基于相空间重构的卡尔曼滤波短时交通流预测模型
2022-01-19杨紫煜焦朋朋洪玮琪
杨紫煜,焦朋朋,云 旭,洪玮琪
(北京建筑大学 通用航空技术北京实验室, 北京 100044)
短时交通流预测指通过路段检测器收集到的一系列交通流数据,结合检测器误差、路与路之间的联系、交通流动态变化及交通流内在联系等因素,对收集的数据进行预处理后再利用统计学特性进行系统性的分析,或者结合数学方法找到大量数据中隐含的内在规律信息,建立数学模型及改进措施对其进行短时的预测。
近几十年来,随着智能交通系统的发展,短时交通流数据的需求不断增强,国内外学者将各领域的理论应用于短时交通流预测,其中包括时间序列模型及衍生形式[1]、卡尔曼滤波模型[2]、支持向量机模型及衍生形式[3-4]、神经网络预测模型及衍生形式[5-6],其中许多研究为了避免单一预测模型存在复杂不稳定的预测缺陷,而将其组合在一起为组合模型。各类模型在计算时各有利弊:时间序列模型建模简单,易于理解,但模型预测需要大量不间断的历史数据,在交通数据获取困难的情况下无法实施;同样,神经网络预测模型在训练中需要大量的原始数据,训练结果也仅限于此研究路段,当道路或交通改变时不再适用,训练样本的构成情况对神经网络预测模型结果的复杂程度有影响,训练过程容易陷入局部极小点等;支持向量机模型针对小样本问题可以获得最优解,泛化能力强但需要在使用过程中不断调整参数;卡尔曼滤波模型只需考虑上一状态的影响,但由于对状态初始值敏感,随着算法递推容易出现发散的现象。钱伟等[7]提出将卡尔曼滤波理论与相空间重构原理相耦合的方法,预测精度比卡尔曼滤波和相空间重构模型高。LI等[8]提出了一种基于贝叶斯理论的多尺度混沌时间序列预测算法。
混沌系统由于其物理特性在交通流预测领域中有较好的应用[9]。混沌现象的发现,使人们发现复杂系统的本质往往不是随机因素而是非线性动力系统中的混沌因素造成的。目前认为短时交通流预测的周期在不超过15 min时常常表现出不规则的复杂行为,识别这类交通流序列是否为混沌现象是进行交通流预测的前提和关键。
本文提出利用最大Lyapunov指数对交通流进行可预测分析,在此基础上进行相空间重构,将重构后的相点作为卡尔曼滤波方程中的初始状态点,以此建立基于相空间重构的卡尔曼滤波短时交通流预测模型,并通过实例验证模型的性能。
1 交通流相关理论及数据采集预处理
1.1 相空间重构
相空间重构将一维时间序列映射至高维,进而找到系统内部蕴含的变化规律。利用相空间重构弥补卡尔曼滤波的初始值问题,获取更准确的初始值。且相空间重构的关键在于确定延迟时间τ和嵌入维数m。C-C法是求解相空间参数常用的方法,将延迟时间和嵌入维数看作相互关联的参数,由嵌入窗宽τw=(m-1)τ来确定。这种方法计算量小,容易操作,抗噪声能力强[10]。选用C-C法求解的公式为:
S(k)={x(k),x(k+τ),…,x(k+(m-1)τ)}
(1)
式中:x(k)为相空间重构的相点,k=1,2,…,N,N为时间序列长度;S(k)为第k个相点;m为嵌入维数;τ为延迟时间。
为了找到恰当的延迟时间,需将整个时间序列分为t个子序列。首先给定一个时间序列为Xi={x1,x2,…,xN}。首先定义关联积分为:
(2)
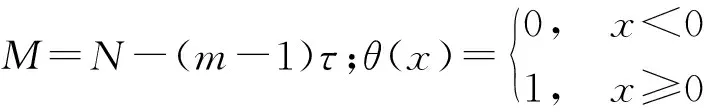
每个子序列的统计量S(m,N,r,t)为:

(3)

当N→∞时,统计量S(m,r,t)为:
(4)
选择最大和最小的两个半径r,定义差量ΔS(m,t)为:
ΔS(m,t)=max{S(m,rj,t)}-min{S(m,rj,t)}
(5)
其中,ΔS(m,t)越小,表示相空间中的点均匀分布越接近,时间序列的相关性也越小。最优的延迟时间τ可取S(m,r,t)~t曲线的第一个零点或第一个局部最小点。

(6)
(7)
(8)
相点个数:
M=N-(m-1)τ
(9)
1.2 卡尔曼滤波理论
卡尔曼滤波是卡尔曼在1960年提出来的。早期将卡尔曼滤波模型用于交通流预测的是OKUTANI和VYTHOULKAS,他们分别在1984年和1993年研究了卡尔曼滤波模型并将其用于交通流预测,前者利用卡尔曼滤波理论创建了交通流量预测模型[11],后者提出基于卡尔曼滤波理论的交通流预测模型[12]。国内研究起步较晚,1999年,杨兆升、朱中将卡尔曼滤波理论用于了交通流预测,为使计算结果更为精准,对模型进行了改进:将交通流原始数据做平滑处理、通过预测交通流量比值代替交通流量原始数据[13]。
离散卡尔曼滤波的时间更新方程和状态更新方程[14]分别为:
X(h)=FX(h-1)+BU(h-1)+GM(h-1)
(10)
Z(h)=HX(h)+V(h)
(11)
式中:h为时间尺度,系统在时刻h的状态为X(h),Z(h)为对应状态的观测信号;F为状态转移矩阵,用以上一时刻推测下一时刻状态;B为控制矩阵,表示控制量U如何作用与当前状态;U为系统的控制量;G为噪声驱动矩阵;M为过程噪声;H为观测矩阵;V(h)为输入的白噪声。
卡尔曼滤波是预测具有随机性变化的交通流的重要方法,已在各智能交通子系统中得到了大量的应用。本文利用了卡尔曼滤波精度较高、鲁棒性较强的优点。但其也存在每次计算前都需要调整权重、计算量大的缺点。
1.3 数据采集预处理
数据采集会导致原始数据出现个别错误,所以在使用这些数据之前要进行数据预处理。通常由于交通传感器硬件故障、噪声干扰和通信故障所引发错误数据的发生,所以必须对错误数据进行剔除,否则这些错误数据会大大降低预测的准确度。错误数据往往与正确数据的偏差非常大,所以先采用阈值法去除明显错误的数据。交通流量的取值范围定义为(0,γmax),γmax=fcCT/60,式中C表示道路的通行能力,可根据城市道路手册进行选取;T为采样的时间间隔;fc取值在1.3~1.5,为修正系数。如果采样数据超过合理范围,可以采用错误数据时间点的相邻时间数据的平均值作为该错误数据时间点的数据。
如果数据在阈值之内,也未必是正确数据,所以还需进行基于多条规则的判断。本文将设立如下的判断规则:
1) 如果雷达检测器收集到的数据平均占有率为0而流量不为0时,应去除该数据。
2) 如果雷达检测器收集到的数据流量为0而平均占有率不为0时,应去除该数据。
2 模型设计与评价指标
2.1 交通流可预测性分析
交通流可预测性是通过判断混沌系统处于确定性、混沌性、纯随机性中的何种状态来决定的。交通流可预测性分析流程如图1所示。

图1 交通流可预测性分析流程Fig.1 Flow chart of traffic flow predictability analysis
短时交通预测的条件是系统变化呈混沌状态。在分析交通流时间序列数据的可预测性时,即判断系统变化的混沌状态通常有2种方法:Lyapunov指数法和构造可预测性递归图法,其中Lyapunov指数意味着相空间中相邻点的发散程度。对交通流系统的Lyapunov指数进行估算可用于研究交通流系统所处的状态,且可以更直观地对混沌现象进行定量的判断[15]。本文采用Lyapunov指数法进行交通流时间序列的可预测性分析。
对于一个具有n维流的动力系统:

(12)
式中:xi为n维变量,它可以用来构成一个n维的相空间;h为时间;f1(x1,x2,…,xn,a)为n维函数;a为控制参数,能够决定相空间吸引子种类[16]。
用公式表示Lyapunov指数λi的定义为:
(13)
式中:ωi(t)指第i时刻椭球的轴长度。
如果Lyapunov指数大于0,则证明其系统为混沌的,并且可以进行交通流预测分析。
张海龙等[17]表明在利用定义法、wolf法、正交法和小数据量法的计算中,运用上述4种方法分别计算了最大Lyapunov指数,结果显示wolf法和小数据量法抗干扰能力最强。故本文将采用wolf法来验证系统的混沌性。
2.2 基于相空间重构的卡尔曼滤波短时交通流预测模型
卡尔曼滤波通过预测系统状态向量实现对未来状态的预测,其初始状态x(1)的确定对预测结果的影响十分重要。初始状态向量的准确性决定预测结果的准确性,相空间重构是解决系统初始状态问题的最优方法。故本文选择相空间重构模型确定系统的初始状态,再选用卡尔曼滤波进行递推式预测。
实际上,利用相空间重构法将交通流系统的吸引子恢复,然后得出反应交通流的特征变化规律,得到:
S(k+T)=f(S(k))
(14)
式中:S(k)为相空间中的点。
根据式(14)基于递推的方式完成相点的预测。但由于非线性拟合误差太大,一般难以确定函数关系。将卡尔曼滤波原理与相空间重构原理相结合,将相空间中2个相点S(k)与S(k+T)(设步长T=1)作为卡尔曼滤波的状态向量S(k)与S(k+1),并把卡尔曼滤波方程中的状态初始向量定义为相空间重构后的相点y(1)。
设交通流的时间序列为{y(1),y(2),…,y(n)},按照相空间重构原理进行重构,重构后的如式(15)所示:
S(k)=[y(k),y(k+τ),…,y(k+(m-1)τ)]
(15)
重构相空间后得到的相点个数可由式(9)得到。
系统初始相点的表达式为:
S(1)=[y(1),y(1+τ),…,y(1+(m-1)τ)]
(16)
根据以上的内容,对基于相空间重构的卡尔曼滤波模型的交通流预测进行总结,具体步骤如下:
步骤1利用C-C法求出交通流时间序列延迟时间τ及时间窗τw,再根据τw=(m-1)τ确定嵌入维数m。
步骤2利用小数据量法求出最大Lyapunov指数,若结果大于0则证明该系统为混沌系统,即可进行下一步的预测。
步骤3重构交通流系统。将一维时间序列进行转化,得到k个相点。
S(1)=[y(1),y(1+τ),…,y(1+(m-1)τ)]S(2)=[y(2),y(2+τ),…,y(2+(m-1)τ)] …S(k)=[y(k),y(k+τ),…,y(k+(m-1)τ)]
(17)
其中由所有向量的分量组成的空间为相空间,完成交通流时间序列转化为相空间中的点。
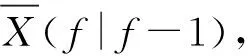

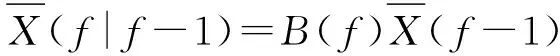
(18)
步骤6预测协方差矩阵p(f|f-1):
p(f|f-1)=B(f-1)P(f-1)BT(f-1)+Q(f-1)
(19)
步骤7预测卡尔曼增益矩阵K(f):
K(f)=p(f|f-1)AT(f)[A(f)p(f|f-1)AT(f)+R(f)]-1
(20)
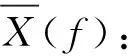
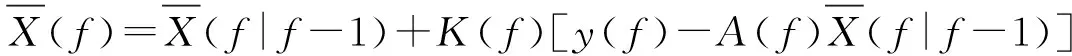
(21)
步骤9预测均方误差矩阵p(f):
p(f)=[I-K(f)A(f)]P(f|f-1)
(22)
将步骤5至步骤9重复至预测长度,完成预测。
2.3 评价指标
在交通流预测的研究体系中有着比较完善的性能评价指标,本文选择的评价指标如下:
平均相对误差MRE:
(23)
式中:Yreal为真实值;Ypre(t)为预测值。
均方百分比误差MSRE:
(24)
均等系数EC:
(25)
3 实例验证及结果分析
为验证模型的可行性、计算模型的准确性,本文以北京市北三环蓟门桥西侧的某一断面为例(数据由2018年2月13日零时至2018年2月20日零时),如图2所示,其中箭头标记处为该断面,该断面为三车道的主干路。

图2 采样断面Fig.2 Sample section
数据采样周期为2 min。根据上文所述,太短的时间间隔会使采样得到的交通流数据呈现出随机状态而很难进一步预测其结果。
数据采样周期为2 min。共收集总数据为6 232条,部分数据见表1。
由于短时交通流预测周期时长普遍认为在15 min以内,为进一步评估模型的性能及适用范围,本文将分别采用时间间隔为6 min、10 min进行预测和对比分析,通过误差计算出该模型在各类情况下的预测性能。预测结果如图3~图6所示,预测误差见表2。

表1 采集断面交通流的部分数据Tab.1 Collect partial data of traffic flow in section
通过误差分析可明显看出该方法的准确性,每一个预测时间内的交通流均等系数均在90%以上,达到了很高的拟合程度。而对比2个预测周期的误差,预测周期为10 min的误差及均等系数均优于预测周期为6 min的预测。所以本文所用的方法更适合预测周期为10 min的预测。
由于采样的路段为三车道的主干路,设计速度为60 km/h,经统计,其高峰时刻每条车道每10 min的断面车流量数据大约为800 pcu,最低断面流量约为200 pcu。根据基本路段服务水平将该道路不同时段分为自由流和稳定流的短时交通流预测,并进行对比分析。
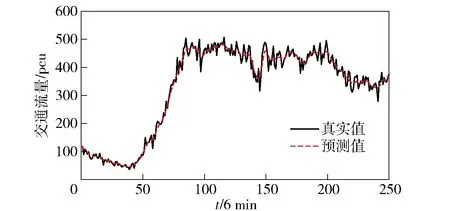
图3 预测周期为6 min时真实值与预测值的对比Fig.3 Comparison of true and predicted values in the prediction period of 5 min
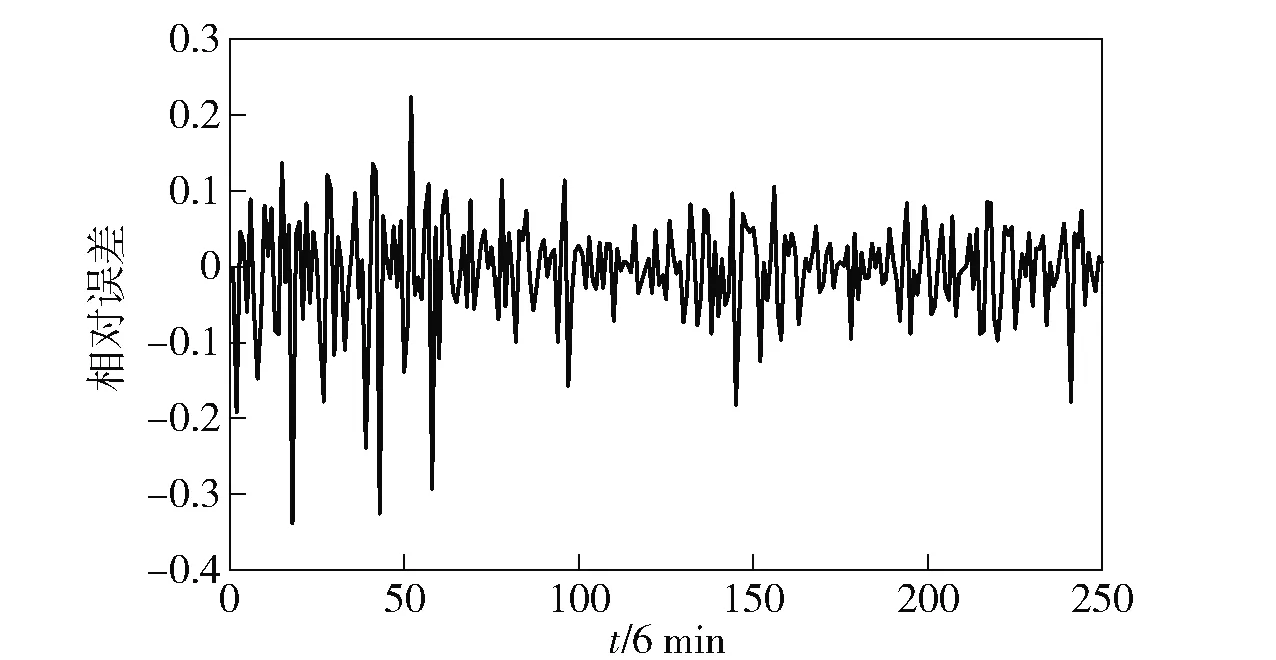
图4 预测周期为6 min时相对误差Fig.4 Relative error in prediction period of 6 min
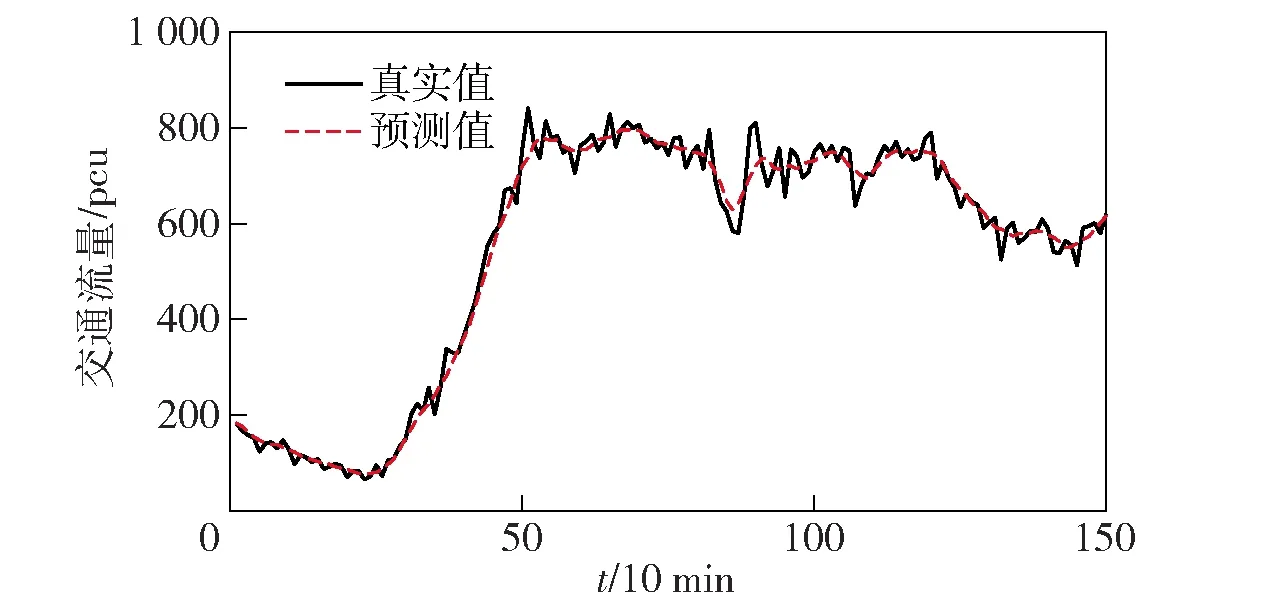
图5 预测周期为10 min时真实值与预测值的对比Fig.5 Comparison of true and predicted values in the prediction period of 10 min

图6 预测周期为10 min时相对误差Fig.6 Relative error in the prediction period of 10 min
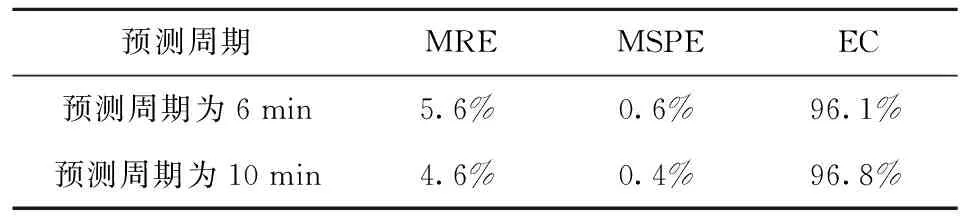
表2 预测结果误差对比分析
分别对自由流和稳定流以10 min进行预测,预测结果如图7~图10所示。

图7 状态为自由流时短时交通流预测结果Fig.7 Short-term traffic flow prediction results in free flow

图8 状态为自由流时短时交通流预测相对误差Fig.8 Relative error of short-term traffic flow in free prediction in free flow

图9 状态为稳定流时短时交通流预测结果Fig.9 Short-term traffic flow prediction results in steady flow
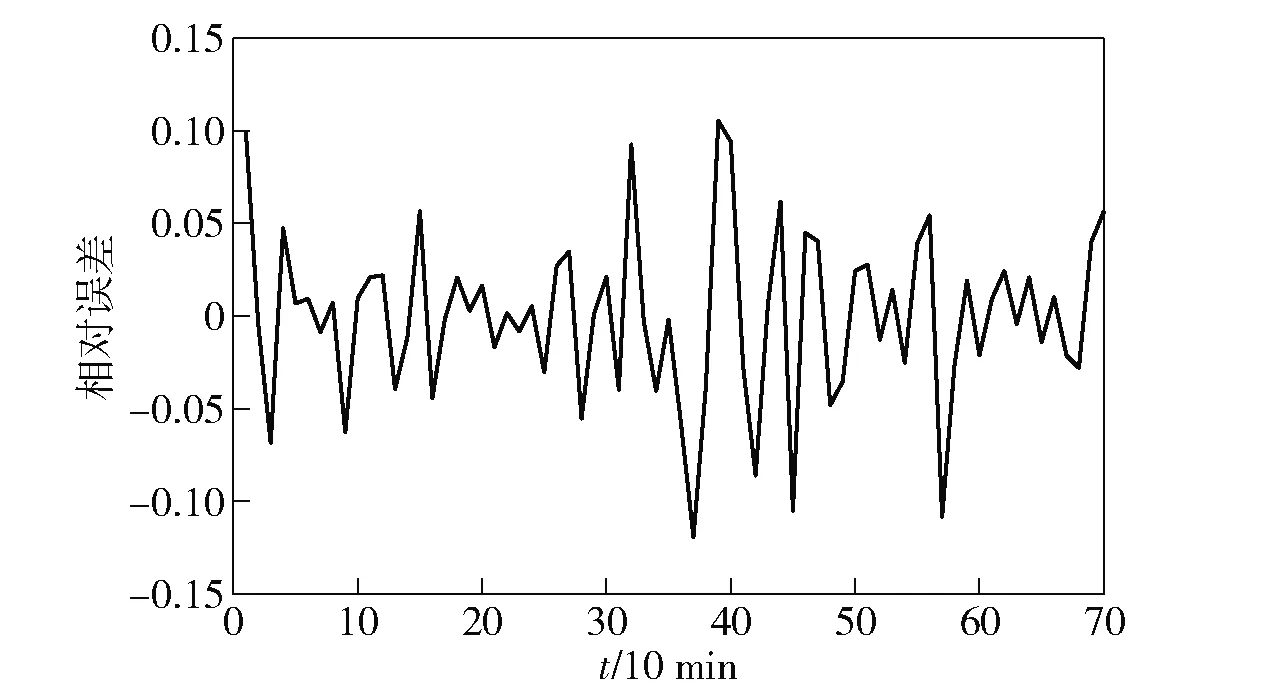
图10 状态为稳定流时短时交通流预测相对误差Fig.10 Relative error of short-term traffic flow prediction in steady flow
由图7~图10明显看出,该方法在此场景中稳定流状态时比自由流状态时的预测精度更为准确。原因是该路段处于自由流的时间过少,导致自由流时刻数据样本量太低,在相空间重构中利用非线性结构统计量计算嵌入维数和延迟时间时导致重构系统与原系统不能达到很好的一致性。所以少样本量的数据可以预测且误差在可接受范围内,但样本量少比样本量大的预测精确度低。
为了验证组合模型的有效性,对卡尔曼滤波模型的交通流预测方法和常用的神经网络方法如长短期记忆方法(LSTM)和门控循环单元(GRU)进行仿真预测,根据上述的评价指标,计算其预测误差,误差对比见表3。

表3 不同模型预测结果误差对比分析Tab.3 Comparison and analysis of the prediction errors of different models
从表3可以看出,基于相空间重构的卡尔曼滤波模型进行预测的结果总体更优,与卡尔曼滤波模型的交通流预测相比,平均相对误差减少0.8%,均方百分比误差减少0.3%,均等系数增大0.5%。与常用的神经网络的方法如LSTM和GRU的预测相比,其误差更小,达到了很高的拟合度,预测准确度更高。主要是由于卡尔曼滤波对系统的初始状态向量十分敏感,使用重构后的初始相点进行预测,其预测过程充分展现了系统的内在信息及轨迹的演化过程。
4 结论
本文将传统的卡尔曼滤波与混沌理论相结合,将交通流时间序列相空间重构后的相点作为卡尔曼滤波的初始相点,以此建立基于相空间重构的卡尔曼滤波短时交通流预测模型,并结合实际案例讨论模型的适用范围,预测结果表明该模型在预测周期为10 min时精准度更高,且样本量较少时预测精准度在可接受范围内,但不如样本量大时准确度高。对于传统的卡尔曼滤波预测方法而言,利用相空间重构后的相点进行递推弥补了初值为缺省的空白。此方法对研究交通流预测模型、提高预测模型的精度和智能交通系统的发展有着重要的意义,为交通信号控制和交通诱导系统提供了较为精准的数据支持。
