知识图谱中的关联实体发现
2021-12-04李剑宇
李剑宇,岳 昆
(云南大学 信息学院,云南 昆明 650500)
知识图谱(Knowledge Graph,KG)中的关联实体发现任务,旨在为用户输入的查询实体推荐最相关的实体集合[1].准确地为用户输入的查询返回关联实体,不仅能够加强用户的查询体验,还能有效地提高用户的参与度.近年来,随着KG在搜索引擎[2]、智能问答[3]和个性化推荐[4]等领域应用的日益广泛,用户对关联实体发现的需求与日俱增.与此同时,用户在KG下游应用中与实体的交互也产生了大量的行为数据[5],称为用户-实体数据.值得注意的是,KG中的实体间的关联往往体现在用户-实体数据中,并且具有不确定性.例如,在图1所示的KG中,某一用户对电影“终结者:黑暗命运”给出“喜欢”的评价,则该用户也有90%的概率会对电影“阿凡达”给出“喜欢”评价.这种不确定性是对真实世界中实体依赖的定量描述,本文将其作为关联度.针对KG中给定的实体,找到与之相关联的实体集合,是关联实体发现的基本任务[6],通过计算实体间的关联度,以更细的粒度回答关联实体查询,能够得到更加符合KG实际应用的结果.因此,如何有效地计算实体之间的关联度,是关联实体发现的关键.
近年来,国内外学者基于KG的结构特征对关联实体发现做了大量研究,主要包括子图匹配和实体相似度计算两类方法.
基于子图匹配的方法是将用户输入的查询表示为一个小型查询图,从KG中找出与查询图匹配的前k个子图[7].例如,Jayaram等[8]提出了基于实体元组查询的方法,在KG中查找与给定元组近似的top-k元组集合;Yang等[9]提出STAR模型来提高大规模KG中查询关联实体的效率.然而,这类基于子图匹配的方法开销十分昂贵,并且不能描述实体之间的隐含关联.
一些学者通过实体间的相似度计算来发现关联实体.例如,Ponza等[10]在KG中创建一个围绕两个查询实体动态增长的加权子图,然后使用已知的相关性度量方法计算子图中的边权重,从而得到实体间的关联度;文献[11]将KG建模为一个异质网络,基于元路径捕捉种子实体之间的潜在共同特征,从而发现关联实体;Chen等[12]基于路径的语义特征来发现关联实体,通过处理知识图的不完全性,提出概率模型来对实体进行排序.
上述方法在利用KG结构发现关联实体方面取得了很好的效果,但在考虑到用户行为时,这些方法不足以获得足够的实体间隐含的关联信息,从而难以满足用户的查询需要.例如,在图1所示的KG中查询与“终结者:黑暗命运”相关联的实体,对于喜欢“詹姆斯·卡梅隆”电影作品的用户而言,可能有90%的概率在喜欢电影“终结者:黑暗命运”的同时也喜欢“阿凡达”,而只有40%的概率同时喜欢电影“死侍”.然而,KG可能会优先给出“死侍”作为关联实体反馈给用户,因为“死侍”和“终结者:黑暗命运”在KG中具有相同的导演“蒂姆·米勒”.
从KG的应用和数据分析来看,KG中实体间的关联信息蕴含在用户-实体数据中.例如,与“泰坦尼克号”相比,“终结者:黑暗命运”和“阿凡达”的关联更强,因为喜欢“终结者:黑暗命运”的用户有更高的概率也喜欢“阿凡达”,而不是“泰坦尼克号”.因此,本文将用户-实体数据中所蕴含的知识作为对KG所描述领域知识的补充,通过计算用户-实体数据中实体之间的关联度,获得更为准确、完整的关联实体集合.具体而言,首先根据给定的查询实体,基于KG的结构描述的领域知识抽取一部分候选实体,通过用户-实体数据蕴含的知识计算候选实体与查询实体间的关联度,返回与查询实体最相关的一组实体集合.为此,我们考虑以下两方面的问题:①如何从KG中抽取候选实体集?②如何计算实体间的关联强度?
为了从KG中获取候选实体集,以查询实体为“中心”,利用广度优先搜索(Breadth First Search,BFS)抽取KG的子图.通过观察实体在用户-实体数据中的特点设计一种加权函数来计算KG子图中实体的权值,从而获得权值最高的一组实体,将其作为候选实体集.然而,基于KG领域知识获得的候选实体并不能反映用户-实体数据中实体之间真实的关联关系,并且无法计算实体间的关联度.
以Apriori算法为代表的频繁模式挖掘,是从数据中挖掘频繁项的经典方法[13].通过从用户-实体数据中挖掘频繁实体,能够生成表示实体之间依赖关系的关联规则,即形如A→B的蕴含式;置信度表示数据中包含A的事务也会包含B的事务的概率[13].为了描述查询实体与候选实体之间的关联关系,我们基于关联规则构建实体关联规则(Entity Association Rule,EAR).通过EAR的置信度来定量描述实体之间的依赖关系,作为查询实体与候选实体之间的关联度.进一步,基于分支限界法得到具有最大置信度的EAR集合,从而获得一组具有最高关联度的关联实体.在真实世界数据集上的实验结果验证了本文提出方法的有效性.
1 候选实体集抽取
下面给出KG和用户-实体数据的定义.
定义1KG是一个表示为G=(E,R,A)的有向图,其中E表示KG中实体对应节点的集合,R表示实体关系对应边的集合,A(e)是将实体e与其属性相关联的函数.
例1针对图1所示的KG,实体“阿凡达”的属性为A(阿凡达)={动作,科幻}.

图1 用户与实体的交互实例Fig.1 Example of interaction between users and entities
定义2用户-实体数据表示为Ω={
给定一个KG,G=(E,R,A)和查询实体eq,首先从G中抽取一部分可能与eq在Ω中关联的候选实体集Ec.为此,以eq为“中心”,利用BFS算法从G中抽取出子图Gs.设计加权函数来计算Gs中除了eq以外实体的权值,以获得具有最高权值的实体并将其加入Ec.直观地,权值应满足以下性质:
(1)KG中任意一个实体与eq之间的最短路径越短,则它与eq越有可能关联,因此,权值与实体间的最短路径成反比;
(2)Gs中具有某一属性的实体出现的频率越高,则具有该属性的实体与eq越有可能关联.例如,若eq类型是“导演”,则它常常与类型为“电影”、“演员”的实体一同出现在真实世界的数据中.
下面给出满足以上性质(1)和(2)的权值计算公式:

其中,↕(e)表示e与eq间的最短路径长度,F(e)表示A(e)在Gs中的频率,F(Gs)表示Gs中A的数量.
为了获取m个候选实体,首先从eq出发,基于BFS算法对G进行搜索,遍历第1层实体得到子图Gs.然后,根据公式(1)计算Gs中eq以外所有实体的权值,并根据权值大小依次把实体添加至候选实体集合,再继续遍历下一层实体.重复上述操作直到获得m个候选实体.上述思想见算法1.
算法1获取候选实体集
输入G=(E,R,A):输入的KG;eq:查询实体;m:获取的候选实体数.
变量Gs=(Es,Rs,As):KG子图;l:广度优先搜索步长.
输出Ec:候选实体集合.
步骤1初始化:Ec←∅;Gs←∅;l←1;i←1;
步骤2以eq为中心,利用BFS得到G第i层子图Gs;
步骤3若|Es|≥m,执行下一步;否则,i++,执行步骤2;
步骤4利用式(1)计算Es中所有实体的权值,根据权值大小将Es中的实体加入Ec,直到|Ec|=m;
步骤5输出Ec.
若BFS抽取Gs的总实体数为En,则BFS时间复杂度为O(|En|2),将m个候选实体加入Ec时间复杂度为O(|m|).因此,算法1的时间复杂度为O(|En|2+O(|m|)).
例2针对图1所示的KG,从查询实体“终结者:黑暗命运”来获取4个候选实体.首先基于BFS搜索步长1范围内的实体,得到子图中的实体集合Es={终结者:黑暗命运(科幻),詹姆斯·卡梅隆(导演,制片),蒂姆·米勒(导演)}.由式(1)计算实体“詹姆斯·卡梅隆”与“蒂姆·米勒”的权值分别为0.75与0.5,将其加入候选实体集Ec.继续遍历下一层的实体并重复上述步骤.最终得到候选实体集为Ec={詹姆斯·卡梅隆,蒂姆·米勒,阿凡达,死侍}.
2 关联实体发现
2.1 关联规则的生成通过算法1抽取m个权值最高的候选实体,记为Ec={e1,e2,…,em}.为了构建表示实体之间依赖关系的关联规则,采用Apriori算法从Ω中挖掘出满足最小支持度的候选实体集L,并通过以下公式计算置信度:

其中,s(eu∪ev) 是D中包含eu和ev的d的数目,s(eu)是D中包含eu的d的数目.
使用以下步骤[13]生成关联规则:
步骤1对于L中的每个频繁项集l,产生所有的非空子集;
步骤2对于l中的每个非空子集ls,如果,则输出规则“ls→(l-ls)”,其中,Cmin是最小置信度的阈值.
2.2 关联实体的获取为了描述eq与L中实体的依赖关系,引入如下关联规则:

其中,eq和e1∧e2∧···∧e j分别称为规则头和规则体.
把具有如(3)式的关联规则称作EAR,所有EAR的集合记为H.
EAR的置信度描述了eq与候选实体集之间的关联度.因此,基于置信度选取一部分EAR、以获取具有最高关联度的前k个关联实体.不难发现,规则体中具有相同候选实体的不同EAR之间存在冲突.例如,若H中存在eq→e1∧e2和eq→e1∧e3两个EAR,其置信度分别为0.7和0.9.已选择前者时,后者中的实体可能不会添加到关联实体集合中.因此,在各EAR规则体互不相交的条件下,如何得到具有最高置信度的一组EAR是获取关联实体的关键.形式化描述如下:

其中,i表示H中EAR的序号,ci表示Hi的置信度,Bi表示Hi规则体中的实体集合,xi表示是否选取第i条EAR.
对于上述优化问题,采用分支限界法来获得最优EAR.形式化描述如下:
(1)解空间树 解空间树为子集树.子集树中的节点作为一个EAR对象,其属性如表1所示.

表1 节点属性Tab.1 Attributes of the node
(2)限界函数对H中所有EAR按照单位实体的置信度(即ci/|Bi|)排序.假设遍历到子集树的第i层(i=1,2,…,|H|),则此节点的上界限界函数为:
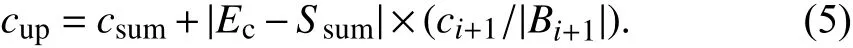
(3)最大堆在子集树的生成过程中,采用最大堆存储和选择扩展节点,以生成解空间,即用二叉树构造最大堆,节点按cup排序,根节点具有最高优先级.
上述思想见算法2.
算法2获取最优关联实体集合
输入H:所有EAR集合;c:EAR置信度集合;Ec:候选实体集合.
变量B:EAR规则体中的实体集合;cmax:获得置信度的最大值.
输出∑:最优EAR集合.
步骤1初始化:初始一个空的最大堆h;初始一个子集树;根据每条EAR的单位实体置信度对H排序;∑ ←∅;i←1;
步骤2将Hi置为子集树根节点,根据式(4)计算Hi的上界函数值,并加入h;
步骤3获取h根节点X,将X从h中删除并更新h;X所在子集树层数i←X.nl;
步骤4i++;Bi←Hi规则体中的实体集合;若Bi∩X.Ssum=∅,执行下一步;否则,执行步骤6;
步 骤5由Hi生成左孩 子Xl:Xl.nc←1;Xl.Ssum←X.Ssum∪Bi;Xl.csum←X.csum+ci;Xl.np←X;cmax←X.csum+ci;将Xl加入h;
步 骤6由Hi生成右 孩子Xr:Xr.nc←0;Xr.Ssum←X.Ssum;Xr.csum←X.csum;Xr.np← X;根据式(4)计算Xr上界函数值,若Xr.cup≥cmax,将Xr加入h;否则,丢弃该节点;
步骤7重复步骤3~7,直到i> |H|;
步骤8X←子集树中具有最大csum值的叶子节点;i←|H|;
步骤9若X.nc=1;∑ ←∑ ∪{Hi};X←X.np;
步骤10i--;重复步骤9直到i=1;
步骤11输出∑
步骤3~7的时间复杂度为O(2|H|).步骤10~11的时间复杂度为O(|H|).将节点插入h的时间复杂度为O(log2(|H|)). 因此,算法2的时间复杂度为O(log2(|H|)×2|H|+|H|).
通过获取∑中所有EAR规则体中的实体,得到与eq具有最高关联度的关联实体集合.
3 实验结果
3.1 实验设置
3.1.1 实验数据实验在两个真实世界的数据集上进行:①来自MovieLens[14]的用户电影评分数据,评分以5星为标准,以半星为增量(0.5星至5.0星).如果用户对电影的评分大于4.0,则为该用户与电影创建“喜欢”关系,此外,每一部电影与其类型之间存在“类型为”的关系;②来自淘宝名为UserBehavior(https://tianchi.aliyun.com/dataset/dataD etail?dataId=649&userId=1)的用户行为数据集,用户行为的类型(点击,购买,购物车,偏好)作为用户与项目之间的关系(例如,〈用户,购买,项目〉).
对于每个数据集,采用70%作为训练数据,30%作为测试数据.在训练数据集中,提取一部分数据来构建KG,其余的作为外部数据来挖掘实体的关联.表2给出上述两个数据集的统计信息.

表2 数据集统计信息Tab.2 Statistics of datasets
3.1.2 测试指标使用准确率(P)、召回率(R)、F1分数(F1)来测试EAR推断的前k个关联实体的有效性,定义如下:

其中,TP、FP和FN分别是正确发现的实体数、错误发现的实体数和未发现的实体数.
3.1.3 对比模型GQBE[8]和TSF[10]作为仅以KG为知识来源发现关联实体的对比方法.Jaccard相似系数[15]作为分别以KG(Jaccard-KG)或用户实体数据(Jaccard-D)为知识来源发现关联实体的对比方法.
3.1.4 测试平台在一台2.5 GHz Intel Core i5-10300H CPU和16GB RAM的机器上用Java实现本文提出的算法.
3.2 有效性测试为了测试基于本文方法发现关联实体的有效性,将前k个关联实体发现的准确率(P@k)与基于其他模型的计算结果进行比较,如图2所示,可得到以下结论:

图2 t op-k关联实体发现的准确率对比Fig.2 Comparison of precision of discovered top-k association entities
(1)EAR在两个数据集中都取得了最高的准确率.与准确率此高的模型相比,EAR在MovieLens数据集的top 1、top 5和top 10的关联实体发现中,准确率分别提高了10.7%、9.9%和6%. 在UserBehavior数据集的top 1、top 5和top 10的关联实体发现中,准确率分别提高了4.1%、2.2%和1%.
(2)仅依靠KG作为知识来源的模型(GQBE,TSF和Jaccard-KG)在UserBehavior数据上的准确率比在MovieLens数据集上的得分低,这是因为UserBehavior数据集中用户与实体之间的交互具有较强的随机性,导致构建的KG中的实体关联相对较弱.与这些方法不同,EAR通过结合KG外部的用户实体数据计算实体之间的关联度,从而能在实体关联较弱的KG中更准确地得到关联实体.
为了进一步测试基于EAR发现关联实体的有效性,将前k个关联实体发现的召回率(R@k)和F1值(F1@k)与其他模型进行了比较,结果如图3和图4所示.我们观察到:

图3 top-k关联实体发现结果的召回率对比Fig.3 Comparison of recall of discovered top-k association entities

图4 top-k关联实体发现结果的F1值对比Fig.4 Comparison of F1-score of discovered top-k association entities
(1)EAR的召回率随着k值增大而稳定上升,且与其他4种模型在不同k值下的召回率差距不大.
(2)EAR在UserBehavior数据集中获得了最高的F1分数.当k值大于5时,EAR在MovieLens数据集中与其他模型相比能得到最高的F1分数.具体而言,相比于F1分数次高的模型,EAR在UserBehavior数据集的top 1、top 5和top 10关联实体发现中,F1分数分别提高了4.4%、3.4%和1.6%.在MovieLens数据集的top 6和top 10关联实体发现中,F1值分别提高了5.1%和4.5%.
4 结束语
本文基于关联规则表示KG查询实体和关联实体间的不确定性依赖关系.相较于基于KG结构的传统模型,通过将用户-实体数据相结合,关联实体发现的准确率有较大提升.对于实体之间关联较弱的KG,EAR能通过结合数据中的知识对KG领域知识进行补充,从而更有效地发现实体之间的关联.
实验还应该考虑以Wikipedia和Freebase为代表的大规模KG数据集,进一步测试本文提出方法的普遍性和实用性.基于本文的方法获取候选实体集时,未能充分利用KG实体之间路径的语义关系,如何有效利用KG中的路径信息发现候选实体集,是我们未来要开展的工作.
