工程造价SVM预测的特征分析及编码研究
2022-02-08郭若礁闫中林郑天君
杨 惠,李 文,郭若礁,李 孟,闫中林,郑天君
(1.山东临港疏港轨道交通有限公司,山东 临沂 276624;2.烟台大学 土木工程学院,山东 烟台 264005)
随着计算机深度学习技术的发展,利用数据挖掘技术进行工程造价的快速预测得到了越来越广泛的应用。利用数据挖掘进行工程造价的快速预测可以提高建设项目的决策效率,实现投资效益的最大化。
作为数据挖掘重要组成部分的特征工程,在工程造价的数据挖掘预测中,更是扮演着重要的作用;特征选取合理,算法模型训练的性能就好,反之则模型性能就低。特征工程不仅包括特征选取,还包括特征构造、特征缩放、特征编码以及特征降维等[1],对于具有明确目的的工程造价预测问题,特征指标的选取主要还是依靠专业人员对业务场景的综合分析来确定,同时,也是一个反复的、试错的、迭代的过程。由于工程造价的影响因素非常复杂,因而特征指标的类型也多种多样,包括建筑、结构、装饰、基础、设计基准等各方面的特征,这些特征的原始数据需要转化为便于机器学习算法进行运算的特征数据,机器学习通过将特征数据拟合到数学模型中获取结论或做出预测。这一转化过程就是特征指标的量化和编码,量化和编码方式不同,工程造价预测模型的性能差异很大。
文章以广联达指标网中陕西省西安市2014年—2017年签约的住宅工程数据为对象,以支持向量机(SVM)算法[2]为预测模型,根据特征指标的属性,及其对工程造价的影响方式,对特征指标采取不同的量化和编码方式进行工程造价预测,预测结果证实了特征指标的编码方式对模型性能确有较大影响,同时,提出了有利于提高工程造价SVM预测模型性能的特征指标的编码方式。
1 数据收集整理及特征指标选取
通过对广联达指标网住宅工程造价数据的收集、梳理和清洗,选取其中160条样本构建SVM模型预测单方造价,模型样本分为训练集和测试集。为了避免数据出现过拟合与欠拟合问题,本研究选取其中127条数据(占比79%) 为训练集,33条数据(占比21%)为测试集[3]。
如前所述,特征选取和模型训练是一个反复试错的过程,笔者通过梳理住宅工程造价的影响因素,结合文献调研[4-8],经过反复试算,确定了住宅工程造价预测的特征指标,包括:工期、建筑外形、地上建筑面积、地下建筑面积、总建筑面积、檐高、结构类型、地上层数、地下层数、总层数、地上平均层高、地下平均层高、抗震烈度、是否有人防、基础类型、装修类别、三级钢筋占比、外立面装饰、室内装饰,共19个特征指标作为SVM模型的输入指标。
根据特征变量的数据类型,特征指标分为定性特征和定量特征,定性特征包括定类特征和定序特征两种类型;定量特征也有连续性和离散性特征两种类型;从统计分析角度,变量分为定类、定序、定距和定比4种类型。
基于特征变量的类型分析,以上特征指标中,工期、地上建筑面积、地下建筑面积、总建筑面积、檐高、地上层数、地下层数、总层数、地上平均层高地下平均层高以及三级钢筋占比等11个特征的原始数据是数值,可以看作连续型特征;结构类型、建筑外形、基础类型3个特征,如表1所示,则是具有排他性的定类特征;是否有人防、抗震烈度、装修类别、外立面装饰、室内装饰5个特征,如表2所示,对工程造价的影响在一定程度上存在一定的递进关系,因此可以看作定序特征。不同类型的特征指标对工程造价的影响方式不同,应该采取不同的量化编码方式。
2 特征指标编码方式
2.1 连续型特征的编码方式
对于连续型特征指标,即本文中所提及的11个定量指标,由于单位不同,其特征值相差较大,甚至可能是不同的数量级,如果不消除这种影响,很容易导致某些特征无法在模型得到应有的表达效果,从而导致预测偏差。为了避免出现这种情况,需要对原始特征进行无量纲化缩放,常用的方法有极差化与标准化。笔者采用极差标准化的特征缩放方式,对数据进行处理。
Xi’=(Xi-Xmin)/(Xmax-Xmin)
(1)
2.2 定类和定序特征的编码方式
定类特征和定序特征常用的编码方式有两种,一种是直接用自然数进行编码的常规编码方式,另一种是独热指标(One-Hot Encoding)方式。笔者分别采用了常规编码方式,独热编码方式和定类特征独热编码、定序特征常规编码的混合式编码方式进行SVM工程造价预测,发现混合式编码即方便了定类特征用自然数编码便于算法模型的定量计算,又考虑了定序特征对工程造价影响的递进关系,预测结果更加准确,模型性能更加优越。
2.2.1 常规编码方式。通过特征值组合,将结构类型、建筑外形、基础类型、是否有人防、抗震烈度、装修类别、外立。
面装饰、室内装饰8个特征的特征值划分成具有排他性的类别型指标,并对特征指标直接用自然数依次排列编码,并且在定序特征编码中按照对工程造价的影响程度从小到大的顺序进行编码,如表1和表2所示。这种编码方式简便易行,便于模型运算,是常见的编码方式。但由于“基础类型”“结构类型”“建筑外形”3个定类特征对工程造价的影响是多方面的,一般不存在明显的递进关系,这种编码方式相当于给不同特征人为赋予了数量差异,在一定程度上对模型性能产生不利影响。

表1 定类特征编码
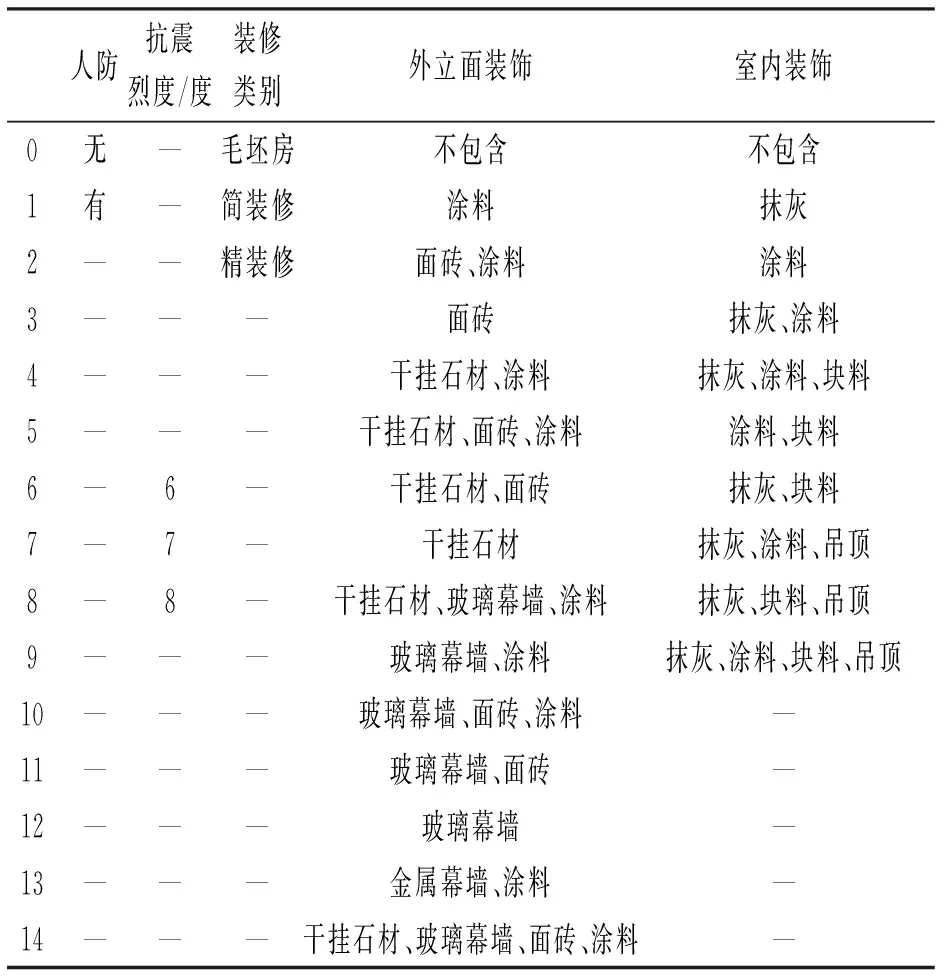
表2 定序特征编码
运用Matlab[9]软件测出该种编码方式的预测结果,图1为训练集单方造价预测结果,图2为测试集单方造价预测结果。分析结果的精度(R2)和均方误差(MSE)可知,训练集的预测结果精确度达到0.904 32,均方误差达到0.006 738 2,但测试集的预测结果为0.825 22,均方误差为0.006 952 1,精确度并不理想。
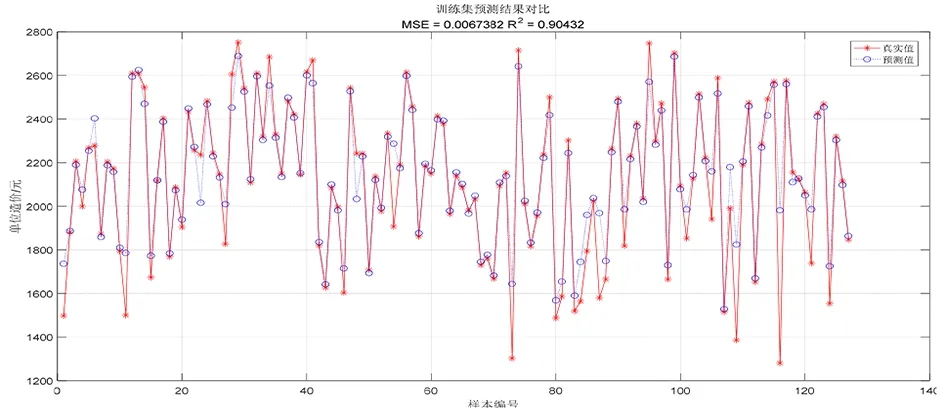
图1 常规编码SVM训练集单方造价预测结果
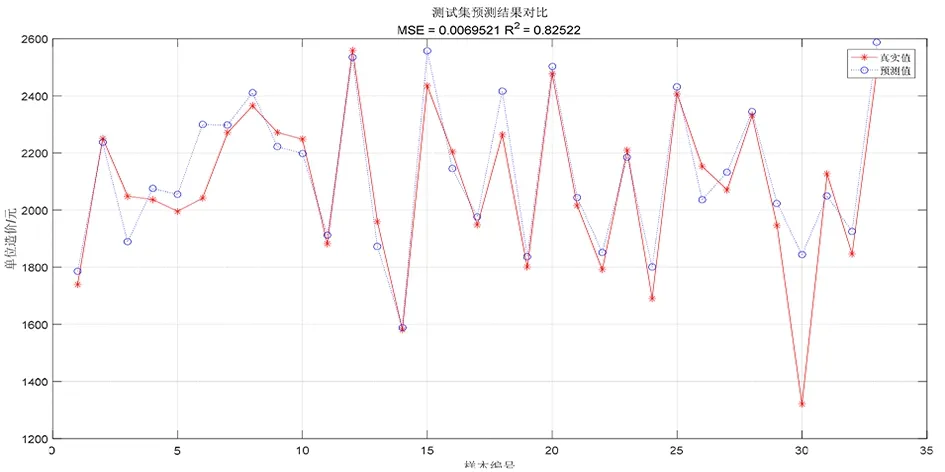
图2 常规编码SVM测试集单方造价预测结果
2.2.2 独热指标(One-Hot Encoding)编码方式。又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。即,只有一位是1,其余都是零值。可以这样理解,对于每一个特征,如果它有N个可能值,那么经过独热编码后,就变成了N个二元特征。
以“建筑外形”为例,有“塔式”“板式”和“异形”3个特征值,因此有3位状态编码,根据独热编码的编码规则,“塔式”编码为100,“板式”为010,“异形”为001。可以理解为“建筑外形”这个特征变成了“是否塔式”“是否板式”“是否异形”3个二元特征。
如果对上述8个特征按照独热编码方式编码,特征指标将会由原来的19个增加至42个,使计算维度大幅度增加。
经测试,训练集预测精确度为0.780 5,均方误差为0.0136 93,如图3所示;测试集预测精确度为0.599 76,均方误差为0.0163 59,如图4所示,结果均不理想。
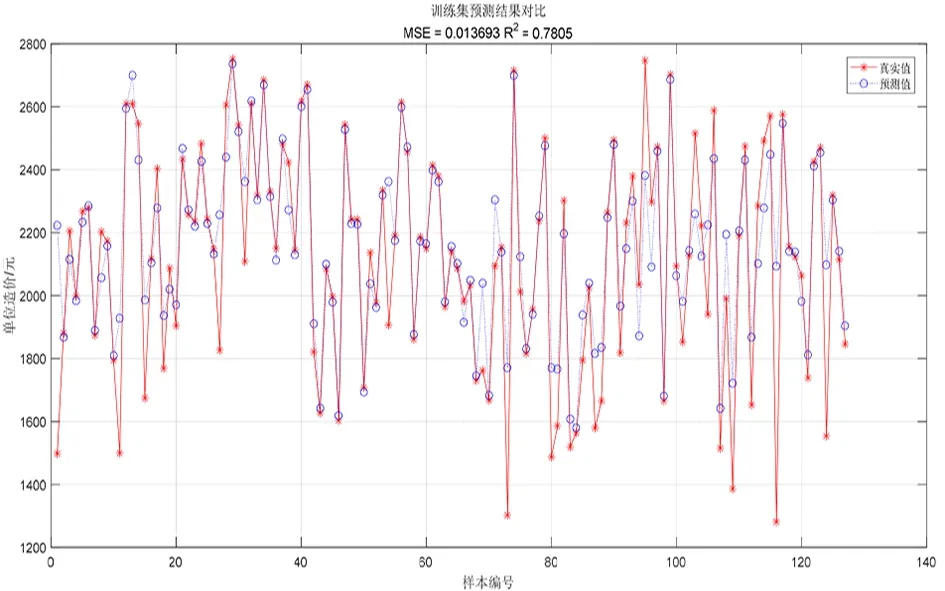
图3 独热编码SVM训练集单方造价预测结果
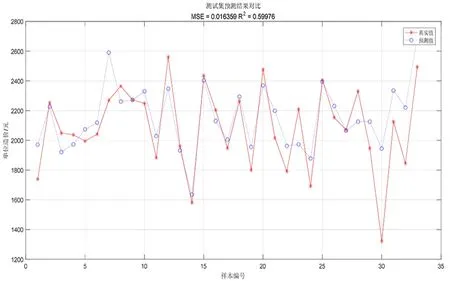
图4 独热编码SVM测试集单方造价预测结果
2.2.3 混合指标编码方式。为了避免单纯使用独热编码方式出现维度诅咒的问题,同时考虑定序特征对工程造价影响的递进关系,对“是否有人防”“抗震烈度”“装修类别”“外立面装饰”“室内装饰”5个定序特征,仍然采用按照对工程造价的影响程度从小到大的顺序用自然数进行编码的常规编码方式;对“结构类型”“建筑外形”和“基础类型”3个定类特征,采用独热编码方式,如表3所示。
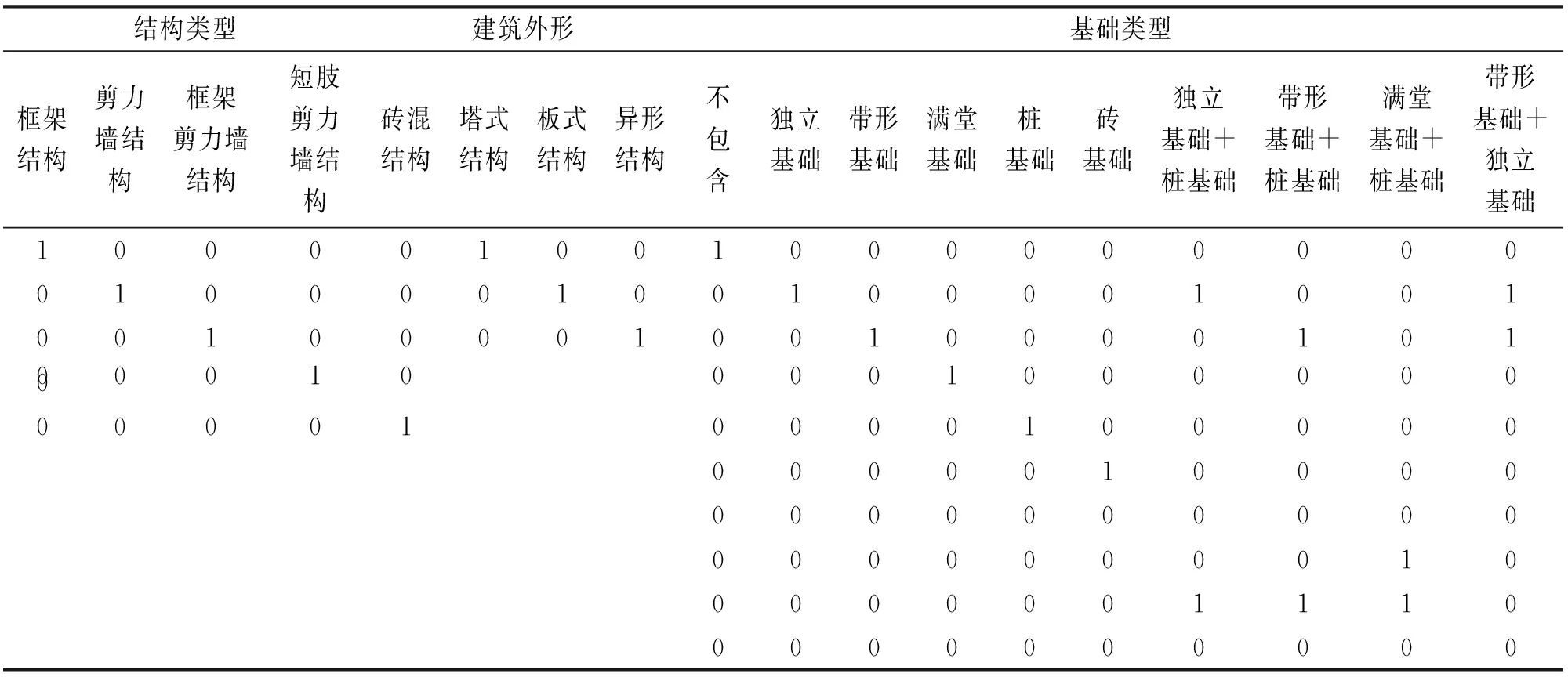
表3 混合指标编码
3 对比分析
以上3种编码方式的预测结果,如表4所示,混合编码方式训练集和测试集预测精度均在85%以上,是较为理想的预测结果,故在基于SVM算法的工程造价预测中,根据特征的类型和对工程造价的影响方式,采用不同的编码方式更为可行。
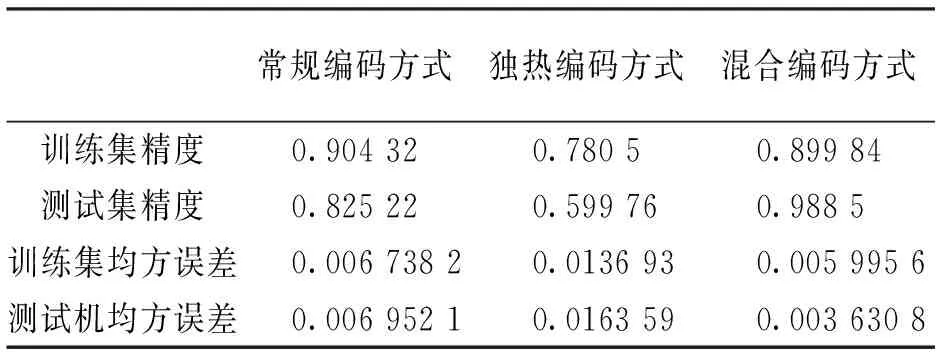
表4 结果对比
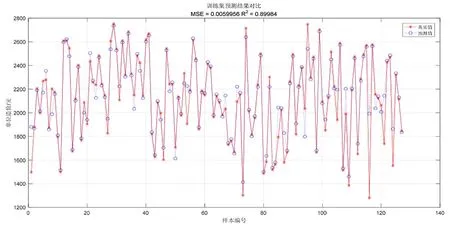
图5 混合编码SVM训练集单方造价预测结果
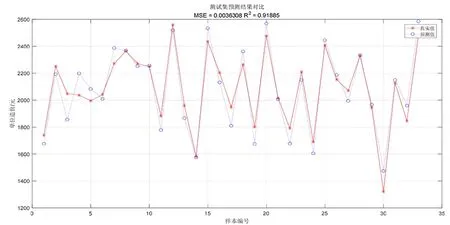
图6 混合编码SVM测试集单方造价预测结果
4 结束语
本文通过分析住宅工程的特征指标对工程造价的影响方式,对特征指标进行分类,提出了针对不同类型特征,进行不同方式的量化和编码的基本思路,对连续型特征采用特征缩放的方式,进行归一化处理是常用的方式;对类别型特征,采用独热编码的方式,可以消除自然数编码人为给特征赋予数量差异的问题,但同时会增加模型算法的计算维度,导致精度下降。因此,对类别型特征进一步细分为定类特征和定序特征,定类特征对工程造价的影响是复杂多元的,各特征值与工程造价的影响没有明显的相关关系,因此采用独热编码,比较合理,如基础类型、结构类型和建筑外形3个特征;但有些类别型特征,如“是否有人防”“抗震烈度”“装修类别”“外立面装饰”“室内装饰”等,其特征值与工程造价存在一定的相关关系,因此,按照对工程造价的影响程度,按照自然数从小到大的顺序进行常规编码量化,是合理的。
因此,在利用SVM等数据挖掘算法进行工程造价预测中,深入分析特征指标对工程造价的影响方式和影响程度,采用不同的编码方式,可以获得较好的预测结果。
