油藏规模序列法在玛湖凹陷低勘探程度区油气资源评价中的应用
2021-12-08蒋文龙郭文建杨海波
李 婷,王 韬,蒋文龙,王 硕,郭文建,杨海波
(中国石油新疆油田分公司,新疆 克拉玛依 834000)
0 引 言
油气资源评价方法是进行油气资源评价的直接手段,选取合适的方法开展油气资源评价对于明确资源潜力、确定勘探和投资方向、制订远景开发规划和宏观经济政策等都具有重要意义[1-2]。目前国内外应用的评价方法主要有类比法、成因法和统计法3类,其中,属于统计法范畴的油藏规模序列法因其简便实用、易于操作等优点,应用最为广泛[3-5]。但对于中国西部广泛存在的低勘探程度区,由于分析数据和统计资料匮乏且应用各类方法开展资源评价工作的历程也较短,因此,在这些探区开展资源评价前,有必要进行评价方法可行性和评价过程合理性分析,进而为后续决策部署提供更加可靠的依据。该文以玛湖凹陷等低勘探程度区为评价对象进行评价,对油藏规模序列法所需参数的敏感性和评价思路进行分析,开展相关领域资源评价,为该区勘探提供理论基础。
1 评价方法基本原理
成因法、统计法和类比法3种资源评价方法中,成因法强调生烃为主的地质分析,类比法重视地质条件的相似性和可对比性,统计法依托储量、钻井等数据进行分析,这3种方法互有所长、相辅相成[6-7]。
1.1 油藏规模序列法理论基础
油藏规模序列法作为统计法的一种,是油气资源评价中最常用的方法。统计表明,将已发现的油气藏按规模大小排列后得到规模序列分布,用概率分布模型外推可得到按离散型随机变量分布的所有潜在油气藏进而预测油气资源量[8-9]。概率分布模型中以帕莱托(Pareto)1927年所提出的模型应用最为广泛,其数学表达式如下:
(1)
式中:Qm为序号为m的随机变量的数值(第m个油气藏的规模),t;Qn为序号为n的随机变量的数值(第n个油气藏的规模),t;k为实数(油气藏规模变化率);m、n为整数序列中的任一数值如1、2、3…(油气藏的序号),m≠n。
将式(1)两边取对数,则有:
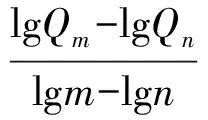
(2)
即当一个特定的含油气区发现一系列油气藏后,以油气藏规模为纵坐标,以油气藏序号为横坐标,在双对数坐标系上投点作图可得一条斜率为k的直线(图1a)。
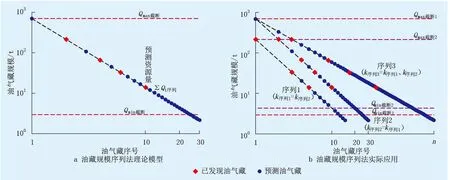
图1 油藏规模序列法预测油气资源量Fig.1 The prediction of hydrocarbon resources by the reservoir scale sequence method
1.2 油藏规模序列法评价过程
理想状况下,应用油藏规模序列法评价过程为:①选取油气成藏条件和规律近似的区域作为评价区;②确定求取油气藏规模序列的k值(记作k序列);③利用已发现油气藏、k序列和式(1)的变形求取完整的油气藏规模序列Q1序列、Q2序列、…、Qi序列(i=1、2、3…);④确定评价区可能的最大和最小油气藏Qmax(记作Qmax截断)与Qmin(记作Qmin截断),用其截断油气藏规模序列,截取范围内所有油气藏的累积规模即为预测资源量,扣除已发现油气藏即为预测待发现资源量。
Qm=Qn(n/m)k,(m、n=1、2、3…,m≠n)
(3)
实践中,k序列、Qmax截断和Qmin截断三者任意一项变化后仍能符合数学模型的油气藏规模序列,但结果不尽相同(图1b)。除了k序列、Qmax截断和Qmin截断,已发现油气藏作为样本时具有k样本、Qmax样本和Qmin样本,在已发现油气藏基础上以k序列求取油气藏规模序列后又具有Qmax序列和Qmin序列。因此,选好参数、合理评价是应用油藏规模序列法预测油气资源的关键。
2 参数敏感性分析
应用油藏规模序列法时,k样本、Qmax样本和Qmin样本仅受控于已发现油气藏本身;k序列直接影响油气藏规模序列Q1序列、Q2序列、…、Qi序列(i=1、2、3…)以及Qmax序列和Qmin序列,k序列、Qmax截断和Qmin截断共同影响预测资源量;Qmax截断和Qmin截断本身与k序列无关,但其作用发挥需要在以k序列求取完整的油气藏规模序列之后。鉴于此,有必要分析各参数的相互影响以及各参数对预测资源量的影响,以便更合理地开展资源评价工作。因此,设置了11组样本,各组样本最大油气藏Qmax样本均为1 000 t、油气藏数均为10、但各组的k样本不同(按k样本=tanθ样本,以间隔1 °依次为40、41、…、50 °),并由此按Qm=Qn×(n/m)k样本(m、n=1、2、…、10,m≠n)分别设计组内样点,对应最小油气藏Qmin样本为64~148 t。
2.1 k序列、Qmax序列、Qmin序列的相互影响
图2a和图2b对比了不同θ样本的样本按不同θ序列求取的Qmax序列与Qmin序列。可以看出,对于同一个样本Qmax序列随θ序列(k序列)改变可增大可减小,但始终在Qmax样本值(1 000 t)附近变化,并且根据Q1=Q2·2k几乎不可能出现Qmax序列与Qmax样本序号不同,而Qmin序列随θ序列减小(k序列减小)逐渐接近该次设定的算法极小值(10 t,为满足计算机运算效率而设,无评价意义)与Qmin样本值(64~148 t)基本无关。由此认为,Qmax序列受θ序列(k序列)的影响较小、受Qmax样本影响较大,Qmin序列受θ序列(k序列)和Qmin样本的影响均较小,若计算机算力足够甚至能达无穷小,因此,k序列、Qmax序列、Qmin序列的相互影响并不强。
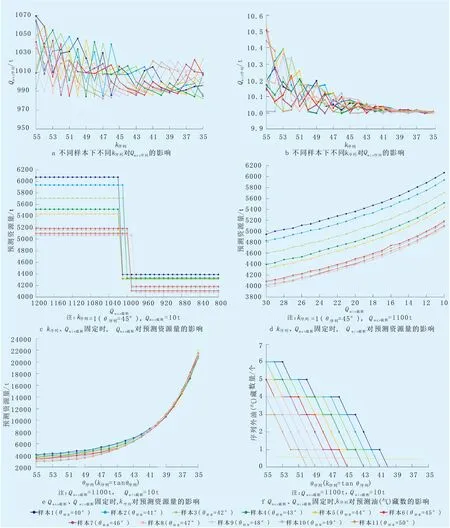
图2 油藏规模序列法参数敏感性分析Fig.2 The parameter sensitivity analysis for reservoir scale sequence method
2.2 k序列、Qmin截断固定时,Qmax截断对预测资源量的影响
图2c表明:当k序列、Qmin截断固定时(k序列=1、θ序列=45 °、Qmin截断=10t),Qmax截断对预测资源量影响有限。当Qmax截断接近Qmax样本值(1 000 t)时预测资源量才会发生变化,预测资源量变化时的Qmax截断为980~1 010 t,仅相当于Qmax样本增加1%或减少2%,考虑到实践中Qmax截断取值一定会大于Qmax样本,并且按式(1),前几大油气藏规模差异显著,在2.1中也提及几乎不可能出现Qmax序列与Qmax样本序号不同,故在实践中选取Qmax截断比较容易,只要同时大于Qmax序列与Qmax样本即可。
2.3 k序列、Qmax截断固定时,Qmin截断对预测资源量的影响
图2d表明:当k序列、Qmax截断固定时(取k序列=1、θ序列=45 °、Qmax截断=1 100 t),Qmin截断对预测资源量影响较大。当Qmin截断分别为30 t和10 t时预测资源量增大22.79%~27.57%,表明预测资源量随Qmin截断的减小而增大且变化显著,进一步分析能得出当Qmin截断分别为20 t和10 t、30 t和20 t时预测资源量增大幅度分别为13.23%~15.72%与8.44%~10.46%,表明Qmin截断越小对预测资源量影响越大。这是由于油气藏越小、规模差异越微弱、分布越密集、越容易被影响。
2.4 Qmax截断、Qmin截断固定时,k序列对预测资源量的影响
图2e表明:当Qmax截断、Qmin截断固定时(Qmax截断=1 100 t、Qmin截断=10 t),k序列对预测资源量影响突出。当θ序列由55 °减小为35 °时,预测资源量增大410.31%~615.13%,表明预测资源量随θ序列(k序列)的减小而增大且变化巨大,因为k样本=tanθ样本、θ本样越大则k样本越大、θ样本越小则k样本越小,因此当θ序列分别为55 °、35 °时预测资源量增大410.31%~615.13%,表明θ序列(k序列)越小对预测资源量影响越大。由式(1)可知:θ序列越小作为幂指数的k序列越小,预测的油气藏更密集、更容易被影响。同时,图2f可知:当θ序列>θ样本(k序列>k样本)时,会有样本油气藏未进入规模序列且θ序列(k序列)越大序列外的油气藏个数越多,可见θ序列(k序列)既不能一味求大,也不能一味求小。
3 参数取值重点与评价过程优化
根据前述分析,各参数间及各参数和预测资源量间的敏感性强弱有别,因此,可以有针对性地确定参数取值重点,制订评价思路,优化评价过程。
3.1 突出层系特征确定评价范围
中国大陆长期处于全球动力学体系复合、交汇部位,形成了一系列多旋回叠合、多成藏组合、多期次聚烃的沉积盆地[10]。基于这种背景,平面上的构造单元不足以限定成藏上的一致性和连续性,而以层系为单元兼顾勘探程度圈定具有同一成藏特征的“层评价区带”,能更好满足油藏规模序列法的应用,后续也利于对相似区进行类比评价。
准噶尔盆地玛湖凹陷构造单元划分依据晚海西期构造格局[11],但其成藏特征自下而上具有显著差异:石炭系—下二叠统紧邻烃源岩或处于源内,勘探程度低,是盆地深层潜在的战略接替领域;中上二叠统大型地层超覆尖灭带、剥蚀尖灭带形成地层型油气成藏群,在“十三五”期间作为重要的勘探领域;以百口泉组为代表的三叠系,在扇控大面积成藏的勘探思路下,在“十二五”“十三五”期间取得了诸多发现;侏罗系等中浅层受河道砂体和断层控制与深层表现出“接力成藏”特征,具备较好的效益勘探条件[12-13](图3)。因此,具体实践中,将成藏特征统一、勘探工作相对丰富的三叠系百口泉组作为一个独立的“层评价区带”,截至2019年年底,百口泉组探明石油区块(具有统一油水界面和储量计算参数,视作一个已发现油藏)15个,最大规模为2 856.27×104t,最小规模为231.01×104t,全部位于凹陷西侧,因此,将工作范围限定在“凹陷西区”。
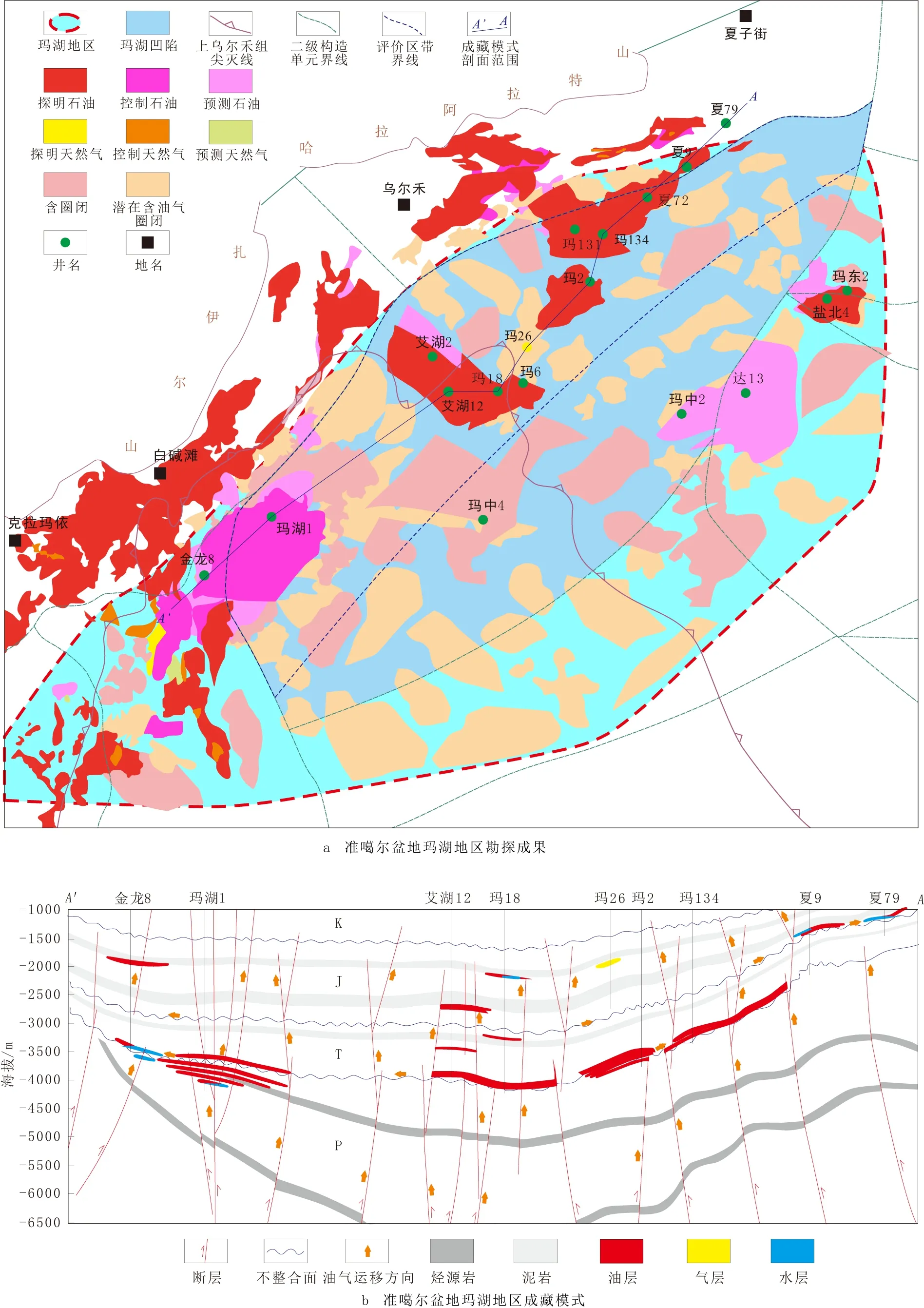
图3 准噶尔盆地玛湖地区勘探成果与成藏模式Fig.3 The schematic diagram of exploration results and accumulation model in Mahu Area, Junggar Basin
3.2 突出资源预期确定Qmax截断和Qmin截断
勘探常规圈闭时,油气藏规模越大、越容易被发现,因此,常规圈闭勘探阶段Qmax样本基本都能在早期被发现,进而Qmax截断也容易确定。但随着勘探目标趋于非常规,“先大后小”的发现规律不再明显,先发现的油气藏不一定是Qmax样本,因此,需要按照地质认识人为修正Qmax样本进而调整Qmax序列并约束Qmax截断。
对于Qmin截断,国外各大油公司以效益为导向时常以最小经济规模作为Qmin截断,但中国资源评价工作更强调资源摸底、更突出发现可能,因此,对效益考量较少时可将评价区地质条件下可能发现的最小规模作为Qmin截断。
百口泉组埋深为2 500~4 400 m,考虑地质条件并类比盆地其他凹陷区同深度段油藏,认为可能发现的最大油藏规模为3 014.23×104t、最小油藏规模为10.04×104t(图4a)。可能发现的最大油藏规模与Qmax样本(2 856.27×104t)比较接近,故Qmax样本无需修正,按最终确定的θ序列=41 °求取的Qmax序列实际等于Qmax样本,因此,Qmax截断超过2 856.27×104t即可。虽然此例并未按照地质认识人为修正Qmax样本,但回顾勘探进程和资源评价经历,人为修正Qmax样本十分重要,2016年“全国第四次油气资源评价”时2 856.27×104t规模的油藏尚未证实(2018年上报),当时最大油藏规模为2 270.00×104t,而通过地质条件类比所得的最大油藏规模为3 000.00×104t,此时若不人为修正Qmax样本,近3 000.00×104t资源量将不会被计入预测资源总量,导致总量减少约5%。
此外,在资源评价实践中,若参考国外将最小经济规模作为Qmin截断,其受行业环境影响巨大,如2020年初,国际油价跌至950 元/t以下甚至负数,此时最小经济规模不复存在,显然资源评价工作也无法顺利进行。同时,中国进行过一些基于远期油价的最小经济规模测算,如郝银全等测算大港油田陆上探区为50.00×104t[14],王学军测算垦东地区为30.00×104t[15],周总瑛等分别测算潜江凹陷和塔河油田为20.00×104t[16]和65.00×104t[17],类比以上实例综合考虑凹陷西区百口泉组开发成本,最小经济规模在30.00×104t以上,但以30.00×104t作为Qmin截断预测资源总量不足4.00×109t、资源探明率上升至50%,不符合凹陷西区百口泉组探明程度较低的地质认识。可见由地质条件确定的最小规模10.04×104t更具合理性[18-19]。
3.3 突出结果可信确定k序列
虽然θ序列(k序列)越小,预测资源量越大、预测油气藏个数越多,但预测资源量和油气藏个数过多也会偏离实际地质条件。因此,应在序列达到较好拟合性的基础上,通过和已发现资源、成因法、类比法及其他统计法评价结果综合对比,通过与相似地质条件的区域相互类比,在预期可靠、结果可信的前提下确定较合理的θ序列(k序列)。
综上所述,以玛湖凹陷凹陷西区百口泉组已发现油藏为样本(Qmax样本=2 856.27×104t、Qmin样本=231.01×104t,样本个数为15)、取Qmax截断为3 000×104t、Qmin截断为10×104t,按k序列=tanθ序列(θ序列按间隔1°依次为20、21、…、80 °)分别求取预测误差、预测最大油藏规模(Qmax序列)、预测油藏个数、预测总资源量(图4),进而分析结果可信度并确定可用的k序列。
由图4可知:θ序列过大(大于61 °)时,预测油藏个数小于已发现油藏个数15,θ序列过小(小于31 °)时,预测油藏个数超过算力极限(大于2 000),显然,θ序列大于61 °或小于31°都不可信。因此,θ序列为32~60 °,进一步综合对比研究区4.00×109t的三级储量、6.11×109t的容积法评价结果、5.76×109t的有利储层预测法评价结果,认为θ序列会在40~44 °(对应预测资源量为6.40×109~3.67×109t),再进一步考虑研究区所处勘探阶段、资源前景、并征求专家意见,认为θ序列取41 °(预测资源量5.57×109t、预测油藏309个)较为合理。
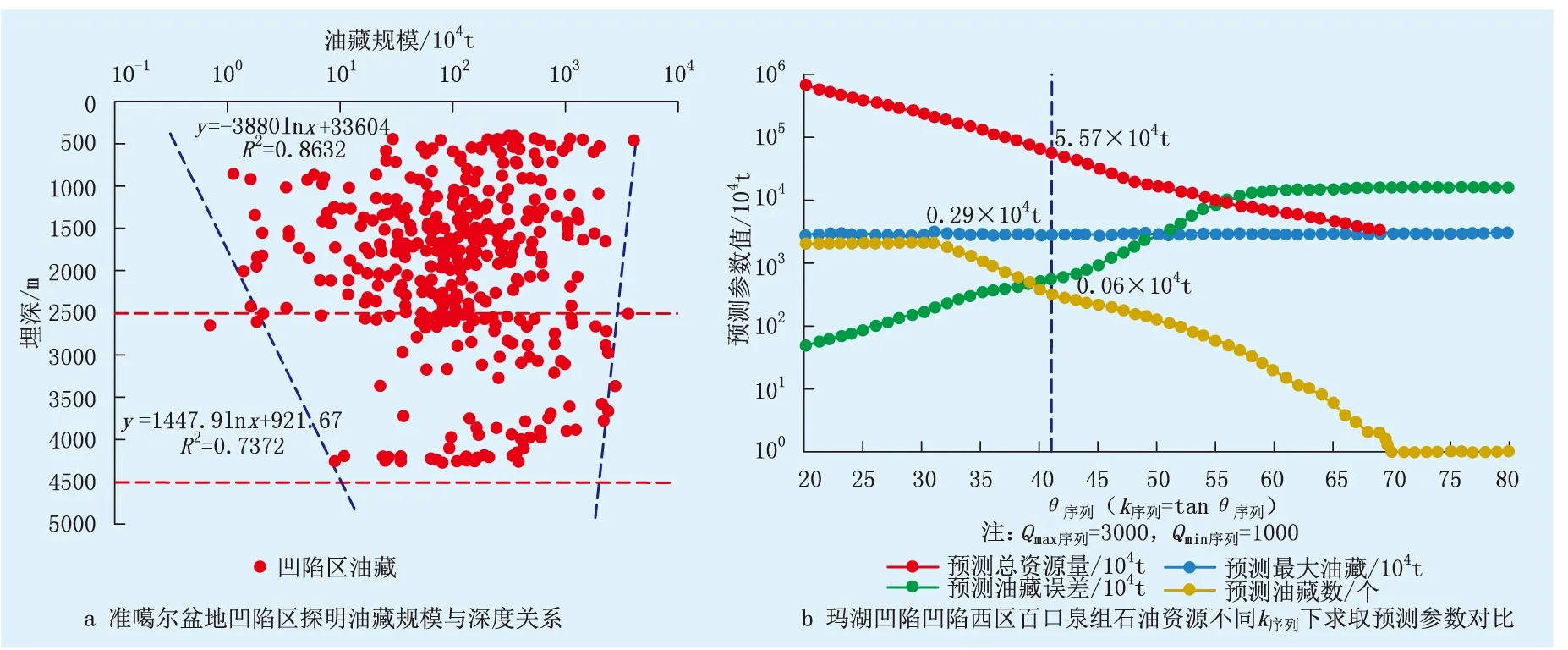
图4 玛湖凹陷“凹陷西区”百口泉组石油资源油藏规模序列法参数取值分析Fig.4 The analysis of parameter choice of reservoir scale sequence method for petroleumresources in Baikouquan Formation, the “West Area”, Mahu Sag
3.4 预测资源量合理性分析
与2016年完成的“全国第四次油气资源评价”结果相比,研究区此次预测资源量减少0.19×109t、资源探明率增加1.5倍。综合来看,评价结果的变化与地质认识、工程工艺的发展相匹配,一方面自2012年玛131、玛18井区相继突破,对于凹陷西区百口泉组的地质认识比较完善,因此,预测资源量未发生较大变化,仅随着评价方法的充实而更加细致;另一方面由于制约该区资源发现的主要原因在于储层致密、采出难度大,随着近些年“水平井细分切割体积压裂”等工程工艺的进步,潜在资源被快速探明并动用,因此资源探明率有了显著提升,并且巨大的勘探潜力也再次得到证实。因此,此次资源评价结果合理,预测资源量具有较高可信度。
4 结 论
(1) 油藏规模序列法预测过程中涉及k样本、Qmax样本、Qmin样本、k序列、Qmax序列、Qmin序列、Qmax截断和Qmin截断等多个参数,不同参数的来源、性质有所差异;k样本、Qmax样本、Qmin样本为定值,由已发现油气藏决定;Qmax序列和Qmin序列为变量,在同一组油气藏下随k序列改变;Qmax截断和Qmin截断也为定值,其经过对已发现油气藏和评价区地质条件的综合分析后人为指定。
(2) 油藏规模序列法的预测结果具有多解性,k序列、Qmax截断和Qmin截断直接影响预测结果;Qmax截断取Qmax样本和Qmax序列中较大值,对预测资源量影响较小;Qmin截断对预测资源量影响较大,预测资源量随Qmin截断的减小而增大,值越小对预测资源量影响越大;k序列对预测资源量影响突出,预测资源量随k序列的减小而增大,值越小对预测资源量影响越大,预测资源量随k序列的增大而失真,值越大失真越多。
(3) 为了使油气资源预测更加合理,应在评价过程中把握突出层系特征确定评价范围、突出资源预期确定Qmax截断和Qmin截断值、突出结果可信确定k序列等关键内容;对于低勘探程度区,油藏规模序列法是一种简便易行的统计学资源评价方法,在资源评价工作中能够有效充实评价方法系列并益于提高最终评价结果的可信度。
