基于相关度分析的分布式能源发电能力预测模型构建
2022-01-10刘春乐
杨 鸽,刘春乐,王 莹
(1.四川水利职业技术学院电力工程系,四川 成都 611231;2.山东泰开电力电子有限公司,山东 泰安 271000)
0 引 言
近年来,随着分布式能源的新增并网及电力储能设备的使用,可以预见在能源互联网这个概念范围内的各类相关数据将会呈现指数级增加,这种情况下就需要对所涉及的海量数据根据实际需要进行有效分析,最大限度地提取有价值的信息,优化能源的利用效率。因此,使用大数据技术对能源互联网所涉及的分布式发电系统进行应用建模研究,能够为能源互联网大数据技术在现实层面的应用提供一定的借鉴[1]。
对于分布式电站发电量预测所使用的数据,特点是数据量大、新数据产生快,当积累的数据量时间跨度变大,使用传统模型(逆变器模型、光照模型等)进行预测则会受到影响。目前,很多预测方法采用不同的机器学习算法,如模糊神经网络、灰色算法、灰色马尔科夫模型以及支持向量回归等[2]。这些方法在预测上都取得了一定的成功,但它们不能处理大数据,也不一定高效,因此急需一种有效的方案处理大体积复杂度高的数据集。
本文提出基于相关度分析的分布式发电能力预测方法,利用大数据技术,以影响分布式场站发电能力因素的相关度为切入点,通过算法根据历史数据做出预测。将影响因素进行分类,形成以相关度为分类根据的不同数据组,将分类好的数据组分别作为学习组进行神经网络训练,得到各组的学习模型。上述不同的数据组和学习模型再进行交叉融合学习,得到最终的预测模型,然后通过预测模型进行发电能力预测[3]。
1 影响因素确定
对分布式能源来说,定量因素(线性关系因素)包括气象情况、设备能量转化效率、设备温度损耗以及电缆线损等,是有据可查的数据,根据这些定量的数值可以直接得出较为准确的发电出力情况。而具体到分布式能源的某一个发电站来讲,发电设备和配套设备的故障时间、不同班组的生产运营管理能力、遮阴和逆变器及组件匹配不合理等设备安装因素、影响发电设备的环境因素等是固定存在的,并且对发电站发电能力有较大的影响,但此类因素对发电出力的影响是以概率形式存在的,无法准确地进行计算。
2 相关因素处理
2.1 定量因素处理
定量因素的处理根据具体场站积累的数据量不同分为两种情况,一种是新并网的分布式能源电站,另一种是运行超过一定时间(以一年为参考时间)的分布式能源电站。两种情况由于并网的时间不同,从而积累产生的数据量就有了区别,对于大数据分析来说,数据的量对于分析和决策有较大影响,故此两种情况都要考虑。
针对上述存在的两种情况,本文所使用的方法为在同一个模型中进行上述两种情况的分析,即在建模时将所有的相关因素都考虑到其中,在使用模型进行发电能力预测时,根据实际情况调整影响因素权值。
对于新并网的电站,统计其各个生产环节的设备,可根据能量转化效率或能量的损耗设定系数。在分布式能源场站中,单位数量的发电设备根据其说明书及铭牌参数,能够计算出固定的自然能源A转换为电能的效率,记为η。η即可认定为出力定量因素系数,作为新并网的电站,其设备因环境产生的损耗可忽略不计,故将相应的定量因素系数权值设置为0。
对于已积累了大量数据可供使用的场站,除了需要计算设备发电效率等系数,还要考虑因设备和线缆长时间运行所产生的出力效率影响。将现有数据进行整理,采用大数据技术中的相关性多因素影响分析模型,对每个因素进行分析后确定其系数。
2.2 定性因素处理
定性因素需要使用到大数据技术中的非线性数据拟合进行处理。在对上述定量因素进行处理之后,分析相同定量条件下不同时段所产生不同出力的原因。
3 分布式能源发电原理模型
对分布式能源电站进行定量因素和定性因素处理的发电出力模型预测功率P为:
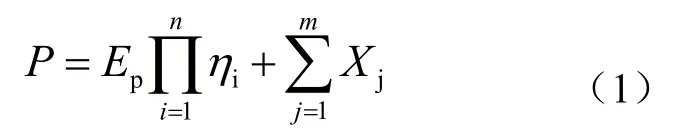
式中,Ep为当前外部环境条件下的理论功率,ηi为各线性影响因素的系数,Xj为非线性因素对系统的影响常数。等号右边的两部分和即为模型的预测出力。第一部分为定量因素,根据其对发电出力的影响特性,为各系数的乘积,各因素的系数是通过大数据技术中的线性回归求得;第二部分为定性因素,由于实际应用中各发电厂站情况不同,经过神经网络学习后可对其影响程度进行分析[4,5]。
4 大数据模型建立
本文所使用光伏实验数据的时间范围为24 h,步长5 min,但实际中在光照功率达不到发电阈值时,记录中的数据没有参考意义,需要根据光照量、发电量等判断条件进行清洗。提取记录中气象条件经过聚类分析所得的相关性强的因素作为数据集,Rapid Miner中K-Means聚类分析模型如图1所示。

图1 Rapid Miner中K-Means聚类分析模型
在上述基础上,以过去每个月的历史气象数据作为输入集,通过BP神经网络训练建立预测模型,将气象数据给出的温度、风向、风速以及光辐射量等信息作为输入量,得到所需的预测功率曲线。本文使用RapidMiner进行各因素的影响分析,加入相关性权重的神经网络模型如图2所示。
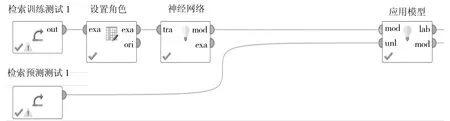
图2 Rapid Miner中神经网络聚类分析模型
5 具体场景分析
5.1 无历史数据的出力预测
对于无历史数据的出力预测,需要将其出力值假定为只受定量因素影响的理想模型,出力功率PI可表示为:

式(2)为式(1)忽略定性因素后的简化,其中各部分的意义与式(1)相同,为精确进行预测,将Ep的当前时间段细化为15 min,ηi为各线性影响因素的系数,根据线性影响因素对发电功率的影响进行乘积处理,其具体值可以通过术语大数据分析工具SPSS进行线性回归分析求得,对于数据较少的分析,也可通过简单的线性回归求得。
5.2 使用历史数据的出力预测
5.2.1 算法功能
基于相关度分析的分布式能源出力预测算法主要有以下功能。一是使用大数据工具Rapid Miner从历史数据中验证理论模型相关因素的相关度,即光照、温度以及设备维护周期等。二是根据相关度对因素进行分类,并针对性地分阶段对数据进行学习、预测,然后与实际值进行比对,接着再进行学习,生成预测。三是数据分析与学习细分为年、季度、月、天、时,针对不同的时间段有最适合的预测方法。四是发现理论模型中未包含的影响因素,如人员等。五是通过步骤2得出的经验参数,对另外的分布式发电站进行预测。
5.2.2 算法实施
本文采用某光伏电站的数据记录作为实验数据。在实验数据中,光伏站固定区域发电量以天为单位收集起来。不同区域的发电量和气象因素分类程度高,格式规范,且存放在本地CSV或类似XLS表格文件中,故使用体量小的Rapid Miner进行预测,可节约时间和软件部署成本。这些原始数据保存在分布式光伏电站的本地磁盘中,其分时环境数据和发电量数据可使用Rapid Miner轻易读取,即使用软件中的一个低级语言去提取数据特征。
具体预测过程如图3所示。首先,原始数据进行窗口化,生成窗口1和窗口2。其次,两个窗口再进行聚类和回归分析,生成相关度系数组1、2、3、4。最后,进行梯度神经网络的训练,生成的模型1、2、3、4和抽取结果的原始数据预测集一起进行融合学习优化最终生成发电能力预测结果。
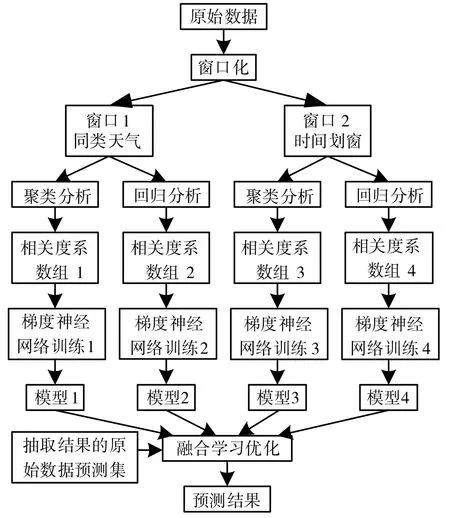
图3 发电能力预测过程
5.2.3 算法评估
在历史数据较为丰富的情况下,使用式(1)对分布式能源进行出力预测,其右侧的线性相关部分可根据式(2)的方法进行求解,但要注意的是,所选数据尽量根据每年相似时段进行分组,以排除因时间积累所产生的误差。另外,对设备进行保养、维护或清理等工作,也需计入到模型中。
Xj为非线性因素对系统的影响常数,其值通过建立模型、分析历史数据、排除线性因素影响后得出,在数据较为丰富的情况下,可对线性因素基本相同的数据分组,然后多次清除已确定的相关值后可得出。
评估算法的性能,比较2017年的发电量预测值与实际值,分别对分布式光伏电站各区域进行测试,评估算法的有效性。区域1和区域2的短时预测值与实际值如图4、图5所示,区域3的长时预测值和实际值如图6、图7所示。
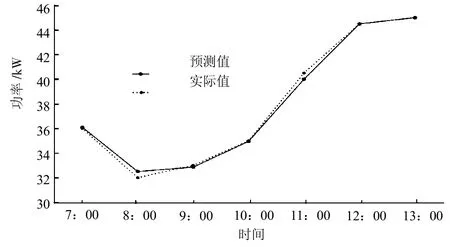
图4 区域1短时预测值与实际值
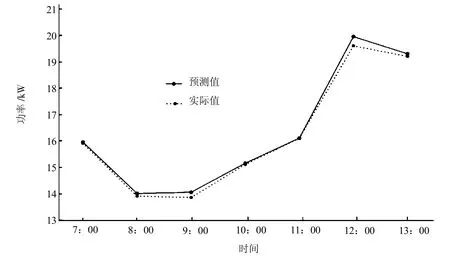
图5 区域2短时预测值与实际值
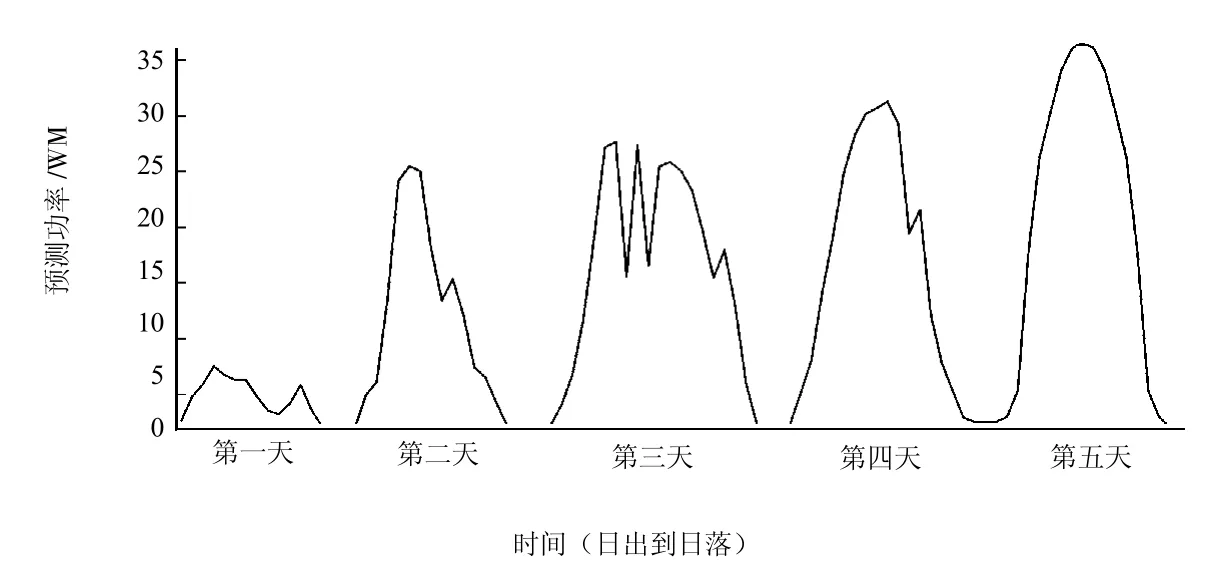
图6 区域3长时预测值

图7 区域3长时实际值
实验结果表明,模型被正确训练,误差率最小化,发电量预测值与实际值非常接近。本模型可以识别数据正确模式,准确进行预测。
6 结 论
本文提出了一个全面、可实行的分布式发电场站历史数据挖掘、实时数据预测功率的建模方法,利用相关度分析、系统聚类、K聚类等算法实现了对分布式发电场站功率和时、日等时间尺度变化规律的分析,并进行建模。根据本方法所建立的模型可使用Rapid Miner方便快捷地进行数据分析和预测,而且对于新场站、历史数据比较少或者数据还在积累过程中的情况,可进行实时学习和预测,并不断调整,在短时间内即可进行功率预测。
