神经网络架构搜索发展综述
2022-02-02潘晓英戚玉涛
潘晓英,曹 园,贾 蓉,戚玉涛
(1.西安邮电大学 计算机学院,陕西 西安 710121;2.西安邮电大学 陕西省网络数据分析与智能处理重点实验室,陕西 西安 710121;3.西安电子科技大学 计算机学院,陕西 西安 710071)
近年来,在人工智能产业的兴起和快速发展的背景下,机器学习领域成为当下研究热点。机器学习研究领域主要包括统计机器学习[1]和深度学习[2]两方面内容。统计机器学习在数据预处理、特征工程和模型选择等方面需要人工搭建网络才能完成。在深度学习领域中,所需要的神经网络结构通常情况下也是人工设计,为了得到一个性能较好的神经网络结构,需要耗费大量计算资源,因此出现自动化机器学习[3](Automated Machine Learning,AutoML)用以解决此类问题。AutoML的研究目标是机器自动学习并对神经网络架构搜索(Neural Architecture Search,NAS)数据训练和超参数优化等做出相应的决策,以获取最佳方案。
自动化深度学习作为AutoML的分支,其目标是通过元学习[3]的方法让机器学会自动调参优化,不仅受到机器学习研究方面的关注,而且还在计算机视觉[4]、数据挖掘[5]、图像分割[6]和自然语言处理[7]等方面有着广泛应用。NAS作为自动化深度学习的研究前沿,具有广阔的前景,其研究重点是根据当前问题的特点,通过机器自动搜索网络中性能更好、表现最优的结构,与传统人工设计网络相比可以降低花费的时间和人力成本等,并可以进一步提高搜索效率和神经网络的性能。拟以发展时间为线,简述神经网络架构搜索发展过程,结合算法所需的实验条件,对各种算法进行整理归纳,从多角度探讨NAS的发展变化,着重分析典型神经网络架构搜索算法的特点和不足,并对研究内容进行总结,探讨神经架构搜索技术未来发展趋势。
1 神经网络架构搜索简述
在深度学习领域的研究历程中,网络结构总是由简单到复杂,由浅显到深入,从最初的LeNet[8]到AlexNet[9]、VGGNet[10](Visual Geometry Group Network)、GoogLeNet[11]以及深度残差网络[12](Deep Residual Network,ResNet)。随着网络深度加深,模型结构也变得越来越复杂。尽管这些网络模型表现良好,但人工设计的网络模型调参优化工作非常耗费人力物力。网络结构参数以及众多的超参数形成的爆炸性组合使得优化难度呈指数型增长。因此,构建高效的神经网络结构以及进行高效的网络搜索对网络模型十分重要。
NAS的机制是在特定的数据集上从零开始采用一定的策略自动构建性能良好的网络模型。一般NAS问题可以被定义为搜索空间、搜索策略和性能评估等3个子问题。通过搜索空间构建网络框架,采用相应的搜索策略进行网络结构搜索,并对搜索得到的网络进行评估,根据评估结果进行反馈更新搜索策略。NAS结构示意图如图1所示。

图1 NAS结构示意图
以基于循环神经网络(Recurrent Neural Network,RNN)的神经架构搜索为例,神经网络架构算法根据数据集生成特定的“子网络”,并对子网络进行训练,得到该子网络在验证集上的准确度,将该准确度作为反馈信号,计算策略梯度更新RNN控制器。在下一次迭代中,控制器为具有更高准确率的网络结构提供更高的概率,即控制器将学习如何随着时间改进其搜索网络空间。
搜索空间构建是网络框架的主要部分,搜索空间的设计是实现网络性能高低的关键因素。传统的网络结构以链式为主,在网络结构多样性方面有所欠缺。2016年Zoph等[13]首次使用强化学习机制自动产生了一个最优的神经网络,开启了机器自动搜索神经网络架构的新领域,通过一个可变长度的String连接网络的结构和循环体内部。在此基础上,Zoph等[14]基于Cell单元结构设计了NASNet。NASNet搜索空间在空间多样性和可迁移性方面有了较大的提升,以适用于更大的数据集。由此,搜索空间的设计从前期的以链式结构,发展为现在主要以Cell单元结构为主。
搜索策略主要是解决用高效的方法搜索出性能更佳的网络。NAS最早是使用强化学习[15]进行搜索。除强化学习外,2017年Real等[16]首次将进化算法引入用来解决NAS问题,并被证明了在数据集上具有较高的精度。同时,贝叶斯优化和基于梯度的方法也被引用到解决神经架构参数优化问题中,取得了一定的成果。
性能评估主要是采用一定的方法和改进策略,提升计算效率并且降低资源消耗,加速搜索最佳网络的进程。2017年Brock等[17]提出SMASH(One-Shot Model Architecture Search through Hypernetworks),利用超网生成权重,训练整个网络。为了加快单样本的学习能力,2018年Bender 等[19]对One-shot模型进行了详细的研究。同年,Pham等[18]采用权值共享的方法,对神经架构进行训练。Liu 等[20]采用代理模型指导结构空间搜索。2019年Liu等[21]提出基于可微分的方式将分散空间进行连续性表示,采用梯度下降的方式搜索结构。目前,神经网络架构搜索涉及的研究重点内容主要是搜索空间、搜索策略和性能评估等3方面,下面将从这3个方面对神经网络架构搜索问题进行详细的描述,并对不同的策略和算法进行讨论总结。
2 搜索空间
搜索空间是由网络结构的深度、操作的类型、连接的类型、核的大小和过滤器数量等参数构成的网络集合,在集合内组合各种操作产生网络架构。不同的操作会产生不同的网络架构,因此构建一个合适的搜索空间,便于高效找到最佳的网络结构。
搜索空间根据空间单元结构可以分为宏(marco)搜索空间和微(micro)搜索空间。宏(marco)搜索空间指的是在给定的空间下进行搜索,网络深度是固定的,由人为设定搜索空间,在人为设定网络层数的基础上进行网络训练和参数优化。从最初设计只有5层的LeNet[8],到20层的GoogleLeNet[11],再到引入152层的ResNet[12],人工设计的神经网络多采用链式结构或者多分支结构,随着网络深度的不断加深,产生的参数也越来越多,消耗了大量的人力物力。于是,微(micro)搜索空间被提出,其将搜索空间设计成一个Cell单元结构作为基本的空间单元,Cell单元内包含若干选择块,不同功能的选择块代表块内不同的操作。Cell单元结构示意图[16]如图2所示。
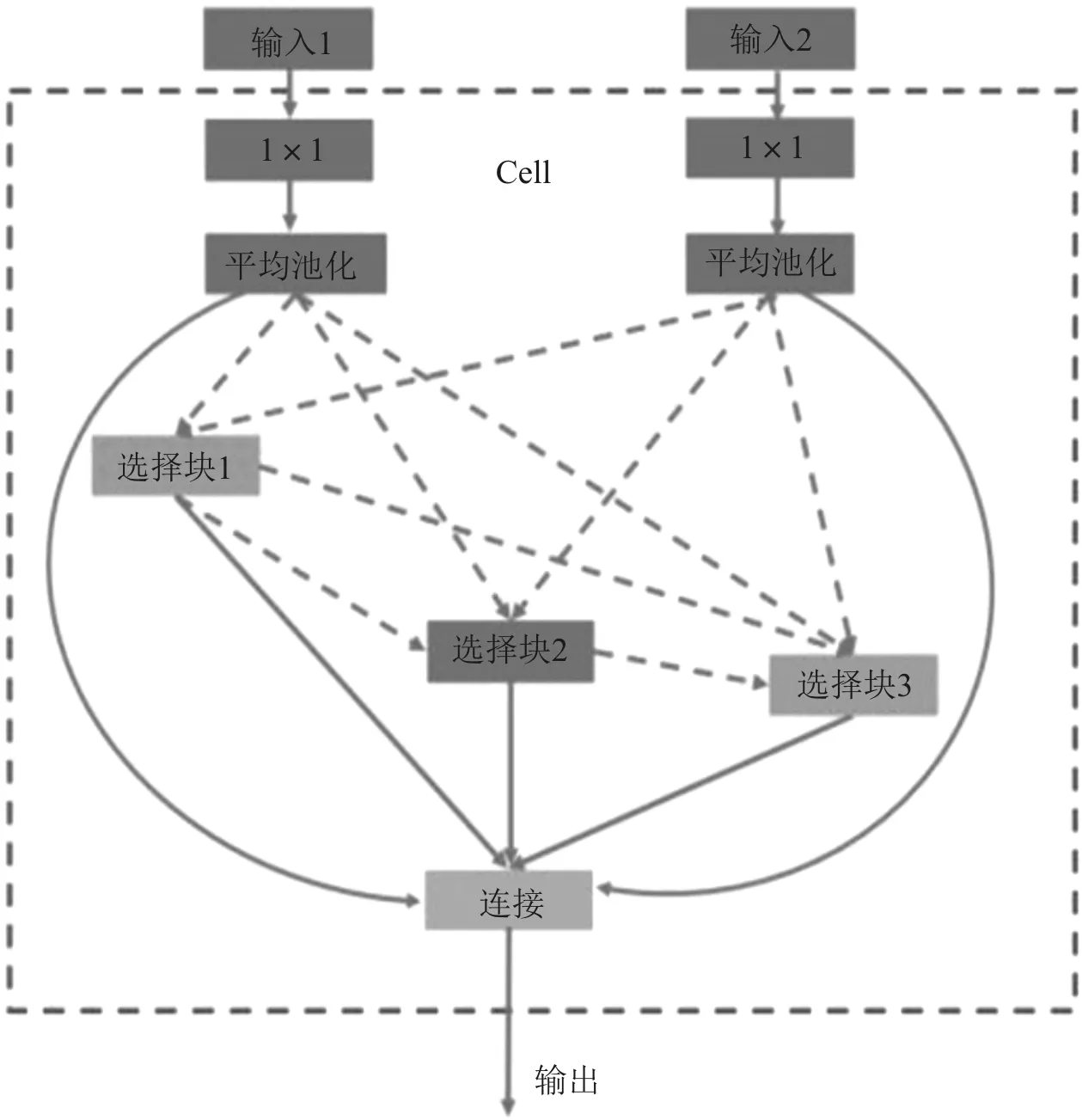
图2 Cell单元结构示意图
使用Cell作为空间堆叠的基本单元,在搜索过程中降低了搜索成本,同时增加了搜索空间的空间多样性。Zoph等[14]在NASNet中间设计中采用Cell-based结构进行网络堆叠,后续的SMASH[17]以及One-shot模型等也相继采用Cell单元结构进行网络构建。目前,搜索空间的研究内容主要是链式结构、多分支结构以及基于Cell-based结构。
2.1 链式结构
链式结构是目前较为常见的一种网络架构,LeNet[8]、AlexNet[9]和VGGNet[10]等都采用链式结构,网络的每一层和相邻的操作层相连,其结构示意图如图3所示,L0…Ln为每层的操作,卷积或池化。

图3 链式网络结构示意图
链式网络结构采用N层顺序结构,每一层提供卷积和池化等可供选择的操作算子,每种操作算子中包含卷积尺寸大小和卷积步长大小等超参数。在网络训练的过程中,随着网络深度的加深,网络结构更加复杂,容易出现梯度消失等问题。
2.2 多分支结构
随着研究者对网络结构的研究,发现网络结构的深度达到一定程度后,再进行增加层数的操作,并不能进一步提高分类性能,反而会造成网络收敛变得更慢、梯度消失等问题。为了缓解梯度消失的问题,便出现了人工手动设计的网络架构,用以研究带有多分支的网络,其结构示意如图4所示。
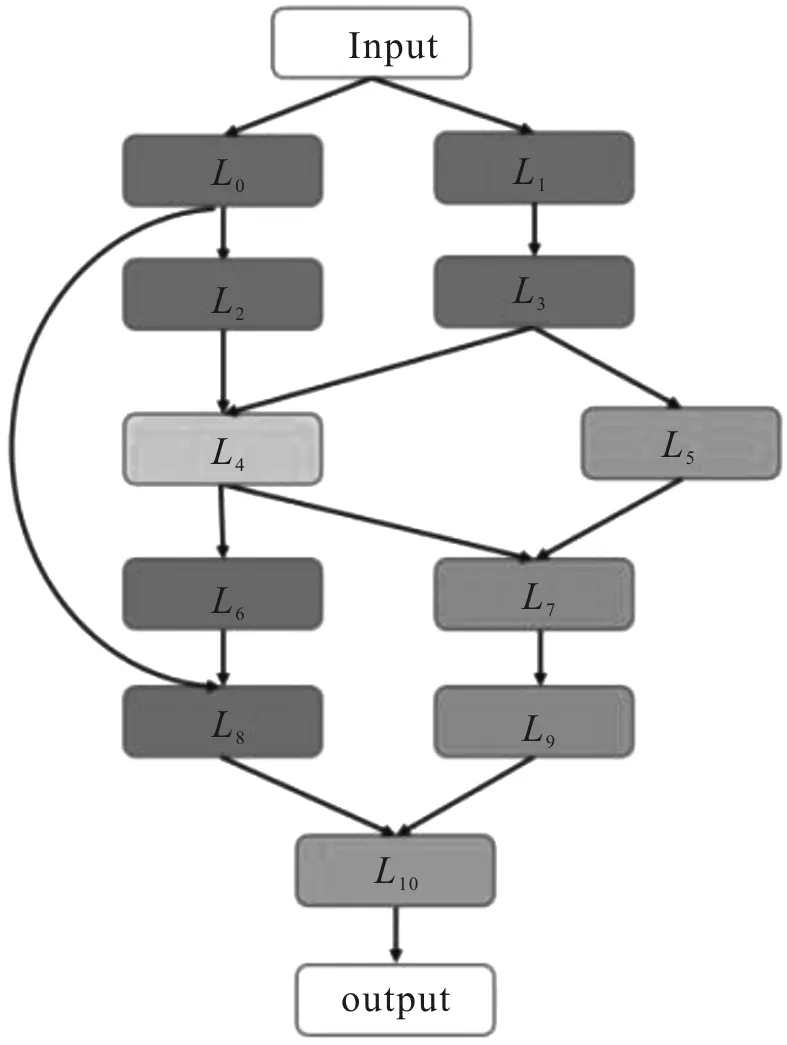
图4 多分支网络结构示意图
GoogleLeNet[11]引入多分支结构,增加了网络的深度和宽度。ResNet[12]引入Skip-connection操作,该操作被用来解决网络层数比较深的情况下梯度消失的问题,同时有助于梯度的反向传播以达到加快训练的效果,并且可以用以构建更为复杂的网络结构。DenseNet[22]在此基础上构建网络,网络中的每一层输入来自前面所有层的输出,减轻了梯度消失问题,构建的网络特征传递更加有效,网络更容易训练。
2.3 基于Cell单元搜索空间
基于Cell单元是通过重复堆叠固定的Cell单元进行网络构建,这样的架构一般是较小的单元结构堆叠起来形成较大的网络架构。这些重复堆叠的结构被称为单元(Cell)或选择块(Block),单元或者选择块内包含一些计算操作,比如卷积(Conv)、平均池化(Avgpool)、最大池化(Maxpool)和跳跃连接(Skip-connection)等。目前,很多的深层卷积神经网络(Convolutional Neural Network,CNN)或RNN架构中都有类似Cell堆叠的网络结构,其示意图如图5所示,虚线框表示一个Cell单元,Cell内的选择快可以是同一类操作拼接,也可以是不同类操作拼接。尽管网络结构很深,但是主体结构还是由Cell单元重复堆叠形成,将Cell单元结构单独抽象出来之后进行研究,可以使得复杂的网络结构变简单,这样操作的目的一方面可以减少需要优化变量的数目,在另一方面具有同等结构的Cell单元可以在不同任务之间进行迁移训练。

图5 Cell堆叠的网络结构示意图
NASNet[14]采用基于Cell单元搜索空间结构,通过在预先定义的排列中重复Cell单元结构构建网络。为了构建可扩展的神经网络架构,当使用某个特征图作为输入时,有两种类型的卷积单元:1)正常采样单元(Normal Cell),不改变特征图的大小;2)半采样单元(Reduction Cell),将特征图的长度和宽度各降低为原来的一半。NASNet使用强化学习的方法不断迭代产生参数,用以更新RNN控制器,搜索在不同数据集上,由Normal Cell和Reduction Cell堆叠生成的网络结构,NASNet弥补了前期基于RNN循环体的NAS的不足,适用于更大的数据集,比如ImageNet、PTB(Penn Tree Bank)等,使其具有更好的迁移性。NASNet[14]在CIFAR-10数据集和ImageNet数据集上的搜索结果示例如图6所示。

图6 NASNet在数据集上的搜索结果示例
虽然NASNet设计的网络结构取得了不错的效果,网络结构更加密集,但是网络结构中关于Normal Cell和Reduction Cell的位置和数量以及大量参数都是人为设计的,即在人为设定的框架下进行“自动”搜索,对于自动搜索的研究还是有待提高。2018年,Pham等[18]提出使用一个有向无环图表示搜索空间,选取其中不同的操作实现不同的Cell结构,即高效神经架构搜索(Efficient Neural Architecture Search,ENAS),其最大的特点就是参数共享,选择子网后在已训练的模型上继续训练,节约了大量的计算时间。如果将Cell作为一个层次,那么组合成的Cell结构也可以被看做一个层次,因此,基于Cell结构的方法提出的基于分层(Hierarchical)思想,极大减少了冗余空间的搜索[23]。渐进式神经架构搜索[20](Progressive Neural Architecture Search,PNAS)继承了NASNet的方法,以Cell作为基本的网络架构,在Cell内选择块(Block)作为基本单位,使用渐进式搜索的方式,从最小的结构开始进行迭代搜索,采用递增式的增加Cell参数规模,使用Surrogate函数选择表现最好的Cell结构,具有更好的效果。和前期NASNet不同的是,PNAS没有规定Normal Cell与Reduction Cell用来调节降低搜索空间大小,而是使用步长减少搜索空间。在NASNet基础上提出的基于可微分架构搜索[21](Differentiable Architecture Search,DARTS)将分散空间进行连续性表示,节点通过超网络的形式构建一个大图,通过梯度下降选取网络边中操作概率最大的操作,形成了一个有向无环图,在网络结构中1/3和2/3处采用半采样单元(Reduction Cell),在其他部分采用正常采样单元(Normal Cell)构建完成网络架构。但是,DARTS在CIFAR-10数据集上的网络结构设定为20个Cell单元堆叠形成,并在特定的位置添加正常采样单元和半采样单元用来调节空间大小,能否通过增加Cell更多的数量获得效果更好的结构还有待研究。
实验表明[14],在深度网络结构中,基于Cell结构的网络在复杂度和准确度方面更具有优势,同时迁移学习效果更好,同时适用于大型数据集。
从网络发展之初的单链接网络到现在以Cell单元为网络基本单元的网络,Cell单元更适合构建更复杂的空间,空间维度更加灵活,空间容量将会呈指数型增长,空间结构更加丰富且更加灵活。但是,现有的神经架构网络结构很多都是在人为设定的框架下进行,存在一定的局限性。随着搜索空间的研究迈入更高阶的维度,构建简单的基本单元和搜索复杂度高的网络成为搜索空间的现状和研究未来。
3 搜索策略
搜索策略的目标便是使用效果最好的搜索算法,对网络结构进行搜索,高效、准确地找到网络结构的最优组合,并对涉及的超参数进行优化,以便搜索最佳的网络结构。目前研究的搜索策略主要是基于强化学习的策略、基于进化算法的策略、贝叶斯优化以及基于梯度的策略。
3.1 基于强化学习的搜索策略
强化学习主要采取“尝试”的学习机制进行学习,通过与环境交流得到反馈后指导下一步学习行为。强化学习主体由智能体和环境两部分组成,智能体同时充当着学习者和决策者的角色,通过和环境交流实现目标。在t时刻,智能体基于当前状态St发出动作At,环境做出反应,生成新的状态St+1和新的奖励值Rt+1,通过循环执行,获取最大的累计奖励值。强化学习交互过程示意图如图7所示。

图7 强化学习交互过程示意图
基于强化学习的策略是神经架构搜索的重点研究内容之一,众多研究者在强化学习的基础上采用不同的优化策略研究出很多优秀的算法。作为NAS的经典算法之一, Zoph等[13]在2016年提出使用一个RNN循环控制器作为智能体,在搜索空间中先搜索一个初级的网络结构,然后在数据集上对该网络进行训练,并在验证集上进行验证获取准确率R,把这个准确率R进行反馈,RNN控制器得到反馈后对网络继续优化得到新的网络结构,反复进行优化操作直到得到最优的网络结构。基于强化学习的策略首次使用循环控制体进行网络搜索的算法,为后续研究者提供了思路,但存在一定的不足,以高昂的算力为代价换取网络结构,在Cifar-10数据集上需要使用800个图形处理器(Graphics Processing Unit,GPU)同时训练,在PTB数据集上需要使用400个GPU训练。训练过程中使用分布式训练和异步参数更新加速控制器的学习效果,可以说强大的算力保障是基于强化学习神经架构搜索的基础。基于强化学习NAS示意图[13]如图8所示。
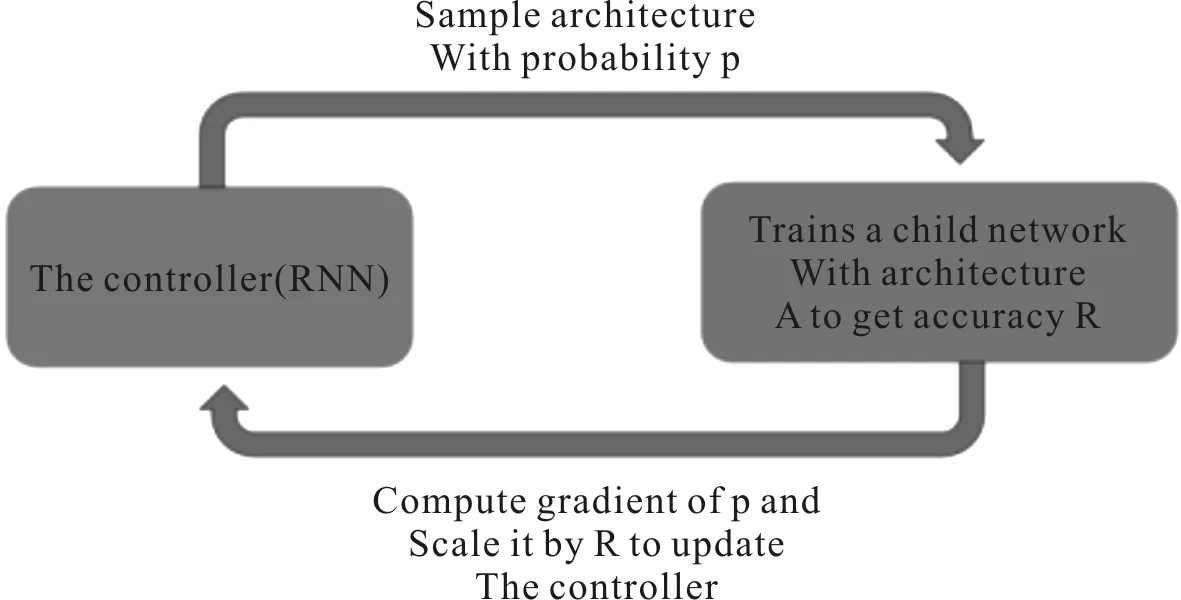
图8 基于强化学习NAS示意图
传统的神经网络模型都是由许多的卷积单元按照一定顺序堆叠在一起形成的,该链接方式限制了网络的深度,随后ResNet和Inception等带有特殊链接的网络模型被提出,其不仅可以构造很深的网络,而且可以改善过拟合的问题。强化学习中存在过度探索可能会导致收敛变慢的问题,使得收敛到局部最优而非全局最优,为此,Baker等[24]在2017年引入了MetaQNN网络结构,该网络结构基于Q-Learning算法进行搜索。通过借鉴马尔可夫决策过程,使用代理选择可能的路径构造网络。MetaQNN的设计灵感主要是通过减少卷积层的定义数量简化参数,定义代理能够选择的集合,使得结构灵活,保持搜索空间和模型容量的大小关系,使用代理进行收敛,可降低模型参数数量。与NAS方法不同的是,MetaQNN将优化范围缩小到某一层上,搜索过程简化很多,搜索时间降低,使用10个GPU训练时间为100 GPU days,加速240倍,相比RNN的强化学习实验条件成本大幅降低。从结果可以看出搜索出来的网络结构较为简单,人为约束条件较多,没有残差连接和并行层。在NASNet的搜索空间中,前两个低网络层中的两个单元的输出或输入,作为下一层每个单元中两个初始隐藏状态hi和hi-1的输入,在给定这两个初始隐藏状态的情况下,同时使用强化学习进行搜索,控制器RNN采用递归方式预测卷积单元的其余结构,其搜索过程示意图如图9所示。
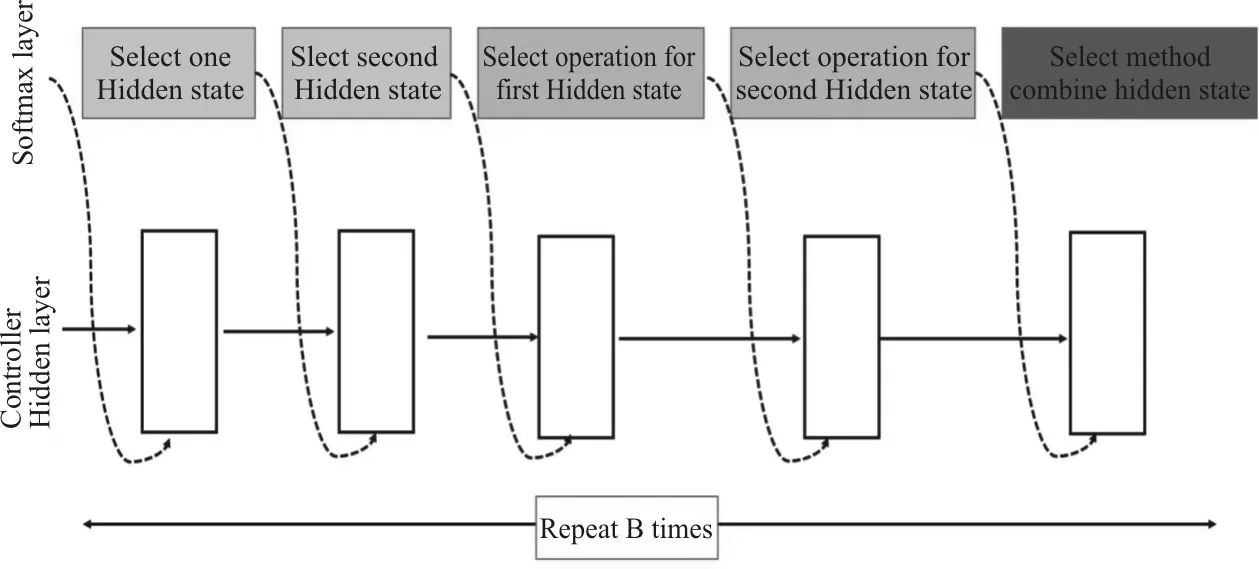
图9 NASNet搜索过程示意图
NASNet使用的搜索策略是近端策略优化(Proximal Policy Optimization,PPO),在NASNet中使用DropPath避免过拟合,但是效果并不是很好。所需实验条件为500个GPU,相比之前使用了更快的硬件设备,最终效率提高了7倍,可以看出实验条件在NAS的研究中起到了十分关键的作用。
Zhong等[25]在2018年提出了基于强化学习的BlockQNN结构,该结构把当前神经网络层定义为强化学习中的现阶段状态(Current State),而下一层结构的决策定义为强化学习中的动作(Action),强化学习算法通过优化寻获最优的动作决策序列。BlockQNN网络结构采用基于Epsilon-greedy搜索策略的Q-Learning范式方法自动构建高性能网络。在构建结构过程中引用BlockQNN结构设计,降低了构建网络的搜索空间大小,可快速构建网络结构。考虑到Block结构本身具备很强的泛化性,在不同的数据集上只需要叠加不同个数的Block结构就可以生成相应的网络结构。同时,BlockQNN结构具有以下优点:1)与传统人工构建的网络相比,网络性能更优;2)模型设计的搜索空间规模减少,训练时间大幅减少;3)可以迁移到更大的数据集,取得了良好的效果。BlockQNN将研究思路从整体网络转变为Block模块,使用了分布式框架同时采用早停技术,在32个GPU(TitanX)的计算资源下将搜索时间降低到3天,相比前面的大幅降低搜索时间。
Pham等[18]在2018年提出了高效的神经架构搜索(Efficient Neural Architecture Search,ENAS),其基于强化学习使用权重共享策略,避免冲突开始训练,节约了计算成本。ENAS实现了可以在单个GPU(1080 Ti)上进行架构搜索,具有十分重大的意义,使低成本下的NAS研究成为了可能。ENAS的成功主要是采用权重共享策略,还有一个原因便是只采用了3×3和5×5的卷积进行搜索空间构建,简化了搜索空间,大幅降低搜索时间。Yang等[27]在2018年提出了一种称为NetAdapt的算法,该算法在给定资源预算的情况下,可以自动地将预先训练好的深层神经网络架构应用于移动平台,是一种自动约束网络优化算法,在满足约束条件(资源预算)的条件下,生成一系列简单网络,实现网络的动态选择和进一步优化。但是,NetAdapt计算消耗大,产生的子结构过多,导致裁剪所用时间过多,针对小规模的模型效果更好。NetAdapt在Samsung Galaxy S8进行实验,开启了NAS应用在移动领域新纪元。2019年,Hu等[28]提出了Petridish算法,以迭代的方式将快捷连接添加到现有的网络层,能够在增强层上使梯度增强。为了减少可能的连接组合的试验次数,在每个生长阶段联合训练所有可能的连接,同时,利用特征选择技术选择其中的一个子集。实验证明这个过程将是一种高效的前向架构搜索算法,可以找到在可重复的搜索空间中占用GPU时间最少的竞争模型网络模块(单元搜索)和常规网络空间(宏搜索)。在Cifar-10数据集上使用两个3×3卷积操作,在实验设备GTX 1080的条件下,Petridish算法可以达到2.87±0.13%的错误率,在错误率方面优于DARTS算法,但是搜索时间较长并且参数量过大。Ying等[29]为了解决NAS消耗计算资源,难以复现的问题,通过引入NAS-Bench-101数据集改善了这些问题。在NAS-Bench-101数据集上构建了结构丰富的网络空间架构,训练并评估了这些架构,同时在CIFAR-10数据集上多次训练并将结果编译成一个超过500万种训练有素的模型。该方法提高了模型精度,通过查询预计运算数据集,用以评估各种模型的质量。在谷歌张量处理单元(Tensor Processing Unit,TPU) v2上进行训练实验,其成本较高。同年,Tan等[30]提出MnasNet方法,目的是搜索出一个在精度和延迟之间达到平衡状态并且拥有表现良好的模型,进一步达到灵活性和搜索空间大小之间更加平衡的状态。MnasNet系统地研究了平衡网络的深度、宽度和分辨率之间的关系,通过改变三者之间关系可以提高性能。实验在64个TPUv2上进行,花费了4.5天,实验条件相比较NASNet和MobileNetV2性能要求更高。
随着网络结构的研究,移动设备设计CNN仍然是一个挑战,因为移动模型需要小而快,对准确度有较高要求。Tan等[26]通过系统地研究模型缩放方法,发现网络的深度、宽度和分辨率三者达到平衡状态可以提高网络性能,在此基础上提出了新的标度用以统一缩放所有大小的方法,构成简单有效的复合系数。使用设计新的基准构建网络结构,并且扩大规模形成EfficientNets。该实验在Intel Xeon CPU E5-2690上进行,网络运行速度比ResNet-152快5.7倍,比GPipe快6.1倍。
神经网络架构自动搜索到的网络与传统的卷积网络相比,网络性能和准确度更高。2020年,Real等[31]设计了一个新的框架,将基本的数学运算作为构建块的机器学习算法,使其可以自动搜索并发现完整神经网络结构。该框架设计的搜索空间减少了偏见,针对搜索空间过大的问题,使用进化算法搜索发现新网络,并通过反向传播训练的两层神经网络,最终构建针对特定任务的网络结构。Luo等[32]为了解决对控制器进行培训既需要大量高质量的架构,也需要保证其准确性,而评估架构并获得其准确性则需要付出高昂的代价等问题,提出了SemiNAS,一种半监督的NAS方法。SemiNAS具有两个优点:1)在相同的精度保证下降低了计算成本;2)在相同的计算成本下达到更高的精度。SemiNAS在4个P40显卡、NASBench-101基准数据集上进行实验,其在评估了大约300种架构后发现了0.01%的顶级架构,而与正则化的进化和基于梯度的方法相比,计算成本仅为1/7。在ImageNet上可以实现最先进的Top-1错误率(在移动设置下)为23.5%,训练时间降低为4天。Guo等[33]在对抗攻击的最新进展中揭示了现代深度神经网络的内在脆弱性,通过专门的学习算法和损失函数增强深度网络的鲁棒性研究,提出的RobNet网络从架构的角度研究了可抵抗对抗攻击的网络架构模式,只保留3个操作算子构建搜索空间,同时采用“免费”对抗训练方案加快训练速度。Lin[34]等研究了在基于微控制器单元(Microcontroller Unit,MCU)的微型物联网(Internet of Things,IoT)设备上的机器学习,提出了MCUNet结构,该结构可以共同设计高效的神经体系结构(TinyNAS)和轻量级推理引擎(TinyEngine),从而在微控制器上实现ImageNet数据集的推理。TinyNAS采用了两个阶段对神经体系结构进行搜索,第一阶段是优化搜索空间以适应资源限制,第二阶段在优化的搜索空间中专门研究网络体系结构。TinyNAS具有在搜索成本比较低的条件下可以自动处理设备、延迟、能源和内存等各种约束条件的优点。
强化学习在神经结构搜索中相比于人工设计的网络极具优势,但是基于强化学习的NAS大部分情况下都需要强大的计算资源支持。随着计算能力的提升,基于强化学习的NAS训练时间已经从二十多天减少为几天,时间效率有所提高,未来将在图形分割、图像识别以及自然语言处理等方面发挥优势。
3.2 基于进化算法的NAS搜索策略
进化算法(Evolutionary Algorithm) 实现结构搜索原理是通过对生物界的种种生物现象进行借鉴和模拟完成,其操作过程主要包括对基因编码、种群初始化、交叉变异算子和保留机制等操作[35]。在初期随机初始化一个种群,然后按一定顺序执行选择算子、交叉算子以及变异算子,根据当前适应度的评价结果,再次选择“初代种群”,进行迭代进化,直到适应度满足条件,循环过程示意图如图10所示。
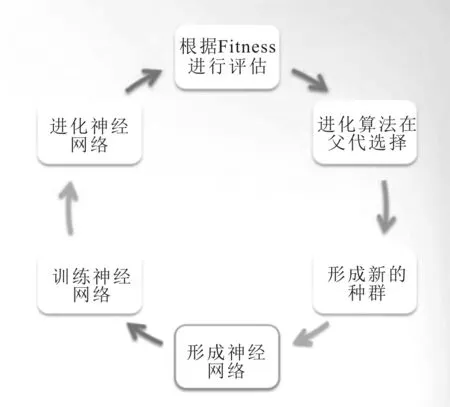
图10 神经网络的基本循环过程示意图
遗传算法作为进化算法的分支则是以自然界中生物的进化规律为基本准则,以种群中的所有个体为对象,利用模拟自然进化技术指导对被编码的空间进行高效搜索,选择最优化的解。采用遗传算法的神经架构搜索主要是通过对产生的子网络结构采用二进制编码方式,运行算法得到神经网络在验证集上精度(适应度)最大的值,该值对应的该网络结构便是最佳结构。
Real等[16]在2017年引用进化算法用来解决NAS相关问题,设计的进化算法是从没有进行过任何卷积操作的最简单的模型开始进化,初期的神经网络架构的深度并不固定,随着搜索空间的不断扩大,运行算法的时间变得越来越长,网络结构深度越深。实验训练和验证都在TensorFlow框架上进行,为了完成实验自行开发了一个大规模并行同时无锁的设备,每个实验都分布在250个并行的设备上,实验成本较高。2017年,Poulsen等[36]提出了将神经进化与CNN的图像特征识别融合的方法,利用CNN网络进行图像识别操作,对识别后的图像采用特征表示的方式进行转换,最后将经过算法处理的图像传递给优化过的神经网络。该方法虽然能够有效地提取图像特征,但是结果是否有效在很大程度上依赖于特征表示的质量。随后,Real等[37]在2018年提出了锦标赛选择的变体aging evolution,依据进化得到代数和进化所用时间去选择比较年轻的模型,经过搜索得出的最优网络结构被称为AmoebaNet。实验候选操作有9个操作,在450个K40 GPU上运行,搜索时间和搜索成本比较高。2019年,Real等[37]对进化算法进行改进,采用一种正则化形式,根据训练时间早晚,选择移除了训练时间最早的神经网络(无论性能有多好),而不是移除训练中结构最差的神经网络。通过改进,在面对任务优化发生变化的时候能够提高稳健性,最终得到了准确度高且损失最低的网络。考虑到使用该方法结构权重不能够继承,因此所有的网络必须从开始进行重新训练。虽然该方法有一定的进步,但是在训练过程中存在的噪声会使得同样架构准确率的情况下产生不同的结构,得到准确度更高的模型概率降低。
Saravanan等[38]提出了细粒度的神经进化(Evolving Neural Networks through Augmenting Topologies,NEAT)算法,该算法通过网络结构自己搜索需要使用多少连接,以这种方式忽略那些不重要的连接,生成的神经网络结构较小,运行速度加快。NEAT通过突变和无损重组直接编码的两种方式生成网络结构,使其具有结构简单和同步能力强的特点。2002年,Stanley等[39]在NEAT基础上提出了一种新型的神经网络进化方法,称为“神经进化的增强拓扑”,旨在利用网络结构作为最小化搜索空间维度的方法。尽管神经网络随着发展越来越完善,但和自然大脑还有不小的差距。为了缩小神经网络与自然大脑之间的差距,Stanley等[40]又于2009年提出HyperNEAT算法,HyperNEAT是NEAT的变体,采用了一种连接合成模式构建网络(Connective compositional Pattern-Producing Networks,CPPNs)的间接编码,产生具有对称性和重复基序的连接模式。该算法将任务的规则映射到网络的拓扑结构,利用任务的几何结构,从而将问题的难度从高维迁移到低维的问题结构上,开辟了将神经进化应用到处理复杂高维任务的研究领域。2010年,Risi等[41]在HyperNEAT的基础上提出ES-HyperNEAT,通过改进使得在信息质量比较高的区域采用更密集基底的网络(Compositional Pattern Producing Networks,CPPN)。为了确定隐藏节点的密度和位置,ES-HyperNEAT通过使用四叉树状结构的方法实现。实验对比得出,ES-HyperNEAT在相关测试中的表现比传统的HyperNEAT表现更强。2014年,Hausknecht等[42]引入神经进化的方法学习Atari游戏,将CNE、CMA-ES、NEAT和HyperNEAT等4种算法在61种Atari游戏中进行评估对比。测试结果证明了神经进化在通用视频游戏的实验中极具潜力,同时也显示在空间有限的情况下直接编码表现效果最好,在更高维的维度中可以用间接编码对结构进行表示。
DeepNEAT算法作为NEAT算法的延伸,也取得十足的发展。两个算法的主要有两个区别,第一个区别是运行的单元不一致,NEAT算法的运行单元是由神经元(Neuron)构成,而DeepNEAT 算法中的操作节点则是一个深度神经网络(Deep Neural Networks,DNN)的层(Layer),其中每一个节点包含实数编码和二进制编码两种编码方式。第二个区别是链接(Link)的代表意义不一致,在NEAT算法中连接代表的是权重值(Weight),而在DeepNEAT算法中则代表链接关系与链接方向。
Miikkulainen等[43]在2017年提出Coevolution DeepNEAT(CoDeepNEAT) 新算法,该算法在增加网络结构复用性的同时可以简化网络结构。CoDeepNEAT算法主要涉及模块和蓝图两个新的概念。模块表示的是一个小的DNN网络结构,蓝图表示的是一个图,即其中每个节点包含指向特定模块的值。CoDeepNEAT算法采用共同进化方法对两组蓝图和模块进行同时进化,通过采用以相应的模块代替蓝图节点的方法,将模块和蓝图组进行组合形成一个大型的网络结构,称为集合网络(Assembled Networks)。2019年,Liang等[44]在CoDeepNEAT进化算法的基础上,提出了功能强大的自动机器学习框架Leaf,即Algorithm Layer、System Layer和Problem-domain Layer。在该框架中不仅可以实现训练和修改网络结构的权值功能,并在此基础上可以修改网络的拓扑结构,通过新增节点和删除节点等操作进行修改,经过实验对比,该框架显示了强大的优越性。
进化算法作为神经架构搜索中最重要的研究内容之一,取得了十分显著的研究成果。2019年,Stanley等[45]对现代神经进化发展的进行总结和回顾,简述了神经进化在大规模计算、结构新颖性和多样性的好处、间接编码的优势等方面以及该领域对结构搜索的重大贡献,并指出未来神经进化将成为追求人工智能的关键工具。使用进化算法的优势就是只要进化代数足够多,就可以得到全局最优解,但是这也是非常消耗算力的一个过程。基于进化算法的NAS研究,不仅依靠算法设计层面,也对实验条件有了更高的要求,空间操作数量越多,迭代次数越多,需要的实验条件就越苛刻。总体来看,目前采用分布式计算提高进化效率是有效的解决办法之一。
3.3 贝叶斯优化
基于贝叶斯优化[46]的搜索策略(Bayesian Optimization,BO)是目前用于进行超参数优化的主要的方法之一,其内容采用基于高斯过程(Gaussian Processes)和基于核方法(Kernel Trick)对于高维优化问题进行优化,优化过程中采用树模型或者随机森林。对于低维空间的问题优化,贝叶斯优化具有良好的效果。考虑到神经网络存在很多的超参数,为了找到最优的参数组合,需要对参数组合进行搜索比对。传统的网格搜索耗时长、速度慢,贝叶斯优化可以用来指导参数优化,Domhan等[47]提出了将贝叶斯优化应用于神经架构搜索。2012年,Hutter等[48]提出基于序列模型的优化(Sequential Model-Based Optimization,SMBO)方法,序列的含义是指一个接一个地进行试验,每次都应用贝叶斯进行模型推理,同时更新概率模型尝试找到更好的超参数。在SMBO的基础上基于序列模型的算法(Sequential Model-based Algorithm Configuration,SMAC)方法被提出,其是基于模型选择而不是随机选择。2013年,Bergstra等[49]提出了一个元建模方法支持自动超参数优化,目的是提供实用的工具,用一个可重复和无偏的优化过程代替手动调整。Swersky等[50]在2014年为条件参数空间定义了一个新内核,该内核明确包含给定结构中的参数相关的信息,通过共享信息提高深度神经网络的性能。2017年,Liu等[20]在SMBO的基础上学习构建CNN的结构,引入渐进式思想设计出渐进式神经网络架构搜索算法,逐渐增减空间复杂度。实验的候选操作为8个,针对大型数据集需要100个P100型号GPU。2018年,Jin等[51]提出一种全新架构,使用贝叶斯优化引导网络变形,同时使用一个神经网络核(Neural Network Kernel)以及一个生成树结构的优化算法高效探索搜索空间,以提升神经架构搜索效率。同年,Kandasamy等[52]提出了神经结构搜索框架NASBOT(BO Algorithm For Neural Architecture Search),该框架基于高斯过程,同时结合基于GP的BO方法,为架构搜索空间推导了核函数,并给出了一种优化神经网络结构获取函数的方法,采用进化算法对获取函数进行优化。2019年,Perez-Rua等[53]以多模态分类为基础,提出了一个新的搜索空间,利用SMBO进行多模态融合,寻找最优的多模态融合架构。
3.4 基于梯度下降的搜索策略
基于梯度(Gradient-based)的方法是机器学习领域最经典的方法。基于强化学习和进化算法的方法在搜索空间的问题上,本质上都属于在离散的空间中进行搜索,为黑箱优化。相比于黑箱优化方法,梯度法的搜索速度更快,能够节约训练时间。在搜索空间连续且目标函数可微的情况下,基于梯度的方法效率更高。2019年,Liu等[21]提出的DARTS方法将搜索空间弱化为一个连续的空间结构,以此可以使用梯度下降进行性能优化。DARTS能够在丰富的搜索空间中搜索到一种具有复杂图形拓扑结构的高性能框架。同年,Luo等[54]提出一种新方法,即先在一个连续的空间中将网络结构进行嵌入(Embedding)操作,该连续空间中的每一个点相对应一个网络结构,在此空间中定义准确率的预测函数。对照目标函数进行梯度优化,找到最佳网络结构的嵌入表征,优化完成后,再将这个嵌入表征映射回网络结构,找到最优的网络结构。该类方法的优点之一就是搜索效率高,同时采用权重共享等加速手段,快速减少了训练所需时间。Cai等[55]提出了一种不使用代理任务的方法ProxylessNAS,能够直接在大规模的目标任务上搜索结构,解决NAS方法GPU高内存占用和计算耗时过长的问题。通过二值化的手段将内存消耗降低了一个量级,给出了一个基于梯度的方法(延迟正则化损失)约束硬件指标。基于ProxyTasks的NAS方法并没有考虑Latency性能的影响,现有的NAS方法采用的是使用堆叠Block构成最终的网络,但实际的网络中是可以存在不同种类的Block。DARTS巧妙地将搜索空间转化为可微的形式,把结构和权重联联合优化,但DARTS基于ProxyTasks,在计算堆叠Block的过程中仍然占用大量的GPU资源。Hundt[56]等对DARTS进行了改进,提出了sharpDARTS,利用余弦功率退火学习率进行优化。Chen等[57]提出P-DARTS,用渐进地增加搜索网络的深度解决深度差异的问题。采用渐进增加搜索网络深度的策略是因为可以用这种方式逐渐地缩小搜索空间,也就是候选操作的种类,从而保持显存消耗在一个合理的水平。同时,在搜索空间近似的前提下,可以根据每个阶段学习到的网络结构参数渐进地减少候选操作的种类,从而降低显存和时间消耗。Xu等[58]提出PC-DARTS采用通道采样(Channel Sampling)的技术,降低搜索时间开销和内存开销,同时提出了边标准化方法(Edge Normalization)。边界标准化用于确定指向一个结点的两条边,通过给每条边再增加一个系数,在确定边时对系数取值,用这种方法可以改善搜索的稳定性。Zheng等[59]提出了一种基于多项式分布估计快速NAS算法(MdeNAS),其将搜索空间视为一个多项式分布,可以通过采样-分布估计优化该分布,从而将NAS的训练转换为分布估计/学习(Multinomial Distribution Learning,DL)。除此之外,还提出并证明了一种保序精度排序假设,进一步加速学习过程。在CIFAR-10上,使用该方法搜索的结构实现了2.55%的测试误差,在实验设备单个GTX1080Ti上仅需4个GPU小时。在ImageNet上,实现了75.2%的Top1准确度。2020年,Guo等[33]在提出的RobNet网络中,使用投影梯度下降生成对抗性示例并在训练期间增加数据,使得网络鲁棒性得到了显着提高。
从传统的随机策略到最初的强化学习,再到引入进化算法、使用梯度下降和贝叶斯优化等方法,搜索策略的发展从最初的随机选择,到指导性的学习优化,以及现在更加智能化的优化,策略的选择范围更加广泛,搜索效果也更加优秀,策略的选择越来越自动化、智能化。
4 性能评估
神经架构搜索的效果在很大程度上依赖于训练数据的规模,规模越大学习的效果越好,但是大规模数据上训练模型的时间非常久,对训练结果的评估将会非常耗时,所以为了尽快找到最优网络会使用一些方法去近似的评估架构性能和策略效率,进一步降低训练成本。为了减少这样的计算量,基于各种模型的搜索方案被提出,通过搜索加速提升网络模型性能。下面将对常见的评估策略以及加速方案进行总结。
4.1 低保真度
低保真度方法指的是使用减少训练的时间,减少训练子集的数量、减少网络层数,以及使用较低分辨率的图像等方法提升训练效果,近似预估网络性能。虽然低保真度在一定程度上降低了计算成本,但也有一定的缺点。由于性能通常会被低估,验证的过程中会引入偏差,导致评估的网络并不是最优。在通常情况下只要不同结构相对排名较为稳定时,性能低估不会影响结构变化。但是,最近的一些研究结果表明当采用低保真度方法后与完全评估的结果之间的差异太大时,这种相对排名就会发生显着变化。为了加速超参数优化,Klein等[60]于2016年提出了一个验证误差随训练集大小变化的生成模型。该模型在优化过程中学习,通过外推到完整数据集,可以探索小子集上的初始配置,并构造了一个贝叶斯优化过程将其命名为Fabolas。该过程将损失和训练时间作为数据集大小的函数进行建模,并自动权衡全局最优解的高信息增益和计算开销。2019年,Hu等[61]提出了一种无导数优化框架,使用多逼真度评估的自动机器学习。对小型数据子集使用许多低保真度评估,而对整个数据集使用很少的高保真度评估。对于低保真度评估可能会产生严重偏差的问题,使用非常低的成本即进行校正予以解决。
4.2 早停及学习曲线方法
2016年,Domhan等[62]提出观察学习曲线(Learning Curve,LC) 的方法,通过学习曲线概率模型进行推断,对预测性能表现不好的网络架构停止搜索。另外,一些研究者则通过预测哪些部分学习曲线最有希望进行参数优化。Klein等[63]利用学习曲线概率模型用来优化超参数,提出在贝叶斯神经网络中通过专门的学习曲线层提高网络的性能。早停是在网络完全收敛的时候就停止训练,防止在通过基于梯度的优化训练过程中模型的泛化性能过差。早停法主要是训练时间和泛化错误之间达到一种平衡状态。2017年,Mahsereci等[64]提出了提前停止准则,基于快速计算局部数据的方法计算梯度的梯度,并完全地消除了对临时验证集的需求。
4.3 搜索加速方案
考虑到搜索过程耗费时间和计算资源,为了进一步加快搜索过程,需要在相对较小搜索空间进行评估,并在较大的搜索空间中进行良好的预测,由此各种加速方案被提出,用来提高搜索效率。
4.3.1 权值共享法
权值共享法是减少参数个数的方法。2018年,HieuPham等[65]提出的ENAS是用于自动化网络模型设计的方法,该方法快速有效且资源耗费低。ENAS是对NAS的改进,各个子网模型采用共享权重方法提升计算效率,从而避免低效率的从头训练。ENAS的控制器通过在大型数据集内搜索最优的子图表示神经网络架构,根据梯度对网络进行训练,以选择一个子网络,以使验证集上的准确度最大化。子网络之间共享参数能够让ENAS提供强大的性能,共享权值的方法使得模型同时训练占用GPU的时间与当时其他的自动模型训练时间少得多,并且与标准的神经架构搜索相比,计算成本显著降低。2019年,Liam等[66]提出了NAS主要是以超参数优化问题为主和随机搜索是超参数优化的竞争标准两个新的NAS标准。以这两个标准为基础,在PTB和CIFAR-10数据集上评估了具有早停功能的随机搜索和具有权重共享算法的新型随机搜索。实验结果表明,采用权重共享的随机搜索结果比具有早期停止功能的随机搜索的结果更好,在PTB和CIFAR-10上同时获得了最优的结果。同年,Zhang等[67]提出了直接稀疏优化NAS(Direct Sparse Optimization NAS,DSO-NAS)方法。在DSO-NAS中,建立了一种新的模型修剪NAS问题的视图。从完全连接块入手,引入缩放因子缩放之间的信息流操作,使用稀疏正则化以修剪无用的连接在建筑中。该方法同时具有可区分性和效率,因此可以直接应用于ImageNet这类的大型数据集。
4.3.2 超网的应用
神经架构搜索可以看作一个内外循环优化的问题,内循环用于查找给定架训练损失的最优参数,外循环用于查找验证损失的最优架构。针对神经架构搜索计算成本过高的问题,提出一种图超网络分摊搜索成本。由图神经网络和超网络(HyperNetwork)组成的网络接收计算机图作为输入,并在图中生成所有节点的结构参数,用于评估随机采样架构的适用性,然后根据验证集的准确率选择性能最优的架构。Brock等[1]在2017年提出一种将网络结构配置与其在验证集上的表现一起排名的搜索方法,网络的参数是通过一个辅助网络生成。在每一次训练开始时,随机取样一个网络结构并使用超网络生成网络的权重值,之后训练整个网络,训练结束后随机取样一定数量的网络机构并评估其在验证集上的表现,权重仍然使用超网络生成的权重值,最后选择在验证集上表现最好的网络,正常训练得到网络权重值。
4.3.3 基于One-Shot模型的加速方案
One-Shot模型主要研究的是单样本的学习能力,当类别训练样本只有一个或者很少时,依然可以分类。基于One-Shot模型的神经网络架构搜索受到了NAS和SMASH的启发,NAS主要依靠一个NAS控制器随着时间反复迭代更新网络的结构,而SMASH在使用控制器迭代网络结构的基础上试图减小网络的计算量,引入超网生成主网络所需的权重值W。NAS和SMASH搜索视为一个黑盒优化问题,One-Shot架构搜索过程视为从一个十分复杂的网络结构开始,逐步对网络进行修剪,修剪到作业较小的部分。将One-Shot模型搜索到的网络训练完成后,使用这个模型对候选结构在验证集上的表现进行评估,选择方法可以是进化算法或强化学习算法,One-Shot架构搜索的输出结果是一系列根据One-Shot正确率排列的网络结构,训练完成后,可以重新训练最佳的结构。2018年,Bender等[19]对One-Shot模型原理进行详细的介绍,从搜索空间、操作的选择、网络架构的构建以及搜索流程进行了详细讲解,同时对One-Shot模型中的权重共享机制进行了详细说明。
基于One-Shot架构搜索方法解决了计算量的问题,但仍带来一些问题。使用超网生成的权重W在优化过程中会变得深度耦合,在对网络的结构a和权重W的优化过程中,由于部分缺乏训练,使不同结构不具有可比性,误导了搜索结构。为了解决这种问题,单路径网络被提出。单路径首先改变的是权重W的优化策略,超网络的权重对于搜索空间中的所有架构同时优化,在超网络的每一步优化过程中,随机选取一个子网络,只有这个子网络的权重被更新。为了解决耦合问题,网络搜索空间被简化成一个单路径结构,其示意图如图11所示。
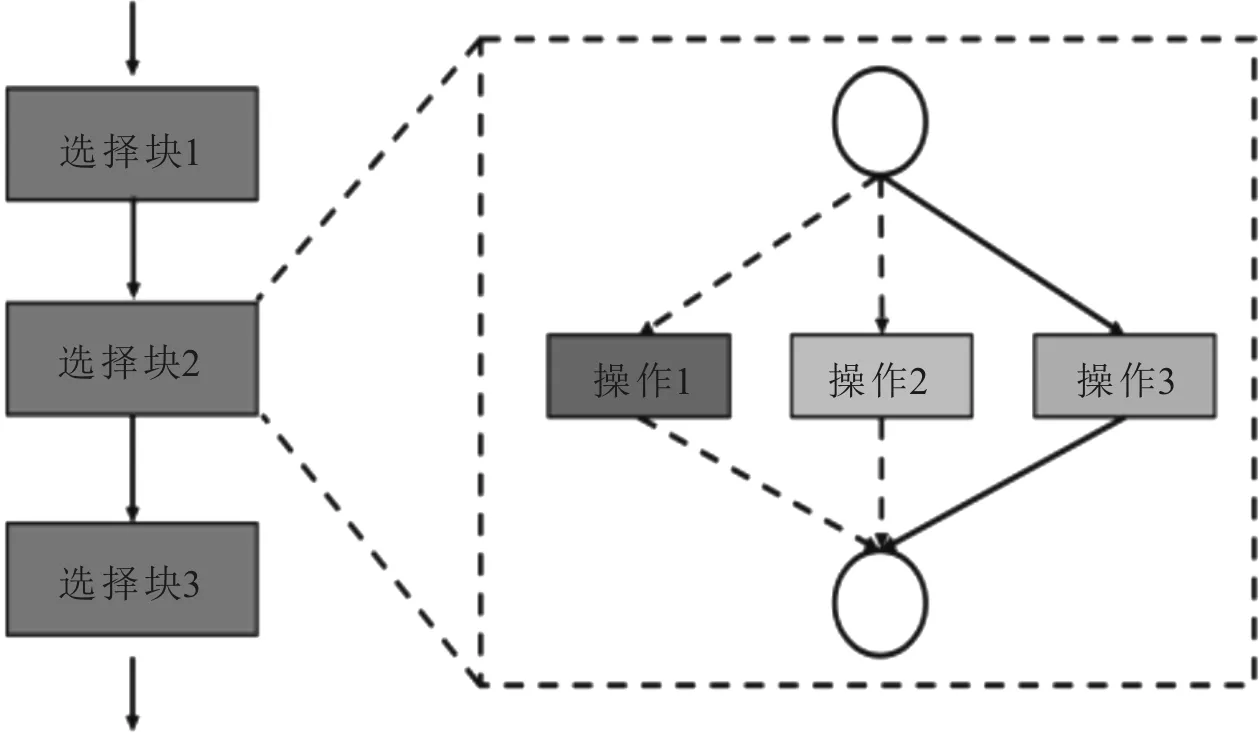
图11 Block结构示意图
使用“选择模块”构建网络结构,选择模块是由多种选择操作组成,每个选择模块在一个时刻只能选择其中一种操作。对选择块中操作的选择目前有两种的方法,一种是使用通道数搜索,每一个选择模块目的是选择出卷积层的通道数,主要思路是从最大数量的通道数开始,在超网络的训练过程中随机选择并通过下一层的反馈进行修剪。另一种方法是混合精度量化搜索,选择块用来搜索卷积层权重值和特征的量化精度。
2019年,Guo等[68]提出了单路径模型以解决训练中遇到的问题,其主要思想是构建一个单路径超网络模型,该网络采用均匀采样方法选择一个子网络进行训练,所有的网络架构及其权重局均采用平等的训练,然后使用进化算法高效地搜索出最佳的体系结构。经过实验证明该方法效率高、易于训练且搜索效率高。同年,Cheng等[69]提出了InstaNAS,即一种实例感知NAS框架。该框架设计思路是控制器在数据集上搜索“架构的分布”而不是仅仅单个架构。InstaNAS由One-Shot模型和控制器组成,使用One-Shot架构搜索用来降低搜索成本,加速搜索过程,针对输入的实例进行训练,对结构目标和准确性目标进行同时优化,自动权衡两个目标,生成适用于实例的网络架构。2020年,Chu等[70]提出训练多路径超级网络以准确评估候选架构,通过研究发现在搜索空间中,从多个路径求和的特征向量几乎是单个路径的特征向量的倍数,扰乱了超网训练及其排名能力。在基于批处理[71](Batch Normalization,BN)的基础上提出了一种称为“影子批归一化”的机制,以对不同的特征统计量进行正则化。同年,Lu等[72]提出了神经体系结构转移(Neural Architecture Transfer,NAT),NAT旨在有效地生成特定于任务的自定义模型,即使在多个相互冲突的目标下,也具有竞争力。该方法的关键是集成在线迁移学习和多目标进化搜索过程,在搜索特定任务的子网的同时迭代地调整了预训练的超级网络。小规模的细粒度数据集从NAT中受益最大,同时架构搜索和传输的效率比现有NAS方法高几个数量级。Huang等[73]提出了GreedyNAS,在训练过程中不覆盖所有的路径,而是通过评估超级网中潜在性能更好的路径,缓解超级网的负担,使用验证数据的代理项部分。Zela等[74]为One-Shot模型的NAS引入了一个通用框架,该框架可以实例化为许多最近引入的变体,并引入了一个通用基准框架,该框架借鉴了最新的数据集 NAS-Bench-101对One-Shot模型的NAS进行低成本随时评估。Li等[75]提出了一种新方法引导参数后验向其真实分布。尽管基于One-Shot模型的NAS通过权重共享显着提高了计算效率,但是在超网训练(架构搜索阶段)期间引入了多模型训练,该过程会使得前面的训练架构出现性能下降的问题。为了克服这种问题,Zhang等[76]假设在联合优化后进行验证时的共享权重为最佳权重,将One-Shot-NAS中的超网训练表述为持续学习的约束优化问题,即当前架构的学习不应在超网训练期间降低先前架构的性能。同时,设计了一种新颖性的搜索方法找到最具代表性的子集用来规范超网训练。2021年,Hu等[77]提出了一个收缩和扩展的超网络,通过减少权重共享的程度解耦共享参数,避免了不稳定和不准确的性能估计。同年,Huang等[78]提出了一种渐进式一次性神经架构搜索(Progressive One-Shot Neural Architecture Search,PONAS)方法,以实现对各种硬件约束的非常有效的模型搜索。在搜索架构空间时,通过构建一个表来存储所有层的所有候选块的验证准确性。对于更严格的硬件约束,可以根据该表通过选择产生最小精度损失的最佳候选块有效地确定专用网络的架构。PONAS方法以结合渐进式NAS和一次性方法的优点,给出了包括元训练阶段和微调阶段的两阶段训练方案,使搜索过程高效稳定。在搜索过程中,评估不同层中的候选块并构建一个用于架构搜索的准确度表,用该表评估完整网络的性能。
4.3.4 代理模型
代理模型就是用来代替某个模型的模型,核心思想为训练并利用一个计算成本较低的模型去模拟原本计算成本较高的那个模型的预测结果,从而避开大型模型的计算。
代理模型进行优化过程主要分为抽样选择(也被称为顺序设计或主动学习)、建立代理模型模式和优化模型参数,以及代理模型准确性评估等3个方面。
基于SMBO策略的新方法,以结构复杂度增加的顺序为网络结构的搜索顺序,同时使用代理模型指导网络结构空间搜索。在搜索空间方面,搜索算法的目标是搜索表现性能良好的卷积单元(Cell),而不是整个的CNN网络结构。使用启发式搜索的方法搜索单元结构的空间,由简单的模型开始,逐步发展为复杂的模型,并在进行过程中修剪掉没有希望的结构。Deng等[1]提出在训练之前基于网络的体系结构预测网络的性能,开发了一种统一的方法将各个层编码为向量,并组合在一起以通过长短期记忆(Long Short-Tern Memory,LSTM)形成一个完整的描述。该方法利用循环网络的强大表达能力,可以可靠地预测各种网络体系结构的性能。
4.3.5 可微分神经架构模型加速方案
DARTS与网络结构的压缩有关,目前是利用现有的神经网络,减少参数数量和计算成本,同时对模型的预测精度影响最小。DARTS主要针对卷积网络进行操作,包括每个卷积层、搜索过滤器大小、通道数量和分组卷积。通过训练与最大体系结构大致相同的单个模型获取更好的效果,而不需要训练大量不同的模型达到类似的性能水平。
DARTS将离散的搜索空间转变成连续松弛的搜索空间,然后使用梯度下降的方法有效地搜索体系结构。DARTS的关键在于是使用Softmax函数对候选操作进行混合操作。将原有离散的搜索空间通过一定的操作变成了连续空间,将目标函数变成为了可微函数,然后使用梯度下降的方法找到最优结构。该方法的搜索空间设计基于NASNet结构,相比其他搜索空间结构大小不设限制,可微分搜索方法在数据集上的结构层数进行了固定,虽然搜索效果很好,但是该方法的搜索过程有一定局限性,搜索结构不够丰富。Hundt等[56]对DARTS进行了改进,提出了sharpDARTS。Chen等[57]又在DARTS改进提出P-DARTS,用渐进地增加搜索网络的深度解决深度差异的问题。采用渐进增加搜索网络深度的策略是因为可以用这种方式逐渐地缩小搜索空间,也就是候选操作的种类,从而保持显存消耗在一个合理的水平。2019年,Xu等[58]提出的PC-DARTS都是在DARTS的基础上进行改进,降低搜索时间开销和内存开销。Xie等[79]提出了随机神经体系结构搜索(Stochastic Neural Architecture Search,SNAS),该方法可以在同一轮反向传播的同时优化训练神经操作参数和网络结构分布参数,并且保持完整性和可区分性。为了在一般可微分损失中利用梯度信息进行体系结构搜索,一种新的搜索梯度被提出,与基于强化学习的NAS相比可以更有效地反馈结果并进行决策。在CIFAR-10上进行的实验中,SNAS花费更少的时间找到具有最新精度的单元架构。
DNAS在设计最先进的高效神经网络方面已展示出巨大的成功。与其他搜索方法相比,基于DARTS的DNAS的搜索空间很小,因为必须在内存中实例化所有候选网络层,导致搜索空间规模有限。为了解决这个瓶颈, Wan等[81]于2020年提出了一种内存有效且计算效率高的DNAS变体:DMaskingNAS。与传统的DNAS相比,该算法对搜索空间进行了扩大,从而支持了空间和通道尺寸上的搜索,并且提出了一种掩蔽机制用于特征图重用,随着搜索空间规模的不断扩大,运行内存消耗和计算成本消耗可以保持不变。采用有效的方式传递最大化每个参数的精度,与所有以前的体系结构相比,可以搜索到的FBNetV2具有最先进的性能。
4.3.6 基于网络态射法和迂回爬山的方案
网络态射法(Network Morphing)的核心思想是通过态射的手段去避免重复训练,从而在速度上取得优势。两个不同的神经网络A和B,满足功能相同而结构不同,那么可以称神经网络A和B互为网络态射,即功能相同,结构不同的神经网络互为网络态射,子网络从父网络继承知识,具有潜力发展为更强大的网络。基于网络态射结构方法能够尽可能的保留原网络的优点,并在原有的网络结构基础上进行修改,通过一定的变换方式可以还原网络,同时与原网络相比,新网络的性能更好。迂回爬山法是指把当前的问题状态经过评估后,在相应条件的限制下,不采用缩小差异的方法,而是采用扩大评估状态与最终目标状态之间差异的方法,采用迂回前进,最终实现总目标,基于爬山法最大的缺点在于非常容易陷入局部最优解。
用于神经架构的爬山法(Neural Architecture Search by Hill-climbing,NASH)是基于简单的爬山过程自动搜索性能良好的CNN架构,其每一次会在临近空间中选择最优解作为当前解,该算法应用网络态射,通过余弦退火对学习率进行优化。构建网络常用的方法是先设计出一个网络结构,紧接着对网络进行训练,并在验证集上验证该网络性能,如果性能表现较差,则重新设计一个网络,但是这样的过程会耗费大量时间。于是,Elsken等[82]于2017年提出了基于网络态射(Network Morphism)的搜索方法。在搜索空间上使用爬山法,从临近的点中选择对应解最优的个体,使之替代原来的个体,并不断的重复这一过程,然后使用余弦退火对学习率进行迭代更新。Verma等[83]于2020年提出基于爬山法的新型神经架构搜索框架,利用梯度更新射态操作的方案,通过增加梯度渐变扩展结构,选择射态节点和增加操作减少时间,获得更高的准确性。
5 实验条件发展
神经架构搜索的开启便是借助于强大的算力搜索尽可能多的网络并找到最佳的网络。计算设备的发展加速了NAS的研究,从最开始的只依赖CPU计算,到利用GPU进行计算加速,再到利用更强大的网络矩阵服务器。同时计算设备数量从最开始的上千个降低到单个设备。
计算设备随着发展从CPU到GPU,再到现在的TPU,计算方法和计算效率大幅提升,3种设备的工作原理及性能对比如表1所示。
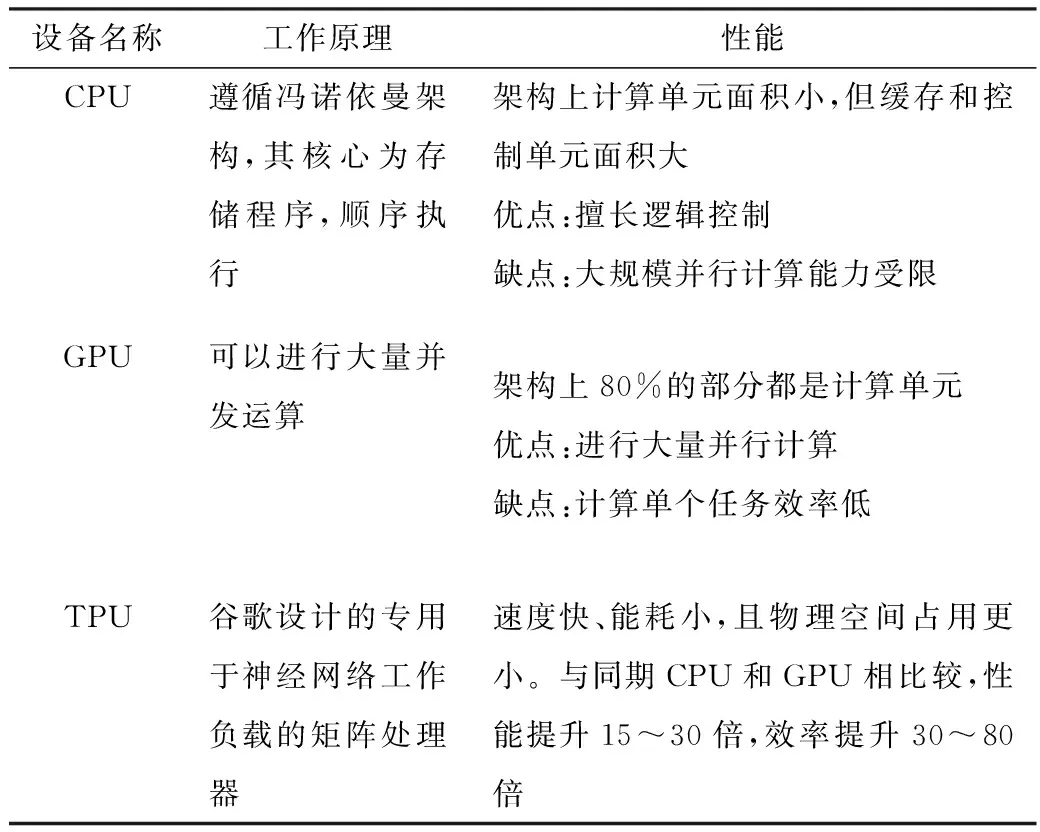
表1 3种设备的工作原理及性能对比
NAS需要进行大量参数计算的研究,目前主流的设备还是以GPU为主。未来随着计算架构的迭代发展,会出现更多性能更优的计算设备,届时NAS的研究发展将会迈向更高的台阶,部分神经架构算法实验条件如表2所示。
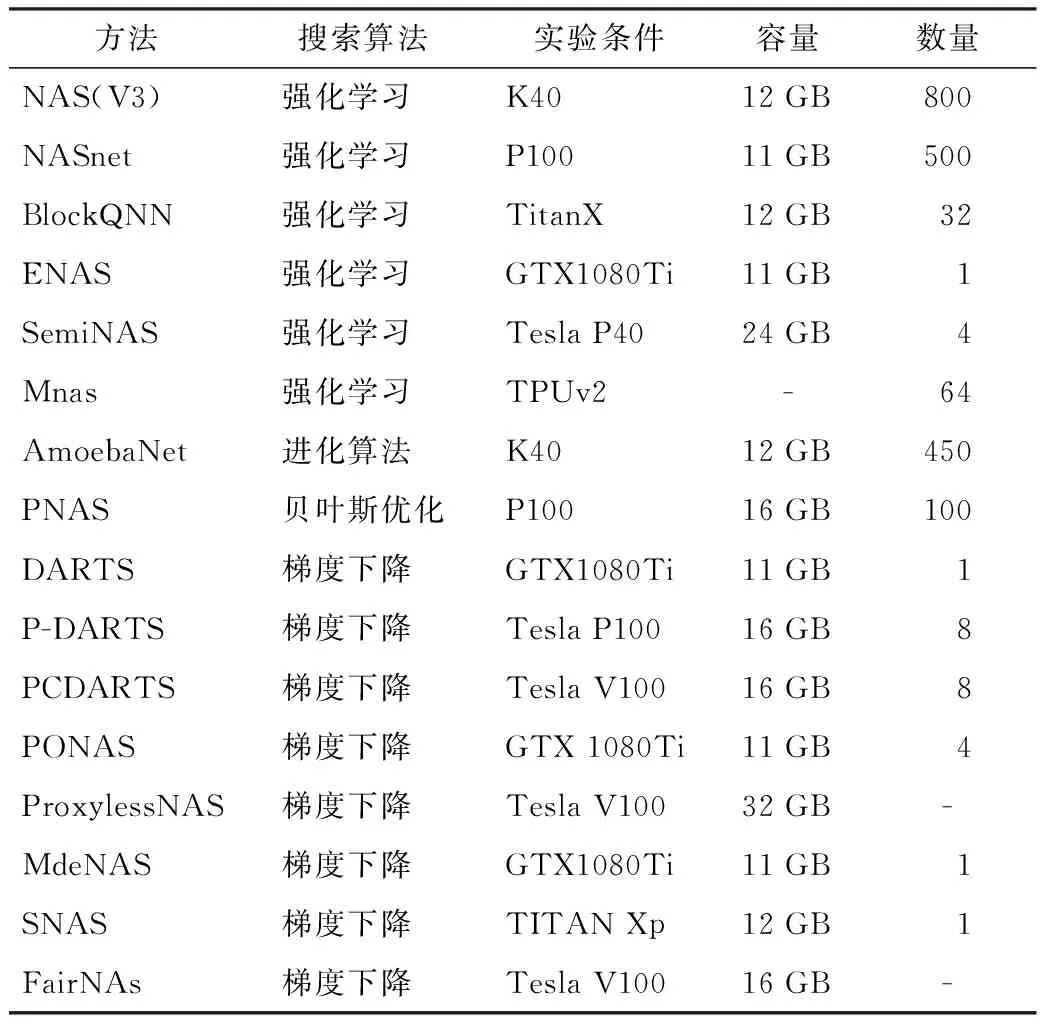
表2 部分神经架构算法实验条件
从表2可以看出,随着研究的深入,神经架构搜索所需要的实验条件逐渐降低,同时网络准确率的不断提升。神经架构搜索在近年取得巨大的发展,除了搜索空间的改进和搜索策略的提升以及参数的优化等3个方面,最大的变化就是与之匹配的实验设备。
从搜索空间来看,基于Cell结构的网络结构在空间多样性和复杂度方面满足要求的同时对计算资源的消耗需求降低,空间大小和网络层数成为影响算力的关键因素。单个GPU计算条件下,在搜索空间设计上进行了简化,从最多的13个候选操作减少为2~3个主要的操作,构建网络的层数也相对较少,整个搜索空间所需要的计算内存较少,单个GPU计算条件下的NAS研究,成为了研究轻量型NAS的新方向。
从搜索策略来看,随机搜索策略作为初代策略,简单直接的进行搜索,没有策略导向,随机性高,对计算资源需求大。强化学习作为神经架构搜索,首先使用“交互型”算法,搜索空间的设计上空间复杂度较高,需要通过不断“试错”找到最佳网络,相比较随机搜索策略,强化学习更加智能,能够根据反馈进行改进,提高搜索效率。在实验设备使用上,基于强化学习的NAS设备利用率更高,需要强大的计算资源做支撑。基于进化算法的策略是一种偏导向的策略,在给定的方向下进行迭代,对搜索空间和实验设备要求没有基于强化学习的高,更多侧重算法层面的优化,快速找到性能较好的网络。随着研究的深入,贝叶斯优化、梯度下降等方法的相继引入,与强化学习和进化算法不同的是,贝叶斯优化和梯度下降是有针对性的策略,局部范围内进行改进,一般搜索空间相对较小,在同等准确率的情况下,搜索效率更高,搜索时间更短。
性能评估在NAS初期对实验条件要求高,在搜索过程中产生的大量参数需要的高性能设备资源去计算。得益于算法的改进,采用权重共享、模型加速和早停等方法降低参数量及模型数量,提高搜索过程中对网络性能的评估效率。通过对评估方法的改进和创新,对搜索空间的进行裁剪和路径选择,并采用更高效的搜索策略,在搜索过程中降低内存消耗,以实现快速评估。
从NAS诞生以来,实验条件成为衡量NAS复杂度的一个标准,出现了NAS空间结构和搜索策略越复杂,需要的计算条件越高的情况。随着NAS的研究方向更加精细化,搜索空间简单、搜索策略高效和评估更快的NAS成为了研究的热点,实验条件正朝着低成本的方向发展。
6 结论
经过近些年的发展,神经架构搜索包含的搜索空间、搜索策略和性能评估等3方面内容有了很大的进展,取得了很多成绩。神经网络构建的模型从简单到复杂,搜索空间相比人工设计的链式网络结构,在空间复杂度方面有了很大的发展,空间结构设计多元化,在一定程度上可以设计出准确率更高的空间。搜索策略从简单的随机搜索,发展到现在多样的策略,越来越多的算法思想被引用到神经架构搜索的研究中,搜索策略更加的灵活,在很复杂的搜索空间中可以高效地搜索出最佳的网络结构,效率极大提高,时间成本大幅降低。性能评估不在局限于边训练、边评估这种耗时耗力的方法,转变研究思路,采取近似估计以及搜索加速的办法,节约计算成本和训练时间。
传统的NAS主要基于搜索空间、搜索策略和性能评估等3个方面研究,随着研究的深入,神经架构搜索可以概括为网络结构优化和参数优化两个互相优化的部分,NAS优化示意图如图12所示。

图12 NAS优化示意图
神经架构搜索的目标是搜索最佳的网络结构,在一定程度上可以转换为网络结构优化和参数优化的双优化问题,两个部分的循环更新以达到最优的效果。网络结构由搜索空间构成,参数优化又是在搜索空间上进行优化,搜索空间的设计可以说是整个神经架构搜索过程各项工作的基础,也是实现突破的重点。从现在的方法来看,以NASNet搜索空间为基础,衍生了很多方法,例如ENAS、MNAS等,DRATS是在ENAS的基础上进行改进和优化方法创新,P-DARTS和PC-DARTS又是在DARTS基础上进一步改进,主要是对搜索策略的改进和参数优化,在搜索空间上的创新较少。在未来的工作中,搜索空间的设计将会是影响神经架构搜索的关键因素之一。同时,网络在搜索过程中会产生大量的参数,参数优化是一个十分艰难的过程,受制于算法和算力,很多方法的参数规模无法进一步压缩,导致在计算过程中会大量占据内存空间,消耗计算资源,参数优化的设计和改进需要进一步研究。
虽然神经架构搜索在时间成本上相比以往有很大降低,但是目前时间成本仍然较高,未来可以通过改进大幅降低搜索时间。同时,神经架构搜索对实验环境要求较高,实验机器等采购成本过高,不利于普惠性推广,未来可以通过对策略以及评估等方面进行研究,降低神经架构搜索的成本消耗。
NAS的评价数据集基本以CIFAR-10[84]、CIFAR-100、ImageNet[85]和PTB[86]数据集为主,最新的适用数据集出现了COCO[87]、DIV2K[88]等数据集用以检测算法的效果,一直以来使用同一数据集检验不同算法效果,将得到的准确率作为判别标准。但是,在任意数据集上的表现,仍有待观察和实验,神经架构搜索的外拓性需要进一步提高。
自2015年NAS被提出来,NAS迎来了井喷式发展,越来越多的研究者投身于NAS的研究。部分典型神经架构算法实验结果对比如表3所示。

表3 典型神经架构算法实验结果
由表3可以看出,在不同的搜索策略下,算法的误差率逐步下降。从时间维度上,NAS的研究重点在策略方面从最初强化学习到现在的进化和梯度下降等,凸显了NAS的研究更加多元、策略化,不再依靠强大的计算资源进行遍历搜索,而是采用更巧妙的方法进行“快捷”搜索。
目前,神经架构搜索的衡量标准只能做到“局部统一”,即在同等的搜索策略下,对数据集误差率和准确率进行对比。神经架构搜索也可以说是一个组合优化问题,使用不同的方法进行相应的组合,在同等策略的条件下进行纵向比较,会有一定的进步和创新。但是整个NAS的横向比较中,以数据集的误差率和准确率作为“统一”标准来看,提升的效果不是很明显。NAS作为一个开放性的研究领域,目前缺乏一个共识性的统一标准衡量所有方法的优劣。
7 展望
神经架构搜索已经被证明在未来具有巨大的前景,目前NAS主要还是在理论研究,受制于理论空间设计等因素,NAS所涉及的实际场景应用较少,未来经过改进的NAS在图像识别、数据处理和视频处理等方面将会是强有力的竞争者。
在研究内容上,搜索空间和搜索策略将会在现有的基础上更加完善,性能评估将会在参数优化方面迎来更大的发展,多方法融合的策略将会成为推动NAS研究的动力之一。在实验条件上,随着计算机体系结构的研究发展,将会出现更多性能高、低功耗的实验室设备,支持和加速NAS的研究发展,NAS的性能相比较目前的水平,将会有一个更大幅度的提升。在应用方向上,超大数据模型网络以及移动端网络将会成为神经架构搜索研究的重点。超大型数据模型网络,比如图像识别分割以及数据分析领域,对大型公司而言,不用在分地区、分类别进行分析甄别,神经架构搜索将会针对以亿为单位的数据集自动搜索得出最适于数据集的网络,以先共性后个性原则,分析数据的特点,最终呈现出以前分割状态下难以发现的数据规律,其算法的准确度和性能将会比利用现存的网络模型的结果更优秀。移动端将会产生大量数据,移动端的神经架构搜索以轻量化为主,以极小的时间得到最佳的结果。在数据集应用上,随着未来研究的深入,更多适用的NAS数据集会产生,NAS可以被应用于广泛的实验验证以及理论研究当中。神经架构搜索将会成为未来人工智能的主流,推动各个领域发展。
