融合车道线视觉增强的拟人化车道保持算法
2022-01-05李智覃小艺邓胜闫春香王玉龙
李智,覃小艺,邓胜,闫春香,王玉龙,2
融合车道线视觉增强的拟人化车道保持算法
李智1,覃小艺1,邓胜1,闫春香1,王玉龙1,2
(1.广州汽车集团股份有限公司汽车工程研究院,广东 广州 510641;2.湖南大学汽车车身先进设计制造国家重点实验室,湖南 长沙 410082)
基于深度学习端到端网络模型建立了拟人化车道保持算法,同时在模型训练过程中采用车道线视觉增强的方法,解决了直接由图像映射到控制信号使得自动驾驶容易受到干扰信息影响的问题,提高了模型的鲁棒性。首先基于GoogLeNet建立了高识别率的车道线检测模型,通过车道线高亮增强和增加车道线图像通道两种不同的方式对原始图像进行视觉增强。然后将增强后的图像输入到车道保持网络中。最终离线测试结果显示两种增强方式均可降低方向盘转角预测误差,RMSE值分别减少了16%和26%。实车测试表明增加车道线图像通道的方式取得较好的车道保持效果。
车道线检测;视觉增强;拟人化;车道保持
引言
车道保持是自动驾驶过程中的重要功能,一般是通过图像检测获得车道线并根据车道线参数确定行驶轨迹,然后利用相应的控制策略计算出方向盘转角大小[1-2]。但车辆在行驶过程中具有非线性、时变性和不确定性等特性,在控制过程中需要尽量平滑系统响应和保证车辆的乘坐舒适性,因此行驶轨迹的选择和控制策略的设计难度较大。同时,特殊工况下车道线可能会不清晰、被遮挡甚至丢失,使得车道保持模型失效。
人类驾驶员在开车过程中会根据车道线变化调整方向盘转角,在车道线不清晰或消失的情况下根据车辆周围环境确定行驶路线,因此人类驾驶行为对自动驾驶功能设计具有非常重要的借鉴意义,而拟人化车道保持算法就是通过深度学习网络模型来学习人类的驾驶行为。该算法通过网络模型直接将图像信息映射到车辆方向盘转角,不需要人为编写车道保持规则,只需要提供足够多的驾驶数据,模型可以自动学习不同场景下的车道保持能力。英伟达Bojarski[3]等人基于CNN网络模型建立了从单帧图像映射到车辆方向盘转角的端到端模型,其测试结果表明该模型在多种测试工况下,包括高速公路、有无车道线的地区道路以及乡村道路,均可取得良好的车道保持效果。Chowdhuri[4]等人通过在CNN网络中加入驾驶模式使得模型对方向盘转角进行更好的预测。焦新宇[5]等人采用场景切分和特征预提取的方法提高了CNN网络对高速公路行驶轨迹预测的准确性和可靠性。上述CNN网络并未考虑自动驾驶过程中涉及的时序问题,因此Chi[6]等人采用了CNN+LSTM的网络模型,通过图像序列对方向盘转角进行预测,相比文献[3]设计的模型更加稳定和有效。Chen[7]等人通过CNN网络识别出自动驾驶过程中的关键环境参数,并以此参数作为输入进行自动驾驶决策,输出对车辆的横向控制参数。
拟人化车道保持算法可以避免建立复杂的决策控制模型并增加车道保持功能的适用场景,但直接从传感器原始信号映射到车辆控制信号导致自动驾驶决策链条过长,模型易受到图像中干扰信息的影响,使得车辆在行驶过程中控制不稳定,偶尔出现偏离车道的现象。因此,为提高模型的安全驾驶能力,本文提出了针对车道线进行视觉增强的拟人化车道保持算法。首先建立高识别率的车道线检测模型,然后采用车道线高亮显示和增加车道线图像通道两种不同的方式对原始图像进行视觉增强,然后将增强后的图像输入到拟人化车道保持网络中,最后通过离线和实车测试验证模型的车道保持效果。
1 拟人化车道保持算法
1.1 拟人化车道保持算法架构
为提高网络模型在车道保持功能中的鲁棒性,本文建立了融合车道线视觉增强的拟人化车道保持算法,其架构如图1所示。首先选取前五帧图像作为输入序列,课题组基于GoogLeNet建立了高识别率的车道线检测模型,通过该模型获得车道线参数,然后利用两种不同的方式对车道线进行视觉增强:一种方式是直接对车道线进行黄色高亮显示,另一种方式是把检测出的车道线转化为二值图,并将其作为车道线通道与原始图像通道结合形成四通道图像,最后将增强后的图像输入到车道保持网络模型中,输出当前车辆方向盘转角的预测值。其中车道保持网络模型是通过采集图像数据和驾驶员驾驶行为数据,利用神经网络自动学习人类的驾驶行为,从而完成车道保持功能。

图1 拟人化车道保持算法架构
1.2 融合视觉增强的拟人化车道保持算法
拟人化车道保持网络模型结构如图2所示,网络输入为经过增强后的前向多帧图像以及方向盘转角和速度的历史轨迹,输出为预测的方向盘转角。网络整体结构由ConvLSTM神经网络层(Convolutional Long Short-Term Memory)和全连接网络层(Full Connection, FC)组成。文献[3]中采用了卷积神经网络(Convolutional Neural Network, CNN)对方向盘转角进行预测,虽然CNN网络可以有效提取图像特征,但却无法获得图像间的时序关系,而自动驾驶本身是一个时序过程,时序变化对车辆控制参数具有重要影响。ConvLSTM是将LSTM网络中的全连接网络替换为卷积神经网络,使其不仅可以像LSTM一样建立图像之间的时序关系,而且可以像CNN一样刻画局部空间特征,实验结果也表明ConvLSTM在获取时空关系上比LSTM有更好的效果[8]。

图2 拟人化车道保持算法结构
本文中输入的图像帧数为5帧,即包括当前帧在内的前5帧图像,经过裁剪和缩放后图像大小为5×240×75×4。ConvLSTM网络一共包括5层,不同层的超参数为[5,5,4,24]、[5,5,24,36]、[5,5,36,48]、[3,3,48,64]、[3,3,64,64],其中前两个超参数为图像序列宽和高的卷积核大小,第三个超参数为输入图像的通道数目,第四个是输出图像的通道数目,最终ConvLSTM网络层输出的特征维度为[1,10,4,64],即网络输出由64个10x4的图像块表示,将图像块进行展平获得维度为[1,256 0]的特征向量。FC层共包括5层,在第二个FC层拼接了速度和方向盘转角的历史轨迹,输出层激活函数为反正切函数,输出方向盘转角的预测值。
2 训练数据采集与处理
拟人化车道保持模型是基于人类驾驶数据进行模型训练,因此数据对自动驾驶能力具有很大的影响。通过车辆前端安装的摄像头采集车辆行驶环境数据,摄像头FOV角度为60°,采集频率为10 Hz,图像尺寸为960×604,采集图像样本不少于30万张,同时利用车载传感器采集驾驶行为数据,包括车辆方向盘转角、速度以及车辆横摆角速度等,采集频率为10 Hz,采集的场景包括不同时间、道路、天气、光线以及车流等。
在自动驾驶行驶过程中,所遇到的场景非常复杂,为了提高模型的泛化能力和鲁棒性,需要针对采集的数据进行数据增强,如图3所示,基于车辆行驶环境的变化,本文主要对图像进行光线调整、阴影处理、平行移动、翻转以及加入高斯噪声等处理。

3 网络训练与结果
3.1 拟人化车道保持网络损失函数
拟人化车道保持网络模型输入为经过增强后的前向多帧图像以及方向盘转角和速度的历史轨迹,输出为当前方向盘转角预测值,其中I表示输入的原始图像序列,L表示检测的车道线通道序列,T表示输入的方向盘转角和速度的历史轨迹,表示网络中的优化参数,表示网络的表达式,Y表示网络预测的方向盘转角,y表示驾驶员输出的实际方向盘转角,最终的优化函数为公式(1)所示,为正则化权重系数,取值为1e-5。
=argmin{(y−(I,L,T,))2+2} (1)
3.2 拟人化车道保持网络模型训练结果
为评估不同模型的预测性能,本文采用均方根误差()和方(2)进行评价[5]。和2的表达式如公式(2)所示,是预测值和实际值之间的平均偏差,的值越小代表模型的预测值和实际值的偏差就越小,模型的预测能力就越强。2是用1减去模型预测偏差与实际方差的比值,2代表可解释方差占总方差的比例,反映了模型对样本的拟合程度,因此2的值越大表示模型预测的精度越高,一般回归模型的2应该在0.7以上才会取得较高的可信度。
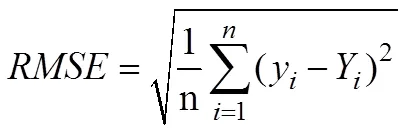

图4所示为模型在直道、弯道以及急转弯等场景下,无车道线视觉增强和两种不同增强方式对方向盘转角的离线预测结果。车辆首先经过一段直道行驶,然后通过一个急转弯,之后再进入直道行驶,最后经过一个长距离的弯道,时间总长度为200 s。从曲线图中可以看出,无论是否对车道线进行视觉增强,方向盘转角的预测值与实际驾驶员输出值均比较吻合,但经过车道线视觉增强后预测的方向盘转角与实际驾驶员输出值更加接近。三种不同方式的方向盘转角值分别为3.1°、2.6°和2.3°,相对于无视觉增强的方式,高亮显示增强方式的方向盘转角值减少了16%,而增加车道线图像通道的增强方式则减少了26%。同时三种不同方式的2分别为0.87、0.91和0.93,相对提高了4.6%和6.9%。从放大图中可以看出,在没有车道线视觉增强的情况下,模型容易受到图像中干扰因素的影响,使得预测过程中出现干扰点,导致车辆运行不平稳,而采用车道线视觉增强的方式使得模型更多的关注车道线,从而减少了干扰点的产生,同时增加车道线图像通道的增强方式改善效果更加明显。

4 实车测试
采用电动车作为线控平台(图5(a)),挡风玻璃处安装有单目摄像头,控制器采用英伟达drivePx2,控制软件基于ROS系统开发。网络模型输出为方向盘转角,通过车载EPS系统进行闭环。测试区域选择图5(b)所示的岛内区域,主要测试路线为环岛路线,全长为5公里,测试过程中涉及直道、弯道、急转弯以及路口。实车测试结果表明,不同模型均可完成绕岛行驶,而增加车道线图像通道的增强方式运行更加平稳,图5(c)和5(d)为模型顺利通过急弯和路口。

图5 实车测试场景
5 结论
(1)建立了融合车道线视觉增强的拟人化车道保持算法,通过和2对不同模型性能进行量化评估,离线测试结果表明采用车道线高亮显示和增加车道线图像通道两种不同的方式均可降低方向盘转角预测误差,值分别减少了16%和26%。
(2)搭建了自动驾驶实车测试平台,针对3种不同网络分别进行了小曲率车道保持测试、大曲率弯道保持测试以及无车道线路口通过测试,测试结果表明,增加车道线图像通道的方式取得较好的效果。
[1] 张海林,罗禹贡,江青云,等.基于电动助力转向的车道保持系统[J].汽车工程,2013,35(6):526-531.
[2] 李进,陈杰平,易克传,等.不同光照下基于自适应图像阈值的车道保持系统设计[J].机械工程学报,2014,50(2):146-152.
[3] Bojarski M, Del Testa D, Dworakowski D,et al. End to end learning for self-driving cars[J]. arXiv preprint arXiv,1604.07316, 2016.
[4] Chowdhuri S,Pankaj T,Zipser K.MultiNet: Multi-Modal Multi-Task Learning for Autonomous Driving[C].2019 IEEE Winter Conference on Applications of Computer Vision (WACV),2019:1496-1504.
[5] 焦新宇,杨殿阁,江昆,等.基于端到端学习机制的高速公路行驶轨迹曲率预测[J].汽车工程,2018,40(12):1494-1499.
[6] Chi L, Mu Y. Deep steering: Learning end-to-end driving model from spatial and temporal visual cues[J].arXiv preprint arXiv,1708.03798, 2017.
[7] Chen C,Seff A, Kornhauser A,et al.Deepdriving: Learning affordance for direct perception in autonomous driving[C].Proceedings of the IEEE International Conference on Computer Vision,2015: 2722-2730.
[8] Xu H, Gao Y, Yu F, et al. End-to-end learning of driving models from large-scale video datasets[C].Proceedings of the IEEE conference on computer vision and pattern recognition,2017:2174-2182.
Human-imitative Lane Keeping Algorithm with Visual Enhancement of Lane Lines
LI Zhi1, QIN Xiaoyi1, DENG Sheng1, YAN Chunxiang1, WANG Yulong1,2
( 1.Auto Engineering Research Institute, Guangzhou Automobile Group, Guangdong Guangzhou 510641;2.State Key Laboratory of Advanced Design and Manufacturing for Vehicle Body, Hunan Changsha 410082 )
Human-imitative lane keeping algorithm is established based on the end-to-end deep learning neural network model. At the same time, the lane line visual enhancement method is used in the model training process, which solves the problem that the automatic driving is easily affected by the interference information when the image is directly mapped to the control signal. Firstly, a lane detection model with high performance is established based on GoogLeNet. The original image is enhanced by two different ways: highlight the detected lanes on the image or add an image channel with detected lanes to the RGB channel.Then, the enhanced image is input into the lane keeping network. Off-line test results show that both enhancement methods can reduce the prediction error of steering angle, and RMSE values are reduced by 16% and 26% respectively. Real world test results show that the lane keeping performance is better by adding the lane image channel.
Lane detection;Visual enhancement;Human-imitative;Lane keeping
U495
B
1671-7988(2021)23-16-04
U495
B
1671-7988(2021)23-16-04
10.16638/j.cnki.1671-7988.2021.023.005
李智,硕士研究生,高级技术经理,就职于广州汽车集团股份有限公司汽车工程研究院,研究方向为人工智能与自动驾驶。
湖南大学汽车车身先进设计制造国家重点实验室开放基金资助项目(编号:31825011)。
