基于WGAIL-DDPG(λ)的车辆自动驾驶决策模型
2022-01-27张明恒,吕新飞,万星,吴增文
张 明 恒,吕 新 飞,万 星,吴 增 文
(1.大连理工大学 工业装备结构分析国家重点实验室, 辽宁 大连 116024; 2.大连理工大学 汽车工程学院, 辽宁 大连 116024 )
0 引 言
近年来,随着汽车保有量的逐渐增加,交通安全、道路通行效率问题日益严峻,而自动驾驶被认为是解决上述问题的有效途径之一.从安全性方面来看,由于驾驶人反应不及时、处置不当而造成的交通事故频发[1],自动驾驶在为人们提供舒适乘车体验的同时,也有助于减少交通事故.从稳定性的角度来看,以车辆在行驶过程中的换道行为为例,人类驾驶员在换道过程中有较强的顿挫感,自动驾驶技术则可以显著提升车辆在换道过程中的稳定性与舒适性[2].基于信息处理过程,自动驾驶可分为环境感知、决策规划、运动控制3个阶段[3].其中,决策规划是实现自动驾驶的关键技术之一.
目前,主要有3种自动驾驶决策规划系统解决方案:基于规则的决策规划系统[4-5]、基于深度学习的“端到端”决策规划系统[6-7]和基于深度强化学习的决策规划系统[8].现有的自动驾驶决策规划系统很大一部分是基于规则的,虽然可以满足常规驾驶情况,但由于我国道路通行条件复杂,不能枚举出所有可能遇到的事件,无法应对一系列未经考虑的突发情况[9],因此,依靠基于规则的决策规划系统进行自动驾驶决策具有较高的安全隐患.基于深度学习的“端到端”决策规划系统虽然取得了一定的成就[10],但深度学习网络需要大量标注好的样本进行网络训练,其训练结果的优劣很大程度上取决于训练样本的选取,而且人工进行大量训练样本的标注是不现实的[11],这些缺陷表明深度学习在自动驾驶决策控制领域的应用存在一定的局限性.基于深度强化学习的自适应控制方法由于可以进行自我学习和自我强化,在场景多变的自动驾驶任务中具有很好的泛化性,逐渐被应用在自动驾驶领域中[12].
对于深度强化学习,可靠性、学习效率和模型泛化能力是决策系统的基本要求.Gao等[13]基于强化学习算法提出了一种车辆决策模型,该模型在简单交通场景下表现出较好性能;为解决复杂场景下的驾驶决策问题,Zong等[14]基于DDPG(deep deterministic policy gradient)算法构建了驾驶决策模型,该模型可以应对复杂场景,但学习效率较低;为解决模型的计算效率问题,Anderson等[15]借鉴深度学习预训练技巧提出了一种强化学习预训练方法,该方法有效提高了强化学习训练效率,但还存在着试错成本高和安全性低等问题.
DDPG算法在连续动作的控制上表现优异,可以很好地解决自动驾驶汽车的连续控制问题,目前有关深度强化学习在自动驾驶决策控制领域的研究,大都以DDPG作为基础算法.黄志清等[16]通过TORCS(the open racing car simulator)平台的不同赛道对DDPG算法进行训练,并将训练结果与DQN(deep Q-learning network)算法进行对比,结果表明DDPG算法在控制精度以及泛化性方面具有更好的效果;张斌等[17]基于DDPG算法提出了一种FEC-DDPG算法,该算法在消除非法驾驶策略的输出上表现出了较大的优越性,但无法在复杂路况下对车辆进行较好的控制;Zou等[18]提出了一种DDPG-IL算法,通过引入双经验池来分别存储专家数据和普通数据,同时使用随机采样的方式打乱了两个经验池数据的相关性,使算法具有更快的收敛速度和更好的性能.相关研究表明,以DDPG算法作为基础算法进行自动驾驶控制决策系统的研究可以取得较理想的结果.
基于此,本文基于深度强化学习理论提出一种用于车辆自动驾驶决策的WGAIL-DDPG(λ)(Wasserstein generative adversarial nets-deep deterministic policy gradient(λ))模型.其中,针对强化学习模型构建关键过程,基于车辆行驶性能要求对奖励函数进行具体设计;通过模仿学习策略的引入,提升模型的计算效率;通过增益调度器的设计,保证从模仿学习到强化学习的平稳过渡.
1 基于WGAIL-DDPG(λ)的自动驾驶决策模型
1.1 模型框架
本文提出的WGAIL-DDPG(λ)自动驾驶决策模型框架如图1所示.DDPG算法通过其Actor 网络生成的驾驶策略加入随机噪声后作为判别器的一个输入,判别器为经过专家数据训练完成的GAN网络的判别器,其以专家数据作为监督信号对DDPG算法生成的驾驶策略进行评分,评分与所设计的奖励函数共同指导DDPG算法进行更新.

图1 WGAIL-DDPG(λ)自动驾驶决策模型框架Fig.1 Automatic driving decision model framework of WGAIL-DDPG(λ)
DDPG算法框架如图2所示.DDPG算法属于Actor-Critic算法,由演员Actor和评论家Critic两部分构成.由于单个子网络的学习过程不稳定,DDPG借鉴了DQN中延时更新Target Net的经验,将Actor和Critic分别又细分为两个子网络:Online Net与Target Net.两者具有相同的网络结构,但具有不同的网络参数,Online Net使用最新的网络参数,每隔一定步数对Target Net的网络参数更新一次.Online Net与Target Net网络参数的不同切断了两者之间的相关性,使网络的学习过程更加稳定.
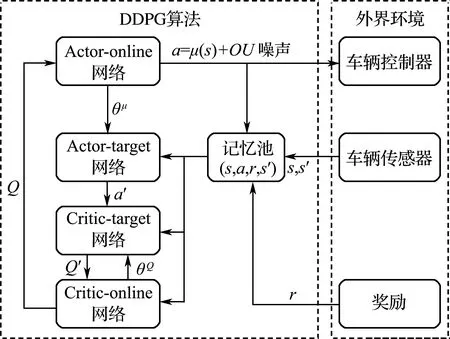
图2 DDPG算法框架Fig.2 The framework of DDPG algorithm
增益调度器的引入将模型分为模仿学习、模仿-强化学习过渡、强化学习3个阶段.阶段一是模仿学习阶段,见图1中增益调度器的黄色背景部分,其主要任务是让智能体在专家策略指导下具备初级驾驶决策功能,解决强化学习前期试错次数过多问题;阶段二是模仿学习向强化学习的平稳过渡,即图1中的绿色背景部分,其主要任务是防止模型在第三阶段的探索过程中偏离初级驾驶策略的分布;阶段三是强化学习阶段,即图1中的蓝色背景部分,其主要任务是让智能体通过与环境的交互,具备更高级的自动驾驶决策功能.
上述模型设计的关键环节在于两方面:奖励函数设计和模仿-强化学习的过渡.其中,奖励函数用以评估强化学习过程优劣,对模型训练结果具有关键影响;实现模仿学习向强化学习的平稳过渡是保证在“自学”阶段数据分布不偏离专家数据分布的重要条件.基于此,本文从车辆使用安全性、稳定性两方面出发对奖励函数进行了具体设计,通过所设计的增益调度器保证模仿学习向强化学习的平稳过渡.
1.2 数据来源
对于实际车辆驾驶过程,影响驾驶人决策的主要外环境信息包括车辆因素、环境因素、道路因素[19].图3为典型车辆行驶外环境信息示意图,其中b为车辆中心与道路中线的距离,d反映本车与其他车辆的相对距离,W为当前车道宽度,vx为车辆纵向速度,vy为车辆横向速度,vz为车辆垂向速度,θ为车辆行驶方向与道路中心线的夹角.

图3 车辆行驶外环境信息示意图Fig.3 Schematic diagram of external environment information of the running vehicle
鉴于实际行车数据获取难度及本文研究目的,本研究基于TORCS平台进行相关数据的获取和模型验证工作.基于车辆行驶性能分析结果,本文所构建的基础数据库由反映车辆安全性、稳定性的两类数据组成,如图4所示.
(a) TORCS平台
1.3 奖励函数设计
强化学习过程是智能体在与环境交互过程中获得最大奖励的过程[20].满足行驶安全性是智能汽车发展的首要要求,在满足安全性的基础上再考虑稳定性等其他要求.因此,从车辆自动驾驶决策系统的功能属性本质要求分析,其一方面应满足车辆行驶的安全性要求,另一方面应尽可能满足行驶过程中的稳定性以提升通行效率及乘坐舒适性.本文基于汽车行驶性能要求,从稳定性、安全性两方面对奖励函数进行具体设计.车辆在行驶过程中,从稳定性的方面考虑,希望使横向速度vy、车辆中心与道路中线的距离b尽可能小,以得到较大的沿道路中线的速度vxcosθ,同时,希望垂直于道路平面的速度vz尽可能小.从安全性方面考虑,希望智能体与其他车辆保持安全距离.同时,为尽可能地使仿真平台模拟现实环境,本文同时设计了复杂交通场景下的奖励函数.
其中,基于单车工况的DDPG模型和WGAIL-DDPG(λ)模型奖励函数分别为
(1)
(2)
其中权重系数向量Cs=(c1c2c3c4)T,vs=(vxcosθ-|vy| -|vz| -|b|)T,λ为用于调整判别器长期监督信号在强化学习奖励中占有的权重的超参数,Si是来自生成对抗模仿学习模块中判别器网络的评分.
复杂交通场景中存在其他车辆时,相应模型的奖励函数分别为
(3)
(4)
其中权重系数向量Cm=(c1c2c3c4c5)T,vm=(vxcosθ-|vy| -|vz| -|b| -vxd)T,fdmg为车辆碰撞时仿真平台返回的受损程度.
1.4 增益调度器设计
增益调度器设计的基本目标是实现从模仿学习阶段向强化学习阶段的平稳过渡.借鉴人类学习过程,在模仿学习阶段,判别器打分对生成器动作优化起主要作用;在强化学习阶段,奖励函数对智能体动作优化起主要作用.因此,λ应具有随模型训练进程逐渐平滑衰减的特性,以保证模型的稳定性,且模型中对应的强化学习部分的权重与λ应满足和为1这一特性.
线性衰减曲线随着训练次数n的逐渐增加呈线性下降,且衰减程度恒定.若衰减程度过大,可能会出现过渡不平稳的情形,在模型训练中表现为强化学习阶段的决策分布偏离专家数据的决策分布;若衰减程度过小,则过渡阶段的训练次数会有所增加,与本文提出的通过引入模仿学习提升强化学习效率的策略相悖.指数衰减型曲线在保证快速衰减的同时具有一定的平滑性,初始阶段衰减程度随训练次数n的增加逐渐增加,快速向强化学习阶段过渡;结束阶段,衰减程度随n的增加逐渐减小,趋于稳定,满足增益调度器的设计要求.
基于此,本文所设计的增益调度器模型为
(5)
式中:N0为增益调度器幅值,α为指数衰减常数.
为验证增益调度器设计的有效性,当α=0.5时,增益调度器特性变化曲线如图5所示.

图5 增益调度器特性曲线Fig.5 Gain regulator characteristic curve
可见,在模型训练起始阶段[n0,n1),λ=1,表明判别器打分对生成器动作优化起主要作用,而奖励函数不起作用;随训练次数逐渐增加,奖励函数权重逐渐增大,而判别器监督作用逐渐降低,从而实现了从模仿学习到强化学习的平稳过渡.
从模仿学习到强化学习的过渡过程中,不同的λ所对应的算法如表1所示.

表1 λ-算法类型对应关系Tab.1 Correspondence relationship of λ-algorithm type
可见,本文所设计的WGAIL-DDPG(λ)算法兼具了模仿学习和强化学习的优点,在[n0,n1]阶段,智能体在专家数据的指引下能尽快地学会基本驾驶策略,大大降低了探索空间;在[n2,n3]阶段,智能体在与环境交互的过程中不断探索更高级的驾驶策略.另外,上述设计的增益调度器实现了从模仿学习到强化学习的平稳过渡.
2 模型测试及结果分析
基于本文研究目的,以下分别针对模型性能、适应性和学习效率进行相关测试和分析.
2.1 性能测试
在设计奖励函数时,本文重点考虑了自动驾驶车辆的稳定性、安全性,因此本文对上述性能进行了测试.
2.1.1 稳定性 稳定性是表征汽车操纵特性的基础性能之一,本文利用归一化之后的智能体偏离道路中线的距离2b/W评价自动驾驶控制系统的平稳性.2b/W越接近0,说明控制系统的循迹稳定性越好;反之,说明车辆偏离道路或左右摆动趋势越明显,稳定性越差.由图6的测试结果可以看出,归一化后车辆偏离道路中线的距离一直在-0.3~0.3波动,表明训练1 300次本文算法可以控制智能体很好地完成车道保持任务.
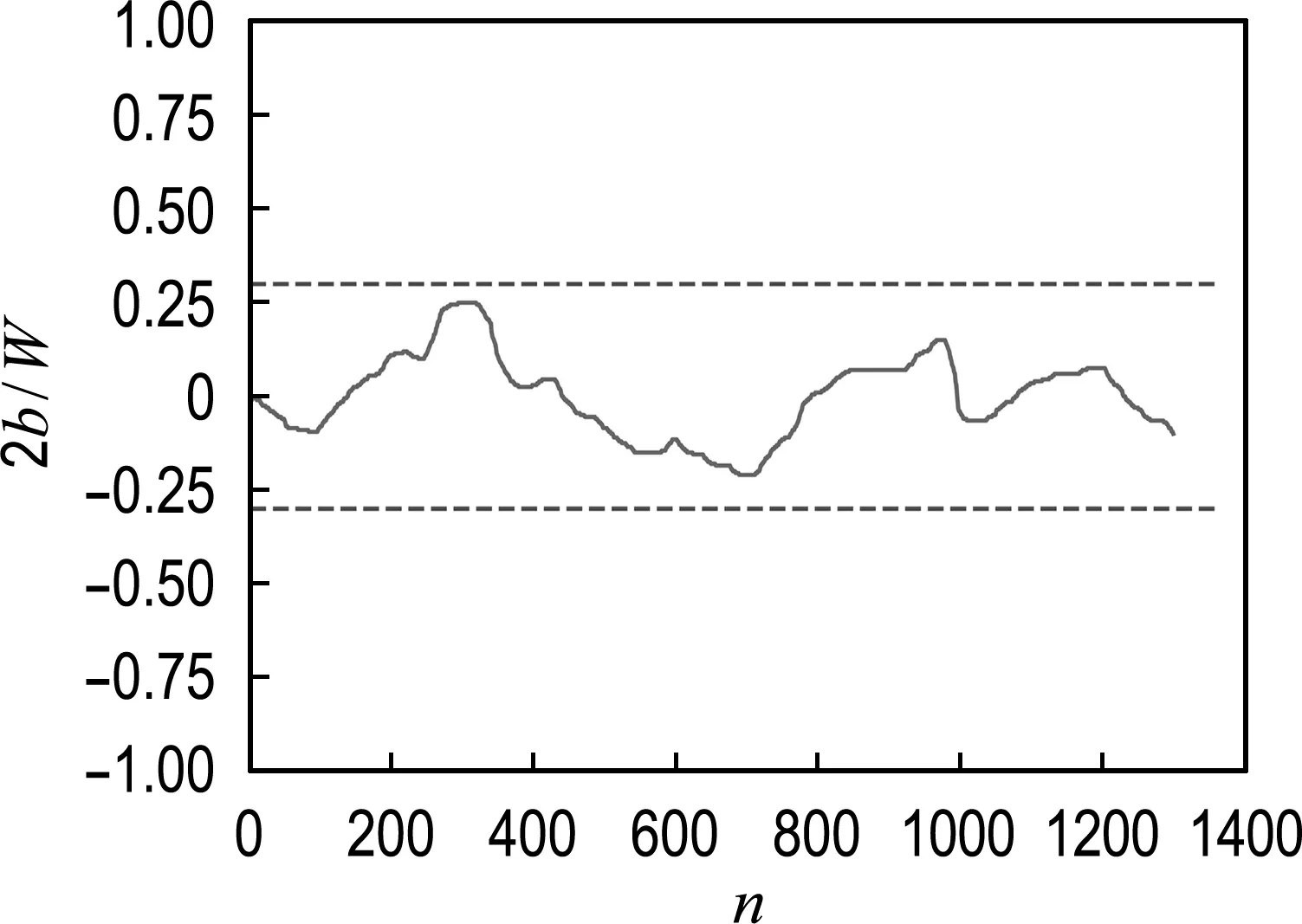
图6 稳定性Fig.6 Stability
2.1.2 安全性 本文基于智能体与周边距离最近车辆的相对距离d这一指标来评价自动决策系统决策方案的安全性.d越小,说明车辆发生碰撞的风险越大.
从测试结果图7可以看出,在刚起步,即n=0时,安全距离d<2.5 m,究其原因在于,智能体与其他车辆从同一起点出发;在n=1 000时,d急剧减小,通过观看测试过程发现,干扰车辆突然超车,智能体为避免与其发生碰撞做出正确决策并逐渐减速,保证与干扰车辆保持安全车距.除上述两处外,智能体与周边其他车辆的距离基本保持在10 m以上,表明所设计的决策模型在多车工况下可以保证车辆具有较高的安全性.
2.2 模型适应性
适应性是表征算法对新样本、新工况的适应能力.为了验证所提出WGAIL-DDPG(λ)模型的适应性,本研究选取训练4 000次时的模型(多车奖励函数,CG Speedway-1)、较复杂的Alpine赛道和较简易的CG Track3赛道进行了相应测试,赛道特征对比如图8所示.

图7 安全性Fig.7 Safety
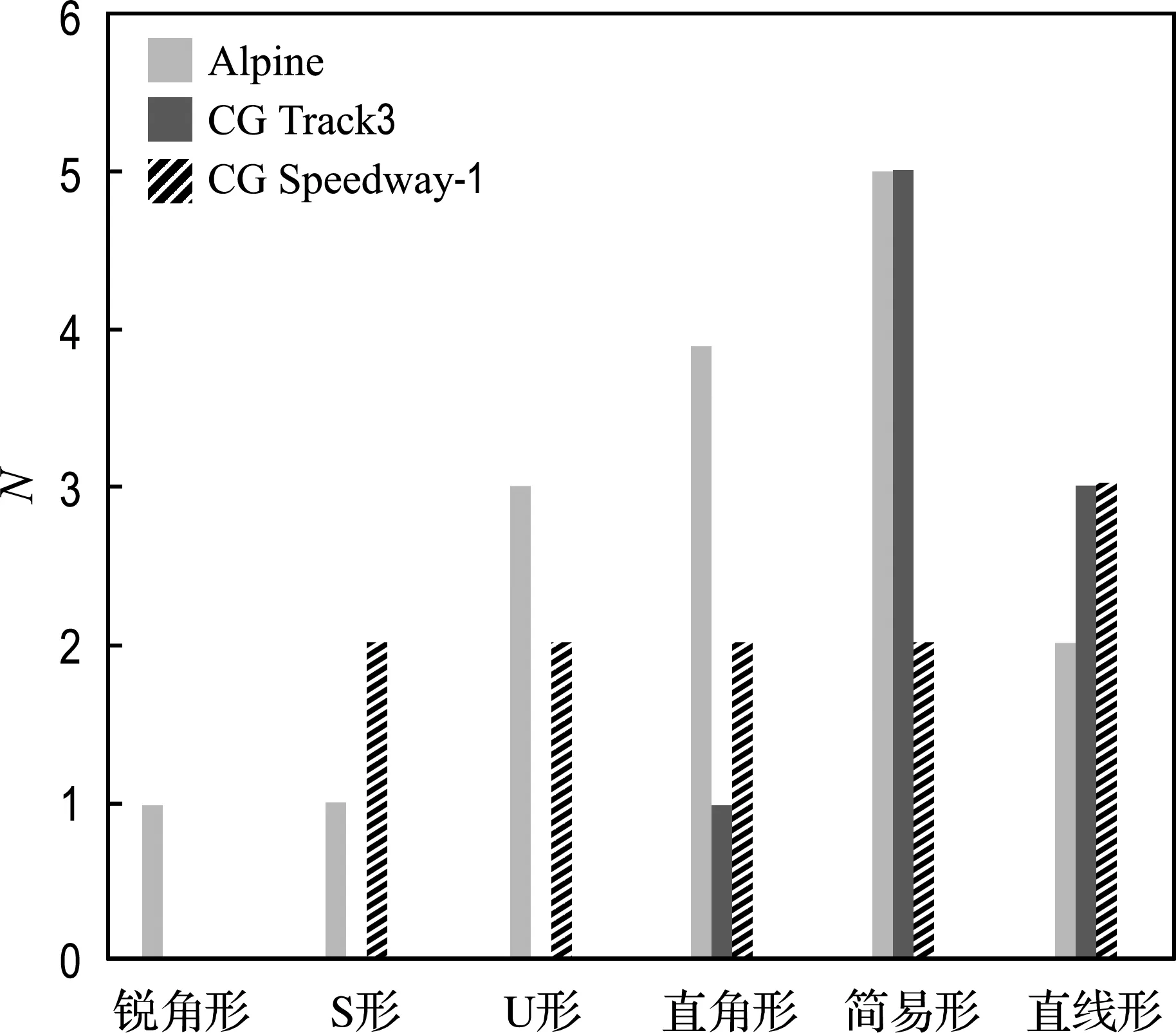
图8 训练赛道与测试赛道对比Fig.8 Comparison between training track and test track
其中,直线形赛道用于验证所提出模型的车道保持能力,简易弯道用于验证车辆过弯时的循迹稳定性,复杂弯道用于验证车辆的过弯能力和安全性能.针对不同赛道的自动驾驶系统决策难度水平顺序为Alpine>CG Speedway-1>CG Track3,发现CG Track3在前5圈均未发生碰撞,Alpine仅在第2圈发生碰撞.
由此可见,训练4 000次的WGAIL-DDPG(λ)模型在较简单的CG Track3赛道上可以很好地完成安全、平稳的驾驶任务.在较复杂的Alpine赛道,尽管存在许多模型未训练过的复杂弯道,智能体也能很好地完成安全、平稳的驾驶任务,仅在第2圈的U形弯处发生一次轻微碰撞.经过分析,主要原因在于模型的训练赛道没有和该测试赛道同等难度的U形弯,智能体在处理未知弯道时,安全距离d过小导致碰撞发生,可通过进一步增加训练赛道线形进行模型的性能提升.
2.3 学习效率
学习效率是表征深度强化学习模型训练过程有效性的重要参数之一,本文通过累计回报R与训练次数之间的关系进一步分析所提出模型的学习效率.为此,这里选择CG Track3作为训练赛道,通过在智能体周围设置多个干扰车辆增加训练难度,以获得多车环境下的自动驾驶决策系统学习效率输出结果.
为说明问题,这里分别对DDPG和本文提出的WGAIL-DDPG(λ)模型进行了测试,测试结果如图9所示.其中,为保证实验准确性,取2次实验的平均值作为最终的累计回报;为保证一致性,两种模型均采用多车情况下的奖励函数进行训练.
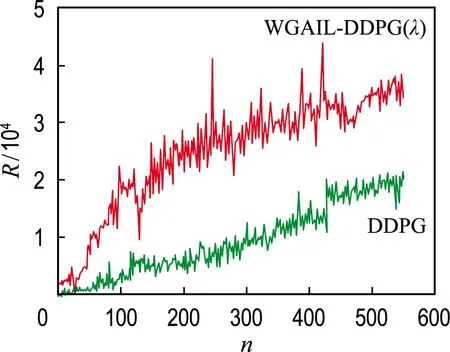
图9 模型学习效率对比分析Fig.9 Comparative analysis of model learning efficiency
图9所示两种强化学习模型的学习效率对比结果如下.
(1)Phase-1阶段,n∈[1,100]
从累计回报曲线的斜率可以看出,在模型训练初期,WGAIL-DDPG(λ)模型的学习效率明显高于DDPG模型.原因在于WGAIL-DDPG(λ)模型中的模仿学习模块在该阶段可以保证智能体快速掌握专家示教策略,这也进一步验证了模仿学习策略引入的有效性.
进一步分析表明:在n=40左右,WGAIL-DDPG(λ)模型累计回报快速达到9 000左右,这表明智能体此时已经掌握了诸如车道跟驰之类的较简单驾驶策略,而对应的DDPG模型仍处于试错阶段.
由此可见,本文通过引入模仿学习策略可以避免智能体在训练初期的盲目试错,从而大幅度提升强化学习的模型训练效率.
(2)Phase-2阶段,n∈(100,550]
在模型训练后期,WGAIL-DDPG(λ)模型获得的累计回报仍明显高于DDPG模型.究其原因在于,智能体在学会初级驾驶策略的基础上,通过增益调度器实现模仿学习向强化学习的平稳过渡,智能体可以探索更高级的驾驶策略.
进一步分析表明:在训练的第140次左右,基于WGAIL-DDPG(λ)模型的智能体累计回报基本稳定在19 000之上,通过观察智能体行为可以看出,该累计回报对应智能体的表现为有初步的躲避车辆行为,并能在车道内稳定驾驶.而基于DDPG模型的智能体在训练480次左右才能实现上述目标.前者比后者学习速度提升了约3.4倍.
由此可见,本文通过设计增益调度器可以实现模仿学习向强化学习的平稳过渡,使智能体在学会基本驾驶策略的基础上进一步探索高级策略.
3 结 论
(1)基于车辆碰撞安全性、稳定性所设计的奖励函数可以有效保证DDPG决策模型的可靠输出.
(2)模仿学习策略的引入可以大大降低强化学习模型初期探索过程中的盲目试错,相较于DDPG模型,WGAIL策略的引入可以有效提升学习效率达3.4倍以上.
(3)所设计的增益调度器保证了从模仿学习到强化学习的平稳过渡.
同时,鉴于相关实车实验开展难度,本文仅从仿真角度对提出的模型、方法进行了有效性验证.未来将基于车载实际要求,融合更多的车辆运动特性对本文所提出的相关模型方法进行进一步细化和拓展.
