基于聚类分析的多天线标签环境反向散射系统
2021-11-25赵菊敏李灯熬
岳 恒,赵菊敏,李灯熬
(1.太原理工大学 a.信息与计算机学院,b.大数据学院,山西 晋中 030600;2.山西省空间信息网络工程技术研究中心,山西 晋中 030600)
物联网的普及和反向散射技术的发展给我们的日常生活带来了便利。由于电子标签与阅读器之间的通信距离较短,极大地限制了反向散射技术的发展。环境反向散射技术(ambient backscatter technology,ABT)的出现推动了反向散射技术的发展,开辟了物联网(IoT)的一个全新领域[1]。ABT是一种新的射频识别技术,它利用周围环境中的现有信号进行通信[2-3]。在环境反向散射通信系统(ambient backscatter communication system,ABCS)中,标签和阅读器之间的通信不需要阅读器产生极其耗电的载波信号,标签可以通过反射周围的无线电波(如电视塔或WiFi信号)。因此,ABCS可以看作是一种新的频谱共享模式,但目前只有相关实验验证了其可行性,相关的理论研究还有待完善[4-5]。
本文主要研究ABCS中多天线标签信号检测的问题,提出了一种新的ABCS模型,针对K-Means算法存在的不足,根据时间的相关性,提出了一种基于队列的方式来计算聚类中心的K-Means-Q(Queue ofK-Means)算法,降低了误码率。与其他研究人员使用的方法不同,该方法可以避免检测时的信道估计。由于信道估计是消耗功率的,因此本文提出的方法可以降低功率压力。理论分析表明,新模型提高了信号通信速率。
1 相关工作
在ABCS中,阅读器接收两种类型的信号:直接链路信号和反向散射信号。因此,ABCS中的关键问题是如何从强干扰信号中分析出弱反向散射信号。一些现有方法使用直接链路信号作为背景噪声的一部分[1,6-7]。在文献[1]和[6]中,能量检测器用于检测后向散射信号。在文献[7]和[8]中,提出了最大似然检测差分调制。近年来,干扰消除技术被应用于ABCS阅读器的设计[9-13]。在文献[9]和[10]中,使用正交频分复用(OFDM)信号的复杂结构来消除直接链路干扰。在文献[14]中,提出了一种基于机器学习的ABCS信号检测方法。该方法直接提取接收信号的特征,通过无监督学习对接收信号进行分类,实现信号检测。此外,通过发送前导来辅助信号检测,不需要估计信道系数和噪声功率。文献[15]提出了一种降低标签在不同编码模式下误码率的理论模型。文献[11]设计了一种双天线接收机模型,通过计算双天线接收信号的幅度比来抵消射频源信号的影响。在文献[16]中,提出了一种阅读器中具有多个天线的ABCS.由于标签只反射信号,当使用多个天线时,信号将通过功率分配进行传输。在阅读器处,首先通过接收的信号检测较高功率的信号。接下来,通过使用第一检测到的信号来检测来自其他天线的信号。由于ABT通常使用能量检测,因此其具有较低的通信速率。在文献[17]中,设计了一种多天线标签系统模型,阅读器不需要知道射频信号功率和信道状态信息,仅使用盲检波器来恢复标签信号。
对于ABT的研究,现有的设计都是在降低信号传输速率的基础上进行的,但均不适合实时性要求较高的场合。因此,本文中详细介绍一种提高ABCS传输速率的可行方案以及ABCS信号检测的算法。
2 多天线标签环境反向散射通信系统
2.1 系统模型
MTABCS模型如图1所示。系统包含环境中的射频源(如无线网络基站、电视塔等)、标签(Tag)和阅读器(Reader)。其中标签带有3个天线,天线1与天线2用来与阅读器通信,由于多天线同时通信,其能耗较高,因此需要采用单个天线从环境中采集能量,使天线3负责从环境中获取能量。
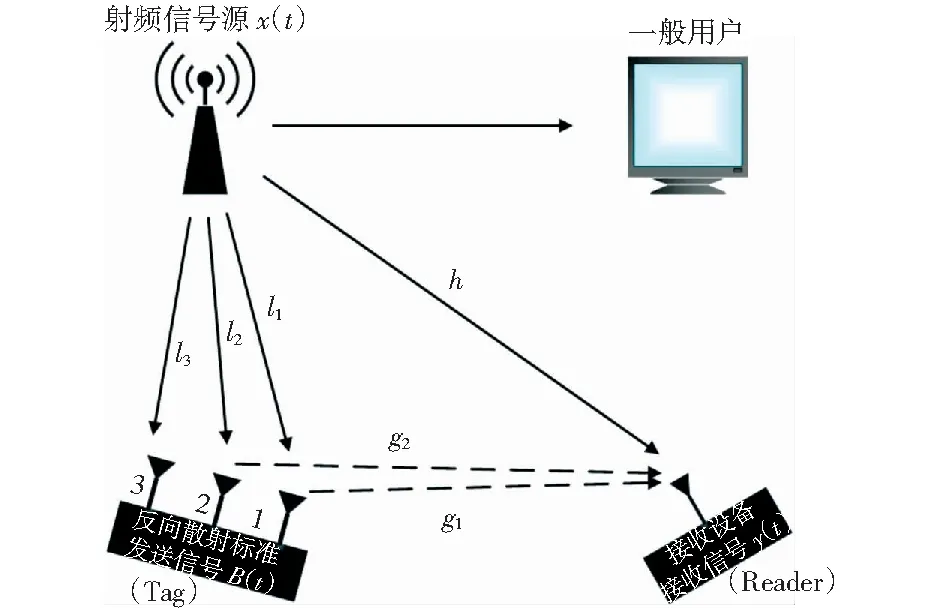
图1 多天线标签环境反向散射通信系统通信模型Fig.1 Multi-antenna tag ambient backscatter communication system communication model
2.2 多天线标签的整体框架
多标签天线的整体框架如图2所示,其主要包含通信模块、能量采集模块、MCU以及各类传感器4部分。由于多天线标签采用天线1和天线2与阅读器通信,因此,通信模块包含两组通信通道。
在MTABCS中,三天线标签工作原理为天线3接收来自环境中的电磁波信号,通过感应电路产生感应电流,并将产生的能量存储在储存单元中。天线1和天线2负责数据反射,其中反射数据需要的能量由天线3供给。多天线标签工作原理与单天线标签的主要区别在于多天线标签使用两个天线进行并行传输,以提高通信速率,并且为了减少标签之间的干扰,使三天线标签使用双频段工作,即能量收集天线3拟工作在415 MHz频段,数据反射天线1和天线2拟工作在825 MHz频段,以减小两种天线之间的干扰。天线1和天线2传输的数据分配由MCU控制,实现数据并行传输并在阅读器端进行解码以提高整个系统的通信速率。
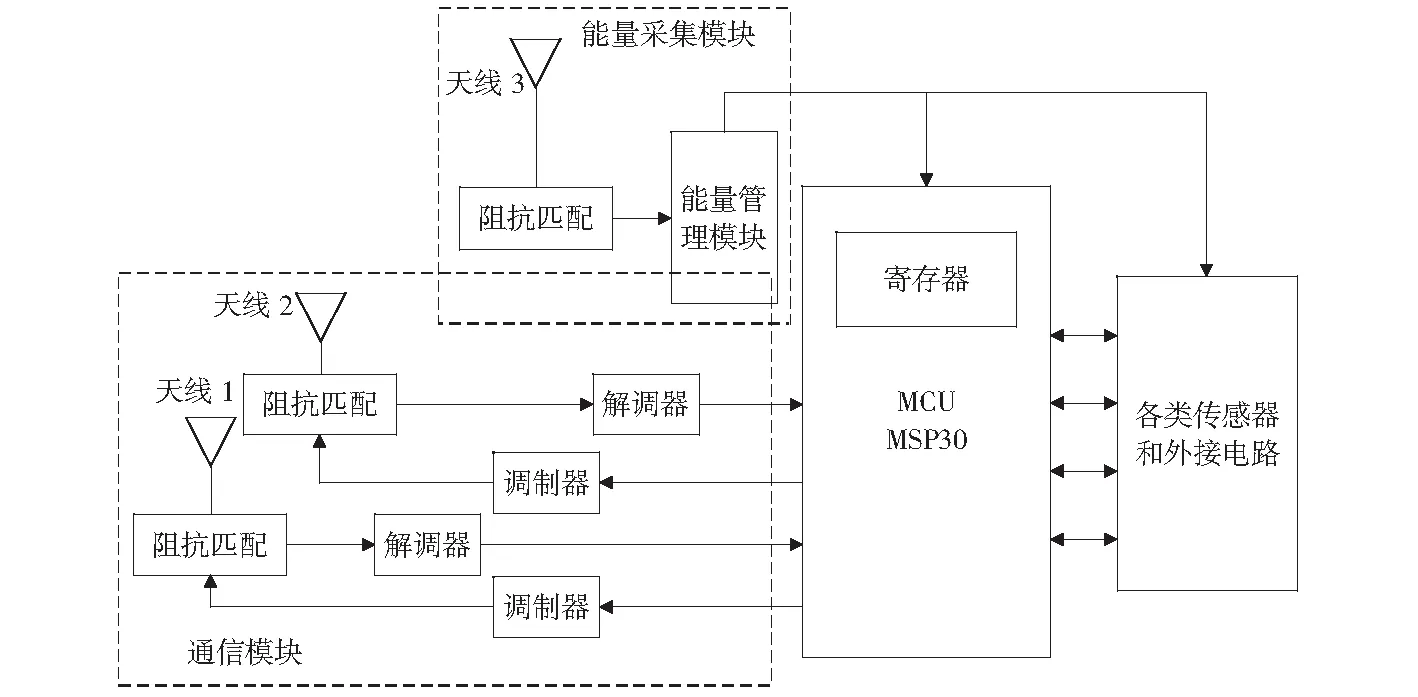
图2 多天线标签的整体框架Fig.2 Whole frame of multi-antenna tag
2.3 信道感知
MTABCS模型利用多天线标签来提高AmBC系统的通信速率。因此阅读器需要对接收到的信号进行检测和对来自标签的两个天线的反射信号进行解码。由于阅读器接收的信号较为复杂,且信号信道响应不同,传统的信号检测的方法比如平均化功率、阅读器多天线对比、非相干检测器以及盲均衡检测器等算法不适用于MTABCS模型,因此提出基于聚类分析算法的信号检测方法实现信号的解码。
如图1,设射频信号源x(t)=Asin(2πft+φ0),多天线标签按照其码元信号B1(t)和B2(t)分别控制其天线1与天线2的反射与不反射,其中B1(t),B2(t)∈{0,1}.因此接收设备接收到的信号y(t)是被B1(t)和B2(t)调制后的电视塔信号。设射频信号源与多天线标签天线1之间的信道响应为l1,射频信号源与多天线标签天线2之间的信道响应为l2,射频信号源与阅读器之间的信道响应为h,多天线标签天线1与阅读器之间的信道响应为g1,多天线标签天线2与阅读器之间的信道响应为g2,多天线标签天线1的功率反射系数为α1,多天线标签天线2的功率反射系数为α2.
根据上述的描述可知,多天线标签天线1从环境中接收到的射频信号x1(t)可以表示为:
x1(t)=l1Asin(2πft+φ1) .
(1)
式中:φ1表示相移。多天线标签天线2从环境中接收到的射频信号x2(t)可以表示为:
x2(t)=l2Asin(2πft+φ2) .
(2)
式中:φ2表示相移。由于存在相移,因此阅读器接收到的来自多天线标签天线1的射频信号c1(t)可以表示为:
c1(t)=α1B1(t)g1l1Asin(2πft+φ11) .
(3)
同理阅读器接收来自多天线标签天线1的射频信号c2(t)可以表示为:
c2(t)=α2B2(t)g2l2Asin(2πft+φ22) .
(4)
式中:φ11和φ22分别表示相移。因此接收机接收到的多天线标签的信号c(t)可以表示为:
c(t)=c1(t)+c2(t) .
(5)
由于存在相移,阅读器接收到来自射频信号源的信号q(t)可以表示为:
q(t)=hAsin(2πft+φq).
(6)
其中φq表示相移。由于阅读器同时接收来自射频信号源的信号和多天线标签反射的信号,因此阅读器接收到的信号y(t)可以表示为:
y(t)=q(t)+c(t)+w(t) .
(7)
其中的w(n)是功率为σ2的加性高斯白噪声,即w(t)~N(0,σ2).
3 多天线标签环境反向散射通信系统的信号检测
3.1 信号检测理论分析
本文研究多天线标签AmBC系统的信号检测则是根据阅读器接收的信号y(t)还原出多天线标签两个天线的反射状态,进而推导出标签的码元信息。
由公式(7)得到y(t)可以表示为:
y(t)=hAsin(2πft+φq)+α1B1(t)g1l1Asin(2πft+
φ11)+α2B2(t)g2l2Asin(2πft+φ22)+w(t) .
(8)
多天线标签两个天线的码元B1(t),B2(t)∈{0,1}并行传输时,在接收端收到的信号相应有4种状态,根据B1(t)和B2(t)不同的取值,可以得到公式(9).由和差公式,公式(9)可以简化表示公式(10).
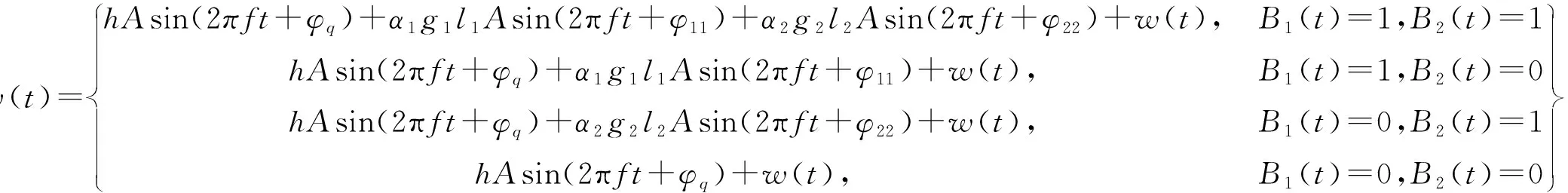
(9)
(10)
不考虑噪声的干扰,即理想情况下y(t)可以表示为:
(11)
为求其对应系数,用cos(2πft)乘公式(11)两边可得公式(12).对公式(12)两边积分得公式(13).其中T为射频源信号的周期,可对应求得:b11、b10、b01、b00.同理使用sin(2πft)乘公式(11)两边并对其进行积分,并求得:a11、a10、a01、a00.将有序数对(a11,b11)、(a10,b10)、(a01,a01)、(a00,b00)与平面直角坐标系上的4个不同的点相对应,解码B1(t)和B2(t).
(12)
(13)
3.2 基于K-Means-Q聚类分析算法的信号检测
K-Means算法是ABCS中常用的信号检测算法,相比于其他信号检测算法性能优越,其在进行聚类时所有数据是等权参与运算的,即每个簇的聚类中心是根据所有属于该簇的点来更新的。当信道状态发生变化时,这样的处理方式会导致较高的误码率,其鲁棒性较差。为了提高系统的稳定性,针对K-Means算法存在的问题,考虑到在实际场景中,当前时刻的信道状态往往与其邻近时刻的信道状态相关性较大,与非邻近时刻的信道状态相关性较小,提出一种基于队列的方式来计算聚类中心的K-Means算法,称之为K-Means-Q算法。其主要是利用4个队列来分别存储最新收集到的固定数量数据,在更新每个簇的聚类中心时只有相对应的队列中的数据参与运算,这就避免了由于所有数据都参与聚类中心的更新而引发的系统稳定性变差的问题。
具体而言,基于K-means-Q聚类分析算法的信号检测步骤如下。
输入:输入信号IQ域图集Ti={L(1),…,L(NoC×4),D(1),…,D(NoD)},其中Ti为Li和Di之和,Li={L(1),…,L(NoC×4)}是循环NoC次的前导码对应的IQ域图上的点,Di={D(1),…,D(NoD)}是标签发送NoD次的码元数据对应的IQ域图上的点;长度为m的4个队列M1、M2、M3、M4,对应存储属于簇的最近的m个数据点。
裁判的判罚会偶尔失误,判罚错误或误判,这种失误有时会影响运动员比赛的心情,更严重时候,如在关键分时候,有可能会改变比赛的结果。
输出:4个簇中心c1、c2、c3和c4,以及每一个码元数据Di对应的解码值,满足SSE收敛。
1) 由于已知前导码码元信息,可以将Li={L(1),…,L(NoC×4)}对应到不同的聚类集C1、C2、C3、C4中。
2) 利用平均值法
分别计算每个聚类中的聚类中心c1、c2、c3和c4.
3) 将步骤2计算的4个聚类中心c1、c2、c3和c4分别存储到对应的队列M1、M2、M3、M4当中。
4) 计算码元数据D到四个簇的聚类中心的欧几里的度量,对于度量较短的,便将其分类到对应簇Ci中。
5) 判断分类成功的数据对应的队列Mi是否已经满,如果Mi已经满,则将队首的数据移除,并将数据D放入到队列Mi的队尾。如果Mi未满,则将数据D直接放入到队列Mi的队尾。
6) 利用队列Mi重新计算簇Ci的聚类中心ci,
|Mi|为队列的有效长度,mx为属于Mi中的数据点。
7) 循环步骤4、5、6,直到码元数据D判断完成。
8) 输出4个簇的聚类中心c1、c2、c3和c4,以及每一个码元数据Di对应的解码值。
4 仿真实验
仿真方式验证本文设计的基于多天线标签的AmBC系统通信速率的高效性,将本系统使用的K-Means-Q算法与ABCS中常用的K-Means算法进行性能比较。在仿真实验中,设定射频源信号频率为450 MHz,前导码信号是00011011码,重复10次,数据信号是随机生成的,长度为1 000 bit,信噪比设置为5.
图3显示了射频源信号、标签信号和阅读器接收信号的波形。图3(a)是射频源信号,图3(b)和图3(c)是由标签天线1和2发送的前同步码信号和数据信号。图3(d)是读取器接收的信号,其包括射频源信号和标签反射信号。
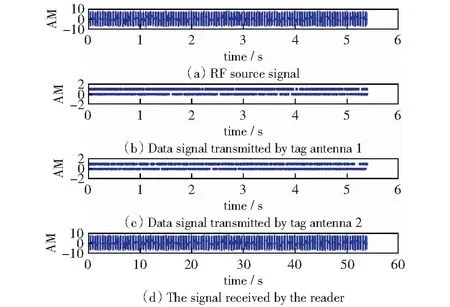
图3 射频源信号、标签信号和阅读器接收信号波形图Fig.3 Waveform of radio frequency source signal, tag signal,and reader received signal
阅读器接收到的信号是射频源信号和标签反射信号的混合信号,利用K-Means算法进行解码。由于系统模型为标签双天线通信,因此算法的分簇中心数K设置为4、前导码重复数设置为10.图4为利用K-Means聚类算法进行数据分类的星座图。图4(a)展示了1 000个数据集的原始分布,通过K-Means聚类分析算法后得到图4(b).从图中可以发现,K-Means聚类算法对整体信号数据处理效果较好,给出了4个明显的聚类中心,但是对于一些边缘离群点的处理较差,比如图4(b)中被圈住的多个数据点,容易出现分类错误,这说明该算法存在部分不稳定性,误码率较高。
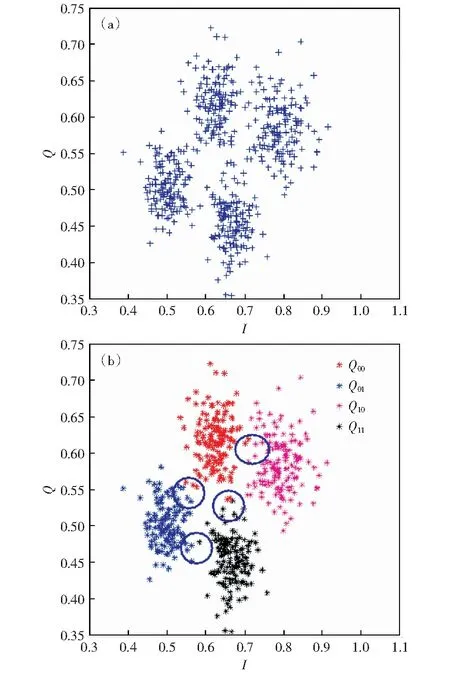
图4 聚类分析算法前后数据分布图Fig.4 Data distribution diagram before and after cluster analysis algorithm
利用K-Means-Q算法进行解码,该算法设置K的取值为4,前导码重复次数设置为10,队列长度M设置为25.利用K-Means-Q聚类算法进行数据分类的结果如图5所示。图5(a)为初始1 000个数据集的原始分布,通过K-Means-Q聚类分析算法后得到图5(b).从图中可以发现,相较于K-means算法,K-means-Q聚类算法可以获得更高的准确率,并且对于一些边缘群点的处理较好,比如上图中被圈住的多个数据点,误码率较低。
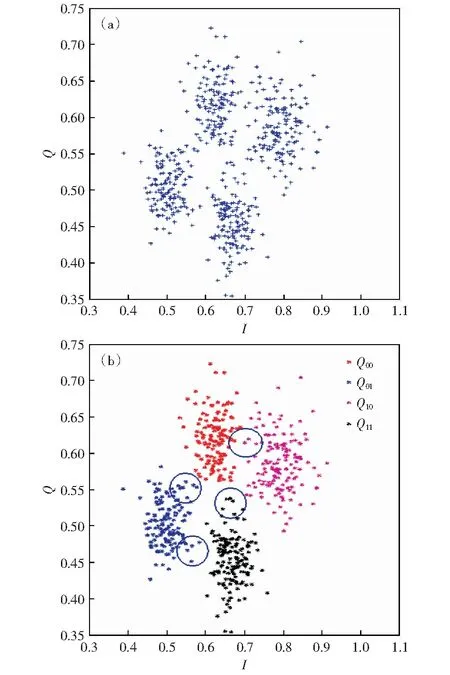
图5 聚类分析算法前后数据分布图Fig.5 Data distribution diagram before and after cluster analysis algorithm
K-Means-Q算法性能优于K-Means算法的关键在于K-Means-Q算法引入队列来存储相关性较大的数据集,摒弃了相关性较小的数据,从而提高了聚类中心的准确性。随着M的变化,K-Means-Q算法的性能也会有所变化。设置发送1 000 bit数据,比较队列长度M和误码率(BER)在不同信噪比(SNR)下的关系,如图6所示。从图中可以看出,当信噪比一定的情况下,随着M的增大,系统误码率出现先降低后升高的变化趋势。当M较小时,由于信号存在不确定性,聚类中心的计算有较大的误差,随着M的增大,数据集平均值趋于稳定,误码率降低。当M较大时,随着M的增大,误码率变高,这是因为聚类中心的确定队列加入了与当前时刻的信道相关性较弱的数据集,并且随着SNR的降低,最佳的队列长度逐渐增大。
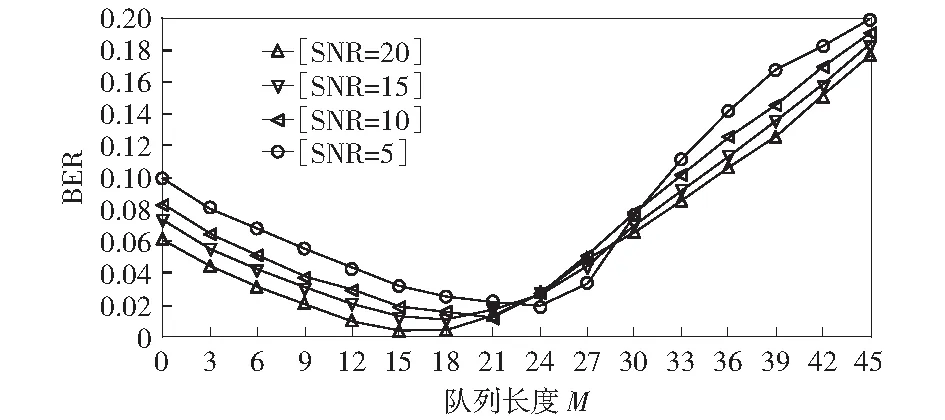
图6 M和BER之间的关系对比图Fig.6 Relationship between M and BER
由图6可知,当信噪比等于20、队列长度M等于15时,误码率最低。图7显示K-Means-Q算法与K-Means算法在发送不同的数据量时误码率的对比。其中K-Means-Q算法中队列长度M设置为15.由图可以看出,随着数据量的增大K-Means-Q算法的误码率基本保持稳定且相对较低,而K-Means算法的误码率随着数据量的增多不断升高。由此可以看出K-Means-Q算法性能较好。
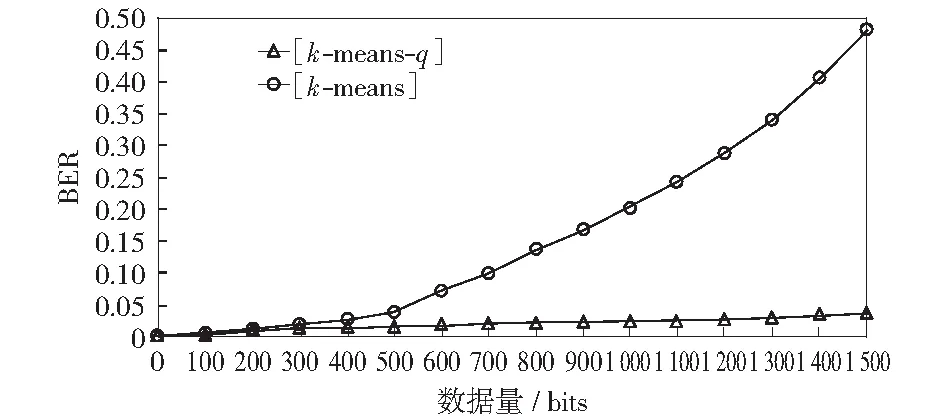
图7 K-Means-Q算法和K-Means算法误码率的对比Fig.7 Comparison of BER between K-means-Q algorithm and K-means algorithm
5 结论
本文针对传统的ABCS通信速率低的问题,提出一种MTABCS模型,标签利用两个天线同时与阅读器通信,使信号传输速率加倍。阅读器使用K-Means-Q算法检测信号,将接收到的信号分为四类,在一定的数据比特传输后重新计算聚类中心,提高了信号检测的准确性。
