一种基于三视图像的三维人脸建模方法
2021-11-24张释如穆本麒
张释如,朱 萌,穆本麒
(西安科技大学 通信与信息工程学院,陕西 西安 710054)
0 引言
三维人脸相比二维人脸包含了更丰富的人脸结构和表情信息,在许多应用中有着更精准、更鲁棒的优势。近年来,三维人脸模型的应用场景不断拓展,在人脸识别[1-3]、医学整形[4]、人脸动画影视制作[5]等方面均起着巨大作用。
三维人脸建模的研究至今已有近50年历史,相关国内外研究者提出了许多建模方法。通常将其分为两大类:扫描设备驱动的和图像驱动的三维人脸建模方法。前者需借助三维扫描仪等采集数据,其体积大、价格昂贵等缺陷限制了应用扩展。相反,后者使用普通相机或手机拍摄的照片就可实现建模,具有更广阔的应用前景。
图像驱动的三维人脸建模通常又可以分为直接和间接的方法,二者区别在于是否使用了通用人脸模型。前者直接从图像获取人脸三维信息来建模,建模效果严重依赖于提取特征点的密集程度,且对额头、脸颊等弱纹理区域,由于特征点太少,常会导致重建模型出现空洞等。后者实现建模需借助通用人脸模型,根据从目标人脸图像中提取的特征点计算深度来形变通用模型,使其逼近目标人脸。由于通用模型的完整性,这种间接式方法建立的模型不会因遮挡或提取的特征太少产生空洞,且这种通用模型在不同的面部表情间建立了潜在的转换,可以实现跨姿态的人脸建模[6],是近年来三维视觉领域的研究热点。
在此之前,研究者们[7-10]采用间接三维人脸建模方法,利用单张照片重建三维人脸的工作已取得了众多成果,但单张照片本身所含信息有限,导致模型的侧面轮廓类似通用人脸。鉴于对更高精度三维人脸模型的追求,近几年众多学者对多视角、多张照片及视频序列等人脸建模展开研究。蔡麟等[11]提出了一种多阶段优化框架,通过将通用模型向7个视角的图片拟合,实现了多视角高精度的人脸重建。Zeng等[12]针对现有通用人脸参考模型对多种族人群重建高精度人脸能力有限的问题,探索出一种基于不同参考模型,采用阴影先验的、用于对一幅正面(0°)和两幅侧面(±90°)人脸图像重建三维模型的方法。Shao等[13]针对单张照片三维人脸特征分析和身份识别常常失败的问题,提出一种多域姿态归一化网络,实现了多视图高精度的三维人脸识别。Song等[14]针对两视图视频流,提出了一种轻量级的恢复人脸几何形状的方法。Hernandez等[15]提出了一种SFM的固定姿势级联回归方法来重建无约束视频中人脸的三维形状。
单视图建模因所含信息太少导致模型侧面效果不佳,多视图及视频的人脸建模均以牺牲计算时间来提高建模精度,即使用图片数目越多,建模精度越高,但计算成本也更高。因此,应以使用更少的图片数目重建出更高精度的人脸模型为目标进行研究。本文采用间接建模方法对更少视图的人脸建模展开研究,提出了一种基于三视图像由粗到精的人脸建模方法。该方法将人脸建模分为粗糙和精细两个阶段。前一阶段,针对输入三视图像中定位人脸特征点的匹配问题,提出一种基于改进LBP特征的稀疏匹配方法进行精准匹配,进而计算深度并形变模型,生成粗糙人脸模型。后一阶段,以粗糙模型为初始人脸,将传统单视图双线性模型扩展至三视图像,并结合三视图像中提取的特征及纹理先验,重新定义模型的能量函数来实现模型匹配;最终为进一步精细化模型的非特征区域,采用了点形变和曲线形变相结合的方法,重建生成了精细三维人脸模型。
1 本文方法
本文三视图像人脸建模方法的实现流程见图1。该方法将整个建模过程分为粗糙建模(虚线框内所示)和精细建模两大阶段。前一阶段生成了包含特征形状信息和表情信息的粗糙人脸模型,为后一阶段模型的定义提供了初始形状,从而促使精细阶段生成既包含几何形状和表情,又包含纹理信息的精细三维人脸模型。
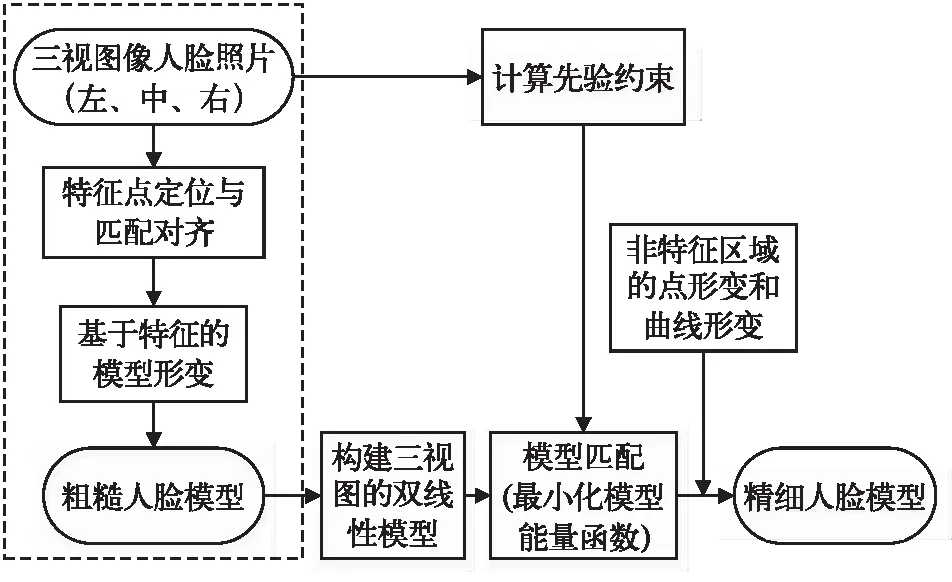
图1 三视图像人脸建模方法实现流程
1.1 粗糙人脸建模
粗糙人脸模型具有基本的人脸几何形状和表情信息,但没有色彩纹理及更细节的形状信息,其是本文后续精细建模的基础。图1流程显示,粗糙建模需先定位输入三视图像上的人脸特征点并进行匹配,进而计算特征点的深度并映射到通用人脸模型上来生成粗糙人脸模型。
1.1.1 三视图像人脸特征点的定位与匹配
1)人脸特征点定位
基于级联回归的人脸特征点定位方法凭借定位速度快、误差小、对遮挡和一定偏角的人脸也能准确定位等优势,目前已成为人脸特征点定位的主要方法之一[16]。本文输入三视图像的左、右两幅人脸具有一定偏角,因此采用了文献[17]提出的基于级联回归的集成回归树算法(Ensemble of Regression Trees, ERT)。该算法通过级联多个梯度提升决策树(Gradient Boosting Decision Tree, GBDT)来一级级地将每级对人脸特征点位置的估计进行回归,不断逼近真实位置。结合Dlib机器学习库,本文采用ERT算法进行68个人脸特征点的定位,结果见图2,可以看到对有一定偏角的侧面人脸也能准确定位。

图2 68个人脸特征点的定位
2)人脸特征点匹配与深度计算
在均匀光照下同步采集三视图像照片,其成像像素受人为因素及光照的影响较小,但难免会受噪声等的干扰。针对精准匹配定位人脸特征点的问题,提出了一种基于改进LBP特征的稀疏匹配方法。该方法以LBP算法为基础,即以某像素点p为中心建立半径为r的窗口,依次比较窗口内周围像素点与中心像素点的灰度值,当周围像素点灰度值小于中心点时,将该点记为0,否则记为1,这样按序拼接后得到8×r位LBP特征二进制编码。为使匹配算法具有一定抗噪能力,将原始LBP中的窗口中心像素灰度值用窗口内各像素灰度值的平均来代替,完成改进LBP特征编码。以3×3窗口为例,加入干扰前后,计算LBP编码见图3,其中avg为窗口内所有像素灰度值的平均。
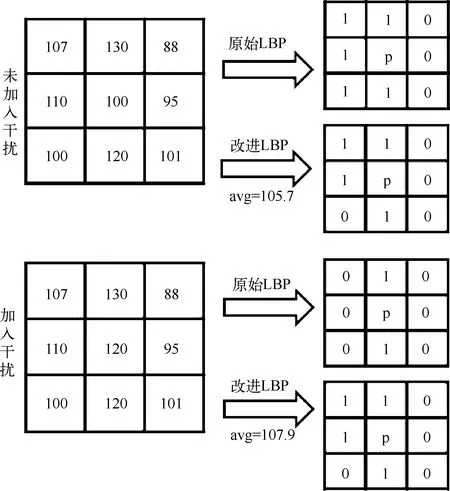
图3 计算LBP特征编码
从图3中可以看到,改进LBP具有一定的抗噪能力。本文基于改进LBP实现人脸定位点稀疏匹配的具体步骤如下:
输入三视图像及其定位的特征点坐标
输出左、右视图的定位特征点分别与中间视图特征点进行匹配后的坐标
步骤1外层循环遍历中间视图特征点的坐标,依次计算特征点处半径为r的窗口内像素灰度值构成的8×r位改进LBP编码;
步骤2内层循环遍历左或右视图特征点的坐标,在各自视图上对应特征点处l×l的邻域内,按步长为1再遍历得到每个特征点对应的(l-2)2个候选匹配点的改进LBP编码;
步骤3根据LBP编码依次计算中间视图特征点与其左右视图的候选匹配点的相似度(采用二进制比特串的汉明距离),比较后得到最佳匹配点。
采用该方法匹配稀疏点时,选取参数r=1,l=8。以中间视图定位特征点为基准,在左右视图的定位点及其邻域内寻找对应的匹配点。匹配结果见图4,其中 68个定位点均精准匹配。根据匹配点的坐标,利用双目视觉原理,由式(1)即构成立体图对的左、右图中特征点坐标的欧氏距离近似计算视差。利用小孔成像及相似三角形原理,由式(2)计算深度,由式(3)计算特征点在当前相机坐标系(将中间视图的相机坐标系看作世界坐标系)的坐标。

图4 稀疏特征点匹配结果
(1)
(2)
(3)
式中,(xil,yil)和(xir,yir)分别为立体图对的左、右图上第i个特征点的二维图像坐标,di为其视差值,b为基线距离,f为焦距,(Xic,Yic,Zic)为该特征点在当前相机坐标系下的坐标,同时Zic为其深度。
根据相机与世界坐标间的刚性变换,由式(4)可准确恢复特征点的真实世界坐标。
(4)
式中,(Xiw,Yiw,Ziw)为第i个特征点的世界坐标,R和T分别为相机的旋转矩阵和平移向量。
1.1.2 特征区域的模型形变
前面已得到人脸定位特征点的真实世界坐标,将其映射到三维通用人脸模型上即可实现模型形变。本文采用3DMM(3D Morphable Model)原理,则加性通用人脸模型由式(5)表示。
(5)
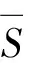
经最小化通用模型上定位点坐标s3d和真实人脸坐标s3dt之间的距离来估计模型参数,见式(6),进而实现模型形变,生成粗糙人脸模型。
(6)
图5给出使用该方法生成的粗糙人脸模型。可以看到,能初步恢复脸型轮廓和表情信息。

图5 三视图像的粗糙人脸模型
1.2 精细人脸建模
粗糙模型远不够表达人脸的真实形态,因此还需对其精细化处理,使模型特征区域和非特征区域的几何分布都更接近人脸的真实结构,并结合纹理信息,最终生成精细化彩色三维人脸模型。
1.2.1 三视图像的双线性模型精细化方法
根据图1流程,模型精细化主要分为模型定义、计算先验约束和模型匹配三个阶段。
1)模型定义
以粗糙模型为初始人脸,采用基于3DMM的BFM(Basel Face Model)模型来构建多视图人脸双线性模型,见式(7)。
(7)
式中,记Mk(Wid,Wexp)=Vk是估计模型上的第k个顶点,Cri,j是模型原始核心张量简化后的张量,Wid是形状系数的m维向量,Wexp是表情系数的n维向量,本文设置m为50,n为25。
根据小孔成像和弱透视投影原理,利用式(8)将三维人脸模型的每个顶点投影到二维空间。
Pi(Vk)=si×Ri×Mk(Wid,Wexp)+Ti
(8)
式中,Mk(Wid,Wexp)见式(7),i={L,C,R}为左、中、右视角的相机,si为比例因子,Ri为旋转矩阵,Ti为平移向量,Pi为该模型上某个顶点投影到i视角的二维图像空间的点。
2)计算先验约束
(1)特征约束
在粗糙建模阶段定位的68个特征点涵盖了脸部最重要的部位,因此将其用作特征先验来估计精确的人脸模型轮廓。在初始人脸模型上按定位特征点的顺序在相应顶点处标记一组点(图6中绿色点集),用Mj(Wid,Wexp)表示,j为标记点的顺序索引。该特征先验即约束模型上标记点投影到二维空间的坐标和该标记点在三个视图上定位特征点的坐标之间的距离,由式(9)表示。
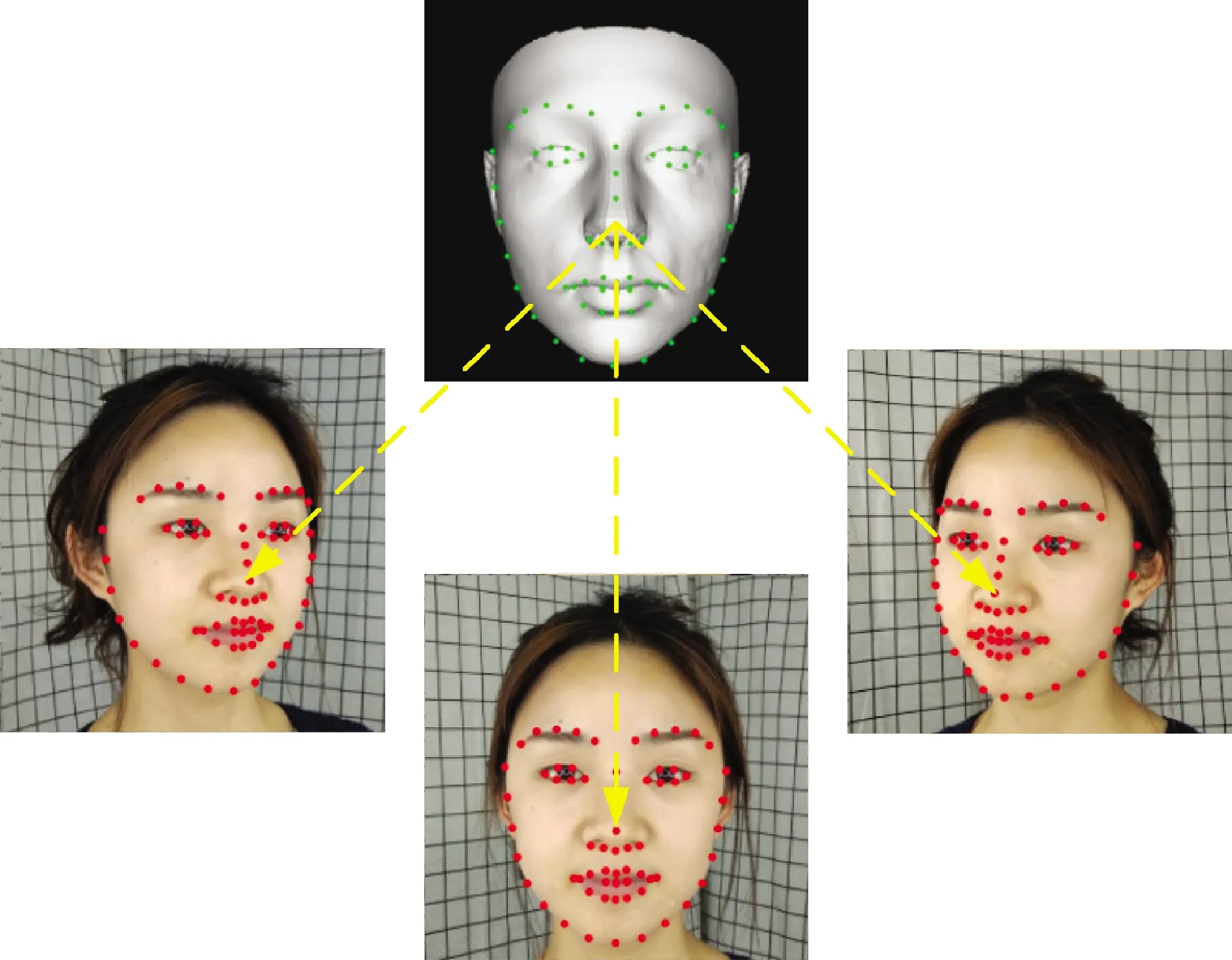
图6 模型标记点与三视图像人脸定位特征点的对应
(9)
(2)纹理约束
仅由特征约束估计的人脸模型没有色彩信息,因此本文引入了自适应纹理约束来增强模型的真实感。根据式(8)将模型上每个顶点投影到三视图像的空间,投影点表示为Pi(Vk),i={L,C,R}。从模型的同一顶点向三个视图投影,则对应的投影点就是立体匹配点,见图7。

图7 模型顶点与三视图像人脸像素点的对应
设以投影像素点Pi(Vk)为中心的邻域记为N,其半径设为5,(u,v)为该像素点的坐标,(u′,v′)为其邻域N内像素点的坐标,由式(10)~式(13)计算该像素点(u,v)处的纹理方差中心,则自适应纹理约束可由式(14)表示,用于惩罚匹配像素间的误差,将三视图像与三维模型间的匹配纹理差异降到最低,使模型整体的纹理与真实人脸更相似。
(10)
ψi(u,v,u′,v′)=D(u,v,u′,v′)H(u,v,u′,v′)
(11)
(12)
(13)
(14)
式中,Ci(u′,v′)为RGB颜色通道,ψi(u,v,u′,v′)为双边权重,D(u,v,u′,v′)和H(u,v,u′,v′)分别是距离权重和颜色权重,σD和σH分别是图像坐标的标准差和图像纹理空间的标准差。
(3)正则化约束
为防止形状和表情系数过拟合,本文引入正则化约束。BFM库包含近3000张人脸混合模型,第m个模型的形状和表情系数由式(15)表示。
(15)
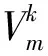
(16)
3)模型匹配
利用特征约束Ef、纹理约束Et和正则化约束Er构建多视图的能量函数见式(17)。
E=λf×Ef+λt×Et+λr×Er
(17)
式中,权重λf、λt、λr表示各约束的相对重要性,之和为1,本文分别设置为0.4,0.3,0.3。为保证三个约束起到均衡作用,通常权重会选择较接近的三个值,但针对有特定要求的建模,则对权重值的选取有特定要求。当要求重建模型五官及轮廓的精度足够高时,对应λf选择相对大的值;当需要重建模型的纹理更自然、且与真实人脸更相像时,λt选择更大的值;当重建模型的精度总不稳定时,说明存在过拟合现象,λr应选择更大的值。
利用L-BFGS-B优化方法[18]最小化该能量函数,确定未知参数Wid、Wexp及三视角各自的相机标定参数(si,Ri,Ti),即可实现模型匹配。
1.2.2 非特征区域的点形变和曲线形变
前面双线性模型算法的精细化建模,在人脸几何形状上仅是对特征区域的形变优化,而非特征区域如五官的周围邻域,额头、脸颊等距离五官较远的区域等对描述真实人脸都起着至关重要的作用。因此,对于非特征区域,本文采用了点形变和曲线形变的方法[19-20],进一步对模型进行精细化;另外,为避免重建人脸表面出现过渡不自然的现象,采用了半核拉普拉斯平滑算子[21]来获取更平缓的人脸,从而提高了重建模型与真人的相似度和精度。
2 实验与结果分析
本文精细人脸模型生成实验主要对真实数据的三视图像照片进行了测试,并做了两组对比实验:一是与单视图双线性建模方法[22]的结果及本文方法流程中采取不同先验约束的建模结果对比,包括不采用约束、仅采用特征约束;二是与其他相关文献建模方法的对比,包括随机稀疏点形变的方法[10]、采用阴影先验约束的方法[12]、固定姿势级联回归的方法[15]。
2.1 三视图像的精细三维人脸模型生成
该三视图像照片由自行研制的同步相机采集,见图8(a)。该相机采用多路图像同步控制技术,单次采集仅需0.01 s,保证了拍摄严格同步。本文方法重建的精细化模型见图8(b),可以直观看到,模型整体较自然,且与真实人脸十分相像。

图8 三视图像真实照片的精细人脸模型
2.2 实验对比与分析
2.2.1 对比实验一
首先对比了单视图及本文方法流程中采取不同约束的建模结果,见图9。其中,(b)是单视图双线性建模方法的结果,由于缺乏侧面信息,侧脸发生了错误形变;(c)是不采用任何约束的建模结果,其仅具有基本的空间结构,表情信息不全;(d)是仅采取特征约束的建模结果,含有表情,但未加入纹理使模型缺乏真实感;(e)是本文同时采用特征和纹理约束的建模结果,未出现模型畸变,且与真实人脸很相像。

图9 单视图及不同约束下建模结果的对比
表1给出了该组实验的定量对比结果。可以看到,本文方法能有效改善单视图建模信息不足及遮挡的问题;另外,当同时引入特征及纹理先验约束时,重建模型的ME(Model Error,模型误差)最小,验证了本文构建的特征约束及纹理约束对提高模型重建精度是有效的。

表1 单视图及不同约束下模型的定量对比
为了分析不同张数的照片对重建模型精度及计算成本的影响,在i5-8250(8G)的电脑上,统一采用分辨率为380×420的人脸照片,采用文献[22]单张、本文3张和文献[11]7张的建模方法进行人脸重建,建模时间及模型误差见表2。随着照片数目增加,模型误差降低,即精度提高,但所需的建模时间也随之增加。因此,在该邻域研究中,如何找到照片数目、模型精度和计算时间的最佳平衡点,还是亟待解决的问题。
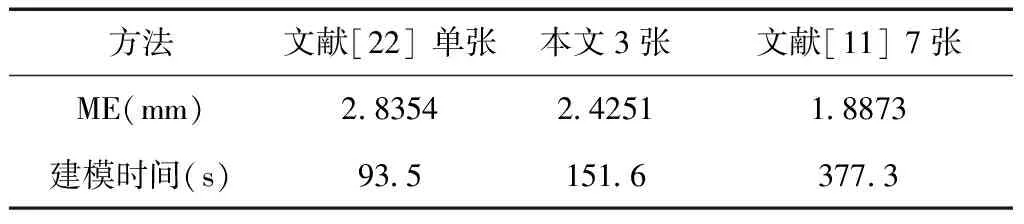
表2 不同张数的照片对建模精度及时间的影响
2.2.2 对比实验二
实验二对比了本文与其他文献的建模方法,结果见图10。其中,(b)是文献[10]的重建模型,其出现了很多顶点邻域畸变,人脸表面凹凸不平;(c)是文献[12]仅采用阴影约束表示能量函数的重建模型,因为受光照影响较大,整体偏暗,且在鼻子区域过渡极不自然;(d)是文献[15]的重建模型,由于该方法难以处理遮挡,导致模型在受遮挡的鼻翼和人脸侧面等区域畸变较严重;(e)是本文方法的重建模型,直观来看,该模型较自然,纹理与真实人脸极为相似,且三视图像建模有效改善了遮挡问题,模型的鼻翼及侧脸均处理较好。

图10 不同建模方法的重建模型对比
表3定量对比了这几种建模方法,可以看出本文重建模型的ME、特征区域的NME(Normalized Mean Error,归一化平均误差)和非特征区域的RMSE(Root Mean Square Error,均方根误差)均更小,表明该方法在建模精度上更具优势,模型匹配更贴近真实人脸,能重建出更逼真、精细的三维人脸模型。
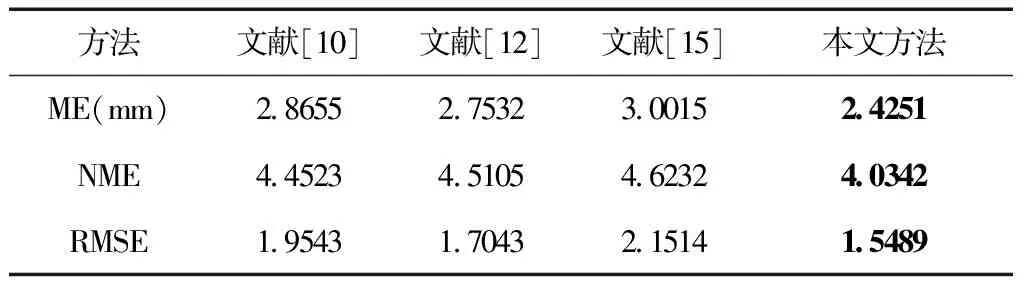
表3 不同建模方法模型的定量比较
3 结束语
本文提出一种基于三视图像的三维人脸建模方法,该方法有效改善了单视图建模信息量不足及无法避免遮挡的问题,同时生成了精细三维人脸彩色模型。实验对比结果显示,该方法重建的人脸模型具有更高的精度和更自然逼真的纹理。受限于人脸图像的数目,重建模型没有耳朵及头发等信息,因此,下一步将扩展本文方法至更多视图的三维人脸建模,对重建出完整的、更高精度的三维人脸模型进行研究。
