基于深度强化学习的多应急车辆信号优先控制
2022-01-12刘翔李艾成卫
刘 翔 李 艾 成 卫
(昆明理工大学交通工程学院1) 昆明 650504) (玉溪市公安局交通警察支队2) 玉溪 653100)
0 引 言
我国道路安全法规定,在保证道路安全的情况下,应急车辆享有绝对的道路优先权,而城市中通行的大部分延误都产生在交叉口,因此在交叉口设置优先信号控制,对应急车辆快速到达事发现场至关重要.
国内外学者针对应急车辆优先通行进行了居多研究.Maram等[1]以紧急车辆能够快速通过为前提,设计了一个动态、高效的交通信号控制算法,以获取各个交通流的最佳绿灯相位时间.Qin[2]设计应急车辆信号优先控制过程.谢秉磊等[3]探讨了应急车辆优先通行的二阶段模型.赵欣等[4]提出了可变导向车道的应急车辆优先通行策略.上述研究均是基于模型的控制方案,而现实中存在诸多不确定因素,导致交通状况不可能一直处于稳定状态,一旦出现意外状况,基于模型的控制会出现极大偏差.文中提出了一种基于深度强化学习的应急车辆信号优先控制方法,使交通信号控制系统具有自我学习、自我判断的能力,在出现行驶方向相互冲突的应急车辆时,可以提供应急车辆的信号优先,同时综合考虑了交叉口各个进口道社会车辆的情况,尽可能减少对相交道路上社会车辆运行的影响.
1 问题描述
由于目前大部分单个交叉口应急车辆优先信号控制的研究都针对应急车辆从某一进口道接近交叉口,从而对应急车辆实现优先控制的方法,这种控制方法通过复杂的建模和优化算法虽然能够解决单个应急车辆优先通过交叉口的问题,但显然存在一定的局限.当城市出现突发状态时,应急车辆可能会从交叉口不同的进口方向同时接近(见图1),出现此情况时,不同进口方向上的应急车辆都需要信号优先控制,之前的方法在这里将不在适用.针对这一问题,文中将综合考虑各方向应急车辆信号优先与社会车辆的通行,通过对每个进口道应急车辆和社会车辆进行编码,将整个应急车辆的信号优先控制过程建模为马尔科夫决策过程,对基于深度强化学习算法的交叉口多应急车辆优先信号控制进行了研究分析.
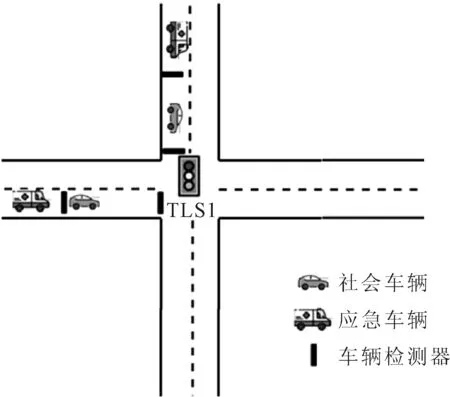
图1 应急车辆从不同方向接近交叉口示意图
1.1 强化学习基本原理
在强化学习中,对于每一个时间步长t,智能体通过与环境的交互,观察环境的状态s,然后根据观测到的状态从动作集合A中选取一个动作a,每执行完成一个动作a∈A,将受到环境的反馈奖励r,同时环境状态更新为新状态s’,经过长时间的交互后,智能体获得了一系列状态、动作和奖赏值组成的四元组
(1)
式中:Rt为折扣期望奖励;γ∈(0,1]为折扣因子.
1.2 深度Q学习
在深度Q学习中,定义动作价值函数Q-function来估计智能体在给定状态下执行策略π下某个动作的效果.Q函数为[5-6]
(2)
在深度Q学习中,将具有权重θ的神经网络函数逼近器称为Q网络,可以通过迭代更新来最小化TD误差来进行学习,当优化损失函数Li(θ)时,暂时固定前一次迭代的参数θi-1,从而得到损失函数梯度计算公式,为
Q(s,a;θi))2]
(3)
式中:i为当前迭代次数,在每次迭代中,参数θ的更新公式为
(4)
式中:ε∈(0,1]为学习率.最终得到Q值的最优估计参数θ*.
(5)
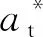
1.3 深度双Q学习
在DQN中,Q学习在估计动作值时,总是选取动作值最大的动作,所以在训练过程中容易陷入局部最优.为了防止出现过估计,双Q学习将评估与选择分开,每个学习经历都会随机分配一个值函数来进行更新,这样就出现了两套权重集合θ与θ′,对于每一次更新,其中一组权重用于决定贪心策略,另一组用来确定其值.
为了将Q学习的选择与评估分开,Q学习的目标函数可改写为
(6)
则双Q学习的目标函数为
(7)
2 应急车辆信号优先关键要素定义
2.1 状态空间表示
假设系统中的车辆属于两种类型,即应急车辆与社会车辆,并根据车辆在交叉口的行驶信息来定义状态.设一个交叉口的来车需求分为P个方向,N为应急车辆与社会车辆的状态空间,将E和S分别定义为应急车辆和社会车辆的状态空间[8-9].
状态空间的定义对于系统是十分重要的,由于应急车辆属于特殊车辆,因此本文中假设应急车辆都具有车载网络或其他车载设备,能够实时发送车辆信息.随着智能检测技术的发展,路口所设置的检测器能够传回应急车辆的实时状态,因此交通管理部门可以实时获得应急车辆的位置以及此时的速度.因此,本节利用车辆在十字路口的位置和速度来定义应急车辆的状态.首先定义di为应急车辆距交叉口的距离,vi为应急车辆的实时速度并将其以最大速度进行归一化,其中.i∈P随后将二者结合为一个二元组
E=[d1,1,1,v1,1,1,d1,1,2,v1,1,2,…,di,j,k,vi,j,k]T,
i=1,2,…,n;j=1,2,…,c;k=1,2,…,g
(8)
式中:i为交叉口的不同进口方向;j为各进口方向的车道;g为不同的车道分段.若应急车辆不存在,vi,j取值为-1.需要特别说明的是本节设定的应急车辆在保证安全行驶的过程中可以自由换道,而社会车辆的换道方式按照仿真软件中默认的换道模型进行换道.
由于目前大部分的车辆并不具备车载通行技术,因此为了更加接近现实,定义每条进口车道的社会车辆数量和平均速度作为社会车辆的状态空间,这二者均可通过安装在路口的车辆检测器获得,即
i=1,2,…,n;j=1,2,…,c
(9)
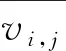
因此,全面描述应急车辆到达时路口的交通环境,将其作为深度强化学习智能体的状态空间输入,这样智能体就可以通过训练学习,逐渐学习到最优策略.
2.2 动作空间表示
在考虑社会车辆能够减少延误与给予应急车辆优先通行的情况下,设置了一组传统四相位控制交叉口,A={‘NS’,‘NSL’,‘WE’, ‘WEL’},分别为南北直行,南北左转,东西直行,东西左转.由于应急车辆行驶的特性,文中所建立的模型并不实行固定相位相序,在每一时间步内,智能体通过观测到的状态选取动作,根据其选取的动作,来为其方向上的车辆提供交叉口的通行权.本文设置绿灯时间持续10 s,智能体可能决定保持相同的动作或者更改动作.此外,当选取的动作不同于目前相位时,会出现一个用于过渡的3 s黄灯相位,此相位不在本次动作的选取集合中,此相位被当作是在交通信号控制系统内部自动执行.
2.3 奖励函数表示
奖励是独立计算的应急车辆奖励和社会车辆奖励的线性组合[10],为
(10)
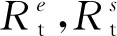
应急车辆的奖励为应急车辆在检测器覆盖区域内是否因红绿灯停车作为判断条件,由于考虑的是可能出现多辆应急车辆同时到达交叉口上游并竞争绿灯相位的情况,为了使应急车辆在智能体的控制下获取较为理想的通行速度,应急车辆奖励函数设计如下.
(11)
若应急车辆在交叉口由于遭遇红灯而停车,即v=0时,给予智能体一个较大的惩罚值,即:
b.The practice of making and serving tea is essential.(147)
(12)
这样设计奖励的目的是为了让智能体倾向于选择使应急车辆在交叉口不停车的动作,并尽可能地保证应急车辆的行驶速度.
对于社会车辆而言,由于应急车辆的出现属于小概率事件,在智能体决策过程中,其奖励值在多数情况下为0.但是由于智能体的控制过程不是去追求一个当前奖励最大化,而是在整个决策过程中,所有的奖励加权之和最大,而且智能体可以从过往的经验中学习,所以即使道路上没有应急车辆行驶,之前的决策也可当作是为应急车辆的优先控制决策做前期准备.设计的奖励函数应该能够保证在应急车辆通过后能够尽快的将交叉口恢复原有秩序,并在正常的交通环境下也能够提高社会车辆的通行效率.对于社会车辆的奖励设计,综合考虑了处于检测范围内社会车辆的排队长度与社会车辆延误因素,如果只考虑各排队长度的和最小,则智能体可能会更倾向于将交通流量较大的车道持续保持绿灯相位,而其他交通量较小的车道会一直持续为红灯相位,这将导致交通量小的车道上的车辆延误剧增,因此为了避免这一情况发生,借鉴文献[11-12]的奖励公式,将其改进为公式为
j=1,2,…,c
(13)
式中:qj为每条车道上检测区域内的社会车辆排队长度;j为交叉口进口车道编号;N为检测区域类社会车辆的总数;α为社会车辆i的累计等待时间;C为社会车辆可容忍的累计等待时间;α、η、ρ为大于0的常数系数.
可得到总的奖励函数,为
j=1,2,…,c
(14)
3 仿真实验及分析
图2为一个单点信号控制的双向四车道的交叉口,右转车道一直被允许通行,本文假定所有车辆的到达概率都服从泊松分布.由于应急车辆的出现具有突发性,所以本文中设置应急车辆从4个方向以随机概率驶入道路,且由于突发性与随机性,交叉口可能出现多辆应急车辆同时在不同进口道排队的情况[13-14].输入的社会车辆本文以作者于2019年7月于云南省曲靖市麒麟南路-南宁西路交叉口的实测数据为输入,为保证随机性,在训练开始时车辆输入以75%的概率直行和25%的概率转向随机输入到交叉口中,每次仿真输入车辆数在1 500~1 800辆浮动,输入车辆数是社会车辆数和应急车辆数的和.

图2 双向4车道交叉口
3.1 训练结果分析
为了评估本文中所提出的方法,利用现状配时和感应优先控制与每次仿真所得出的基本指标作为基本线[15-16],本文中所利用的感应优先为一旦应急车辆接近交叉口并被检测器检测到,便为这辆应急车辆提供优先信号控制.并将社会车辆累计延误、应急车辆累计延误与基本线进行对比,结果见图3,DDQN训练累计奖励见图4.
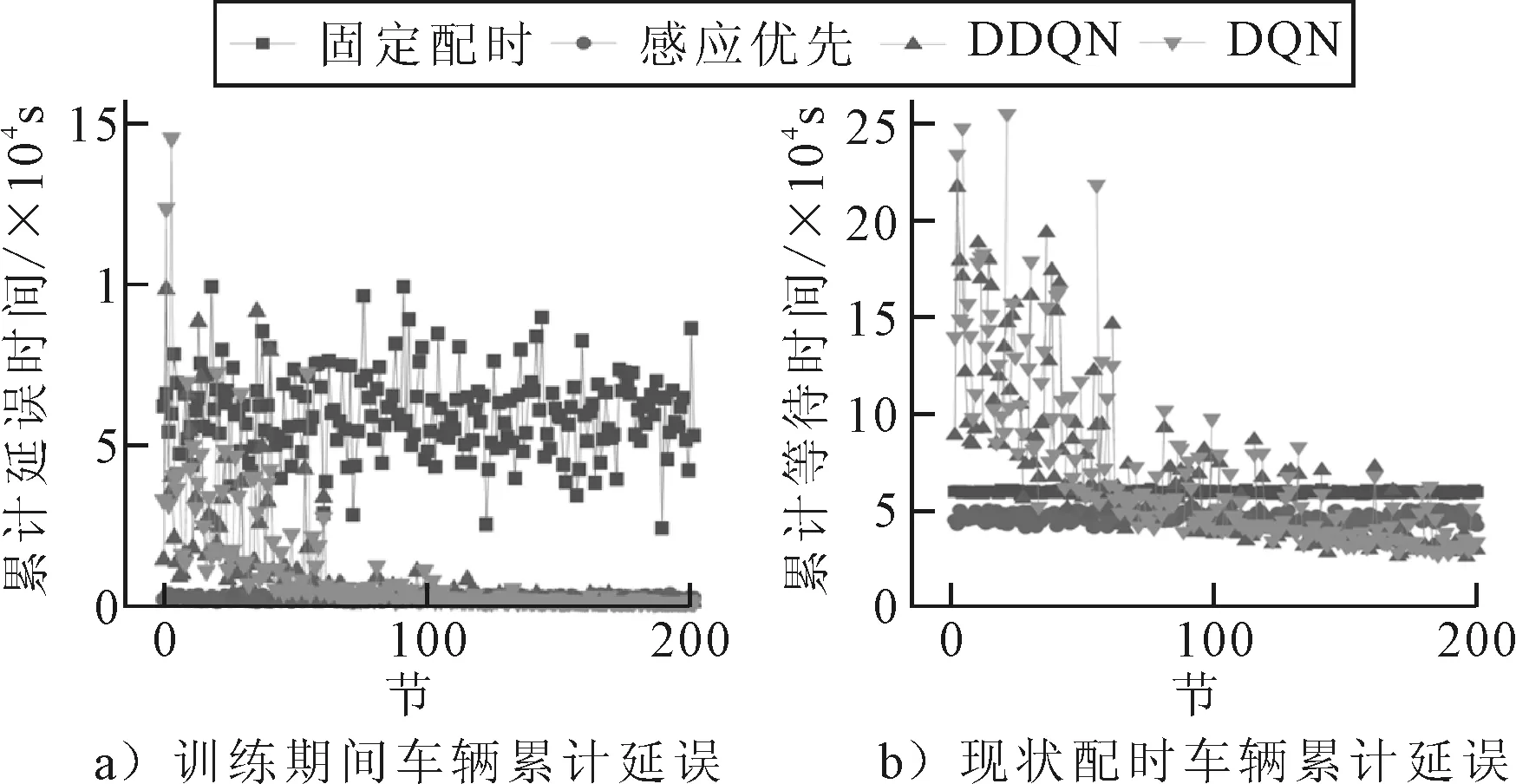
图3 训练期间车辆累计延误与现状配时车辆累计延误
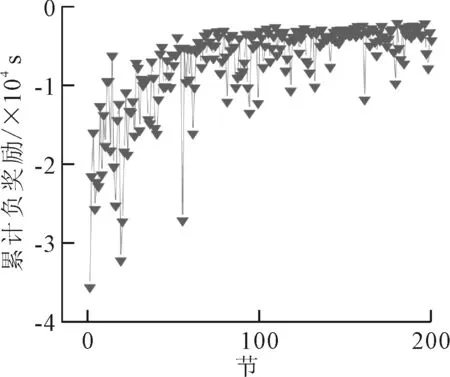
图4 DDQN每节累计奖励
由图4可知,DDQN交通控制智能体随着训练的逐步增加,性能在逐步提升中,并且由图3可知, DDQN方法随着训练轮次的增加,累计延误都比基线延误低,且稳定性较DQN好,所提出的方法性能明显优于现状配时与感应优先控制,同时,在减低应急车辆累计延误的情况下,社会车辆的累计延误也在逐步减少.
3.2 实验验证分析
分别采用高峰时期与平峰时期的流量进行验证,并在相同流量的情况下分别仿真10次且每次仿真应急车辆出现的概率不相等,所得结果取平均值.选用车辆平均延误、车辆平均旅行时间、车辆平均损失时间(损失时间为速度偏差时间,即车辆速度小于最大行驶速度的时间)作为本次实验验证的评价指标.平峰和高峰时间仿真结果分别见表1~2.
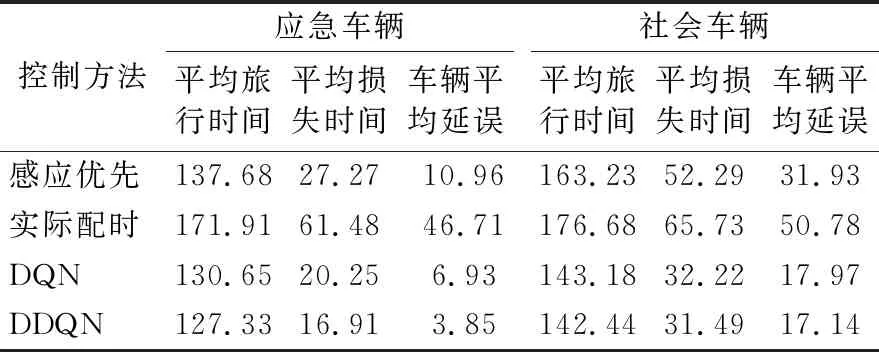
表1 平峰时段不同控制策略下仿真结果数据统计表 单位:s
由表1可知,利用本文所提出的方法相较于感应优先法、现状配时,本文所提出的基于深度强化学习的多应急车辆信号优先控制在平峰时间对比感应优先与实际配时分别能够减少应急车辆64.9%和91.8%的平均延误、7%和26.1%的平均行程时间以及38.0%和72.5%的平均损失时间,应急车辆在交叉口的通行效率大大提升,且速度更快.此外,在同时减少应急车辆延误与行程时间的情况下,对社会车辆在交叉口的通行效率也有显著提升,分别减少了46.3%和66%的平均延误、12.7%和19.3%的平均行程时间和39.8%和52.1%的平均损失时间.
由表2可知,采用本文所提出的方法相较于感应优先法、实际配时,在高峰时间对比感应优先与现状配时分别能够减少应急车辆84.70%和89.71%的平均延误、18.51%和38.5%的平均旅行时间以及70.70%和77.89%的平均损失时间,而在社会车辆方面分别能够减少27.38%和19.22%的平均延误、11.60%和7.40%的平均旅行时间以及23.15%和14.71%的平均损失时间.而在高峰时段,感应优先虽能够一定程度的减少应急车辆在交叉口的延误,但是却是在牺牲社会车辆正常通行的前提下完成的,对正常的交通流影响较大,容易造成道路拥堵,甚至引发二次事故.
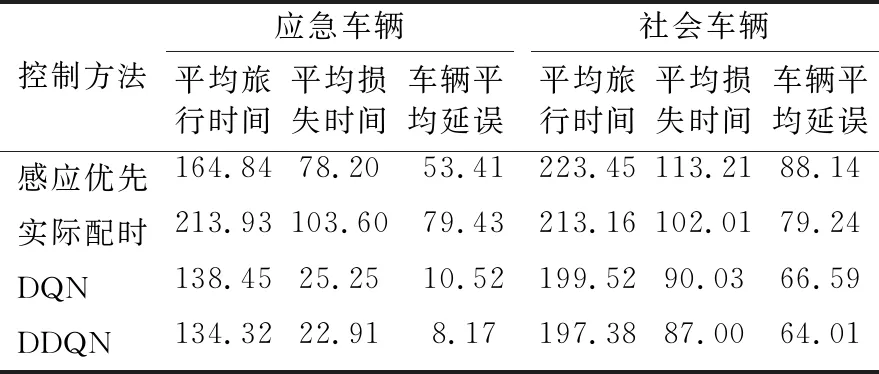
表2 高峰时段不同控制策略下仿真结果数据统计表 单位:s
文中提出的基于深度强化学习的多应急车辆优先控制方法是可行,当多辆应急车在交叉口同时需要优先通行的情况下,本文所提出的方法能够有在效减少应急车辆在交叉口行程时间与延误,同时也能够提高社会车辆的通行效率,且在高峰时段下与感应优先相比,本文的方法能够在不牺牲社会车辆正常通行的情况做到对应急车辆的最小延误,表现出了对实时交通环境的适应性并具有较强的鲁棒性.
4 结 论
1) 文中提出的一种基于深度强化学习的多应急车辆信号优先方法,通过对路况的实时监控、智能体自动收集车辆行驶信息,将车辆信息输入模型进行训练,从而获得最大的累计奖励,继而得到应急车辆的优先控制信号,避免了基于模型的优先控制方法的局限性.仿真结果表明,在不同的交通流量下,具有较强的鲁棒性,在交叉口可能出现多辆应急车辆同时到达的情况下,应急车辆平均延误时间减少了60%.
2) 文中提出的方法在考虑应急车辆优先通行的同时,也考虑了应急车辆在交叉口实施优先控制时对社会车辆的影响,减少了社会车辆的平均延误时间,保障了应急车辆通过后交叉口的正常通行秩序.
