融合多方面潜在特征和神经网络的推荐模型
2022-01-21董露露
郑 诚,付 娴,董露露
1(安徽大学 计算机科学与技术学院,合肥 230601)2(安徽广播电视大学 教务处,合肥 230022)
1 引 言
随着大数据时代的到来,超载的网上信息将用户淹没,帮助用户从大量资源中发现可能感兴趣项目的推荐系统,在各种线上平台中发挥着越来越重要的作用.协同过滤CF(Collaborative Filtering)[1]是目前使用最为广泛的推荐算法,其基本思想是,过去有过相似交互行为的人,未来可能会有相似的选择.
为了充分挖掘用户相似的偏好,潜在因子模型(如矩阵分解)[2]提出,该方法通常将用户-项目交互矩阵(评分矩阵)分解为低维的用户矩阵和项目矩阵,然后利用低维矩阵进行评分预测.然而,潜在因子模型通常存在冷启动问题,因此,许多扩展的潜在因子模型在矩阵分解框架下整合了辅助信息,如Zhao等人[3]提出将社会关系加入到推荐中,冯兴杰等人[4]联合评论文本及评分矩阵共同学习出用户和项目的潜在特征向量,进一步提升模型推荐效果.孟祥福等人[5]考虑到空间兴趣点之间存在的位置关系和社会关系,统一构建了兴趣点的地理-社会关系模型.最近,一个新的趋势是Wang等人[6]提出的利用项目知识图进行推荐,通过用户和项目之间的属性将用户-项目实例链接在一起,并通过抽取高阶链接路径来表达网络中的节点.
近年来随着深度学习的兴起,许多作品开始使用深度模型(如利用文本信息、图像信息[7]和网络结构信息[8])进行更有效的推荐.深度神经网络也被用于深度捕获用户和项目的潜在特征,如He等人[9]提出的神经协同过滤NCF(Neural Collaborative Filtering)利用多层前馈神经网络代替矩阵分解模型中的内积运算,从而捕获用户和项目之间的非线性关系.Xue等人[10]提出深度的矩阵分解DMF(Deep Matrix Factorization)直接使用评分矩阵作为输入,通过深度神经网络将用户和项目映射到普通的低维空间里.Chen[11]等人提出了使用深度学习技术来对物品之间的相关性进行挖掘.
虽然这些模型取得了良好的性能,但是现有的模型通常只侧重于通过用户和项目的交互信息挖掘用户和项目的潜在因子,而这些信息只反映了用户偏好和项目特征的一个方面.然而,在实际应用中,通常还包含着大量的属性信息(年龄、性别、类型等),这些属性信息可以从不同的方面更全面地反映用户偏好和项目特征.因此,潜在因子模型应该从不同角度充分挖掘用户和项目的潜在特征.
针对目前的推荐系统研究趋势以及存在的问题,本文提出了一种融合多方面潜在特征和神经网络的推荐模型MLFNNR(Recommendation Model Based on Multi-aspect Latent Feature and Neural Network),主要贡献如下:
1)针对现有的网络嵌入方法大都集中于同构网络,仅通过单一类型的节点和边提取的单一方面特征不足以充分挖掘用户偏好这一问题,提出了一种基于异构信息网络表示学习的方法,通过基于元路径随机游走的方式获取用户和项目多方面的特征.
2)针对传统线性融合的方式不能区分不同方面特征的重要程度这一问题,提出了结合注意力机制来融合多方面的潜在特征,以得到用户和项目的最终向量表示.
3)针对传统的矩阵分解简单地将潜在特征通过内积的形式来模拟交互的方法,不足以捕获用户项目交互数据的复杂结构这一问题,提出了使用神经网络来模拟用户和项目之间的交互,以实现最终的评分预测.
2 相关工作
2.1 潜在因子模型
潜在因子模型是一种基于隐变量的模型,如今在推荐系统领域得到了广泛的应用与研究.它的基本思想是将用户和项目映射成潜在因子,并利用这些潜在因子进行推荐.代表性著作有矩阵分解MF(Matrix Factorization),隐语义模型LFM(Latent Factor Model),概率矩阵分解PMF(Probabilistic Matrix Factorization)[12]和奇异值分解SVD++(Singular Value Decomposition)[13].以矩阵分解为例,其目标函数旨在最小化观测评分的正则化平方损失:
(1)
其中ri,j表示样本的真实评分,xi和yj表示用户i和项目j的潜在因子,λ是控制正则化强度的参数,通常使用L2范数来防止过拟合情况的发生.
基于这一基本的矩阵分解框架,通过添加一些辅助信息,提出了许多扩展的潜在因子模型,如社会推荐和基于异构网络的推荐.而现有的潜在因子模型的局限性在于,潜在因子主要通过一个方面提取的,即交互方面.但是其他一些更细粒度的用户-项目交互信息在很大程度上被忽略,而这些信息很可能对推荐结果有着一定影响.
2.2 异构信息网络
异构信息网络HIN(Heterogeneous Information Network)[14]包含了多种类型节点以及不同类型节点间的多种连接关系,通过网络中全面的结构信息可以准确地区分出不同语义,对推荐系统中的复杂对象及其丰富的关系进行建模,挖掘出更有意义的知识.不同于同构信息网络中的单一节点类型,HIN被表示为一组节点集合V和一组关系集合E.如图1展示了一个电影推荐中的HIN场景,其中包含了3种类型的节点(用户,电影,类型)和2种类型的连接关系(用户-电影,电影-类型).

图1 异构信息网络举例Fig.1 Example of HIN
对于图1所示的异构信息网络,当预测用户3可能感兴趣的电影时,如果只考虑交互历史行为,可以推断出用户3可能会更喜欢电影2和电影4,因为和他同样看过电影1的用户分别选择了电影2和电影4.然而,当考虑到电影类型时,可能会发现电影3是更好的推荐,因为电影1和电影3属于类型1.
为了评估HIN中实体之间的相似性,现有的研究提出了几种基于路径的相似性度量的方法,如基于元路径的相似性算法Pathsim(Meta Path-based Similarity)[15]、基于异构信息网络相似性的算法Hetesim(Heterogeneous Networks based Similarity)[16]等,并且取得了很好的性能,因此,越来越多的人开始意识到HIN在推荐领域的发展潜能.随后,元路径(meta-path)提出并逐渐引入到混合推荐中,Shi等人[17]提出了基于HIN的推荐,利用元路径提取了推荐系统中丰富的异构信息.此外,Yu等人[18]利用元路径的方式提取异构信息网络中不同类型的朋友关系,并提出了基于隐式朋友的个性化推荐框架.Luo[19]等人利用异构网络中的多种关系提出了一种基于协同过滤的社会推荐方法.最近,Lu等人[20]提出将元路径引导的异构关系分为所属关系与交互关系,并利用不同的模型分别处理.在文献[21,22]中,在不同的语义下,通过基于元路径的相似程度来评价用户与项目的相似度,并提出了一种基于双正则化框架的矩阵因子分解方法来进行评分预测.
因此可以得知,基于HIN的方法大多依赖于基于路径的相似性,但这可能并不能充分挖掘出HIN上用户和项目的潜在特征,因此需要一种更有效的方法,来利用元路径对不同方面的特征进行建模.
3 MLFNNR
本文提出了一种融合多方面潜在特征和神经网络的推荐模型MLFNNR,其基本思想是提取用户和项目在不同方面的潜在特征.如图2所示,本文首先通过基于元路径的随机游走策略,生成包含不同方面语义的节点序列,再通过异构skip-gram模型,最大化节点与其邻居节点在通过给定元路径采样的序列中的共现概率,以学习用户和项目在不同方面的潜在特征.对于每个方面的潜在特征向量,结合注意力机制来为不同的方面分配注意力权值,并将多方面的特征向量进行融合得到全局向量表示.最后将得到的用户和项目全局向量送入神经网络实现评分预测.
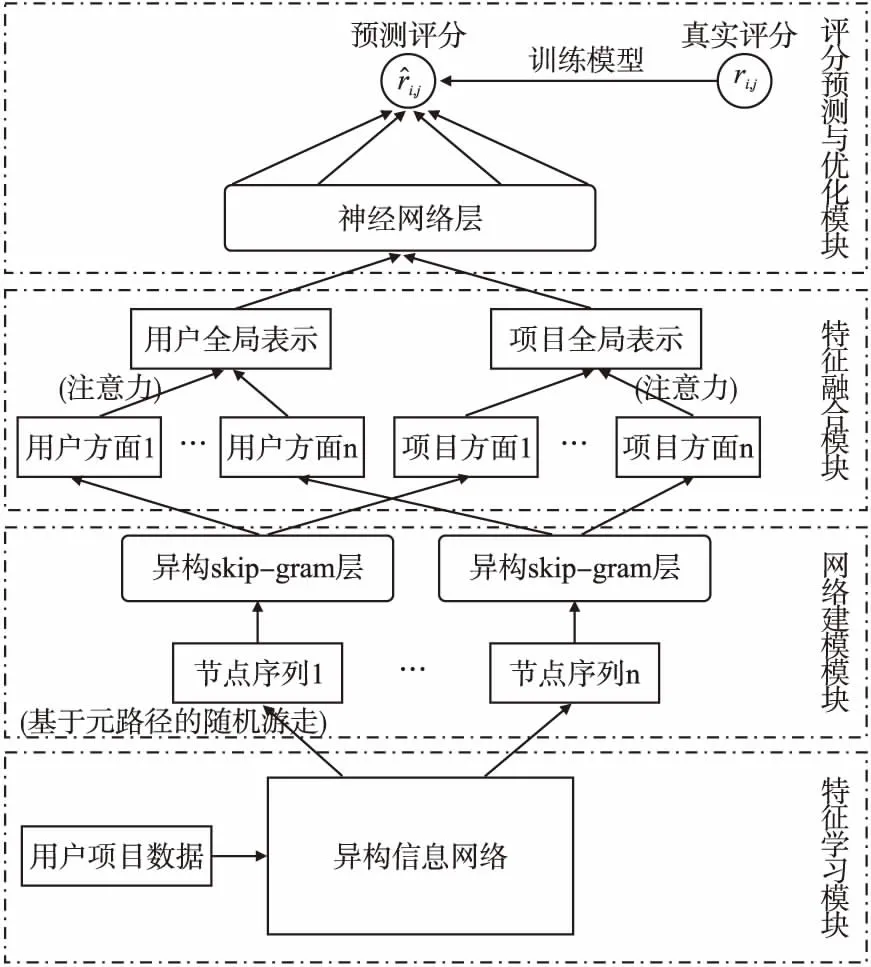
图2 融合多方面潜在特征和神经网络的推荐模型Fig.2 Recommendation model based on multi-aspect latent feature and neural network
3.1 异构信息网络建模
异构信息网络是一种特殊的信息网络,它包含多种类型节点和多种类型连接.本文通过不同的元路径提取HIN中的不同的语义,具体如表1所示,给出了电影数据集中可以提取的几条元路径以及不同元路径所对应的不同方面的特征.
表1 元路径及所提取的方面信息
Table 1 Meta-paths and the extracted aspect information

方面元路径用户电影交互行为UMUMUM导演 UMDMUMDM演员 UMAMUMAM电影类型UMTMUMTM
3.2 多方面潜在特征向量的提取
3.2.1 基于元路径的随机游走
在确定了用户和电影的不同方面的信息之后,假设给定一条指定的元路径,为了生成可信的节点序列,采用了基于元路径的随机游走,在第t步游走的转移概率定义如下:
(2)
其中nt表示随机游走的第t个节点,v节点的类型为Vt,E表示节点的集合,NVt+1(v)为节点v的一阶邻居节点集合,这些节点的类型为Vt+1.在游走的每一步,下一个节点的类型是由设定好的元路径所决定的.步骤将遵循设定好的元路径模式,直到达到预定的最大游走长度.
3.2.2 异构网络节点表示学习
通过基于元路径的随机游走,可以得到一系列包含不同类型的节点序列,为了进一步的研究,需要使用网络表示学习的方法来学习节点的低维向量表示.传统的深度方法如DeepWalk[23]、LINE(Large-scale Information Network Embedding)[24]等,虽然取得了很好的性能,但都是基于同构信息网络的,无法对异构的节点序列进行学习.因此本文结合了Dong等人[25]提出的异构 skip-gram模型,来学习异构网络下节点的表示.
模型可以看作是一个3层的神经网络,输入层为中心节点的表示向量,输出层为其他节点与中心节点共现的概率.模型的目标是,给定节点序列和窗口大小,令目标节点的邻近节点出现在同一窗口内的概率最大,目标函数如下:
(3)
其中Nt(v)表示节点v的上下文,窗口大小为w,p(ct|v;θ)被定为一个softmax函数,如下所示:
(4)
其中Xv为节点向量矩阵X的第v行,表示了节点v的嵌入向量,Vt表示网络中t类型的节点集合.与常规的softmax函数不同的是,异构网络下的softmax仅在相同类型的节点下进行归一化,因此只考虑了目标节点与其相同类型节点共现的概率.
3.3 基于注意力机制的特征融合
在分别学习到用户和项目的不同方面潜在特征向量表示后,需要通过一个融合函数将它们聚合起来,才能得到最终可以表示用户偏好和项目特征的特征向量.传统的方法偏向于对所有向量求平均值,即假设用户在不同的方面有着相同的偏好,通过简单的线性融合为每个方面分配相同的权重:
(5)
其中P为元路径的集合,Wl和bl表示第l条元路径下的变换矩阵和偏置向量.然而,这种方法计算的结果可能存在很大的误差,因为在实际中不同的用户在不同方面会有着不同的偏好,不同的元路径应当赋予不同的权重.如今注意力机制在图像字幕和机器翻译等各种机器学习任务中已经取得有效成果,它可以通过学习为不同方面的潜在向量分配不同的注意权值,较高的权值表示相应的方面在推荐中提供较多信息.因此尝试使用注意力机制来融合这些潜在特征向量,以此来区分各个方面的重要性.
首先使用两层的神经网络来计算注意力得分:
(6)
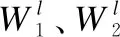
(7)
得到不同方面的权重后,再将多个方面的表示进行加权求和,得到用户i的全局向量:
(8)
按照同样的方法,可以得到项目j的全局向量vj:
(9)
3.4 模型优化
在分别得到了用户i和项目j的全局向量表示后,为了预测用户对项目的交互概率,传统的矩阵分解用内积来评估它们之间的交互:
(10)
其中K表示潜在空间的维度,矩阵分解方法的局限性在于,提升模型的准确性需要扩大维度K,但这不利于模型的泛化能力.因此尝试使用神经网络来模拟用户和项目之间的交互.首先,将表示向量进行合并,以得到交互的统一表示:
xi,j=ui⨁vj
(11)
其中ui和vj表示用户i和项目j对应的全局向量表示,“⨁”表示向量的连接操作.将其输入一个两层的神经网络,以实现对交互的建模:
h=ReLU(W2ReLU(W1·xi,j)+b1)+b2)
(12)
其中,W1和W2为神经网络的权重矩阵,b1和b2为偏置,采用了ReLU激活函数.然后通过一个权值为wr,偏置为br,激活函数为sigmoid的输出层,得到用户对项目最终的预测交互概率:
(13)
在模型优化上,参考了矩阵分解的目标函数,最小化观测评分的正则化平方损失:
(14)

4 实验及结果分析
4.1 实验设置
本文采用了电影评分数据集Movielens-100k和豆瓣电影数据集,通过对原始数据集进行清洗和整理,提取用户和项目的属性信息,处理成统一的异构信息网络作为实验的输入.
其中,Movielens-100k数据集包含U(用户)、M(电影)、A(用户年龄)、T(电影类型)4种类型节点.豆瓣电影数据集包含U(用户)、M(电影)、D(导演)、A(演员),T(电影类型)5种类型的节点.数据集的详细描述如表2和表3所示.在表2中,元路径UMU和MUM路径用来提取用户和物品在交互历史方面的特征;UMTMU和MTM表示用户因为某个电影类型进行选择,提取的是电影类型方面的特征;UMDMU和MDM表示用户根据某个导演而选择电影,提取的是在导演方面的偏好特征;UMAMU和MAM表示用户根据某个演员而选择电影,提取的是在演员方面的偏好特征.
表2 元路径的选择
Table 2 Selected meta-paths

DatasetsMeta-pathsMovielensUMU(用户-电影-用户),UMTMU(用户-电影-类型-用户),MUM(电影-用户-电影),MTM(电影-类型-电影),豆瓣 UMU(用户-电影-用户),UMDMU(用户-电影-导演-电影-用户),UMAMU(用户-电影-演员-电影-用户),UMTMU(用户-电影-类型-电影-用户),MAM(用户-演员-用户),MUM(电影-用户-电影),MDM(电影-导演-电影),MTM(电影-类型-电影)
表3 数据集的具体信息
Table 3 Specific information of datasets

Datasets关系(A-B)ABA-BMovielens用户-电影9431682100000电影-类型1682182861用户-电影13367126771068278用户-用户244022944085豆瓣 电影-类型126783827668电影-导演10179244911276电影-演员11718631133587
实验结果采用平均绝对偏差(MeanAbsoluteError,MAE)和均方误差(RootMeanSquaredError,RMSE)两个推荐常用评估指标,计算公式为:
(15)
(16)
对于本文的模型,将嵌入维度设置为128,窗口大小设置为5,随机游走路径长度为10,学习率为0.001,实验选取80%的数据作为训练集,20%作为测试集.
4.2 实验结果及分析
本文采用以下方法比较提出的模型:
1)basedMF:经典的矩阵分解算法,将用户项目交互矩阵分解为两个低维的用户矩阵和项目矩阵,然后利用分解后的矩阵进行进一步的预测.
2)SVD:奇异值分解算法,不同于经典的矩阵分解算法,其将交互矩阵分解为将矩阵分解为奇异矩阵和奇异值.
3)UserKNN:最近邻协同过滤算法,基本思想是根据相似度找出目标用户的最近邻居集,然后用邻居用户评分的加权组合来为目标用户作推荐.
4)PMF:经典的概率矩阵分解模型,假设用户和项目的特征矩阵均服从高斯分布.
5)HeteMF:是一种基于元路径的推荐算法,它利用基于元路径的计算出在HIN上的实体相似性,再结合矩阵分解实现推荐.
6)HeRec:是一种基于元路径随机游走学习向量表示的方法,利用一组融合函数来将多条元路径连接,最后结合矩阵分解实现的推荐.
7)MLFNNR:融合多方面潜在特征和神经网络的推荐模型,利用元路径和表示学习方法提取并学习用户和项目的多方面潜在特征向量,再结合注意力机制和神经网络实现推荐.
在对比实验中,用到HIN的方法需要指定使用的元路径,在对元路径的选择上进行了一些过滤,考虑到算法复杂度以及噪声问题,排除了过长的路径,仅保留步骤数不超过4的路径.
表4 实验结果对比
Table 4 Comparison of experimental results
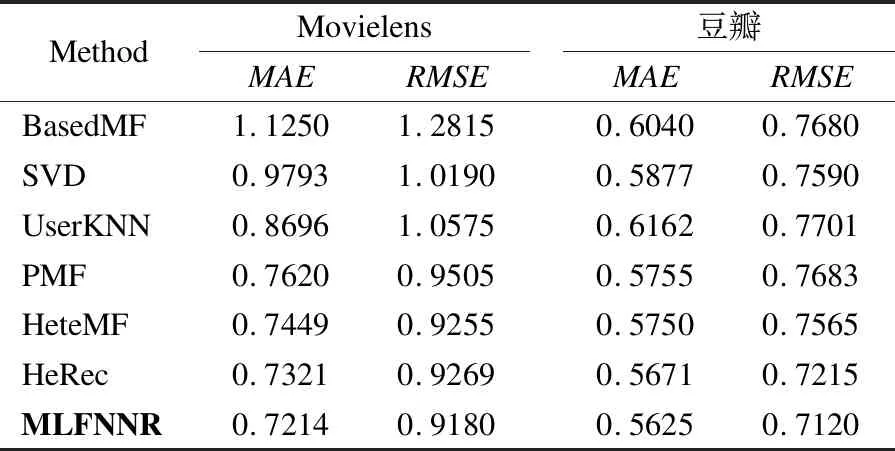
MethodMovielensMAERMSE豆瓣MAERMSEBasedMF1.12501.28150.60400.7680SVD0.97931.01900.58770.7590UserKNN0.86961.05750.61620.7701PMF0.76200.95050.57550.7683HeteMF0.74490.92550.57500.7565HeRec0.73210.92690.56710.7215MLFNNR0.72140.91800.56250.7120
表4展示了在两个数据集上各种算法的MAE值和RMSE值,可以看出本文采用的方法在两个数据集上皆取得了最佳性能,证明了该模型的有效性.其中,基于HIN的方法(HeteMF,MLFNNR,HeRec)明显要优于其他几种方法,证明了异构信息网络的有效性.HeRec同样是基于元路径随机游走的算法,但是其局限性在于使用的融合函数有一定的局限性,而且最终结合矩阵分解内积的形式实现推荐.而本文的方法优于其他基于HIN的方法的原因是采用了更有原则的方法利用HIN来改进推荐系统,提供了更好的信息提取,以及利用了神经网络来代替了传统矩阵分解中的内积,从数据中自动学习任意函数.

图3 训练比率对实验结果的影响Fig.3 Performance comparison of different training ratio on Movielens-100k
图3展示了在实验中,分别选取20%、40%、60%、80%、90%的数据作为训练集,剩余作为测试集时取得的实验结果,可以看出,选取80%的数据集时结果性能最佳.由于数据的稀疏性,当选取更多的数据来训练模型时,会取得更精确的结果.然而,选取到80%时,实验结果已经足够好,继续扩大训练集对性能的提升影响并不大.
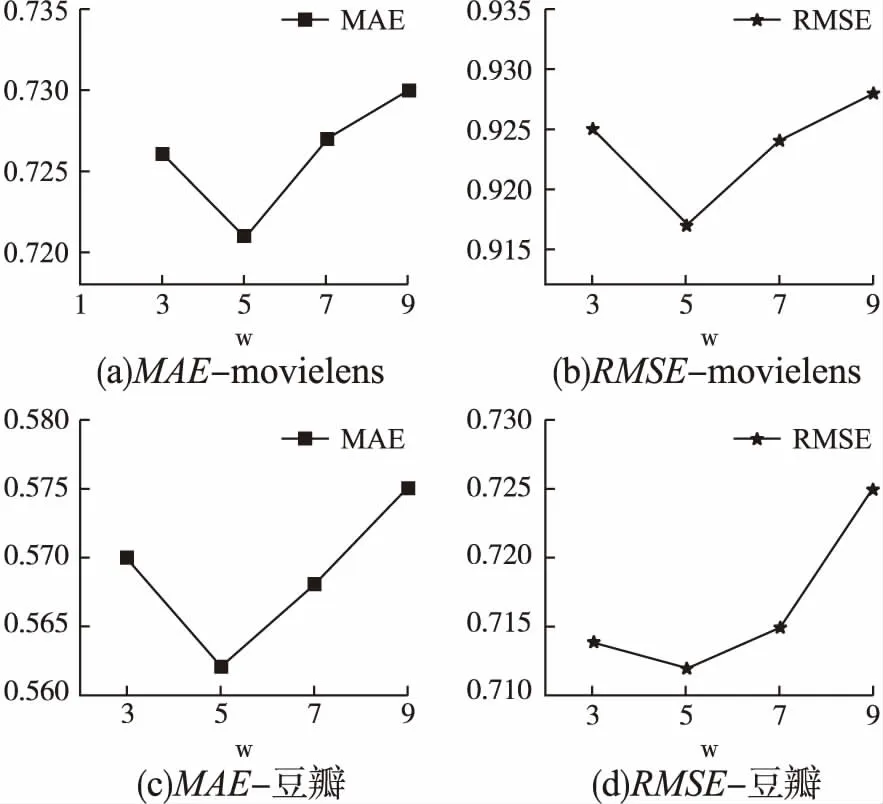
图4 窗口w大小对实验结果的影响Fig.4 Influence of the size of window
图4展示了在基于元路径的随机游走过程中,实验通过把窗口分别设置为3、5、7、9来测试滑动窗口w的大小对实验结果的影响.从图中可以看出,在w=5时取得了最好的效果,这也说明了并不是窗口越大就一定越好,因为窗口过大可能会导致在一些关系不紧密的节点之间建立边.
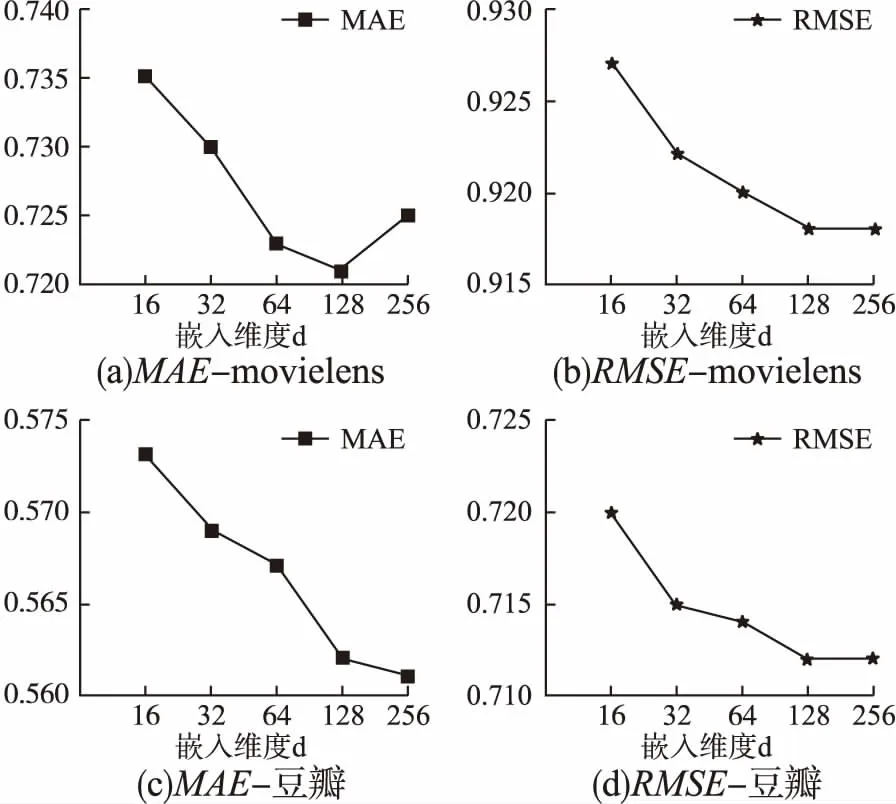
图5 嵌入维度d的大小对实验结果的影响Fig.5 Influence of the size of embedding dimension
为了探索节点嵌入维度d的大小对模型的影响,实验中分别把嵌入维度d分别设置为16、32、64、128、256.如图5所示,对于movielens数据集,增加维度达到128时取得了最好的实验结果,对于豆瓣数据集,维度为128时和256时性能差距不大.因此两个数据集都选用128作为嵌入维度,维度过大不一定会继续提升模型性能,相反,还可能会增加模型的复杂度.
为了验证多方面潜在特征对实验结果的影响,实验中对两个数据集分别测试了在仅基于单一方面特征下的实验结果.如UMU-MUM表示仅根据用户与项目的交互历史这一方面,UMTMU-MTM表示仅根据电影的类型这一方面,UMDMU-MDM表示仅根据电影导演这一方面,UMAMU-MAM表示仅基于电影演员这一方面.得到的实验结果如图6所示,可 以看出基于交互历史这一方面的影响力最大,因为交互历史中通常包含了推荐系统中最重要的信息.在同时加入3种元路径时,实验效果最好,这也说明了加入多方面潜在特征的必要性.同时,在多方面的向量表示融合这一步骤中,加入了使用线性融合函数替代注意力机制进行的对比试验“Average”,而“Average”的结果要差于MLFNNR,这也说明了注意力机制的有效性.

图6 仅基于单一方面的实验结果Fig.6 Results based on single aspect
5 结束语
由于推荐系统现有的研究大都是基于用户和项目的交互行为这一单一方面实现,考虑多方面的特征也许能有效地提升推荐性能.因此,本文提出了一种融合多方面潜在特征和神经网络的推荐模型,有效利用HIN中的属性信息来建模多方面的信息,从而提升推荐结果的准确性.通过设计好的一组包含不同语义的元路径,使用基于元路径随机游走以及异构skip-gram模型学习到用户和项目的多方面的潜在特征向量,再通过注意力机制来进行融合,最终结合神经网络实现评分预测.最后通过在两个经典数据集上进行的实验以及补充的消融实验,验证了模型的有效性,也证明了提取用户和项目多方面的特征在推荐系统中的必要性.
