基于哑变量和因子选择的森林蓄积量估测研究
2022-02-10罗洪斌岳彩荣张国飞朱泊东
罗洪斌,岳彩荣,张国飞,金 京,谷 雷,朱泊东
(西南林业大学 林学院,云南 昆明 650224)
森林是陆地生态系统的重要组成部分,在全球碳循环和气候变化中具有重要的作用,随着国民经济的快速发展,森林资源及其生态作用的显得日益突出[1]。森林资源监测和森林经营活动中,蓄积量是重要的数量指标,森林蓄积量是衡量一个国家或地区森林质量的基本指标,也是评价森林生态环境和森林资源的重要依据[2],传统的森林蓄积量依靠人工地面调查为主,需耗费大量的人力、物力、财力,虽然可获得高精度的地面调查数据,但效率低、调查区域有限,无法快速实现区域尺度的森林蓄积量监测[3]。
遥感技术的出现,极大地改善了传统森林蓄积量监测效率低的问题,通过结合少量地面样本数据和遥感变量建立估测模型从而快速高效地实现大区域的森林蓄积量监测[4]。20世纪中后期,R.Nelsonetal[5]、童庆禧等[6]利用不同的遥感数据利用地面样本与遥感数据间的关系进行森林参数的估测,其研究结果为森林蓄积量的遥感监测奠定了基础。随着遥感技术的发展、传感器的更新以及估测算法的进步,如何提高森林蓄积量的遥感估测精度逐渐成为了当前的研究热点之一。在目前的光学遥感数据源中,Lansat 8 OLI以其较高的空间分辨率和光谱质量以及大区域覆盖的优势为大尺度森林资源监测提供数据支撑,在此基础上目前的研究主要从估测算法的优化、多数据源的结合以及特征的优化选择等方面进行探索[7-9]。
由于光学遥感数据的饱和性,不同大小的森林蓄积量以及其他森林参数随遥感影像的光谱纹理信息的响应灵敏度不同,随着蓄积量的增加,光谱响应灵敏度逐渐降低最后达到饱和[10]。然而,传统的森林蓄积量遥感估测中仅考虑遥感变量与森林蓄积量的关系,而忽略了光饱和问题对估测结果带来的影响,因此有学者提出了对森林类型以及树种进行划分后进行估测,或者将不同大小的森林参数进行分段估测[11],此方法虽在一定程度上提高了估测精度,但也存在一定的局限性,若在样本量较少的情况下进行分类估测或分段估测,则参与模型构建的样本数较少会导致估测模型不具代表性。哑变量的引入能有效解决上述问题,哑变量是一个定性变量,可用来定义样本数据的类型或状态,在总样本数量不变的情况下按照样本数据的属性对样本类型进行区分,E.Csaplovicsetal[12]在森林生物量估测中引入植被类型作为哑变量发现估测结果相较于未加入哑变量的估测精度有较大的提高,王宗梅等[13]、岳振兴等[14]以高山松为研究对象,以龄组为哑变量分别构建了基于多元线性回归和神经网络的蓄积量估测模型,表明在加入哑变量后模型的估测精度有明显的提高,随着遥感技术的进步,将哑变量应用于森林参数的监测研究逐渐增多,W.S.Zengetal[15]利用非线性混合效应模型结合哑变量方法有效的提高了森林地上生物量和地下生物量的估计精度;C.Lietal[16]、G.Ouetal[17]以龄组和冠层密度等为哑变量,结合多种估测模型进行生物量估测研究,表明哑变量的引入可以有效提高股精度。但针对不同的估测方法和研究对象此问题还需进一步进行探讨分析,在此基础上,本研究以龄组为哑变量,探讨哑变量对于森林蓄积量估测的影响,在利用随机森林算法进行变量的筛选的基础上分别构建基于哑变量的偏最小二乘(PLSR)和支持向量机回归(SVR)的森林蓄积量估测模型,通过对比哑变量的引入以及不同方法的估测结果,从而为提高森林蓄积量的估测精度提和哑变量在森林参数估测中的应用提供参考。
1 研究区概况
1.1 研究区概况
思茅区地处云南省普洱市(100°19′29″-100°26′57″E,22°27′7″-23°5′29″N),总面积3 861.7 km2,思茅区东接江城县,西接澜沧,南邻西双版纳,北接宁洱,地势西北高东南低,区域内山脉、峡谷、水系众多,平均海拔为2 155 m,气候类型属于南亚热带季风气候,干湿季节不分明,常年高温、湿润、多雨,年平均气温为17.8 ℃,平均降水量为1 524 mm,在特殊气候类型的作用下,境内森林覆盖率较高。
1.2 数据的获取与处理
1.2.1 地面调查数据 地面样地数据来自2015年11-12月森林资源二类调查的森林抽样控制样地,考虑到样本数量的特点,选取93块阔叶林样地,样地信息主要包括经纬度坐标、龄组、地类、蓄积量、公顷断面积、平均树高、平均胸径等。样地蓄积量的统计特征见表1。
1.2.2 Landsat8 OLI数据与处理 卫星影像数据采用Landsat8 OLI数据。Landsat8陆地观测卫星主要对陆地资源、环境等领域提供有效信息,该陆地观测卫星搭载了2个传感器:OLI陆地成像仪和TIRS热红外传感器, OLI陆地成像仪包含9个光谱波段,本研究采用1~7波段[18]。根据思茅区的行政区划范围通过地理空间数据云官网(http://www.gscloud.cn/)下载所需的Landsat8 OLI影像数据,影像成像时间为2015年12月,对影像进行了辐射定标、大气校正、几何校正和地形校正等处理。
2.3 遥感变量提取
遥感影像的光谱、纹理以及变换信息是地物特点的直观表现,遥感影像上光谱反射率大小以及纹理的变化能有效反映森林蓄积量以及其他森林参数的大小,因此遥感变量信息与森林蓄积量有良好的相关性,但不同植被类型以及森林林分结构的不同,在遥感影像上表现出来的特点也不一致,因此变量因子的选取对于后续的研究有一定的影响。本研究选取了单波段变量(B1-B7)、植被指数(DVI、NDVI、EVI、SAVI、RVI、SLAVI,公式中用DVI、NDVI、EVI、SAVI、RVI、SLAVI表示)、主成分分析(PC1-PC7,公式中用PC1-PC7表示)以及1~7波段的纹理信息共76个变量作为备选参数(表2)。

表2 变量参数说明
2 研究方法
2.1 遥感变量参数筛选
遥感变量与森林蓄积量之间有良好的相关性,但在自变量较多时,去除多余变量以及部分对回归估测中的贡献程度较低的变量对回归模型的构建有一定影响,通过变量的筛选达到特征降维的作用从而提高模型构建的效率和估测精度,因此,采用随机森林算法(random forest)对变量进行筛选,随机森林是以决策树为基础的机器学习器的集成算法,广泛应用于分类和回归分析中,利用随机森林进行变量筛选的主要原理是通过判断每个特征在随机森林的每棵树中所做的贡献大小,然后取平均值,最后比较特征之间的贡献大小,计算方式分为基尼指数和袋外数据错误率,本研究所采用的是基尼指数[19]。
2.2 哑变量的设置
哑变量也称为虚拟变量,通常用0或1来表征定性数据的状态或类别[20-21]。在森林蓄积量估测模型构建中,遥感变量为连续变量,但在实际情况中由于森林结构的差异以及森林参数组分之间差异,需要引入类别或状态进行区分,本研究以森林的龄组为哑变量,龄组包括幼龄林、中龄林、近熟林、成熟林。
2.3 回归估测模型
2.3.1 偏最小二乘回归 偏最小二乘回归(partial least squares regression)具有能克服自变量间的多重共线性问题和合适小样本的优点,且能够对样本中的噪声进行识别,多用于多自变量和因变量的回归建模,还可实现主成分分析以及典型相关分析,回归建模原理为:n个自变量(X1,X2,…,Xa)和因变量Y构成的自变量和因变量的矩阵X=[x1,x2,..,xa]n×a和Y=[y]n×1。在自变量X中提取第1个主成分的同时对因变量进行回归,若未达到既定精度,则继续提取下一主成分,直至达到既定的精度为止[22-23]。
2.3.2 支持向量机回归 支持向量机(SVM,support vector machine)以统计学中的多维数和最小风险的原理为基础,它具有支持小样本数和低风险的特点,即在现有的样本和既定的精度以及精确无误地辨识样本的前提下寻找最佳的方法,从而获得较好的期望和普适性。因此支持向量机算法也是目前机器学习中最为常用的一类算法,其核函数包括线性核函数、多项式核函数、径向基核函数和S形核函数,研究表明径向基核函数的效果较优,通过自动寻优选择惩罚参数(C)和gamma进行模型构建[24-25]。
2.4 精度评价指标
采用决定系数(R2)、均方根误差(RMSE,公式中用RMSE表示)和相对均方根误差(rRMSE,公式中用RMSEr表示)对模型的预测结果进行评价。
(1)
(2)
(3)
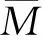
3 结果与分析
3.1 基于随机森林算法的变量特征筛选
基于93个森林蓄积量样本数据,使用随机森林算法进行变量的筛选,由于提取的变量较多,使用随机搜索进行随机森林的参数优化,构建随机森林模型,并计算各变量的重要性(VIP值),选取累计贡献率达到85%的变量参与回归模型的构建,结果见表3,由表3可知,通过特征的选择,自变量个数由76个降低到了15个,显著降低了自变量的维度,从而能有效提高后续模型构建的效率;在所有入选的自变量中,主成分分析的第2波段PC2对因变量的贡献率较高,VIP值为45.68%,其次为有效叶面积指数SLAVI,VIP值为12.52%,其余的变量VIP值均小于10%,说明第2主成分PC2和SLAVI对蓄积量估测的影响最为重要。
表3 遥感变量VIP值
3.2 结合暗哑变量的回归模型的构建
根据自变量的筛选结果,以累计贡献率大于85%的15个遥感变量为自变量,并以龄组为哑变量,由于不同龄级样本数分布不均,通过对93个不同龄组的样本数据的单因素方差分析和差异性检验将幼龄林和中龄林分为一组(A=0)、近熟林和成熟林分为一组(A=1),然后分别构建SVR模型和PLSR模型,在SVR模型构建时通过寻找最佳c参数和g参数完成模型的构建;PLSR模型构建时当主成分个数对应的交叉有效性小于0.097 5时终止算法,采用留一交叉验证对结果进行验证,模型的拟合结果和交叉验证结果见表4。

表4 模型拟合结果
从估测结果来看,不同的估测模型在加入哑变量后估测精度相较于无哑变量时有明显的提高,根据不同的哑变量模型拟合结果,无哑变量SVR模型的决定系数R2为0.59,均方根误差RMSE为30.5 m3·hm-2,在加入哑变量后,模型的决定系数R2从0.59提高到了0.68,均方根误差RMSE从30.50 m3·hm-2降低至27.36 m3·hm-2,R2提高了15.25%,RMSE降低了10.3%;PLSR模型在哑变量的引入后R2从0.53提高到了0.62,RMSE从32.70 m3·hm-2降低至29.25 m3·hm-2,且2种模型的交叉验证结果在引入哑变量后验证精度均高于无哑变量时的精度;其次,对比2种模型的拟合精度和交叉验证精度,SVR的估测精度均大于PLSR,在哑变量模型中SVR的估测精度较PLSR模型高2.27%,主要由于自变量与因变量存在一定的非线型,但两者总体差异并不大。
根据图1-图4的散点图的变化发现,无论SVR还是PLSR在有无哑变量引入的情况下均存在低估和高估现象,但哑变量的引入后(图2、图4),2种模型的估测结果在蓄积量较小的部分较为收敛,这主要由于哑变量的引入对龄组进行了区分,改善了不同蓄积量大小在遥感因子下的响应灵敏度,从而提高了总体蓄积量估测精度,但也有部分点较为离群,结合数据源的特点分析得出,研究所采用森林资源二类调查的角规控制样地数据,角规测树的依据是同心圆原理,根据角规测量的公顷断面积计算得到单位面积森林蓄积量,而遥感影像的像元大小为30 m,因此单位面积的森林蓄积量与所对应的遥感影像信息存在一定差异;另外研究区地处亚热带季风气候区,区域内植被类型丰富,林下植被较多,在林郁闭度较低的情况下,林下植被的光谱也会对估测结果产生一定影响;其次,由于光学遥感数据的特性,随着蓄积量的增加光谱反射率信息逐渐达到饱和,可以看出,随着蓄积量的增加,高值低估现象越发显著,这是光学遥感的局限性之一。
4 结论与讨论
以森林蓄积量为对象,结合Landsat8 OLI遥感影像数据探究了哑变量技术在森林蓄积量遥感估测中的作用,研究表明,使用随机森林算法进行变量的选择能有效减少自变量的维度,提高模型构建的计算效率;以龄组为哑变量引入估测模型后,估测精度有明显提高,此结论与王宗梅等[13]、岳振兴等[14]的研究一致,同时本研究还对2个线性模型和非线性模型的估测结果进行了对比,发现SVR的泛化能力优于PLSR,估测精度相对较高,但两者之间的差别不大,此结论也说明哑变量技术的应用能有效提高森林蓄积量的估测精度。
从研究的整体来看,也存在一定的局限性。首先,样地数据来源于森林资源二类调查的角规控制样地数据,根据公顷断面积来计算单位面积蓄积量,样地数据获取过程中会存在一定误差,且93个角规控制样地数据的龄组分布不均,成熟林和近熟林的样本数较少,因此,在哑变量的划分上也存在一定的差别,同时数据调查时间较早,无法进行补充调查;其次,自变量的筛选使用随机森林进行筛选,方法较为单一且模型参数优化只达到局部最优,这导致变量的选取也存在一定的差异;从遥感数据源的角度来看,研究区植被类型丰富,地形沟壑纵横,在复杂的地形和植被条件下,影像的质量也会受到影像,同时光学遥感估测中的饱和问题以及林下灌草光谱一直是定量遥感中常见的问题。今后的研究中可考虑采用多模型组合,对模型进行全局优化,使用全局最优模型进行特征选择和森林参数的估测,另外,在样地数据获取过程中保证地面样本数据质量,数据源的选择上可考虑采用高精度的遥感数据或者多源数据结合。
