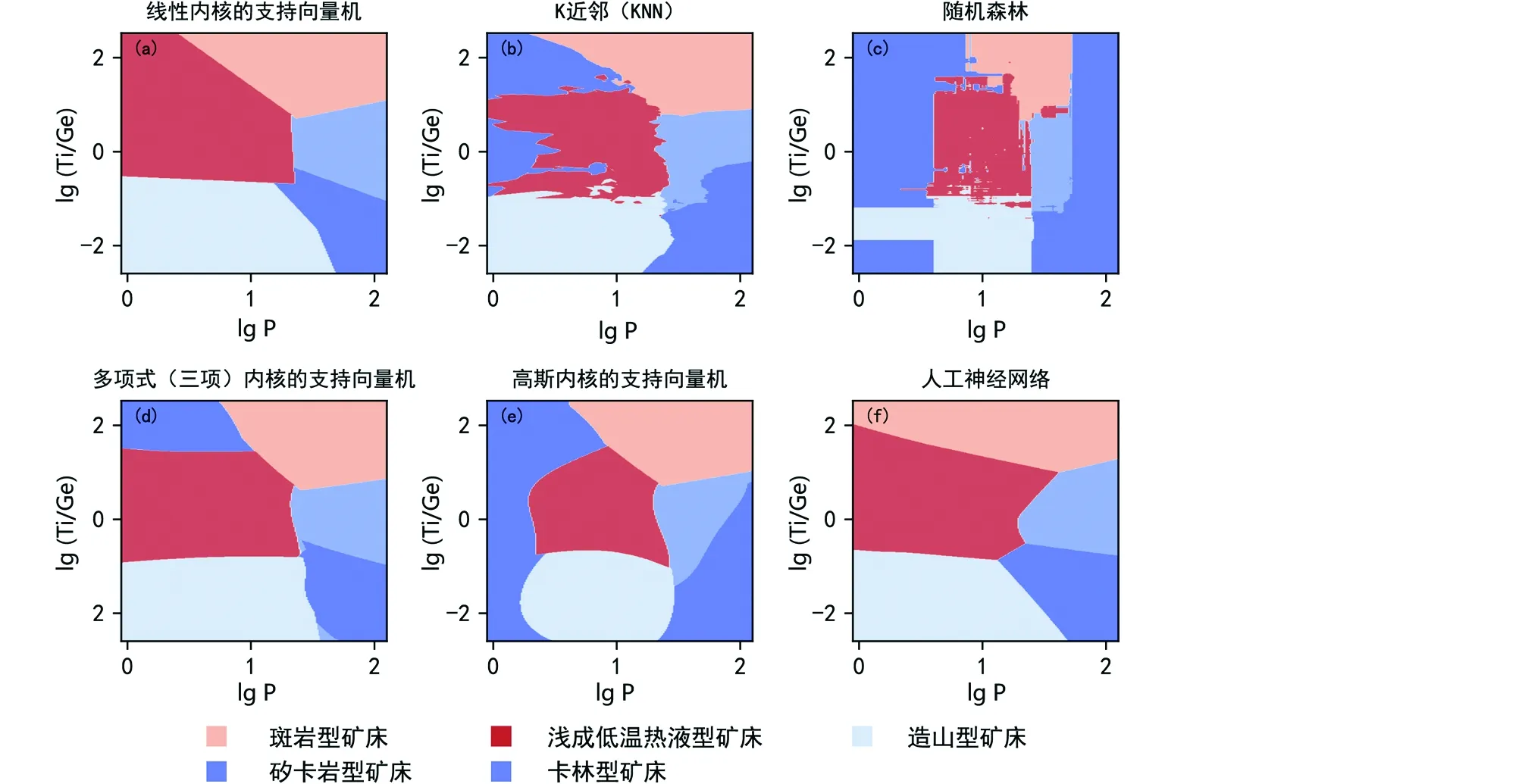
图8 六种机器学习分类算法在不同矿床类型石英分类的决策边界问题上的比较Fig.8 Comparison of six machine learning classification algorithms on the making decision boundary of different mineral deposit types of quartz
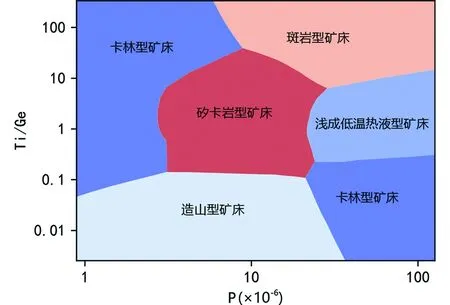
图9 矿床类型石英判别图解经过网格搜索调整超参数的人工神经网络预测出决策边界Fig.9 Discriminating diagram for different types of quartzDecision boundaries predicted by neural network whose hyperparameters was tuned by gridsearch
学习曲线结果显示(图7),除线性内核的支持向量机(图7a)最终交叉验证分数为0.716,其他五种算法均在0.8左右,无显著差异代表预测结果准确度约为80%。除随机森林外(图7c),其他五种算法的训练集曲线和交叉验证集曲线均已收敛,无过度拟合。80%准确率,存在一定的欠拟合,从曲线走势来看增加样本量已不能解决问题,已经是在二维空间中的理想结果。高斯内核的支持向量机更适合解决中等样本数量和中等特征数量的问题,而此问题仅有两个特征,从其可视化的的结果来看(图8e),大面积出现样本概率低的区间均被预测为卡林型矿床类别。此类别的数据点相对分散,对高斯内核的支持向量机方法呈现出的结果有较大影响,因此不建议在此问题上使用高斯内核的支持向量机。K近邻法和随机森林法的边界图边界过于嘈杂,不宜用作判别图解(图8b, c)。尽管线性内核的支持向量机(图8a)交叉验证分数稍低,但其具有良好的抗过度拟合能力,所得的决策边界图结果优于K近邻法和随机森林法。线性内核的支持向量机更适合解决线性可分的问题,本数据集中卡林型矿床类型石英的P值呈现出两极化特征,而线性内核的支持向量机无法兼顾。神经网络具有较高的普适性。但神经网络需要进行超参数调整,例如隐藏层数量、各隐藏层神经元的数量、学习速率和迭代次数等,调整超参数较为复杂。且隐藏层的神经网络具有非凸的损失函数,其中存在多个局部最小值,因此,不同的随机权重初始化可能导致不同的验证准确性(周志华, 2016)。在实验中我们也发现在不限定随机权重初始化情况下,人工神经网络方法每次得出的结果有明显差异,较为多变。
4.3 建议矿床判别图解
综合学习曲线和决策边界图的视觉审查(图7、图8),人工神经网络最有利于解决此问题。为尽可能取得最优结果,通过网格搜索,以3种神经网络构架、2种优化器和100组不同参数值初始化组合的多个神经网络训练后,取交叉验证分数最高的解作为最终参数。这相当于从多个初始点开始搜索,并行选择误差函数更接近全局最小值的预测结果(周志华, 2016)。交叉验证计算得出,此Ti/Ge-P图解(图9)具有约86%的准确率。随着未来更丰富的石英微量元素数据被发表,此图解还有待进一步更新优化。
5 结论
本研究为可视化地研究石英微量元素提供借鉴,以P、Ti/Ge为端元的图解,能有效区分矿床类型。Al/Li值在斑岩型矿床、浅成低温热液型矿床系列中变化明显,Al/Li的强相关性可能受温度影响。
在使用机器学习制定二维分类判别图解问题上,应避免使用K近邻与随机森林应方法;人工神经网络与支持向量机是推荐方案;人工神经网络虽然现在常用于更为复杂深度学习,但是在为判别图解制定决策边界这种低特征数量分类问题上亦有较好的表现。在二维可视化的基础上运用的机器学习方法,高维度的研究目标特征,做出精确预测,将是未来的研究方向。有足量数据的情况下,本工作流程亦适用于其它地球化学判别图解的研究与建立。
Ti/Ge-P图解的决策边界由经过超参数调整优化的人工神经网络计算得出,可用来判别斑岩型矿床、矽卡岩型矿床、浅成低温热液型矿床、卡林型矿床以及造山型矿床中的石英,此图解具有约86%的准确率,是大数据技术与机器学习技术在地球化学研究中的探索。随着未来更丰富的石英微量元素数据的发表,此图解还有待进一步更新与优化。
致谢论文的完成得益于邓军院士的指导;感谢张静教授和两位匿名审稿专家对文章提出的宝贵意见;感谢俞良军老师对本文细心的审阅;感谢中国地质大学(北京)的李珊珊博士后、龙政宇博士、朱紫怡和周飞为本文提供宝贵的修改意见。
