时序数据库在海量地震波形数据分布式存储与处理中的应用初探
2022-02-03陈通韩雪君马延路
陈通 韩雪君 马延路
中国地震台网中心,北京 100045
0 引言
近几年,随着国家对防震减灾要求不断提高,我国先后实施了多个大型地震监测工程项目,优化和加密观测台网和仪器。同时,随着物联网、云计算和地震预警技术的发展,更多非传统地震计类型的地面运动传感器的数据接入地震台网,用于地震实时监测和预警。国家地震烈度速报与预警工程建设完成后,地震监测台网中的台站数量将由约1300个扩充至15000个以上,其汇入中国地震台网中心的地震波形数据也将增长一个数量级,由约40G/天增至超过400G/天。因此,在原有单台服务器上存储和处理地震数据的方式已不适用,针对海量数据的汇入,探索分布式的数据存储和处理已事在必行。
传统的地震波形数据存储方式一般将连续波形数据记录以天为单位进行分割,将每天每个台站每个分量上的记录保存为一个miniSEED文件,这些文件按照“台网.台站.位置.通道.类型.年.天”的格式命名,并以“/年/台网代码/台站代码/通道.数据类型/文件名”的树形目录方式组织,存储于文件系统中。为了便于查询使用,可同时在关系型数据库中构建数据文件的起始时间、路径位置等信息表和数据包索引表。在请求数据时,可以Web服务接口或人工查询方式获得所需台站一定时间范围内的数据文件位置,进而下载数据进行处理。
当数据量激增后,数据处理效率受限于数据获取的快慢,而获取数据的速度依赖于数据存储方式,传统以文件形式将全部数据集中存储于大的磁盘阵列的方式,其处理效率会受限于服务器读写磁盘的速率。大量数据传输回本地既需要较长的传输时间,又给本地计算机处理增加了压力。近年发展的基于Hadoop分布式HDFS文件系统和HBASE分布式数据库,将数据分散到集群不同节点上分别存储,能够很好地解决地震数据存储容量不断扩张和数据高可用的问题。基于MapReduce、Spark等分布式并行数据处理平台,可将数据处理算法和模块以任务方式提交至数据存储所在的节点上进行分布式计算,有效解决大量数据传输瓶颈和单台服务器处理能力有限的问题。对于实时数据,Kafka、FLINK、Spark Streaming等流式处理框架能够分布式处理高流量、高吞吐量数据,进而降低实时处理延迟。Addair等(2014)和Magana-Zook等(2016)使用Hadoop、MapReduce、Spark对离线地震波形数据进行分布式存储,并以此为基础开展波形互相关、数据质量分析等分布式处理研究;Junek等(2017)在Hadoop架构上,使用Accumulo分布式数据库来替代miniSEED文件式存储并进行分布式处理分析;刘坚等(2015)、王丹宁等(2016)、郭凯等(2017)和单维锋等(2019)也分别针对地震波形数据,开展了基于Hadoop、HBase、OpenTSDB、Spark等通用大数据平台对地震波形数据存储与分析处理的研究。这些通用的大数据平台应用范围广,无论结构化或非结构化数据均能处理,尽管可以直接将其应用于存储和处理地震波形数据,但这些平台并未针对时间序列形式的地震波形数据进行优化,且平台涉及的软件系统种类较多、关系复杂、学习曲线陡峭,无论是存储还是处理地震波形数据效率均较低。
针对海量地震专业波形数据的存储和处理难题,本文尝试一种轻量级时序数据库技术,通过分析比较目前3个广泛使用的国产时序数据库系统的特点,提出基于时序数据库的地震波形数据存储和处理的技术方案,经过开发、测试和初步应用,能够较好地解决波形数据量激增所带来的存储和处理瓶颈,为未来地震预警中心海量波形数据的高效存储和处理探索新途径。
1 时序数据库的技术特点
时序数据库已广泛应用于物联网、车联网等领域,用于存储仪器设备的监控和实时采样数据。其是一种专用于存储时间序列类型数据的数据库,通常将数据按照产生的时间顺序排列,构造“时间戳|采样值”对,按设备编号以列的形式存储在不同表中,每张表及其多个备份分布式保存在多个服务器节点的多块硬盘中。作为一种新兴技术,其具备大数据技术平台的基本特征,如支持集群高可用,当数据库的部分服务器节点宕机后系统仍可用,保证数据完整和持续提供数据服务;支持集群节点水平扩展,在数据量增长后,通过简单的增加节点自动提升存储和处理能力;支持分布式处理,使用各节点数据及其副本进行在线查询和计算,大大提高数据查询和计算效率。同时,时序数据库可针对时序数据存储和处理进行优化(如按时间索引和多维度分区分表等)和预计算,相较于关系型数据库对时序数据的存储和处理,检索与处理效率大大提高。
目前最为流行的时序数据库为InfluxDB,但近几年来国内也涌现了诸如TDengine、DolphinDB、IoTDB等优秀的自主研发的时序数据库产品,其在读写、聚合查询、压缩性能等方面均达到或超过InfluxDB,且不同于以往的实时数据库一般只支持一主多备,现在的时序数据库支持集群和线性扩展,极大增强了数据存储和处理能力(表1)。

表1 TDengine、DolphinDB、IoTDB基本情况
分析 3 款国产时序数据库,总结时序数据库具备适用于地震波形数据的以下技术特点:
(1)数据高速写入能力。由于地震台站持续产生地面振动的海量波形数据,且在时序数据库中以“时间戳|采样值”两列的数据结构来存储,数据量不断增大。按照预警工程项目建设完成后实时接入1.5万个台站的4.5万道数据流、每道流每秒采集100条数据记录测算,数据库需实现每秒450万条记录的高速写入。时序数据库一般采用内存表或内置消息中间件缓存实时到达的数据,再执行并行批量统一落盘的机制,保证了每秒数百万条记录的高速写入。
(2)数据的高压缩率。地震数据的永久存储一般按年计,通过对列式存储的时序数据进行压缩,进而减少硬盘空间需求,亦或在同等硬盘容量下可存储更多数据。由于地震波形数据均为等间隔采样,且在无地震发生的情况下噪音的数值一般变化不大,这使得时序数据库能够高效压缩数据成为可能。
(3)快速响应能力。时序数据库通过数据分级存储方式达到快速响应的能力。实时热数据存储在内置消息队列或内存缓存中,近实时温数据保存在SSD硬盘中,以及大量的历史冷数据保存在机械硬盘中,三类数据的存储、检索依赖时序数据库的存储引擎自动管理,实现自动转存、统一查询等。
(4)时序数据处理的多功能集成。时序数据库系统能将数据库、消息队列、内存缓存、流式计算等功能融为一体,通过存储和处理引擎的管理和调度,既实现了实时数据的计算处理、结果的永久保存,又实现了历史数据的查询和批量处理。多功能集成减少了数据在消息队列、数据库、流计算等不同软件系统间传输所带来的性能和时间损耗,为实时全量数据处理提供了更简捷的解决方案。此外,由于无需集成Kafka、Redis、HBase、Spark、HDFS等大数据通用软件,开发运维复杂度也大幅降低。
(5)支持基于时间窗的聚合函数和用户自定义函数或插件。在实时/历史地震数据处理时,通常会使用一段固定时间长度的波形数据进行计算,如使用最大值函数(Max)计算固定时间窗内地面运动的峰值速度。时序数据库为用户提供自定义函数(UDF)或插件,可在数据库内实现处理地震数据所需要的函数,并通过数据库脚本,将相关处理函数串联形成较复杂的地震数据处理流程。
(6)支持多种触发机制和有历史状态的流式计算。地震波形数据尤其是实时波形数据的计算,经常依赖时间触发或数据到达触发相关的处理,其触发机制可总结为以下几类:①数据事件触发,例如每当流入一个波形数据包时触发处理(适用于时效性较高的震相检测业务);②时间窗触发,例如设定1s时间窗,每当流入的最新数据达到1s后便触发相应计算(适用于每秒地震动峰值计算业务);③定时触发,例如每天0:00、0:05、0:10、…、23:55相隔5min触发启动网络传输延时的统计计算。触发后的处理计算不仅依赖于当前的输入数据,而且能保存之前不间断处理过程产生的历史状态,例如常用的实时震相检测算法STA/LTA(Allen,1982)、FilterPicker(Lomax et al,2012)均涉及新输入数据加历史状态的迭代计算,随着新数据流入的触发,震相检测程序既输出新的特征函数值,同时也更新迭代公式中的中间变量,这些中间变量作为历史状态值保存,与之后新到的数据一起进入新一轮迭代。时序数据库的实时数据和历史状态数据的缓存技术、数据订阅机制以及支持多种触发机制的计算引擎能够支撑较为复杂的地震实时处理需求。
中国地震台网中心的地震波形数据主要是指由国家地震台站、各省区域地震台网等地震观测网络系统中地震计采集并传回中心的数据,其具有典型的时序数据特征:①数据按时间顺序等间隔产生、持续传输并存储、一般无更新和删除操作;②采样频率快,10ms间隔采样一次;③地震传感器多、数据流量大,目前接入超过15000个台站,传回的未经任何处理的原始miniSEED文件数据量超过1T/天;④一次读取的数据量大,绘制一条24h波形曲线需要读取860万条采样点数据。地震波形数据是开展地震监测预警、数据分析与挖掘、地震异常研判等应用的基础材料,数据应用的基本需求包括地震数据归档存储和检索、历史地震事件波形分析、实时波形数据处理等。结合上述时序数据库特点和地震波形数据应用需求,本文设计并实现了针对地震波形数据和地震业务需求的基于时序数据库技术的存储和处理系统。
2 系统设计方案
地震时序数据库系统架构分为三层,总体框架如图1所示。其中,最下层为数据层,包括多块本地磁盘,用于存储地震波形数据和描述数据包的元数据(如数据包到达时间、包中采样起始时间、实际采样点个数等)。中间层为时序数据库的核心组件,包括内存表和消息队列,可为实时数据接入提供缓存空间,既便于计算引擎开展实时处理,也便于存储引擎并行将数据在磁盘中永久存储;计算引擎实现了基于数据流的触发计算、滑动窗计算等功能,存储引擎实现了磁盘的高速读写和数据快速检索。上层为业务层,其中时序数据库中提供的自定义函数或插件功能作为计算和存储引擎的程序接口,允许用户定制开发数据库内置的处理函数和插件,再通过脚本和SQL查询语句的混合编程方法,可将多个自定义函数及SQL检索的命令串联形成较复杂的地震数据处理过程。目前,业务层包含地震流数据接入、解析与存储模块,元数据存储模块,波形数据处理工具模块,实时震相到时拾取模块,历史数据三分量能量比计算模块等5个主要应用模块,模块具体功能如下:

图1 地震时序数据库系统的总体框架
(1)地震流数据接入、解析与存储模块实现从地震实时流服务器接收地震波形数据包,并从miniSEED数据包中解析出每个采样点的数值,以“时间戳|采样值”对的形式存入内存表或消息队列,之后存储引擎自动转移存储至硬盘中。
(2)元数据存储模块负责存储每个入库的miniSEED数据包的描述信息,包括数据包的ID号、数据采集的起始时间、数据包到达服务器时间、包内实际采样点数、包内预期采样点数(miniSEED包头段信息中标识的采样点数)等,这些信息的留存使得分析数据实时传输延时、乱序等情况成为可能。
(3)波形数据处理工具模块将常用的地震波形处理函数,如滤波、去均值、去趋势、互相关等集成至数据库处理工具集中,可直接在类SQL语句中使用这些处理函数,函数的实现采用时间阈迭代公式,既可应用于实时数据,也可以对离线数据进行处理。
(4)实时震相到时拾取模块,将基于多频带滤波方法的FilterPicker震相拾取程序作为计算插件集成至数据库中,可对实时入库的数据包进行快速震相到时检测。当数据包流量较大时,计算引擎可触发多个FilterPicker模块并行处理,并将检测出的震相到时存入相应的表中。
(5)历史数据三分量能量比计算模块,三分量能量比计算同一台站一天内每5min窗口东西、南北、上下3个分量能量中每2个分量的比值,保留这些能量比的中位值,通过分析中位值随时间的变化来判定地震仪器是否正常工作(Pedersen et al,2020)。
3 系统测试和功能检验
在2台服务器上搭建地震时序数据库测试系统,其中一台服务器既作为管理节点,也作为数据节点,另一台服务器仅作为数据节点,服务器配置如表2所示。测试实时接入地震预警台网15000余个台站、45000多道数据流的数据。虽然测试使用的服务器数目较少,但每台服务器上安装了多块硬盘,通过I/O高并行度来提高数据库的读写速度。另外,服务器配备了一块读写速度较快的SSD硬盘作为内存与硬盘之间过渡的存储介质,用于提高系统整体的响应速率。

表2 数据库服务器硬件配置
3.1 波形数据与元数据存储
地震波形数据是观测站点处传感器记录的地面运动速度或加速度通过数据采集设备放大和数字化后得到的。通常每个观测点产出2个水平向、1个垂直向共3个通道的数据流。站点的位置由其所属台网代码、台站代码和测点位置号码决定。这一数据流的台网代码、台站代码、位置号码、通道号码四分量标识存在于每个数据包的包头中(中国地震局,2003)。在地震时序数据库中,针对每一道数据流建立一张数据表,如表3所示,表名由台网(network)、台站(station)、位置号(location)、通道号(channel)4个分量联合组成(如JL_ZXT_00_SHE);表中仅有两列,一列为时间戳,另一列为该时间点的采样值。地震波形数据包的元数据也独立成表(表4),表中每一个数据包为一行,表中各列包含数据包的多种描述信息,包括数据采集时间、数据接收时间、包内实际采样点数、包内预期采样点数。整个系统共有45000余个数据表,存储45000余个地震数据流;共有45000余个元数据表,存储45000余个数据流中每个数据包的描述信息。

表3 地震波形数据存储表(以表JL_ZXT_00_SHE为例)

表4 地震波形元数据存储表(以表JL_ZXT_00_SHE_META为例)
我们在TDengine时序数据库平台上研发了从地震预警快流服务器通过HTTP协议获取地震数据包的程序,解析每个miniSEED包所属的“台网/台站/位置号/通道号”和采样起始时间、采样率等信息,根据“台网/台站/位置号/通道号”标识将波形数据写入对应的数据表中(表3),并将数据包到达时间等信息写入元数据表中(表4)。
实时数据流接收和存储模块连续运行15天,每天入库约4000亿采样点的记录,与预警系统归档的数据文件对比,没有数据缺失。且数据库文件与归档的miniSEED格式文件占用磁盘空间接近,以四川九寨沟台三分量30天连续波形历史数据为例,miniSEED文件大小约693MB,对应数据库文件大小约623MB,显示波形数据存储具备较好的压缩性能。
3.2 地震波形数据连续率统计
波形数据连续率和延时情况是衡量数据质量的重要指标,只有当地震台站观测的波形数据连续率较高、延时较低时,才能保障监测预警业务的正常运行。在统计预警地震波形数据的连续率时发现,一般台站(传感器为简易烈度计)的波形数据存在重叠和缺失,因此在统计数据连续率之前,必须对数据包进行排序和去重处理。原有的业务模块采用了离线的工作模式,积累一天全部台网所有台站的连续波形数据包后再进行批量计算。我们在地震时序数据库系统中实现了连续率的实时统计计算,在波形数据包入库时,已将“时间戳|采样值”对形式的数据进行了去重和排序,且将数据按台站/时间行分块存储,并在分块的元数据信息中保存了采样点数信息。因此,在统计数据一天的连续率时,可使用时序数据库中的count函数快速查询到指定台站和指定时间段内采样点个数。由于count函数通过查询分块的元数据集中采样点数信息并求和实现,比直接统计某一台站表中的行数更快。图2显示2021年8月29日地震预警先行先试的5个省和随机抽取的5个省所有分量数据(共18870道波形)的3个百分位的连续率,统计用时仅需90s,而原有离线文件处理方式则耗时超过30min。

注:SC四川,YN云南,BJ北京,HE河北,TJ天津,FJ福建,GD广东,XJ新疆,GS甘肃,JL吉林。
3.3 数据包到达延时统计
使用地震时序数据库中数据包的元数据表(表4),可直接统计每个数据包的延时,计算公式为:数据包延时=数据包到达时间-包中最后1个采样点时间。
使用TDengine和DolphinDB两个时序数据库系统中存储的2021年8月16—21日每天12:00—13:00数据包的元数据表统计延时,并按照每道数据流中数据流的90%分位延时值的分布绘制小提琴图(图3),可以看出2个时序数据库的数据包延时绝大多数在2s以内。
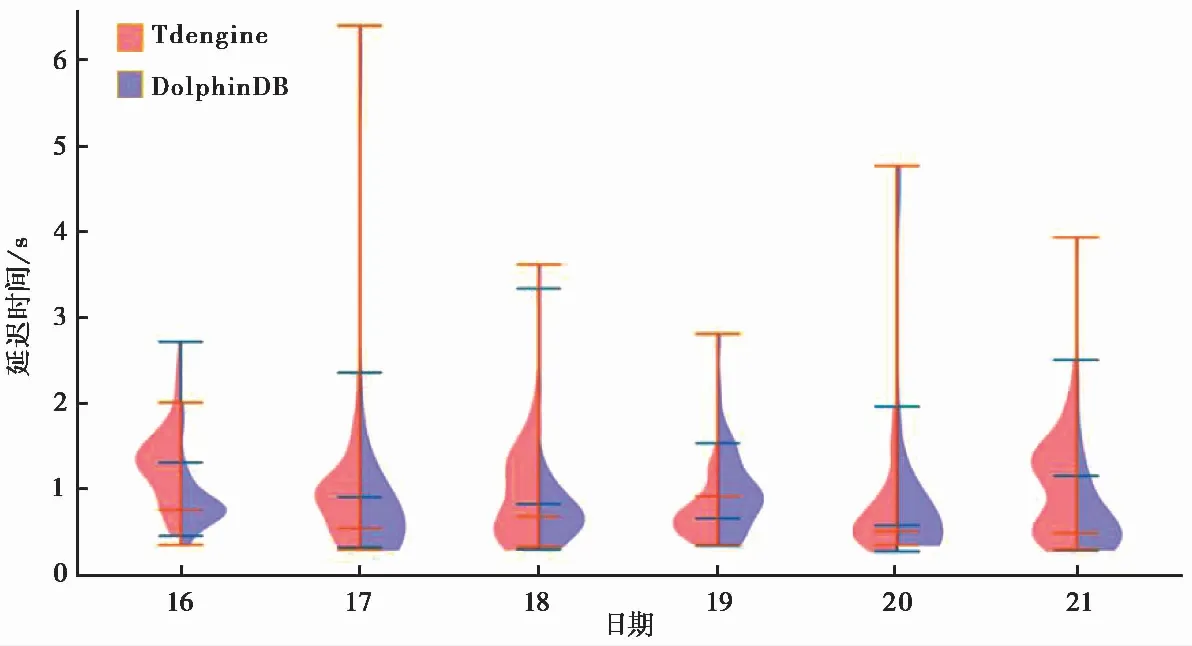
图3 2021年8月16—21日12:00—13:00数据流延时分布
3.4 FilterPicker模块检测
将FilterPicker作为插件集成至时序数据库中,对流入数据库的全量实时数据进行震相到时检测,并将检测结果按照每个分量一张表存入相应表中。图4展示了QH.MAD.00.BHZ分量震相到时检测结果,结果表分为2列,一列为震相到时时间,另一列为震相到时检测的时间。

图4 FilterPicker插件实时检测震相到时结果
将地震时序数据库中QH.MAD.00.BHZ分量2021年6月7日0时至8时的FilterPicker检测震相结果与FilterPicker源程序对相同离线数据震相检测结果进行对比(图5),可以看出实时数据和离线数据检测结果基本一致,FilterPicker源程序离线检测的震相到时为113个,时序数据库Filterpicker插件实时检测的震相到时为119个,其中113个与离线计算结果一致,6个为实时计算独有的震相到时。

注:(a)离线波形数据和FilterPicker离线检测的震相到时(红色短竖线);(b)时序数据库实时波形数据和FilterPicker实时检测的震相到时(红色短竖线),红圈内为实时检测独有的震相到时。
3.5 地震波形三分量能量比计算模块测试
对2012—2019年四川九寨沟台历史波形数据进行能量比计算,首先将离线历史波形数据导入时序数据库,然后应用波形处理工具模块中的滤波、去趋势等函数对数据进行预处理,之后使用时序数据库的聚合功能,将连续波形以5min窗进行分割,对每个窗口内数据的采样值进行平方和的聚合计算,求出各分量能量平方和的比值,最后对一天内288个5min窗口的比值再一次聚合取得中位数。地震时序数据库在计算时,计算引擎采用map-reduce方法,将编写好的处理脚本分发至各服务器节点并发处理分布在各自服务器自身硬盘上的数据,计算结果如图6所示。可以看出2015年8月和2017年7月出现能量比异常,对比台站运行维护记录,同期均出现地震计故障、标定异常的故障报告。

图6 2012—2019年四川九寨沟台三分量能量比计算结果
我们还对比了时序数据库程序和原有串行程序计算波形数据三分量能量比的计算效率(表5),对比数据采用2017年8月四川九寨沟台波形数据,原有串行程序也运行在时序数据库的服务器节点上。实验表明,地震时序数据库将波形数据分布式保存,地震数据处理算法在数据库内实现后,可充分利用多节点并行处理数据。另外,与大量数据相比,处理脚本属轻量级,可以较快地分发到各个服务器节点上进行处理计算,最后仅需返回最终计算结果,这种处理模式比原有地震业务先将所需大量波形数据下载至本地后再进行离线计算的方式更有效率。

表5 三分量能量比计算程序计算效率对比
4 结语
本文设计并实现了针对海量地震波形数据的地震时序数据库系统,其中包含多种地震业务功能模块。海量地震波形数据分布式存储在集群的各个硬盘上,处理程序也能够分布式处理,大大提高了数据的存储和计算效率。地震时序数据库既拥有大数据集群系统的高可用性,同时又对地震波形数据的存储和检索进行了优化,对分析处理海量波形数据工作具有较好的应用前景。
