一种基于优化QPSO的大数据云存储调度方法研究
2021-11-15于国龙崔忠伟熊伟程
于国龙 崔忠伟 熊伟程 赵 勇 左 羽
1(贵州师范学院数学与大数据学院 贵州 贵阳 550018) 2(贵州师范学院大数据科学与智能工程研究院 贵州 贵阳 550018) 3(北京大学深圳研究生院信息工程学院 广东 深圳 518000)
0 引 言
云计算作为一种新兴的虚拟共享计算技术,在大数据的计算存储中得到了广泛的应用。云计算通过网络,利用虚拟化技术将处于不同地点,复杂的,甚至异构的计算资源建立起一个分布式共享资源池,在这个资源池中,最重要的问题就是要有一个合理的调度算法来高效均衡地调度这些资源。由于这些云计算资源相对数量庞大且非线性,计算逻辑复杂,资源使用频繁,因此云环境下任务调度问题实际上就是一个NP完全问题。在有限的时间复杂度基础上是很难得到该问题最优解的,只能尽可能寻找最优调度策略。传统的Min-min算法、Max-max算法、Sufferage算法、OLB算法、Duplex算法等都在云计算任务调度中得到了有效的应用,但调度效率不高,资源调度均衡性较差[1]。于是基于启发式智能算法的云计算任务调度策略被提出,如粒子群算法、蚁群算法、遗传算法等在云计算任务调度中得到了广泛的研究和应用[2-3]。文献[4]提出了动态惯性权重函数的方法来提高标准PSO的寻优速度,以此提升云任务调度效率;文献[5]提出了基于粒子适应度值的动态惯性权重,并借助Levy飞行防止粒子陷入局部最优,该算法在云计算任务调度中效率得到了提高;文献[6]提出了粒子位置更新惯性权重值自适应的QPSO,提高了算法的全局搜索速度,从而提高云计算任务调度效率。上述改进中,PSO及其改进算法采用得较多,但在应用中仍然存在搜索时容易陷入局部最优解、越往后粒子收敛的效率越低、不能以概率1收敛到最优解等不足。
为了提高粒子的全局搜索能力,本文选择QPSO。尽管QPSO有着比PSO更多的优点,但QPSO仍存在许多不足之处,诸多研究人员对其收缩扩张系数、种群多样性、收敛效率、平均最优位置的决策策略等方面做了大量的优化改进[7]。文献[8]为了寻找更为有效的CE系数控制方法,根据CE系数递减思想提出了一种凸凹性可变的指数型非线性下降CE系数控制策略;文献[9]首先建立了一个基于武器攻击目标的毁伤收益的分配模型,然后根据该模型的条件约束特点,提出一种基于排序映射的编码调整方式,并引入一种非线性扩张收缩因子自适应调整方法,同时引入了判断和避免陷入局部最优的有效机制。文献[10]为了提高QPSO求解多峰优化问题的能力,引入遗传算法中的交叉算子并融入交叉概率自适应的参数控制技术,来计算粒子吸引点和势阱特征的长度,该算法保证了粒子群体的多样性和活力性,能有效地避免陷入局部解和算法收敛的不确定性。
除了上述工作很多研究者也对QPSO收敛效率的优化做了大量的工作。但在目前考虑优化势阱特征长度计算研究中,平均最优位置计算的优化方法不多。本文结合大数据云存储的高频次资源使用的特点,从不同粒子在平均最优位置的计算中粒子位置的权重也不同的角度出发,考虑优秀粒子应拥有较大的决策权重,劣势粒子则应拥有相对较小的决策权重。因此提出了一种基于粒子适应度比重的决策权重计算方法,来提升QPSO的全局搜索能力及搜索效率。经过标准测试函数与原始QPSO和文献[10]改进的QPSO对比测试,本文优化后的QPSO较之前收敛效率有较大的提升。最后将本文优化后的QPSO应用到大数据云存储平台的任务调度中。仿真实验表明,本文算法在任务调度中有较高的效率,能为云存储平台提供高效的任务调度策略,提升云平台的数据存储效率。
1 QPSO模型
QPSO中粒子的运动状态借鉴了量子理论采用波函数来表示,取代了原始PSO中粒子的牛顿空间运动,用波函数的概率密度来为粒子确定迭代位置。这个位置可以是解空间的任意值,因此其全局搜索性能较好,只要粒子不停地迭代,就会以某一概率经过解空间任意一个位置。这样,粒子根据量子行为不断地更新自己的位置,逐渐向全局最优解迭代[11-12]。

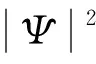
(1)
式中:Q是概率密度函数。Q要满足归一化要求:
(2)
在QPSO中,每个粒子在系统中的状态变化遵循Schrödinger方程,同时在系统中引入δ势阱,在pi点建立势阱,势能函数如式(3)所示,可得粒子在势阱中的定态Schrödinger方程,如式(4)所示。
V(x)=-γδ(X-pi)
(3)
(4)
式中:E为粒子的能量;h为Planck常量;m为粒子的质量。
解式(4)薛定谔方程可得到波函数,如式(5)所示[15-16]。
(5)
最后,采用蒙特卡洛随机模拟的方式测量粒子的位置:
(6)
式中:ui(t)~U(0,1)。势阱特征长度Li(t)的值由式(7)计算[17]。
Li(t)=2α(t)|mb(t)-xi(t)|
(7)
式中:mb表示平均最优位置,它是系统中所有粒子本身最优位置的中心点。在D维空间中mb(t)可由式(8)来计算。
(8)
式中:pbi(t)为每个粒子的局部最优值;α为收缩-扩张系数,它是QPSO的唯一控制参数。文献[18]已经证明了QPSO收敛到势阱中心的充分必要条件就是收缩-扩张系数α<1.78,在QPSO中,只要控制好系数α就可以保证算法以概率1收敛于最优解,它的取值会直接影响算法的收敛性能。本文α(t)的取值为:
(9)
传统PSO模型的速度和位置更新如式(10)和式(11)所示,传统的PSO需要确定的参数较多且复杂,可以看出传统PSO需要确定ω、c1、c2、r1、r2共5个参数,相对QPSO要复杂得多,这会导致算法不确定因素增多,算法的复杂性升高,稳定性也会较差。从PSO模型可见,当粒子的极值趋近于种群极值时,粒子将保持速度不变,如果速度的惯性权重ω<1时,粒子速度会越来越慢,最后停止在一个局部解上,这就造成了传统PSO算法更容易陷入局部最优,算法搜索后期效率会越来越低,且算法无法保证以概率1收敛到最优解,导致传统的PSO寻优性能要远低于QPSO。
vi(t+1)=ω·vi(t)+c1r1(pbi-xi(t))+c2r2(pg-xi(t))
(10)
xi(t+1)=xi(t)+vi(t+1)
(11)
式中:ω为速度的惯性权重,一般情况下取值范围为[0,1];c1、c2为学习因子,是两个正常数;r1、r2是[0,1]之间的随机数。
QPSO与经典PSO的最大区别在于粒子位置更新方法的不同。QPSO在原算法中增加了平均最优位置mb,mb可以增加粒子之间的相互作用,使得粒子能综合考虑其在系统中的位置更新,从而使得QPSO全局搜索能力得到提升。
平均最优位置mb如式(8)所示,可以看出它是每个粒子位置局部最优值的平均值,它决定了粒子位置的更新。在mb的计算过程中,每个粒子的局部最优值pbi(t)所占的权重相同,如式(12)所示。每个粒子的位置在mb的计算中所占的比重都是1,即每个粒子对最终的平均最优位置mb决策影响力是相同的。这不符合群体智能决策策略,现实应用中应是优秀粒子所占的决策权重比劣势粒子的要高。
(12)
2 QPSO粒子平均最优位置决策优化
针对QPSO中粒子在mb决策中影响力不均衡的问题,引入权重因子δ,δi(t)表示在第t次迭代中第i个粒子的局部最优值pbi(t)在粒子个体平均最优位置mb(t)计算中所占的权重值。引入权重因子δ后,粒子个体平均最优位置mb(t)的计算公式可表示为:
(13)
在本文优化的QPSO中,设每个粒子的适应值为fi,1≤i≤N,i∈Z,则在第t次迭代中,fbi为粒子i历史最高适应度值。当粒子迭代过程中,如果当前迭代的粒子适应度值与其历史最高适应度值变化不大,则:
|fi(t)-fbi|<ε
(14)
式中:ε为一个极小常量。ε越小,说明该粒子趋于最优解,具有较强的寻优能力;反之,粒子处于探索解空间状态,寻优能力较弱。所以本文构建Fi(t)函数来描述平均最优位置计算的粒子位置权重,如式(15)所示,其中1≤j≤N,j∈Z。
(15)
在应用中,寻优能力较强的粒子,即粒子当前适应度值与历史最高适应度值差距越小的粒子,应该获得平均最优位置计算中较高的权重。为构建随着粒子当前适应度值与历史最高适应度值差距越小权重越高的权重函数,归一化得到第i个粒子的局部最优值的权重因子δ(t),如式(16)和式(17)所示。
(16)
(17)
则粒子个体平均最优位置mb(t)的计算公式可表示为:
(18)
这样寻优能力越强的粒子,其局部最优值在平均粒子最优位置mb的计算中,就占有越高的权重,反之,占有较低的权重。
通过本节对QPSO的平均最优位置计算权重的优化,经过总结分析得到优化后的QPSO计算框架如图1所示。优化后QPSO初始化完粒子种群之后,就开始计算每个粒子的适应度值,然后由每个粒子的适应度值,利用式(17)来计算粒子在平均最优位置计算中优化后的权重,将得到的每个粒子的位置权重δi代入式(13)便就可以得到粒子个体平均最优位置mb(t),再通过式(7)和式(6)计算出粒子的势阱长度L(t)和粒子更新位置,并更新粒子的历史和全局最优位置,就完成了算法的一次迭代。最后判断算法是否达到迭代终止条件,若达到,则终止算法寻优,输出最优解,否则算法继续迭代。

图1 QPSO框架
优化后的QPSO实现伪代码如下所示:
//初始化N个粒子
fori=1 toN
//fis fitness
iff(xi) gb=min(pbi) 通过式(17)计算δi 通过式(13)计算mbd ford=1 toD ψ1=rand(0,1) ψ2=rand(0,1) p=(ψ1×pid+ψ2×pgd)/(ψ1+ψ2) u=rand(0,1) ifu>0.5 xid=p+α×abs(mbd-xid)×(ln(1/u)) else xid=p-α×abs(mbd-xid)×(ln(1/u)) end end end input global best 为了测试优化后的QPSO的收敛性能,本文选择了文献[10]表1中的21个标准测试函数,来测试优化后算法的收敛性能。设定种群数为40,维数为30,取与文献[10]表1相同的粒子搜索范围,迭代1 000次,对比原始QPSO、文献[10]算法及本文算法的收敛性能。文献[10]的CQPSO取原文参数。三种算法在21个测试函数上经过100次实验,得到的测试平均结果和标准方差如表1所示。 表1 测试函数运行的均值与标准方差 可以看出,本文算法在测试函数上获得的解的收敛精度要远远高于其他两种算法,全局搜索能力也优于其他两种算法。主要是由于算法在平均最优位置的计算过程中,考虑了优秀的粒子占有较高的决策权,即适应度越高的粒子在平均最优位置计算过程中,位置权重越高。这样更有利于防止粒子陷入局部最优,使得每个粒子尽可能向群体中适应值高的粒子学习经验,增强算法的全局搜索能力。 建立一个拥有m个资源的大数据云存储平台模型,资源R={r1,r2,…,rm};现有n个数据存储任务的任务集S,S={s1,s2,…,sn}需要在云存储平台上运行并调度。 在粒子搜索时,tij表示任务si在资源rj上执行所花费的时间,tij=0表示任务si没有被调度到资源rj上执行。所有数据存储任务的执行时间总和(CTF)越小,即粒子的收敛速度越快,说明任务集S被调度执行的效率越高,大数据云存储平台的性能越好。所以用CTF来衡量粒子搜索性能的优劣,搜索时间越短的粒子适应度越高,搜索时间越长的粒子适应度越低。系统执行完全部任务所需要的时间为: (19) 式中:G为粒子群的规模。因此,构建一个粒子适应度函数: (20) 算法在执行时,粒子的适应度越高则越容易被选中,说明粒子的任务集执行时间相对越短,粒子群算法的收敛速度越快,算法性能越好。 基于式(18)构建的大数据云存储平台任务调度模型的适应度函数,来确定优化QPSO的粒子平均最优位置计算权重,若tbi为粒子i历史任务调度最短时间的适应度值,则每次迭代粒子平均最优位置的权重δi(t)为: (21) 由式(19)可以得出当前粒子i寻优的任务调度策略所花费的时间与历史最优时间相差越短,其在平均最优位置计算中的权重δi(t)就越大,这样就使得平均最优位置更靠近最优解,增加了寻优过程中滞后粒子的势阱长度,从而吸引滞后的粒子也更快速的向最优解靠拢,同时也保留了粒子间一定的协同作用。这样就加速了QPSO的收敛速度,使优化后的QPSO能更快地寻找到最优云存储任务的调度策略,提升大数据云存储平台的数据存储效率。 实验平台采用CloudSim开源云计算仿真平台和MATLAB数据处理工具,具体的实验环境如表2所示。根据本文研究问题的建模需求,在平台上对任务模型、虚拟机模型进行调整,并改写其中DatacenterBroker类和Cloudlet类,在其中实现优化后的QPSO,同时复现原始QPSO和文献[10]算法。 表2 实验环境配置表 实验采用本文优化的QPSO与原始QPSO和文献[10]算法在云平台上进行任务集调度,来对比三种算法的调度性能,具体的实验参数如表3所示,其中文献[10]算法采用原文参数。实验中对比了三种算法在云平台资源数固定情况下,执行不同数量任务的时间,以及任务数固定,云平台资源数变化时,执行任务的时间。 表3 CloudSim模拟器参数列表 本节实验对比了在云存储平台中的Vmware的数量为10和20情况下,任务数量为40、80、120、160、200时,本文算法与原始QPSO及文献[10]算法,在云存储平台上任务集执行所用的时间对比,最终结果取50次实验的平均值。实验对比结果如图2和图3所示。 图2 资源数为10时的三种算法执行时间对比 图3 资源数为20时的三种算法执行时间对比 可以看出,当云平台计算资源固定的时候,随着任务数的增加,三种算法的任务执行时间都在增加,但本文算法较另外两种算法的增速要缓慢。其中,资源数为10时,本文算法较原始QPSO执行任务时间平均要短19.8%,较文献[10]算法执行任务时间平均要短13.77%;资源数为20时,本文算法较原始QPSO执行任务时间平均要短38.7%,较文献[10]算法执行任务时间平均要短25.8%。说明通过本文算法进行云存储平台任务调度,可以找到比另两种算法任务总执行时间更短的调度策略,收敛效率得到提升。 本节实验对比了分别在云存储平台上运行100和200个任务时,本文算法与原始QPSO及文献[10]算法在云存储平台虚拟机数量分别为10、15、20、25、30时的平台上任务执行效率。实验对比结果如图4和图5所示,最终结果取50次实验的平均值。 图4 任务数为100时的三种算法执行时间对比 图5 任务数为200时的三种算法执行时间对比 可以看出,当云平台执行任务数固定的时候,随着计算资源数的增加,三种算法的任务执行时间都在减少,相对于原始QPSO和文献[10]算法,本文算法减少的幅度较另两种算法要大,这也与5.1节实验结果相吻合,而且本文算法的时间减少幅度较平稳。说明使用本文算法进行云存储平台任务调度,不仅可以搜索到高效的任务调度策略,且算法稳定,资源利用率高。 本文优化了QPSO中平均最优位置的计算方法,在平均最优位置的计算中,使寻优能力越强的粒子,占有的决策权重越高。这符合群体智能决策策略,能使QPSO迅速向最优解收敛,提高算法的收敛效率。将优化后的QPSO在标准测试函数集上测试,得到了较好的收敛效果。最后将优化后的QPSO应用于大数据云存储平台的任务调度中,仿真实验表明,相比其他QPSO的改进算法,本文优化后的QPSO能提供高效的任务调度策略,提升云存储平台的存储效率。3 性能测试

4 基于优化QPSO的大数据云存储调度模型
5 仿真及结果分析


5.1 任务数量对云平台任务调度效率的影响
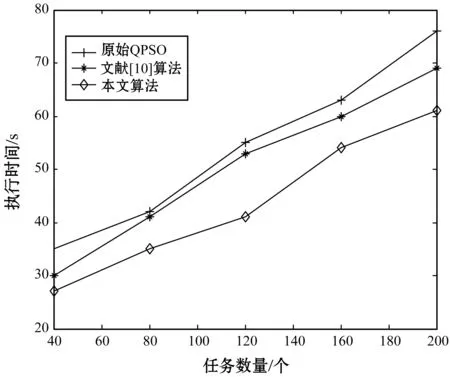
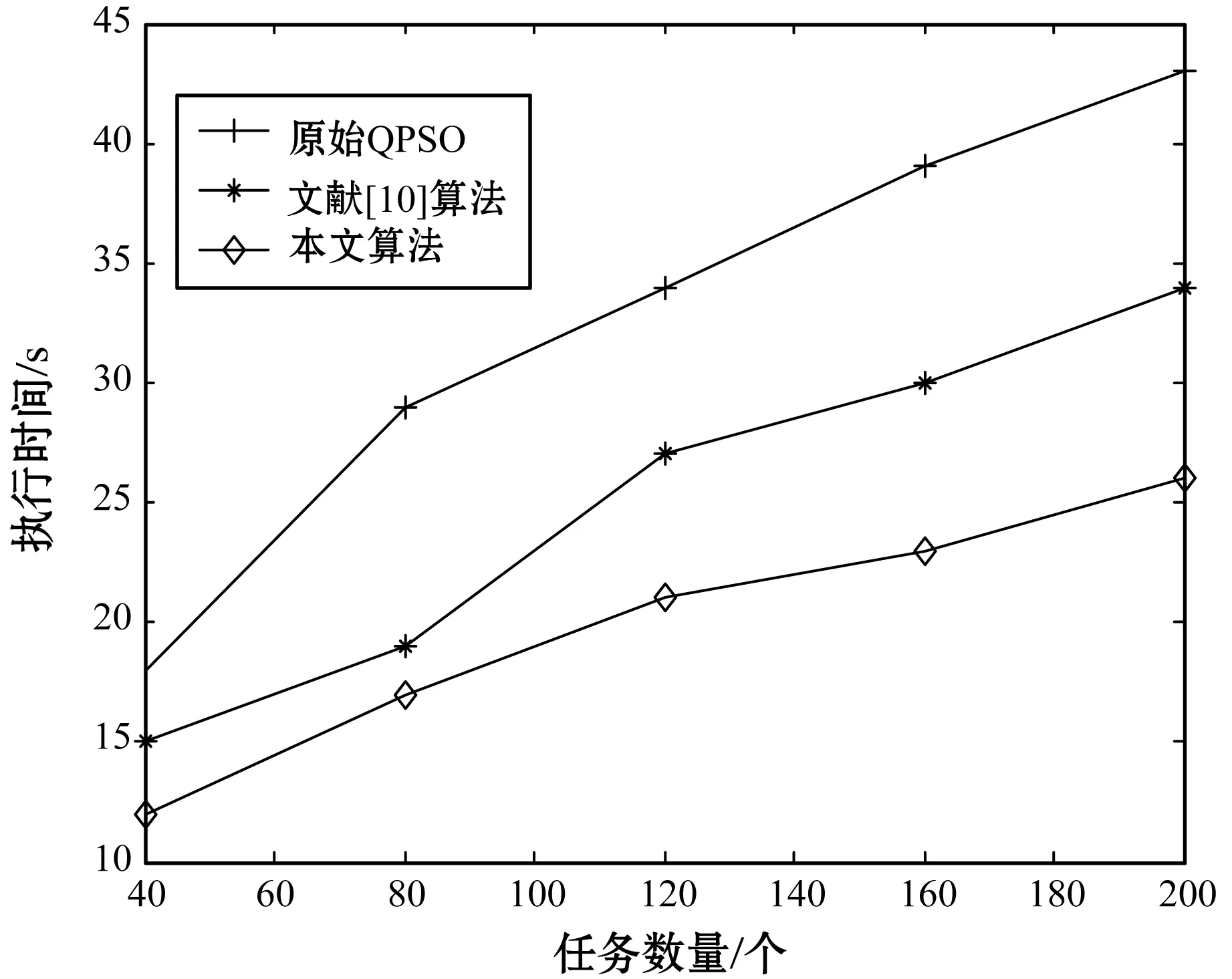
5.2 资源数量对云平台任务调度效率的影响


6 结 语
