属性语义与图谱语义融合增强的零次学习图像识别
2022-01-22汪玉金余蓓蓓向鸿鑫
汪玉金,谢 诚,余蓓蓓,向鸿鑫,柳 青
属性语义与图谱语义融合增强的零次学习图像识别
汪玉金,谢 诚,余蓓蓓,向鸿鑫,柳 青
(云南大学软件学院,云南 昆明 650500)
零次学习(ZSL)是迁移学习在图像识别领域一个重要的分支。其主要的学习方法是在不使用未见类的情况下,通过训练可见类语义属性和视觉属性映射关系来对未见类样本进行识别,是当前图像识别领域的热点。现有的ZSL模型存在语义属性和视觉属性的信息不对称,语义信息不能很好地描述视觉信息,从而出现了领域漂移问题。未见类语义属性到视觉属性合成过程中部分视觉特征信息未被合成,影响了识别准确率。为了解决未见类语义特征缺失和未见类视觉特征匹配合成问题,本文设计了属性语义与图谱语义融合增强的ZSL模型实现ZSL效果的提升。该模型学习过程中使用知识图谱关联视觉特征,同时考虑样本之间的属性联系,对可见类样本和未见类样本语义信息进行了增强,采用对抗式的学习过程加强视觉特征的合成。该方法在4个典型的数据集上实验表现出了较好的实验效果,模型也可以合成较为细致的视觉特征,优于目前已有的ZSL方法。
零次学习;知识图谱;生成对抗网络;图卷积神经网络;图像识别
零次学习(zero-shot learning,ZSL)是迁移学习在图像识别领域中的一个重要分支。ZSL可在完全没有视觉训练样本的情况下,对从未训练过的视觉目标类别进行一定程度的识别。这种学习模型能够显著提升传统视觉计算模型的适应性和泛用性,在视觉计算领域有着极其重要的研究意义。其相关研究也在快速增长,成为了当前的一个重要研究热点。
ZSL的本质是跨模态学习,具体来说是语义(属性)-视觉”的跨模态学习。即视觉特征是可以被语义特征所描述的,只要准确地找到视觉特征与语义特征的跨模态对应关系,便可以在不进行相应视觉样本训练的条件下,预测未见视觉目标的所属分类。一个经典事例是:一个从未见过斑马的人,通过对斑马的语义表述(如像一匹马,身体白色,但有黑色斑纹),便能够在脑海中想象出斑马样貌,从而识别出斑马。基于该思路,ZSL不断迭代发展,已经衍生出一系列经典方法。
2009年,ZSL首次由PALATUCCI等[1]明确提出。同年,LAMPERT等[2]正式发表了第1个ZSL模型-直接属性预测(direct attribute prediction,DAP),其原理是对视觉样本进行属性标记(如是否有尾巴、毛发颜色等),进而学习视觉目标的语义属性特征,最后由一个判断器评判视觉目标所满足的属性组合分类。随着语义嵌入技术的发展,ZSL的第2个阶段性标志是2013年由AKATA等[3]提出的属性标签嵌入(attribute label embedding,ALE)模型,其将属性的语义编码作为向量,并将图像编码作为特征向量,而后学习一个函数,计算属性语义编码和图像视觉编码之间的相似度,从而预测图像的分类。
随着深度学习技术在图像识别领域的发展,ZSL的第3个阶段性标志是2017年由KODIROV等[4]提出的激活酶(SUMO-activating enzyme,SAE)模型,采用自动编码技术,其能够对图像更细粒度的属性特征进行编码,并与语义属性特征进行解码映射,较好地做到了“视觉-语义”的跨模态学习,整体性能较ALE有明显提升。凭借着对抗生成网络[5]在视觉计算中的显著效果,ZSL迎来了第4个阶段性标志。2018年ZHU等[6]发表了对抗生成的零次学习(generative adversarial approach for zero-shot learning,GAZSL)模型,其采用对抗生成网络,将语义特征合成为视觉特征,进而能够通过语义信息合成伪视觉信息,开创性地实现了“语义-视觉”的跨模态学习,其H-score (未见类得分和可见类得分的调和分数)在多个ZSL标准集中超过25%,较之前最优模型提升近2倍。基于该对抗生成的思路,ZSL出现了井喷式的发展。到2020年底,相关研究[7-10]已经将GAZSL模型进行了深度优化,H-score在ZSL多个标准集中也达到了60%以上。然而,对比一般的图像分类模型普遍90%以上准确率,ZSL还有很大的提升空间,但目前已触到了瓶颈。
这个瓶颈便是ZSL中经典的“领域漂移问题”。从2009年ZSL首次提出,到2020年底的最新研究,领域漂移问题不断被消解,但从未被消除。领域漂移问题普遍存在于“语义-视觉”跨模态学习中,由于语义信息较视觉信息更为单一,在语义信息转化为视觉信息时,会丢失视觉的细节信息,从而造成误判。典型的例子是同样描述一个视觉目标是否“有黑色的尾巴”,但是真实视觉可能是“罗威纳犬的尾巴”或“杜宾犬的尾巴”,虽然都是黑色的尾巴,但是其视觉细节有着巨大的差异,语义信息并不能完备地对其描述。这主要是由于相较于视觉信息,语义信息不够丰富而不能对等匹配,在“语义-视觉”跨模态转化时,产生严重的领域漂移问题。
针对该问题,本文提出了一种属性语义与知识图谱关联语义融合增强的方法,用于增强语义信息,缓解目前语义信息与视觉信息不对称情况,进一步消解ZSL的领域漂移问题。首先,基于对抗生成的思路,模型采用图卷积网络设计了一个知识图谱视觉特征生成网络,能够将知识图谱语义信息转化为相应的关联视觉特征。而后,将关联视觉特征与通过属性语义信息转化而来的属性视觉特征共同输入特征融合网络合成融合视觉特征。最后,将融合视觉特征输入一个特征空间映射网络并与真实视觉特征进行合理性判别和类别判别。整个模型在ZSL标准集SUN,AWA,CUB和aPY中进行了评估,结果证明其能够显著地增强语义特征,合成更为细致的视觉特征,其表现优于目前已有的ZSL方法。
1 相关工作
1.1 知识图谱关联零次学习
知识图谱是一种特殊的图结构,也可以看作是一种大规模的语义网络[11]。知识图谱抽象地描述了现实世界。现实中的事物被描述成图谱中一个点,事物之间的联系描述成了一条边。错综复杂的事物关系便构成了一张网。结构化的表现形式和丰富的语义信息让知识图谱可以服务人工智能领域的下游任务。
知识图谱用于ZSL的现阶段工作较少。2018年KIPF和WELLING[12]引入了图卷积网络(graph convolution networks,GCN),在做零次图像识别时使用了语义属性的嵌入和类别的关系的类别预测分类器[13],并将每个数据集类别作为一个知识图谱的节点,样本类别之间的关系作为图谱的边。GCN模型训练的输入为节点的语义嵌入特征。该模型使用6层的图卷积作为预测类别分类器。测试中,使用训练完成的可见分类器给未见类别进行分类。该方法在某些指标上得到2%~3%的提升。是最早将知识图谱应用于ZSL的方法。
2019年KAMPFFMEYER等[14]针对文献[13]工作做了改进,提出了GCNZ[13]的一些不足并做了改进,同时指出6个层次的图卷积层会导致过度的拉普拉斯平滑,让每一个节点趋于相似,降低了模型的性能。另一个矛盾是,较浅的图卷积网络层不会学习到较远距离的节点特征。于是本文针对该问题做了2个改进:①减少了GCN图卷积网络的层数,设置为2;②改进了知识图谱的结构,在原有的知识图谱上将祖先节点和孙子节点进行了相连从而得到了更为稠密的知识图谱。同时在知识图谱的边上设置权重值,即稠密图传播(dense graph propagation,DGP)方式。其他处理形式同文献[13]。
1.2 生成式的零次学习
生成对抗网络(generative adversarial networks,GAN)是文献[13]提出的机器学习架构。监督学习的数据集通常是由大量的带有标签的训练集和测试集组成。非监督方式学习[15]可以根据学习,从而降低出错的概率。监督方式的学习准确率领先于非监督式的学习方式,但前者需要大量优质的带有标签的数据集,且十分费时费力。GAN的出现是非监督式学习提升一个关键因素。其十分擅长无监督的学习,特别是在生成数据方面。GAN具有强大的表征能力,在潜在的向量空间执行算数运算,并可以很好地转换为对应特征空间的特征表示。
图1是生成对抗网络的基本学习框架。随机噪声输入到生成器中生成伪视觉特征。训练样本的视觉特征和生成器生成的视觉特征一同输入到判别器中进行判别。若判别器识别正确,说明生成器效果还有提升,此时会优化生成器;若判断错误,说明判别器有优化空间,对其进行优化,以避免错误再次发生。经过不断的迭代优化,生成器可以生成接近真实图片分布的伪视觉特征,判别器可以鉴别出真和伪视觉特征,两者达到一个均衡和谐的状态。
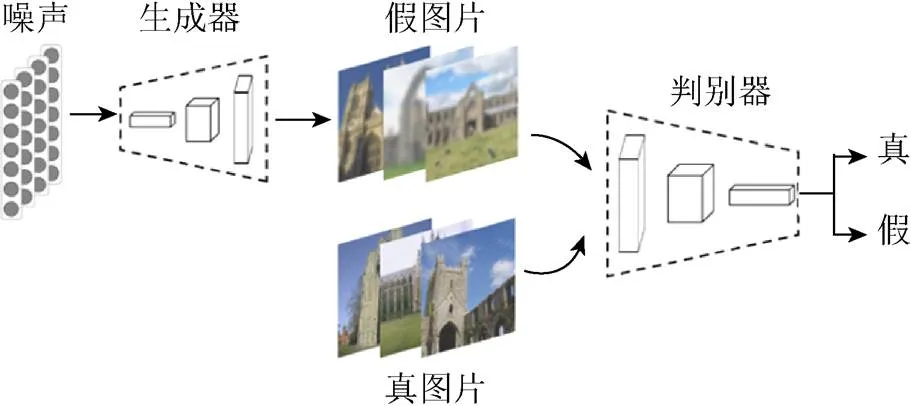
图1 生成对抗网络的基本框架
原始GAN[5]生成图片的效果并不理想,与变分编码器(variational autoencoder,VAE)[16]效果不相上下,远远未达到研究者的目标。因此研究者们对GAN做了较多的改进,解决其训练中存在的不稳定、梯度消失和模式崩溃等问题。例如WGAN模型(wasserstein generative adversarial networks)[17]通过理论分析发现,若2个分布之间存在不相交的部分,则JS散度不适用于衡量这两者之间的距离。因此使用Wasserstein代替JS散度来测算2个条件分布之间距离,解决模式崩溃的难题。基于文献[17],条件生成对抗网络(conditional GAN,CGAN)[18]通过为生成器以及辨别器引入辅助信息,例如类别标签、文本甚至图像,提高生成图像的质量。辅助分类生成对抗网络(auxiliary classifier GAN,ACGAN)[19]则通过添加额外的类别识别分支,进一步稳定了辨别器的训练过程。与ACGAN[19]不同,为ZSL设计的生成对抗网络(generative adversarial approach for zero-shot learning,ZSL-GAN)[20]中添加了视觉轴正则化(visual pivot regularization,VPG)使生成样本的数据分布中心尽可能逼近真实样本数据分布聚类中心。
目前,已有较多研究基于GAZSL开展。文献[13]为了解决GAN中存在的多样性和可靠性低的问题,提出了条件式瓦瑟斯坦距离的(conditional Wasserstein GAN,CWGAN)。语义描述和噪声作为CWGAN的输入来产生具有多样性的生成样本。同时,该方法定义了灵魂样本,通过使生成器生成的样本靠近对应的灵魂样本来保证生成器的可靠性。为了解决GAN在语义到视觉转化过程中出现的领域漂移现象,HUANG等[21]提出了双向的生成对抗网络(generative dual adversarial network,GDAN),该网络分别使用生成器和回归器完成语义到视觉和视觉到语义的双向映射来保证更加泛化的生成器。然而,目前该方向的研究仍然基于常规的对抗生成网络,在ZSL跨模态生成过程中存在原理上的局限。
2 属性语义与图谱语义融合增强的零次学习模型
2.1 知识语义图谱构建
知识图谱(knowledge graph)[11]的概念由谷歌2012年正式提出,旨在实现更智能的搜索引擎,并于2013年后开始在学术界和工业界普及。其在智能问答、情报分析、反欺诈等应用中发挥着重要的作用。
知识图谱构建采用2种方式:①基于数据集原始属性语义空间距离构建知识图谱;②基于自然知识构建知识图谱。
基于属性语义空间构建知识图谱具体流程如图2所示。由原始属性语义的空间分布来获取类别之间的联系。类别联系建立的依据是否超过2个类别属性语义空间分布距离D。D值根据类别可视化距离分布情况而设定。
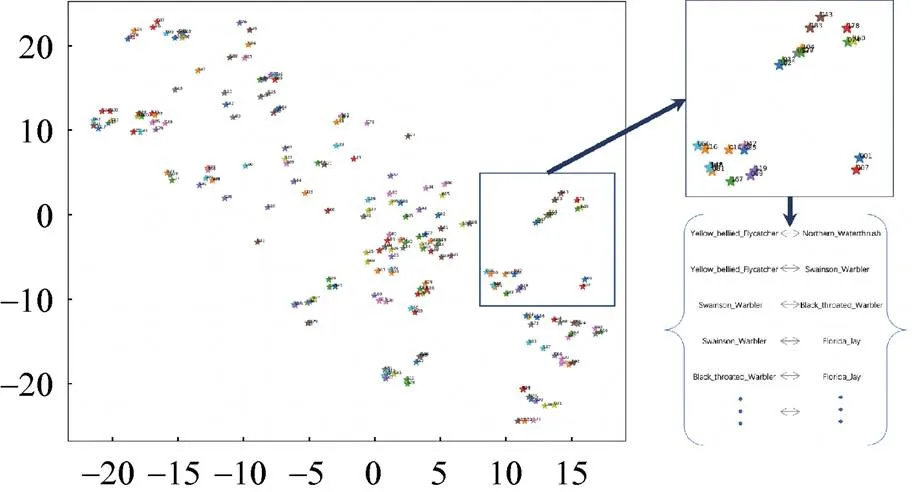
图2 基于语义空间距离的图谱构建
基于自然知识构建知识图谱方法具体流程如图3所示。实验中AWA[22]和SUN[23]使用自然知识构建了图谱。因为AWA和SUN中类别属性语义空间分布比较杂乱,构建质量较好的数据集图谱较为困难。AWA知识图谱构建是根据门纲目科属种中的“属”关系来进行构建。SUN知识图谱构建是根据其官网展示中的场景相似链接。以此场景相似关系作为SUN知识图谱构建的依据。AWA,SUN,CUB和aPY构建的图谱规模见表1。
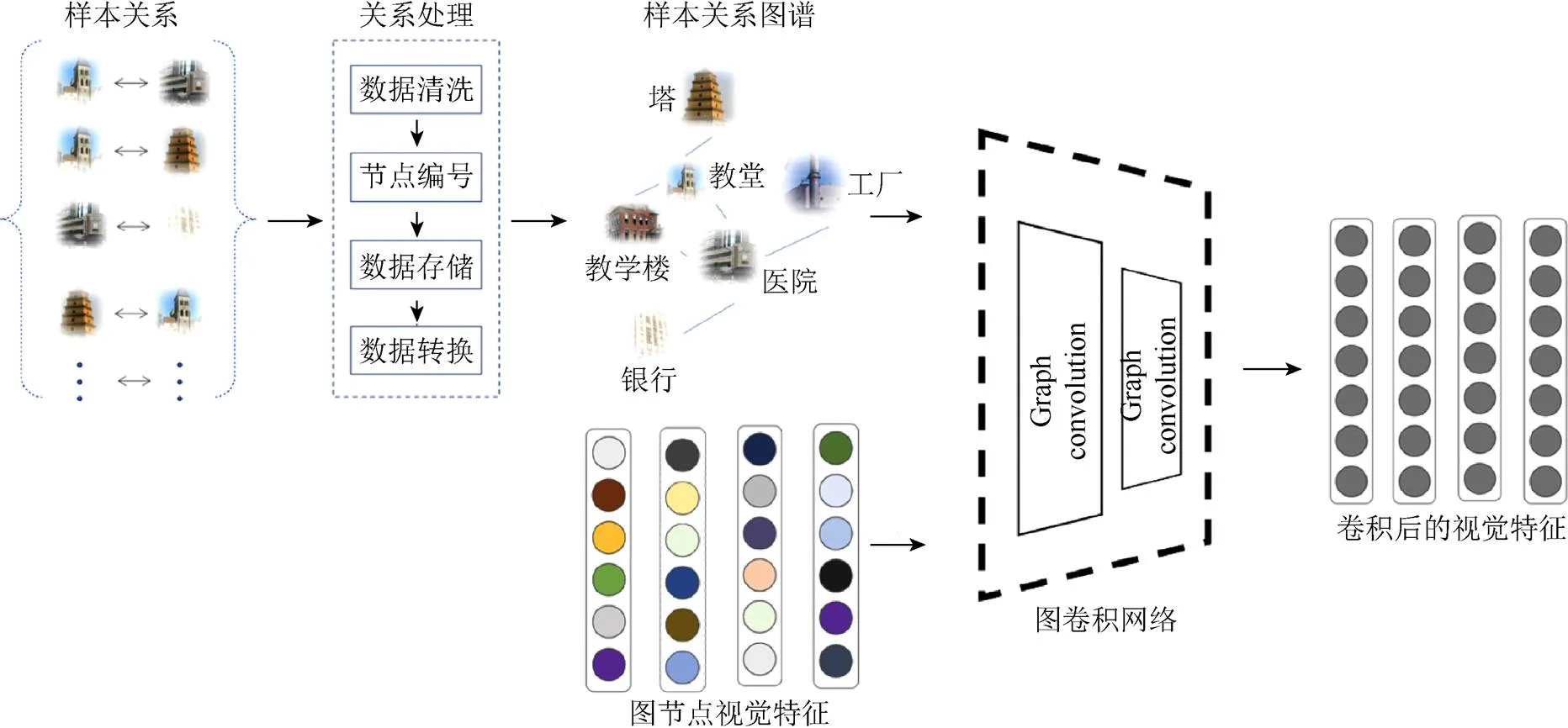
图3 基于自然知识的图谱构建
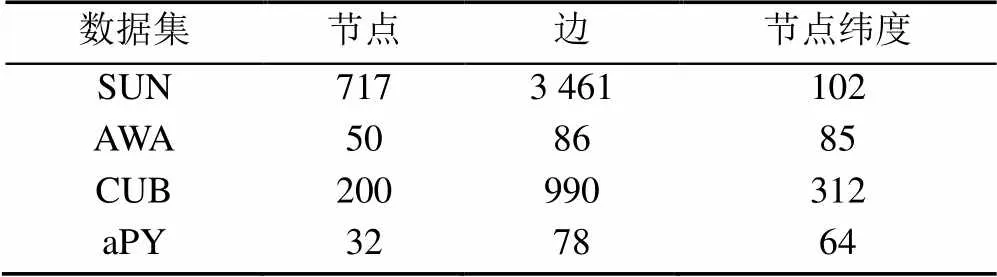
表1 SUN,AWA,CUB和aPY图谱大小
2.2 知识图谱嵌入学习
图嵌入(graph embedding)是表示学习的范畴,也可以叫做图表示学习。其目的是将图谱中的节点表示成向量的形式。嵌入后的向量在特定的向量空间中可以得到合理的表示,具体的可以用于学习的下游任务,比如节点的分类等。
图嵌入的方式有3种:①矩阵分解;②DeepWalk;③图神经网络(graph neural network,GNN)。实验中知识图谱嵌入方法使用图卷积神经网络(graph convolutional network,GCN)的方式。GCN是GNN的一种,即采用卷积方式的一种网络,具体为
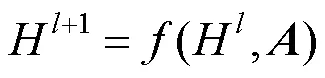
其中,为第层的输入,当=0时,对应的H是原始图谱的输入;为邻接矩阵,不同的GCN的差异体现在了函数上。
式(1)是以图谱语义网络作为输入。通过不断的迭代实现节点图卷积学习的效果。以节点为特征的图卷积式为
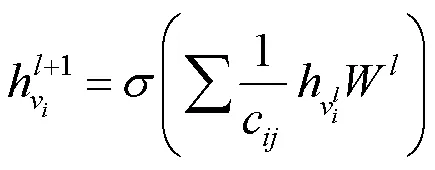
权重矩阵参数。
2.3 图谱语义与属性语义融合学习
模型可以划分为3部分:①图谱语义学习;②属性语义学习;③空间映射学习。本文将以SUN数据集为输入来说明属性语义与图谱语义融合增强ZSL模型学习过程。
2.3.1 图谱语义学习
与传统的GCN不同,本文方法在GCN卷积融合的同时让其做泛化的生成。GCN模块的使用会弥补GAN中缺失合理泛化和语义信息缺失的问题。GCN的对抗学习网络设置了判别器DGcn (discriminator for Gcn),其对抗优化的目标式为
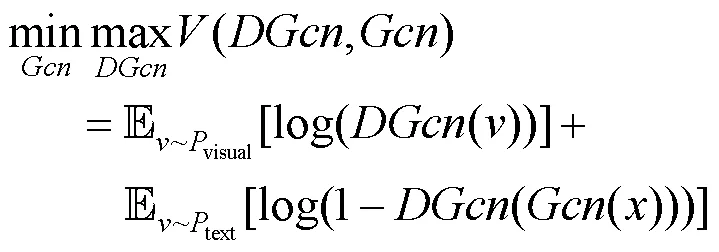
图卷积部分实现图谱语义到视觉空间的嵌入。本文使用SUN官网场景相似关系提取了该数据集中的样本关系。SUN知识图谱包含717个类节点,3 641条属性边。按照DGL库中标准输入,本文将样本分为起始节点和结束节点的集合。类别节点的特征表示使用原始语义属性。图谱语义特征到视觉特征之间的映射方法使用GCN[12]{Kipf, 2016 #11}来实现。GCN输入是图关系中的起始节点的序号集合和结束节点序号集合。研究方法使用了DGL库中2个图卷积函数来组成图卷积模块。GCN输出的伪视觉特征和真实视觉特征使用余弦相似度比较产生损失进行图卷机模块GCN的学习。图谱语义学习框架如图4中图谱语义部分。
图4 属性语义与图谱语义融合增强模型架构。生成器实现语义到视觉特征的映射;图卷积网络实现图谱语义到视觉映射
Fig.4 The framework of attribute and graph semantic reinforcement. The generator realizes the mapping from semantic attributes to visual features, and the graph convolution network realizes the mapping from graph semantic attributes to visual features
2.3.2 属性语义学习
生成器(generator,G)在模型中是用来将语义信息合成伪视觉特征。合成的伪视觉特征将用于视觉特征的融合。生成器部分实现了属性语义到视觉空间的映射。
场景类别的102维度的语义特征拼接102维的噪声后输入到生成器。噪声的加入保证了生成器可以生成丰富多样的特征,如图4中属性语义部分。
训练过程中生成器和判别器对抗优化的目标式为
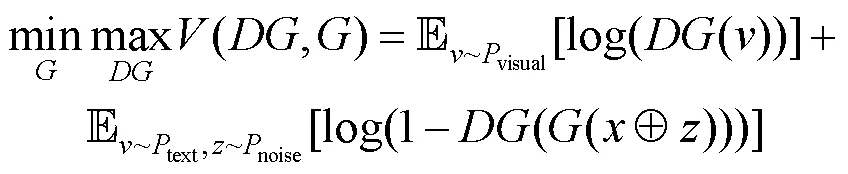
2.3.3 空间映射对抗学习
空间映射模块的作用是将融合后的视觉特征映射到新的空间中,合成的视觉特征在此空间更加的泛化。空间映射(space encoder,SE)模块,对应的对抗判别器(discriminator for space encoder,DSE)。其将GCN和G的融合视觉特征映射到新的特征空间。其对抗优化式为
模型中的图卷积模块和生成器产生的伪视觉特征通过融合模块进行了特征融合,产生了新的视觉特征,如图4框架图后半部分。为使融合的视觉特征在测试阶段具有类级别的判别性,模型使用空间映射模块SE (space encoder)让伪视觉特征在新的特征空间进一步接近真实视觉特征。训练空间映射模块时真实特征的输入为ResNet[24]提取的2 048维度的视觉特征。空间映射模块接受融合后的伪视觉特征和真实图片的视觉特征输入,将合成的视觉特征和真实的视觉特征映射为1 024维度。SE判别器在图片的真实性和类别标签正确性两方面进行判别。该判别器在保证SE映射后的视觉特征真实性的前提下,又让样本之间产生一定的判别性。空间映射模块的判别器中使用了标签损失以此来达到更好地分类效果。这种判别性具体体现在类别视觉特征经过SE现映射后在映射空间会存在合理的距离。模型测试阶段的分类方法使用KNN算法[25]来实现样本的分类。
3 实验及性能评估
实验通过SUN,AWA,CUB和aPY 4个数据集来评估属性语义与图谱语义融合模型。本文将依次介绍本次实验数据集、评估方法、实验细节和可视化对比展示。
3.1 数据集
在ZSL中常用的数据集有CUB[26],AWA1,AWA2,SUN和aPY[27]等。其中CUB和SUN数据集是细粒度的数据集。AWA1,AWA2和aPY是粗粒度的数据集。为了更好地评测该方法的有效性,本文选择了SUN,AWA1,CUB和aPY 4个标准数据集进行实验。
场景理解(scene understanding,SUN)数据集,是中规模细粒度混合场景(包括人物、风景、风筝等类别)的数据集。其包括717个场景类别的14 340张图片,每类含有20张图片。并且数据集中为每个类别提供了102维的场景属性向量。这些属性特征描述了场景的材质和表面属性,以及照明条件、功能、供给和一般图像布局等属性。
动物与属性(animals with attributes,AWA)数据集涵盖50个动物分类,30 475张图像,每类至少包括92个样本。每张图像由6个预提取的特征表示,并且为每个类别标注了85维语义属性。标注的属性使得已见类到未见类的知识迁移成为可能。通常在ZSL的实验中,将数据集中的40类划分为训练集,10类划分为测试集。
加州鸟类(Caltech-UCSD Birds-200-2011,CUB)数据集是目前细粒度分类识别研究的基准图像数据集,共有11 788张鸟类图像,包含200类子类,提供了图像类标记信息、图像中鸟的属性信息、位置边框信息等。
帕斯卡和雅虎(attribute Pascal and Yahoo,aPY)数据集是中规模粗粒度的数据集。该数据集类别语义为64维,共有15 339张图片,包含32个目标类。4个ZSL数据集详细规模信息见表2。
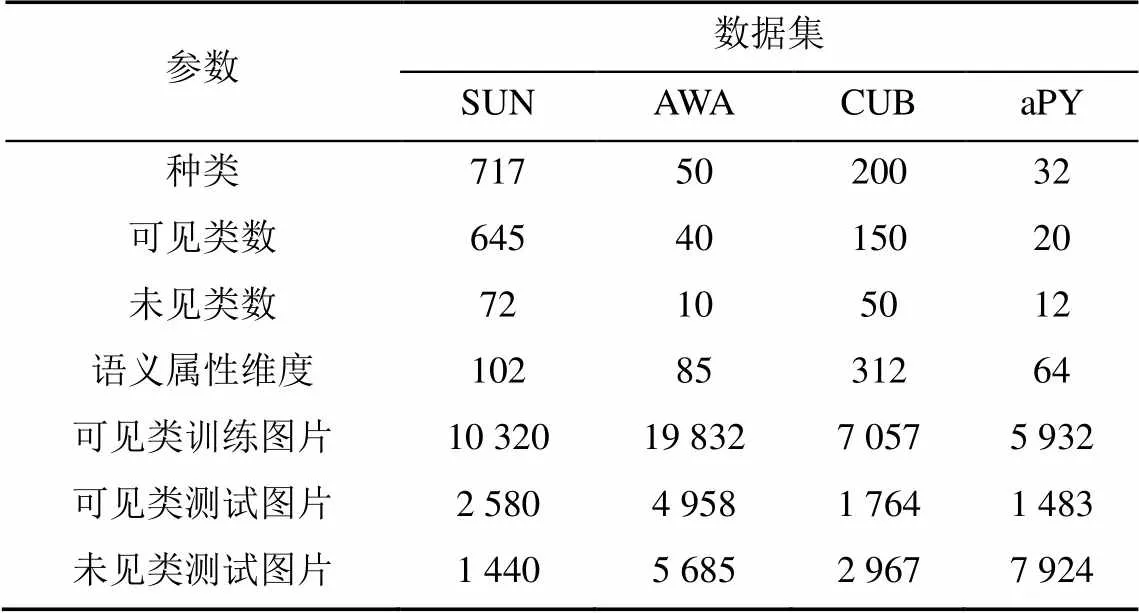
表2 SUN,AWA,CUB和aPY数据集规模
3.2 评估指标
目前对于小规模数据集评价指标分为2类,即平均分类准确率(accuracy,Acc)和平均精确率(mean average precision,mAP)。由于部分数据集可能出现样本分布不均的情况,在这种情况使用mAP将导致评价结果失去意义。
模型性能的评估是通过每个类别的Top-1准确率来进行评估的。在广义的ZSL中,可见类和未见类的图片作为ZSL的测试集。然而传统的ZSL测试集仅仅是未见类中的图片。在此,评估模型的Top-1准确率在可见类中,记做。同样的,未见类的Top-1准确率记做。然后定义调和平均值=(2××)/(+)来整体评测ZSL模型的性能。
3.3 实验参数设置
实验中,模型的搭建选择了神经网络框架Pytorch。生成器构建了含有4 096个隐藏单元的隐藏层,激活函数采用LeakyReLU[28]激活方式。
GCN的知识图谱的构建以及图谱的卷积操作,模型使用DGL库函数以及自定义的模块化的GCN网络来完成知识图谱语义知识到伪视觉向量的映射。
在DGcn和DG中的相似度判别方式使用了余弦相似度的方式来计算GCN和G生成伪视觉特征的损失值。余弦相似度不同于欧氏距离,其从特定的向量空间中计算出空间向量的夹角,可以从整体的角度去衡量合成视觉特征的真实性。
在特征融合阶段,GCN的输出特征和G的输出特征通过融合模块融合。现阶段的视觉特征融合方法使用视觉特征拼接的方式。
在优化器的选择上,选择了Pytorch中的Adam优化器[29],同时将批处理大小设置为512。学习率设置为0.000 1。实验中为了使生成器生成伪视觉特征更真实稳定,模型的学习过程采用Wasser-steinGAN[17]和一些其他的改进优化策略。
3.4 结果可视化分析
本文与其他方法进行比较,以验证属性语义与图谱语义融合增强方法的有效性。实验针对测试阶段合成视觉特征的数量,对模型的性能进行了相应的测试。合成视觉特征的数量对实验结果有很大的性能影响是因为测试预测阶段使用最近邻算法(K-nearest neighbor,KNN)[25]的方式去进行评估,如图5所示。
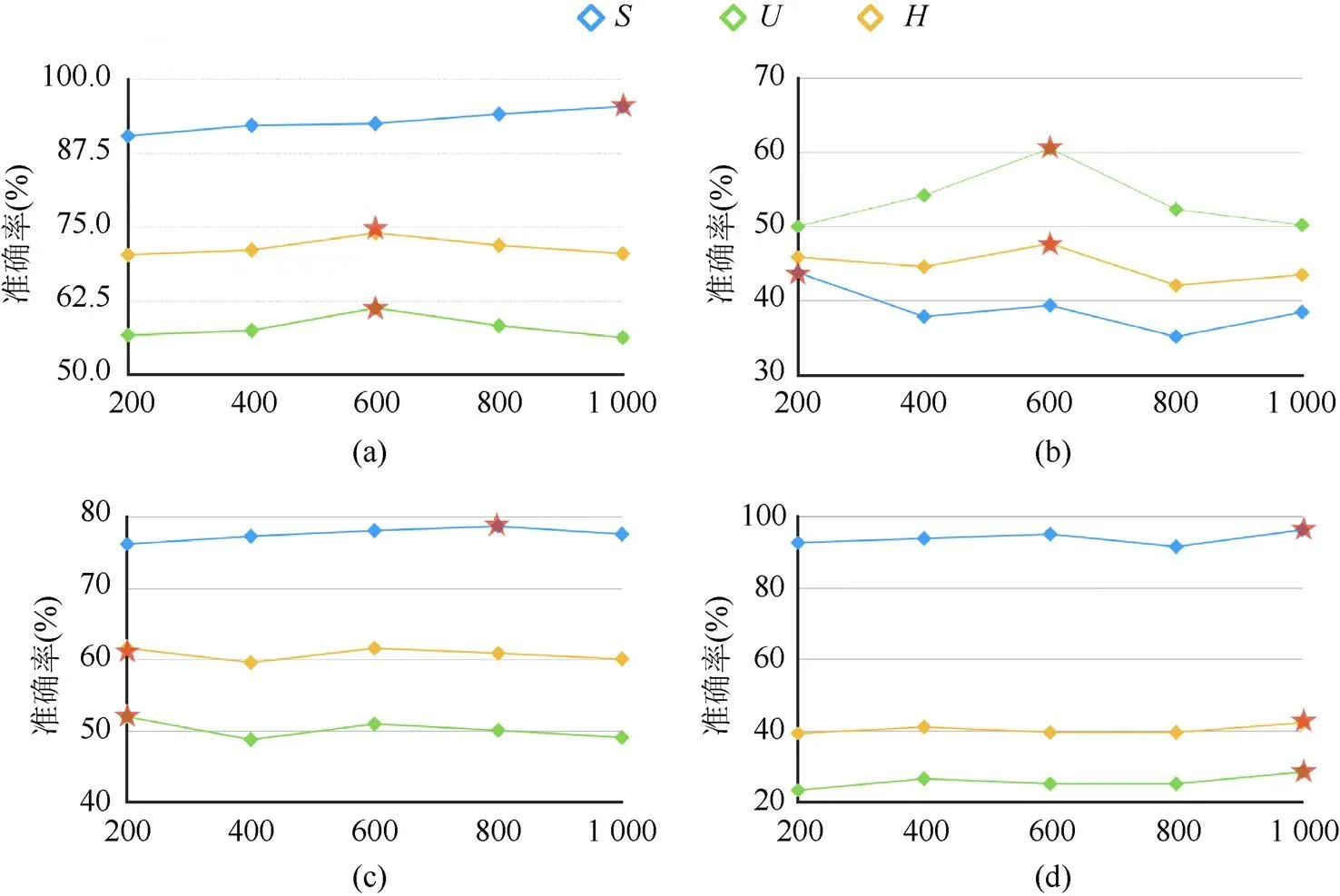
图5 生成器合成视觉特征数量对实验结果的影响((a)AWA数据集下,不同数量的合成视觉特征对的影响。当数量为600时H取得最好的结果;(b)SUN数据集下,不同数量的合成视觉特征对的影响。当数量为600时H取得最好的结果;(c) CUB数据集下,不同数量的合成视觉特征对的影响。当数量为200时H取得最好的结果;(d)APY数据集下,不同数量的合成视觉特征对的影响。当数量为1000时H取得最好的结果)
KNN考虑的是特征空间中最近的个特征,合成的伪视觉的数量会直接影响评估算法的匹配。合成未见类特征数量越多,匹配到未见类别视觉特征的几率越大。通过在SUN,AWA,CUB和aPY 4个标准数据集实验发现:
(1) SUN数据集上合成的视觉特征数量在600时,,和都取得了最高的值。SUN数据集中训练种类多且数据集中每个场景类别图片数量有明显差距。属性语义与图谱语义融合增强的ZSL模型泛化能力,让类别数量较少的未见类识别精度高于可见类识别精度。
(2) aPY数据集上,和3个值最高均在合成数量为1 000时。aPY数据集上和值差距较大是由于测试图片数量高于训练图片的数量。
SUN数据集在ZSL中是有挑战的数据集。诸多ZSL模型在AWA,CUB和aPY数据集上表现较好,但是在SUN数据集上效果欠佳。图6展示了SUN数据集未见类真实的视觉特征通过t-SNE[30]算法降维后的数据特征分布。SUN数据中未见类的真实视觉特征区分度不大,聚合度不够,场景类别视觉中心不够明显。
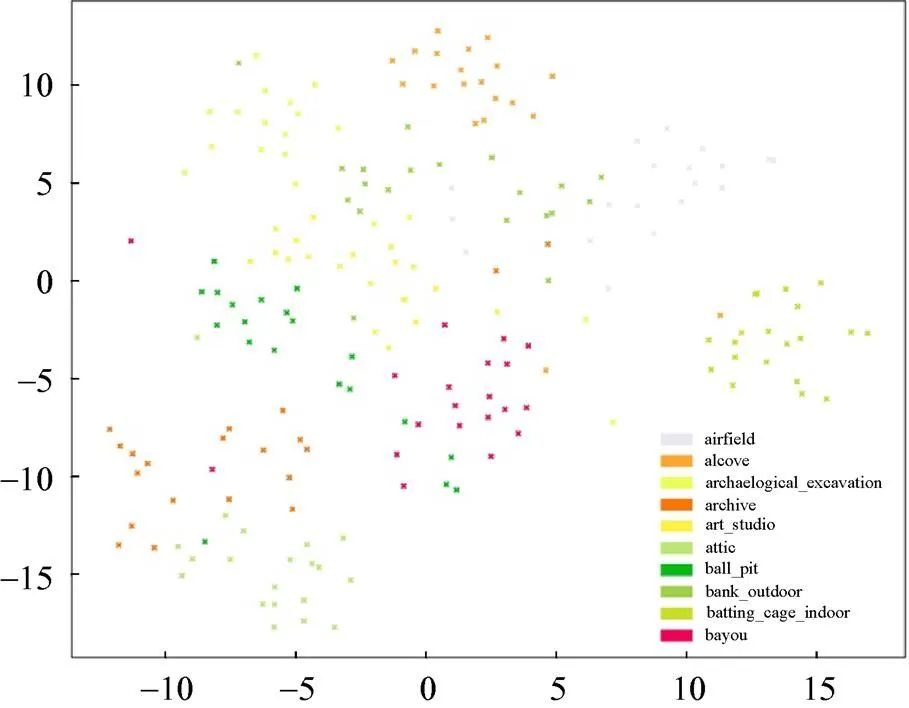
图6 SUN未见类中真实视觉特征分布
为使数据的类视觉中心明确。本文方法首先通过属性语义与图谱语义融合增强,进而输入到SE模块映射到新空间中进行分类预测。在新的特征空间中合成的未见类视觉特征可以合理的分布在真实视觉特征中心的周围,如图7所示。
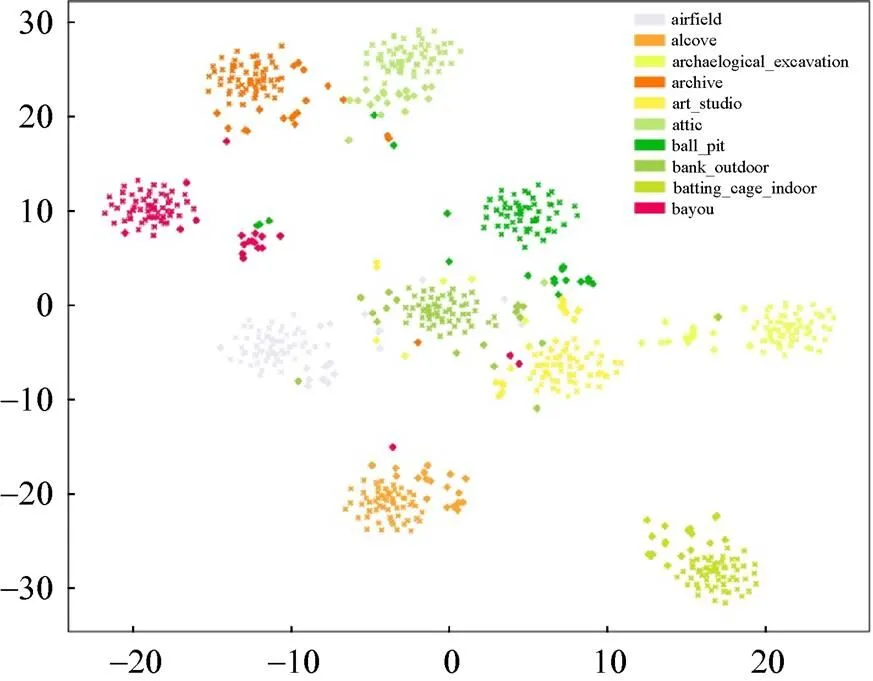
图7 SUN未见类中真实特征和合成特征的分布
表3为广义的ZSL的结果。本文选择近三年来广义ZSL的相关方法与属性语义与图谱语义融合增强的方法进行对比。通过对比,本文方法模型在4个标准数据集上都取得了相对较好的实验结果。
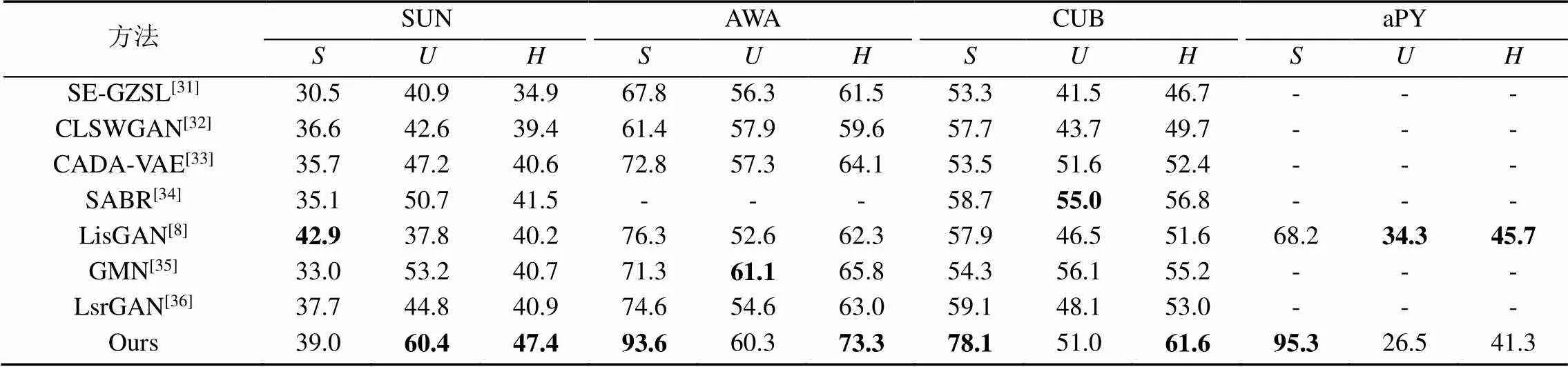
表3 属性语义与图谱语义融合增强的零次学习方法与现阶段工作的对比
4 总结与展望
本文设计了一种属性语义与图谱语义融合增强的ZSL模型,并在SUN,AWA,CUB和aPY数据集上进行了实验,表现出较好的效果。该方法结合知识图谱和GAN在ZSL中的优点,一定程度上解决了领域漂移问题中语义信息缺失问题,可以将类别语义特征合成更为细致泛化的视觉特征,有着较强的泛用性和可解释性。
后续将针对ZSL中领域漂移的未见类语义缺失问题,通过使用知识图谱关联目标级别的视觉特征尝试进行解决。这也是ZSL向强人工智能迈进的重要一步。
[1] PALATUCCI M, POMERLEAU D, HINTON G E, et al. Zero-shot learning with semantic output codes[C]//The 22nd International Conference on Neural Information Processing Systems. New York: ACM Press, 2009: 1410-1418.
[2] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 951-958.
[3] AKATA Z, PERRONNIN F, HARCHAOUI Z, et al. Label-embedding for attribute-based classification[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 819-826.
[4] KODIROV E, XIANG T, GONG S G. Semantic autoencoder for zero-shot learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 4447-4456.
[5] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144.
[6] ZHU Y Z, ELHOSEINY M, LIU B C, et al. A generative adversarial approach for zero-shot learning from noisy texts[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1004-1013.
[7] JI Z, CHEN K X, WANG J Y, et al. Multi-modal generative adversarial network for zero-shot learning[J]. Knowledge- Based Systems, 2020, 197: 105847.
[8] LI J J, JING M M, LU K, et al. Leveraging the invariant side of generative zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 7394-7403.
[9] HUANG H, WANG C H, YU P S, et al. Generative dual adversarial network for generalized zero-shot learning[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 801-810.
[10] SARIYILDIZ M B, CINBIS R G. Gradient matching generative networks for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 2163-2173.
[11] PUJARA J, MIAO H, GETOOR L, et al. Knowledge graph identification[C]//The 12th International Semantic Web Conference. Heidelberg: Springer, 2013: 542-557.
[12] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2021-02-21]. https:// arxiv.org/abs/1609.02907.
[13] WANG X L, YE Y F, GUPTA A. Zero-shot recognition via semantic embeddings and knowledge graphs[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6857-6866.
[14] KAMPFFMEYER M, CHEN Y B, LIANG X D, et al. Rethinking knowledge graph propagation for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 11479-11488.
[15] BARLOW H B. Unsupervised learning[J]. Neural Computation, 1989, 1(3): 295-311.
[16] KINGMA D P, WELLING M.Auto-encoding variational bayes[EB/OL]. [2021-01-30]. https://arxiv.org/pdf/1312.6114. pdf?source=post_page.
[17] ARJOVSKY M, CHINTALA S, BOTTOU L.Wasserstein generative adversarial networks[C]//The 34th International Conference on Machine Learning. New York: ACM Press, 2017: 214-223.
[18] MIRZA M, OSINDERO S.Conditional generative adversarial nets[EB/OL]. [2021-02-05]. https://arxiv.org/pdf/1411.1784. pdf.
[19] ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier GANs[EB/OL]. [2021-02-29]. http:// proceedings.mlr.press/v70/odena17a/odena17a.pdf.
[20] ZHU Y Z, ELHOSEINY M, LIU B C, et al. A generative adversarial approach for zero-shot learning from noisy texts[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 1004-1013.
[21] HUANG H, WANG C H, YU P S, et al. Generative dual adversarial network for generalized zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 801-810.
[22] PATTERSON G, XU C, SU H, et al. The SUN attribute database: beyond categories for deeper scene understanding[J]. International Journal of Computer Vision, 2014, 108(1-2): 59-81.
[23] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[24] HASTIE T, TIBSHIRANI R. Discriminant adaptive nearest neighbor classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(6): 607-616.
[25] WELINDER P, BRANSON S, MITA T, et al. Caltech-UCSD birds 200 [EB/OL]. [2021-01-30]. https://www.researchgate. net/publication/46572499_Caltech-UCSD_Birds_200.
[26] FARHADI A, ENDRES I, HOIEM D, et al. Describing objects by their attributes[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2009: 1778.
[27] LAMPERT C H, NICKISCH H, HARMELING S. Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 951-958.
[28] ZHANG X H, ZOU Y X, SHI W. Dilated convolution neural network with LeakyReLU for environmental sound classification[C]//2017 22nd International Conference on Digital Signal Processing (DSP). New York: IEEE Press, 2017: 1-5.
[29] DA K. A method for stochastic optimization[EB/OL]. [2021- 01-13]. https://arxiv.org/pdf/1412.6980.pdf.
[30] VAN DER MAATEN L, HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2625.
[31] VERMA V K, ARORA G, MISHRA A, et al. Generalized zero-shot learning via synthesized examples[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4281-4289.
[32] XIAN Y Q, LORENZ T, SCHIELE B, et al. Feature generating networks for zero-shot learning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5542-5551.
[33] SCHÖNFELD E, EBRAHIMI S, SINHA S, et al. Generalized zero- and few-shot learning via aligned variational autoencoders[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 8239-8247.
[34] PAUL A, KRISHNAN N C, MUNJAL P. Semantically aligned bias reducing zero shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 7049-7058.
[35] SARIYILDIZ M B, CINBIS R G. Gradient matching generative networks for zero-shot learning[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 2168-2178.
[36] VYAS M R, VENKATESWARA H, PANCHANATHAN S. Leveraging seen and unseen semantic relationships for generative zero-shot learning[C]//The 16th European Conference on Computer Vision - ECCV 2020. Heidelberg: Springer, 2020: 70-86.
Attribute and graph semantic reinforcement based zero-shot learning for image recognition
WANG Yu-jin, XIE Cheng, YU Bei-bei, XIANG Hong-xin, LIU Qing
(School of Software, Yunnan University, Kunming Yunnan 650500, China)
Zero-shot learning (ZSL) is an important branch of transfer learning in the field of image recognition. The main learning method is to train the mapping relationship between the semantic attributes of the visible category and the visual attributes without using the unseen category, and use this mapping relationship to identify the unseen category samples, which is a hot spot in the current image recognition field. For the existing ZSL model, there remains the information asymmetry between the semantic attributes and the visual attributes, and the semantic information cannot well describe visual information, leading to the problem of domain shift. In the process of synthesizing unseen semantic attributes into visual attributes, part of the visual feature information was not synthesized, which affected the recognition accuracy. In order to solve the problem of the lack of unseen semantic features and synthesis of unseen visual features, this paper designed a ZSL model that combined attribute and graph semantic to improve the zero-shot learning’s accuracy. In the learning process of the model, the knowledge graph was employed to associate visual features, while considering the attribute connection among samples, the semantic information of the seen and unseen samples was enhanced, and the adversarial learning process was utilized to strengthen the synthesis of visual features. The method shows good experimental results through experiments on four typical data sets, and the model can synthesize more detailed visual features, and its performance is superior to the existing ZSL methods.
zero-shot learning; knowledge graph; generative adversarial networks; graph convolution; image recognition
TP 391
10.11996/JG.j.2095-302X.2021060899
A
2095-302X(2021)06-0899-09
2021-03-24;
2021-05-10
中国科协“青年人才托举工程”项目(W8193209);云南省科技厅项目(202001BB050035)
汪玉金(1995-),男,山东泰安人,硕士研究生。主要研究方向为知识图谱、零次学习和图像生成。E-mail:wyj1934966789@gmail.com
谢 诚(1987-),男,云南普洱人,副教授,博士。主要研究方向为知识图谱与零次学习。E-mail:xiecheng@ynu.edu.cn
24 March,2021;
10May,2021
China Association for Science and Technology “Youths Talents Support Project” (W8193209); Technology Department Program of Yunnan Province (202001BB050035)
WANG Yu-jin (1995–), male, master student. His main research interests cover knowledge graph, zero-shot learning and image generation. E-mail:wyj1934966789@gmail.com
XIE Cheng (1987–), male, associate professor, Ph.D. His main research interests cover knowledge graph, zero-shot learning. E-mail:xiecheng@ynu.edu.cn
