深度集成森林回归建模方法及应用
2021-11-16乔俊飞郭子豪
汤 健,夏 恒,乔俊飞,郭子豪
(1.北京工业大学信息学部,北京 100124;2.计算智能与智能系统北京市重点实验室,北京 100124)

集成学习作为机器学习的主要分支,在工业过程领域的建模研究中得到了广泛的应用[4].决策树(decision tree,DT)算法是一种能够同时处理分类和回归问题的树形学习器,最具代表性算法为分类与回归树(classification and regression tree,CART)[5].通常,基于DT进行集成学习的方法称为森林算法(forest method,FM),以Breiman提出的随机森林(random forest,RF)算法应用最为广泛[6-7].因每个DT模型均可被看作If-Then规则的集合,这使得并行集成DT模型的RF算法具有良好的解释性[8].目前,RF在软测量领域已有很多应用,如:文献[9]提出了基于密度峰聚类和RF的软测量;文献[10]采用RF建立针对康复训练的手臂末端力软测量模型;文献[11]将RF用于雾霾预测等.上述研究成果表明基于FM的集成学习策略具有较好的可应用性,但其针对小样本的预测鲁棒性仍有待于进一步提升.
近年来,深度神经网络学习[12]已在多个领域获得成功应用,如电网电力负荷预测[13]、燃煤锅炉多目标预测[14]和风电场风速预测[15]等,这使得传统机器学习在很多领域失去了竞争性.针对难测参数建模,文献[16]指出深度神经网络能够作为隐变量模型描述输入变量间的高相关性,也可提取海量无标记样本的非监督特征;文献[17]提出基于变分自编码器的潜在特征提取策略.但上述方法所提取的深度特征难以进行物理解释.此外,深度学习的“黑箱”模型本质使得对其进行理论分析非常难,同时也存在超参数多、训练难度大、可解释性差等问题[18].
Zhou等[19]借鉴深度神经网络(deep neural networks,DNN)成功的内在因素,提出了由多粒度扫描和级联森林两部分组成的深度森林(deep forest,DF)算法处理分类问题,采用逐层提取类向量进行深度特征增强,实现非神经网络模式深度学习模型,初步探索了基于FM的深度集成模型.Miller等[20]在DNN中获取灵感,通过替换神经元为DT,提出了前瞻性深度随机森林.具有类似深度结构的相关研究文献逐渐增多,但研究以图像识别、故障诊断等分类问题为主[21-23].针对工业过程连续性数值数据,文献[24]在多粒度扫描模块前引入深度玻尔兹曼机(restricted Boltzmann machine,RBM),将连续性数值特征转换成二维向量后采用DF构建分类器,提高工业过程故障诊断的识别率.综上可知,目前关于非神经网络模式DF的研究集中在分类问题,级联间的表征学习采用类分布向量.显然,上述成果不适用于复杂工业过程的难测参数建模.
针对上述问题,本文提出了包括输入层、中间层和输出层森林模块的深度集成森林回归(deep ensemble forest regression,DEFR)建模方法,其中:输入层以原始特征向量为输入,基于DT训练多个子森林模型通过K最近邻(K-nearest neighbor,KNN)法选取子森林模型预测均值附近值以获得层回归向量,与原始特征向量进行组合,将得到的增强层回归向量作为输出;中间层包含K-2层,以输入层的增强层回归向量为输入,采用与输入层相同的方式获得第2层森林模型的输出,并重复进行直到获得第K-1层森林模型的输出;输出层以第K-1层的增强层回归向量为输入构建输出层(第K层)森林模型模块,将多个子森林模型输出进行平均以获得DEFR模型预测值.采用加州大学欧文分校(University of California Irvine,UCI)平台混凝土抗压强度数据和真实城市固废焚烧过程的DXN排放质量浓度数据仿真验证了所提方法的有效性.
1 建模策略
本文提出了由输入层、中间层和输出层森林模块组成的DEFR建模策略,其中:每层的每个子森林模型均使用Bootstrap和随机子空间法对训练集进行样本和特征的随机采样以通过提高子森林模型训练样本的多样性增加子森林模型的多样性;为增加子森林模型类型的多样性,所提DEFR结构中采用RF和完全随机森林(complete random forest,CRF)2种类型的森林算法构建子森林模型.最终获得包含K层森林模型的DEFR模型,如图1所示.图1中符号含义的描述如表1所示.
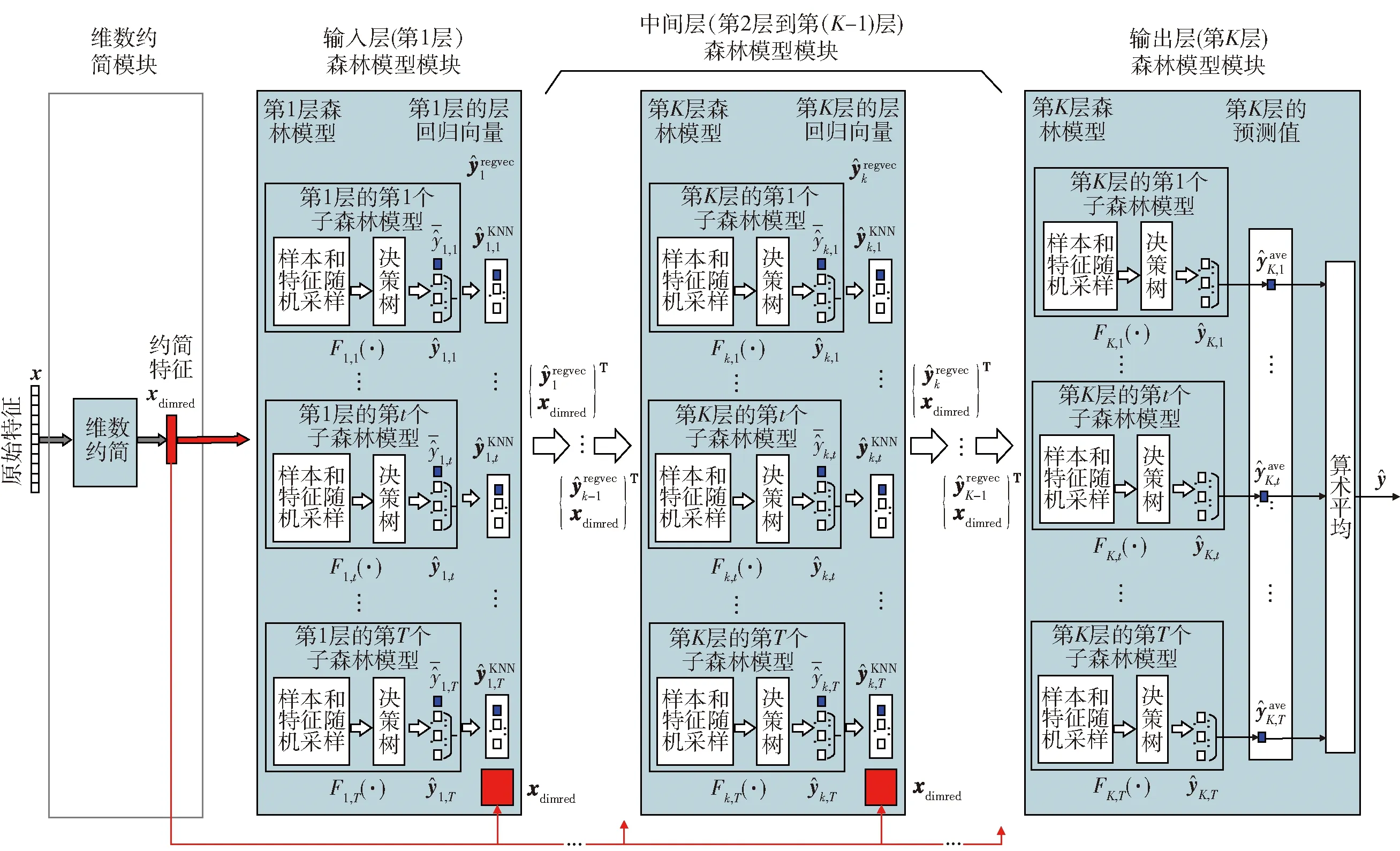
图1 建模策略Fig.1 Modeling strategy

表1 建模策略中的符号含义Table 1 Symbol meaning in modeling strategies
上述模型中不同模块的功能如下:
1)输入层森林模型模块 以原始特征向量为输入,利用Bagging思想构建由T个包含J个决策树组成的子森林模型,构成并行集成的输入层模型.在每个子森林模型预测值向量中选择kKNN个组成层回归向量,与原始特征向量组合后获得增强层回归向量,进而获得中间层森林模型模块的输入.
2)中间层森林模型模块 以输入层模型得到的增强层回归向量构建中间层的首层模型,然后采用Stacking思想重复上述步骤构建中间层中其他层模型.
3)输出层森林模型模块 以第K-1层模型的输出为输入训练第K层模型,并将T个子森林模型的预测值进行加权平均以获得最终预测结果.
注释1本文涉及多个层次的森林模型,其中:DEFR模型包含K个层森林模型,每个层森林模型由T个子森林模型组成,每个子森林模型包含J个DT模型.目前,子森林模型主要采用RF和CRF中2种算法构建,两者的主要区别在于针对DT进行分裂的规则存在差异.
2 建模算法
2.1 输入层(第1层)森林模型模块

(1)
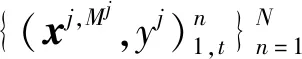
使用上述函数J次,即可得到输入层模型中第t个子森林的训练子集
(2)
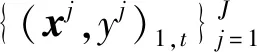

图2 子森林模型F1,t(·)的构建策略Fig.2 Construction strategy of sub-forest model F1,t(·)
基于准则
(3)

基于上述准则,首先通过遍历所有输入特征找到最优变量编号和切分点取值,将输入特征空间划分为左、右2个区域;然后对每个区域再重复上述过程,直到叶节点包含的样本数量少于阈值θForest;最终将输入特征空间划分为Q个区域.为构建回归树模型,定义函数
(4)
式中
(5)
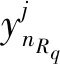
重复上述步骤,最终得到子森林模型
(6)

算法1RF
步骤1 利用Bootstrap和RSM对训练集进行样本和特征的随机采样,获得J个子训练集;
步骤2 For 1:J
步骤3 采用式(3)中的准则,遍历寻找最佳切分特征编号和切分点取值;
步骤4 划分输入特征为Q个区域;
步骤5 构建回归树模型Γj(·);
步骤6 End for
步骤7 构建RF模型FRF(·).
算法2CRF
步骤1 利用Bootstrap和RSM对训练集进行样本和特征的随机采样,获得J个子训练集;
步骤2 For 1:J
步骤3 采用随机的方式,遍历寻找切分特征编号和切分点取值;
步骤4 划分输入特征为Q个区域;
步骤5 构建回归树模型Γj(·);
步骤6 End for
步骤7 构建CRF模型FCRF(·).
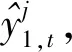
(7)
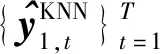
(8)
式中:fFeaCom表示特征组合函数,其功能为将层回归向量与原始特征串联组合;kKNN表示选择的预测值数量.
2.2 中间层森林模型模块
(9)
式中,第k层模型训练集Dk中的特征数量Mk=M+(kKNN×T).
然后,对训练集Dk进行样本和特征的随机采样,第k层模型中第t个子森林模型的第j个训练子集为
(10)

(11)
重复上述步骤J次,得到第k层模型中第t个子森林模型
(12)

(13)
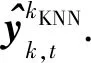
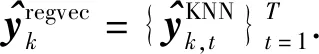
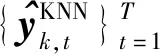
(14)
2.3 输出层(第K层)森林模型模块
(15)
式中,第K层模型训练集DK的特征数量用MK=M+(kKNN×T)表示.
然后,对训练数据集DK进行样本和特征的随机采样,输出层模型中第t个子森林模型的第j个训练子集为
(16)

(17)
重复上述步骤J次,获得第K层模型中第t个子森林模型
(18)

(19)
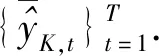
(20)
2.4 算法步骤
算法3DEFR
步骤1 For 1:T/2
步骤2 RF(D,J,Mj,θForest);
步骤4 CRF(D,J,Mj,θForest);
步骤6 End for
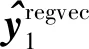
步骤8 For 1:K-2
步骤9 将上一层模型的增强层回归向量与训练集组合得到中间层模型中第k层模型的输入训练集Dk;
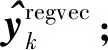
步骤12 End for
步骤13 将中间层模型输出的增强层回归向量与训练集真值组合,得到输出层模型输入训练集DK;
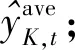
3 仿真验证
DEFR模型初始参数设置为:森林层的子森林个数设置为T=8,其中包含4个RF和4个CRF,KNN选择的预测值个数kKNN=1.
3.1 基准数据集
3.1.1 实验数据描述
采用UCI平台提供的混凝土抗压强度数据集[26-27]验证本文方法.该数据集中包含8个输入特征,以混凝土抗压强度作为输出,样本共1 030个.在仿真实验中,将1 030个样本中的1/2作为训练样本,1/4作为验证样本,1/4作为测试样本.
3.1.2 实验结果
针对基准数据集,其他参数设置为:K=3、Mj=4和J=500.以50次运行均值为最终结果,基于验证集的DT叶节点样本阈值θForest与均方根误差RMSE的关系如图3所示.
由图3可知,叶节点样本阈值为20时验证集RMSE(6.694 7)值最小,故选择该值为DT叶节点的训练样本阈值.中间层模型的子森林模型DT数量J与RMSE之间的关系如图4所示.
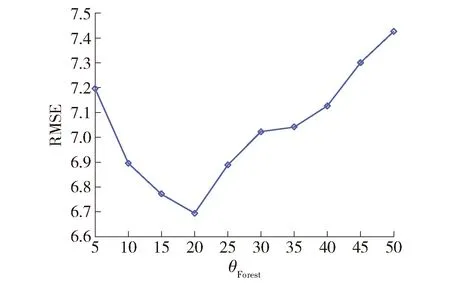
图3 基准数据样本阈值与RMSE间的关系Fig.3 Relationship between the sample threshold and RMSE for benchmark data

图4 基准数据DT数量阈值与RMSE间的关系Fig.4 Relationship between the DT number threshold and RMSE for benchmark data
由图4可知,中间层模型的子森林的DT数量在J=500时,验证集RMSE(6.694 7)值最小.子森林模型数量T与RMSE间的关系如图5所示.
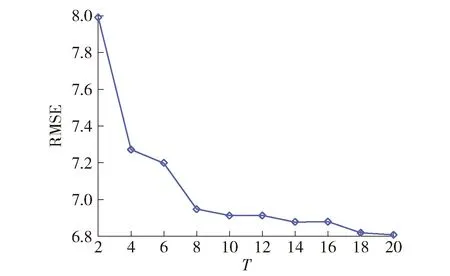
图5 基准数据子森林模型数量与RMSE间的关系Fig.5 Relationship between the sub-forest model number and RMSE for benchmark data
由图5可知,当T>8时,验证集误差下降较为平缓.综合考虑模型运行的时间成本,本文选择T=8.
3.1.3 方法比较
采用CRF、RF和深度置信网络(deep belief network,DBN)与所提DEFR进行比较.模型参数设置为:CRF,θForest=10,J=500,Mj=4;RF,θForest=10,J=500,Mj=4;DBN,3层网络,每层8个神经元.上述方法针对样本集的预测曲线如图6~8所示(为了清晰展示拟合效果,图中仅给出前100个样本).不同建模方法的统计结果如表2所示.

图6 基准数据集训练样本的预测曲线Fig.6 Prediction curve of training samples for benchmark dataset
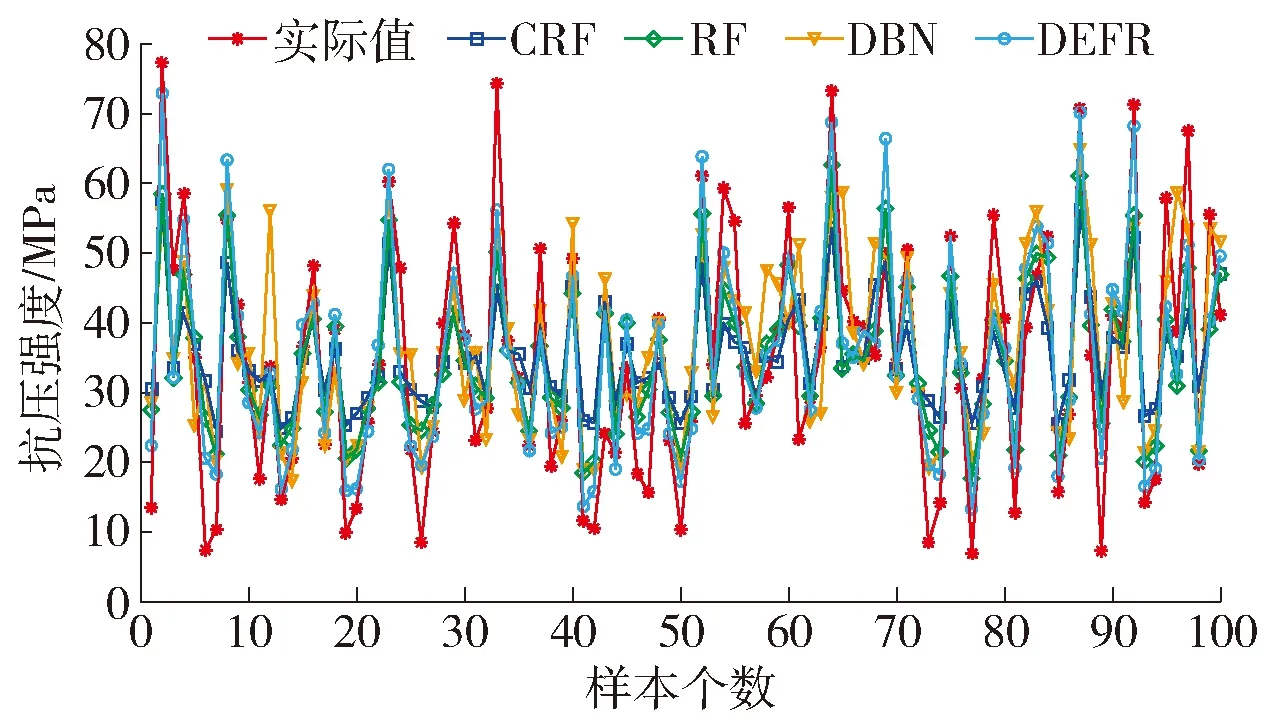
图7 基准数据集验证样本的预测曲线Fig.7 Prediction curve of validation samples of benchmark dataset

图8 基准数据集测试样本的预测曲线Fig.8 Prediction curve of testing samples of benchmark dataset
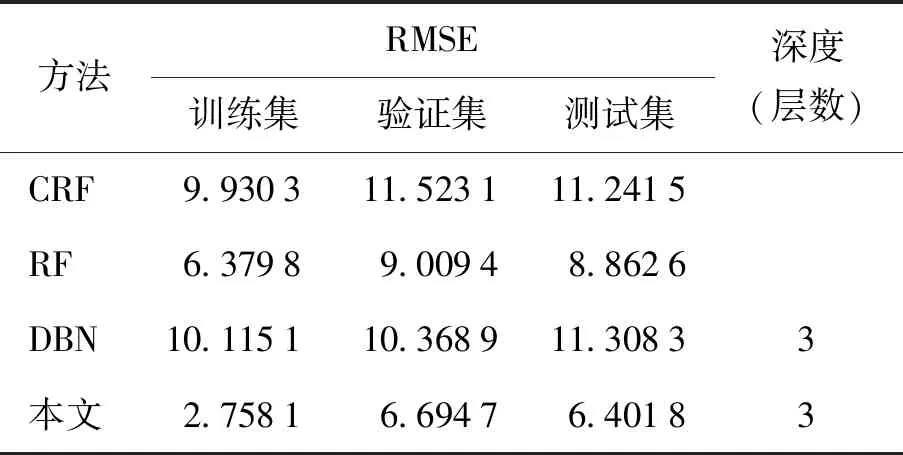
表2 基准数据不同建模方法的比较结果Table 2 Comparison results of different modeling methods for benchmark data
图6~8和表2的结果表明:
1)从训练、验证和测试3个数据集的预测误差可知,DBN在训练和测试数据上具有最差的泛化性能,验证数据仅是略强于CRF模型,表明其不适合小样本数据建模.
2)CRF固有的随机性导致其在不同数据集中的预测精度均弱于RF,而后者也具有强于DBN的性能,表明该算法针对小样本数据建模具有有效性.
3)本文所提DEFR方法针对训练集、验证集和测试集对混凝土抗压强度均具有最小预测误差,分别为2.758 1、6.947 0和6.401 8;原因在于DEFR模型集成了CRF和RF,具有复杂的集成结构以及层级之间的特征表征学习能力,在保证子模型精度的前提下提高了其多样性,从而使其具有更好的泛化性能.
3.2 DXN排放质量浓度数据集
3.2.1 实验数据描述
本文DXN数据为北京某MSWI发电厂1#和2#炉近6年来的真实数据,包含过程变量和实际DXN测量值,其中:过程变量分别源于发电系统(53个)、公共电气系统(115个)、余热锅炉系统(14个)、焚烧系统(79个)、烟气处理系统(20个)和末端检测系统(6个);DXN排放质量浓度的单位为ng/m3.全部66个样本中的1/2用作训练数据,1/4用作验证数据,1/4用作测试数据.
3.2.2 实验结果
针对DXN数据集,根据经验设置输入特征数量Mj=17、DT数量J=500和最大层数K=3.根据验证集样本数量,选取DT叶节点样本阈值区间为[2,20].DT样本阈值θForest与验证集误差的关系如图9所示.
由图9可知,θForest=2时验证集的RMSE值(0.023 6)最小.进一步,设置θForest=2,J=500,K=3,将Mj的取值区间设定为[7,52],Mj与RMSE间的关系如图10所示.
由图10可知,在Mj=52时验证误差(0.022 4)达到最小,并且验证误差随Mj增加呈现明显下降趋势.可见,建模参数仍可进一步地进行优化调整.设置θForest=2,Mj=52,K=3,将J的取值区间设为[50,500],DT数量J与RMSE的关系如图11所示.
由图11可知,在J=50时验证误差(0.022 3)达到最小.从曲线趋势可知,建模参数仍可有待于进一步优化调整.基于上述参数设置,子森林模型数量T与RMSE间的关系如图12所示.
综合考虑运行成本,结合图12选择子森林数量为T=8.
3.2.3 方法比较
采用CRF、RF和DBN与所提DEFR方法进行比较,相应的参数设置为:CRF,θForest=2,J=50,Mj=25;RF,θForest=2,J=50,Mj=25;DBN,3层网络,每层3个神经元.不同建模方法的预测曲线如图13~15所示,统计结果如表3所示.
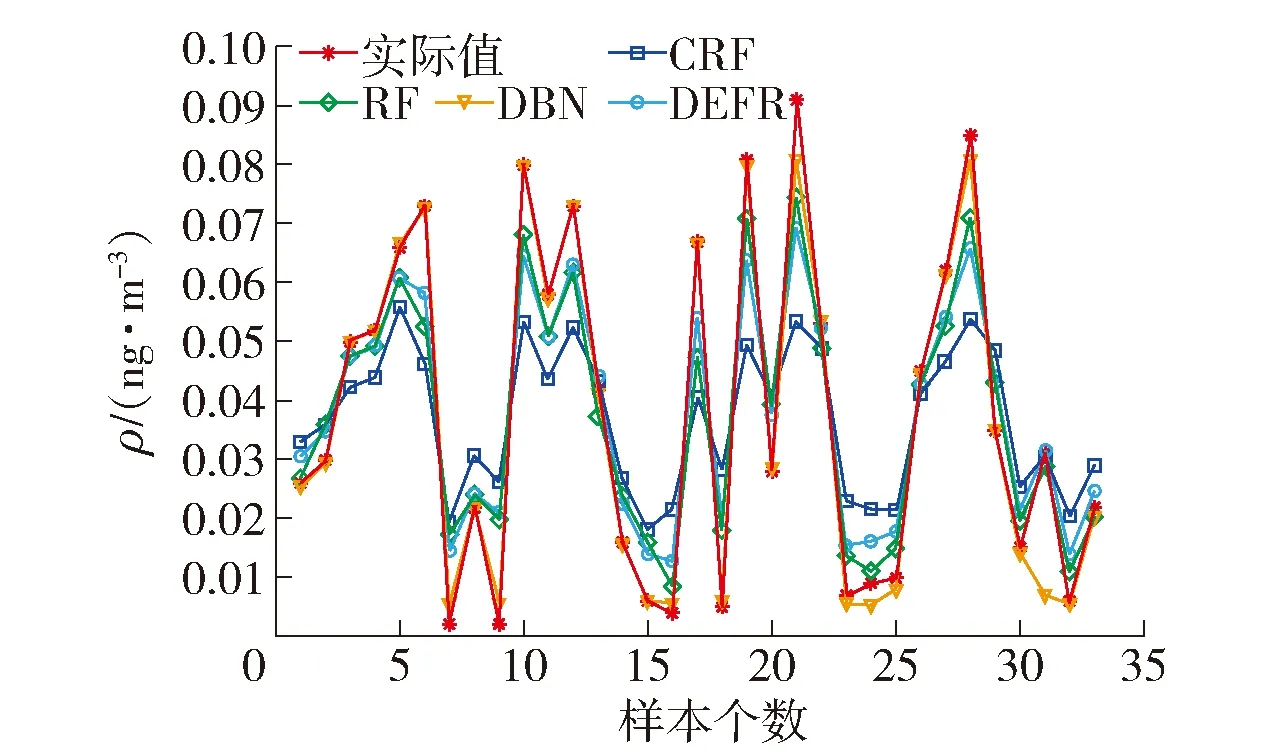
图13 DXN数据集训练样本的预测曲线Fig.13 Prediction curves of training samples for DXN data
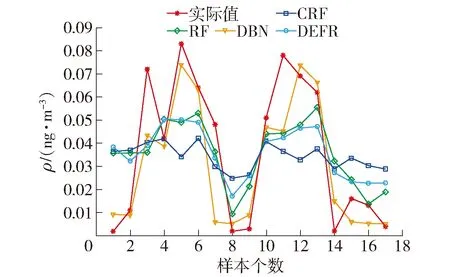
图14 DXN数据集验证数据的预测曲线Fig.14 Prediction curves of validation samples of DXN data
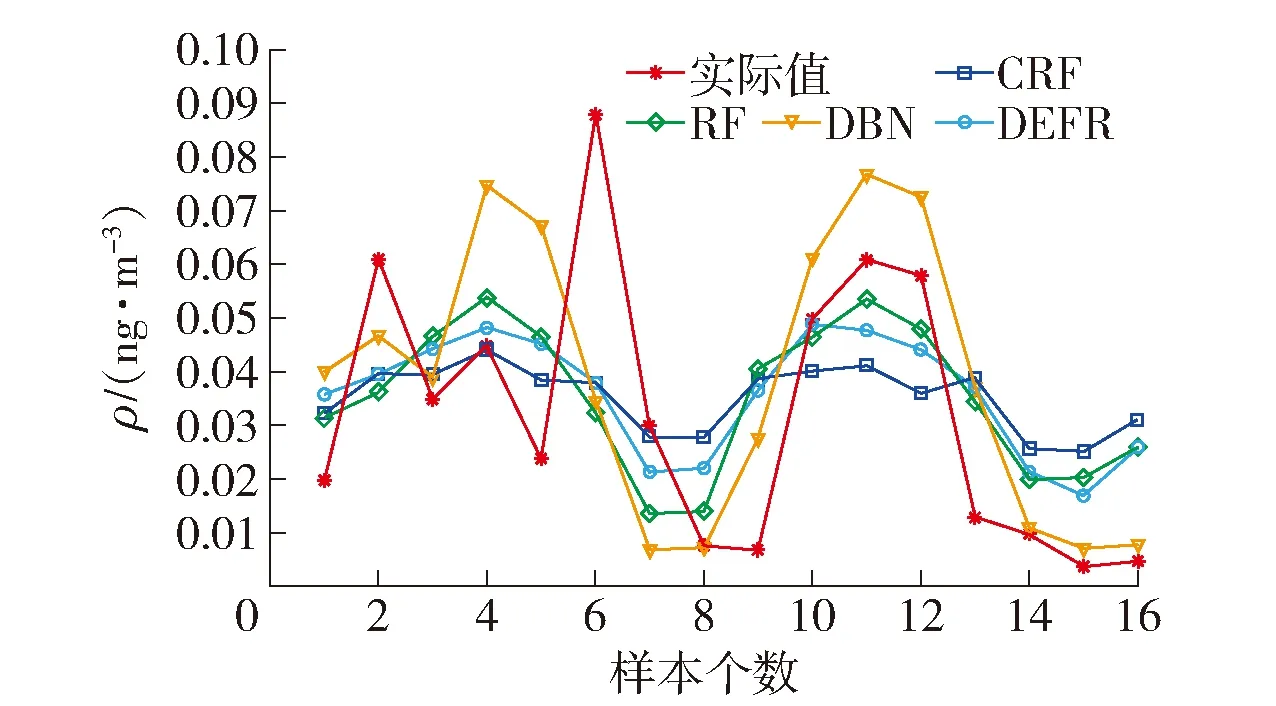
图15 DXN数据集测试数据的预测曲线Fig.15 Prediction curves of testing samples of DXN data

表3 DXN数据不同建模方法的比较结果Table 3 Comparison results of different modeling methods for DXN data
图13~15和表3的结果表明:
1)DBN模型具有最小训练误差和最大测试误差,表明针对高维小样本数据建模容易导致DBN模型过拟合,其测试误差(0.022 9)大于以DT为基学习器的其他3种集成建模方法.
2)基于CRF、RF和DEFR的预测结果可知,本文所提DEF通过深度集成CRF和RF以增加集成子模型的精度和多样性的方式提高了泛化性能.
因此,从上述基准数据集与DXN数据集的仿真结果可知,本文所提DEFR模型比传统RF、CRF和DBN模型具有更好的性能.
3.3 模型超参数分析
本文所提DEFR模型的超参数包括:模型深度K、输入特征数量Mj、KNN选择个数kKNN、子森林模型数量(宽度)T、DT模型数量J、叶节点最小样本数θForest等.此处,对主要超参数进行定性分析.
1)输入特征数量Mj在高维数据集中,模型预测精度随着Mj增大而随之提高,但模型的运行效率降低.因此,Mj的设置需要根据实际需求确定.
2)子森林模型数量(宽度)T该参数的增大可提高模型预测性能,但会增加建模的时间成本,故T值不宜过大.
3)DT模型的数量J模型的预测精度随J的增加具有差异化的趋势,该参数也与建模数据相关.
4)叶节点最小样本数θForest模型预测精度随着θForest增加而降低,该值应该考虑时间成本结合建模数据按需要选取.
综上可知,如何针对DEFR模型的超参数进行整体优化是有待深入研究的方向.
4 结论
1)针对工业过程难测参数的软测量建模,本文提出一种基于深度集成森林回归的建模方法.
2)本文提出了非神经网络模式的深度学习回归建模方法,解决了深度集成森林回归算法的层级间特征表征方式,实现了深度森林结构在回归建模问题中的应用.
3)通过UCI平台混凝土抗压强度数据和DXN排放质量浓度数据集仿真验证了所提方法的有效性.
