基于CEEMDAN-SAFA-LSSVM的短期风功率预测
2021-11-17张景杨王维庆王海云武家辉
张景杨,王维庆,王海云,武家辉
(新疆大学可再生能源发电与并网技术教育部工程研究中心,新疆乌鲁木齐830047)
1 引言
由于风功率具有随机性大,波动性强的缺点,风电的大规模使用给电网的安全稳定运行带来了很大的风险[1]。因此对风功率的精准预测是保证电网安全稳定运行的前提[2]。
目前,对风功率预测有许多方法,例如,时间序列法的优点是易于建模,但在描述风功率变化特征时存在缺点[3];卡尔曼滤波模型对风功率进行预测寻优时虽然可以避免陷入局部最优,但该方法易受统计特性不明的影响[4];相关向量机虽然消除了卡尔曼模型易受统计特性不明的影响,但该方法需要训练大量的原始数据作为输入[5-6];EMD与SVM组合预测模型虽然有着较高的预测精度,但该模型的缺点是复杂度高和训练时间长[7-9]。
通过上述分析,本文采用CEEMDAN算法对风功率进行分解能够很好地克服EMD和EEMD所存在的问题,在分解风功率序列上有更好的表现[10]。同时对于向量机(SupportVectorMachine,SVM)模型的缺点,提出一种萤火虫(SAFA)优化最小二乘支持向量机(LSSVM)预测模型[11]。可以解决LSSVM预测精度易受参数选择的影响[12]。于是本文建立了一种基于CEEMDAN-SAFA-LSSVM组合预测模型。通过与LSSVM和EEMD-LSSVM进行对比,结果表明本文提出的模型具有更快的收敛速度和更高的预测精度[13]。
2 算法原理
2.1 CEEMDAN算法
CEEMDAN算法是在原始风功率分解过程中的每一阶段添加自适应高斯白噪声,通过计算唯一余量信号得到各个模态分量,分解过程完整,重构误差极低。有效解决EMD模态混叠问题,同时克服EEMD分解效率低和噪声难以完全消除的问题[14]。
CEEMDAN算法实现的步骤如下:
1)利用CEEMDAN对信号X(t)+ε0ni(t)进行N次重复分解,通过均值计算得到第一个模态分量
(1)
2)然后对得到的第一个余量信号进行计算r1(t)
(2)
3)然后对信号r1(t)+ε1E1(ni(t))进行N次重复分解,分解完成后可得到第二个模态分量

(3)
4)对于k=2,…,K,计算第k个残余信号
(4)
5)重复步骤3)的计算过程,得到第k+1个模态函数为
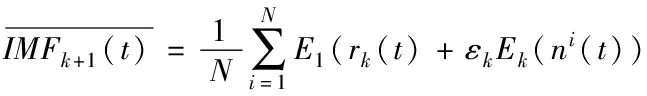
(5)
6)重复计算步骤4)和5),直到余量信号达到分解的终止条件,最终得到K个模态分量。分解的最终残差信号为
(6)
最终原始信号可以分解为
(7)
2.2 相空间重构
相空间重构的思想是系统中任一分量都与其它分量有关,而其它分量的信息隐藏在这一分量中。因此,通过对其分量的分析,从而实现重建原非线性系统的目的[15]。
设某一混沌序列的延迟时间为τ,嵌入维数为m,则重构的相空间为
{f(i)=[x(i),x(i+τ),x(i+2τ),…,x(i+(m-1)τ)]}
(8)
式中:f(i)为相点;i=1 2…N。
因此只要τ和m选择合适,则原系统的状态空间就和重构的相空间等价。所以,相空间重构要点就是要选取合适的延迟时间τ和嵌入维数m。
3 最小二乘支持向量机及其参数优化
3.1 LSSVM算法
假设m个训练数据{xi,yi}im=1,xi∈Rn为LSSVM模型的输入向量,yi∈R为LSSVM模型的输出向量,则LSSVM数学模型为
(9)
式中:ω—权重,C—惩罚参数,
ξi—松弛变量。
b—偏置。
φ(x)—映射函数。
LSSVM模型的Lagrange函数
(10)
式中:ai——Lagrange乘子。
式(9)求偏导,消去ω和ξi,可得到LSSVM模型的估计公式为
(11)
式中:K(x,xi)——核函数。
本文核函数采用径向基核函数,其定义为
(12)
式中:g——核函数的参数。
3.2 萤火虫算法
萤火虫算法(FireflyAlgorithm,FA)是通过高亮度的萤火虫会吸引低亮度的萤火虫,可以使萤火虫不断变换位置,从而实现参数寻优的目的[15]。
亮度高的萤火虫j会吸引亮度低的萤火虫i,萤火虫位置变化公式如下
Xi=Xi+β(r)×(Xj-Xi)+α×εi
(13)
式中:β(r)——萤火虫之间的吸引度。
(14)
β0——rij=0时萤火虫的吸引度;
Xi——萤火虫i的位置。
Xj——萤火虫j的位置。
为提高FA算法的搜索能力,将非线性动态惯性W引入式(15),得到新的萤火虫位置更新式(16)
(15)
式中:wmax——权重w的最大值;
wmin——权重w的最小值;
f——当前萤火虫的适应度函数值;
favg——所有萤火虫个体的平均适应度函数值;
fmin——萤火虫的最小适应度函数值。
所以,式(13)改进为
Xi=w×Xi+β(r)×(Xj-Xi)+α×εi
(16)
3.3 SAFA优化LSSVM的实现
针对LSSVM的预测精度受参数选择的影响,将SAFA引入用于对LSSVM的参数优化,可以解决LSSVM预测精度受参数选择的影响,从而可以提高LSSVM对风功率的预测精度,同时本文采用均方差作为适应度函数如下式
(17)
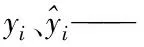
[Cmin,Cmax]——C的取值范围。
[gmin,gmax]——g的取值范围。
3.4 SAFA优化LSSVM的优化流程
由于SAFA算法对种群中最亮萤火虫的位置具有快速准确的寻优,同时又因为LSSVM模型的预测精度易受惩罚参数C和核函数参数g的影响,所以SAFA优化LSSVM就是其将参数(C,g)最优化问题转换成寻找萤火虫群体中萤火虫亮度最大的问题,即寻找到萤火虫亮度最大的位置(C*,g*)。基于SAFA-LSSVM的风功率预测步骤具体可描述如下。
Step1:设置SAFA的初始参数;萤火虫个数N,步长α,最大迭代次数T、初始吸引度β0、萤火虫初始位置X。
Step2:根据计算得到所有萤火虫的亮度再根据萤火虫的亮度大小对其进行排序,计算所有萤火虫群体的适应度函数值fi(C,g)并对其进行排序,得到最亮萤火虫的位置。
Step3:判断是否达到最大迭代次数,若大于最大迭代次数T,则转到Step4,反之转到Step5。
Step4:找到最亮萤火虫位置,从而可以得到优化后的LSSVM模型的参数(C*,g*)。
Step5:重新确定萤火虫位置,根据式(16)确定萤火虫最新的位置。
SAFA优化LSSVM的流程图如图1所示。
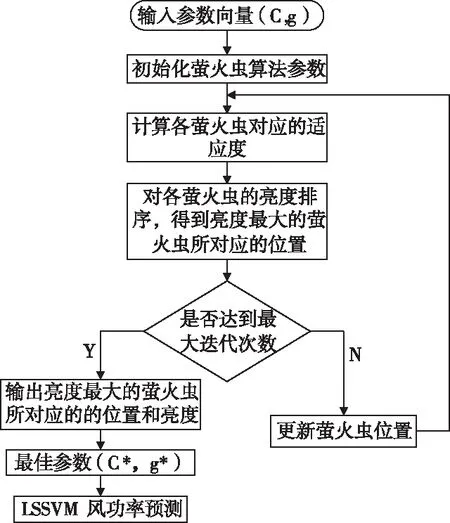
图1 SAFA优化LSSVM的流程图
4 基于CEEMDAN-SAFA-LSSVM风功率短期组合预测方法
CEEMDAN算法是在原始风功率分解过程中的每一阶段添加自适应高斯白噪声,通过计算得到各个特征相异的分量,分解过程完整,重构误差极低。有效解决EMD模态混叠问题,同时克服EEMD分解效率低和噪声难以完全消除的问题,然后利用相空间重构原理,对IMF分量进行重构,可有效提高风功率预测精度和预测效率。LSSVM在预测方面优于SVM但预测精度易受参数的选择影响,所以提出SAFA对LSSVM参数进行优化,可有效解决LSSVM预测精度受参数选择的影响。基于此建立了CEEMDAN-SAFA-LSSVM的组合预测模型对风功进行预测,预测流程如图2所示。
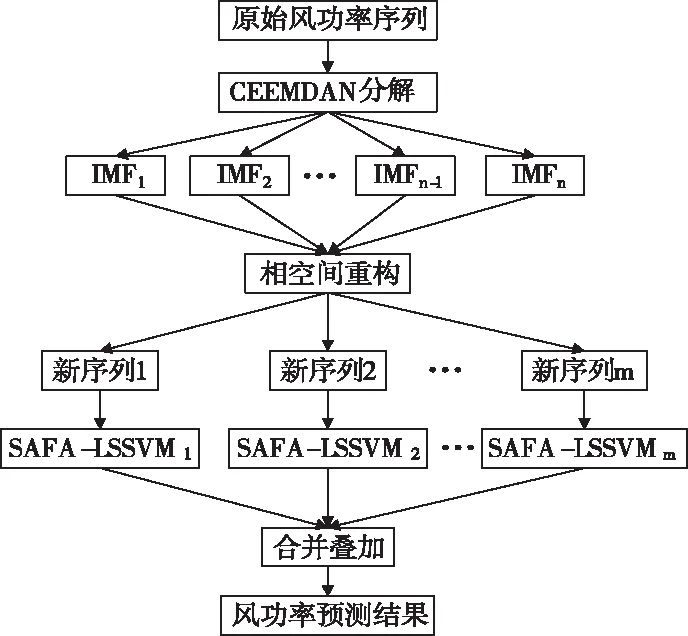
图2 CEEMDAN-SAFA-LSSVM预测流程
CEEMDAN-SAFA-LSSVM模型实施步骤如下。
1)采用 CEEMDAN算法对风功率进行分解,将其分解成各个特征相异的各个分量。
2)对风功率序列分解产生的各个分量进行相空间重构来确定各分量的参数τ和m。
3)根据新本征模态分量的特征,使用SAFA优化后的LSSVM模型,对各新本征模态分量分别进行预测。
4)将各分量的预测结果进行叠加处理,从而可以得到真实的预测结果。
5 算例分析
为了证明本文所提CEEMDAN-SAFA-LSSVM预测模型的有效性,以中国新疆某风电场实测风功率数据为测试样本,每隔15min取一个点,以某月连续12d的1152个数据为测试样本,用前1088个数据为本文模型的初始训练数据,后64个数据用来作为预测模型的测试值来验证模型的有效性。
5.1 CEEMDAN对风功率序列的分解
CEEMDAN算法是在原始风功率分解的每一阶段添加自适应高斯白噪声,通过计算可将原始风功率分解成多个模态分量,分解过程完整,误差极低。解决了EMD和EEMD中存在的模态混叠问题,计算量过大和添加白噪声幅值不当的问题。CEEMDAN对原始风功率序列进行分解如图3所示。
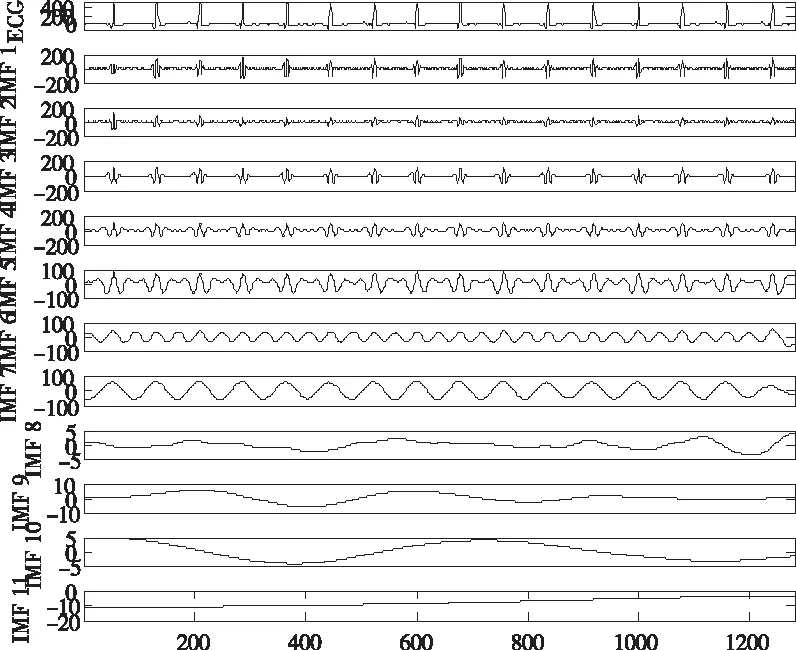
图3 CEEMDAN分解的风功率序列
从图3可知,原始风功率序列被分解成了特征互异的11个IMF分量和一个ECG分量。然后利用相空间重构原理对经CEEMDAN分解后的每个IMF分量进行处理,同时确定每个分量的延迟时间和嵌入维数。表1给出了各个IMF分量经相空间重构后确定的延迟时间τ和嵌入维数m[16-17]。
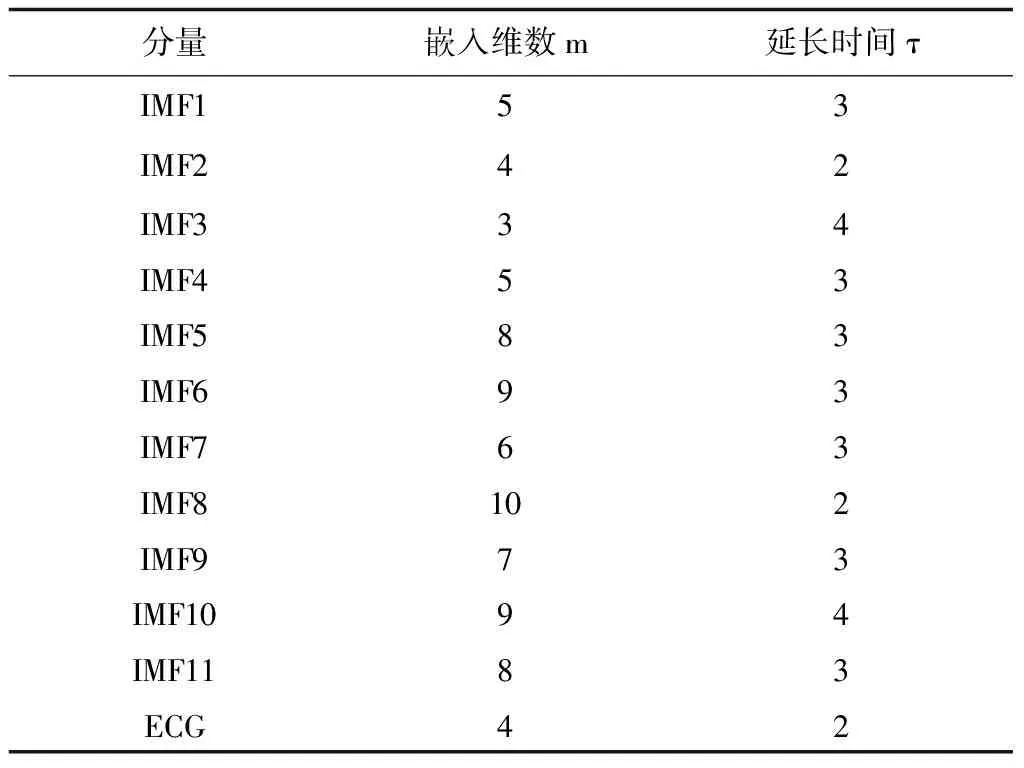
表1 相空间重构参数
对CEEMDAN分解后的各个分量进行相空间重构,然后对重构之后的各分量分别建立的SAFA-LSSVM预测模型,对风功率进行预测,最后对预测结果进行叠加得到实际的预测结果。
为了验证本文所用模型对于参数优化的优越性,将本文模型与LSSVM,EEMD-LSSVM进行对比。
由图4可见,CEEMDAN-SAFA-LSSVM优化模型数时,其迭代次数最少,10次左右就能达到收敛,而LSSVM和EEMD-LSSVM需迭代20次左右才可实现收敛,虽然本文的模型收敛时的适应度稍微大些,但本文的模型整体效果更为理想。
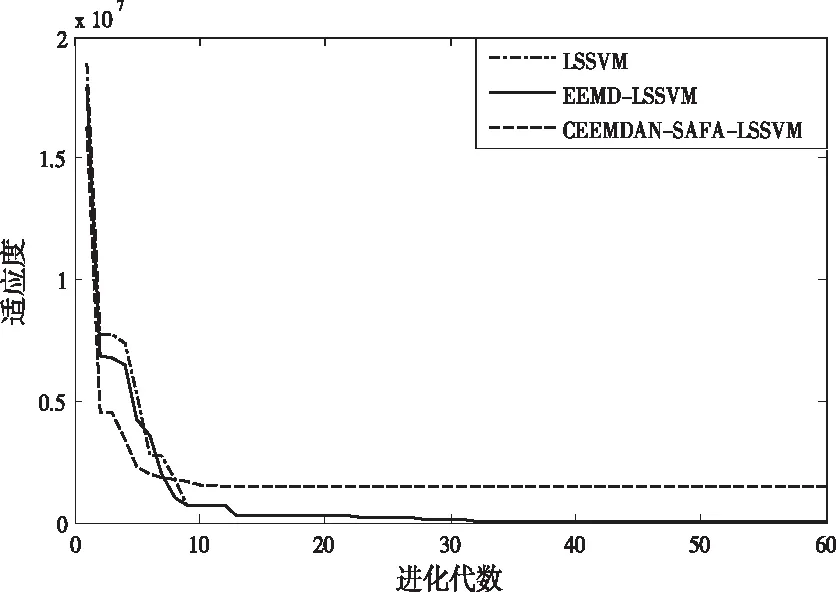
图4 三种优化算法的适应度曲线
5.2 预测结果对比分析
为提高风功率预测的效率,采用滚动预测法对后64个数据点进行滚动预测,然后将其预测的各分量的结果进行叠加得到风功率最终预测值。为验证CEEMDAN-SAFA-LSSVM组合预测模型相比于其它模型的优越性,与LSSM、EEMD-LSSVM进行对比,结果如图5所示。

图5 风功率预测曲线
从图5可知,虽然LSSVM与EEMD-LSSV两种预测模型预测出的风功率在整体趋势上大致可以跟随实际输出,但是在关键点处这两种预测模型的预测曲线偏离实际输出较大,预测效果较差。而本文提出的CEEMDA-SAFA-LSSVM预测模型在大多数预测点都更贴近实际值,预测效果比LSSVM和EEMD-LSSVM这两种模型更好,同时在关键点本文预测模型的预测曲线能紧跟实际风功率序列的变化。说明,本文模型预测效果更好。
为了比较每个预测方法的预测精度,选用绝对百分比误差(MAPE)和均方根误差(RMSE)这两个参数对各方法进行评价。
(18)
(19)

从表2可知,相比于LSSVM,EEMD-LSSVM预测模型的RMSE与MAPE指标分别降低了11.81%和17.44%,预测精度更高,说明对原始风功率进行分解,可以有效提高风功率预测精度。而CEEMD-SAFA-LSSVM模型相对于EEMD-LSSVM模型的RMSE与MAPE指标分别降低了11.61%和13.38%,可知采用CEEMDAN分解法可有效改善EEMD分解中的缺点。同时采用SAFA优化LSSVM参数,提高了LSSVM参数寻优速度和预测的精度。说明本文所提的CEEMDAN-SAFA-LSSVM预测模型提高了风功率预测效率和预测精度。

表2 几种预测方法结果对比分析
6 结论
本文建立的CEEMDAN-SAFA-LSSVM组合预测模型,对风功率进行短期预测,经过以上分析可得如下结论。
1)利用CEEMDAN对波动的风功率序列进行逐级分解解决了EMD和EEMD中存在的模态混叠问题,计算量过大和添加白噪声幅值不当的问题。
2)利用相空间重构原理,对IMF分量进行重构,可有效提高风功率预测精度和预测效率。
3)采用SAFA优化LSSVM参数,解决了LSSVM参数寻优效率低的问题。
4)通过与LSSVM和EEMD-LSSVM相比,研究结果表明本文提出的模型CEEMDAN-SAFA-LSSVM降低了原始非平稳序列对预测精度造成的影响提高了收敛速度,同时具有更高的预测精度,证明了本文所提的CEEMDAN-SAFA-LSSVM预测模型对风功率预测的有效性,同时为未来短期风功率预测提供了铺垫。
