面向流式数据的边缘训练研究
2022-01-19杨加圣尹雯姣彭丽丽刘小光
杨加圣 尹雯姣 彭丽丽 刘小光
江苏电力信息技术有限公司
0 引言
用户在日常使用各类移动终端的过程中会产生大量数据。各大互联网公司通过诸如聚类、分类、回归等机器学习相关技术分析这些数据,用于词条竞价、搜索排序,以及各类内容服务优化。在此过程中,往往需先汇聚数据,再进行分析。将原始数据经由开放网络传输汇聚,容易泄露用户隐私。联邦学习训练,通过各节点的本地训练并汇聚中间结果的方式,避免直接传输原始数据,并能达到和集中式训练同等的训练效果。
现有工作主要从学习模型的收敛分析和训练的配置调整两个角度对联邦学习进行了训练优化:一部分工作研究联邦学习的理论模型,如模型汇聚精度随全局迭代轮数增长之间的联系等;另一部分工作将联邦学习等作为服务部署到网络边缘,以满足边缘用户的训练。
如果等到所有用户数据就绪之后,再进行联邦学习训练,不仅会浪费数据就绪的整个过程,产生不必要的等待,而且会在数据就绪之后的短时间内持续在边缘设备上产生高峰训练负载,影响边缘设备的正常使用。因此,亟需研究利用流式数据的到达特点,不断在流式数据到达的过程中在边缘设备上进行负载的摊销,不断进行小批量数据计算,避免给边缘设备带来过高的负载,以达到和数据就绪后不断反复迭代产生类似的训练效果。
本文描述了一种边缘设备流式数据的训练方法,主要包含边缘设备上的小批量数据处理以及边缘设备间的联邦学习交互,以达到在数据不断到达的过程中就不断进行模型训练,避免数据就绪后的高峰负载,也避免了边缘设备因训练拥塞对其他业务产生的影响。具体来说,本文首先为不断到达的数据维护数据权重,并利用到达数据的采样进行数据权重的更新,再辅以不断的联邦学习交互,以期在数据就绪时产生的训练模型已有不错的效果。
1 问题分析与建模
(1)系统描述。面向流式数据的边缘训练结构如图1所示。本文提及的面向流式数据的边缘训练架构包含两个部分。第一部分为边缘设备上的流式数据处理;第二个部分为边缘设备与边缘服务器构成联邦学习训练。整个联邦学习包含多个大的时隙,在每一次时隙结束的时候,边缘服务器都会从各边缘设备上收集模型进行汇聚。在每一个时隙之内,各个边缘设备利用自身设备到达的流式数据进行模型训练。具体的过程是在每一个时隙开始的时候,各边缘设备从边缘服务器出获取最新的模型;在时隙内,利用该模型和流式数据进行模型的更新计算;并在一个时隙结束的时候,将局部更新的最新模型上传至边缘服务器。在每一个边缘设备上,有一个单独的线程负载在每个时隙的开始与结束和边缘服务器进行交互,并在每一个时隙内部不断处理到达的流式数据。由于数据到达动态变化,在没有数据的时候,该线程就会挂起,等到新数据到来的时候,就会触发时隙内的模型更新。
(2)问题建模。对于一台边缘设备i,建模其时序到达的数据流为{…,xit1,…,xitM,…},其中xitj表示在时隙t里的时间戳j,设备i上到达的流式数据规模。在这里整个时间轴被分为{1,…,T}共T个时隙,且每个时隙都有M个均匀间隔的时间戳。在每一个时隙结束的时候,每台边缘设备会产生一个中间模型wit。该模型是一个多维的向量,描述了特定模型结构下的模型参数。在每个时隙结束的时候,边缘服务器收集所有边缘设备上的模型{wit}将其聚合成为时隙t的全局模型并将该模型下发至所有设备,是下一个时隙训练的基础,其中N为设备数。具体计算为:

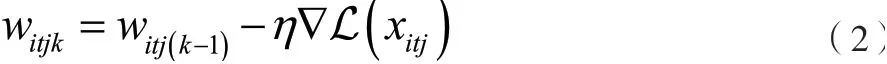
其 中k的 范 围 是[1,yitj],witj1=wit(j-1)yit(j-1),wit11=表示梯度计算;L(xitj)表示利用xitj流式数据样本所构成的损失函数。该过程不断迭代,直到时隙结束。
实际上,L(xitj)无需包含所有xitj个流式数据样本。L(xitj)可以用特定的方式在xitj个流式数据样本中进行采样。例如,每两个样本选取一个样本放入L所构成的函数内等。这样的好处是,L可以不用包含入所有的样本,继而大幅降低边缘设备上的训练计算负担。其极端的两个情况分别是:所有样本包含入函数及仅有一个随机采样的样本包含入函数。一般来说,L中包含的样本数量越多,边缘设备训练计算产生的模型效果就越可信,结果也越有可能更好。然而,若一个时隙内xit1,…,xitM这些数据都是源自同一个数据分布的话,适当降低L中的样本规模,反而能够在大致保证模型训练效果的同时,大幅度降低训练负载。
每一个时隙内的局部轮数和模型的训练效果具有关联。若一个时隙内的局部轮数集合为{yit1,…,yitM},那么对于一个时隙而言,边缘设备产生的模型wit与其最优模型之间的差距可以表示为wit-w*it≤χ(yit1,…,yitM,xit1,…,xitM)。也就是,随着数据规模的上升和局部迭代轮数的上升,wit与其最优模型w*it的差距会不断减小。不仅如此,在将每个时隙的收敛推广到整个时间轴就可以得到面向整个训练的模型效果,也就是

2 边缘训练算法
在上述建模的基础上,本文调整每个时隙t每个设备i上的局部迭代轮数。这是由于过多的局部迭代轮数虽然能够让训练产生的模型快速收敛,但会引入大量的计算开销;同时过少的局部迭代轮数反而无法使得模型收敛。因此本文设计的调整局部迭代轮数的方法为:
(1)每一个时隙t时间戳j的开始,收集上一个时间戳产生的训练效果。也就是,上一个时间戳j-1的局部训练轮数为yit(j-1);边缘设备产生的模型为wit(j-1);上一时隙全局模型为以及边缘设备i因计算产生的最大持续计算负载为
(2)通过收集训练效果,计算边缘设备i在时隙t时间戳j上需要更新的局部轮数偏差Δijt。该训练偏差与收集所得训练效果构成关系为
(3)利用局部轮数偏差Δijt进行局部轮数的更新,即
直观来说,上述3个步骤的执行遵循动态调整、逐步优化的原则。也就是,该动态调整过程不断依照上一个时间戳的效果进行局部轮数的修正。当上一个时间戳的局部轮数过大时,如边缘设备负载过高或是局部模型与全局模型之间的偏
图1 面向流式数据的边缘训练架构差较为稳定时,即可减少当前时间戳的局部轮数。反之,若上一时间戳的负载相对较小且局部模型与全局模型之间的偏差仍然震荡还未收敛,当前时间戳的局部轮数可以适当放大。函数将这些因素统筹考虑在内。
3 实验结果与分析
本文就所提出的面向流式数据的边缘训练进行了实验验证。图2展示了训练损失。无论是数据就绪后采用蓝色传统的批量梯度下降,还是利用本文所提出的面向流式数据的红色的训练,都能够在同一个数据集上达到相近的训练损失。图3展示了训练过程中的资源开销。相比于蓝色的传统批量梯度下降,也就是必须等到所有数据就绪后才进行持续一段时间的高负载训练,红色部分是本文所提出的方法,在数据不断到达的过程中就陆续进行训练计算,利用小批量数据进行模型参数的更新。因此,避免了数据就绪后长时间持续的高负载占用;在流式数据到达过程中也不会产生高负载,使得整体训练不会给边缘设备带来更多的影响,也不会给其他业务形成干扰,影响正常设备使用。
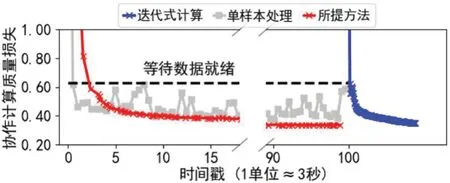
图2 边缘训练的训练损失

图3 边缘训练的资源开销
4 结束语
为了避免在边缘设备上持续产生高训练负载,避免在数据就绪后持续对边缘设备产生影响,也为了充分利用数据就绪过程,本文提出了一种边缘设备流式数据的训练方法,主要包含边缘设备上的小批量数据处理以及边缘设备间的联邦学习交互,以使数据在不断到达的过程中就不断进行模型训练。本文进一步就局部迭代轮数进行了自适应地控制,以平衡边缘设备的负载和整体的训练效果。
