基于低分辨率输入图像的年龄识别方法
2022-01-22朱喜梅
朱喜梅,李 蕊
基于低分辨率输入图像的年龄识别方法
朱喜梅1,李 蕊2,3
(1. 中原科技学院文学与传媒学院,河南 郑州 450046; 2. 南阳理工学院计算机与软件学院,河南 南阳 473000; 3. 青海师范大学计算机学院,青海 西宁 810008)
针对通常获取到的人脸图像,由于分辨率较低会丢失人脸原本的皱纹等特征信息,从而降低年龄识别的性能的问题,提出一种基于低分辨率输入图像的年龄识别方法:首先使用条件生成对抗网络(CGAN)对输入的低分辨人脸图像进行重构,再采用深度学习方法进行年龄识别。并进行了关于图像重构的对比实验,然后在不同的人脸图像数据集上进行了关于年龄识别的结果对比。通过与其他深度学习方法关于信噪比、峰值信噪比与平均绝对误差的实验对比,表明了该方法在图像重构与年龄识别2方面的有效性。此外,对该方法的时间复杂度进行了分析。
低分辨率;年龄识别;深度学习;时间复杂度
人脸图像传达了重要的生物学信息,其中包括身份、年龄、性别和表情等各种特征。基于人脸图像的年龄识别方法可应用于多个领域,包括商品的需求分析和推荐、公安干警的现勘刑侦等。人脸随着时间的推移而老化,且每个人都会经历不同的衰老过程,虽然衰老过程各异,但仍可用一般且共通的特征对其进行解释[1]。由于人脸的衰老是一个缓慢而复杂的过程,随着时间的推移,会受到每个人内在和外在因素的影响。另外,由于不同年龄的人衰老的平稳性差异较大,使得各年龄段的人脸特征空间又具有差异性。因此,基于人脸图像的年龄识别不如身份或性别等其他类型的识别准确。一般的年龄识别算法包括2个步骤:特征提取和年龄函数的学习,特征提取将人脸在衰老过程中的外观变化转化为用于年龄识别的特征[2],可分为局部特征和全局特征[3]。前者通常来源于额头、眼圈、脸颊等明显显示年龄相关特征的部位,而后者通常来源于整张人脸。年龄函数学习的目的是通过提取到的特征来进行年龄识别,通常可建模为分类模型或回归模型。在分类模型中,假设类标签是相互独立的。然而,由于年龄标签是一个有序集,具有很强的顺序关系,所以分类模型在近年来很少使用。回归模型将年龄标签视为实数值[4]。然而,每个人脸都会因个体差异而经历不同的衰老过程[5],因此会产生非平稳的随机过程。由于在回归模型中通常会涉及到学习非平稳核函数,因而很容易发生过拟合现象[6]。
近年来,能够将特征提取和年龄识别包含在一体的端到端结构的深度学习方法被引入到年龄识别当中。文献[7]提出了一种标签扩展方案,从弱监督分类标签中增加正确标签的数量,以用于年龄估计。文献[8]利用基于标签敏感的深度度量学习方法,将人脸样本投影到一个潜在的公共空间,通过深度残差网络寻找一系列的非线性变换。文献[9]结合不同类型的特征提取方法,通过特征和分值的二级融合实现对人脸年龄的精确识别。文献[10]将卷积神经网络(convolutional neural network,CNN)中的多层特征与一系列年龄相关的手工特征结合,从而进行年龄识别。文献[11]提出了一种新的深层神经网络结构,即有向无环CNN,利用CNN不同层的多阶段特征进行年龄识别。
如上文献进行的人脸图像为输入的年龄识别方法。然而,当使用低质量模组的相机采集图像,或在距离较远的地方获得人脸图像时,图像的分辨率会降低。此时人脸的皱纹和纹理会丢失,从而无法获得年龄识别的关键特征[12]。解决低分辨率输入问题最常用的方法是图像重构,将低分辨率图像重构为高分辨率图像。过去的图像重构方法通常采用双三次插值、最近邻插值、基于实例的方法或基于稀疏编码的方法。近年来,基于CNN的图像重构技术被用于场景图像的清晰化成像[13-14]。文献[13]利用超分辨率CNN,扩充了基于稀疏编码的方法。该架构由特征提取层(由低分辨率图像生成特征图),非线性映射层(将特征图由低分辨率映射为高分辨率)和分辨率重构层(从高分辨率特征地图重建高分辨率图像)。文献[14]通过引入生成对抗网络(generative adversarial network,GAN)[15]解决街景图像的分辨率问题。其使用残差网络[16]中的快捷连接,在分类和构造生成器(generator)方面均取得了良好的效果。并将经过预训练的VGG网络[17]的卷积核转换成连续的3×3卷积核以此构造鉴别器(discriminator)。此外,利用生成器和鉴别器的交叉熵作为损失函数,提出了一种基于整流线性单元(rectified linear unit,ReLU)的损失函数,以此代替会引起高频细节损失的像素级均方误差损失函数(mean square error,MSE)。但是由于GAN的模态崩溃问题(mode collapsing problem)[15],其损失函数很难收敛,即使实现了收敛,训练的效果也无法保证。
上述现有的图像重构方法主要集中于提高一般场景图像的分辨率,很少涉及到低分辨率图像的年龄识别,即使有,也只考虑了图像中出现的光学模糊或运动模糊问题[18-20],并未考虑到低分辨率下的年龄识别问题。为了更好地解决该问题,本文首先利用条件生成对抗网络(conditional generative adversarial network,CGAN)将低分辨率人脸图像重建为高分辨率人脸图像,然后将其作为CNN的输入得到人脸的年龄值。与以往的方法相比,本文方法在以下几个方面具有创新性:
(1) 使用低分辨率人脸图像进行年龄识别;
(2) 针对低分辨率输入,提出了一种不需要单独预处理的采用CGAN的图像重构方法;
(3) 将采用CGAN的图像重构与采用CNN进行年龄识别的过程分开进行,在降低了训练复杂度的同时也提高了学习速度;
(4) 本文使用的CGAN和CNN以及人脸图像数据集皆为开源可获取的,因此便于后来的研究者对其进行发展与扩充。
1 提出的方法
1.1 总体框架
本文方法总体架构如图1所示,首先检测人脸和眼睛的位置;其次利用检测到的人脸和眼睛来补偿在收集图像时可能出现的仿射变换并对人脸的感兴趣区域(region of interesting,ROI)重新定义(见1.2节);然后使用CGAN[21]对预处理得到的低分辨率人脸图像进行重构;最后利用CNN模型对重构后的人脸图像进行年龄识别。
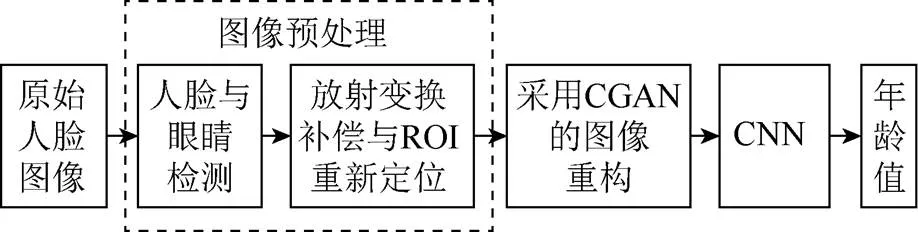
图1 本文方法流程图
1.2 图像预处理
通常,数据集中的原始人脸图像不会是完全对齐,其所在区域还可能包括不具有年龄信息的部分。该不足可能会影响年龄识别的性能,因此有必要删除该冗余背景区域,以便进行后续处理。本文进行的预处理如图2所示。
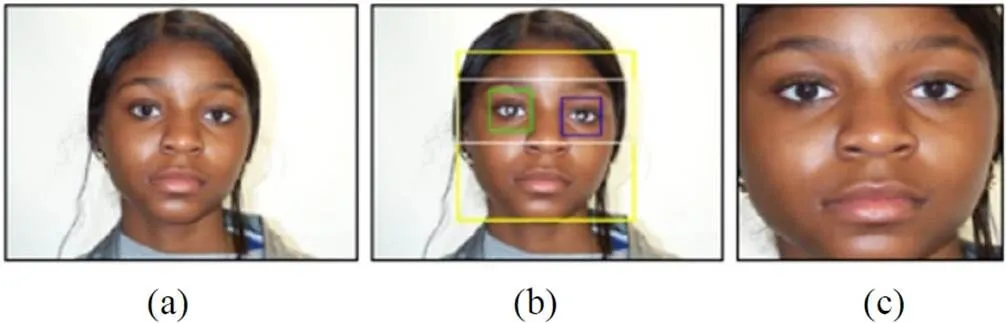
图2 本文方法的预处理图示((a)原始人脸图像;(b)人脸检测结果;(c)人脸对齐与ROI重新定义)
首先,使用Adaboost方法在输入图像中检测出人脸[22]。再进一步在该范围内检测出双眼可能的位置。在预处理步骤中,原本考虑使用文献[23]中基于空间注意力模块(spatial attention module)的方法。但该方法有3个缺点:①为了获得人脸和双眼的ROI,需要对空间注意力模块生成的类激活图进行精确的阈值分割,增加了计算复杂度。②经过类激活图得到的ROI较为粗略,而预处理步骤需要得到比较精确的ROI。③空间注意力模块需要额外的训练。基于上述考虑,本文选取了较为传统的Adaboost方法检测脸部和双眼的ROI。
图2显示了检测到的人脸和眼睛的位置。根据此信息,利用双线性插值对人脸图像的放射变换进行校正,旋转校正使用的角度为
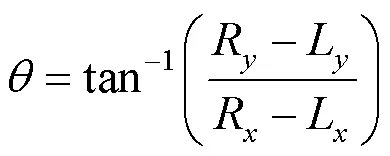
其中,R和R分别为右眼的横坐标与纵坐标;L和L分别为左眼的横坐标与纵坐标。
最后为了去除背景区域,使用双眼的位置并利用文献[18-20]的方法重新确定人脸图像的ROI,最终得到的图像如图2所示。
1.3 基于CGAN的图像重构
为了进行基于低分辨率输入图像的鲁棒人脸年龄识别,本文使用CGAN进行超分辨率重构,在生成器与鉴别器之间进行对抗学习[21]。即利用生成器的编码器提取低分辨率人脸图像的特征,而解码器将提取的特征与对应的高分辨率图像块进行匹配,从而提高分辨率。现有的GAN接收随机噪声向量和图像IN作为输入,并创建OUT作为伪图像,得到一个经过训练映射到OUT的模型[24]。此时,鉴别器进行学习以区分OUT和TAEGET,其中前者为虚假的图像而后者为真实的图像。生成器学习如何欺骗鉴别器将OUT看作真实图像。相应地,损失函数[24]为
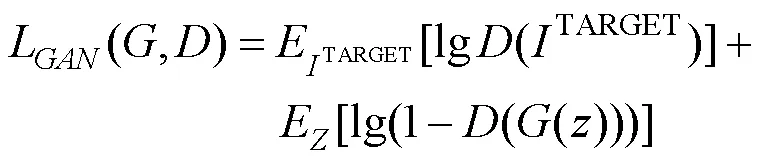
其中,为生成器;为鉴别器。由于本文是通过对抗学习而进行的图像重构,因此以低分辨率人脸图像(LOW)和高分辨率原始人脸图像(HIGH)分别作为输入,从而使网络能够学习从RECONSTRUCTION到HIGH的映射。CGAN的此过程如图3所示。
图3 CGAN的处理过程
Fig.3 The internal running program of CGAN
本文中,生成器学习将对应于低分辨率人脸图像IN(LOW)的高分辨率重构人脸图像OUT(RECONSTRUCTION)如何映射至高分辨率原始人脸图像TAEGET(HIGH)。鉴别器不是简单地区分人脸图像,而是将OUT和TAEGET与IN联系起来。根据IN得到的映射被加强。因此,损失函数为
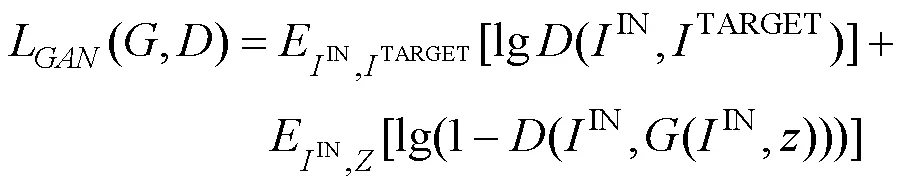
文献[25]将现有的损失函数添加到GAN的生成器中。本文中的鉴别器作用同样如此,但是文献[25]中的生成器通过计算OUT和TAEGET之间的L2距离来生成清晰的图像。然而,L2距离比L1距离更容易产生模糊的图像。为此,文献[21]将由式(4)中的L1添加到GAN的损失函数中,得到
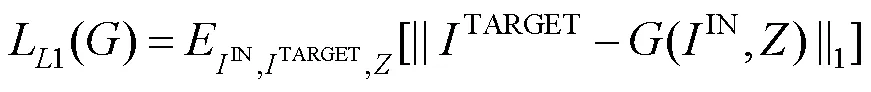
因此,使用的最终损失函数为
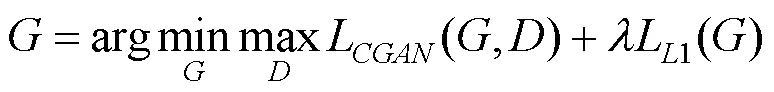
1.3.1 生成器
基于深度学习的图像重构是一个从低分辨率图像中提取特征并获得相应的高分辨率图像的映射过程。此外,图像重构应尽可能保留原有的外部细节和形状。以前多使用编解码器网络(encoder- decoder network)来创建和转换图像[25-29],本文则通过为编解码器网络添加跳跃连接(skip connection)从而构建一种U-net结构[30]。并将第个编码器层的特征与第个解码器层的特征进行串联,以尽可能保留外部细节和形状。因为在图像重构中采用了原始的CGAN[21],所以在生成器中也使用了U型网络,其中跳跃连接是网络的重要组成部分,如图4所示。
图4中的生成器是由8个编码器和8个解码器单元组成的编解码器结构。每个编码器单元包括卷积(convolution),批量归一化(batch normalization)和Leaky ReLU (其中第一个卷积层中不包括批量归一化)。每个解码器单元包括反卷积,并利用Dropout进行批量归一化来获得随机噪声向量。与编码器不同,解码器使用ReLU而不是Leaky ReLU。最后,从解码器获得的特征输入至tanh函数中。
1.3.2 鉴别器
训练鉴别器以区分真图和伪图。图像IN输入后,通过卷积提取特征,并生成图像OUT或输入图像IN和目标图像TAEGET。为了区分真伪图像,从最后一层提取的大小为30×30×1特征图未针对L1和L2损失函数进行核对,而是对每个网格(grid)分别进行判断,以此检查每个图像的细节和形状(本文感受野为70×70),此外也可以最小化由L1和L2损失引起的图像模糊问题。本文利用马尔可夫随机场将真实图像与伪图像进行区分,即patchGAN。patchGAN的patch在整张图像中移动并判断该局部区域是真是伪。因为每个patch都是独立的,因此鉴别器有效地将图像建模为马尔可夫随机场[21]。鉴别器的输出是一个概率矩阵,其中每个元素都提供了使用马尔可夫随机场或patchGAN采样的一对对应patches是真的概率。鉴别器的架构如图5所示。
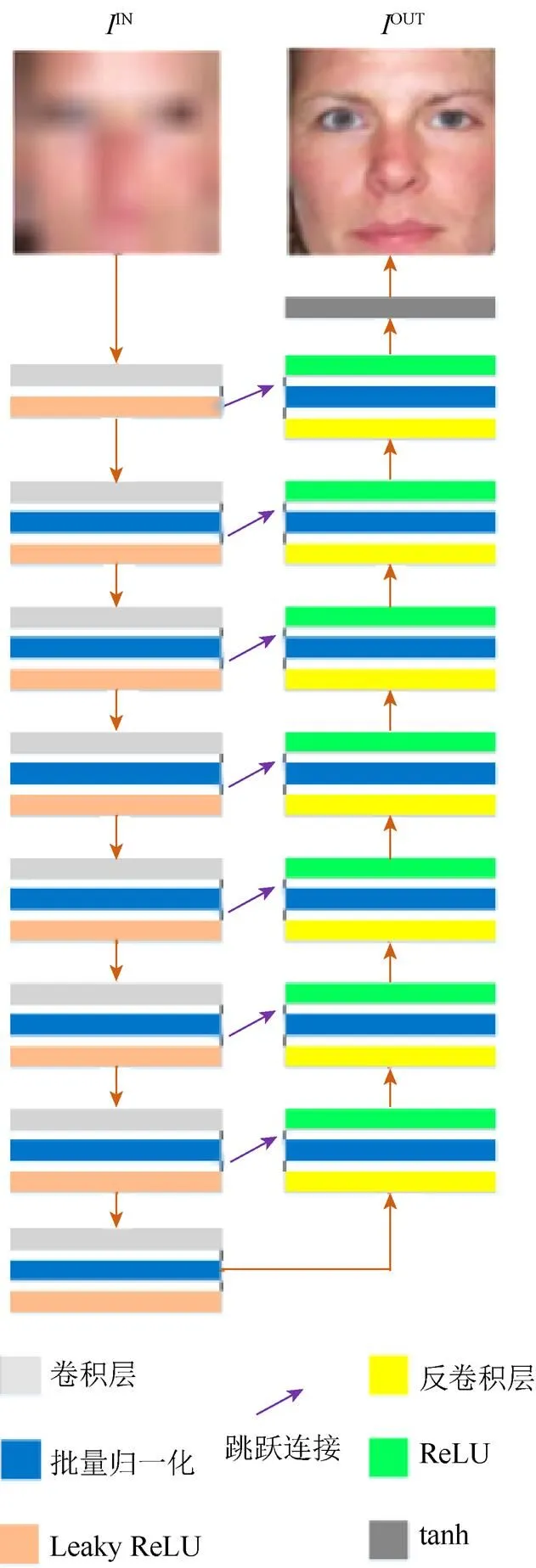
图4 生成器的架构
生成器使用创建的图像OUT来学习欺骗鉴别器。随着训练时间的增加,生成器学习的不是创建与真实图像相似的图像,而只是简单地欺骗鉴别器。因此,鉴别器也会被错误地训练。本文使得鉴别器学习目标图像,从而保持真实图像的特征。此外,OUT和TAEGET并不是简单的输入,而是与IN串联(concatenation),以此可以训练鉴别器更好地表达IN的细节和形状。
1.4 年龄识别
本文使用重构后的人脸图像训练CNN以进行年龄估计。基于残差网络[16],DEX[31],带有随机森林的INCEPTION-V2[32]以及AGE-NET[33]4个深度网络进行年龄判别。
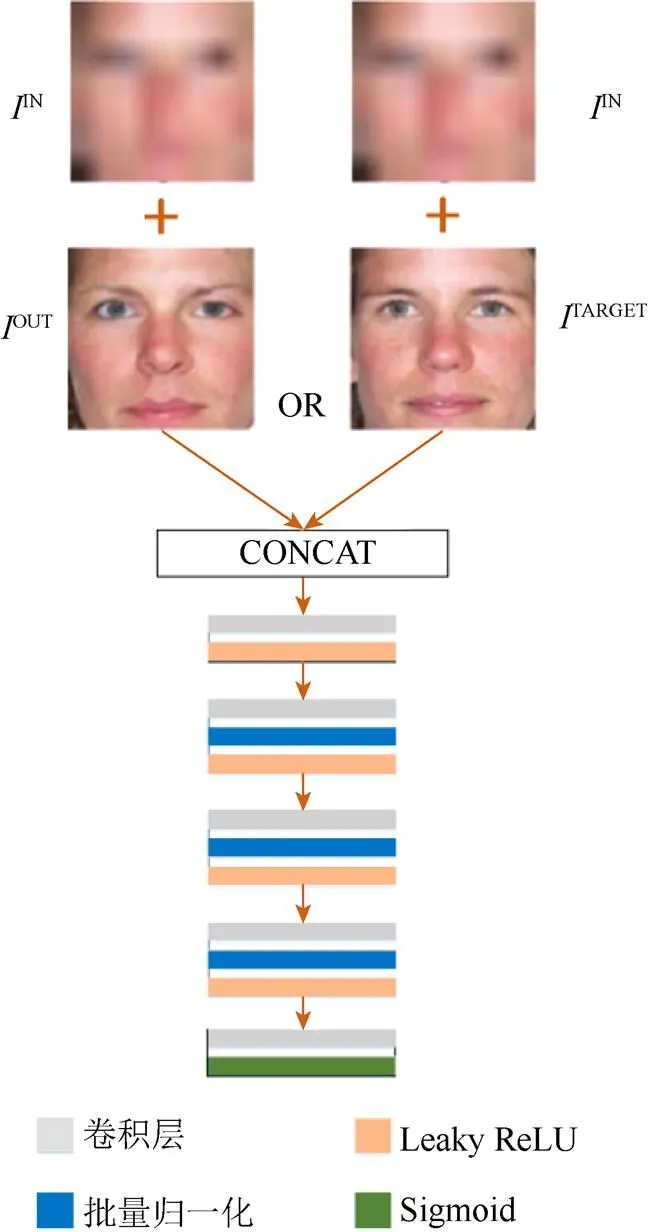
图5 鉴别器的架构
1.4.1 残差网络
ResNet是一个已经被证实在分类任务中表现优异的CNN[16]。其由3×3和1×1大小的连续滤波器组成的瓶颈结构(bottleneck block)和一个可以将前一层的特征图与残差块后的特征图连接起来的跳跃连接(skip connection)结构组成,由此降低特征图的维数和复杂性。此外,由于采用了批量归一化,因此小批量数据的特征图可以根据其均值与标准差进行标准化处理,学习速率也得到了提高。ResNet的深度主要取决于残差块的数量。本文使用了ResNet-50和ResNet-152网络。在网络最后一个全连接层后,应用softmax函数进行分类,从而得到所有类别的概率。
1.4.2 DEX
DEX[31]是一个在Chalearn年龄识别竞赛中排名第一的网络。DEX的体系结构与VGG-16[17]相同,其是通过ImageNet,IMDB[34]和WIKI[35]数据集预训练的模型构建的。对于年龄识别而言,其未使用CNN中标准softmax函数来得到类别概率,而是在softmax函数之后输出每个类标签和概率的乘积和作为年龄,即
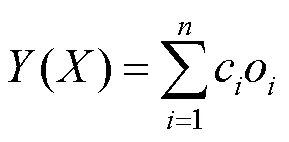
其中,c和o分别为第个类的标签和概率值;为输入图像识别到的年龄值。所有的卷积层和全连接层均采用RELU作为激活函数。此外,在第1次和第2次最大池化后,还进行了局部响应归一化(local response normalization)。在全连接层中使用dropout减小过拟合。使用均值为0,标准差为0.01的高斯分布对权重进行随机值初始化。
1.4.3 带有随机森林的INCEPTION-V2
文献[32]使用了Inception-v2[36]来估计年龄。该方法在Chalearn年龄识别竞赛中表现良好(排名第四)。Inception-v2与先前的Inception-v1有相同的架构,即使用不同大小的滤波器构建了一个宽层次(wide)而不是深层次(deep)的网络。Inception-v2是通过将批处理归一化添加到Inception-v1的Inception块中创建的。在文献[32]中,首先对Inception-v2进行了训练,然后提取来自随机森林的特征对Inception-2进行训练,最后进行人脸图像的年龄识别。
1.4.4 AGE-NET
文献[33]采用VGG[17]和AGE-NET进行年龄识别。该方法在Chaleran年龄识别竞赛中同样取得了良好的成绩(排名第五)。其学习过程包括2个步骤:①首先将由ImageNet数据集预训练后的VGG通过MORPH数据集进行微调。然后,将不同的开源数据集混合并分为2组,分别采用KL散度损失和softmax损失函数进行参数的学习。该方法创建了4个微调模型,并在每个模型的最后一层使用基于距离的投票式集成方法来创建一个串联的特征映射。②使用不同的开源数据集和KL散度损失函数对AGE-NET进行训练。VGG和AGE-NET具有相同的输出维度。如果2个网络之间的年龄识别差异<11岁时,则其平均值被确定为预测年龄;当差值≥11岁时,采用第一个网络(VGG)的结果作为预测年龄。
2 实验结果及分析
2.1 实验设置
本文使用PAL[37]和MORPH数据集[38]进行实验。
PAL数据集是一个包含18~93岁的人脸图像数据集,其中白种人和非裔美国人分别占76%和16%,剩下的8%有亚洲、南亚和西班牙裔背景,本文从中截取了580张较为中性的人脸图像进行实验(图6)。这580张图像按1.2节所述进行预处理,并重新定义人脸ROI。对图像进行了8个方向(由左至右,由上至下)的预处理,其中平移操作分3步进行,如图7所示。通过对高分辨率的人脸图像进行水平方向的镜像,总共获得了580(8×3+1)× 2=29000张数据增强的图像。由于本方法需要生成高分辨率和低分辨率的人脸图像,因此通过双线性插值将256×256大小的高分辨率图像转换为8×8大小的低分辨率图像,从而降低了增强后数据的分辨率,结果共获得高分辨率和低分辨率人脸图像共计29 000对。

图6 PAL示例图像
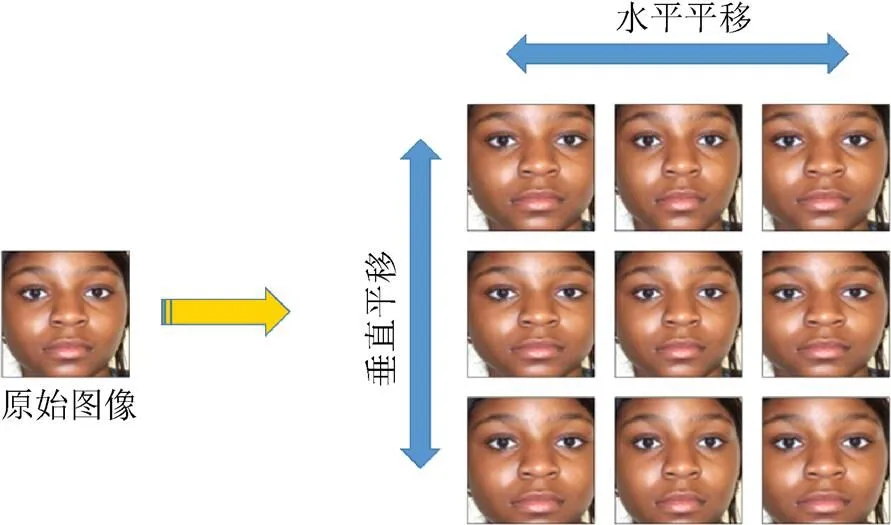
图7 图像平移
MORPH数据集包含了13 617个人的55 134张人脸图像,年龄从16~77岁。从该数据集中,随机选择了1 000张不同个人、不同年龄和不同性别的图像进行实验,如图8所示。数据扩充的方式与图7中相同。在PAL数据集应用了四折交叉验证,而对MORPH数据集应用了二折交叉验证。表1给出了实验中使用的PAL和MORPH数据集在每个交叉验证中的原始图像和数据扩充后图像的数量。扩充后的图像仅用于训练CGAN和年龄识别的CNN。未进行扩充的原始图像用于测试环节。

图8 MORPH示例图像
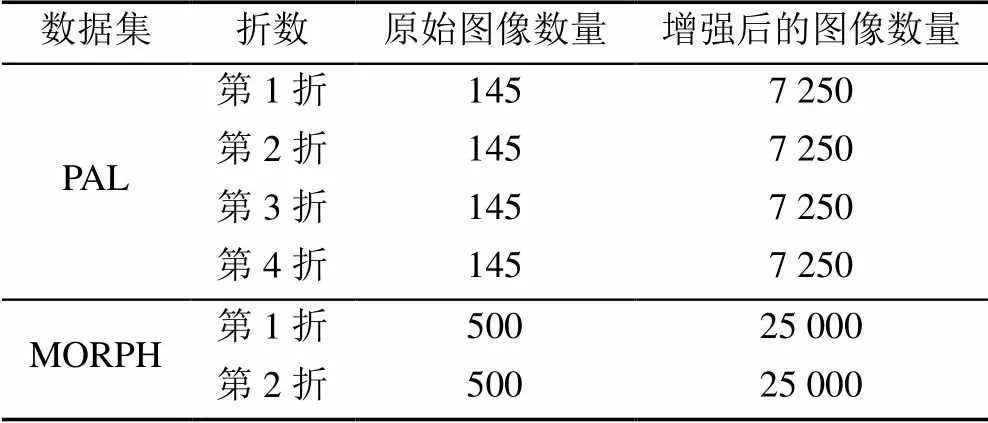
表1 数据集协议下的数量情况
在实验中,使用了一台配备了3.50 GHz CPU (Intel ®CoreTMi7-3770K)和24 GB RAM的台式计算机。在网络的训练和测试过程中使用了Ubuntu Caffe。显卡是Nvidia GeForce GTX 1070,其有1 920个CUDA内核和8 GB RAM。使用了OpenCV库,提取人脸ROI。
低分辨率人脸图像和高分辨率人脸图像分别作为IN和TAEGET来训练CGAN,如图9所示。

图9 用于训练的高分辨-低分辨图像对
经过数据增强后的图像被调整到286×286大小,然后被随机裁剪成256×256,再进行训练。Adam优化器[39]被用于网络参数的更新。学习率为0.000 2,1和2分别设置为0.500和0.999。学习过程包括40个epochs。图10 (鉴别器)和11 (生成器)显示了在使用PAL数据集时,根据epoch变化时CGAN的训练损失。由图中可以看出,经过一段时间,损失值趋于收敛。
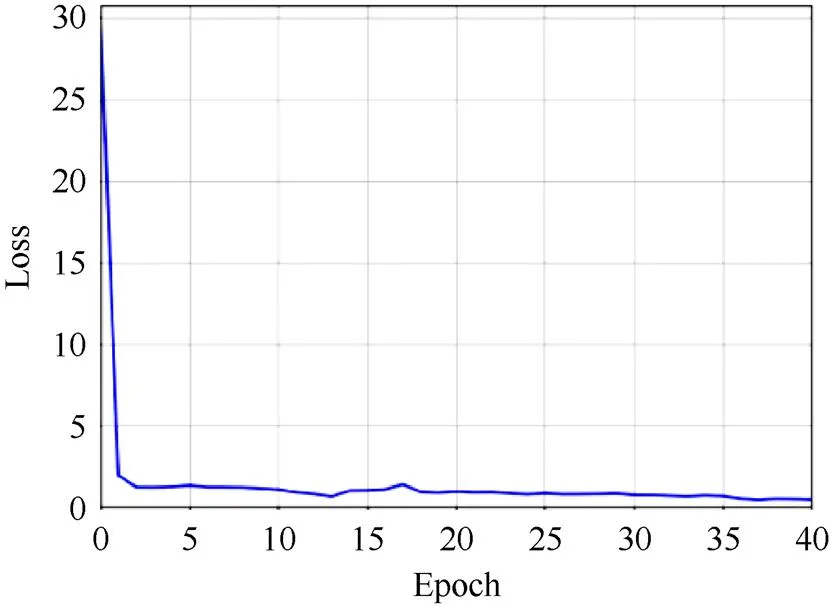
图10 鉴别器的损失值变化情况
本文首先使用CGAN重构人脸图像,然后训练CNN进行年龄识别。各种CNN网络都通过扩充后的数据进行了微调,且这些网络均训练了100个epochs。其中DEX在利用CGAN重构的图像进行训练和测试的CNN中达到了最好的年龄识别性能。图12显示了经过PAL数据集训练的DEX年龄识别的损失和准确率,可以看出DEX通过重构后的图像得到了充分的训练。
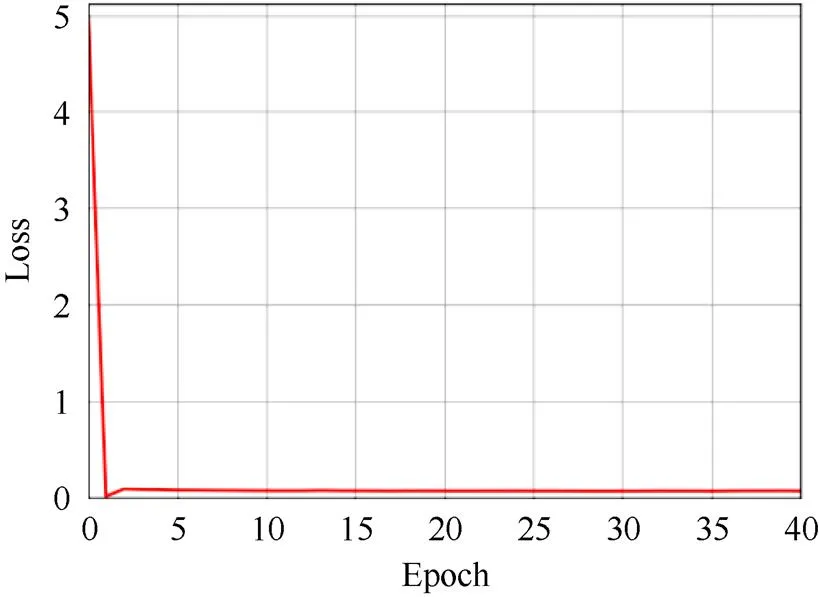
图11 生成器的损失值变化情况
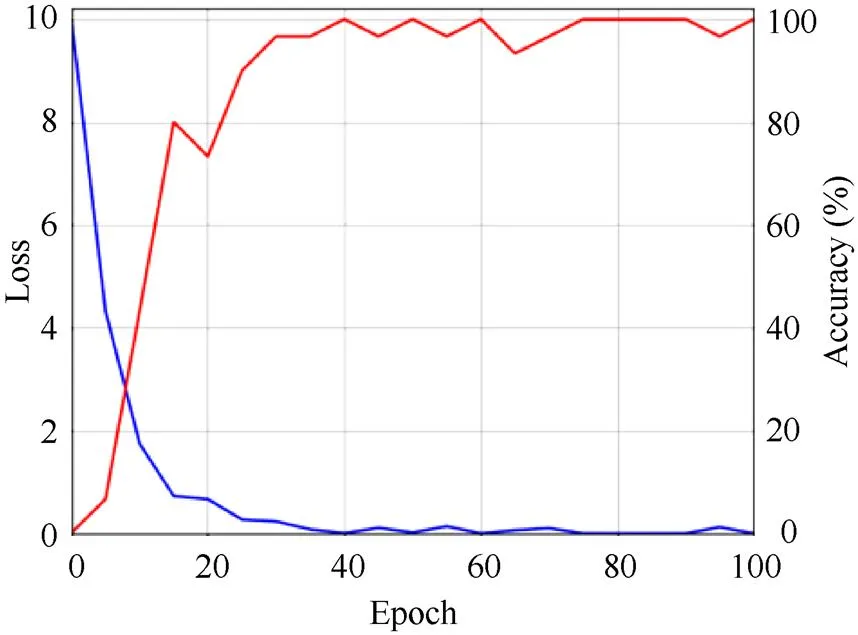
图12 DEX的损失与准确率变化情况
2.2 人脸图像重构实验结果与分析
本文首先对提出的图像重构方法进行了实验(表2),并比较了本文方法CGAN,VDSR[40],DCSCN[41],SRGAN[42]4种方法在峰值信噪比(peaksignaltonoiseratio,PSNR)和信噪比(signaltonoiseratio,SNR)方面的重构结果。
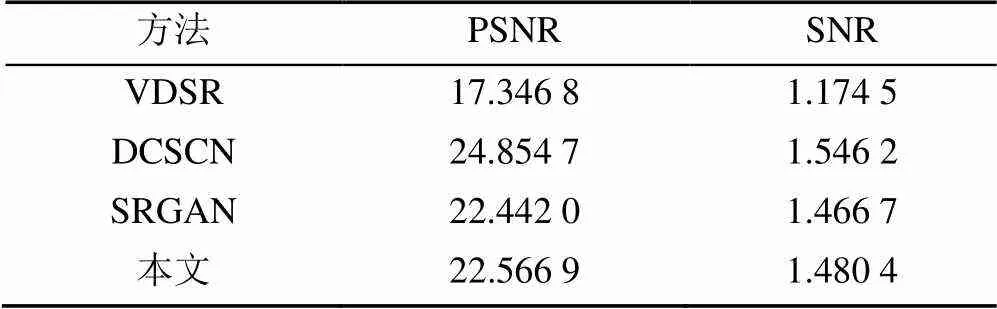
表2 不同方法的图像重构结果
由表2可知,本文方法的PSNR和SNR均高于VDSR和SRGAN,但低于DCSCN。然而,当基于DEX比较年龄识别精度时,本文方法比其他3种方法皆显示出更高的精确性(表3)。

表3 重构后的年龄识别MAE结果对比
表3中DCSCN方法重建的图像数值高于本文方法,如图13所示,DCSCN方法重建的图像比本文方法模糊。

图13 不同方法的图像重构效果对比((a)原始低分辨率图像;(b)VDSR方法;(c)DCSCN方法;(d) SRGAN方法;(e)本文方法;(f)原始高分辨率图像)
由于DCSCN方法生成的图像较为模糊,说明其噪声较少(图13(c)),其PSNR和SNR结果皆优于本文方法。然而,生成的模糊图像中,其人脸特征不明显,这使得年龄识别的精度低于本文方法。
此外,图13中PAL数据集的一些图像重构结果表明,与VDSR和DCSCN方法相比,本文方法能产生更接近原始的高分辨率图像。
2.3 年龄识别实验结果与分析
年龄识别中的准确性评价指标为平均绝对误差(mean absolute error,MAE),即
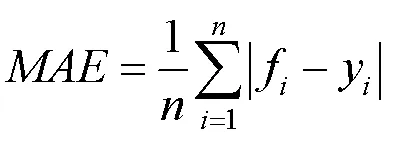
其中,为输入图像的数量;f为识别到的年龄;y为真实年龄。表4和5分别比较了PAL和MORPH数据集中使用原始图像、低分辨率图像和重构图像的不同年龄识别方法的性能。其中每种方法原本由特定的数据集进行预训练,然后通过本文使用的PAL和MORPH数据集进行微调。注意到基于MORPH数据集训练ResNet时,未采用Adaboost方法进行人脸和双眼检测,而是使用Dlib人脸特征跟踪器[43]进行人脸检测,最终采用与DEX相同的方式得到年龄识别值。
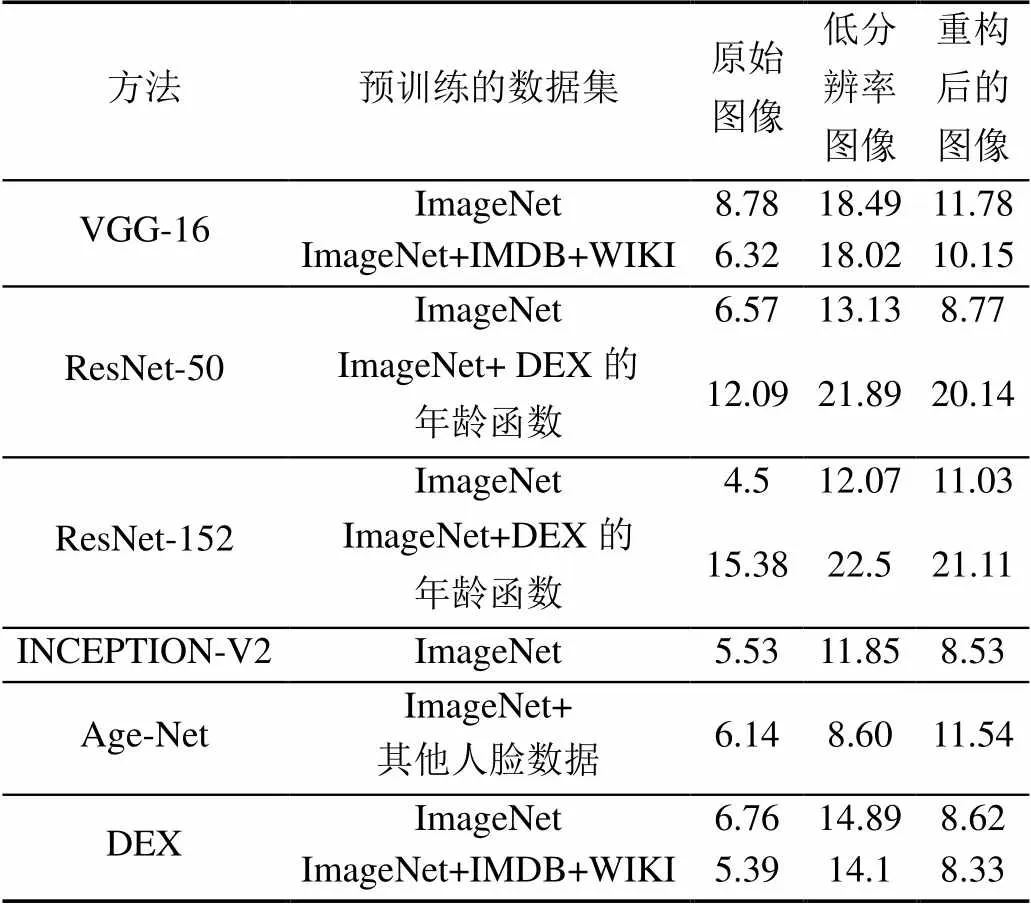
表4 在PAL中基于不同CNN的年龄识别MAE结果对比
表4和5中,使用低分辨率图像时所有年龄识别方法的精度都低于使用原始高分辨率数据时的精度。当采用本文的图像重构方法再进行年龄识别时,精度高于低分辨率图像(低于高分辨率原始图像)。此外,将本文图像重构方法和DEX结合时,获得了最好的年龄识别精度。
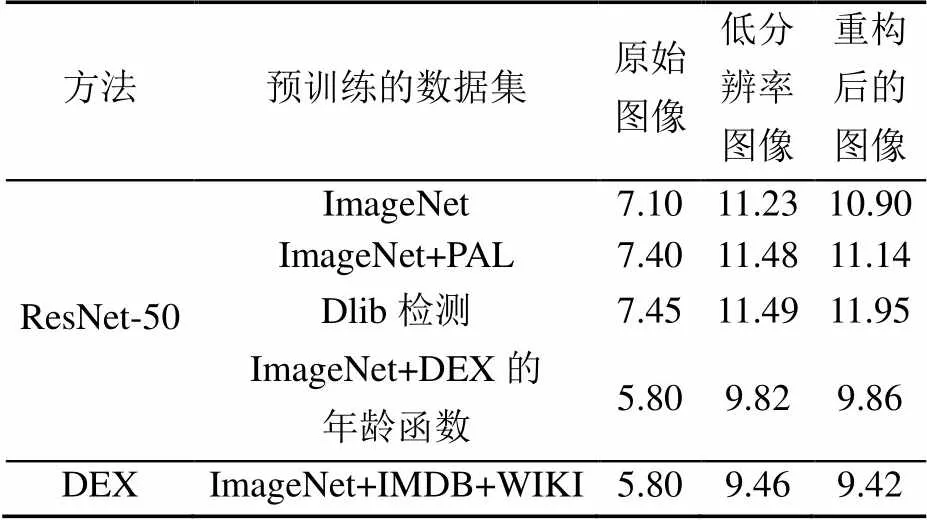
表5 在MORPH中基于不同CNN的年龄识别MAE结果对比
图14显示了正确的年龄识别情况。表中的低分辨率结果是通过DEX中的方法得出的(下面的表格为其对应MAE值)。可以看出,在每种情况下,本文方法皆比低分辨率图像识别到的年龄更接近实际年龄。图14中,本文方法即使在低分辨率的老年人人脸图像上也能正确地恢复纹理和皱纹,与低分辨率图像相比,本文方法得到的人脸图像的年龄值更接近真实年龄。

图14 正确的年龄识别结果((a)真实图像;(b)低分辨率图像;(c)重构图像)
图15显示了错误的年龄识别情况。可以看到,在有些情况下重构后的人脸图像中错误生成的斑痕或皱纹会导致年龄识别的较大误差。

图15 错误的年龄识别结果((a)真实图像;(b)低分辨率图像;(c)重构图像)
此外,还进行了这样的实验:首先对通过重构后的图像在水平和垂直方向上进行2倍的下采样,然后使用高斯滤波器进行随机模糊,最后使用双三次插值在水平和垂直方向上进行两倍的上采样,得到的年龄识别结果见表6。
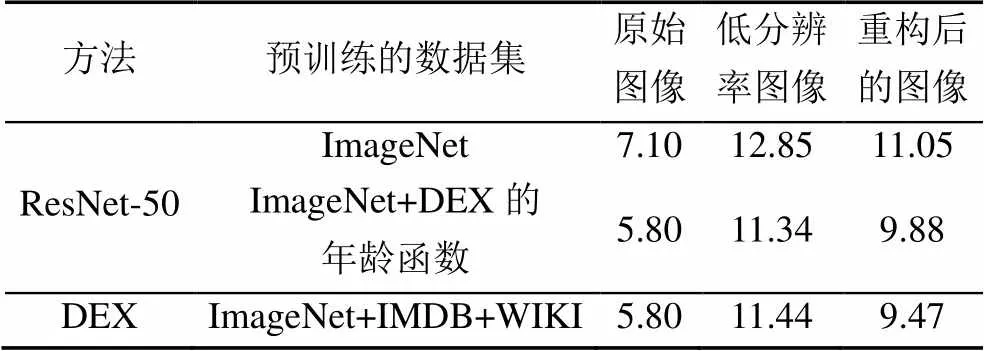
表6 在MORPH中对数据进行扰动后基于不同CNN的年龄识别MAE结果对比
由表6可以看到,此实验得到的年龄识别精度与表5中的结果相当,表明本文方法对这种退化并不敏感。
其实在上述中隐含着消融实验,即比较了使用与不使用CGAN的年龄识别方法的准确性。表5和6中,明显先进行图像重构的年龄识别准确性更好。
2.4 运行时间
本节中对所提出方法的处理时间进行了评估,其中关于实验中使用的台式计算机配置在2.1节中已经进行了描述,结果表明本文在图像重构时所花费的时间为11.2 ms,进行年龄估计时花费的时间为24.8 ms,因此每帧的平均处理时间约为36 ms,即本文方法的处理速度约为27.8帧/秒。
3 结束语
基于人脸图像的年龄识别在诸如商品推荐,现场刑侦等许多领域皆有应用。然而,若使用低分辨率的相机捕获图像或距受试者的距离较远,则人脸图像的分辨率会降低。在这种情况下,人脸中的皱纹或其他纹理等信息将会缺失,导致年龄方面重要的特征无法获得,严重影响年龄识别的精度。现有的年龄识别方法很少涉及低分辨率图像而通常只使用在受限环境下捕获的高分辨率的人脸图像。为了克服这一局限性,本文提出了一种基于CGAN的人脸图像重构下的年龄识别方法。首先利用CGAN将低分辨率的人脸图像重构为高分辨率图像,然后将得到的图像作为输入进行年龄识别。在2个开源数据集PAL和MORPH上的结果表明,本文方法在图像重构和年龄识别方面皆具有优越性,其中图像重构结合年龄识别方法取得的准确率高于仅使用低分辨率图像进行的年龄识别。未来的研究方向将是图像重构与视频下的年龄识别方法相结合。此外,还需要确定所提出的方法对低照度环境下获取的人脸图像是否仍然有效。
[1] ALBERT A M, RICANEK K, PATTERSON E. A review of the literature on the aging adult skull and face: implications for forensic science research and applications[J]. Forensic Science International, 2007, 172(1): 1-9.
[2] KANNALA J, RAHTU E. BSIF: binarized statistical image features[C]//The 21st International Conference on Pattern Recognition (ICPR 2012). New Yow: IEEE Press, 2012: 1363-1366.
[3] SUO J, CHEN X, SHAN S, et al. A concatenational graph evolution aging model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2083-2096.
[4] NIU Z X, ZHOU M, WANG L, et al. Ordinal regression with multiple output CNN for age estimation[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 4920-4928.
[5] RAMANATHAN N, CHELLAPPA R, BISWAS R. Computational methods for modeling facial aging: a survey[J]. Journal of Visual Languages & Computing, 2009, 20(3): 131-144.
[6] HUERTA I, FERNÁNDEZ C, PRATI A. Facial age estimation through the fusion of texture and local appearance descriptors[C]//European Conference on Computer Vision - ECCV 2014 Workshops.Heidelberg: Springer, 2015: 667-681.
[7] YOO B, KWAK Y, KIM Y, et al. Deep facial age estimation using conditional multitask learning with weak label expansion[J]. IEEE Signal Processing Letters, 2018, 25(6): 808-812.
[8] LIU H, LU J W, FENG J J, et al. Label-sensitive deep metric learning for facial age estimation[J]. IEEE Transactions on Information Forensics and Security, 2018, 13(2): 292-305.
[9] TAHERI S, TOYGAR Ö. Integrating feature extractors for the estimation of human facial age[J]. Applied Artificial Intelligence, 2019, 33(5): 379-398.
[10] TAHERI S, TOYGAR Ö. Multi-stage age estimation using two level fusions of handcrafted and learned features on facial images[J]. IET Biometrics, 2019, 8(2): 124-133.
[11] TAHERI S, TOYGAR Ö. On the use of DAG-CNN architecture for age estimation with multi-stage features fusion[J]. Neurocomputing, 2019, 329: 300-310.
[12] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision – ECCV 2014. Heidelberg: Springer, 2014: 818-833.
[13] DONG C, LOY C C, HE K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307.
[14] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 105-114.
[15] MIRZA M, OSINDERO S. Conditional generative adversarial nets[EB/OL]. [2021-01-09]. https://arxiv.org/abs/1411.1784.
[16] LI X L, DING L K, WANG L, et al. FPGA accelerates deep residual learning for image recognition[C]//2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). New York: IEEE Press, 2017: 837-840.[LinkOut]
[17] ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in Deep Scene CNNs[EB/OL]. [2021-01-27]. http:// dspace.mit.edu/handle/1721.1/96942.
[18] NGUYEN D T, CHO S R, PHAM T D, et al. Human age estimation method robust to camera sensor and/or face movement[J]. Sensors: Basel, 2015, 15(9): 21898-21930.
[19] NGUYEN D, CHO S, PARK K. Age estimation-based soft biometrics considering optical blurring based on symmetrical sub-blocks for MLBP[J]. Symmetry, 2015, 7(4): 1882-1913.
[20] KANG J, KIM C, LEE Y, et al. Age estimation robust to optical and motion blurring by deep residual CNN[J]. Symmetry, 2018, 10(4): 108.
[21] DONG H, NEEKHARA P, WU C, et al. Unsupervised image-to-image translation with generative adversarial networks[EB/OL]. [2021-01-10]. https://arxiv.org/abs/1701.02676.
[22] VIOLA P, JONES M J. Robust real-time face detection[J]. International Journal of Computer Vision, 2004, 57(2): 137-154.
[23] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//European Conference on Computer Vision – ECCV 2018. Heidelberg: Springer, 2018: 3-19.
[24] GOODFELLOW I J,POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//The 27th International Conference on Neural Infornation Processing Systems. New York: ACM Press, 2014:1-9.
[25] PATHAK D, KRÄHENBÜHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting[J]. 2016 IEEE Conference on Computer Vision and Pattern Recognition: CVPR, 2016: 2536-2544.
[26] WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
[27] SHAHIDI F. Breast cancer histopathology image super-resolution using wide-attention GAN with improved Wasserstein gradient penalty and perceptual loss[J]. IEEE Access, 2021, 9: 32795-32809.
[28] DUTTA J K, BANERJEE B. Learning features and their transformations from natural videos[C]//2014 IEEE Symposium on Computational Intelligence in Dynamic and Uncertain Environments (CIDUE). New York: IEEE Press, 2014: 55-61.
[29] YOO D, KIM N, PARK S, et al. Pixel-level domain transfer[M]//European Conference on Computer Vision – ECCV 2016. Heidelberg: Springer, 2016: 517-532.
[30] CHO C, LEE Y H, PARK J, et al. A self-spatial adaptive weighting based U-net for image segmentation[J]. Electronics, 2021, 10(3): 348.
[31] ROTHE R, TIMOFTE R, VAN GOOL L. DEX: deep EXpectation of apparent age from a single image[C]//2015 IEEE International Conference on Computer Vision Workshop (ICCVW). New York: IEEE Press, 2015: 252-257.
[32] ZHU Y, LI Y, MU G W, et al. A study on apparent age estimation[C]//2015 IEEE International Conference on Computer Vision Workshop (ICCVW). New York: IEEE Press, 2015: 267-273.
[33] HUO Z W, YANG X, XING C, et al. Deep age distribution learning for apparent age estimation[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New York: IEEE Press, 2016: 722-729.[LinkOut]
[34] IMDb.com, Inc. IMDb database[EB/OL]. [2021-01-21]. https://www.imdb.com/interfaces.
[35] Wili.com. WIKI database[EB/OL]. [2021-02-03]. https://www.wikidata.org/wiki/Wikidata:Database_download.
[36] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 1-9.
[37] MINEAR M, PARK D C. A lifespan database of adult facial stimuli[J]. Behavior Research Methods, Instruments, & Computers, 2004, 36(4): 630-633.
[38] TouchNet Company. MORPH database[EB/OL]. [2021-02-11]. https://ebill.uncw.edu/C20231_ustores/web/store_main.jsp?STOREID=4.
[39] KINGMA D, BA J. Adam: amethod for stochastic optimization[EB/OL]. [2021-01-28].https://arxiv.org/abs/1412. 6980v8.
[40] HU S Y, WANG G D, WANG Y J, et al. Accurate image super-resolution using dense connections and dimension reduction network[J]. Multimedia Tools and Applications, 2020, 79(1):1427-1443.
[41] YAMANAKA J, KUWASHIMA S, KURITA T. Fast and accurate image super resolution by deep CNN with skip connection and network in network[C]//The 24th International Conference on Neural Information Processing. Heidelberg: Springer, 2017: 217-225.
[42] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 105-114.
[43] KAZEMI V, SULLIVAN J. One millisecond face alignment with an ensemble of regression trees[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 1867-1874.
Age recognition method based on low resolution input image
ZHU Xi-mei1, LI Rui2,3
(1. School of Literature and Media, Zhongyuan Institute of Science and Technology, Zhengzhou Henan 450046 China; 2. School of Computer and Software, Nanyang Institute of Technology, Nanyang Henan 473000 China; 3. School of Computer Science, Qinghai Normal University, Xining Qinghai 810008, China)
If the accessed facial image is of low resolution, facial wrinkles and other characteristics of the information would often be lost, undermining the performance of age identification. In view of the existing age identification method lacking this research field and in order to solve this problem, this paper proposed an age identification method for low-resolution images by reconstructing the input low-resolution face images using conditional generative adversarial net (CGAN), and then identifying the age using the deep learning method. Firstly, a comparative experiment on image reconstruction was carried out, and then the results of age recognition were compared on different face image data sets. The experimental comparison with other deep learning methods on signal noise ratio, peak signal noise ratio, and mean absolute error shows the effectiveness of the proposed method in image reconstruction and age recognition. In addition, the time complexity of the proposed method was also analyzed.
low resolution; age recognition; deep learning; time complexity
TP 391
10.11996/JG.j.2095-302X.2021060931
A
2095-302X(2021)06-0931-10
2021-02-26;
2021-04-08
河南省教育厅人文社会科学研究项目(2019-ZDJH-189)
朱喜梅(1985-),女,河南鹿邑人,讲师,硕士。主要研究方向为信息化教育与教学。E-mail:zhuxm904@126.com
26 February,2021;
8 April,2021
Humanities and Social Science Research Project of Education Department of Henan Province (2019-ZDJH-189)
ZHU Xi-mei (1985-), female, lecturer, master, Her main research interests cover information education and teaching. E-mail:zhuxm904@126.com
