基于双层神经网络模型参数辨识的变结构多模型自主导航方法
2021-12-06许晓伟赖际舟陆俊清白师宇胡华峰
许晓伟,赖际舟,吕 品,陆俊清,白师宇,胡华峰
(1.南京航空航天大学 自动化学院,南京 210096;2.湖北航天技术研究院 总体设计所,武汉 430040)
井下的煤炭开采的作业空间狭小,工作人员靠近大型机械,以及空气中存在的易燃易爆气体和粉尘都对井下安全带来了挑战。为了确保采煤效率和工人的工作安全,煤炭开采正在由人工向自动化方向转变,其中采煤机定位是实现煤炭开采自动化的核心技术[1,2]。在GNSS拒止的井下定位环境中,惯导系统凭借其较好的自主性和可靠性被广泛应用于井下的复杂环境[3,4]。为了提高惯导系统的定位精度,零速校正是一种常用的误差约束手段,但这种方式需要载体不断地静止实现载体的速度约束,不利于采煤机的连续开采。杨海等人[5]通过对采煤机振动引起的惯导系统计算误差进行了相关研究,通过对振动频谱特性的分析,建立了圆锥误差和划船误差的补偿模型,利用多子样算法提高了惯导系统的计算精度。但是在随机振动中,多子样补偿算法的效果不明显[6]。受制于惯导系统自身定位机理,长时间的采煤过程导致惯导系统定位误差不断累积[7]。为保证惯导系统长期的定位精度,通常需要借助外部信息的周期性的修正惯性误差。例如通过里程计和惯导系统的组合,减少了采煤机长时间切割过程中的位置发散,或者利用在井下环境中布置的UWB锚节点组成无线传感网络实现对惯导位置的约束[8]。Jonathon R等人利用热成像相机,利用采煤机煤炭切割过程中截割部与不同成分的煤层摩擦产生的不同红外特性,提高了煤层垂直面位置的定位精度[9]。由于井下恶劣的环境对传感器的可用性、可靠性和安全性都提出了严格的要求。因此目前基于惯导/里程计的组合导航仍是最主要的导航方式。
为了分析井下惯导系统在振动环境下的输出特性,采用陀螺零偏稳定性为0.003°/h的惯导在某矿井下采集了采煤机工作时的实际陀螺输出,如图1、2所示。

图1 井下开采静止状态陀螺实际输出Fig.1 The output of the gyro at static state

图2 井下开采切割状态陀螺实际输出Fig.2 Output of gyro under vibration
从图中可以看出,开采静止状态的陀螺输出基本符合惯导标称的性能水平。但是在切割状态下,惯导系统由于振动使陀螺输出精度存在明显下降。图3是实际开采过程中惯导系统陀螺仪在井下振动环境的噪声频谱图,其中存在着多种不同的振动频率分量,导致噪声水平多变。

图3 井下开采实际陀螺噪声频谱Fig.3 Spectrum of noise under vibration
目前传统的卡尔曼滤波估计通常基于固定噪声模型,在滤波过程中由于模型参数失配导致滤波结果精度较差甚至发散,难以适用于井下定位环境。多模型估计(Multiple Model Estimation, MME)是一种能够处理系统结构和参数不确定的自适应估计方法[10],被广泛用于时变模型的故障检测和诊断[11]、目标跟踪[12]、组合导航[13,14]等领域。为了解决轮式里程计在轮胎出现滑动时误差时变的问题,Hyoungki Lee等人[15]提出了一种交互式多模型的轮式里程计滑移检测及补偿方法,利用基于模糊逻辑辅助的交互式多模型逼近无滑移和滑移过程中的时变动力学模型,提高了载体的定位精度。为了解决GPS拒止的巷道环境下的车辆多动态高精度定位,王磊等人[16]针对组合导航系统中存在的时变或非高斯噪声,提出了一种交互式多模型秩滤波算法,实验结果表明算法能够提高组合导航系统姿态、速度和位置估计精度。但是,传统固定结构多模型算法均针对较少的系统状态。当时变系统运动状态需要较多的模型集合来描述时,不仅计算更加复杂,而且模型之间的竞争会导致系统状态的估计精度下降。变结构多模型算法针对更加复杂的目标运动状态,能够在不增加计算复杂度的情况下提高系统性能[17]。由于煤层复杂的组成成分以及机体的自身振动,导致采煤机在切割过程中的系统噪声呈现时变特点,变结构多模型估计算法能全面地描述不同开采工序下的采煤机系统模型参数,提高采煤机的导航定位精度[18,19]。但目前仍然没有有效理论指导模型集的设计,不能保证模型切换的时效性和正确率。
因此,本文针对井下复杂的振动环境,设计了基于变结构多模型的定位方案。对传统基于后验概率进行模型切换的模型识别算法进行改进,提出了基于支持向量机(Support Vector Machine, SVM)和极限学习机(Extreme Learning Machine, ELM)相结合的双层神经网络模型参数辨识算法。实现快速准确的最佳模型集选择以及模型集的激活和终止。相较于传统模型集在线选择算法[20]具有更快的模型切换效率和更高的准确性,提高了井下复杂环境惯导/里程计组合导航的定位精度。
1 惯导/里程计井下定位方案
综合机械化采煤是一种利用机械化和自动化设备进行采煤工作的过程。设备主要包括常用的滚筒式采煤机、刮板输送机和液压支架,通过三者之间的紧密配合,实现破煤、运煤和支护任务,具体结构如图4所示。综合机械化采煤切割面大约有200-450 m宽,长度可以达到5 km,采煤机每次大约切割0.8 m厚的煤层,每次采煤机开机进行煤炭切割,都需要切割数百米的煤层,时间长达数小时。采煤机在开采过程中存在静止、前进、倒退等不同的运动状态,对应着不同的切割过程。由于采煤机切割过程中煤层成分的不确定导致截割部的受力变化,采煤机工作过程中会产生不同程度的机械振动,导致器件时变误差特性时变。

图4 综合机械化采煤切割面结构Fig.4 Structure of fully mechanized coal mining face
井下恶劣环境对于传感器的选择提出了苛刻的要求。需要在能够保证井下安全的基础上,提供可靠的导航信息。其中,无线电定位容易在巷道中产生多路径和非视距效应,甚至信号被完全遮挡。视觉传感器和激光雷达等主动传感器容易被粉尘、泥浆等环境影响,可靠性和精度难以保证,因此并未得到广泛应用。
惯导系统更新频率快,短时精度高,能够获得采煤机三维的速度、位置和姿态。里程计受采煤机振动的影响小,误差的发散特性与其运动距离相关,适合采煤机这种工作时间长,运动相对较慢的载体,能够在较长时间保持较高的定位精度。基于卡尔曼滤波的惯导/里程计组合导航方案被广泛应用于井下采煤机定位。由于没有考虑采煤机开采过程的时变噪声对组合导航精度带来的影响,导致采煤机的定位精度难以满足实际的工程需求。综上,本文设计了基于双层神经网络模型参数辨识的惯导/里程计井下融合方案,综合机械化采煤结构和组合方案如图5所示。

图5 综合机械化采煤导航系统结构和组合方案Fig.5 Structure and combination scheme of the navigation system for fully mechanized mining
2 基于双层神经网络模型参数辨识的改进变结构多模型方法
传统的模型集切换方法通常采用可能模型集算法(Likely Model Set, LMS)以及模型组切换算法(Model Group Switching, MGS),其中现有模型选择策略较多,但没有一种经典理论指导模型集合的在线选择,模型集自适应选择正确率和时效性不能得到保证。传统算法为了尽量保证模型参数的匹配,会倾向于选择模型较多的集合,因此这种模型集选择的取向会在状态估计和基于新激活的模型的滤波器的协方差中带入误差,导致滤波精度下降[20]。本文结合井下采煤工作时的运动特性,通过对可能模型集算法的改进,提出了基于双层神经网络模型参数辨识的改进变结构多模型方法,具体结构如图6所示。

图6 基于双层神经网络模型参数辨识的变结构多模型框架图Fig.6 Block diagram of Two-Layer Network Identification based Variable Structure Multi-Model
2.1 基于双层神经网络的多模型参数辨识算法
系统噪声的模型参数随着采煤机的不同运动状态产生相应的变化,因此我们根据采煤机的切割、倒车和停止等多个状态下的系统模型进行分类,这类系统噪声之间的区别明显,单层的神经网络分类算法可以较为准确的识别。但即使处在同一运动状态下时,采煤机的振动变化会导致系统模型发生改变,这种变化相对于不同运动状态下采煤机系统噪声尺度变化小。当这些不同级别的系统噪声全部用于对单层的神经网络分类算法的训练时,由于不同数量级辨识的尺度不同,模型参数辨识的精度出现了明显的下降,存在同量级的模型噪声混淆的问题。为了提高模型的辨识精度,提出一种将SVM和ELM结合的双层神经网络模型参数辨识算法。

图7 采煤机开采噪声模型双层神经网络辨识算法Fig.7 Two-layer neural network identification algorithm for mining noise model of shearer
双层神经网络模型参数辨识算法包括两层分类处理,两层分类依次衔接,构成了针对噪声量级的初步辨识和同一量级的细分辨识,构成完整噪声模型识别方案。大尺度粗辨识数据量较大,一旦出现辨识错误将影响后续的第二层辨识,因此需要足够的稳定性。考虑到增加辨识层会导致系统计算量的增加,第二层神经网络分类算法应当具备较快的辨识速度,从而保证系统的实时性。本文针对大尺度粗辨识的稳定性以及小尺度精辨识的小样本特点,首先利用SVM识别噪声所属量级,然后针对已经根据运动状态分类的同一数量级特征采用相应的ELM分类模型进行具体的噪声模型识别。
SVM算法本质是在样本空间中找到一个超平面,将不同类别的样本分开。通过找到“最大间隔”超平面,使得分类结果具有鲁棒性,泛化性能最好,同时分类性能稳定。首先假设分离超平面为:

点到平面距离为:

其中<w,x>为向量点积,当两类样本线性可分时,设满足以下条件:

假设两个平行超平面H1和H2作为间隔边界以判断样本分类:

超平面H1和H2到原点的距离分别为和因此H1和H2的间距为时,分类间隔最大就是使最小,即:

其中w为法向量,ωs决定了超平面的方向,bs为位移项,ωs通过和sb确定划分超平面。对于提取的惯导数据特征,采用SVM进行初步分类。将多分类简化为多个二分类,采用的输出为0、1输出。
第二层模型参数辨识网络通过ELM与上层辨识结构相连,其模型如图8所示,通过随机初始化单隐层神经网络的输入权重和偏置得到相应的输出权重,具有学习速度和运算速度快的优势,适合处理小样本数据。
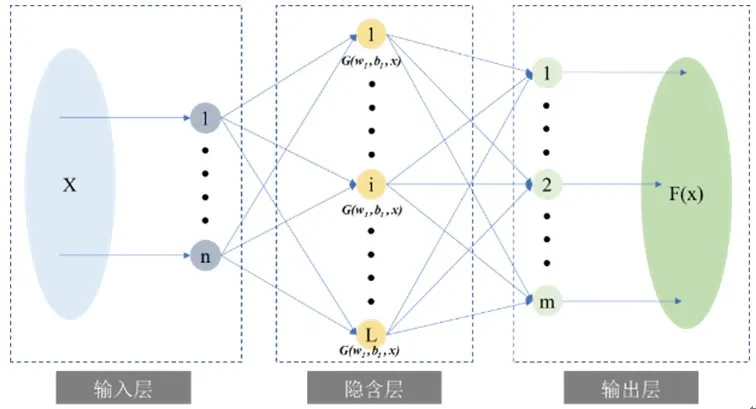
图8 极限学习机结构图Fig.8 Structure diagram of extreme learning machine
针对已经由上层辨识网络获得的不同数量级噪声,训练多个独立的分类模型。对于上述的每一个类别,给定采集的N个训练样本(XNN,TNN) = {(xi,ti),i=1,2...N},此处XNN为提取的噪声特征矩阵,TNN为对应的期望输出,N为该类别输入的样本个数,xi=[xi1,xi2,...,xin]T表示XNN中的第i个样本,n为输入的样本维,ti=[ti1,ti2,...,tim]T表示第i个样本的对应输出,m表示输出的向量维(与噪声类别相同)。在本文中,期望输出向量采用0、1标记方式标定,即样本属于第几类噪声模型,则将期望输出向量位置中的第几位标记为"1",其余位全均记为"0"。设单隐层神经网络的隐含层有L个节点,其输出为:

其中,ωi为连接输入神经元与第i个隐含层节点的权向量,bi为第i个隐含层节点的偏置,βi是第i个隐含层节点的输出权向量,g()·为激活函数。因此,可将式(8)简化成:

其中,H是隐层节点的输出,β为输出权重,O为单隐层神经网络的输出。
ELM的学习目标是通过最小化预测误差损失函数之和来求解输出权重,其运用最小范数得到最小误差解:

因此根据上述公式可以推导出隐含神经元与输出神经元的输出权值矩阵最优解:

其中H+是矩阵H的摩尔-彭罗斯广义逆。通过双层神经网络模型参数辨识获得当前运动状态的模型参数,从模型库中选取与该参数标准差最小的多个模型组成模型集合带入变结构多模型算法,对当前采煤机的运动状态进行估计。
根据数据特征构建的双层神经网络模型参数辨识充分利用不同神经网络分类算法的优势,解决了传统模型自适应完全依赖于后验概率模型导致的模型切换准确性和实时性难以保证的问题,能够有效避免模型误匹配带来的滤波器发散。同时相较于单层模型参数辨识神经网络,提高了小尺度模型之间的辨识精度,兼顾了多层神经网络的辨识效率。
2.2 基于模型参数辨识的改进变结构多模型算法
2.2.1 系统及量测模型构建
本文基于东北天导航坐标系来讨论。为了描述采煤机的运动状态和惯性仪表误差以及里程计标度因数误差,考虑状态量设置如下:
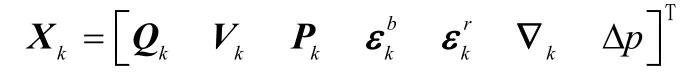
其中,Qk= [q1(k)q2(k)q3(k)q4(k)]为k时刻姿态四元数,为k时刻载体东向、北向及天向速度;Pk=[λ(k)L(k)h(k)]分别是经度、纬度和高度,和分别为3个轴向的陀螺仪的随机常值零偏和一阶马尔可夫随机噪声,分别为3个轴向加速度计的一阶马尔可夫随机噪声,pΔ是里程计的标度因数误差。
里程计每个采样周期输出的量测量如下:
对ITC数据进行切片,采用MATLAB对其进行可视化,得到网络快照集合{G1,G2,…,Gn},G1表示初始时刻的网络拓扑图,G2表示时隔一个切片时长后的拓扑图,依次类推,Gn表示最后一张拓扑图,其演化过程如图4 (a)~(c)所示.

里程计的位置递推公式如下:

其中,Mk和Mk-1分别是k和k-1时刻的脉冲数,Pk和Pk-1为k和k-1时刻导航系下采煤机的位置,为k-1时刻的姿态转移矩阵,p为里程计的标度因数,Δp是标度因数误差。滤波时将导航系下的预测位置转化为地心地固坐标系下的经度、纬度和高度。本文采用直接法进行扩展卡尔曼滤波,状态方程和量测方程构建可以参考文献[21]。
2.2.2 变结构多模型算法
从量测模型可以看出,里程计的位置精度不仅取决于自身输出,也受到载体姿态的影响。其中,航向角对里程计水平位置输出的精度有直接影响。当系统噪声模型和量测噪声模型不准确时,系统难以准确估计预测和量测的误差水平,使系统状态估计精度下降,同时将不准确的航向信息再耦合进里程计量测中,导致量测的精度也难以保证。因此建立多个系统模型达到逼近实际模型的目的,有效降低了滤波器对系统数学模型的依赖性,有利于提高组合导航系统的滤波精度。
变结构多模型算法能够在没有准确系统模型和先验知识的情况下通过多个模型之间的自适应,避免模型失配导致滤波器发散。变结构多模型由多个并行的扩展卡尔曼滤波器组成,根据模型集自适应算法选出当前适合的模型集,将最优模型集带入滤波器,通过不同滤波器之间的残差和方差获得对应模型的似然函数即条件概率密度函数,进而通过贝叶斯公式计算各个模型的概率。最后将上一时刻的状态估计和模型概率转化为权重,初始化当前状态及其协方差阵。具体计算步骤如下所示。
(1) 交互输入
利用上一个周期的状态和模型转移概率获得当前时刻的交互输入,初始模型转移概率为:
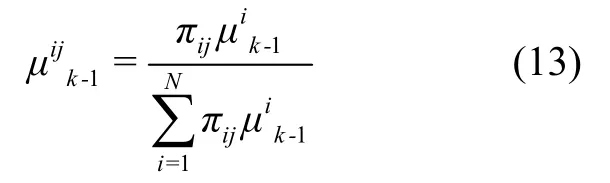
根据模型条件转移概率重新初始化模型j的状态与协方差阵为:

(2) 模型滤波
根据上述扩展卡尔曼滤波的过程,带入辨识后的噪声模型,计算模型的滤波残差和方差:
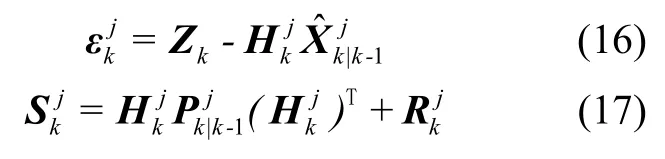
(3) 模型概率更新
根据假设检验原理,如果统计模型与实际模型匹配,则滤波残差服从零均值高斯分布,由此获得该模型的似然函数为:

模型概率可更新为:

其中,πij表示先验的Markov模型转移概率,为k-1时刻i模型的概率。
当模型检测算法检测到模型需要切换后,在当前运行模型中引入新的模型,重新分配新旧模型的权重,运行两个模型集的并集。计算新模型集合和旧模型集合的概率,当新模型概率占总模型概率达到一定阈值时,丢弃旧模型,继续运行新模型,通常阈值稍小于1,防止模型的直接切换可能带来的模型跳变。最后对每个模型的滤波状态进行加权,获得全局的状态估计。
3 仿真与分析
3.1 参数设置
为了验证本文提出的算法性能,通过MATLAB对算法进行仿真。平台搭载intel i7 8700k处理器,主频3.7 Ghz。根据采煤的实际工况,将其开采流程分为3个步骤。首先是对工作面的水平切割,随后进行斜切进刀工序,进刀距离1 m,进刀完成后切割三角煤,重新回到端头进行下一次的切割。但在切割过程中可能由于煤层中的杂质等影响,导致采煤机暂停切割和倒退。每个工序根据采煤机与煤层接触所产生振动情况设计相应的模型噪声以及采煤机可能的实际运动状态进行仿真,仿真传感器主要包括高精度惯导系统和里程计。惯导系统的解算周期是0.02 s,里程计的解算周期是1 s,滤波周期与里程计解算周期相同。仿真轨迹按照实际可能的采煤机运动状态进行模拟。在煤炭切割状态速度为0.1 m/s,进刀状态按照0.01 m/s。采煤机沿400 m切割面做往复运动,每次切割完毕向煤层推进0.9 m。全程共用4.4 h。变结构多模型算法模型集合切换阈值设置为0.8,初始马尔可夫转移概率设置为:

真实运动轨迹设计如图9所示,传感器参数和多模型算法参数如表1所示。

表1 传感器参数设置Tab.1 Parameters setting of sensors
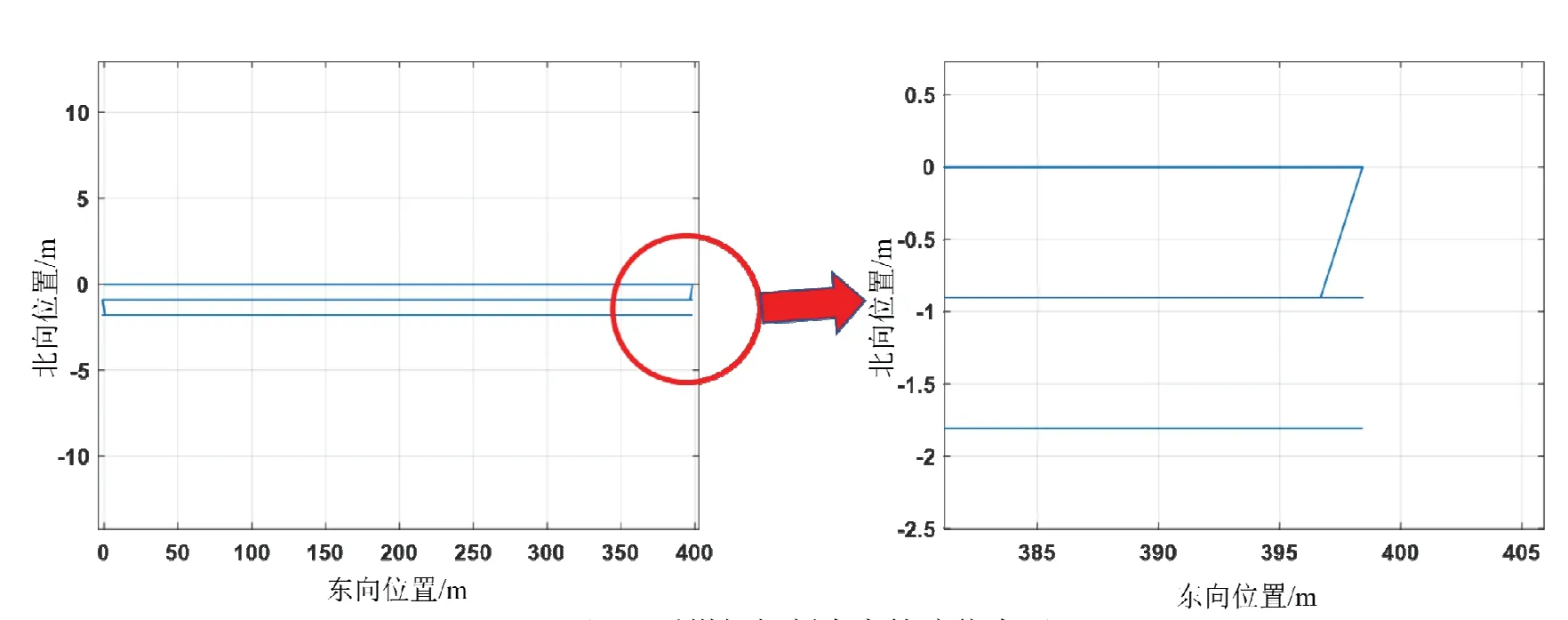
图9 采煤机切割真实轨迹仿真图Fig.9 Simulation diagram of the real trajectory of shearer cutting
3.2 双层神经网络模型参数辨识精度分析
为验证双层神经网络模型参数辨识的正确率和辨识精度。仿真4组不同的采煤机完整开采过程的惯导/里程计输出,并且根据切割状态对数据进行分割,共分成4种不同工作模式下的11种噪声模型,将各类模型下的惯导/里程计输出标准差、方差、最大值和极差作为数据并添加多分类模型标签进行依次训练。
针对训练好的双层神经网络,重新仿真4组完整采煤机开采的惯导和里程计输出作为测试集并且根据采煤机的实际工作状态添加相应模型分类标签进行识别,将识别结果和添加的标签进行对比,对比结果如表2所示。本文所提出的算法在模型切换时达到98%以上的识别率,相较于仅通过单层网络辨识提高了12%以上的识别准确率,因此通过双层辨识神经网络有效提高了系统的辨识精度。

表2 算法的辨识精度对比Tab.2 Comparison of the identification accuracy of algorithms
3.3 改进变结构多模型定位精度分析
将训练好的双层神经网络用于变结构多模型算法的模型参数辨识。为了验证算法的实际融合效果,与传统的交互多模型算法(Interacting Multiple Model,IMM)进行对比。根据仿真所设计的采煤机运动状态,设计了多分类模型下惯导/里程计的噪声模型参数,构建了多分类模型库,如表3所示。每个多分类模型中设计了具体模型参数,分别对应变结构多模型算法中设计的4个滤波器噪声信息。

表3 多分类模型库设计Tab.3 Design of multi-classification model library
由于井下里程计受振动的影响较小,在采煤机运动方向上的误差可以得到抑制,而航向完全基于陀螺仪输出,陀螺系统噪声的设置精度尤为重要,因此本文在多分类模型中构建了更多噪声模型进行匹配。
图10是不同算法和真值的轨迹对比,可以看出本文算法的轨迹精度显著高于传统IMM算法。图11、图12和图13分别对比了两种算法的东向位置误差、北向位置误差和航向角误差。结合表4可以得到以下结论:IMM算法由于在较多模型集合的选择中不能分配较为精准的权重,系统模型参数失配,导致滤波精度不高。相较于传统算法,本文所提出算法凭借可靠的模型参数辨识,获得了明显的井下定位、定向精度提升。其中,本文所提算法的东向位置误差均方差为1.15 m,北向位置误差均方差为2.44 m;传统IMM算法的东向位置误差均方差为1.55 m;北向位置误差均方差为4.54 m,有效抑制了由于振动噪声导致的航向发散,航向精度提升42%,东向精度提升26%,北向精度提升46%,水平精度总体提升43%。另外,通过多组仿真,得到本文算法单次信息融合平均解算时间耗时为0.86 ms,传统IMM算法的平均解算时间为2.75 ms。值得注意的是,采煤机在切割过程中航向误差存在4处比较明显的跳变,这是由于采煤机在切割到工作面端头后进行斜切进刀过程中航向明显变化导致。综上,本文算法相较于传统的IMM算法提高了井下采煤机在不同运动阶段惯导/里程计的融合的定位精度,同时保证了解算效率。

图10 不同算法的自主导航定位精度对比Fig.10 Comparison of different algorithms

图11 东向位置误差对比Fig.11 Comparison of east position error

图12 北向位置误差对比Fig.12 Comparison of north position error
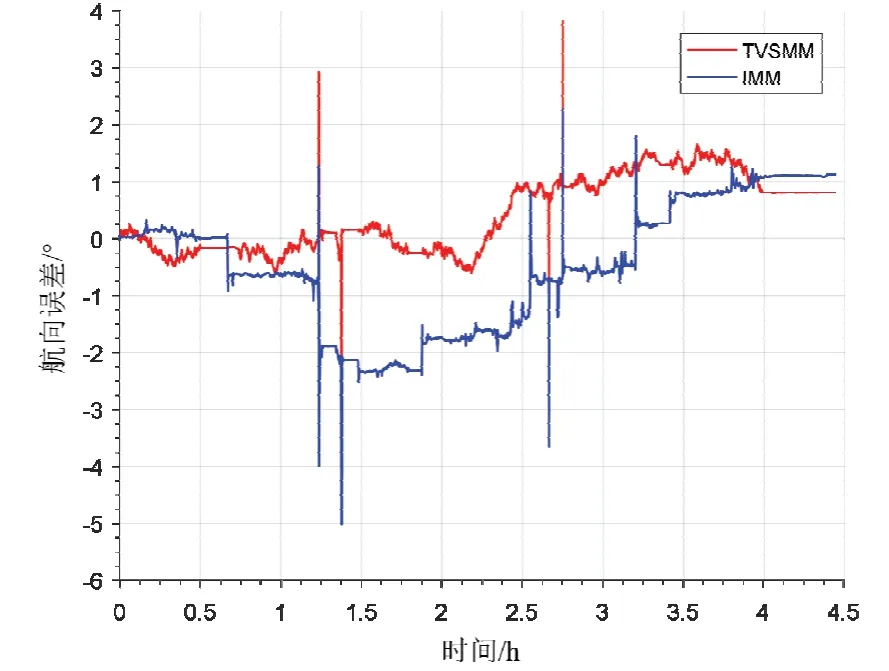
图13 航向误差对比Fig.13 Comparison of heading error

表4 算法定位精度对比Tab.4 Comparison of positioning accuracy of algorithms
4 结 论
本文针对井下采煤机采煤过程中的复杂运动状态,基于高精度惯导系统和里程计设计了一种基于双层神经网络模型参数辨识的变结构多模型导航算法。利用惯导仿真数据针对不同运动模型的特征进行训练,通过对数据分割与截取、特征建模、机器学习策略的研究,实现在采煤机运动模型在运动状态变化时的精准切换。该算法不依赖于后验概率,具有较快的模型切换的速度。通过变结构多模型与双层神经网络模型参数辨识算法的结合,解决了在GNSS拒止的复杂环境下时变系统的高精度定位问题。仿真结果表明,相较于传统多模型导航算法,本文所提出算法能够有效应对复杂、时变的井下振动环境,实现了实时、高精度的导航定位。
