机器学习在水力压裂作业中的应用综述
2022-01-18何玉荣宋志超张燕明肖元相
何玉荣,宋志超,张燕明,肖元相
(1.哈尔滨工业大学能源科学与工程学院,黑龙江哈尔滨 150001;2.中国石油天然气股份有限公司长庆油田分公司油气工艺研究院,陕西西安 710018)
数据驱动技术为科学研究及工程应用提供了一系列新的研究手段,可用于在大量数据中检测数据背后的隐藏关系、计算不确定性以及吸收多种数据类型进而提取有用信息[1]。传统理论建模方法多依赖于试错,而且计算过程耗时冗余,利用机器学习算法发现数据的物理本构关系,可以简化理论模型,加速模型计算,成为传统模型的有利补充[2]。自水力压裂技术试点[3]成功以来,测井数据数量与质量不断提高,为机器学习在水力压裂作业中的实施提供了有利基础。值得注意的是,机器学习算法在水力压裂作业中已经成为不可或缺[4]的实用工具。由于传感器收集的数据如速度、压力具有非线性和高维度特性,如何将这些原始数据转换为可用信息作为输出,纳入现场监控和生产管理至关重要。笔者综述水力压裂作业过程中常见的机器学习算法,重点论述这些经典机器学习算法在水力压裂作业中的实际应用,包括对压裂作业中参数预测与评估、产能预测与优化、实时预测与监控等。最后对机器学习算法在水力压裂应用过程中面临的挑战以及未来可能的研究方向进行展望。
1 经典机器学习算法
机器学习是数据驱动建模的统称,也是人工智能算法的子集[5]。机器学习通过学习过程,从训练集中获取经验,并比对测试集进行验证。机器学习算法在特定的任务当中,模型的性能是通过性能指标来衡量的。虽然机器学习算法众多,但是没有算法可以完美地解决所有问题,尤其是对于预测模型来说,受到数据集的规模和结构影响较大。主要综述预测模型中的经典算法以及各算法的特点及其适用性。
1.1 线性回归
线性回归也被称为简单线性回归,将两个变量之间的关系用一条直线表示[6]。通过调整一元函数的斜率和截距找到最优直线,从而最小化回归误差。该模型[7]可表示为
y=b0+b1x.
(1)
式中,x为输入参数;y为输出参数;b0和b1分别为一元函数的截距和斜率。
多元线性回归模型被用于检查多个变量之间的线性相关性,是普通最小二乘法的延伸[8],在此基础上进行预测分析,该模型可表示为
y=β0+β1x1+β2x2+…+βzxz+ε.
(2)
式中,y为预测参数;xi为输入参数;β0为常数;βi为回归系数;ε为残差项。
多元线性回归模型中认为输入变量与输出变量之间存在线性关系,独立变量之间不是高度彼此相关[9]。线性回归算法的优点是计算简单,其缺点是不能拟合非线性数据。
1.2 树型算法
树型算法与线性模型不同,树型模型对非线性关系也可以有很好的映射,这些算法赋予预测模型稳定性与准确性。常见的树型模型有决策树[10](回归树、分类树),随机森林[11]、梯度提升树[12]等。
决策树(decision tree,DT)是有监督学习中常见的分类(回归)算法,决策树的生成通常分为两个步骤[13]:①节点分裂,若分裂该节点可获得最大信息增益,则该节点分裂为两个或多个节点;②阈值确定,选择合适的阈值可以使误差达到最小。在实际应用过程中,决策树算法对具有时间序列的数据,需要过多的预处理,在分类作业过程中,决策树算法错误会增加的很快。
决策树算法[14]易于理解、可视化分析、从模型中提取规则、运行速度较快,可以在短时间内对大规模数据集做出效果良好的预测。但是该算法不容易发现数据之间的关联属性,易出现过拟合现象;另外当数据集中出现一新的数据时,需重新计算。随机森林就是以这些问题为切入点被提出的。
随机森林是一种基于决策树模型的分类与回归模型,当对某一具体问题进行预测时,需统计随机森林中每一颗决策树的预测结果。随机森林的随机体现在两个方面,一为随机抽样,二为随机特征,被视为多个独立的决策树模型[11],其数学模型可表示为
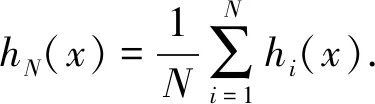
(3)
式中,hi为决策树模型;N为决策树模型的个数。
随机森林模型通过平均决策树模型,降低了模型过拟合的风险[15],即使数据集中出现一个新点,随机森林整体算法也不会受很大影响。但是相比于决策树而言,随机森林引入决策树个数、最大深度、候选特征数范围等超参数,使模型变得更为复杂,同时增加了计算成本。具体算法[16]如图1所示。

图1 随机森林算法与原理Fig.1 Random forest algorithm and principle
1.3 神经网络
神经网络是受生物神经系统启发而产生的统计学模型,对人脑神经系统进行抽象构造人工神经元,神经元之间的连接由一定拓扑结构构建,神经网络在挖掘非线性数据关系方面非常有效,被认为是石油工程师的新工具[17]。水力压裂技术过程中常见的神经网络,包含前馈神经网络(feedforward neural network,FNN)、径向基函数神经网络(radial basis function network,RBF network)以及卷积神经网络(convolutional neural network,ConvNet或CNN),结构示意如图2[18-19]所示。
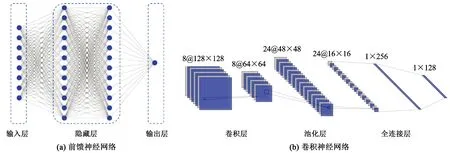
图2 前馈神经网络和卷积神经网络算法与原理Fig.2 Feedforward neural network and convolutional neural network algorithm and principle
前馈神经网络由输入层、隐藏层、输出层3部分组成。整体算法分为正向传播和反向传播两个过程,对于正向传播而言,任意神经元的数学模型[20]可表示为

(4)
式中,xj为净输入;yi为神经元的净输出;w为权重矩阵;b为偏置向量;f为激活函数;k为上一层隐藏层神经元数量。
考虑非线性对模型的影响,解决线性模型的缺陷[21],若没有激活函数,即f(x)=x相对于神经网络没有隐藏层的情况,神经网络退化成最初始的感知机。常见的激活函数有Sigmoid型函数、Tanh函数、ReLU函数系列、Swish函数等,激活函数的选择直接决定了输入与输出之间的非线性映射。2017年谷歌公司[22]提出一种形式简单的激活函数即Swish函数,表明对于绝大多数情况,Swish激活函数优于ReLU函数。
对于反向传播而言,通过最小化非凸损失函数(对于回归问题一般是均方差,对于分类问题一般为交叉熵),找到神经网络权重的最大似然估计,利用梯度下降法更新权重矩阵[18]。其数学模型的一般表达式为
(5)
式中,L(x,y)为损失函数;α为步长或称为学习速率。利用链式求导法则即可求出各层各参数的偏导数。
前馈神经网络具有很强的学习能力,适用于高维度、高自由度、非线性问题,但是容易出现训练集损失函数不断下降,测试集却趋于不变,即出现过拟合现象。Srivastava等[23]提出Dropout技术,发现可以有效避免过拟合现象。
RBF神经网络[24]是仅有一层隐藏层的神经网络,且激活函数为径向基函数,相比于普通神经网络而言,RBF神经网络具有更强的逼近能力,结构简单,可以逼近任意非线性函数且输入节点与隐藏层之间的连接权重为1。对于RBF神经网络而言,仅有一层隐藏层,隐藏层的神经元个数为N,N的选取根据具体问题而设定,RBF隐藏层第j个节点的数学模型[24]的输出表示为
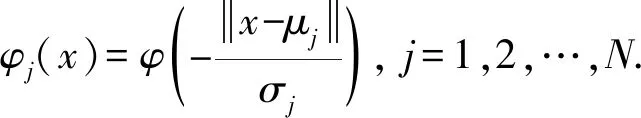
(6)

输出层的数学模型[24]可表示为
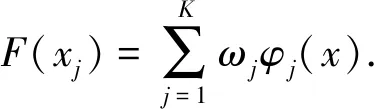
(7)
式中,ωj为权重;F(xj)为输出。
RBF神经网络保留了上述神经网络的优点,例如,非线性映射能力强、并行能力强;此外由于RBF神经网络结构简单算法速度得到了极大提高,且具有很强的聚类分析能力。
卷积神经网络[25]是一种典型的深层神经网络,在计算机视觉领域占据主导地位。仅采用全连接神经网络处理图像信息时,具有参数过多和局部不变性特征两个问题。而卷积神经网络具有局部连接、权重共享以及汇聚等特点,使得卷积神经网络在图像处理等领域的准确率远远超过其他神经网络,结构如图2(b)所示。卷积神经网络一般包括卷积层、池化层、全连接层3部分[19],卷积层是一种局部特征提取器,特征图数量由卷积核数量直接决定;池化层是一种特征压缩器,将卷积层提取到的特征压缩,减小图像的失真率,通过池化层使得图像具有一定的局部不变性;全连接层是一种分类器,对特征进行分类输出,针对分类问题最后一层一般是Softmax输出层。
神经网络[26]可以处理大规模数据,准确率高,易于并行,能充分逼近任意复杂的非线性关系;对于小噪点数据,神经网络也具有较强的鲁棒性和容错性。但是神经网络训练时间长,需要大量参数且训练过程为黑盒过程,使得输出结果难以解释。
2 机器学习在水力压裂作业中的应用
水力压裂作为一种增产技术,自20世纪以来,迅速在全球范围内得到广泛应用[3]。该技术通常将数十兆帕的压裂液泵入井筒中,在地层中形成裂缝,同时裂缝在支撑剂的作用下保持打开状态,促使致密油气输送到地面。此外水力压裂可结合水平钻井技术,使其成为最具成本收益的增产技术。然而在实际多级压裂作业中,有多达三分之一的射孔簇没有产出[27]。这是因为压裂设计尚有缺陷以及地质学等因素导致各射孔簇产量不均匀。在水力压裂作业前根据井的历史数据和储层信息对产能进行预测,对压裂进行优化设计,有助于提高产能。在水力压裂作业中,实时对相关参数诸如裂缝密度、渗透率、声波曲线、压力曲线等进行预测,可以实时改变压裂设计方案。
2.1 水力压裂作业中参数预测与评估
在水力压裂过程中诸如:渗透率、裂缝密度等参数难以直接测量,不易评估[28]。近数十年来,试验和数值模拟方法积累了大量相关数据,为机器学习算法在参数评估与预测方面的实施提供了基础。本部分主要综述机器学习与物理建模的混合应用、机器学习对水力压裂作业中未知的关键参数的预测与评估。
水力压裂作业过程中,对裂缝进行全面建模、表征裂缝几何形状是实现油气管理预测的必要条件[29]。模拟油气在多孔介质中三维输运建模是石油压裂过程中常见的方法,建模方法种类较多,例如:由Ertekin等[29]提出的有限差分流体动力学模拟,Hunsweck等[30]提出有限元方法模拟水力裂缝的扩展,Crouch等[31]提出边界元方法改进拟三维模型。为了精准计算,通常采用底层模拟或细网格技术,相比之下耗费时间。
机器学习建模或机器学习与传统方法混合建模在石油压裂领域得到了广泛应用。Kalyuzhnyuk等[32]利用神经网络代替传统数值模拟建模,成功应用于稳态水力裂缝形状的评估。Artun[33]分别采用神经网络与简单物理建模——电容-电阻模型构建具有合理精度和计算效率的地质模型,量化注水油藏注采井之间的井间储层连通性。相比之下神经网络模型更具有灵活性,训练时间不足1 min,具有很高的计算效率。Urban-Rascon等[34]利用微地震数据结合自组织映射与多属性分析,对霍恩河页岩的裂缝网络的复杂性进行表征;并利用人工神经网络辅助选择与现场裂缝和模拟相关的重要数据。Llorca等[35]利用神经网络对虚拟瞬态压力进行模拟,利用现场瞬变压力进行训练,对未进行试井的其他井的瞬变压力进行预测,并评估了测试井的生产历史、井的数量以及井的位置。该模型不仅降低了试井的成本,并在几秒之内生成可靠的虚拟瞬态压力数据;而且通过对虚拟瞬态压力进行分析,同时可以预测干扰效应与储层渗透率。
至今,在水力压裂作业中应用了各种机器学习算法,每种建模方法各具特色。除取代传统数值模拟或与数值模拟混合使用探究参数信息外,还可以根据以往的测井数据结合当地储层具体情况,直接获取裂缝或储层等相关信息,并对压裂效果进行评估。Jafari等[36]使用伊朗西南部油田结合模糊神经网络方法,将声波、体积密度、孔隙率、电阻率作为输入参数,推断裂缝密度,构造离散和连续两种模型,均可对裂缝密度进行良好的推断。Li等[37]利用遗传算法结合支持向量机对裂缝密度做出了精准预测。Mohamed等[38]利用线性回归和多层感知机算法预测裂缝闭合压力、裂缝闭合时间、渗透率等参数,同时将输出结果与实际测量结果相比较,均获得了良好结果。Kumar等[39]利用德克萨斯州米德兰盆地的水力压裂试验场的示踪、完井及增产数据,对水力压裂作用中的天然裂缝以及新产生的裂缝组成的裂缝网络进行了详细评估,为非常规储层的油气采收提供参考。将现有数据与机器学习方式相结合,提供裂缝网络以及流动信息并将其可视化表示,可为油气生产优化提供较优决策。
虽然上述研究中机器学习算法可以获得良好结果,但是由于数据规模与数据结构不同,导致没有一种算法可以适用于所有情况。具体何种算法最适用于所面临的问题,往往需要多次尝试。Nouri-Taleghani等[40]对比了RBF神经网络、多层感知机算法并采用遗传算法优化各算法的权重,利用全套测井数据进行训练,提升模型泛化能力,开发确定裂缝密度的数学模型,取代传统岩心数据和图像测井方法。相比之下RBF神经网络具有较强的预测能力。Shi[41]针对南襄盆地泌阳凹陷安棚油田以及鄂尔多斯盆地塔巴庙地区致密油田分别采用支持向量机、人工神经网络、多元回归分析算法对裂缝进行预测。结果证明支持向量机在有限数据下精度较高,在工程应用中可以作为辅助工具。Wang等[42]对比了4种有监督学习算法:随机森林、提升树、支持向量机和神经网络算法,对每口井泵送的支撑剂、真实垂直深度等近20个重要参数进行了预测,发现基于随机森林算法的预测模型对Montney致密油井水力裂缝处理更有效,可为工程应用提供很高的实用价值。
机器学习除直接预测裂缝或储层参数信息外,在实际压力过程中由于压裂作业的成本受限,在钻井过程中没有对相关测井曲线进行测定;或由于老井年久,导致相关参数缺失,一些研究中尝试利用机器学习算法,从可用参数中估算实际参数。Onalo等[43]利用多层感知机神经网络结合实际伽马射线与地层密度估算了地层中声波纵波与横波的渡越时间。Bukar等[44]分别利用多元性回归模型、支持向量机、决策树(回归树)等有监督学习算法对声波测井曲线进行预测。对于缺少声波测井数据的老油气田,这种方法尤为重要。Shan等[45]将卷积神经网络与双向长短期记忆神经网络相结合,在中国港东油田进行了性能测评,在实际工程应用中可应用该方法补充声波测井、伽马射线测井以及自发电位测井的数据。樊毅龙等[46]通过苏东气井筛选收集了800口井关于施工条件和生产方面的数据集,通过多元线性回归算法,分析各个参数及其标准误差并以此为标准。发现多重填补法效果对于补充数据缺失值来说,效果最佳。Wang等[47]采用K-fold交叉验证方式辅助提高了神经网络的鲁棒性,同时对神经网络中隐藏层数量,每一层神经元个数,激活函数等超参数进行了优化。研究结果表明在水力压裂的每个阶段,平均支撑剂的含量是影响产能的主要因素之一;而且在实际压裂过程中,如将该神经网络模型集成到水力压裂相关程序中,该数据驱动模型可以实时进行更新。
2.2 水力压裂作业中产能预测与优化
不论是对水力压裂模拟还是对储层模拟,由于压裂过程中流体输运性质具有极高的不确定度,同时考虑到储层的复杂性、底层的裂缝性质等因素,通过数值模拟方式对产能进行预测,往往不准确[48]。另外一些研究中提出利用幂律指数递减法[49]、Arps下降曲线[50]等方法预测产量,但是由于流体在人工裂缝和天然裂缝之间有流动差异,通过这些方法预测往往会低估油气产量。相比之下,科研人员利用机器学习算法可以对裂缝进行良好的预测。李菊花等[16]利用涪陵页岩气田一期数据集,结合随机森林算法对气井产量进行预测。研究表明密度测井值、脆性指数等参数是影响多级压裂井产量的主要因素。马先林等[51]用苏里格气田东区712口压裂直井数据,对比随机森林、支持向量机、神经网络、多元回归等算法对产能进行了预测,结果表明随机森林算法预测性能最佳。Cao等[52]考虑非常规储层的未知因素,采用人工神经网络算法针对实际油井产量进行建模。该模型可以预测现有井的产量,同时也可以对未开采的油井进行预测,表明利用神经网络建立的模型可以取代传统经验公式以及数值建模的产能预测。
相比较于随机森林与神经网络算法,对于有时间序列的数据集,基于长短期记忆神经网络(long short-term memory,LSTM)的深层神经网络具有更高的准确性,同样也被应用到水力压裂产能预测过程中。Esmaili等[53]基于数据驱动技术建立机器学习预测模型,对宾夕法尼亚州西南部Marcellus页岩油气生产过程进行了建模,相比于传统数值模拟方法,该模型精度更高,且识别周期更短,可以与完整的油井历史数据相匹配,也可以获取单个井的生产行为。Song等[54]将LSTM的超参数用粒子群算法进行了优化配置,该模型可以准确捕捉在多种因素共同作用下,油气产能的复杂变化规律;并与传统神经网络结合递减曲线分析方法的结果相比较,发现LSTM神经网络针对时间序列的数据预测性能远高于传统神经网络。Liu等[55]提出了一种基于LSTM结合集成经验模式的学习模式,并采用遗传算法确定LSTM的超参数,结果表明该方法可以很好预测井的产量。
在对水力压裂产能预测的同时,许多学者考虑到经济效益,将压裂过程与各致密油气的价格相结合,估算致密油气的净现值。Morozov等[56]利用俄罗斯西伯利亚西部20口不同井,近5 000组相关典型数据,选择包含压裂设计参数在内的92个特征为输入变量,生产数据包含产量在内的16个特征为输出;结合过滤手段消除数据库中的噪点并补充缺失值,通过选择最佳裂缝参数达到优化设计提高油气产能的目的。Nguyen-Le等[57]提出一种动态经济指标的框架,基于多元线性回归算法将储层参数与压裂参数以及各种致密油气价格相结合,考虑初始油气饱和度和吸附天然气含量,用于估算致密油气的净现值。
水力压裂作业的成本很高,所以对压裂参数进行优化是经济、高效、实用的方法[58]。在过去的一些研究中,大多数研究均是通过局部敏感性分析确定最佳参数,然而这些方法不能筛出不重要参数,因此机器学习算法的引入,可极大程度地帮助科研人员解决这一问题。Alwarda[59]利用水力压裂水锤衰减数据结合主成分分析以及偏最小二乘回归算法估计瞬时关阀压力与摩擦损失,这个摩擦损失包含井筒与射孔之间、近井筒弯曲处等局部摩擦损失,该研究可以辅助射孔的优化设计以及完井的设计决策,强调机器学习算法的实用价值。Yu等[60]结合机器学习算法提出一种高效的框架,考虑井底压力、裂缝半长、储层压力、渗透率等8个参数;同时考虑不同致密油气价格,优化非常规致密油气水力压裂作业的生产方案与工艺设计,可以辅助工程师根据实际裂缝状态重新对后续裂缝位置进行设计。Han等[48]利用150口井的典型数据包含8 560个数据点,选择完井系数、水力压裂系数、储层性质等参数作为特征输入,结合神经网络模型并使用递减曲线分析方法,对未来生产率进行预测。同时为了保证神经网络算法具有高质量的输入输出数据,此研究中通过无监督学习聚类算法识别数据之间的相关性。Surguchev等[61]利用人工神经网络方法进行预模拟并通过筛选工具评估在不同油藏条件下的适用性,在储藏数据有限时可用该方法进行协助决策。Jin等[62]基于低频分布声波传感数据结合神经网络算法对裂缝进行识别,突出裂缝特征,通过训练、验证、测试证明该方法与人工手动识别效果吻合良好,结果表明更密集的裂缝网络需要较小的簇间距设计。
对于优化问题,除根据各种数据集规模与特征确定最优算法外,同时可以结合群体优化算法(如遗传算法、粒子群算法等)对施工参数进行优化配置。陈新浩[63]利用某气田近300口井施工数据,结合神经网络、决策树、支持向量机等机器学习算法对水力压裂过程进行优化,发现神经网络结合优化算法最适合优化配置施工参数。Sabah等[64]利用马伦油田2 820组数据,开发了一种将遗传算法、粒子群算法、布谷鸟算法与多层感知机相耦合的方法,采用Savitzky-Golay(SG)过滤器对数据集中不相关冗余数据,对钻井前的井漏进行了预测,结果表明混合智能算法的预测性能相比于单一机器学习算法更加强大。
机器学习算法在水力压裂产能预测与优化过程中,需要通过交叉验证、网格搜索、随机搜索等方式或者采用群体优化算法对机器学习算法中的超参数进行确定,以提高模型的鲁棒性与适用性[65]。同时为保证数据质量,可以考虑在机器学习模型训练前对数据进行过滤,或采用无监督学习算法对噪点过滤[66]。
3 结论与展望
简要回顾了机器学习经典预测算法,例如线性回归、树形算法、神经网络的优缺点以及各算法在水力压裂作业中的应用。机器学习已经成为推测流体流动特性、储层特性、相关参数信息的有效工具。机器学习算法在水力压裂作业中的应用仍有不足:①在数据大量缺失或数值模拟建模未稳定的情况下,应用机器学习算法会引来很大偏差;②在数据特征不明确或有噪点时同样会给机器学习带来极高的不确定度;③对于大多数机器学习算法而言,输入数据与输出数据之间的关联是不透明的,导致从数据中获取的关联可能存在问题。针对机器学习在水力压裂过程中的应用提出如下展望:机器学习算法之间以及机器学习算法与优化算法混合使用,以提高模型的预测能力;发展数据集的公共平台,方便科研人员用于寻求数据;将物理建模与机器学习算法混合使用,针对实际问题提供优化方案。
