基于Hadoop生态圈的选煤数据中台设计
2022-01-19赵鑫王然风付翔
赵鑫, 王然风, 付翔
(太原理工大学 矿业工程学院, 山西 太原 030024)
0 引言
目前智能化煤矿建设已成为国家战略[1],在智能化选煤厂建设过程中,主要关注设备及其控制的智能化分析,而数据智能化是选煤厂智能化的有机组成部分,对实现选煤数据精细化管理具有重要意义[2-5]。
在物联网、大数据、云计算、人工智能为核心的新一代信息技术支撑下,许多学者对选煤数据智能化进行了研究。匡亚莉[6]针对智能化选煤厂建设,提出选煤大数据系统研究的目标是全面的数据融合与集成。张磊[7]针对选煤厂数据共享实时性差和信息传输准确性低等问题,提出利用PLC二次回路技术提高现场设备运行数据采集的精确度,并通过对系统集成接口进行深度开发,建立了全面的信息管理系统。高晓茜等[8]为提高选煤厂调度员数据记录效率,设计了基于B/S架构的信息化调度管理系统,实现了选煤厂生产数据自动记录、集成和共享。孙小路等[9]研究了选煤实时数据、关系数据库中离散数据的存储规则,并通过Web API (Application Programming Interface, 应用程序接口)实现数据共享。选煤厂信息管理系统的应用,提高了选煤厂生产数据的管理效率,但不同系统采用的接口不规范,导致数据重复采集,使得信息严重冗余,且各系统相互独立,对多源异构数据处理能力弱,数据融合缺乏大数据技术支撑。
针对上述问题,本文提出了基于Hadoop生态圈的选煤数据中台设计方案:通过MDM(Master Data Management,主数据管理)系统实现主数据标准规范化;通过ESB(Enterprise Service Bus,企业服务总线)实现系统集成接口规范化;设计归一化、相关系数矩阵和噪声异常点检测程序实现数据处理;结合D-S(Dempster-Shafer )证据理论与Hadoop生态圈技术设计多源异构数据融合子系统,实现数据融合共享;运用Highcharts数据可视化组件实现数据实时交互式的可视化展示。
1 选煤数据中台架构
选煤数据中台由数据感知层、基础设施层、中台实现层和业务服务层组成,其总体架构如图1所示。
(1) 数据感知层负责数据的自动采集与感知。通过PLC、传感器等智能终端,采用Modbus、OPC协议自动感知洗选、人员定位等数据;使用WebService、IEC104协议实现SCADA(Supervisory Control and Data Acquisition,数据采集与监视控制)、ERP(Enterprise Resource Planning,企业资源计划)、OA(Office Automation,办公自动化)等系统的关系型数据库中计划、生产、能源、环保、安全、设备等管控数据的自动采集;通过录像机、视频环网使用RTSP(Real Time Streaming Protocol,实时流传输协议)接入监控视频数据。
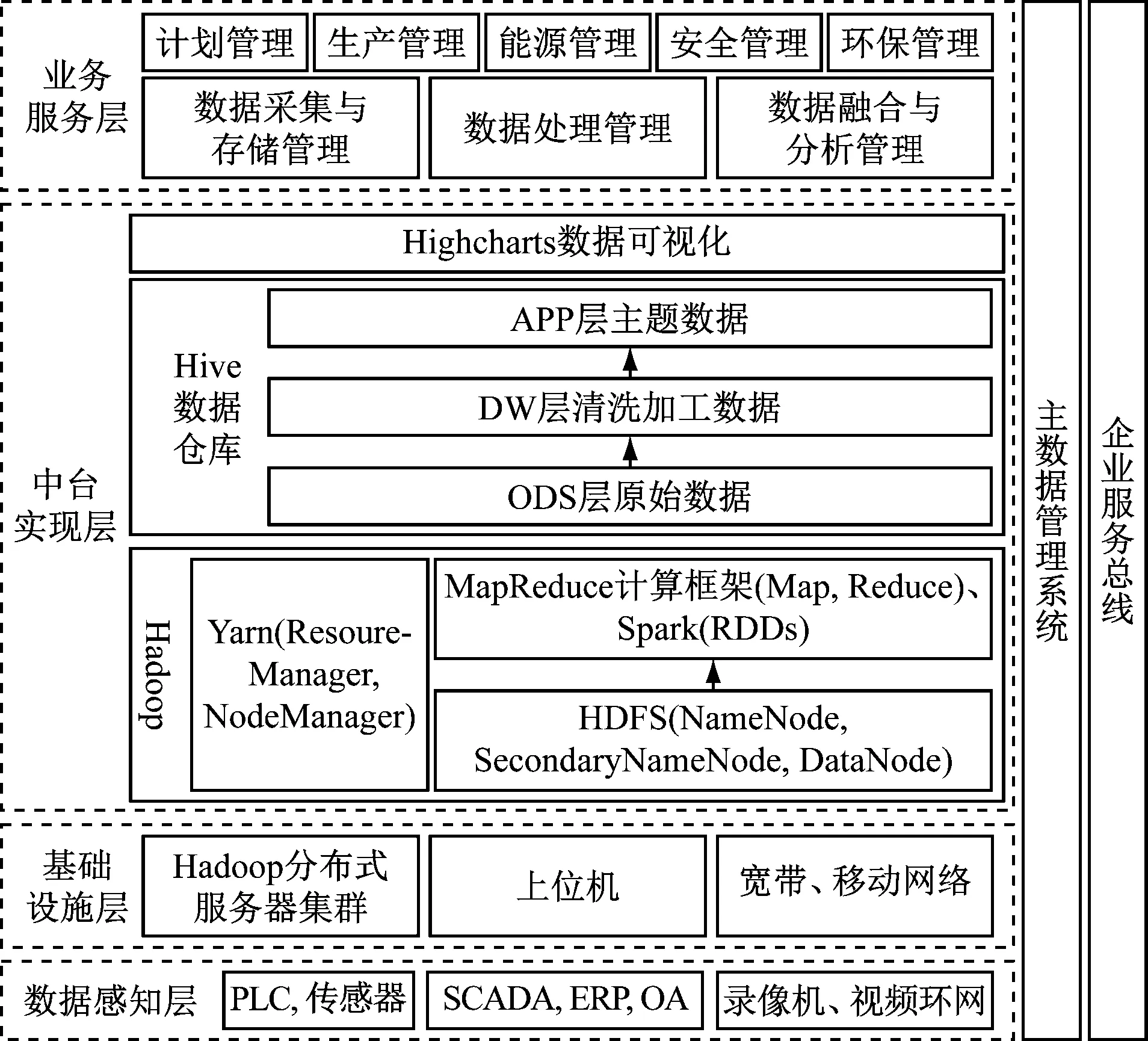
图1 选煤数据中台总体架构Fig.1 Overall structure of coal preparation data center
(2) 基础设施层由选煤厂互联网数据中心部署分配的Hadoop分布式服务器[10-11]集群、上位机及宽带、移动网络组成。Hadoop分布式服务器集群通过分布式架构解决了单台服务器多线程并行计算耗时多,大规模数据存储量大、网络带宽等问题。通过部署服务器集群[12-13]将大数据技术的相关模块部署在不同服务器并形成备份,以解决高并发访问量情况下的负载不均衡问题,避免了因某一台服务器单点故障而影响整个数据中台运行。Hadoop分布式服务器集群由5台服务器组成,每台服务器彼此独立,相互之间仅通过消息队列通信。
(3) 中台实现层由Hadoop框架、Hive数据仓库和 Highcharts数据可视化组件组成。
Hadoop框架包括HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、Yarn(Yet Another Resource Negotiator,另一种资源协调者)、MapReduce计算框架和Spark 4个组件。HDFS组件中NameNode作为主节点,负责获取数据位置信息;SecondaryNameNode作为辅助节点,管理元数据信息;DataNode作为从节点,负责读写、存储相关数据。Yarn组件中ResourceManager执行用户的计算请求,并负责合理分配资源;NodeManager负责管理Hadoop集群中的单个计算节点。MapReduce计算框架在Map阶段将大规模的计算任务拆解成多个子任务,在Reduce阶段将子任务计算结果合并为最终的计算结果。该组件需要处理的原始数据及计算结果通过HDFS存储,计算的同时需要Yarn并行提供资源调度。Spark通过RDDs(Resilient Distributed Datasets,弹性分布式数据集)执行引擎将中间数据在服务器内存中迭代存储,克服了MapReduce计算框架在磁盘中运算的缺陷。
Hive数据仓库面向特定主题,关注联机分析处理与管理决策。Hive数据仓库包括ODS(Operational Data Store,数据运营)层、DW(Data Warehouse,数据仓库)层、APP(Application,数据应用)层。ODS层实现与其他数据中台的关系数据库数据表、文档、图片、点击流日志的同步;DW层对数据进行清洗加工、分析与挖掘,并形成特定业务主题数据存入APP层;APP层提供针对特定场景的个性化业务数据,供后续数据分析与挖掘使用。
Highcharts数据可视化组件用于实现数据交互式的可视化展示。
(4) 业务服务层依据选煤厂及煤炭集团业务需求,将数据中台功能进行模块化封装,根据用户操作权限展示与操作不同功能页面。
2 选煤数据中台关键技术
面对TB级别、彼此孤立存在的海量多源异构数据,数据中台通过Hadoop生态圈技术实现数据感知、集成、处理、融合、分析、可视化展示的全生命周期管理。
2.1 多源异构数据集成技术
(1) MDM系统。数据中台的主数据包括通用基础类(地区、民族、资金单位)数据、单位类(内部单位、外部单位)数据和产品类(原煤、中煤、精煤、矸石)数据等。针对主数据分类、编码不一致,关键信息录入空值、不规范等问题,数据中台设计MDM系统,根据DB14/T 2245—2020《煤炭洗选企业标准化管理规范》,明确定义增量数据中间表的相关字段、数据类型与映射关系。以产品类主数据中间表字段为例,通过MDM系统实现各生产部门按需选择主数据及相应的属性字段,为ESB提供集成的主数据字段映射关系,相关信息见表1。
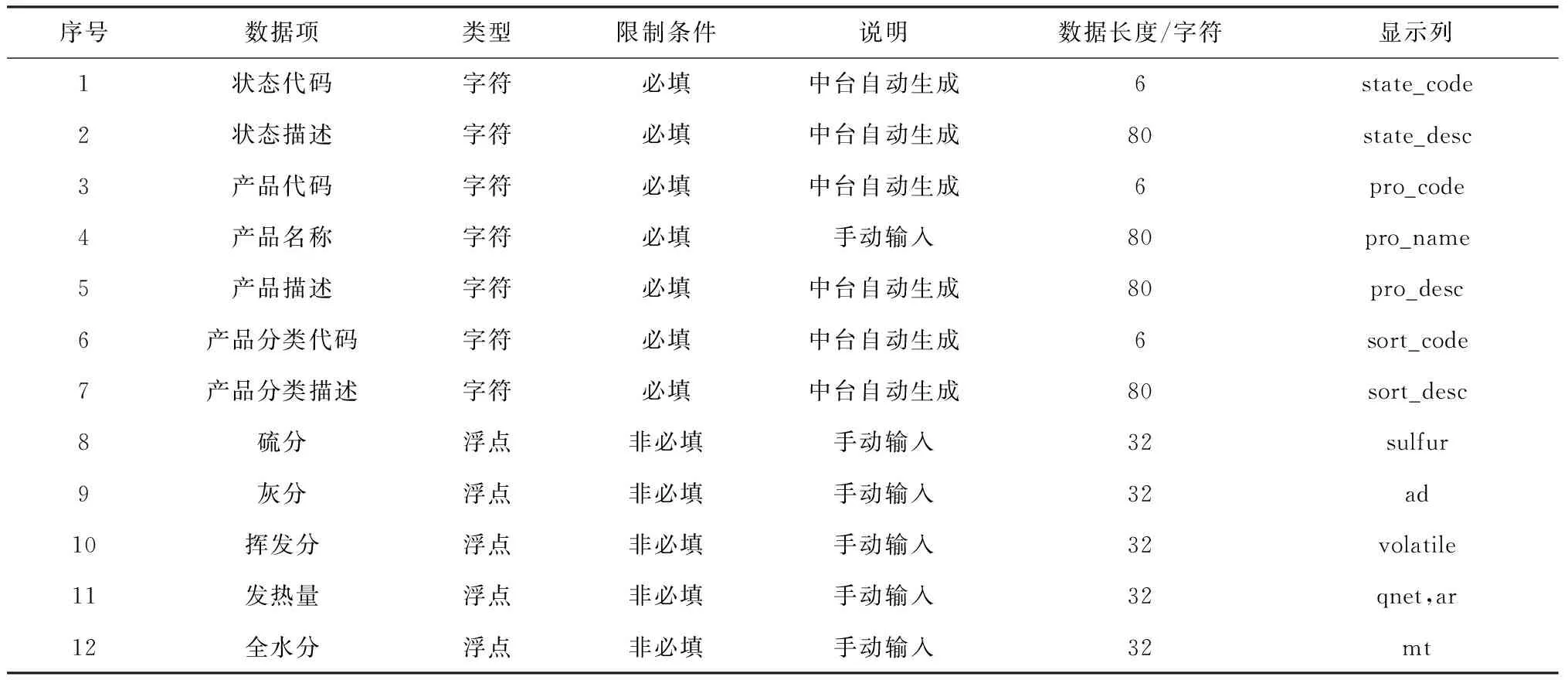
表1 主数据煤炭类中间表字段及相关信息Table 1 Master data coal intermediate table fields and related information
(2) ESB。针对现有数据处理软件采用不同的编程语言、数据库及系统集成接口不规范等问题,数据中台采用SOA(Service Oriented Architecture,面向服务)架构的ESB模式实现系统集成接口规范化。SOA架构将不同的应用功能单元视为一个服务,对服务定义标准化的接口与契约,实现松耦合的总线型拓扑结构。
ESB模式按照数据流的传输方向,将访问服务分为生产者(数据提供方)与消费者(数据接收方),如图2所示。生产者在数据发生变化时调用ESB接口传入Json文件,并发起流程;ESB调用数据接收接口,使用单条同步的方式进行状态同步;ESB通过日志回传接口向生产者反馈消费者的状态同步结果。当未来新上线的系统需要通过ESB与数据中台集成时,统一注册并拓展Rest服务接口,使用标准WebService协议实现消息通信、服务检测等功能。

图2 ESB架构Fig.2 ESB architecture
2.2 多源异构数据处理技术
针对数据采集、集成过程中数据原始量纲不统一,多随机变量间相关关系无法判断,数据集包含不一致、不完整的“脏数据”等问题,数据中台借助Hadoop生态圈的ETL(Extract-Transform-Load,数据仓库技术),研究并设计归一化程序、相关系数矩阵程序和噪声异常点检测程序进行数据处理,为后续数据融合与分析提供数据支撑。
(1) 归一化(去量纲)。将有量纲的数据集通过比例缩放转换为无单位的小范围标量。通过线性函数离差归一化方法(式(1)),将数据集映射到[0,1]区间。
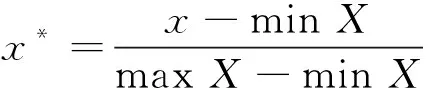
(1)
式中:x*为归一化数据;x为原始数据;X为原始数据集。
(2) 相关系数矩阵。根据MapReduce计算框架的键值对思想,利用Pearson公式对数据集进行映射与规约,计算每个特征值之间的相关系数。MapReduce计算框架在Map阶段通过多线程并行循环读取行数据与列数据并进行分布式计算,在Reduce阶段将分组算出的系数汇总并输出。以商品煤质量鉴定单中煤泥化验结果为例,将全水分、灰分和发热量3个字段作为数据处理对象,选取500组数据作为数据集,见表2。
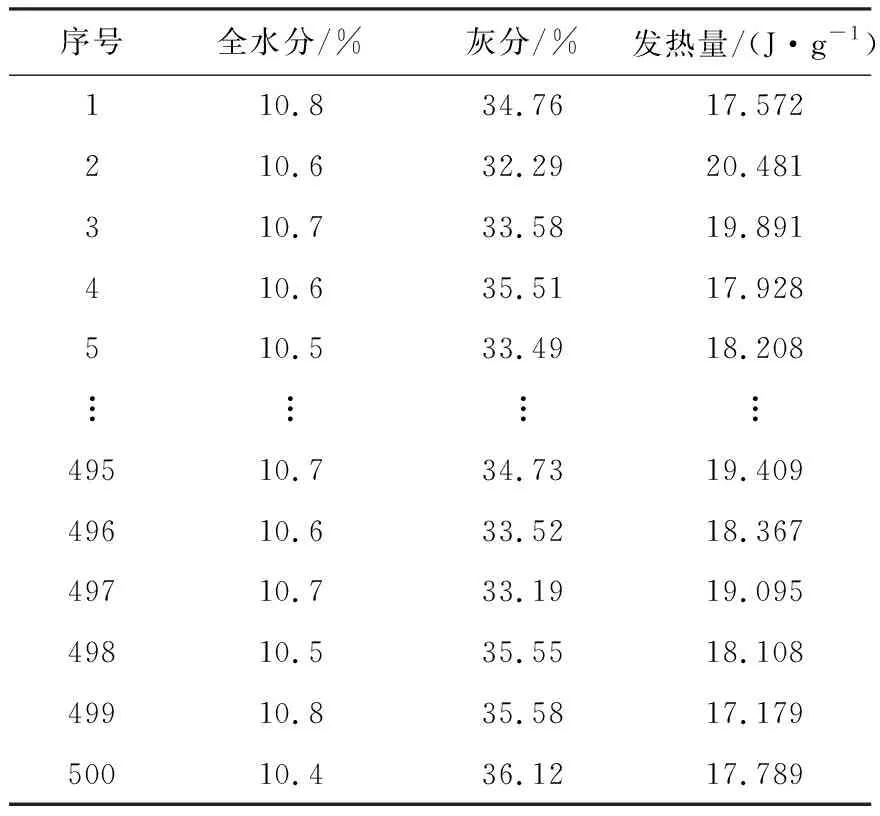
表2 商品煤质量鉴定单Table 2 Commercial coal quality appraisal sheet
采用Pearson公式对数据集进行运算,运算结果的特征关系系数值域为[-1,1],通过Highcharts数据可视化组件中的矩阵表示随机变量间的相关性关系,如图3所示。
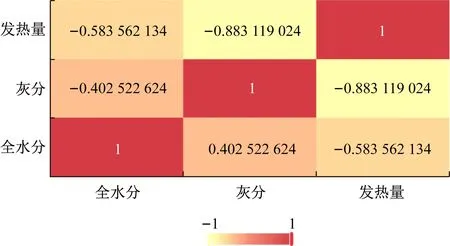
图3 相关系数矩阵Fig.3 Correlation coefficient matrix
由Pearson公式定义可知,相关系数>0表示二者之间呈正相关,相关系数<0表示二者之间呈负相关。由图3可知,发热量与全水分的相关系数为-0.583 562 134,绝对值位于0.40~0.69之间,表示二者之间呈中度负相关;发热量与灰分的相关系数为-0.883 119 024,绝对值位于0.70~0.89之间,表示二者之间呈高度负相关。通过相关系数矩阵程序处理,为下一步数据挖掘发热量与全水分、灰分的线性关系提供支持。
(3) 噪声异常点检测。数据中台引入Spark框架下的DataFrame对象,借助四分位距原理检测一组测试数据中是否存在噪声异常数据。DataFrame对象将Hive数据仓库、Json文件、关系型数据库的数据表作为数据源,调用内置approxQuantile()方法传入列名及计算分位点等参数,并求出每个字段的边界;调用select()、filter()方法循环遍历数据集,最终筛选出噪声异常数据。
2.3 多源异构数据融合技术
针对选煤厂海量数据融合的需求,结合经典D-S证据理论[14-15]、Hadoop和Hive数据仓库,设计了多源异构数据融合子系统。D-S证据理论运用Dempster合成准则和信度函数描述按时序获得的要素间相互关系。数据融合流程如图4所示,其中FN(·),BN(·),PN(·)分别为MapReduce将大规模计算任务拆分成N个子任务的正交和组合函数、信任函数、似然函数。
(1) 调用API(Application Programming Interface,应用程序接口)中的showTables()方法判断数据源表是否存在,若存在则调用selectTable()方法选择目标数据源表、调用map()方法选择表中的具体字段,否则转至数据集成与预处理。
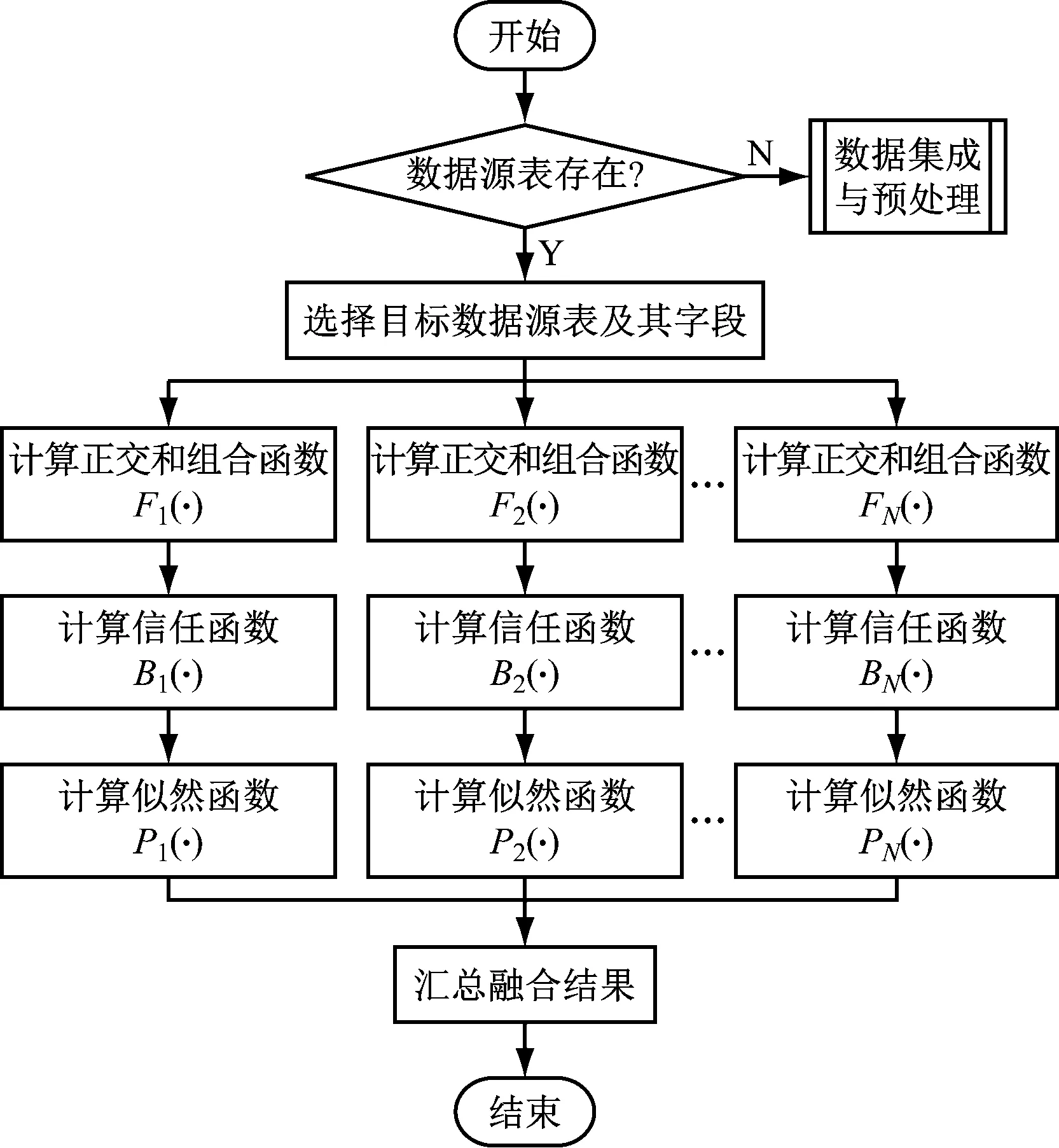
图4 数据融合流程Fig.4 Data fusion process
(2) 主服务器(Master)根据数据表字段与节点个数,调用splite()方法将数据集平均分割给各从服务器(Slave)进行融合计算。
(3) 计算基本概率分配函数。设总样本空间为Ω,基本概率分配函数f(·)满足2个约束条件:
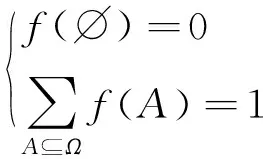
(2)
式中:f(∅)为空命题∅为真的概率;A为2Ω中的1个或多个命题;f(A)为命题A为真的概率。
(4) 计算正交和组合函数F(·)。设f1(·),f2(·)为2个不同的基本概率分配函数,正交和组合函数F=f1(·)⊕f2(·)符合F(∅)=0,则
(3)
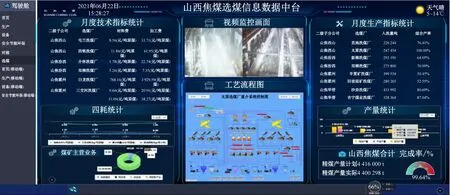
(4)
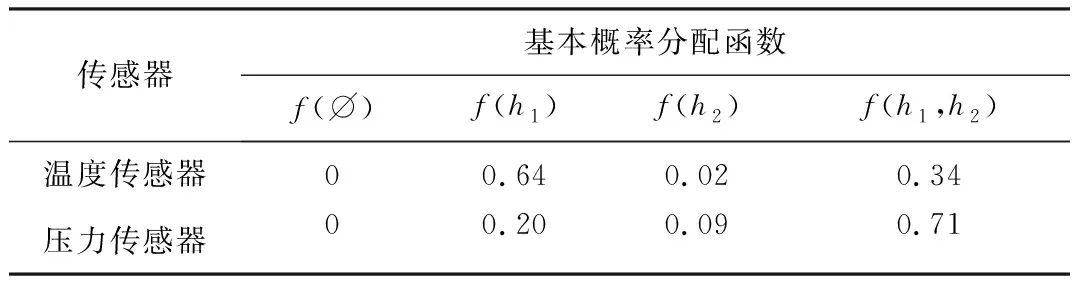
式中:C为2Ω中的命题;k为证据冲突因子,当k=1时,表示命题A,C完全冲突;0 (5) 计算信任函数B(·)。B(A)表示对命题A为真的信任度。 (5) (6) 计算似然函数P(·)。P(A)表示对命题A为非假的信任度。 P(A)=1-B(A) (6) (7) 主服务器重写reduce()方法,并将从服务器的融合结果汇总并写入HDFS中。 Highcharts 是基于Web应用程序、用JavaScript语言编写的可视化交互图表库。首先通过初始化函数 Highcharts.chart ()创建图表,然后通过构造函数绑定图表对应的全局样式、绘图区、图表事件等配置项,最后通过JavaScript读取纯文本数据文件或通过Ajax 请求数据接口读取与处理数据。利用Highcharts数据可视化组件的jquery.min.js,highcharts.js等静态资源库,将厂区地图、视频监控、工艺流程、生产统计报表等数据通过丰富的可视化图表(包括仪表盘、速度仪、散点图、漏斗图等)展现给管理决策层,便于其观看、分析与决策。 该数据中台已在山西焦煤集团有限责任公司洗选加工部、二级子公司和分属选煤厂试运行,实现了数据定义与系统集成、数据处理、数据融合与数据可视化展示4大数据管理功能。选煤中台主要功能模块如图5所示。 图5 选煤数据中台功能模块Fig.5 Function module of coal preparation data center platform (1) 数据定义与系统集成管理。该管理模块构建了MDM和ESB 2大系统。MDM系统通过汇总各业务部门需用的主数据及相应的属性字段,编制了包括单位类、产品类和通用基础类等主数据目录,便于提供集成的主数据字段映射关系。ESB系统通过拓展Rest服务接口,成功将已上线的山西焦煤集团有限责任公司主数据管理系统、统一认证管理平台、协同OA系统、煤炭销售管理系统等集成,由ESB系统统一进行服务监控和消息转发,满足了集团异构系统互通互联的集成需求。 (2) 数据处理管理。提供了归一化、相关系数矩阵和噪声异常点检测程序,实现了计划(数/质量计划、生产计划、采购计划等)、生产 (工艺流程、生产指标等)、能源 (能源消耗分析、选煤节能对标等)、安全 (双预控、瓦斯、消防等)、环保 (“三废”管理等) 等业务数据的清洗与处理。 (3) 数据融合管理。通过多源异构数据融合子系统,选煤厂成功实现了多故障类型下压滤机等设备的故障原因分析,避免了只通过单一机理和传感器数据无法准确判断复杂工况下设备故障的问题。压滤机是最常用的选煤厂煤泥脱水关键设备,在压滤生产系统中具有重要作用。压滤机发生故障时,受复杂运行环境的影响,如仅通过单一传感器监测数据对常见故障进行原因分析,必然忽视了多种故障因素共同作用的影响。利用多源异构数据融合子系统定义样本空间h1(压滤机拉钩传动链轴承温度过高)、h2(压滤机拉钩传动链轴承异响)2种异常状态。将2种状态下轴承处温度、压力数据集通过噪声异常点检测程序过滤掉异常的“脏数据”后,进行归一化处理,并根据专家知识库给出样本空间的基本概率分配函数,见表3。 表3 样本空间基本概率分配函数Table 3 Basic probability assignment functions of sample space 将温度数据集与压力数据集对应的基本概率分配函数进行融合,由式(3)、式(4)得出k=0.946 4,F(h1)=0.689,F(h2)=0.049。F(h1)最大,表明压滤机拉钩传动链轴承温度过高的可能性大。由式(5)得出B(h1)=0.689,B(h2)=0.049,由式(6)算出P(h1)=0.951,P(h2)=0.311,B(h1)>B(h2),P(h1)>P(h2),根据当前样本集推断出压滤机处于拉钩传动链轴承温度过高状态的可能性最大。 (4) 数据可视化管理。通过Highcharts数据可视化组件,将选煤关键指标、运营情况等数据通过速度仪表盘、雷达球等形象化图表展示给管理决策层。如图6所示,可视化界面左侧实时滚动刷新各选煤厂月度技术指标、四耗指标和煤炭主营业务等关键数据;中间显示生产车间的视频监控画面和调度室的选煤工艺流程图;右侧显示月度生产指标、产量与完成率等数据。 图6 Highcharts数据可视化Fig.6 Highcharts data visualization (1) 基于选煤企业数据管理的现状、存在的问题与需求,运用Hadoop生态圈大数据技术,提出了基于Hadoop生态圈的选煤数据中台总体架构,研究了数据定义与集成、数据处理、数据融合与数据可视化展示等关键技术。 (2) 应用结果表明,基于Hadoop生态圈的选煤数据中台可实现主数据定义标准与系统集成接口规范化,提高了选煤数据处理能力,实现了多源异构选煤数据的融合共享、数据实时交互式的可视化展示。
2.4 多源异构数据可视化技术
3 选煤数据中台应用
4 结论
