语音情感识别研究综述
2021-11-17张会云黄鹤鸣
张会云,黄鹤鸣*,李 伟,康 杰
(1.青海师范大学计算机学院,青海 西宁 810008;2.藏文信息处理教育部重点实验室,青海 西宁 810008;3.青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008)
1 引言
随着语音识别技术的迅速发展,以计算机、手机、平板等为载体的人工智能研究日新月异。各种人机交互不再局限于识别特定说话人语音中的单一音素或语句,如何识别语音中的情感已成为语音识别领域的新兴研究方向。语音不仅包含说话人所要表达的语义信息,也蕴含说话人的情感状态。对语音情感的有效识别能够提升语音可懂度,使各种智能设备最大限度理解用户意图,从而更好地为人类服务。
2 语音情感识别研究
情感是一种综合了人类行为、思想和感觉的现象[1]。语音情感是指从语音信号中获取相应情感信息,情感信息主要表现在内外两个层面:内在情感信息指心率、脉搏、血压等无法通过外表观察到的信息;外在情感信息指面部表情、声音、语气、眉头、姿势等通过外表能观察到的信息。语音情感识别(Speech Emotion Recognition,SER)指利用计算机分析情感,提取出情感特征值,并利用这些参数进行相应的建模和识别,建立特征值与情感的映射关系,最终对情感分类。
2.1 语音情感语料库
人的情感是通过面部表情、身姿、声音及生理信号等多种模态表现出来的[2,3]。情感判断可基于这些模态中的一个或多个进行,但单模态信息不全、易受干扰,而多模态信息能够互相印证、互相补充,从而为情感判断提供更全面、准确的信息,以提高情感识别性能。语音情感语料库是进行SER的基础,大规模、多样化、高质量的优质语料库对SER性能的提升至关重要。随着SER的发展,各种单模态、多模态语音情感数据库应运而生,根据语音属性将数据库归类,见表1。

表1 语音情感语料库的归类
表1根据语种差异、语音自然度、情感获取方式及情感描述模型将语音情感数据库归类,通常研究者立足于情感描述模型,即将情感划分为离散型情感和维度型情感进行研究。为了更直观地区分两类情感,表2进行了详细总结。
由表2可知,离散型情感[2]指使用形容词标签将不同情感表示为相对独立的情感类别,多属于表演型或引导型,每类情感演绎逼真,能达到单一、易辨识的程度。维度型情感[2]通过唤醒维(Arousal)、效价维(Valence)、支配维(Dominance)等取值连续的维度将情感描述为一个多维信号,要求标注者将主观情感直接量化为客观实数值,如图1所示。其中,唤醒维是对人生理活动/心理警觉水平的度量;效价维度量人的愉悦程度,情感从极度苦恼到极度开心互相转化;支配维指影响周围环境或反过来受其影响的一种感受。为了更完整地描述情感,研究者也将期望维(Expectation)、强度维(Intensity)加入维度描述模型。期望维是对说话人情感出现的突然性度量,即说话人缺乏预料和准备程度的度量;强度维指说话人偏离冷静的程度[3]。
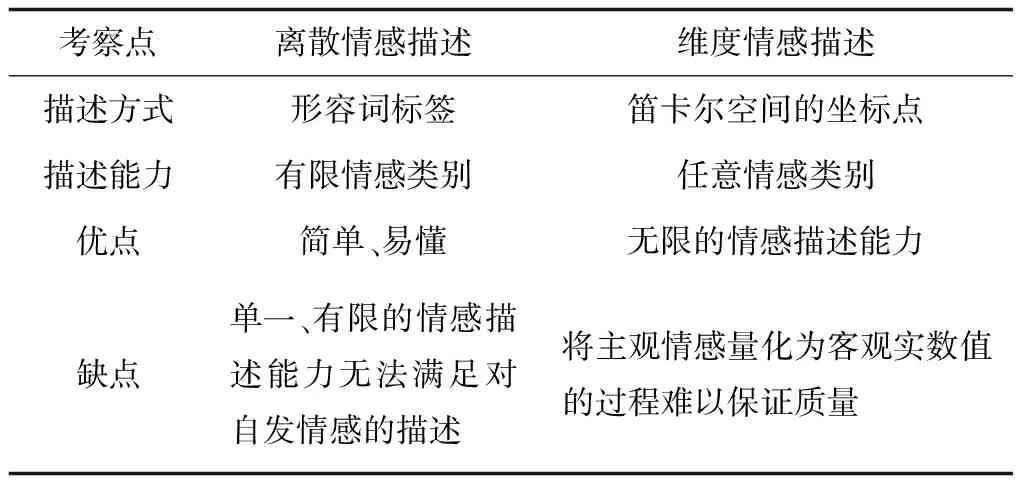
表2 两种情感描述模型的区别
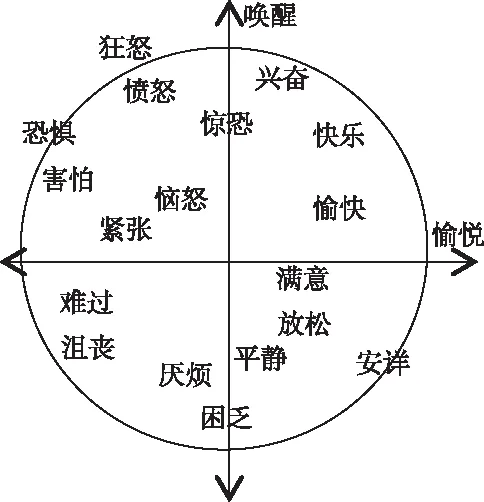
图1 愉悦-唤醒模
近年来,随着SER研究的顺利开展,研究者根据情感描述模型录制了相应的离散型语音情感数据库(见表3)和维度型语音情感数据库(见表4),所列的各类情感数据库大都公开或可以通过许可证授权得到。
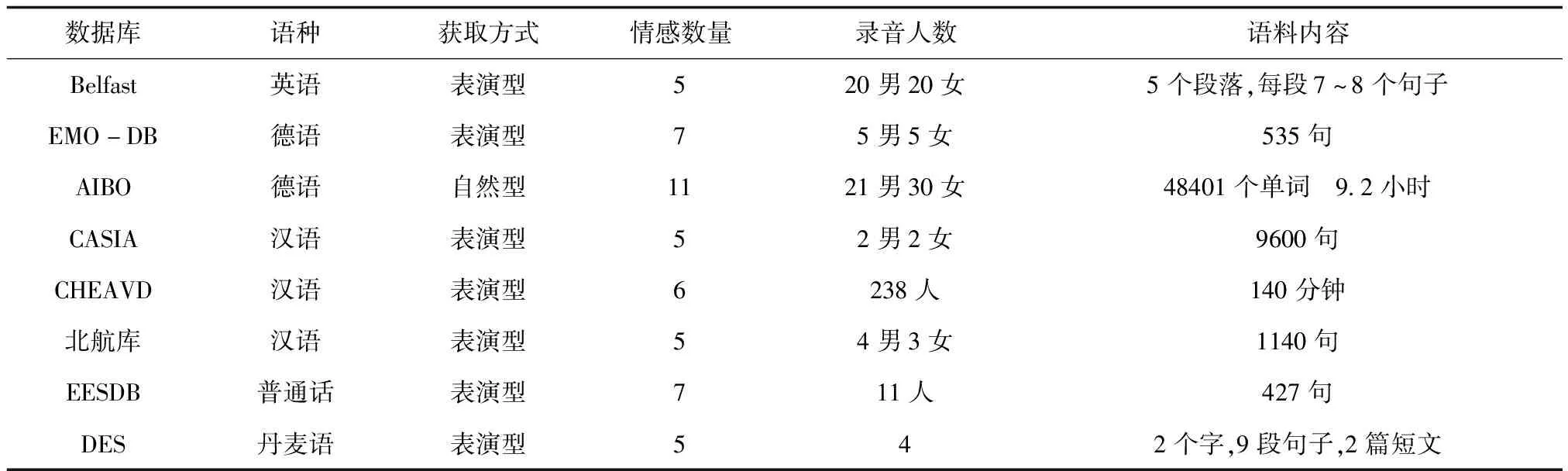
表3 常用的离散型语音情感数据库
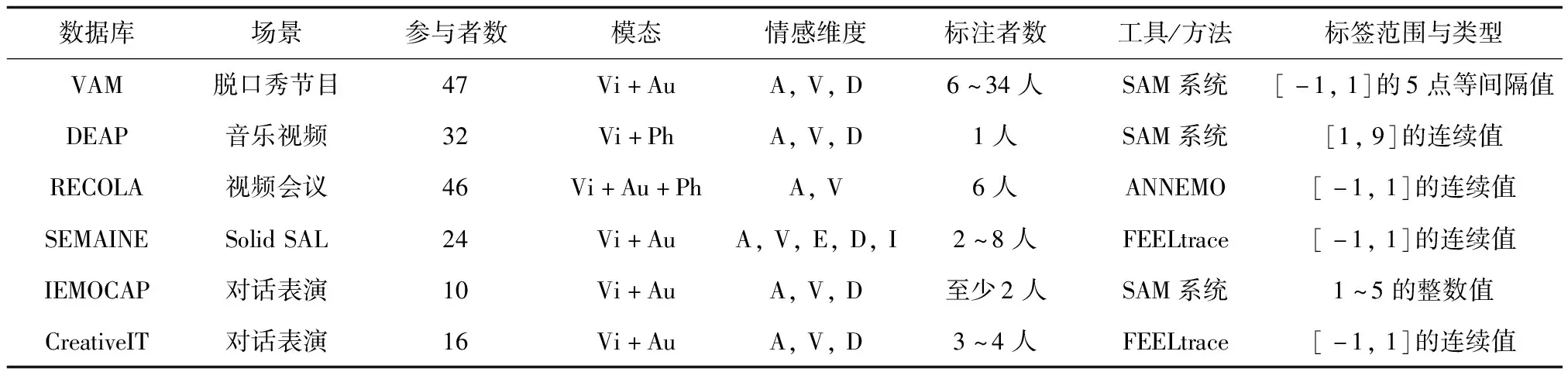
表4 常用的维度型语音情感数据库
由表3可见,大部分数据库都是通过表演方式采集。事实上采用自发语音情感更合理,但使用表演型情感数据库也有一定好处,可避免数据库包含过多无效标签数据。由表4可知,常用的维度型情感语料库主要有:VAM、DEAP、RECOLA、SEMAINE、IEMOCAP等,对于维度型情感库通常采用PAD(Pleasure-Arousal-Dominance)量表进行情感信息标注。
随着SER的发展,越来越多的研究者尝试将多模态信息融合来进一步提升SER性能。下面以常用的eNTERFACE05、SAVEE和RML模态数据库为例,分析在不同数据库上使用不同分类方法所取得的最佳性能。
表5展示了2015~2019年在SAVEE数据库上使用不同分类方法所取得的性能。由表5可知,在SAVEE数据库上,目前结合多模态信息的SER系统最优性能可达到98.33%,这是一个非常可观的结果。
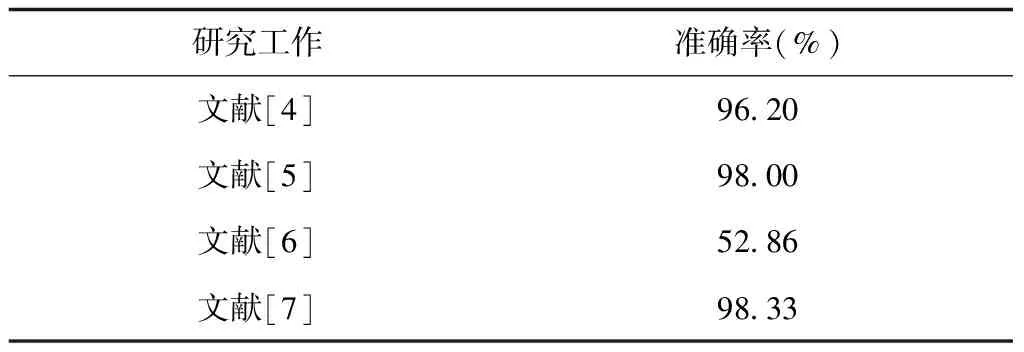
表5 SAVEE多模态库上不同方法性能比较
表6展示了2012~2019年部分研究者在RML模态数据库上的研究结果。由表6可知,目前RML数据库上各分类方法整体性能不是很好,2015年取得的最优性能为83%。

表6 RML多模态库上不同方法的性能比较
表7展示了2009~2019年部分研究者在eNTERFACE05模态数据库上的实验结果。由表7可知,文献[10]取得了最优的性能,其它各类方法的性能均较低。纵观表5、表6、表7,可以得出:在SAVEE数据库上目前各分类方法取得了最优性能,RML次之,eNTERFACE05数据库上性能最差。归因于eNTERFACE05库带有一定噪音,而RML模态数据库中的语料较为干净,SAVEE数据库是由专业演员录制的,对于每种情感的表达到位,数据库质量较好。
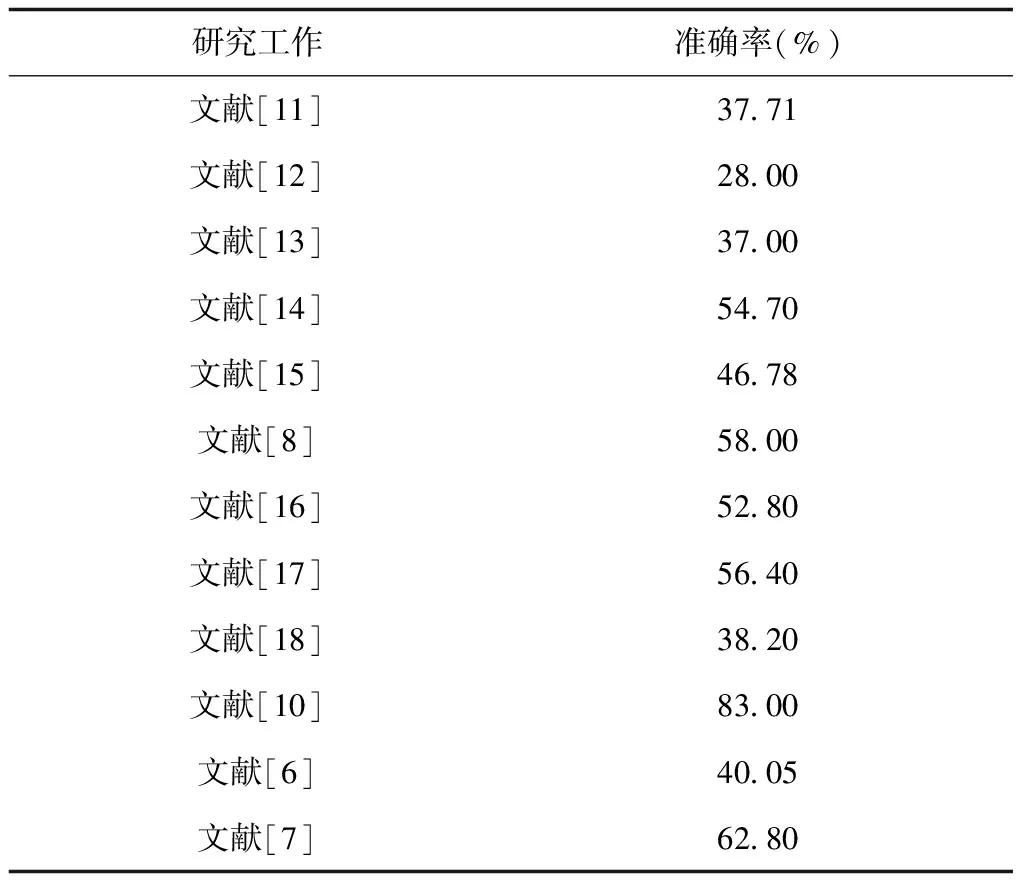
表7 eNTERFACE05多模态库上不同方法的性能比较
2.2 语音情感特征提取
语音中情感的自动识别将是一项具有挑战性的任务,对情感的识别严重依赖于语音情感特征分类的有效性。语音情感特征可分为语言特征和声学特征。语言特征即语音所要表达的言语信息,声学特征则包含了说话人的语气、语调,蕴含感情色彩。提取关联度高的情感声学特征有助于确定说话人情感状态。通常以帧为单位提取声学特征,但这些特征一般以全局统计的方式作为模型的输入参与情感识别。全局统计指听觉上独立的语句或单词,常用的统计指标有极值、方差、中值、均值、偏度、最小值、最大值、峰度等。目前,常用的声学特征包括韵律特征、谱特征和音质特征。为了进一步提升识别性能,研究者也将个性化特征[19]与非个性化特征[20]、非线性动力学特征[21]、基于人耳听觉特性的特征[22]以及i-vector特征[23]引入SER中,见表8。

表8 基于语音情感的声学特征分类
表8给出了语音情感特征的分类及其所包含的成分。通常来说,单一特征不能完全包含语音情感的所有有用信息,为了使SER系统性能达到最优,研究者通常将不同特征融合来提高系统性能。下面将详细介绍每种情感特征的内容及其研究状态。
2.2.1 韵律特征
韵律特征[24]在SER领域已被普遍使用,这些韵律特征并不影响对语音语义信息的识别,但决定着语音流畅度、自然度和清晰度。最常用的韵律特征有:时长相关特征(如语速、短时平均过零率等)、基频相关特征(如基因频率及其均值、变化范围、变化率、均方差等)以及能量相关特征(如短时平均能量、短时能量变化率、短时平均振幅)等。关于韵律特征对SER性能的影响,研究者作了深入分析与研究,见表9。
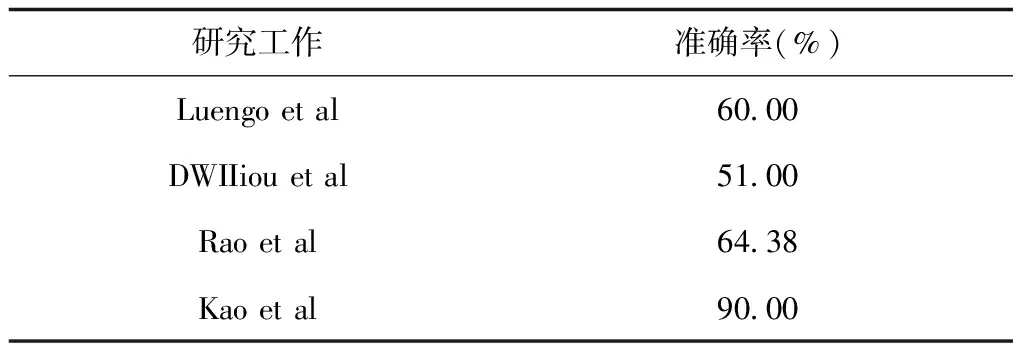
表9 常用的韵律特征对SER性能的影响
表9中,Luengo等人[25]使用了由基频和能量的最大值、最小值、均值及方差等组成的31维韵律特征集,在包含英语、法语等多语种情感语料库上的识别性能均接近于60%;IIiou等人[26]提取了EMO-DB语料库的35维韵律特征,系统性能达到51%;Rao等人[27]提取了韵律特征时长、基频和能量对应的全局特征和局部特征,并采用SVM在EMO-DB语料库上对7种情感进行分类,取得了64.38%的平均识别性能;Kao等人[28]分别从帧、音节、词语级别提取了韵律特征并对4种情感进行分类,获得了90%的识别性能。综合来看,韵律特征对情感识别系统性能的影响较大。
2.2.2 基于谱的相关特征
基于谱的相关特征体现了声道形状变化与发声运动间的相关性[29]。谱特征参数反映信号在频域的特性,不同情感在各个频谱间的能量是有差异的(如表达欢快的语音在高频区间能量较高,表达哀愁的语音在同样的频段能量较低)。基于谱的相关特征主要分为线性频谱特征和倒谱特征。常用的线性谱特征有:线性预测系数(Linear Prediction Cofficients,LPC)、对数频率功率系数(Log Frequency Power Coefficients,LFPC)及单边自相关线性预测系数(One-sided Autocorrelation Linear Predictor Coefficient,OSALPC)等;常用的倒谱特征有:线性预测倒谱系数(Linear Prediction Cepstrum Cofficients,LPCC)、单边自相关线性预测倒谱系数(One-sided Autocorrelation Linear Predictor Cepstral-based Coefficient,OSALPCC)以及梅尔频率倒谱系数(Mel-Frequency Cepstrum Cofficients,MFCC)等。关于谱特征对SER性能的影响,部分研究者作了深入分析与研究,见表10。

表10 常用的谱特征对SER性能的影响
表10中,Bou-Ghazale等人[30]研究了倒谱特征和线性谱特征在压力语音检测任务中的性能表现,实验表明,单独使用LPC、OSALPC、LPCC、OSALPCC、MFCC特征时,识别率为:48.19%、53.51%、68.71%、65.87%、69.45%,平均识别率为61.15%。从实验结果可以看出,倒谱特征的区分能力明显优于线性谱特征;Nwe等人[31]使用LPCC、MFCC和LFPC特征时识别率分别为56.1%、59%和78.1%,平均识别率为64.4%,通过实验证明线性谱特征的识别性能优于倒谱特征。目前,MFCC表现出的性能最优,是因为其具有计算简单、区分能力好等优点。台湾学者选用MFCC、LPCC等作为特征向量,使用SVM对普通话5种情感进行分类,获得了84.2%的识别结果[32]。文献[33]单独使用MFCC特征对情感语音进行分类,平均识别率为62.3%。综合来看,谱特征对SER的性能影响较大。
2.2.3 音质特征
音质特征是语音的一种主观评价指标,描述了声门激励信号的性质,包括发声者语态、喘息、颤音及哽咽,用来衡量语音纯净度、清晰度和辨识度[34]。通过对声音质量的评价,可获得说话人的生理、心理信息并对其情感状态进行区分。用于衡量声音质量的声学特征一般有:共振峰频率、带宽、频率扰动、振幅扰动、谐波噪声比、闪光及声门参数等。关于声音质量对SER的影响,其代表性成果见表11。

表11 常用的音质特征对SER性能的影响
表11中,Lahaie等人[35]研究了5种音频带宽对SER的影响,平均识别率为71.65%。Li等人[36]提取了频率微扰和振幅微扰等音质参数,仅有MFCC特征时,基线性能是65.5%,将MFCC与频率微扰或振幅微扰结合时,系统性能都会有所改善,将三者结合,系统最佳性能可达到69.1%。Wang等人[37]等人提出了一种傅里叶参数特征,使用该特征时SER性能可达到76.00%。综合来看,音质特征对SER性能也有一定的影响。
2.2.4 其它特征
为进一步提升SER性能,一些研究者致力于提取更为有效的特征,经过大量实验验证,除韵律特征、谱特征和音质特征外,目前对系统性能影响较大的一些特征有:个性化特征与非个性化特征、基于人耳听觉特性的特征、i-vector特征以及非线性特征,下面详述各类特征及其典型的研究成果。
个性化与非个性化特征:根据语音情感声学特征是否受说话人自身说话特征影响,将其分为个性化和非个性化特征。个性化特征反映数值大小,包含大量反映说话人语音特点的情感信息;非个性化特征反映说话过程中情感的变化情况,包含一定情感信息且不易受说话人影响,具有很好的相通性和稳定性。文献[38]提取了基频、短时能量、共振峰的变化率及它们的变化范围、方差等统计值作为非个性化特征,同时提取了传统基频、共振峰等个性化特征,并用这两类特征进行实验,结果表明非个性化特征对SER有着很大的作用,且这类特征受不同说话者的影响更小。
基于人耳听觉特性的特征:过零峰值幅度特征(Zero Crossings with Peak Amplitudes,ZCPA)使用过零率和峰值的非线性压缩表示语音信号的频率及幅度信息,是一种基于人耳听觉特性的特征。文献[39]将其引入SER领域分析了分帧时长对ZCPA特征的影响,提出了一种将Teager能量算子与ZCPA特征相结合的过零最大Teager能量算子特征。该特征保留了人耳听觉特性,同时也将最能表征情感状态的特征融入系统,实验结果表明,该特征取得了较好的识别性能。
i-vector特征:i-vector是一种将GMM超向量空间映射到低维总变异空间的技术。文献[40]首先提取1584维的声学特征训练语音情感状态识别的通用模型,然后在该模型基础上为每类情感状态生成用于i-vector的GMM超向量并将其串联,最后使用SVM来识别4类语音情感,结果表明,该特征取得了较好的识别性能。
非线性特征:基于语音混沌特性,应用非线性动力学模型分析情感语音信号,可以提取该模型下情感语音信号的非线性特征及常用的声学特征(韵律特征和MFCC)。文献[41]将非线性动力学模型与情感语音信号处理相结合,提取了最小延迟时间、关联维数、Kolmogorov熵、最大Lyapunov指数和Hurst指数等情感非线性特征,并将非线性特征与不同特征融合验证了该组合下的情感识别性能,研究了EMO-DB语料库下语音信号混沌特性对SER性能的影响,结果表明,在单独使用韵律特征、MFCC和非线性特征时,识别率分别为:69.00%、80.88%和72.00%。将三者融合最佳识别率可达到87.62%。从识别结果来看,非线性特征有效表征了情感信号的混沌特性,与传统声学特征结合后,SER性能得到了显著提升。
2.2.5 特征融合
单一特征仅从某个侧面对语音情感信息进行表达,不能很好地表示语音情感,为此,研究者通常将多个单特征融合以进一步提升SER性能,见表12。

表12 融合特征对系统性能的影响(%)
表12中,赵力等人[42]将韵律特征与音质特征相结合,平均识别性能达到了75%;Amol等人[43]将MFCC、过零率、能量等特征相结合,获得了98.31%的性能。文献[44]提取了短时平均能量、短时平均幅度,短时过零率、线性预测系数、MFCC和短时自相关系数特征并将其融合,最佳识别率可达到79.75%。综合来看,融合的特征集对情感识别性能均优于单一特征集。
2.2.6 深度学习特征
深度学习方法在处理复杂的海量数据建模上有很大优势,可以直接从原始数据中自动学习最佳特征表示,通过组合低层特征形成更加抽象的高层特征以表示属性的类别或特征,从而有效捕获隐藏于数据内部的特征,近年来部分研究者将其应用于语音情感特征提取,并取得了一定成果,见表13。
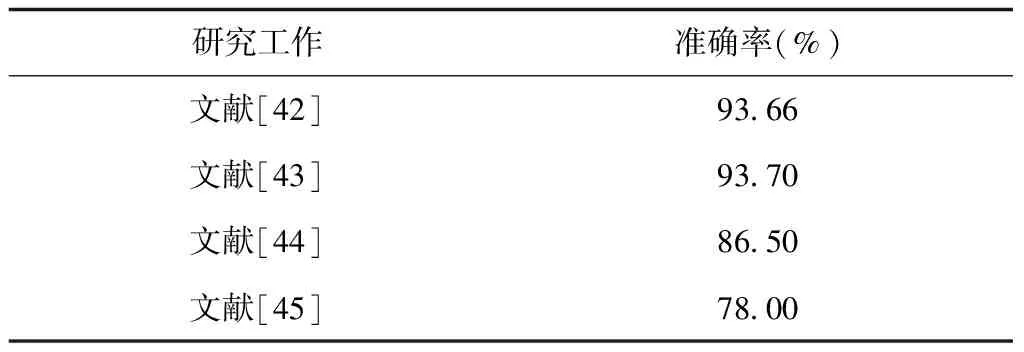
表13 深度学习特征对系统性能的影响
表13给出了深度学习特征对SER性能的影响。文献[45]将瓶颈结构(Bottle-Neck,BN)和深度置信网络(Deep Belief Network,DBN)相结合来提取新的特征,其识别率可达到93.66%。文献[46]采用CNN进行特征提取,其最佳识别率可达到93.7%;文献[47]使用RNN提取语音情感特征,识别率可达到86.50%;文献[48]使用LSTM提取语音情感特征,在CHiME中可进一步将错误率降到22%。综合来看,使用深度学习自动提取的特征对SER性能的影响较大,更有利于SER的顺利进行。
2.3 语音情感声学建模
要对情感状态进行判断,首先要建立SER模型。识别模型是SER系统的核心。在识别过程中,情感特征输入到识别网络,计算机通过相应算法获取识别结果。显然,识别网络的选择与识别结果有着直接关系。早期的统计模型与识别算法大致有以下几种:决策树、基于模型匹配法、贝叶斯网络、动态时间规整(Dynamic Time Warping,DTW)、多层感知机(Multilayer Perceptron,MLP)、高斯混合模型(Gaussian Mixture Model,GMM)、支持向量机(Support Vector Machine,SVM)、隐马尔科夫模型(Hidden Markov Model,HMM)等。随着深度学习的兴起,SER模型训练阶段逐渐采用人工神经网络(Artificial Neural Network,ANN)。目前SER领域使用最广泛的模式分类器有:HMM、GMM、SVM及ANN等,下面着重介绍这几种算法。
2.3.1 隐马尔科夫模型
HMM是一种模拟了人类语言过程的时变特征有参表示法。在SER领域有着广泛的应用,部分研究者在常用的一些情感语料库(如EMO-DB、IEMOCAP等)上提取了韵律特征、谱特征、音质特征等各类特征,并采用HMM作为分类器识别不同语音情感,相关研究成果见表14。

表14 HMM分类算法对系统性能的影响
从表14可以看出,使用HMM作为分类器时,Yun等人的研究成果达到了89.00%的识别率,文献[50,55]的研究成果也取得了不错的成绩,但最低性能仅有62.5%。
2.3.2 高斯混合模型
GMM是一种可拟合所有概率分布函数的概率密度估计模型。相关研究者提取了基频、能量、MFCC、共振峰及其它特征并将各类特征以不同方式融合,在各类情感语料库上做了大量实验,见表15。
从表15可以看出,使用GMM进行SER识别时,Neiberg等人的研究成果达到了90.00%的识别率,这是一个非常不错的识别结果。除此之外,文献[57-58]也取得了可观的识别结果。
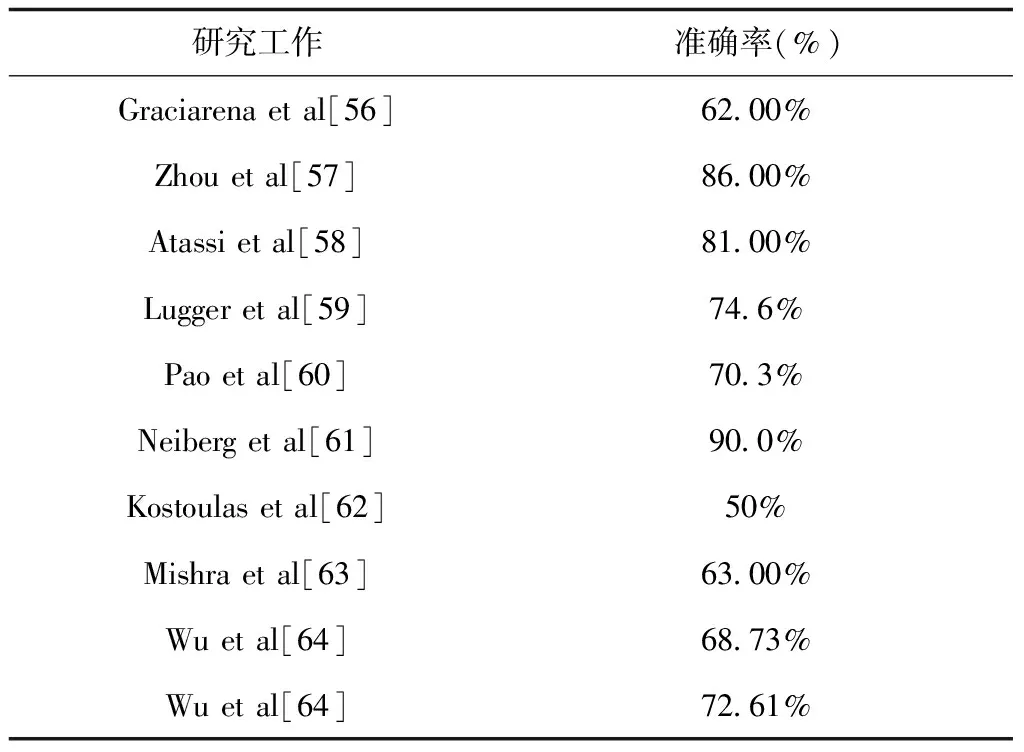
表15 GMM分类算法对系统性能的影响
2.3.3 支持向量机
SVM是一种通过核函数将特征向量由低维空间映射到高维空间实现最优分类的算法。在SER领域有着广泛的应用,相关研究成果见表16。
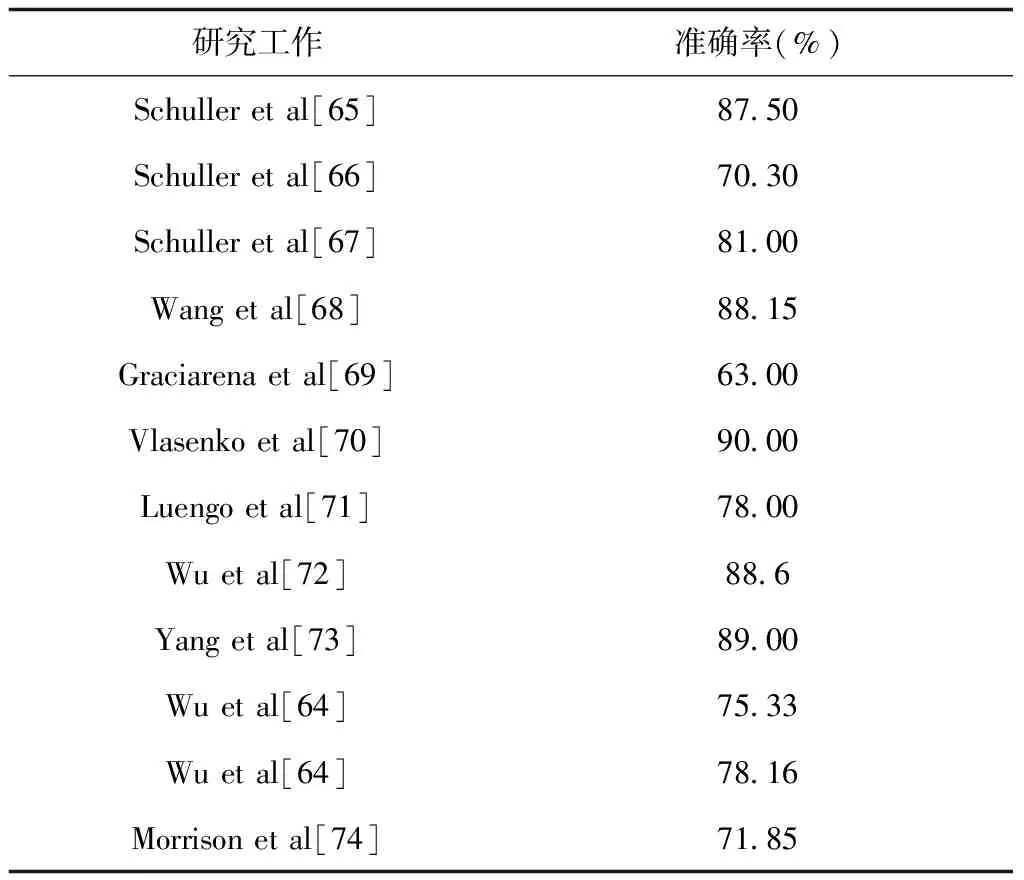
表16 SVM分类算法对系统性能的影响
从表16可以看出,目前很多研究者使用SVM作为分类器进行SER并取得了非常可观的识别结果。其中,文献[70]达到了90.00%的最优识别性能,其他研究者的研究成果也仅次于文献[70]。综合来看,该方法有利于提高SER的性能。
2.3.4 人工神经网络
人工神经网络(Artificial Neural Network,ANN)是基于生物学中神经网络的基本原理,在理解和抽象了人脑结构和外界刺激响应机制后,以网络拓扑知识为理论基础,模拟人脑对复杂信息处理机制的一种数学模型、数学方法、计算结构或系统。该网络具有一定的智能性,表现为良好的容错性、层次性、可塑性、自适应性,并具有联想记忆、非线性和并行分布式处理能力。
近年来,ANN依靠其强大的特征提取及对海量数据进行深层次建模能力,在SER领域取得了显著进步。循环神经网络(Recurrent Neural Network,RNN)、卷积神经网络(Convolutional Neural Network,CNN)以及各种自编码器等新的网络模型、分支及算法不断被提出,这些模型对SER系统性能的提升产生了深远影响。下面以RNN、CNN以及各种自编码器为例,详细介绍SER的研究进展。
循环神经网络:RNN中存在环形结构,其隐含层内部神经元互连,可存储网络序列输入的历史信息,是一种专门用于处理时序数据的神经网络,其时序并非仅仅指代时间概念上的顺序,也可理解为序列化数据间的相对位置,如语音中的发音顺序、某个英语单词的拼写顺序等。若相关信息与预测位置间隔较小,RNN可顺利预测;反之,RNN无法学习这些信息。为此,研究者对RNN进行了改进,提出了长短期记忆网络(Long Short-Term Memory,LSTM),该网络能够学习长期依赖关系,已被广泛使用,相关研究成果见表17。
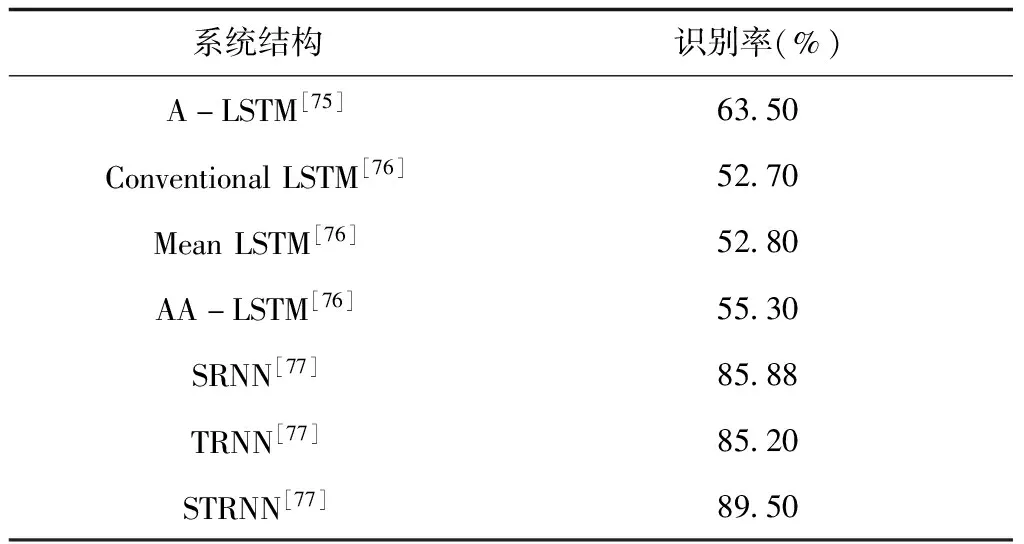
表17 循环神经网络对SER性能的影响
在表17中,文献[75]使用LSTM网络从语音中自动发现与情感相关特征,并使用局部注意机制以集中于语音信号中更突出情感的特定区域,在IEMOCAP语料库上进行了评估,结果表明,与使用固定特征的传统SVM情感识别算法相比,该方法可提供更好的性能。然而,传统LSTM假设当前时间步长状态取决于前一个时间步长,该假设限制了时间依赖性建模能力,文献[76]提出了Advanced-LSTM网络,可更好地进行时间上下文建模,实验表明,该网络性能优于传统LSTM。文献[77]提出了一种时空循环神经网络(Spatial-Temporal Recurrent Neural Network,STRNN),将信号源时空信息的特征集成到统一时空依赖模型。通过沿不同方向遍历每个时间切片空间区域,利用多方向RNN层捕捉长距离上下文信息。实验表明,所提出的方法更具竞争力。
卷积神经网络:CNN是一种专门用来处理具有类似网格结构数据的神经网络,如时间序列数据和图像数据。CNN引入了权值共享及降采样的概念,大幅减少了训练参数数量,在提高训练速度的同时有效防止过拟合,相关研究成果见表18。
在表18中,文献[78]使用CNN对4种情感进行识别,平均识别率可达到73.32%。文献[79]提出了基于时间调制信号的3维卷积循环神经网络(Three-dimensional Convolutional Recurrent Neural Network,3D-CRNN)端到端SER系统。卷积层用于提取高级多尺度频谱时间表示,循环层用于提取情感识别的长期依赖性。在IEMOCAP数据库上进行验证,结果表明,所提出方法具有更高识别精度。文献[80]针对CNN训练中卷积核权值的更新算法进行改进,使卷积核权值的更新算法与迭代次数有关联,提高CNN的表达能力。在语音情感特征提取方面,选择提取语音特征应用最广泛的MFCC方法进行实验,同时为了增加情感语音之间的特征差异性,将语音信号经过预处理后得到的MFCC特征数据矩阵做变换,提高SER性能。对改进CNN的SER模型进行实验分析,结果表明,改进后的SER算法的错误率比传统算法减少约7%。

表18 卷积神经网络对SER性能的影响
自编码器:自编码器是一种能够通过无监督学习学到输入数据高效表示的ANN。输入数据的这一高效表示称为编码,其维度一般远小于输入数据,使得自编码器可用于降维。此外,自编码器可作为强大的特征检测器,应用于神经网络预训练,相关研究成果见表19。
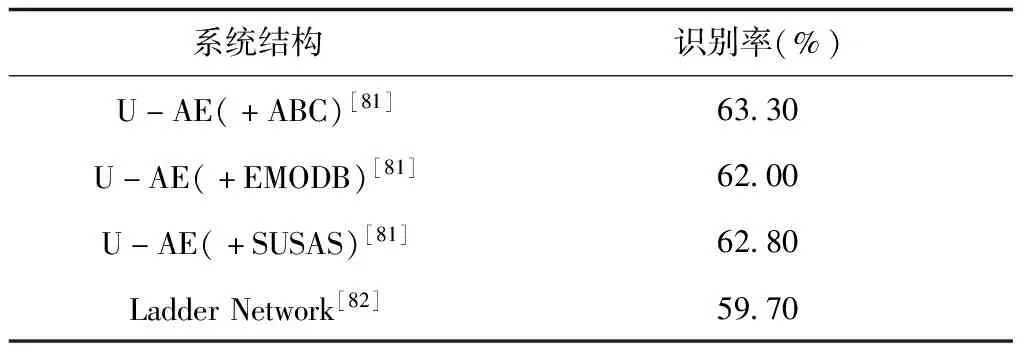
表19 自编码器对SER性能的影响
在表19中,文献[81]提出了新的无监督域适应模型—Universum自编码器,以改善在不匹配的训练和测试条件下系统性能。在标记的GEWEC数据库和其它3个未标记的数据库上的实验结果表明,与其它域适应方法相比,该方法具有较好的效果。文献[82]使用半监督阶梯网络进行情感识别,最佳识别率可达到59.7%。
3 语音情感识别的应用
SER是一个新兴的研究领域且在教育、医学、心理学、话务中心、汽车驾驶、电子商务等人机交互领域有着广泛的应用。
教育领域:对接受在线教育的学生进行语音情感分析,可随时反馈学生状态;若发现学生对课程内容困惑时,可适当调整教学难度和教学进度,实现更人性化的网络教学,从而提升教学效果。
医学领域:言语障碍者的言语特征往往比正常人言语特征更难理解,VAESS工程开发了一种便携式语音合成器来辅助残疾人讲话和表达情感,对语音中情感的有效识别能提升语音可懂度,帮助听众更好地理解说话人所要表达的含义。
心理学领域:情感不仅与说话人语音有关,也与说话人所处的情景密切相关,基于SER系统的情景分析能够及时获取说话人情感状态,帮助说话人排解不良情绪,避免产生抑郁倾向。另外,将基于说话人情景的检测与心理学医师的医疗方案结合,能够为说话人提供良好的心理疏导。
智能话务系统:根据用户情感状态安排服务优先级或直接转给人工客服,若用户情绪起伏不定,智能系统可为用户及时转接人工客服;若人工客服情绪受到客户影响,智能系统将及时提醒客服保持良好的服务态度,提高服务效率和质量。
汽车驾驶:通过提取驾驶员的语速、音量等声学特征信息实时监控并分析驾驶员情感状态,当发现疲劳驾驶时及时督促驾驶员安全驾驶,可有效避免交通事故发生[47]。
电子商务领域:在购物网站和股票交易网站识别用户语音情感,可灵活调控流量。
综上所述,研究SER系统具有一定学术价值和实用价值。要实现更好地人机交互,需要计算机在听懂说话人言语信息的基础上也能够理解其中所蕴含的情感信息。
4 总结和展望
随着模式识别的迅速发展和ANN的再度兴起以及人机交互的迫切需求,越来越多研究者逐渐投入SER并取得了显著性成果。本研究论述了SER领域的几个关键问题,包括语音情感模型、语音情感语料库、语音情感声学特征提取、声学建模及SER技术应用。出于对SER研究现状的分析和语音情感复杂性的考虑,总结了该领域面临的挑战和值得深入探究的问题及未来发展趋势。
4.1 总结
纵观近几年文献来看,尽管有很多算法成功运用于SER中,但大多数研究者仅使用这些算法在某些特定数据库上测试,对实验数据依赖性强。在不同情感数据库和测试环境中,各种识别算法均有其优劣势,没有普遍性。常见的SER方法都是基于语音情感特征进行研究,但不论这些情感识别方法有多么精确,都无法与人脑相媲美。
4.2 展望
泛化性与多模态信息融合:SER不再局限于对普通语音进行情感识别,如何将远程通话语音、言语障碍者语音以及低资源语音(如各地区方言、藏语等民族语言)中的情感语音与各类人群的面部表情、肢体语言和语义特征等多模态信息相融合进行情感识别需要深入探讨,多模态情感信息互相补充、相互验证,但在情感表达过程中,个体易受环境影响,不能充分表达多模态情感,在获取情感数据过程中也会受当前技术限制,使得多模态信息有所缺失;另外,多模态情感信息一般情况下借助多种传感器来获取,会存在记录的异步性和不同模态与情感状态表现的异步性。因此,将多模态信息进行有效融合来提高SER性能将是一个值得深究的问题。
语料问题:优质的情感语料库能够提供可靠的训练数据和测试数据。与大规模语音语料库和歌曲语料库相比,现有情感语料库一般是根据研究者研究目的建立的表演型、引导型语料库,语料资源较为稀少。另外,由于低资源语音使用人群较少且从事低资源语音情感研究的人群也明显少于英语、汉语等大语种的研究人群,使得低资源相关研究仍处于萌芽阶段。最后,不同研究者所采用的语音情感语料库也有所差异,诸如语种、情感种类及说话人差异等均影响SER。因此,针对现有语料库问题,合理丰富各类情感语料库及采用先进技术对情感语料库进行有效标注很有必要。
语音情感与声学特征的关联度:SER的目标是让机器胜任人脑识别水平。要求机器以尽可能接近人脑信息加工的方式对情感语音进行声学特征提取并加以正确关联和映射。语音识别中提取的MFCC特征大幅改善了系统性能,而SER领域目前并未找到具有MFCC同样地位的情感声学特征。通常情况下将韵律特征、声音质量、谱特征相融合选出最优特征集进行SER。截至目前,该领域研究者普遍认为基于语句时长的全局特征与情感状态间的关联最密切,但界定情感特征的最优时长及将不同时长声学特征进行融合探究与情感表达关联更密切的声学特征仍具有一定挑战。
SER建模:利用充足的语料训练情感识别系统找出各种声学特征对应情感的映射,实现对测试语料的正确识别。SER是对人脑语音情感信息加工方式的模拟,受人脑情感信息加工方式的复杂性及科技水平的限制,目前该领域构建的识别系统仅是对人脑的一些简单功能的模拟,还无法达到机制模拟水平。在现有认知水平上,构建接近人脑信息加工机制的SER系统具有很大挑战。
SER技术的普及:随着人机交互技术不断发展,语音交互技术逐渐从实验室进入市场(如苹果公司Siri语音搜索软件)。但SER领域目前并没有成熟的相关应用问世,人机互动的实时性要求在SER性能提升的同时也能降低计算量,具有很大实用价值。
