基于多级索引的前向语义数据流推理
2022-01-28杨帆玉顾进广
高 峰 杨帆玉 顾进广
(武汉科技大学计算机科学与技术学院 湖北 武汉 430065)(湖北省智能信息处理与实时工业系统重点实验室 湖北 武汉 430065)
0 引 言
在大数据领域,语义数据量急速增长,越来越多的应用程序要求能够实时处理语义数据流,特别是在处理和查询庞大复杂的RDF(Resource Description Framework)数据流方面,仍然有着巨大难题。一方面,为了满足数据流的高吞吐量和低延迟,流处理引擎处理必须足够有效;另一方面,查询语言必须具有一定的表述能力,才能支持可能需要递归的逻辑推理。目前,流处理模型还没有一个统一的标准,流处理系统应该有自己的流模型和查询语言,由于缺乏统一的标准,所以设计流系统变得异常困难。由于RDF流数据的生成速率极快,连续的SPARQL[1]查询通常涉及到密集的联接操作,这些操作很可能会造成性能瓶颈,因此需要针对性的优化技术。与连续SPARQL查询处理相比,RDF流推理的复杂性和支持实时推理的难度更大,特别是在传递规则的推理方面,其推理结果是指数级的;与此同时,推理结果并不全是有用的,如何去消除中间集减少冗余数据也是一个难题。
针对上述难题,本文提出了CSPARQL-Ci,即基于C-SPARQL[2]和Cichlid[3]的RDFS流推理平台,使用支持复杂事件处理的ESPER[4]流处理引擎,其吞吐量达到每秒十万级别;基于Spark[5]的Cichlid进行RDFS流推理,并针对传递规则的推理效率低和推理中间集冗余提出了多级索引算法,主要包括优化的传递规则推理算法和中间集消除算法。优化的传递规则推理算法是将RDF结果集分割为多个具有相同传递规则的子图,再将子图内部各个节点相互联接得到新的RDF。中间集消除算法主要是根据单个查询条件分割生成对应的子图,再通过查询条件依赖关系进行联接操作得到满足条件的集合。和ECS[6]、C-SPARQL和BigSR[7]等平台在相同的LUBM[8]数据集做对比实验和评估,结果表明大部分情况下查询延迟都有很明显的优势。
1 相关工作
1.1 RDF流和C-SPARQL
RDF流由一系列成对的有序序列组成,每对序列由一个RDF三元组和对应的时间戳组成,每个RDF三元组对应的结构是t∈
最早提出的C-SPARQL采用ESPER处理RDF数据流和Jena[9]进行SPARQL查询。本文的中间集消除算法则是在上述查询语句的基础上建立常量和变量索引,通过常量索引得到满足任一查询条件的三元组,通过变量索引得到满足全部查询条件的三元组。
1.2 RDFS流推理
基于RDF,RDFS定义了一组表示隐藏信息的规则,RDFS推理规则集如表1所示,而推理是通过使用RDFS推理规则从现有的RDF数据中推断出隐式信息的过程。例如,给定一个RDF图G,可以从RDFS规则中得到一些表示为T的新的三元组,将T添加到G,则可以获得更大的RDF图G′,从G到G′的过程称为推理。
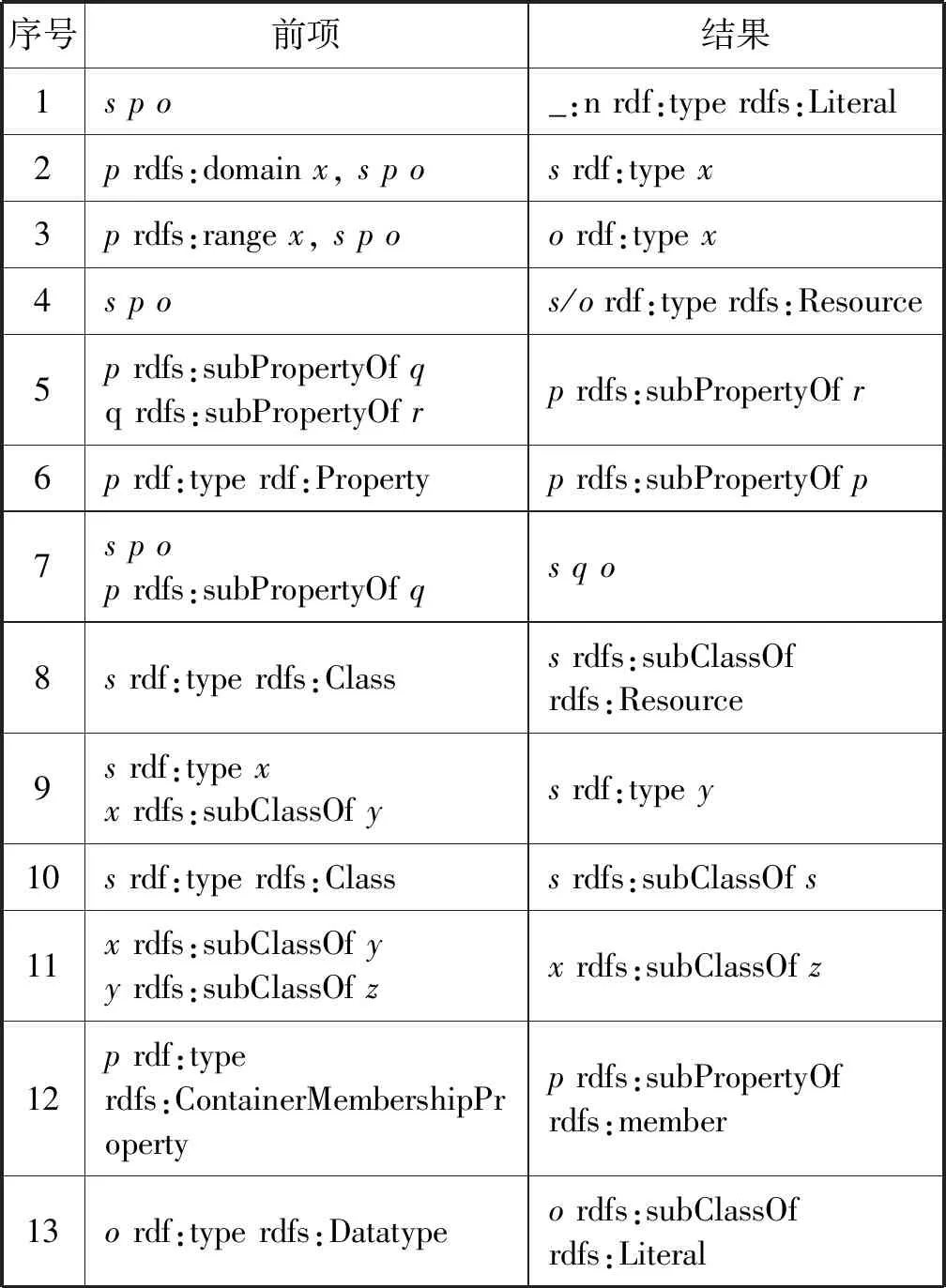
表1 RDFS规则集
RDF数据的推理可以采用前向链式和后向链式两种不同的策略进行推理。前向链式推理是从数据开始,通过利用规则集循环迭代得到新的RDF数据,将派生的RDF数据添加到原始RDF数据中,以供后期查询和推理,如Cichlid;而后向链式推理则是根据查询条件出发,根据规则集动态查询是否有满足的事实,如EP-SPARQL[10]。文献[11]提出,前向链式推理相对缩短了查询响应时间,但是资源开销比较大而且会有重复数据。
目前,针对语义数据流的推理研究主要关注对复杂推理能力的支持,或对简单查询的性能优化。在评测集方面,SRBench[12]、CSRBench[13]、CityBench[14]和YABench[15]等常见的RDF流处理评测集对于流系统的设计有很大的帮助。在处理系统方面,有很多RDF流处理系统相继被提出。最先提出的C-SPARQL内置推理性能一般;CQELS[16]是最先进行连续SPARQL查询优化的系统,CQELS将输入流预处理,然后通过查询优化后获取了很高的性能;ETALIS[17]是一个基于规则的复杂事件处理引擎,EP-SPARQL在ETALIS的基础上插入了一个编译器层,将连续的SPARQL查询编译为逻辑规则。StreamRule[18]使用RSP引擎和Clingo[19]进行数据流预处理和推理查询,吞吐量较之前提升数倍,但在推理能力仍有不足;Laser[20]和Ticker[21]都是基于Lars[22]架构的流处理引擎,Ticker主要专注于增量模型维护,但是依赖外部引擎而降低了一定的性能;Laser提出了基于时间的增量模型,降低了重复计算;BigSR是结合Spark和Lars架构的分布式流推理平台,有着百万级别的吞吐量和毫秒以内的延迟。本文采用的是前向链式推理策略,并针对重复数据问题,在YARS[23]和ECS的索引基础上提出一种改进的中间集消除算法。
2 数据流推理引擎设计
本节在CSPARQL引擎的基础上扩展,并提出一种基于多级索引的前向语义数据流推理引擎(CSPARQL-Ci),其系统架构如图1所示。
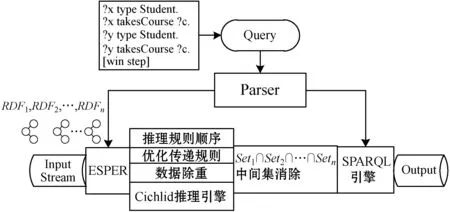
图1 CSAPRQL-Ci系统架构
2.1 系统架构
图1所示的CSPARQL-Ci主要由以下四个部分组成。
(1)ESPER流处理引擎:主要负责将输入的RDF流与对应的查询进行绑定,然后进行窗口操作,并提取滑动区间内的三元组数据放入Cichlid推理引擎中。
(2)Cichlid推理引擎:将ESPER输出的RDF数据进行处理,并根据RDFS推理规则的依赖关系,建立一次推理顺序,然后利用传递规则算法进行RDFS的传递规则推理,最后将推理的结果进行数据除重。
(3)中间集消除:根据查询条件的常量和变量建立不同的索引,并根据推理出来的结果进行分类,筛选出满足查询条件中常量的RDF数据,再将相同变量进行联接操作以进一步筛选得到大部分满足的推理结果,最后放入SPARQL查询引擎中。
(4)SPARQL引擎:将筛选后的三元组数据放入该引擎中,构建图模型并进行SPARQL查询,最后将查询得到的结果输出。
2.2 优化传递规则推理
传递规则推理衍生的结果是指数级别的,并且推理过程需要多次迭代,例如规则集中的规则5和规则11,以及本文应用的schoolMate规则等。进行传递规则推理本质上是在RDF图上计算传递闭包,从关系代数理论的角度来看,计算传递闭包的一种常见的方法是对数据流执行自联接,但是该方法有两个缺点:1)包含太多的迭代处理,长度为n的传递链需要进行n倍的迭代计算;2)推理过程冗余,以计算传递链p1→p2→…→p10为例,在计算从
本文使用的LUBM数据集是一个主要描述学校组织关系的数据集,其本体模型中的属性memberOf表示学生和学校之间的关联关系,即该生为该校成员;schoolMate表示校友关系,s1和s2都是该校的成员,那么s1和s2就互为校友,如果一个学校的成员有n(n>1)个人,要查询互为校友的成员,其结果为n×(n-1)个。针对上述场景,本文定义了如下传递推理规则。
(s1,memeberOf,u),(s2,memberOf,u)=>
(s1,schoolMate,s2),(s2,schoolMate,s1)
进一步对于所有与schoolMate类似的传递规则的属性,有如下定义:
(p,type,transitive),(s1,p,s2)=>(s2,p,s1)
具体的传递规则推理算法分为两步,如算法1所示。
算法1传递规则推理
输入:三元组triples。
输出:推理结果out。
begin
valmap=Map
valin=Set
valout=Set
for(tintriples){
if(map.containsKey(t.p))
input.add(t)
}
valg=Map
for(tinin){
if (!g.get(t.p).containsKey(t.o))
g.get(t.p).put(t.o,Set)
g.get(t.p).get(t.o).add(t.s)
}
for(transing.keySet())
for(uing.get(trans).keySet())
for(s1,s2ing.get(trans).get(u))
out.add(Triple(s1,map.get(trans),s2))
returnout
end
(1)子图索引构建:将筛选满足传递规则的三元组作为输入数据;开始遍历三元组,如果该三元组表示的元素所属的子图已经存在,那么放入该子图,如果不存在则新建子图并放入该元素;生成同一学校的学生与所属学校对应的一个子图。
(2)遍历各子图:将第一步中多个子图进行遍历,最后取出处于同一子图的元素进行联接得到输出结果。
2.3 中间集消除
经过Cichlid推理引擎得到的输出结果数量是巨大的,经过了数据除重之后仍然大部分的数据都是与查询不相关的,如何根据查询语句建立索引将无用数据最大程度的剔除掉显得尤为重要。经过分析,查询语句中存在常量和变量,通过常量可以很直接地消除大部分不满足的三元组,通过不同查询语句中相同变量集合进行联接可以消除掉只满足部分查询条件的三元组。根据查询语句的结构,设计了以下6种索引结构,其中“?”表示查询的变量,对应的右边的变量索引下标(该变量在查询中首次出现的下标,“0”表示为常量),根据这些索引可以将输入的三元组分为这6种集合,每种集合都满足该查询的索引结构,具体如表2所示。
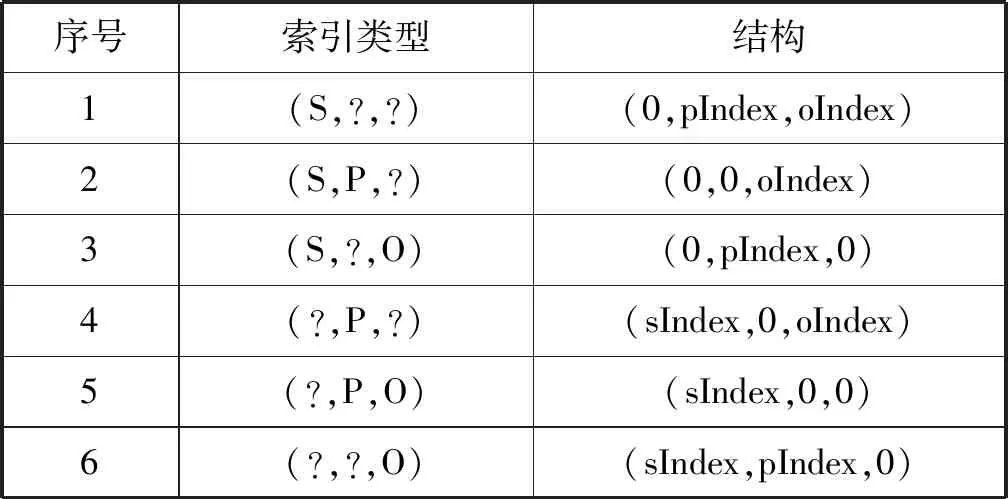
表2 索引结构
具体消除算法可大致分为三步,如算法2所示。
算法2中间集消除
输入:三元组triples,变量表indexList。
输出:消除后结果set。
begin
valmap=Map
valmapSet=Map
valin=List
for(indexinindexList){
for(tintriples)
if(index.match(t))In.get(index).add(t)
}
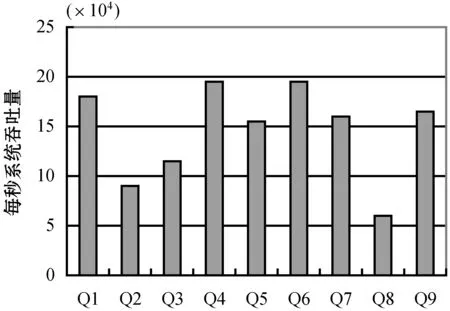
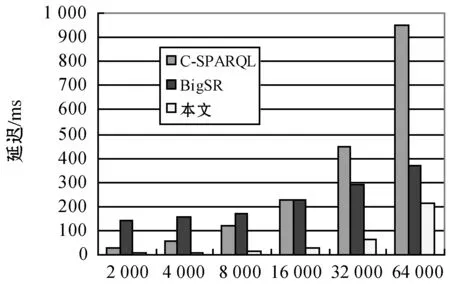
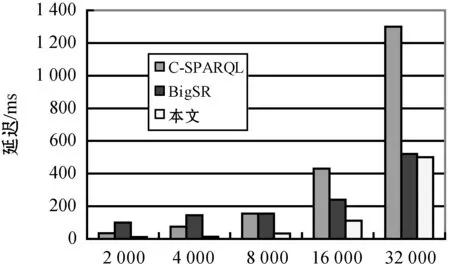
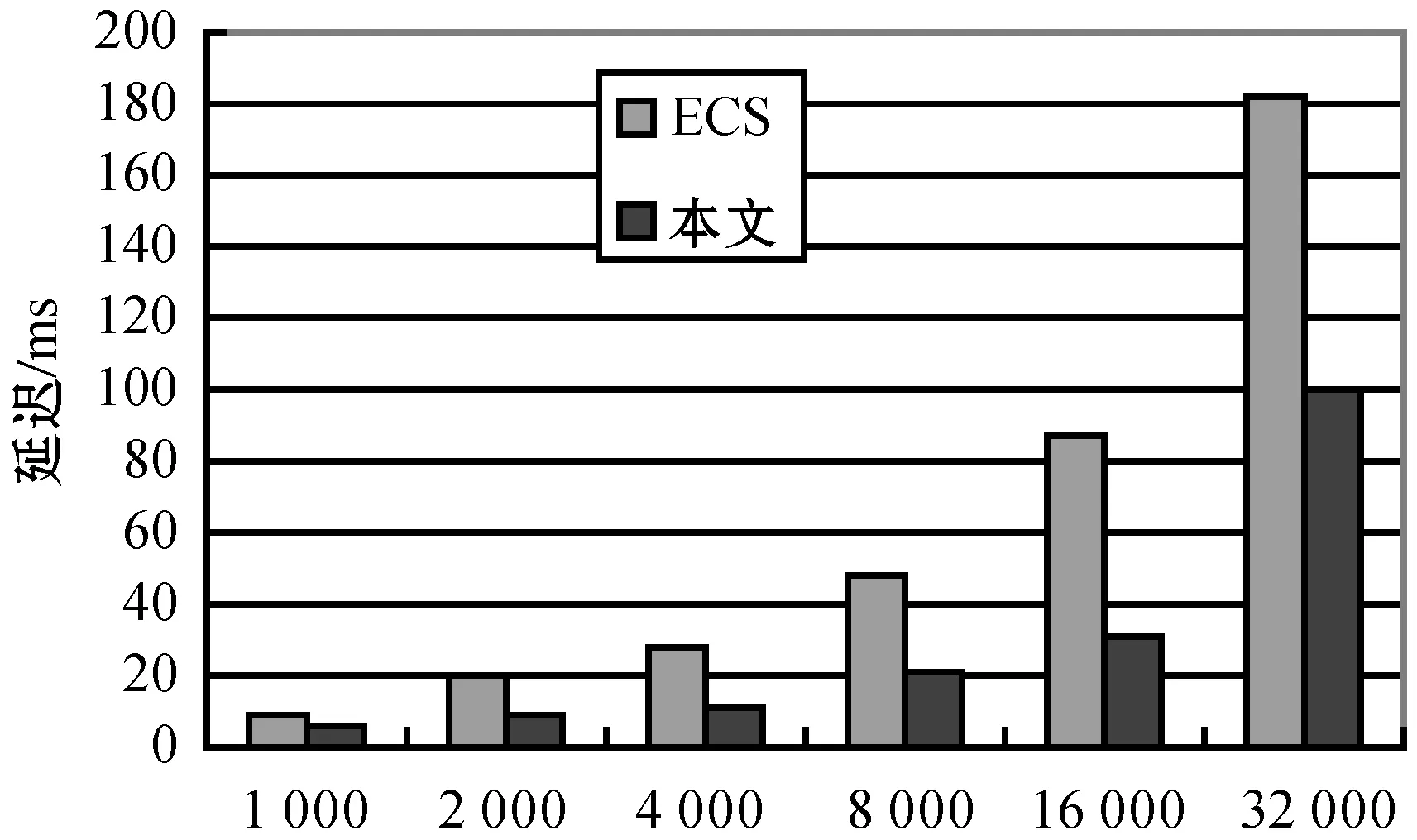
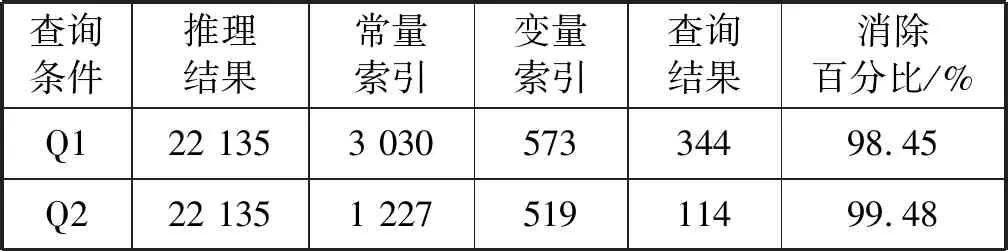
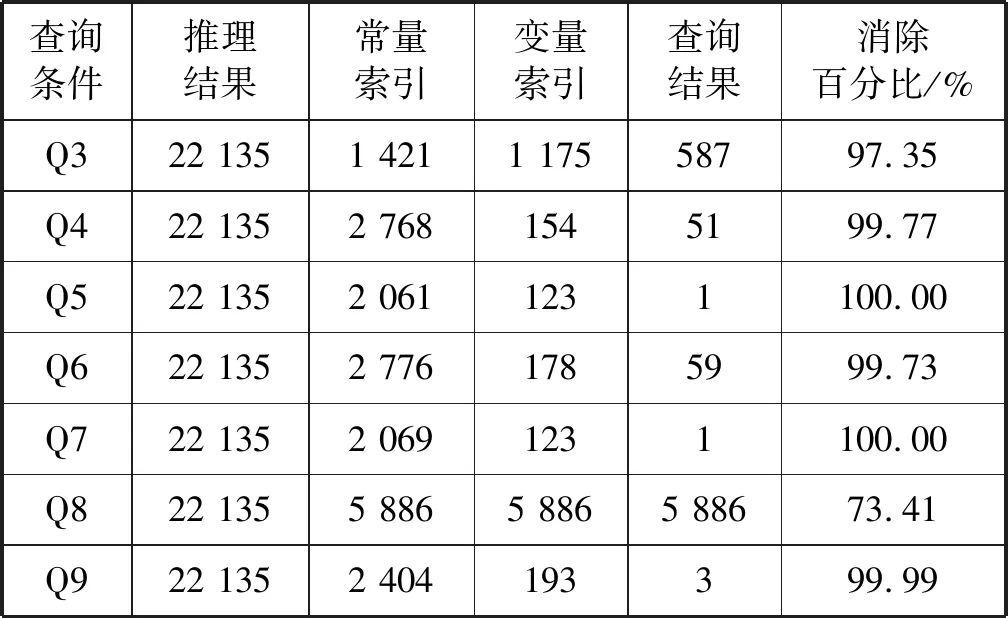
for(i valindex=indexList.get(i)curr=0 for(j valt=in.get(i).get(j) map.get(index.sIndex).get(curr).add(t.s) map.get(index.pIndex).get(curr).add(t.p) map.get(index.oIndex).get(curr).add(t.o) }} for(i<=num;i++) //未知变量的数量 for(tinmap.get(i).get(0)){ while(j !map.get(i).get(j).contains(t)?b=false break j++} b?mapSet.get(i).add(t) } returnmapSet end (1)根据常量筛选满足的集合,建立查询条件——满足条件三元组集合的关系表,将输入的每个三元组放入满足条件的集合,如果存在一个三元组满足多个条件,需放入多个集合中。 (2)建立变量集合表,将所有满足不同查询条件的相同变量分别放入与变量对应的集合中,相同变量的集合构成了变量集合表。 (3)联接获取所有变量集合表中每个变量的子集,将属于同一变量的子集依次进行联接操作,可以得到满足所有查询条件的公共子集。 实验代码基于Java8,数据集和查询测试可在GitHub(https://github.com/qq348991318/CSPARQL-Ci.git)上获取。实验使用的操作系统是MacOS 10.15,CPU是8259U,主频2.3 GHz,内存16 GB。实验数据集是综合基准的LUBM50数据集,它是一种广泛使用的标准基准;采用系统吞吐量和查询延迟作为主要的性能指标,吞吐量表示单位时间内可以处理多少数据,在本文中表示为每秒多少个三元组;延迟是指输入到达和生成输出之间消耗的时间。将CSPARQL-Ci与ECS、C-SPARQL和BigSR在单机的环境下做了对比实验。设计了多组查询语句,每个查询分别为每秒200、400和800个三元组,窗口大小为10 s、20 s、40 s和80 s,并统计多次查询延迟和吞吐量的平均值。 本文根据LUBM数据集设计了9组查询语句,分别对实体层次结构(Q2、Q4)、属性层次结构(Q3、Q4)、实体和属性关系的层次结构(Q1、Q4、Q5、Q6、Q7、Q9)及传递规则(Q8)进行推理。实体层次结构是指实体的上下位关系,例如本科生是学生的子类,查找所有学生就需要对本科生进行推理;属性层析结构是指属性的上下位关系,例如为学校工作的教授是该学校的成员,那么工作就是成员的子属性。实体和属性关系的层次结构是混合了实体和属性的多层次结构。 1)吞吐量。图2展示了系统的吞吐量,一共统计了9组不同的查询。在单机下,最高吞吐量达到每秒19.5万个三元组;在传递规则推理查询中吞吐量会降到每秒6万个。经过中间集消除算法,系统吞吐量在C-SPARQL的4万的吞吐量的基础上提升了近4倍;但由于本实验中系统为集中式处理系统,在吞吐量上对比分布式的BigSR有一定差距。 图2 CSPARQL-Ci在LUBM查询吞吐量 2)延迟。统计9组不同的查询,记录了多次查询延迟的平均值,并分别与C-SPARQL和BigSR在单机的条件下作了对比实验,分别记录了多组数据的平均查询延迟和传递规则查询延迟,实验结果如图3和图4所示。 图3 CSPARQL-Ci与同类引擎查询延迟对比 图4 传递规则查询延迟 如图3所示,在单机测试环境下,平均查询延迟是最低的;但是因为查询还是基于Jena,所以随着吞吐量的提升,查询延迟比BigSR增幅要快。如图4所示,针对传递规则查询的统计中,由于推理结果是指数级,因此查询的延迟也大幅度提升。实验结果表明,优化算法大幅度减少了推理和查询时间。 3)索引结构。本文也与在流平台下的ECS索引进行了对比实验。由于ECS是基于文件的静态索引,在持续的流查询中性能无法评估,并且ECS的查询时间是微秒级别的,因此统计了索引的构建时间作为查询延迟,索引文件的载入时间不计算在内。如图5所示,本文在ECS的基础上采用了部分索引,简化了索引构建过程,但在一定程度上增加了查询时间,综合效果更好。 图5 索引构建与查询 4)索引效率。本文针对不同的查询统计了多级索引删除冗余数据的效率,如表3所示,在每秒一万个三元组的速率下,分别统计了推理结果后、经过常量索引筛选后、经过变量索引筛选后和最终满足查询结果的数量。在统计过程中,中间级消除算法可以减少近99%的无关推理结果,因为算法依赖查询条件之间常量和变量之间的依赖关系,所以随着查询条件的增多,消除比例也在增加。 表3 索引效率评估 续表3 本文在C-SPARQL的基础上,加入了Cichlid推理引擎。针对前向推理数据冗余提出了传递规则优化算法和中间级消除算法,并与ECS、BigSR和C-SPARQL做了对比实验,实验结果表明,本文的推理机制不仅提高了原有系统吞吐量,而且大幅度地降低了查询延迟。但是本文方法仍然存在一些不足,例如基于Jena查询在一定程度上限制了查询效率,因此系统在处理大规模的RDF流推理仍存在不足,未来可以考虑实现分布式索引查询,增加RDF流推理的规模。3 实 验
3.1 实验配置
3.2 实验场景设置
3.3 实验结果分析
4 结 语
