基于SRNN+Attention+CNN的雷达辐射源信号识别方法
2021-11-29高诗飏董会旭田润澜张歆东
高诗飏, 董会旭, 田润澜, 张歆东,*
(1. 吉林大学电子科学与工程学院, 吉林 长春 130012;2. 空军航空大学航空作战勤务学院, 吉林 长春 130022)
0 引 言
雷达辐射源识别[1]是通过分析处理截获的对方雷达信号,获取对方雷达的工作参数和信号特征参数,通过与已知雷达数据库对比,判断雷达的型号、工作模式、位置,进而掌握其作战平台、工作状态、威胁等级等信息,为战场电磁态势感知[2]、威胁告警[3]、作战计划制定等提供情报支持。随着战场电磁环境的日渐复杂,传统的基于脉冲描述字(pulse description words, PDW)参数[4]的识别方法已经不能很好地满足低信噪比条件下雷达辐射源信号识别的要求。而低截获概率(low probability of intercept,LPI)雷达[5]的出现使雷达辐射源信号识别更加困难。因此,对雷达辐射源信号的准确识别,具有十分重要的现实意义。
雷达辐射源识别的关键是特征提取[6]。近年来,基于机器学习的雷达辐射源识别技术因其具有更强的泛化性和智能性受到研究学者的广泛关注[7]。作为机器学习领域的一个重要研究分支,深度学习及其应用也是人工智能领域的研究热点,在诸如机器翻译[8]、问题回答[9]、图像分类[10]、语音识别[11-12]、文本分类[13]等领域已经取得了很好的效果。深度学习与传统模式识别方法最大的不同在于其能够从数据中自动提取特征。通过逐层特征变换,将样本在原空间的特征变换到一个新特征空间,用简单模型即可完成复杂的分类任务,从而使分类或预测更容易。
国内外的许多学者将深度学习方法引入到雷达辐射源识别中,以期达到比传统人工识别方法更好的识别效果。文献[14]提出了一种基于卷积神经网络(convolutional neural networks, CNN)和基于树结构的机器学习过程优化识别方法,对二维时频图进行识别,在信噪比为-4 dB的条件下对12种信号的总体识别率达到94.42%。文献[15]提出了一种混合分类器,包括CNN和埃尔曼神经网络两个相对独立的子网络,在信噪比为-2 dB的条件下,12种信号的总体识别率达到94.5%。文献[16]提出利用深度卷积网络迁移学习的识别方法,将信号转化为时频图并进行预处理后,输入到CNN预训练模型中进行特征提取,最后用支持向量机分类器得到分类结果,在信噪比为-2 dB的条件下,对9类调制信号总体识别率可达97%。
上述方法主要的问题在于:第一,在低信噪比条件下,识别准确率不高,上述文献的实验结果多是在较高的信噪比下得出的,而在战场电磁环境中,这样的信噪比条件是很难达到的;第二,各类信号的识别准确率不平衡,特征不明显、不容易识别的信号也是最有可能被对方采用、威胁最大的信号,这种不平衡可能会造成严重的后果。由此也限制了这些网络的实际应用。
针对上述问题,本文提出了基于切片循环神经网络(sliced recurrent neural networks, SRNN)、注意力机制和CNN的雷达辐射源信号识别方法。通过SRNN网络提取雷达辐射源信号更高层次的信号特征,将输入的幅度序列转化成一个固定长度的向量,产生的特征向量经过Attention层处理后输入到CNN网络中,将特征向量转化成分类结果输出。在CNN中引入批归一化(batch normalization,BN)层,进一步提升网络的识别能力。
1 相关技术
1.1 SRNN
循环神经网络(recurrent neural networks, RNN)[17-18]是一类专门用于处理序列数据的神经网络。RNN中引入了循环结构,可以利用上下文信息,但是每一个状态都依赖前一状态的输入,这种串行结构训练需要花费大量的时间,这就限制了RNN的应用。
2018年,Yu等人提出了SRNN算法[19]。将输入的雷达辐射源幅度序列分割成几个具有相同长度的最小子序列并在每一个子序列上应用循环单元同时工作,信息通过多个网络层进行传递。将长度为T的序列划分成n个等长的子序列,重复划分操作K次,直到最底层的最小子序列长度合适为止。将每个子序列的输出合并为一个新的序列作为下一层的输入,即:
(1)
(2)

(3)
网络结构如图1所示。以一个1 024输入的SRNN计算模型为例,共划分2次,每次划分为8个子序列,则最小子序列长度为16。

图1 SRNN网络结构Fig.1 SRNN network structure
相较于标准RNN结构,SRNN在训练时间上具有优势。设每个循环单元花费的时间为r,对于标准RNN结构,训练所需时间为
tRNN=Tr
(4)
对于k+1层的SRNN网络,训练时间为
(5)
比较SRNN与RNN的训练时间:
(6)
序列长度T通常为定值。理论上,只要调整划分的份数n和划分的次数k,就可以调整SRNN相对于RNN的训练速度优势的大小。
1.2 注意力机制
注意力机制[20-22]最早应用于视觉图像领域,来源于人类的视觉注意力。通常人类视觉在感知物体时,会将更多的注意力聚焦到当前任务目标更关键的部分,从众多信息中选择出对当前任务目标更关键的信息。注意力机制本质上是一种权重概率分布机制,对重要的内容分配更大的权重,对其他内容减少权重。这样的机制更专注于找到输入数据中与当前输出显著相关的有用信息,发掘信号中的自相关性,突出与预测相关的部分特征,从而提高输出的质量,使得训练更为高效。工作原理[23]如图2所示。

图2 注意力机制工作原理Fig.2 Working principle of attention mechanism
注意力状态转换的实现如下所示:
(7)
(8)
(9)
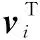
注意力机制的实现如图3所示。
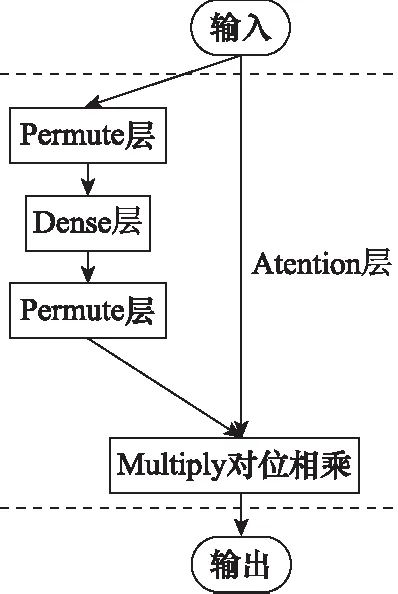
图3 Attention层结构Fig.3 Attention layer structure
1.3 BN
在训练时某一层的参数更新后,会导致该层网络的输出分布改变,使训练变得复杂。使用较小的学习率及较好的权重初值,会导致训练很慢,同时也导致使用饱和非线性激活函数时训练很困难。
BN层[24]是一种特殊的归一化层,由Ioffe等人于2015年提出,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定[24]。其出现解决了在训练过程中,中间层数据分布发生改变的问题。BN层的作用主要有3点[25]:① 加快网络训练和收敛的速度;② 防止梯度爆炸和梯度消失;③ 防止过拟合。BN层可以使优化环境更加平滑[26]。这种平滑性会导致渐变的预测性和稳定性更好,从而可以更快地进行训练。BN过程如下:
(10)
(11)
对于在神经网络中应如何使用BN层这一问题,一些学者也进行了研究。文献[24]认为BN层应该放在卷积层之后非线性激活层之前。而在目前的实践中,更倾向于把BN层放在激活函数层后面。文献[27]中对卷积层、BN层和激活函数层组成的3种网络方式进行了分析对比,得出结论:在复杂数据集和深度网络上卷积+BN+激活函数的组成表现更好,这样的组合使输入数据的范围更契合激活函数的定义域。在本身网络比较简单的情况下,BN+卷积+激活函数的结构能够更好地加速网络收敛,把输入映射到正态分布,加快当前层卷积网络的收敛。而卷积+激活函数+BN的组合方式将上一层的输出归一化,能够加快下一层的卷积的收敛。在不同的应用场景下,需要具体实验确定。
1.4 CNN
CNN[28-30]是一种深度学习模型,具备良好的表征学习能力,能自主学习雷达辐射源信号的特征,实现低级特征到高级特征的抽象提取。
传统的CNN模型由卷积、池化和全连接层构成。假设输入为x,卷积核为w,偏置为b,则卷积算子可以表示为
h=f(w*x+b)
(12)
式中:*代表卷积运算;f(·)表示卷积层的激活函数。
在CNN中,对卷积操作得到的局部特征采用池化方法提取的特征代替整个局部特征,可以大幅降低特征向量的大小。池化主要分为两种:平均池化和最大池化。
经过多个卷积-池化层提取雷达辐射源信号特征后,通过全连接层进行分类:
Output=softmax(W*X+b)
(13)
式中:W表示全连接层的权重;b为全连接层的偏置;softmax(·)为全连接层的激活函数,输出的每一个值都在[0,1]区间内,且和为1。这就将多分类的输出数值转化为概率,更容易理解和比较。
2 模型结构及训练流程
2.1 模型结构
模型结构如图4所示。

图4 模型结构Fig.4 Model structure
本文采用的模型主要由SRNN层、注意力层、3个相同的BN-卷积-池化层和Dense层组成。参数如表1所示,除表中提及的参数外,其他参数均为默认值。
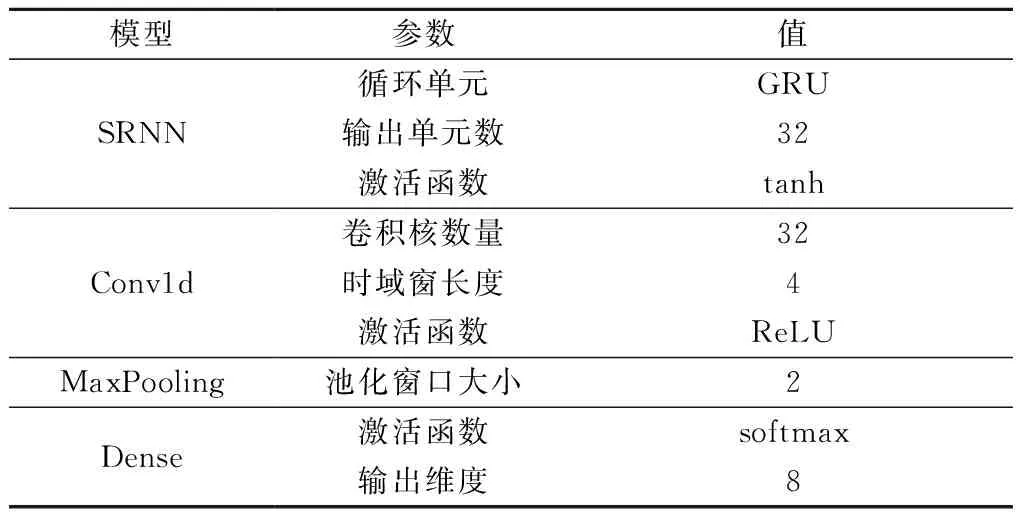
表1 模型参数
2.2 训练流程
模型训练流程如下。
步骤1数据预处理。对读入的雷达辐射源信号数据进行Min-Max归一化处理。归一化处理后数据的值在[0,1]内,特征向量中不同特征取值的差相对减小,降低了奇异样本数据导致的不良影响,可以加快梯度下降求最优解的速度。Min-Max转换函数如下:
(14)
步骤2建立训练集、验证集和测试集。将数据和标签对应随机打乱,按照60%、20%、20%的比例划分训练集、验证集和测试集。
步骤3对所有数据的标签进行one-hot编码[31]:one-hot编码针对离散型特征,将属性值转化为二元特征,在任意时刻只有其中一位有效。
步骤4对输入数据进行切割分片,满足SRNN对输入数据的维度要求。
步骤5设置优化器、损失函数、早停和学习率衰减。优化器采用AdamOptimizer;采用交叉熵损失函数;为了避免过拟合的发生以防止网络的泛化能力降低,引入早停机制,以验证集损失作为标准,在验证集损失连续10轮不减小时停止训练;引入学习率衰减,当验证集损失连续3轮不减小时,学习率下降为原来的10%。
步骤6训练网络。将训练集数据输入到网络模型中训练。设置初始学习率为 0.001,最大训练轮数为200轮,batch_size大小为200。
3 实验及结果分析
为了验证第2.1节构建的模型的性能,设计实验如下。首先,探究第1.1节SRNN相对于GRU的速度优势,并确定基本模型。其次,探究第1.2节注意力机制在网络中的效果。然后,探究第1.3节BN层对训练时间和识别准确率的影响,确定模型。最后,在前3个实验的基础上,对照经典网络模型,对第2.1节所构建的模型进行评价。实验环境如表2所示。

表2 实验环境
为了验证模型的性能,本次实验采用Matlab仿真的时域下雷达脉冲幅度序列数据得到的原始数据集,包括二进制相移键控(binary phase shift keying, BPSK)、科斯塔斯码(Costas)、调频连续波(frequency-modulated continuous wave, FMCW)、弗兰克码(Frank)、P相码(P1、P2、P3和P4)共8种信号,其中弗兰克码与P相码统称为多相码。信号信噪比范围-20~10 dB,步进2 dB;每种信号每种信噪比产生2 000个样本,每个样本长度为1 024。信号参数如表3所示。
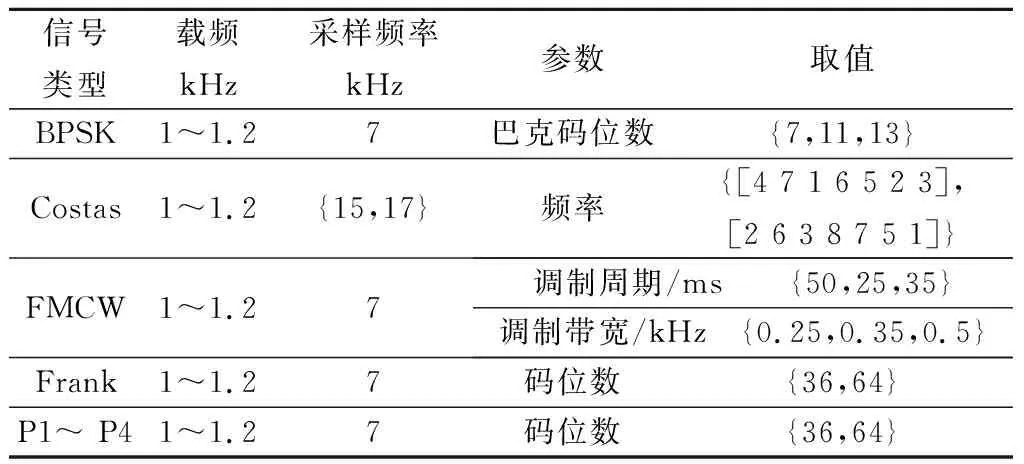
表3 仿真信号参数
实验 1验证第1.1节提出的SRNN相较于GRU的速度优势,并确定基本模型。通过比较测试集损失和识别准确率、训练轮数、训练总时间以及测试集测试的运行时间来衡量网络的训练效果。实验结果取多次实验的平均值,如表4所示。
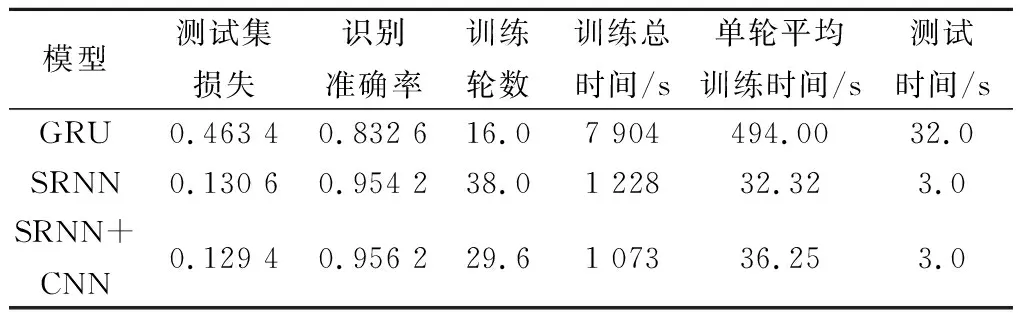
表4 实验结果
从SRNN与GRU的比较中可以看出,无论是从训练总时间还是单轮平均训练时间,SRNN均优于GRU,单轮平均训练时间仅为GRU的6.54%,证明了并行化结构的SRNN能够大大加快训练速度,解决训练时间过长的问题。进一步,在SRNN的基础上,与CNN结合,虽然单轮平均训练时间上相比SRNN有略微提升,但训练轮数有明显减少,网络收敛速度加快,训练总时间下降,识别准确率也略有提升。从测试时间上来看,与CNN结合并没有过多的增加模型的复杂程度,对测试集的测试时间几乎没有影响。因此,将SRNN+CNN确定为基本模型。
实验 2在实验1中SRNN+CNN基本模型的基础上探究注意力机制对训练时间和识别准确率的影响。
为了探究注意力机制对网络性能的影响,实验将是否使用Attention层作为自变量,分别训练网络模型。通过比较测试集损失和识别准确率、训练轮数、训练总时间以及测试集测试时间来衡量网络的训练效果。实验结果取多次实验的平均值,如表5所示。
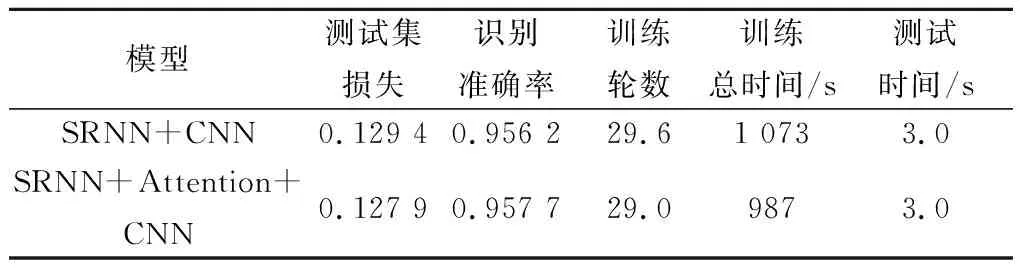
表5 Attention层对网络识别的影响
由表5可以看出,注意力机制能够在一定程度上降低损失,提高识别准确率,加快训练速度,训练时间相比不使用Attention层的网络减少了9%。Attention层将注意力更多地分配到需要关注的特征上,在一定程度上加快网络训练,提升网络的识别准确率。
为了观察Attention层关注了哪些特征,使得训练时间减少和准确率提高,设计实验探究Attention层的输入与输出特征向量的变化。实验步骤如下。
步骤 1在数据集中任取1个长度为1 024的信号,输入保存的模型中,获得Attention层的输入特征向量Feature1和输出特征向量Feature2。
步骤 2将Feature1和Feature2按统一的标准进行Min-Max归一化。取Feature1最小值与Feature2最小值中较小的作为归一化的最小值;同理,取二者最大值中较大的作为归一化的最大值。
步骤 3取归一化后Feature2与Feature1的差值FeatureDIF。
实验算法伪代码如下所示。

算法1中,FeatureDIF的正负代表Attention层对某一特征赋予更多或更少的关注,分配更大或更小的权重。
在FeatureDIF中截取长度为100的样本可视化输出,将结果绘制成火柴图,如图5所示。

图5 可视化输出结果Fig.5 Visual output
从图5可以明显的看出经过Attention层后特征的变化。Attention层对6/17/49/55/70/81等图中值为负的位置的特征分配了更少的注意力甚至不分配注意力;对39/53/85/96等图中值为正的位置特征分配更多的注意力,说明这些特征是对训练网络更重要的。
实验 3在实验2的基础上,探究BN层对训练时间和识别准确率的影响。
为了探究BN层对网络性能的影响,在实验2中SRNN+Attention+CNN模型的基础上,将是否在CNN中使用BN层以及BN层与卷积层和池化层的相对位置作为自变量,分别训练网络模型。通过比较测试集损失、识别准确率、训练轮数、训练总时间以及测试集测试时间来衡量训练效果,进而确定BN层在模型中的位置。实验结果取多次实验的平均值,如表6所示,表中Conv表示卷积层,AF(activation function)表示激活函数。
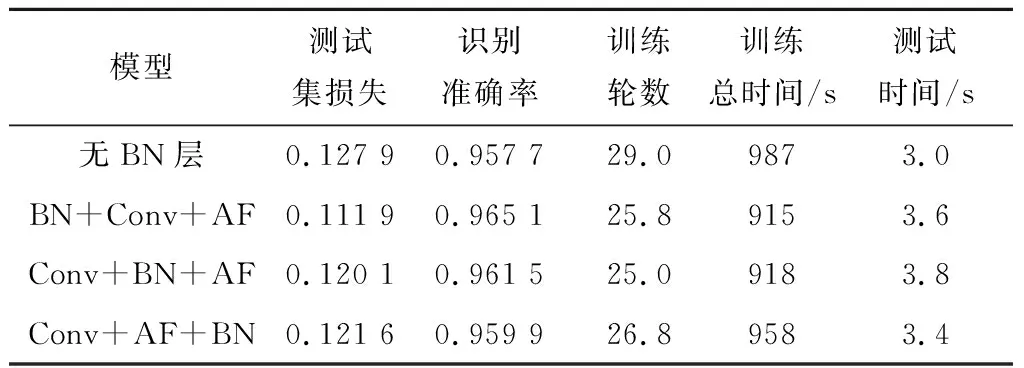
表6 探究BN层对网络识别的影响
从训练轮数与训练总时间可以看出,对于SRNN+Attention+CNN模型来说,BN层的使用使训练轮数明显减少,训练总时间减少,最多减少近8%,收敛速度加快。从测试集的测试时间上看,使用BN层会使测试集测试时间略微增加。
Conv+AF+BN的组合方式将上一层的输出归一化,第一层卷积输入并没有被归一化,因而相对于其他两种组合方式训练时间更长,理论上这种差异在卷积层数较少的网络中尤为明显。综合衡量测试集损失、识别准确率以及训练时间等方面,BN+Conv+AF的组合方式更有优势,损失低,识别准确率更高且训练时间和测试时间与Conv+BN+AF组合基本持平,因而本文选定这种组合方式作为最终方案。
实验 4在实验3选定的BN+Conv+AF的组合方式的基础上,首先探究SRNN+Attention+CNN模型在不同信噪比条件下对8种信号的识别情况。利用训练保存的模型对8种信号识别,在不同信噪比下识别准确率结果如图6所示。从图6中可以看出,信噪比大于等于-10 dB情况下基本可以达到100%的准确率;在-20 dB时全部信号的识别准确率均大于60%,BPSK和FMCW准确率超过70%,其他5种多相码信号准确率超过85%。

图6 SRNN+Attention+CNN模型在不同信噪比条件下对8种信号的识别准确率Fig.6 Recognition accuracy of SRNN+attention+CNN modelfor 8 kinds of signals under different SNR
8类信号的混淆矩阵如图7所示。

图7 SRNN+Attention+CNN模型混淆矩阵Fig.7 Confusion matrix of SRNN+Attention+CNN model
图7中,主对角线上代表信号被正确识别,同一行的其他格子代表被错误识别成其他7类信号对应某一类。格子颜色越深,代表相应的概率越高。可以看出,对角线上的颜色最深,证明大多数信号都能够被正确识别。BPSK与Costas、Costas与FMCW(图中红框)相互识别错误率相对比较高,结合图6可以说明,在低信噪比下以上两组信号比较接近难以区分。SRNN+Attention+CNN模型对Frank、P1~P4码5种多相码有较好的识别准确率,且相互之间错误识别的概率也普遍较小,证明模型对多相码的特征提取效果是比较好的。
在上述实验的基础上,进一步将SRNN+Attention+CNN模型与经典模型比较。通过比较测试集损失、识别准确率、训练轮数、训练总时间以及测试集测试时间来衡量网络的训练效果。实验结果取多次实验的平均值,如表7所示。

表7 SRNN+Attention+CNN模型与经典模型比较
从表7的实验结果中可以看出,SRNN+Attention+CNN模型相比于GRU,在训练速度方面有着明显的优势,在测试集损失以及识别准确率方面也有较大的优势。相比其他经典模型在识别准确率方面有一定的优势,在训练时间方面仅比AlexNet差,与VGG16持平,比VGG19和ResNet18更好。在测试时间方面, SRNN+Attention+CNN模型与AlexNet接近,与其他经典模型相比有很大的优势。
在表7实验结果的基础上,进一步探究6种模型在不同信噪比条件下的表现。用不同信噪比的8种信号对6种模型进行测试。测试结果如图8所示。

图8 6种模型在不同信噪比条件下的识别准确率Fig.8 Recognition accuracy of six models under different SNR
由图8可以看出,SRNN+Attention+CNN模型在低信噪比的条件下的表现相对于其他5种经典模型要更好,在-12 dB条件下识别准确率接近100%,在-20 dB条件下依然达到近80%,证明了SRNN+Attention+CNN模型在低信噪比的条件下有着较好的识别能力。
4 结 论
本文将SRNN模型引入雷达辐射源信号识别领域,提出了SRNN+Attention+CNN模型,对8种常见的雷达辐射源信号进行识别,并与其他5种经典模型进行比较。实验结果表明,本文提出的模型在低信噪比条件下能够对8种常见信号有效识别,相比于GRU模型在训练速度和识别准确率方面有较大的提升,相比于其他4种经典模型也有一定的优势。
