容器热迁移的快速内存同步技术
2022-02-12游强志胡怀湘陈相宇
游强志,胡怀湘,陈相宇
(中国电子科技集团第十五研究所,北京 100083)
0 引 言
云计算是一种融合了多项计算机技术的以集中式计算和存储为特征的密集型计算模式[1],其中虚拟化技术是最为关键的技术之一。目前业界对虚拟化技术可以分为2类。一类是基于Hypervisor的容器化虚拟机技术[2],其中以Hyper为代表。另一类是基于Namespace和Cgroups机制的容器技术[3],其中以Docker为代表。
对于基于Hypervisor的容器化虚拟机热迁移,其本质上仍旧是基于传统虚拟机的热迁移技术。国内外学者对于传统虚拟机的热迁移技术,进行了广泛而深入的研究。
虚拟机的迁移主要包括CPU状态、内存状态、设备状态[4]。日志重放和快照是虚拟机迁移中广泛使用的2种方案[5]。其中基于日志重放机制的虚拟机迁移技术会记录虚拟机的所有异步事件,然后在目的虚拟机上确定性地重放日志,以实现虚拟机端到端迁移的目的[6]。然而该种方法的弊端在于尽管在虚拟机监视器的帮助下,日志记录很容易完成,但是日志记录的确定性重放很大程度上依赖于目标体系结构[7]。除此之外,对于多核CPU,跟踪共享内存是非常困难的。而快照机制的虚拟机迁移,待迁移虚拟机在运行时其输出将会被缓冲,与此同时虚拟机状态会被打下快照,并且传输到待同步虚拟机上,当主从虚拟机状态同步完成后,输出被刷新,迁移完成[8]。基于快照机制,设备状态实质上存储在内存中,而其余数据可以通过共享存储[9]等方案快速传输,这就导致该种方案的主要开销在于内存同步。许多方案被提出以减小虚拟机迁移过程中内存同步的开销。其中应用得最广泛的一种技术是预拷贝(pre-copy)技术,通过多次迭代拷贝将源虚拟机的内存拷贝至目标主机,每次拷贝只传输源虚拟机中的脏内存,能够大大减少虚拟机的停机时间和传输损耗[10]。该种方法的弊端在于如果内存修改过于频繁,某些热点内存页可能被反复传输,造成资源的浪费,甚至导致迭代过程无法收敛[11],造成迁移失败的情况。为解决这个问题,很多基于预拷贝的改进算法被提了出来。例如对每轮传输的内存页进行统计,将传输频繁的热点内存页留到最后一轮传输[12],以减少传输总量。还有通过CPU调度减少迁移过程中内存脏页的生成速率,保证迁移的顺利进行,但这样不可避免会造成虚拟机性能的下降[13]。除此之外,包括利用局部性原理优化内存拷贝[14]、计算内存脏页率并分频传输[15]、预测内存修改频率[16]、对内存脏页进行分类并多路复用传输[17]等方案,目的都是减少内存传输总量,从而保证迁移的顺利进行。与预拷贝技术对应的,另一种迁移算法是后拷贝(post-copy),该算法一次性将所有内存页拷贝到目的主机,随即切换服务,仅当目的主机上发生页错误时,才将源虚拟机中对应的内存页复制过来,以保证每个内存页只被传输一次[18]。但后拷贝可能导致服务的不可用,以及停机时间过长等弊端[19]。因此,学术界提出了一种名为混合方案的新迁移算法,以综合预拷贝和后拷贝2种算法的优势,即先进行预拷贝,令源虚拟机在正常运行的情况下将全部内存页复制到目的虚拟机,随后启动目的虚拟机提供服务,使用后拷贝对内存脏页进行处理[20]。
目前为止预拷贝算法广泛应用于工业界当中,而其余算法更多还仅是停留在学术界的讨论当中。
与基于Hypervisor的重量级虚拟化技术相比,以Docker为代表的虚拟化是一种基于操作系统层级的轻量级虚拟化技术,一个容器实质上等同于一个进程。
相较于传统容器化虚拟机的迁移,学术界针对容器热迁移的研究比较少。目前容器的热迁移主要依赖的技术是CRIU技术,首先对容器进行Checkpoint操作,将容器的CPU、内存等信息存储为文件,容器随后停机,将信息文件拷贝到目的主机上,执行Restore操作恢复容器继续工作[21]。该种方案中,在传输过程及恢复过程中容器完全停机,通常导致停机时间较长。除此之外,也有人尝试使用日志记录容器运行过程中的事件,随后在目的端容器中进行回放,回放完成后停止源容器[22]。该种方案依赖于计算机的系统结构,并且在多CPU的应用场景下,很难做到日志的确定性重放,所以该方案目前仍旧停留在理论研究中,不适用于云平台、集群的应用场景下。
本文主要针对以Docker为代表的容器虚拟化的热迁移技术,基于预拷贝(pre-copy)算法设计并实现容器在不同主机之间的热迁移方案,并提出3种改进策略,以满足容器热迁移过程中减少停机时间及传输性能上的优化。
1 容器热迁移方案设计
1.1 设计目标
本文中的容器热迁移,针对的是用户无感知情况下,容器跨节点间的迁移,迁移过程必须实现以下几个目标:
1)透明性。透明性是指在迁移过程中应该对用户保持透明化,即在容器迁移发生时,对外服务应当保持正常,在用户无感知的情况下完成容器的迁移过程。
2)实时性。实时是指不停机的一种迁移方式,即在迁移过程中保证服务的高可用,但在单容器运行情况下的迁移无法做到完全不停机,在本文中的容器迁移应当做到迁移过程中的停机时间尽可能地短。
3)一致性。一致性是指在迁移前后,容器的进程运行状态应当与迁移前在源主机上的容器进程状态保持一致。
4)节能性。在实际生产场景中,容器镜像跨节点的传输速度取决于带宽,通常来说,一台主机上会运行多个容器,共享主机的带宽资源,所以在满足上述3个目标的前提下,应尽量减小传输消耗。
1.2 方案设计
容器传统的迁移过程由4个阶段组成:运行阶段、检查点(checkpoint)阶段、传输阶段、和恢复(restore)阶段。容器经由检查点阶段将容器的状态信息输出为文件保存,随后容器停止,经过传输阶段传输到目的主机上,通过恢复阶段恢复运行。
如图1所示,在容器传统迁移过程中,容器的停机时间包括传输阶段和恢复阶段。然而正常使用的容器产生的状态信息文件大小可以达到GB级,在带宽受限的情况下会导致停机时间过长,影响服务的正常使用,无法实现实时迁移的目的。
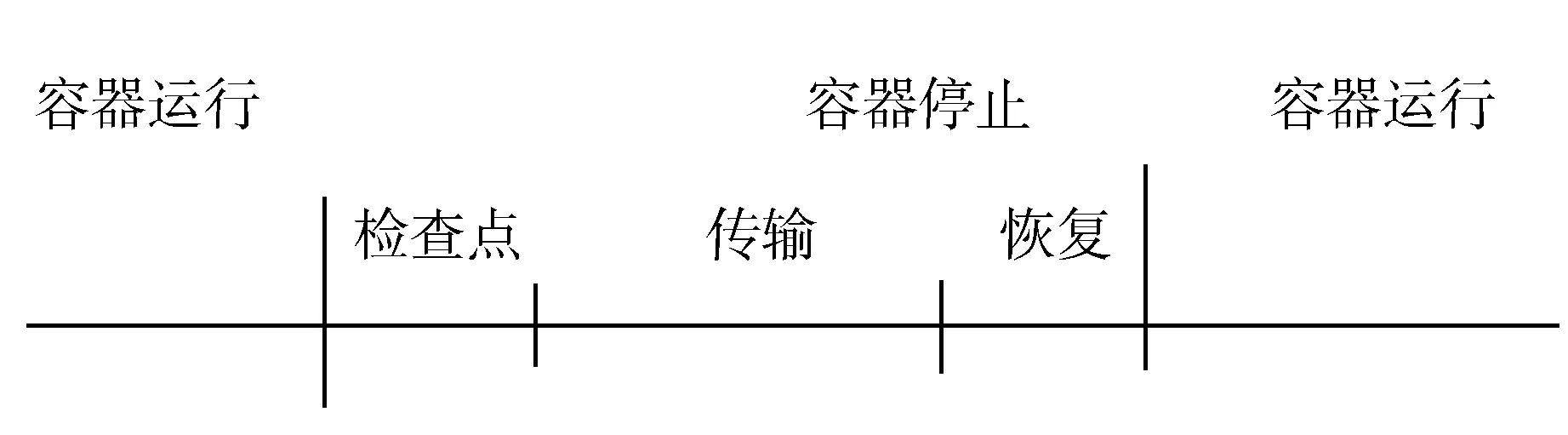
图1 容器传统迁移
为了减少停机时间,基于预拷贝(pre-copy)算法对容器传统迁移算法进行优化。
如图2所示,迁移流程可以总结为如下步骤:

图2 基于pre-copy算法的容器迁移流程
1)生成容器的全量检查点,并将生成的状态文件传输到目标主机,保持容器运行。
2)生成容器的增量检查点,增量检查点中主要包含2次检查点之间的脏内存信息。
3)判断步骤2中产生的增量检查点大小是否小于阈值,如果是,进行步骤4,否则进行步骤5。
4)判断迭代传输轮次是否达到上限,是则进行步骤5,否则传输该检查点,重复步骤2。
5)停止容器,传输最后一次的检查点。
6)在目的主机上恢复容器。
根据上述步骤,如图3所示,该算法中容器的停机时间包括最后一次增量检查点的传输时间和容器的恢复时间。增量检查点的阈值通过人为设定为明显小于全量检查点的大小,能够大大减少传输时间,从而达到减少停机时间的目的。
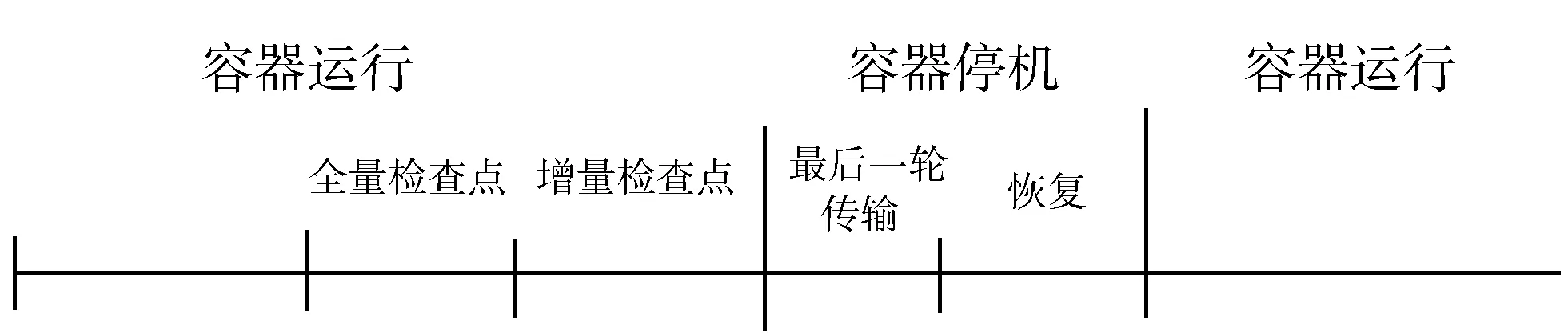
图3 基于pre-copy算法的容器迁移阶段
1.3 模块设计
相较于传统的基于CRIU技术实现的checkpoint/restore容器热迁移,本文设计的基于预拷贝算法的容器迁移方案与之最大的区别在于内存拷贝时,对脏内存的处理以及2种检查点的使用,在CRIU技术的基础上设计迁移系统的模块如下:
1)检查点模块。
2)传输模块。
3)恢复模块。
1.3.1 检查点模块
检查点模块负责将容器进程的状态信息全量或增量存储为镜像文件,该模块的实现主要依赖于/proc文件系统,镜像文件中主要包含以下内容:
1)文件描述信息,通过/proc/$pid/fd和/proc/$pid/fdinfo进行收集。
2)进程参数信息,通过调用ptrace接口和解析/proc/$pid/stat进行收集。
3)内存映射信息,通过/proc/$pid/maps和/proc/$pid/map_files/收集。
在开始检查点进程之前,必须保证检查点进程不会改变原先容器进程的运行状态,并且为了保证检查点的有效性,在进行检查点操作时,容器进程及其子进程状态必须是不变的。一般而言,可以通过停止信号“杀死”进程,但这样就改变了容器进程的运行状态,所以这里通过调用ptrace接口暂时地冻结进程树。
然后,为了收集进程的内存数据,通过调用ptrace接口向进程注入寄生虫代码,每当mmap进行内存文件映射时,检查点模块将寄生虫代码拷贝到相应的进程地址空间,收集内存数据。在收集完所有信息后,由于寄生虫代码本身会占用内存,为了尽可能减少对容器进程的影响,需要对其进行清除。
检查点模块的具体工作流程如下:
1)根据容器进程的pid递归地遍历/proc/$pid/task/和/proc/$pid/task/$tid/children收集容器进程及其子进程构成的进程树信息。调用ptrace接口的PTRACE_SEIZE命令冻结进程树。
2)检查点模块收集容器进程中可获取的资源信息,包括文件描述信息、进程参数信息、内存映射信息等,并写入文件。
3)向容器进程中动态注入PIE(Position-independent code)格式的寄生虫代码[23]。当容器进程调用mmap操作时,寄生虫代码被拷贝到对应的地址空间,记录随后的内存变化。
1.3.2 传输模块
传输模块通过使用Linux的SCP命令,负责将检查点模块生成的镜像文件迭代地从源主机传输到目的主机。
1.3.3 恢复模块
恢复模块负责在目的主机上合并迭代传输过来的容器镜像文件,并恢复容器运行。其中镜像文件分为2类,一类是第一次传输的容器全量信息,另一类为迭代预拷贝过程中生成的内存脏页信息,恢复模块负责将内存页信息镜像文件合并成一个文件,并以生成的镜像文件信息恢复容器的运行。
恢复模块的工作流程:
1)合并传输收到的多个内存页镜像文件,得到最终的内存页镜像文件。
2)恢复模块读取合成的镜像文件,并且解析镜像文件中进程的共享资源,随后共享资源的恢复存在2种方式,一是由某个进程恢复,其他进程之后继承,二是通过其他方式恢复,如通过memfd文件描述符恢复共享内存。
3)恢复模块递归地生成需要恢复的进程树,恢复进程的基本资源,在这个阶段,恢复模块将会恢复容器进程打开的文件、准备命名空间、填充私有内存数据、创建套接字等等。
从表5三次考查结果可以看出,进入锡石浮选脱泥前-0.010 mm粒级产率为56.68%,含泥较高,经过三次脱泥后,有45.30%的锡金属进入锡石浮选中,整个锡石浮选作业效率达到79.44%,对原矿的回收率为5.15%。超过了预期目标。
4)对于步骤3中创建的进程,注入寄生虫代码,执行munmap和mmap操作取消旧内存映射,并恢复成容器原本的内存映射,恢复计时器、线程等。
5)调用ptrace接口清除步骤4中注入的寄生虫代码,恢复进程运行。
2 快速内存同步优化设计
2.1 细粒度脏内存识别
在基于CRIU进行脏内存跟踪时,实质上是通过虚拟内存写保护机制来实现的。每次修改内存页时,都会出现写保护,这将导致尝试写入进程内存页面时发生页面错误,与此同时记录下本次写入的内存页,随后继续完成操作。
虽然虚拟内存写保护机制十分方便,但是当内存修改频繁时,这种机制可能带来不小的性能开销。除此之外,这种机制对脏内存的追踪粒度级别是内存页,这意味着哪怕某个存储页中只有单个字节被修改,整个内存页也被认为是脏内存页,可能造成额外的传输开销。
为了解决上述问题,本文引入一种细粒度的脏内存识别技术。与跟踪整个页不同,可以将一个内存页细分为若干个块,并且为每个块计算一个哈希值,并将这些哈希值存储在内存中。在检查点阶段,为每个块计算一次当前的哈希值,如果与上一次检查点阶段的哈希值不同,替换为新的哈希值,将相应的块标记为脏块,最后传输阶段,只传输脏内存块,而不是整个页。
内存块的大小越小,识别的脏内存也越准确,但也会带来更大的内存开销。对于一个典型的内存页(4 kB),假定一个块的大小为256 B,每个哈希值占用8 B,额外的内存开销约为3.1%,而当块的大小为128 B时,额外的内存开销约为6.3%。除此之外,计算哈希值也会增加额外的开销,但在本文的测试机上,MD5哈希计算的吞吐量约为320 MB/s,远高于专用千兆以太网链路的持续吞吐量128 MB/s,内存块的哈希值计算可以很容易地与传输过程一起流水化。
2.2 脏内存压缩传输
基于预拷贝算法的容器热迁移过程中需要迭代地拷贝若干次脏内存,势必会占用一部分的带宽资源。而在云环境的应用场景下,同一主机上的带宽是有限的,为了减少迭代传输所占用的带宽,本文对脏内存进行压缩传输。
几种常见的压缩算法对比如表1所示。

表1 常见压缩算法对比
压缩和解压过程会增加内存开销,并且需要时间。为了保证在迭代过程中压缩、传输、解压、恢复过程能够流水化,要求压缩算法的压缩速度至少要高于专用千兆以太网链路的最大吞吐量128 MB/s,本文使用Zippy/Snappy压缩算法。
Zippy/Snappy是一种基于最近邻算法(K-Nearest Neighbours),旨在实现高速与合理压缩比的一个压缩、解压库[24]。
假设最后一次检查点大小为x,压缩速率是v1,压缩率为y,解压速率是v2,网络传输速率是v3,可以得到最后一次传输过程时间,引入压缩/解压缩时间与不引入的比值为v3(v2+yv1)/v1v2,在实验室中该值仅为5%,对停机时间影响不大。
2.3 提前合并内存镜像
在恢复容器运行之前,恢复模块需要将目的主机上接收的内存镜像文件合并,并基于生成的最终内存镜像文件恢复新的容器进程。也就是说,事实上,最终只需要最后生成的合并镜像文件,而合并过程可以与镜像传输过程一起进行,即进行预合并操作。
容器生成的内存镜像文件有2类,一类是pagemap.img,该文件中存储内存的映射关系,例如图4中pagesmap1.img,表示前4个内存页将从pages.img中读取并放置到地址0x1000000处。当执行增量检查点时,pagemap.img中会增加一个标示位in_parent,表示这些内存页从前一个检查点读取。另一类文件为pages.img,存储内存页的具体内容。
预合并过程实现如图4所示。

图4 预合并过程
假设目的主机上接收到了N批内存镜像文件,其中包括一份全量状态镜像文件和N-1份脏内存镜像文件,需要执行N-1次合并操作。若进行预合并操作,理想情况下只需要执行最后一份脏内存镜像文件和容器镜像文件即可,即执行1次合并操作,能够有效减少恢复阶段造成的停机时间。
在实验机上测量,预合并的速度约为135 MB/s,高于专用千兆以太网链路的持续吞吐量128 MB/s,可以与传输过程一起流水化进行。
3 实验与比较
本章中的实验环境是2台完全一样的物理机,物理机硬件配置如表2所示,软件配置如表3所示。2台物理机与1台路由器构成简单的网络拓扑。
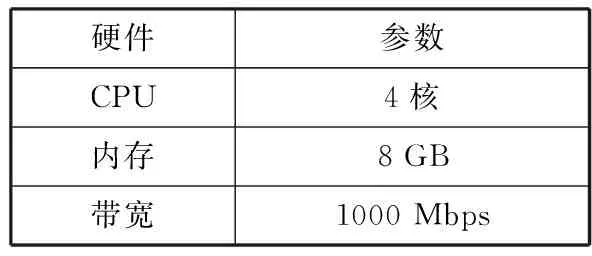
表2 主机硬件配置

表3 主机软件配置
为了方便对比不同内存更新率的情况下的实验结果,本文使用Linux容器,通过Linux性能压测工具Stress来模拟容器在不同负载下的情况,默认Stress使用1个进程,不停申请并释放内存,间隔时间为1024 ms。容器的相关配置如表4所示。
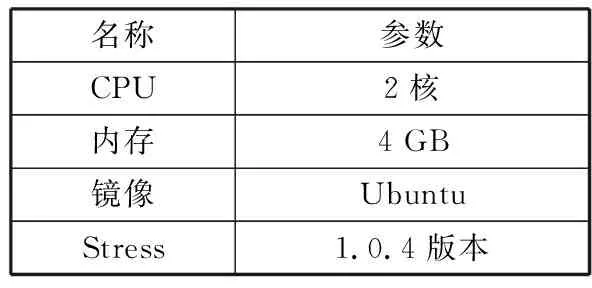
表4 容器配置
3.1 细粒度脏内存识别
在容器中,使用Stress软件分别申请512 MB、1024 MB、2048 MB内存,不停地计算随机数的平方根并写入内存,设置检查点迭代间隔大小为500 ms,迭代阈值设置为全量检查点大小的50%,迭代上限设置为10次时,容器迁移过程中的传输字节总量与内存分块大小的关系如图5所示。
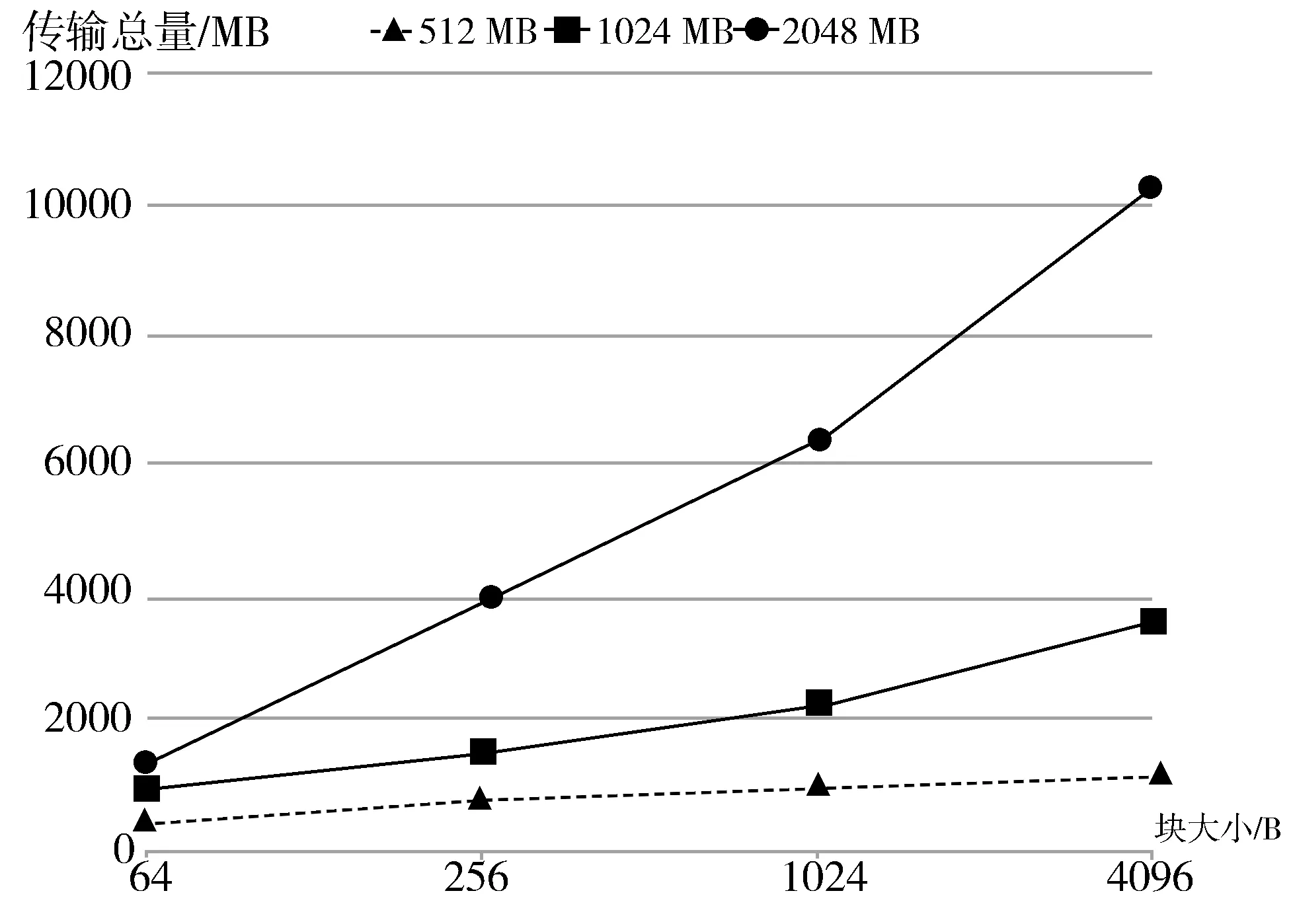
图5 传输字节量与块大小关系
随着内存块大小的增加,整个迁移过程中传输的字节总量会增大。对比3条曲线可以看出,写内存越稀疏,传输总量也会增大。
3.2 脏内存压缩传输
在容器中,使用Stress软件申请1024 MB内存,不停地计算随机数的平方根并写入内存,迭代阈值设置为全量检查点大小的50%,迭代上限设置为10次时,使用Zippy/Snappy压缩和不使用压缩时,传输总量的大小与迭代间隔大小的关系如图6所示。

图6 传输字节量与迭代间隔大小的关系
实际上,由于压缩对象主要是内存信息,格式都是二进制文件,Snappy能够实现的压缩比远高于0.22这个比率,对比不进行压缩的情况下,传输开销明显减少。
3.3 提前合并内存镜像
使用Stress软件,申请1 GB内存、阈值设置为全量检查点大小的50%时,采用pre-restore提前合并内存镜像与正常restore恢复过程所需要花费的时间与迭代间隔的大小如图7所示,恢复时间与迭代轮次的关系如图8所示。

图7 恢复时间与迭代间隔大小关系

图8 恢复时间与迭代轮次关系
随着迭代轮次的增大,未使用预合并内存镜像所需要的恢复时间明显增加,而使用了预合并内存镜像所需要的恢复时间基本保持不变。事实上迭代轮次的大小通常与迭代阈值的大小成正相关关系,预合并内存镜像能够明显减少恢复时间。
3.4 总结
当迭代阈值设置为全量检查点大小的50%,迭代间隔为500 ms,在容器中使用Stress软件申请512 MB内存,迭代轮次上限设置为10次,不停地计算随机数的平方根并写入内存。对该容器进行热迁移的实验结果如表5所示。

表5 512 MB实验结果
从表5可以看到,与传统checkpoint/restore机制的迁移方式比,采用预拷贝(pre-copy)方式产生的停机时间并没有明显优化,这是由于迭代轮次增加,恢复时间增加所导致的。当采用细粒度脏内存跟踪优化后,停机时间仅为传统迁移方式的77%,传输总量为预拷贝方式的45%。当采用预合并镜像后,停机时间减少了61%。当采用压缩脏内存传输优化后,传输总量比传统迁移方式减少了近一半。最后,进行了优化后的预拷贝容器热迁移机制,相比于传统的checkpoint/restore迁移机制,停机时间减少了77%,传输总量减少了63%,停机时间和传输节能获得了明显的优化。
4 结束语
为了优化容器热迁移过程中产生的停机时间和传输开销,本文设计并实现了一种基于预拷贝(pre-copy)算法的容器热迁移方案,并且提出了3种优化策略。实验表明,上述方案相比于传统的checkpoint/restore迁移机制,停机时间减少了77%,传输开销减少了63%,得到了明显的优化。
