一种简化门控结构的增强序列文本语义匹配模型研究
2022-01-04黄静陈新府豪
黄静 陈新府豪




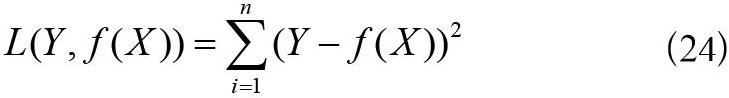
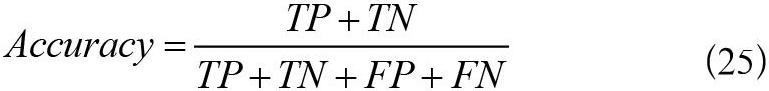
摘 要:在自然语言处理的文本相似度匹配方面,针对长短期记忆网络拥有多个控制门层,导致其在训练过程中需要一定的硬件计算能力和计算时间成本,提出一种基于Bi-GRU的改进ESIM文本相似度匹配模型。该模型在双向LSTM(BiLSTM)的ESIM模型的基础上,通过Bi-GRU神经网络进行数据训练,提高模型的训练性能。实验表明,在公开数据集QA_corpus和LCQMC上分别进行测试,改进后的ESIM模型较之原先模型,在结果数据对比图中,绝大部分组的损失函数数值均小于原先模型,准确率数值均大于原先模型。
关键词:相似度匹配;双向长短期记忆网络;Bi-GRU;ESIM
中图分类号:TP391.1 文献标识码:A
文章编号:2096-1472(2022)-01-50-05
Abstract: In terms of text similarity matching in natural language processing, the long and short-term memory network has multiple control gate layers, which requires a certain amount of hardware computing power and computing time cost during the training process. Aiming at these problems, this paper proposes an improved ESIM (Enhanced Sequential Inference Model) text similarity matching model based on Bi-GRU. Based on the ESIM model of bidirectional LSTM (Long Short-Term Memory), the proposed model is trained by Bi-GRU neural network to improve the training performance of the model. The improved ESIM model is tested on QA_corpus and LCQMC (Large-scale Chinese Question Matching Corpus) respectively. Test results show that compared with the original model, the loss function values of most groups are lower than the original model, and the accuracy values are higher than the original model.
Keywords: similarity matching; bidirectional LSTM; Bi-GRU; ESIM
1 引言(Introduction)
相似度匹配是自然語言处理领域的一个重要分支[1],是问答系统[2]、信息检索[3]及对话系统[4]等领域的关键技术之一。在基于概率和统计方法方面的研究中,BERGER等[5]提出应用统计模型,将检索词拓展到近义词,增大检索范围。郭庆琳等[6]通过适当增加词频改进DF算法,弥补个别有用信息的误滤,并将特征项在特征选择阶段的权重应用到文档集合,改进TF-IDF算法,提高其精度。石琳等[7]通过调整特征项的权重改进TF-IDF算法,优化权重计算。张奇等[8]提出三对向量分别代表TF-IDF、bi-gram、tri-gram的值,通过回归模型计算得出相似度。
基于概率、统计方法的相似度匹配在实际运用中取得不错的效果,但随着深度学习在图像、语音方面的发展,学者们开始利用深度学习模型进行自然语言处理[9]。深度学习模型特征能够自动提取,并且相比于前者泛化性能更好。HUANG等[10]提出以输入、表示、匹配三层为架构的DSSM模型;ZHOU等[11]提出BiLSTM双向长短期记忆网络模型;GERS等[12]在LSTM的基础上,增加了窥视孔连接;CHEN等[13]提出以双向LSTM(BiLSTM)和tree-LSTM为结构的ESIM模型,此外还有多种LSTM的变体研究。LSTM因自身存在多个控制门层,每个单元需要四个线性层,因此训练时需要较大的存储带宽。
针对LSTM网络的不足,本文采取在LSTM基础上将忘记门和输入门融合的GRU网络融合ESIM模型,提出基于Bi-GRU的改进ESIM文本相似度匹配模型,在实际计算任务中相比于改进之前收敛速度加快。
2 相关模型介绍(Introduction to relevant models)
2.1 Word2vec模型
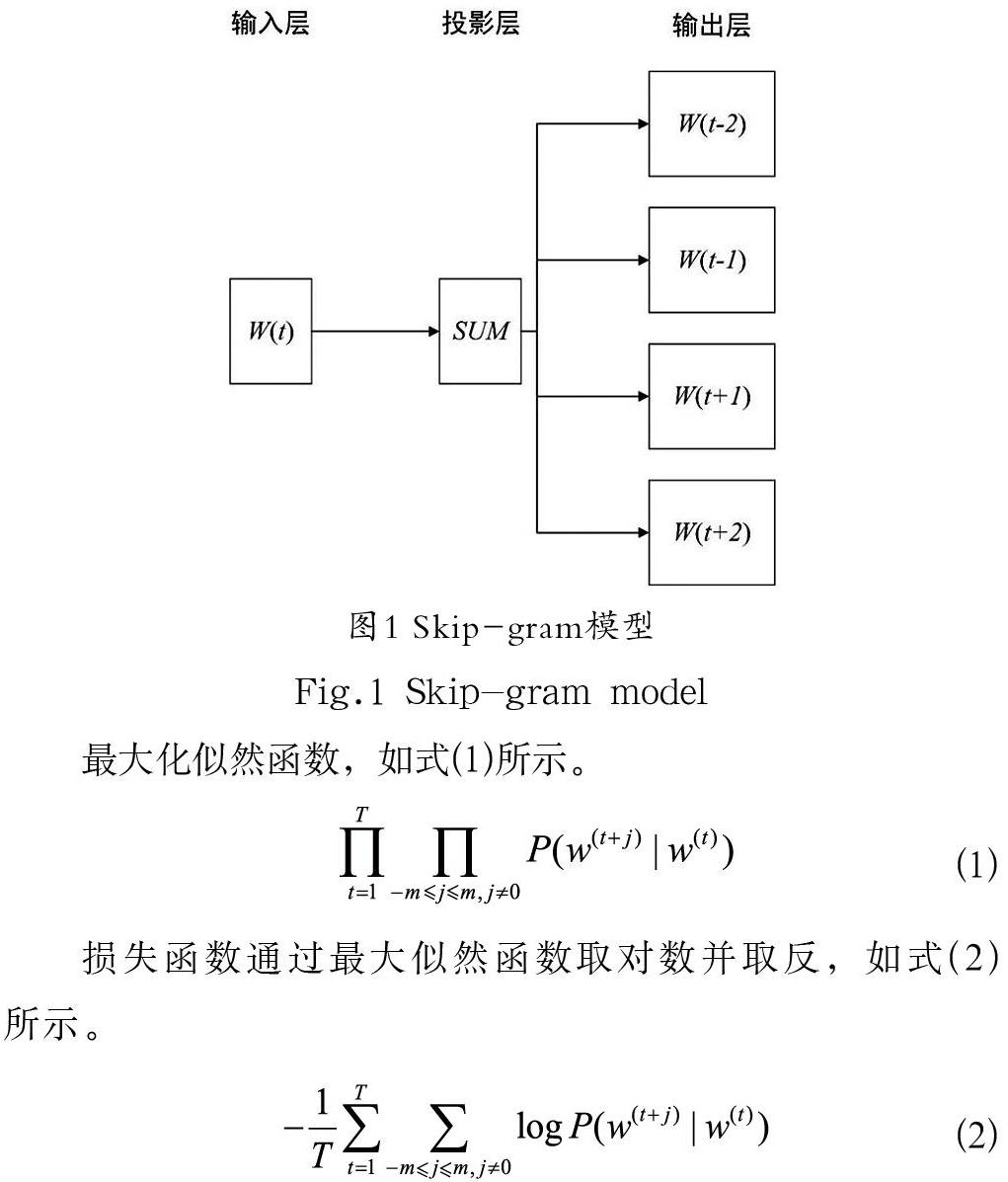
Word2vec模型是2013 年Goolge开源的一款词嵌入模型,用于将文本内容生成词向量,投影到向量空间以便后续做向量运算,其中包括连续词袋CBOW和跳字Skip-gram两种模型。
本文使用Skip-gram模型,通过词本身来预测其上下文。该模型结构分为三层,分别为输入层、投影层、输出层,具体如图1所示。
最大化似然函数,如式(1)所示。
损失函数通过最大似然函数取对数并取反,如式(2)所示。
在式(2)中,m表示窗口大小并大于零,T表示训练文本大小。Skip-gram模型计算条件概率即根据给定词推测其上下文词汇的概率,如式(3)所示。
2.2 LSTM模型
RNN属于时间序列网络,能存储历史信息,但在序列过长的情况下会产生梯度消失的问题[14]。LSTM作为RNN的特殊形态,用于处理该问题。LSTM的网络结构包含三个门层,分别是用于保留或删除上一时刻状态的忘记门层、用于决定保存输入当前时刻的输入门层,以及用于控制当前时刻输出的输出门层。具体的模型结构如图2所示。
忘记门公式如式(4)所示。
忘记门通过sigmoid激活函数实现,当其值为1时,表示保留信息;当其值为0时,表示舍弃信息。
输入门公式如式(5)—式(7)所示。
输入门也可成为更新门,用于更新当前网络单元的状态,通过sigmoid、tanh激活函数协同调节网络,来决定更新哪些信息。
输出门公式如式(8)、式(9)所示。
输入门和单元状态共同决定輸出,即LSTM的最终输出[15]。
2.3 GRU模型
GRU(Gated Recurrent Unit)模型是LSTM模型的一种特殊类型,其结构是在LSTM的基础上,将忘记门和输入门融合并混合单元状态和隐藏状态,得到只含更新门和重置门的结构模型。更新门控制上一时刻状态信息流入当前时刻的程度,重置门是控制上一时刻状态信息写入当前时刻的阀门。具体的结构模型如图3所示。
更新门公式如式(10)所示。
重置门公式如式(11)所示。
GRU模型的单元输出公式如式(12)、式(13)所示。
由于GRU相比于LSTM的结构更加简化,因此在循环神经网络的长依赖问题方面展现出更好的性能。
2.4 ESIM模型
ESIM模型的英文全称为Enhancing Sequential Inference Model,是一种为自然语言推断而生的加强版LSTM[16]。其工作原理为:通过给定的前提推导出假设,再由损失函数判断和的关联程度,当此模型进行文本相似度匹配时,损失函数的工作从判断推理与假设之间的关联转向判断两序列是否同义。
ESIM模型有双向LSTM(BiLSTM)和tree-LSTM两种结构,分为四层,分别是输入编码层(Input Encoding)、局部推理模型层(Local Inference Modeling)、推理合成层(Inference Composition)、池化层(Pooling)。本文为了高效简洁,选择BiLSTM结构进行研究,具体的结构模型如图4所示。
输入编码层的输入结构为已训练完成的词向量或添加词嵌入层,再将输入通过双向LSTM(BiLSTM)网络对输入值进行编码,即特征提取。输出结果为和,如式(14)、式(15)所示,其中和即为前提和假设。
(2)Local Inference Modeling
局部推理模型层是将特征值做差异性处理,引入注意力机制,上一层的输出和的注意力权重矩阵计算公式如式(16)所示。
再根据注意力权重计算a和b权重加权后的值,计算公式如式(17)、式(18)所示。
此处的计算方法是与做加权。同理,的计算方法也是与做加权。
得到计算出的编码值和加权编码值后,再对其做差异性计算,通过将编码值和加权编码值进行相减、相乘再拼接,结果向量如式(19)、式(20)所示。
(3)Inference Composition
推理合成层用于捕获和的局部推理信息及其上下文信息,再进行推理组合操作,将值送入池化层,对其进行最大池化和平均池化的操作并拼接得到固定长度的向量,最后将值送入全连接层与softmax输出层。计算公式如式(21)—式(23)所示。
3 实验(Experiment)
本次实验使用TensorFlow为深度学习框架,通过jieba分词分解文本,并以Word2vec将词转换为词向量,利用Bi-GRU网络搭建ESIM模型,最后分别在两个公开数据集上进行模型的训练学习,检测改进后的ESIM模型相比于改进前的ESIM模型的损失函数,以及准确率伴随不断迭代的收敛性能。
3.1 实验环境
本文训练模型所处的实验环境和硬件相关的配置如表1所示。
3.2 实验数据集
本文训练模型时使用的公开数据集分别是QA_corpus和LCQMC。其中,公开数据集QA_corpus的训练数据为100,000 条,验证数据为10,000 条,测试数据为10,000 条,并有人工标注标签1和0,表示语义相似与否。LCQMC是哈尔滨工业大学在自然语言处理国际顶会COLING2018上构建的语义匹配数据集,其中训练数据为238,876 条,验证数据为8,802 条,测试数据为12,500 条,并有人工标注标签1和0,表示语义相似与否。
3.3 参数设置
本文模型的实现主要基于Python和TensorFlow。其中,模型训练的相关参数分别如下:词向量的维度设为100 维,嵌入隐层单元数设为512 维,上下文隐层单元数设为256 维,学习率设为0.001,每个批次的训练数据数设为1,024,训练的总轮次数设为50 次。
为了在训练过程中避免过拟合现象的产生,设置Dropout参数[17]。本文将Dropout值的大小设为0.7,该参数的含义是指在向前传播过程中,以一定的概率让某神经元的激活值停止工作,进而使网络变得稀疏,模型的泛化能力更强,从而减少局部特性的依赖和不同特征之间的协同效应[18]。
3.4 实验结果及分析
将本文提出的改进Bi-GRU-ESIM模型和原始ESIM模型进行训练效果对比,以相同的参数及超参数设置在两个公开数据集上训练,完成两组对比实验。将损失函数和准确率作为衡量模型训练的性能,同时记录且对比评估50 次总训练轮数的完成时间。
本文采用平方损失函数作为描述性能的标准之一,如式(24)所示。先进行反向传播,将数据值代入损失函数,通过梯度下降更新网络中的参数,再让正向传播过程中的损失函数不断减小[19],随着训练次数的增加,损失函数数值由大变小趋于稳定,代表训练完成。
准确率(Accuracy)随着迭代次数的增加呈现由小到大的变化,并趋于最终稳定,定义如式(25)所示。
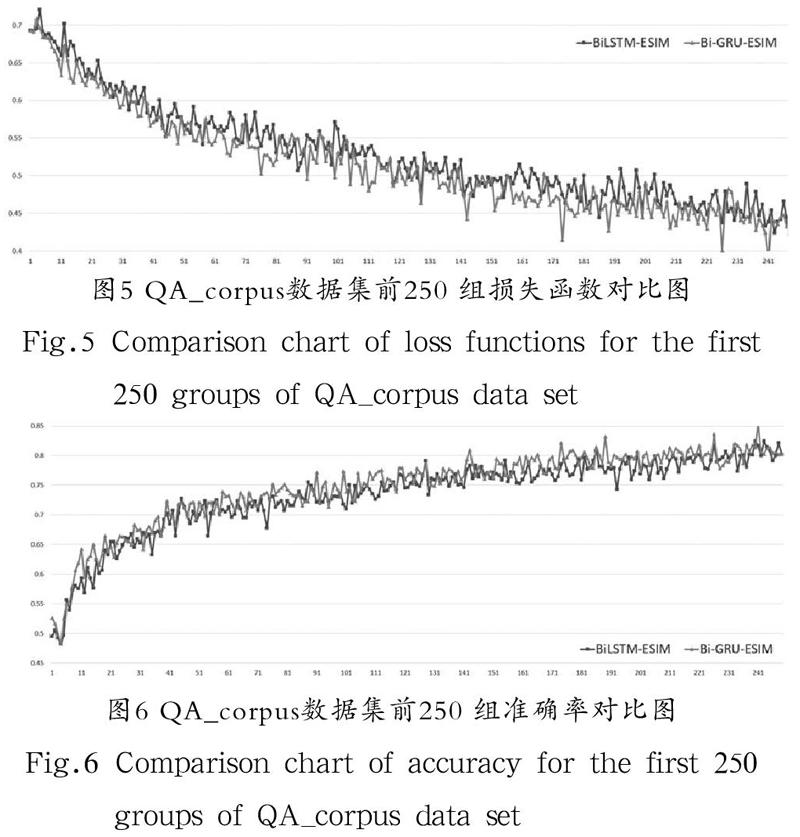
在公开数据集QA_corpus上训练,总数据量为100,000 条,每批次训练数为1,024 条,训练总轮数为50 次。在训练过程中打印出每一批次的损失函数和准确率,得到4,851 组迭代数据,将改进前后的实验结果绘图对比,分析模型的学习效果。由于数据密集,并且损失函数和准确率收敛最终趋于平稳之后的数据接近重合,因此截取前250 组收敛速率明显的数据对比以便更加直观。损失函数对比如图5所示,准确率对比如图6所示。
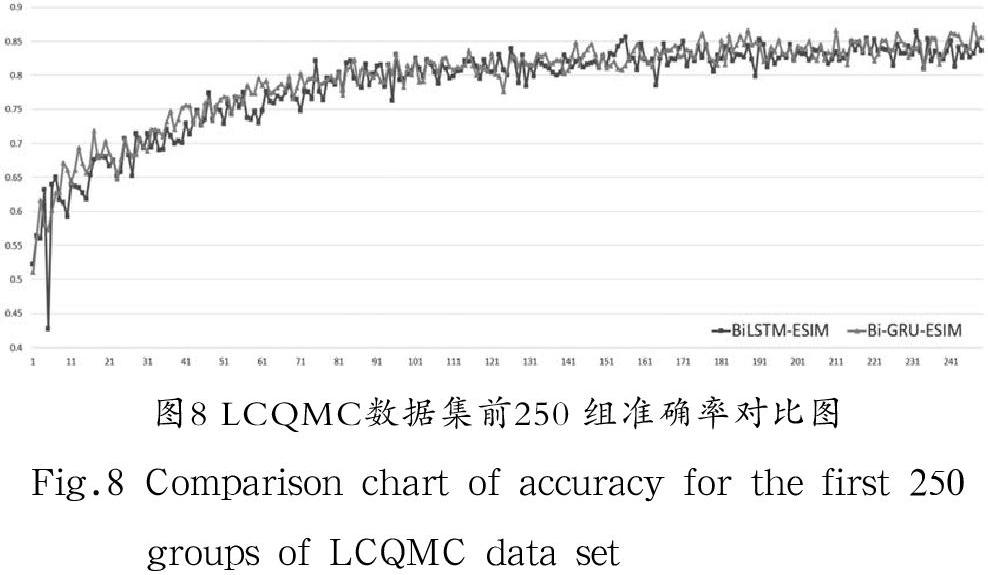
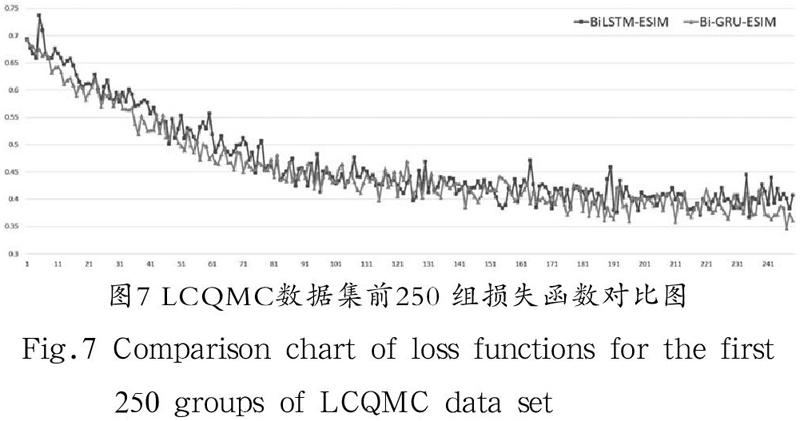
在公开数据集LCQMC上训练,总数据量为238,876 条,每批次训练数为1,024 条,训练总轮数为50 次。在训练过程中通过程序打印出每一批次各个迭代步骤的损失函数和准确率,得到11,651 组迭代数据,将改进前与改进后的数据绘制成折线图对比,分析训练效果。由于数据密集,并且损失函数和准确率收敛最终趋于平稳之后的数据接近重合,因此截取前250 组收敛速率明显的数据对比以便更加直观。损失函数对比如图7所示,准确率对比如图8所示。
改进前后两模型分别在两个数据集上完成训练所需的时间如表2所示。
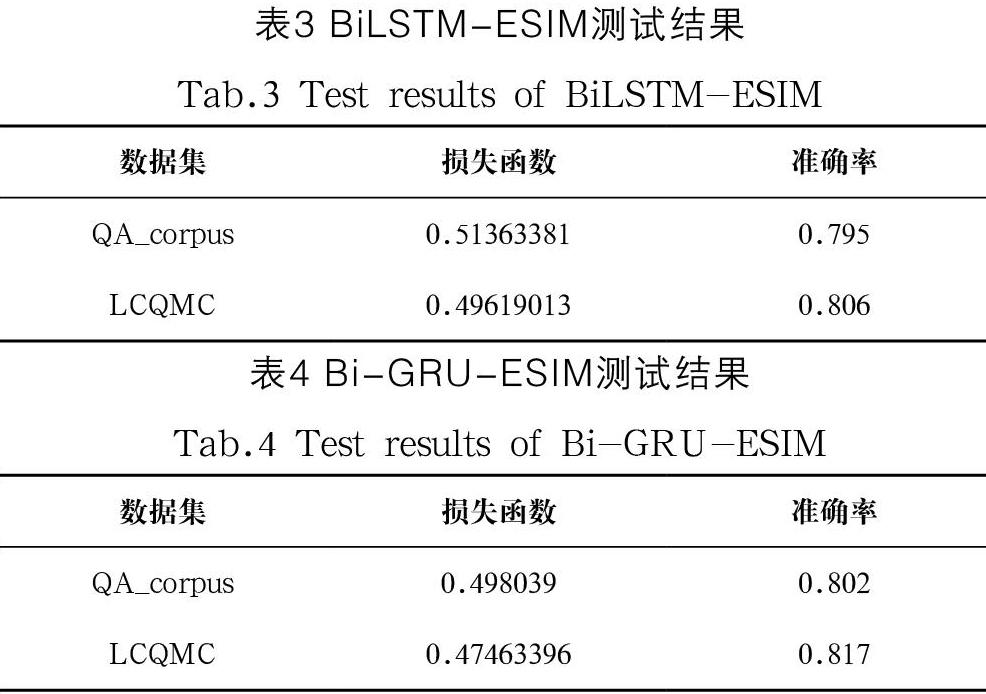
改进前后两模型分别在QA_corpus和LCQMC提供的测试数据上测试得到的损失函数和准确率如表3、表4所示。
本文的实验结果分析如下:
(1)由图5和图6中的数据对比可以得出,随着训练的不断迭代,Bi-GRU-ESIM模型的损失函数的下降收敛和准确率上升收敛速度在相同迭代步数下要比BiLSTM-ESIM模型更快。
(2)由图5和图7相比,图6和图8相比,LCQMC数据集数据量是QA_corpus数据集数据量的2.4 倍,可以得出在训练数据量较少的情况下,Bi-GRU-ESIM模型训练的收敛速度比BiLSTM-ESIM模型更快。
(3)由表3和表4可以得出,改进后的Bi-GRU-ESIM模型较之改进前的模型在准确率测试方面较为相近。但在结合表2分析下得出,Bi-GRU-ESIM模型与BiLSTM-ESIM模型达到相同的准确度性能时,改进后的模型完成训练所需要的总时间比改进前的模型完成训练需要的总时间要少。
4 结论(Conclusion)
本文提出的基于Bi-GRU的改进ESIM文本相似度匹配模型与基于BiLSTM-ESIM的模型相比,在训练的收敛速度上有所提升,并且在训练数据较少的情况下,因Bi-GRU-ESIM模型的门层较少,所以训练的收敛速度更快。虽然ESIM模型在改进前后的测试效果接近,但在模型训练的时间上,Bi-GRU-ESIM模型所需要的学习时间更少,这就意味着与改进前的ESIM模型相比,改进后的ESIM模型达到相近的效果所需要的硬件资源和计算成本更少,因此改进后模型的学习性能有所提高,具有一定的实用价值和现实意义。
由于此次改进只针对优化学习速率,对于提高模型准确度方面实际效果差别不大,因此在提高模型学习性能的基础上优化模型的准确率将是下一步研究的重点和方向。
参考文献(References)
[1] 周艳平,朱小虎.基于正负样本和Bi-LSTM的文本相似度匹配模型[J].计算机系统应用,2021,30(04):175-180.
[2] 侯莹,陈文胜,王丹宁,等.智能问答技术在网络运维服务中的研究[J].软件工程,2020,23(09):9-12.
[3] 张超,陈利,李琼.一种PST_LDA中文文本相似度计算方法[J].计算机应用研究,2016,33(02):375-377,383.
[4] 刘征宏,谢庆生,李少波,等.基于潜在语义分析和感性工学的用户需求匹配[J].浙江大学学报(工学版),2016,50(02):224-233.
[5] BERGER A, LAFFERTY J. Information retrieval as statistical translation[J]. ACM SIGIR Forum, 2017, 51(2):219-226.
[6] 郭庆琳,李艳梅,唐琦.基于VSM的文本相似度计算的研究[J].计算机应用研究,2008(11):3256-3258.
[7] 石琳,徐瑞龍.基于Word2vec和改进TF-IDF算法的深度学习模型研究[J].计算机与数字工程,2021,49(05):966-970.
[8] 张奇,黄萱菁,吴立德.一种新的句子相似度度量及其在文本自动摘要中的应用[J].中文信息学报,2005(02):93-99.
[9] 王寒茹,张仰森.文本相似度计算研究进展综述[J].北京信息科技大学学报(自然科学版),2019,34(01):68-74.
[10] HUANG P S, HE X, GAO J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// QI H, ARUN I, WOLFGANG N, et al. Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management. New York, United States: ACM, 2013:2333-2338.
[11] ZHOU P, SHI W, TIAN J, et al. Attention-Based bidirectional long short-term memory networks for relation classification[C]// ERK K, SMITH N A. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Berlin, Germany: The Association for Computer Linguistics, 2016: 207-212.
[12] GERS F A, SCHMIDHUBER J. Recurrent nets that time and count[C]//LEWIS R D, KENNEDY J, ANDRUSKIEWICZ M, et al. EEE-INNS-ENNS International Joint Conference on Neural Networks. Como, Italy: IEEE, 2000:189-194.
[13] CHEN Q, ZHU X, LING Z, et al. Enhanced LSTM for natural language inference[C]// MOHIT B, HENG J. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017:1657-1668.
[14] YOUSFI S, BERRANI S, GARCIA C. Contribution of recurrent connectionist language model in improving LSTM-based Arabic text recognition in videos[J]. Pattern Recognition, 2017, 41(5):245-254.
[15] 陶永才,吴文乐,海朝阳,等.一种结合LSTM和集成算法的文本校对模型[J].小型微型计算机系统,2020,41(05):967-971.
[16] 马宇生.基于深度文本匹配模型的智能问答系统问题相似度研究[D].上海:上海师范大学,2020.
[17] 黄建强,赵梗明,贾世林.基于biLSTM的新型文本相似度计算模型[J].计算机与数字工程,2020,48(09):2207-2211,2278.
[18] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1):1929-1958.
[19] 卢超.基于深度学习的句子相似度计算方法研究[D].太原:中北大学,2019.
作者简介:
黄 静(1965-),女,博士,教授.研究领域:通信工程,大数据,深度学习.
陳新府豪(1996-),男,硕士生.研究领域:嵌入式与物联网,智能信息处理.
